
MLアプリプロジェクトの時間、コスト、および成果物の見積もり
公開: 2019-11-20店でカスタマイズされた財布を購入しようとしていると想像してみてください。
必要なウォレットの種類はわかっていますが、カスタマイズされたバージョンを入手するのにかかるコストや時間はわかりません。
機械学習プロジェクトの場合も同様です。 そして、このジレンマを解決するために、プロジェクトを成功させるための詳細な情報を提供しました。
機械学習は、両面を持つコインのようなものです。
一方では、プロセスから不確実性を排除するのに役立ちます。 しかし一方で、その開発は不確実性に満ちています。
ほぼすべての機械学習(ML)プロジェクトの最終結果は、ビジネスを改善し、プロセスを合理化するソリューションです。 その開発部分には、共有すべきまったく異なるストーリーがあります。
MLは、いくつかの確立されたモバイルアプリブランドの収益ストーリーとビジネスモデルを変える上で大きな役割を果たしてきましたが、それでもまだ厄介な状況で運営されています。 この新しさにより、モバイルアプリケーション開発者は、時間とコストの制約を念頭に置いて、MLプロジェクト計画を処理し、本番環境に対応させることがさらに困難になります。
この問題の解決策(おそらく唯一の解決策)は、時間、コスト、および成果物の白黒の機械学習アプリプロジェクトの見積もりです。
しかし、これらのセクションに進む前に、まず、ナイトキャンドルの難しさと燃焼がそれだけの価値がある理由を調べてみましょう。
アプリに機械学習フレームワークが必要な理由
時間、コスト、および成果物の見積もりの途中で、フレームワークについて話している理由を考えているかもしれません。
しかし、時間とコストの背後にある本当の理由はここにあり、それはアプリ開発の背後にある私たちの動機について私たちに知らせます。 機械学習が必要かどうか:
パーソナライズされたエクスペリエンスを提供するため
高度な検索を組み込むためのm
ユーザーの行動を予測するため
より良いセキュリティのために
深いユーザーエンゲージメントのために
これらの理由に基づいて、時間、コスト、および成果物はそれに応じて異なります。
機械学習モデルの種類
時間とコストを調整するために、どのタイプのモデルを検討しますか? わからない場合は、要件と予算に応じて、モデルを理解して選択するための情報を提供しています。
さまざまなユースケースの中での機械学習は、3つのモデルタイプに分類できます。これらのモデルは、基本的なアプリをインテリジェントなモバイルアプリ(教師あり、教師なし、強化)に変える役割を果たします。 これらの機械学習モデルが何を表すかについての知識は、ML対応アプリの開発方法を定義するのに役立ちます。
教師あり学習
これは、アルゴリズムの入力とその出力に正しくラベルが付けられたデータがシステムに提供されるプロセスです。 入力情報と出力情報にラベルが付けられているため、システムはアルゴリズム内のデータのパターンを識別するようにトレーニングされています。
