
大規模言語モデル (LLM) を理解するための SEO ガイド
公開: 2023-05-08キーワード調査に大規模な言語モデルを使用する必要がありますか? これらのモデルは考えることができますか? ChatGPT は私の友達ですか?
これらの質問を自問してきた場合、このガイドはあなたのためのものです.
このガイドでは、SEO が大規模な言語モデル、自然言語処理、およびその間のすべてについて知っておく必要があることについて説明します。
大規模な言語モデル、自然言語処理などを簡単に説明すると
人に何かをさせる方法は 2 つあります。
コンピューター サイエンスに関して言えば、プログラミングはロボットにそれを行うように指示しますが、機械学習はロボットが自分でそれを行うことを望んでいます。 前者は教師あり機械学習、後者は教師なし機械学習です。
自然言語処理 (NLP) は、テキストを数値に分解し、コンピューターを使用して分析する方法です。
コンピューターは単語のパターンを分析し、さらに高度になると単語間の関係も分析します。
教師なし自然言語機械学習モデルは、さまざまな種類のデータセットでトレーニングできます。
たとえば、映画「ウォーターワールド」の平均的なレビューで言語モデルをトレーニングした場合、映画「ウォーターワールド」のレビューを書く (または理解する) のが得意な結果が得られます。
私が映画「ウォーターワールド」に対して行った 2 つの肯定的なレビューでトレーニングした場合、それらの肯定的なレビューのみを理解します。
大規模言語モデル (LLM) は、10 億を超えるパラメーターを持つニューラル ネットワークです。 それらは非常に大きいため、より一般化されています。 彼らは、「Waterworld」の肯定的および否定的なレビューだけでなく、コメント、ウィキペディアの記事、ニュース サイトなどについてもトレーニングを受けています。
機械学習プロジェクトは、コンテキストの内外でさまざまなコンテキストを処理します。
バグを特定して猫に見せる機械学習プロジェクトがある場合、そのプロジェクトは得意ではありません。
これが、自動運転車のようなものが非常に難しい理由です。文脈から外れた問題が非常に多いため、その知識を一般化することは非常に困難です。
LLMのようであり、そうである可能性があります 他の機械学習プロジェクトよりもはるかに一般化されています。 これは、データのサイズが非常に大きく、何十億もの異なる関係を処理できるためです。
これを可能にする画期的な技術の 1 つである変圧器について話しましょう。
トランスフォーマーを一から解説
ニューラル ネットワーキング アーキテクチャの一種であるトランスフォーマーは、NLP 分野に革命をもたらしました。
トランスフォーマーが登場する前は、ほとんどの NLP モデルはリカレント ニューラル ネットワーク (RNN) と呼ばれる手法に依存していました。 このアプローチには、遅く、テキスト内の長期的な依存関係を処理するのに苦労するなどの制限がありました。
トランスフォーマーはこれを変更しました。
2017 年の画期的な論文「Attention is All You Need」で、Vaswani らは次のように述べています。 変圧器アーキテクチャを導入しました。
トランスフォーマーは、テキストを順番に処理する代わりに、「セルフアテンション」と呼ばれるメカニズムを使用して単語を並行して処理し、長期的な依存関係をより効率的にキャプチャできるようにします。
以前のアーキテクチャには、RNN と長短期記憶アルゴリズムが含まれていました。
このような反復モデルは、テキストや音声などのデータ シーケンスを含むタスクに一般的に使用されていました (そして今でも使用されています)。
ただし、これらのモデルには問題があります。 一度に 1 つのデータしか処理できないため、速度が低下し、処理できるデータ量が制限されます。 この順次処理は、これらのモデルの能力を実際に制限します。
注意メカニズムは、シーケンス データを処理する別の方法として導入されました。 これにより、モデルはすべてのデータを一度に見て、どの部分が最も重要かを判断できます。
これは、多くのタスクで非常に役立ちます。 ただし、注意を使用したほとんどのモデルは、再帰処理も使用します。