将来の入力データに基づいて結果を予測するために使用されるため、さらに有益になります。 この例は、ソーシャルメディアが写真でタグ付けされたときに誰かの顔を認識するときに見ることができます。
教師なし学習
教師なし学習の場合、データはシステムに供給されますが、その出力は、教師ありモデルの場合のようにラベル付けされません。 これにより、システムはデータを識別し、情報からパターンを決定できます。 パターンが保存されると、将来のすべての入力がパターンに割り当てられ、出力が生成されます。
このモデルの例は、ソーシャルメディアが人口統計、学歴などのいくつかの既知のデータに基づいて友人に提案を与える場合に見ることができます。
強化学習
教師なし学習の場合と同様に、強化学習でシステムに提供されるデータにもラベルが付けられません。 両方の機械学習タイプは、正しい出力が生成されると、システムに出力が正しいと通知されるという理由で異なります。 この学習タイプにより、システムは環境と経験から学習できます。
この例はSpotifyで見ることができます。 Spotifyアプリは、ユーザーが親指を上に向けるか、親指を下に向ける必要がある曲を推奨します。 選択に基づいて、Spotifyアプリはユーザーの音楽の好みを学習します。
機械学習プロジェクトのライフサイクル
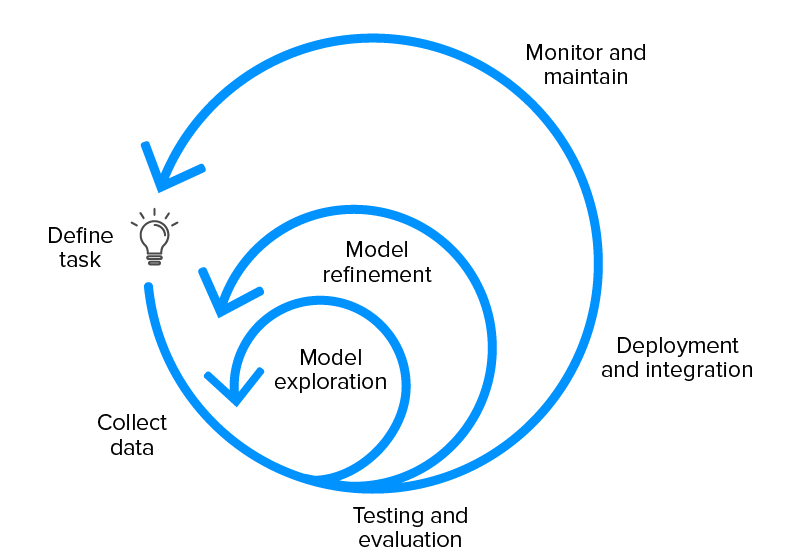
機械学習プロジェクトの成果物のタイムラインのライフサイクルは、通常、次のようになります–
MLプロジェクト計画の設定
- タスクと要件を定義する
- プロジェクトの実現可能性を特定する
- 一般的なモデルのトレードオフについて話し合う
- プロジェクトコードベースを作成する
データの収集とラベル付け
- ラベル付けドキュメントを作成する
- データ取り込みパイプラインを構築する
- データ品質の検証
モデル探索
- モデルパフォーマンスのベースラインを確立する
- 初期データパイプラインを使用して単純なモデルを作成する
- 初期段階で並行してアイデアを試す
- 問題のあるドメインのSoTAモデルがある場合はそれを見つけて、結果を再現します。
モデルの改良
- モデル中心の最適化を行う
- 複雑さが増すにつれてモデルをデバッグする
- 障害モードを明らかにするためにエラー分析を実施します。
テストと評価
- テスト分布でモデルを評価する
- モデル評価指標を再検討し、それが望ましいユーザー行動を促進することを確認します
- テストの作成–モデル推論関数、入力データパイプライン、本番環境で予想される明示的なシナリオ。
モデルの展開
- RESTAPIを介してモデルを公開します
- 新しいモデルをユーザーのサブセットにデプロイして、最終的なロールアウトの前にすべてがスムーズであることを確認します。
- モデルを以前のバージョンにロールバックする機能があります
- ライブデータを監視します。
モデルのメンテナンス
- モデルの古さを防ぐためにモデルを再トレーニングする
- モデルの所有権が譲渡された場合は、チームを教育します
機械学習プロジェクトの範囲を見積もる方法は?
Appinventiv Machine Learningチームは、Machine Learningタイプと開発ライフサイクルを熟読した後、次のフェーズに従ってプロジェクトのMachineLearningアプリプロジェクトの見積もりを定義します。
フェーズ1–発見(7〜14日)
MLプロジェクト計画のロードマップは、問題の定義から始まります。 対処すべき問題と運用上の非効率性を調査します。
ここでの目標は、要件を特定し、機械学習がビジネス目標を満たしているかどうかを確認することです。 この段階では、エンジニアがクライアント側のビジネスマンと会い、解決しようとしている問題の観点から彼らのビジョンを理解する必要があります。
次に、開発チームは、所有しているデータの種類と、外部サービスからデータを取得する必要があるかどうかを特定する必要があります。
次に、開発者は、アルゴリズムを監視できるかどうか、つまり予測が行われるたびに正しい応答が返されるかどうかを判断する必要があります。
成果物–プロジェクトが些細なものか複雑なものかを定義する問題ステートメント。
フェーズ2–探索(6〜8週間)
この段階の目標は、APIとしてインストールできる概念実証に基づいて構築することです。 ベースラインモデルがトレーニングされると、MLエキスパートのチームが本番環境に対応したソリューションのパフォーマンスを見積もります。
この段階では、検出段階で計画されたメトリックでどのようなパフォーマンスが期待されるかが明確になります。
成果物–概念実証
フェーズ3–開発(4か月以上)
これは、チームが本番環境での回答に到達するまで繰り返し作業する段階です。 プロジェクトがこの段階に達するまでの不確実性ははるかに少ないため、見積もりは非常に正確になります。

ただし、結果が改善されない場合、開発者は別のモデルを適用するか、データを作り直したり、必要に応じてメソッドを変更したりする必要があります。
この段階では、開発者はスプリントで作業し、個々の反復の後に何を行うかを決定します。 すべてのスプリントの結果を効果的に予測できます。
スプリントの結果は効果的に予測できますが、機械学習の場合、事前にスプリントを計画することは間違いである可能性があります。これは、未知の海域で作業するためです。
成果物–本番環境に対応したMLソリューション
フェーズ4–改善(継続的)
展開されると、意思決定者はほとんどの場合、コストを節約するためにプロジェクトを終了することを急いでいます。 この式はプロジェクトの80%で機能しますが、機械学習アプリには同じことが当てはまりません。
何が起こるかというと、データは機械学習プロジェクトのタイムライン全体で変化します。 これが、AIモデルを常に監視およびレビューする必要がある理由です。これは、モデルの劣化を防ぎ、モバイルアプリの開発を可能にする安全なAIを提供するためです。
機械学習中心のプロジェクトは、満足のいく結果を達成するために時間を必要とします。 アルゴリズムが最初からベンチマークを上回っていることに気付いたとしても、それらが1回の攻撃であり、別のデータセットで使用するとプログラムが失われる可能性があります。
全体的なコストに影響を与える要因
機械学習システムを開発する方法には、データ関連の問題やパフォーマンス関連の要因など、最後の費用を決定するいくつかの特徴的な機能があります。
データ関連の問題
信頼性の高い機械学習の開発は、驚異的なコーディングだけでなく、トレーニング情報の質と量も重要な役割を果たします。
- 適切なデータの欠如
- 複雑な抽出、変換、読み込みの手順
- 非構造化データ処理
パフォーマンス関連の問題
高品質のアルゴリズムには数ラウンドのチューニングセッションが必要なため、適切なアルゴリズムのパフォーマンスはもう1つの重要なコスト要因です。
- 精度は異なります
- 処理アルゴリズムのパフォーマンス
機械学習プロジェクトのコストをどのように見積もるのですか?
機械学習プロジェクトのコストの見積もりについて話すときは、最初にどのプロジェクトタイプについて話しているのかを特定することが重要です。
機械学習プロジェクトには主に3つのタイプがあり、機械学習の費用に答える役割を果たします。
まず、このタイプにはすでに解決策があります。モデルアーキテクチャとデータセットの両方がすでに存在します。 これらのタイプのプロジェクトは実質的に無料であるため、それらについては説明しません。
第二に–これらのプロジェクトには基礎研究が必要です–主流モデルと比較して完全に新しいドメインまたは異なるデータ構造でのMLの適用。 これらのプロジェクトタイプのコストは、通常、スタートアップの大多数が支払うことができないものです。
第三に–これらは私たちがコスト見積もりで焦点を当てようとしているものです。 ここでは、既存のモデルアーキテクチャとアルゴリズムを使用して、作業中のデータに合わせてそれらを変更します。
ここで、MLプロジェクトのコストを見積もる部分に移りましょう。
データコスト
データは、機械学習プロジェクトの主要な通貨です。 ソリューションと研究の最大値は、教師あり学習モデルのバリエーションに焦点を当てています。 教師あり学習が深くなるほど、注釈付きデータの必要性が高まり、機械学習アプリの開発コストが高くなることはよく知られている事実です。