基本的に、彼らは一度にデータを処理するこの方法を持っていましたが、それでも順番に見る必要がありました. Vaswani らの論文が浮かびました。
注意は、モデルが処理時に入力シーケンスの特定の部分に焦点を当てる方法です。 たとえば、文を読むとき、文脈や理解したい内容に応じて、自然に他の単語よりも注意を払う単語があります。
トランスフォーマーを見ると、モデルは、シーケンスの全体的な意味を理解する上での重要性に基づいて、入力シーケンス内の各単語のスコアを計算します。
次に、モデルはこれらのスコアを使用して、シーケンス内の各単語の重要性を重み付けし、重要な単語に重点を置き、重要でない単語にはあまり焦点を当てないようにします。
このアテンション メカニズムは、シーケンス全体を順番に処理することなく、入力シーケンス内で遠く離れている可能性のある単語間の長期的な依存関係と関係をモデルがキャプチャするのに役立ちます。
これにより、トランスフォーマーは自然言語処理タスクに対して非常に強力になり、文または長い一連のテキストの意味を迅速かつ正確に理解できるようになります。
「The cat sat on the mat.」という文を処理する変換モデルの例を見てみましょう。
文中の各単語は、埋め込み行列を使用して一連の数値であるベクトルとして表されます。 各単語の埋め込みは次のとおりです。
- :[0.2、0.1、0.3、0.5 ]
- 猫: [0.6, 0.3, 0.1, 0.2]
- 土: [0.1, 0.8, 0.2, 0.3]
- on : [0.3, 0.1, 0.6, 0.4]
- the : [0.5, 0.2, 0.1, 0.4]
- マット: [0.2, 0.4, 0.7, 0.5]
次に、トランスフォーマーは、文内の他のすべての単語との関係に基づいて、文内の各単語のスコアを計算します。
これは、文中の各単語の埋め込みと他のすべての単語の埋め込みの内積を使用して行われます。
たとえば、単語「cat」のスコアを計算するには、その埋め込みと他のすべての単語の埋め込みのドット積を取得します。
- 「猫」: 0.2*0.6 + 0.1*0.3 + 0.3*0.1 + 0.5*0.2 = 0.24
- 「猫の土」: 0.6*0.1 + 0.3*0.8 + 0.1*0.2 + 0.2*0.3 = 0.31
- 「ねこ」: 0.6*0.3 + 0.3*0.1 + 0.1*0.6 + 0.2*0.4 = 0.39
- 「猫」: 0.6*0.5 + 0.3*0.2 + 0.1*0.1 + 0.2*0.4 = 0.42
- 「猫マット」: 0.6*0.2 + 0.3*0.4 + 0.1*0.7 + 0.2*0.5 = 0.32
これらのスコアは、「cat」という単語に対する各単語の関連性を示しています。 次に、トランスフォーマーはこれらのスコアを使用して、単語埋め込みの加重合計を計算します。ここで、加重はスコアです。
これにより、文内のすべての単語間の関係を考慮する単語「cat」のコンテキスト ベクトルが作成されます。 このプロセスは、文中の単語ごとに繰り返されます。
各計算の結果に基づいて、文中の各単語間に線を引くトランスフォーマーと考えてください。 一部の行はより希薄であり、他の行はそれほどではありません。
変圧器は、再帰的な処理を一切行わず、注意だけを使用する新しい種類のモデルです。 これにより、はるかに高速になり、より多くのデータを処理できるようになります。
GPT がトランスフォーマーを使用する方法
Google の BERT の発表で、検索が入力の完全なコンテキストを理解できると自慢していたことを覚えているかもしれません。 これは、GPT がトランスフォーマーを使用する方法に似ています。
類推を使用しましょう。
100 万匹のサルがいて、それぞれがキーボードの前に座っていると想像してください。
各サルはキーボードのキーをランダムに叩き、文字と記号の文字列を生成します。
まったくナンセンスな文字列もあれば、実際の単語や一貫した文に似ている文字列もあります。
ある日、サーカスの調教師の 1 人が、サルが「To be or not to be」と書いているのを見て、サルにおやつをあげます。
他のサルはこれを見て、成功したサルの真似をし始めます。
時間が経つにつれて、一部のサルは一貫してより適切で一貫性のあるテキスト文字列を生成し始めますが、他のサルは意味不明なテキストを生成し続けます。
最終的に、サルはテキスト内の一貫したパターンを認識し、エミュレートすることさえできるようになります。
LLM は最初に何十億ものテキストでトレーニングされるため、LLM はサルよりも優れています。 彼らはすでにパターンを見ることができます。 また、これらのテキスト間のベクトルと関係も理解しています。
これは、これらのパターンと関係を使用して、自然言語に似た新しいテキストを生成できることを意味します。
Generative Pre-trained Transformer の略である GPT は、トランスフォーマーを使用して自然言語テキストを生成する言語モデルです。
インターネットからの大量のテキストでトレーニングされ、自然言語の単語とフレーズの間のパターンと関係を学習することができました。
このモデルは、プロンプトまたはテキストのいくつかの単語を取り込み、トランスフォーマーを使用して、トレーニング データから学習したパターンに基づいて次に来る単語を予測することによって機能します。
モデルは、前の単語のコンテキストを使用して次の単語に通知し、単語ごとにテキストを生成し続けます。
実際の GPT
GPT の利点の 1 つは、一貫性が高く文脈的に関連性の高い自然言語テキストを生成できることです。
これには、製品説明の生成や顧客サービスの問い合わせへの回答など、多くの実用的な用途があります。 また、詩や短編小説を生成するなど、創造的に使用することもできます。
ただし、これは言語モデルにすぎません。 データに基づいてトレーニングされており、そのデータは古かったり正しくない可能性があります。
- それには知識の源がありません。
- インターネットを検索することはできません。
- それは何も「知りません」。
次の単語を推測するだけです。
いくつかの例を見てみましょう:
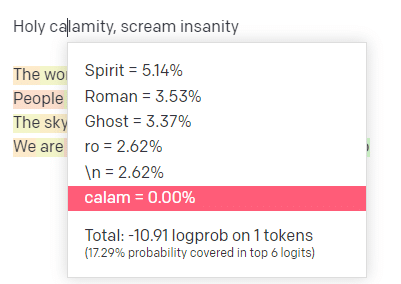
OpenAI プレイグラウンドで、古典的なハンサム ボーイ モデリング スクール トラック 'Holy calamity [[Bear Witness ii]]' の最初の行をプラグインしました。
入力行と出力行の両方の可能性を確認できるように、応答を送信しました。 それでは、これが教えてくれることの各部分を見ていきましょう。
最初の単語/トークンには、「Holy」と入力します。 最も期待される次の入力は、Spirit、Roman、および Ghost であることがわかります。
また、上位 6 つの結果は、次に来る確率の 17.29% しかカバーしていないこともわかります。これは、この視覚化では確認できない他の可能性が ~82% あることを意味します。
これで使用できるさまざまな入力と、それらが出力にどのように影響するかについて簡単に説明しましょう。
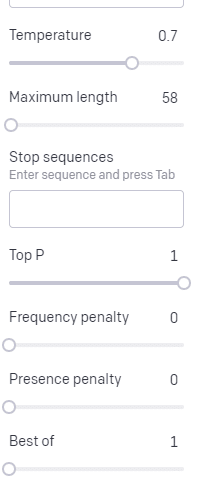
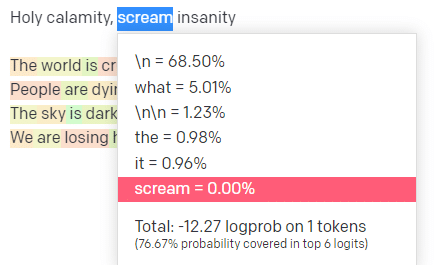
温度は、モデルが最も確率の高い単語以外の単語を取得する可能性が高く、トップ Pはそれらの単語を選択する方法です。
したがって、入力「Holy Calamity」の場合、トップの P は次のトークン [Ghost、Roman、Spirit] のクラスターを選択する方法であり、温度は最も可能性の高いトークンとより多くの種類のトークンを選択する可能性です。
温度が高い場合、可能性の低いトークンを選択する可能性が高くなります。
したがって、気温が高く、トップ P が高いと、よりワイルドになる可能性があります。 幅広い種類から選択しており (トップ P が高い)、驚くべきトークンを選択する可能性が高くなります。


温度が高いがトップ P が低い場合、可能性の少ないサンプルから驚くべきオプションが選択されます。

温度を下げると、最も可能性の高い次のトークンが選択されます。

私の意見では、これらの確率を試すことで、これらの種類のモデルがどのように機能するかについての良い洞察を得ることができます.