ScaleやAmazonのMechanicalTurkなどのサービスはデータの収集と注釈付けに役立ちますが、品質についてはどうでしょうか。
データサンプルをチェックしてから修正するのは非常に時間がかかる場合があります。 この問題の解決策は、データ収集を外部委託するか、社内で改善するかの2つの側面に直面しています。
データの検証と改良の作業の大部分を外部委託してから、データサンプルのクリーニングとラベル付けを行うために社内に1人または2人を任命する必要があります。
研究費
プロジェクトの研究部分は、上記で共有したように、エントリーレベルの実現可能性調査、アルゴリズム検索、および実験フェーズを扱います。 製品デリバリーワークショップから通常表面化する情報。 基本的に、探索段階は、すべてのプロジェクトが生産前に通過する段階です。
最高の完成度でステージを完了することは、MLディスカッションを実装するためのコストに付随する番号が付属するプロセスです。
制作費
機械学習プロジェクトのコストの生産部分は、インフラストラクチャコスト、統合コスト、およびメンテナンスコストで構成されます。 これらのコストのうち、クラウド計算で最小限のコストをかける必要があります。 しかし、それもアルゴリズムごとに複雑さによって異なります。
統合コストはユースケースごとに異なります。 通常、APIエンドポイントをクラウドに配置し、それを文書化して、システムの他の部分で使用するだけで十分です。
機械学習プロジェクトを開発するときに人々が見落としがちな重要な要素の1つは、プロジェクトのライフサイクル全体を通じて継続的なサポートに合格する必要があることです。 APIから取得するデータは、適切にクリーンアップして注釈を付ける必要があります。 次に、モデルを新しいデータでトレーニングし、テストして展開する必要があります。
上記の点に加えて、AIアプリ/ MLアプリの開発コストの見積もりに重要な要素が2つあります。
機械学習アプリの開発における課題

通常、機械学習アプリプロジェクトの見積もりが作成されると、それに関連する開発上の課題も考慮されます。 ただし、MLを利用したアプリ開発プロセスの途中で課題が見つかる場合があります。 このような場合、全体的な時間とコストの見積もりは自動的に増加します。
機械学習プロジェクトの課題は、次の範囲に及ぶ可能性があります。
- どの機能セットが機械学習機能になるかを決定する
- AIと機械学習ドメインの人材不足
- データセットの取得には費用がかかります
- 満足のいく結果を得るには時間がかかります
結論
ソフトウェアプロジェクトを完了するために必要な人員と時間を見積もるのは、モジュール設計に基づいて開発され、アジャイルアプローチに従って経験豊富なチームによって処理される場合、比較的簡単です。 ただし、時間と労力を考慮して機械学習アプリプロジェクトの見積もりを作成する場合、同じことがますます困難になります。
目標は明確に定義されているかもしれませんが、モデルが望ましい結果を達成するかどうかの保証はありません。 通常、スコープを下げてから、事前定義された納期までタイムボックス設定でプロジェクトを実行することはできません。
不確実性があることを特定することが最も重要です。 遅延を軽減するのに役立つアプローチは、入力データが機械学習に適した形式であることを確認することです。
ただし、最終的には、どのアプローチに従う予定であっても、複雑さを最も単純な形で開発およびデプロイする方法を知っている機械学習アプリ開発エージェンシーと提携した場合にのみ、成功したと見なされます。
機械学習アプリプロジェクトの見積もりに関するよくある質問
Q.アプリの開発に機械学習を使用するのはなぜですか?
機械学習をモバイルアプリに組み込むことで、企業が利用できる多くのメリットがあります。 最も普及しているもののいくつかは、アプリのマーケティングの最前線にあります–
- パーソナライズされた体験を提供
- 高度な検索
- ユーザーの行動を予測する
- より深いユーザーエンゲージメント
Q.機械学習はビジネスにどのように役立ちますか?
企業にとっての機械学習のメリットは、破壊的なブランドとしてマークするだけではありません。 それは、彼らの提供物がよりパーソナライズされたリアルタイムになることに波及します。
機械学習は、ビジネスを顧客に近づけるための秘訣であり、顧客がどのようにアプローチしたいかを示します。
Q.機械学習プロジェクトの開発でROIを見積もるにはどうすればよいですか?
この記事は機械学習アプリのプロジェクト見積もりを立てるのに役立ちましたが、ROIの計算は別のゲームです。 ミックスの機会費用も考慮に入れる必要があります。 さらに、あなたはあなたのビジネスがプロジェクトから持っている期待を調べる必要があります。
Q. MLプロジェクトに適したプラットフォームはどれですか?
Androidアプリ開発会社と接続するか、iOS開発者と接続するかは、ユーザーベースと意図(利益を生み出すか価値中心か)に完全に依存します。