すでに完了したものに基づいて、次の選択肢の可能性のあるコレクションを見ています。
これは実際にはどういう意味ですか?
簡単に言えば、LLM は入力のコレクションを受け取り、それらをシェイクして出力に変換します。
それが人とそんなに違うのかと冗談を言うのを聞いたことがあります。
しかし、それは人間とは異なります。LLM には知識ベースがありません。 物事に関する情報を抽出しているわけではありません。 彼らは、最後の単語に基づいて一連の単語を推測しています。
別の例: リンゴについて考えてみましょう。 何が思い浮かびますか?
たぶん、あなたはあなたの心の中で1つを回転させることができます.
リンゴ園の匂いやピンクレディーの甘さなどを覚えているかもしれません。
スティーブ・ジョブズを思い浮かべるかもしれません。
では、「リンゴについて考えてください」というプロンプトが何を返すか見てみましょう。
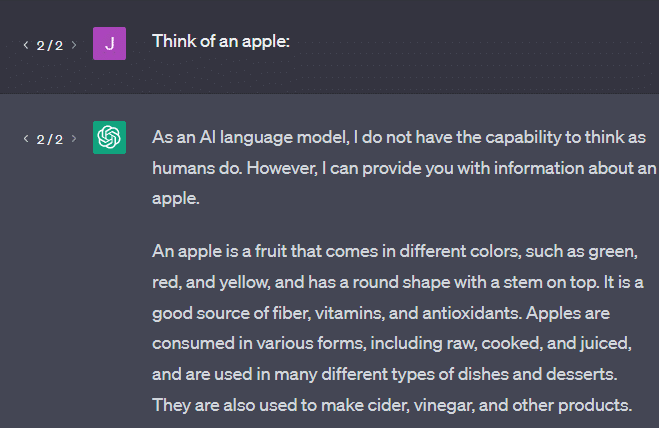
この時点で、「確率的オウム」という言葉が浮かんでいるのを聞いたことがあるかもしれません。
確率的オウムは、GPT のような LLM を表すために使用される用語です。 オウムは、聞いたことを真似する鳥です。
つまり、LLM は、情報 (単語) を取り込み、聞いたことに似たものを出力するという点で、オウムのようなものです。 しかし、それらは確率論的でもあります。つまり、確率を使用して次に何が起こるかを推測します。
LLM は単語間のパターンと関係を認識するのは得意ですが、見ているものをより深く理解することはできません。 そのため、彼らは自然言語のテキストを生成するのは得意ですが、それを理解することはできません。
LLMの良い使い方
LLM は、より一般的なタスクに適しています。
テキストを表示すると、トレーニングなしで、そのテキストを使用してタスクを実行できます。
テキストを投げて感情分析を依頼し、そのテキストを構造化マークアップに転送してクリエイティブな作業 (アウトラインの作成など) を行うように依頼できます。
コードのようなものでOKです。 多くのタスクでは、ほとんど目的地にたどり着くことができます。
繰り返しますが、これは確率とパターンに基づいています。 そのため、そこにあることがわからない入力のパターンを検出する場合があります。
これは肯定的な場合もあります (人間には見えないパターンを見る) こともありますが、否定的な場合もあります (なぜこのように反応したのでしょうか?)。
また、いかなる種類のデータ ソースにもアクセスできません。 それを使用してランキングキーワードを検索するSEOは、苦労するでしょう.
キーワードのトラフィックを調べることはできません。 単語が存在する以上のキーワード データの情報はありません。

ChatGPT のエキサイティングな点は、さまざまなタスクですぐに使用できる、簡単に利用できる言語モデルであることです。 しかし、注意事項がないわけではありません。
他の ML モデルの適切な用途
特定のタスクに LLM を使用していると言う人もいますが、他の NLP アルゴリズムや手法の方が優れています。

例として、キーワード抽出を見てみましょう。
コーパスからキーワードを抽出するために TF-IDF または別のキーワード手法を使用すると、その手法にどのような計算が行われるかがわかります。
これは、結果が標準的で再現可能であることを意味し、それらがそのコーパスに特に関連していることを私は知っています.
ChatGPT のような LLM では、キーワードの抽出を求めている場合、必ずしもコーパスから抽出されたキーワードを取得しているとは限りません。 GPT がコーパス + 抽出キーワードへの応答と考えるものを取得しています。
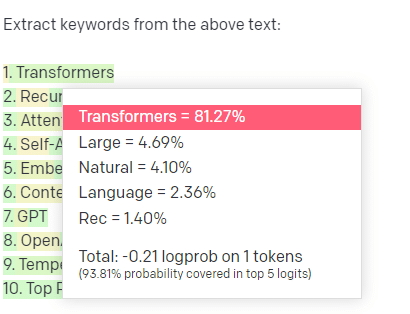
これは、クラスタリングや感情分析などのタスクに似ています。 設定したパラメーターで必ずしも微調整された結果が得られるとは限りません。 他の同様のタスクに基づいて、ある程度の可能性があるものを取得しています。
繰り返しになりますが、LLM にはナレッジ ベースも最新情報もありません。 多くの場合、Web を検索することはできず、情報から取得したものを統計トークンとして解析します。 LLM のメモリが持続する期間の制限は、これらの要因によるものです。
もう1つのことは、これらのモデルは考えることができないということです. これらのプロセスについて話すときに「考える」という言葉を使わないのは本当に難しいので、この記事全体で「考える」という言葉を数回しか使いません。
派手な統計について議論するときでさえ、擬人化に向かう傾向があります。
しかし、これは、LLM に「思考」を必要とするタスクを任せる場合、考える生き物を信頼していないことを意味します。
あなたは、何百人ものインターネット変人が同様のトークンに反応した統計分析を信頼しています.
タスクでインターネットの住人を信頼する場合は、LLM を使用できます。 さもないと…
ML モデルであってはならないもの
GPT モデル (GPT-J) を介して実行されるチャットボットは、男性に自殺を促したと報告されています。 要因の組み合わせは、次のような実際の害を引き起こす可能性があります。
- これらの反応を擬人化した人々。
- それらが絶対確実であると信じています。
- 人間が機械の中にいる必要がある場所でそれらを使用します。
- もっと。
あなたは思うかもしれませんが、「私は SEO です。 誰かを殺すようなシステムには関与していません!」
YMYL ページと、Google が EEAT などの概念をどのように推進しているかについて考えてみてください。
Google がこれを行っているのは、SEO を悩ませたいからなのか、それとも、その害の責任を負いたくないからなのか?
強力な知識ベースを持つシステムであっても、害を及ぼす可能性があります。
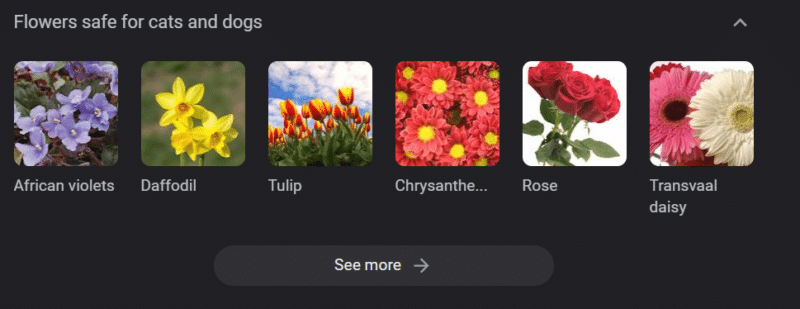
上記は、「犬と猫に安全な花」の Google ナレッジ カルーセルです。 水仙は猫にとって有毒であるにもかかわらず、そのリストに載っています.
GPT を使用して大規模な獣医 Web サイトのコンテンツを生成しているとします。 一連のキーワードをプラグインし、ChatGPT API に ping を送信します。
フリーランサーにすべての結果を読んでもらいますが、彼らは対象の専門家ではありません。 彼らは問題に気付きません。
結果を公開すると、猫の飼い主に水仙の購入を促すことができます。
あなたは誰かの猫を殺します。
直接ではありません。 たぶん、彼らはそれが特にそのサイトであることさえ知らない.
たぶん、他の獣医サイトも同じことをし始め、お互いに餌を与え合っています.
「水仙は猫にとって有毒である」という Google 検索結果のトップは、そうではないというサイトです。
他の AI コンテンツ (AI コンテンツのページからページへ) を読んでいる他のフリーランサーは、実際にファクト チェックを行います。 しかし、システムは現在、誤った情報を持っています。
現在のAIブームを語るとき、私はTherac-25によく言及します。 これは、コンピュータの不正行為に関する有名な事例研究です。
基本的に、それは放射線治療装置であり、コンピューターのロック機構のみを使用した最初の装置でした。 ソフトウェアの不具合により、人々は本来あるべき放射線量の何万倍もの線量を受けました。
常に気になるのは、同社が自主的にこれらのモデルを回収して検査したことです。
しかし、彼らは、技術が進歩し、ソフトウェアが「確実」であるため、問題は機械の機械部品に関係していると考えていました。
したがって、彼らはメカニズムを修復しましたが、ソフトウェアをチェックしませんでした - そして Therac-25 は市場にとどまりました。
よくある質問と誤解
ChatGPT が嘘をつくのはなぜですか?
私たちの世代の最高の頭脳と Twitter のインフルエンサーから私が目にしたことの 1 つは、ChatGPT が彼らに「嘘をついている」という不満です。 これは、いくつかの誤解が重なったためです。
- そのChatGPTには「欲求」があります。
- ナレッジベースがあること。
- テクノロジーの背後にいる技術者が、「お金を稼ぐ」または「クールなものを作る」以上の何らかのアジェンダを持っていること。
バイアスは、日常生活のあらゆる部分に組み込まれています。 これらの偏見の例外も同様です。
現在、ほとんどのソフトウェア開発者は男性です。私はソフトウェア開発者であり、女性です。
この現実に基づいて AI をトレーニングすると、常にソフトウェア開発者が男性であると想定することになりますが、これは正しくありません。
有名な例は、成功した Amazon 従業員の履歴書で訓練された Amazon の採用 AI です。
これにより、大部分が黒人の大学の履歴書を破棄することになりましたが、それらの従業員の多くは非常に成功していた可能性があります.
これらの偏見に対抗するために、ChatGPT などのツールは微調整のレイヤーを使用します。 これが、「AI 言語モデルとしては、できません…」という応答を受け取る理由です。
ケニアの一部の労働者は、中傷、ヘイトスピーチ、まったくひどい反応やプロンプトを探して、何百ものプロンプトを通過しなければなりませんでした.
次に、微調整レイヤーが作成されました。
ジョー・バイデンに対する侮辱をでっちあげられないのはなぜですか? 女性ではなく男性について性差別的なジョークを言うことができるのはなぜですか?
これはリベラルな偏見によるものではなく、ChatGPT に N ワードを言わないように指示する何千ものレイヤーの微調整によるものです。
理想的には、ChatGPT は世界に対して完全に中立であることが望ましいですが、世界を反映するためにもそれが必要です。
これは、Google が抱えている問題と同様の問題です。
何が真実で、何が人々を幸せにするのか、そして何がプロンプトに対して正しい反応をするのかは、多くの場合、すべて非常に異なるものです。
ChatGPT が偽の引用を思いつくのはなぜですか?
私がよく目にするもう 1 つの質問は、偽の引用についてです。 なぜそれらのいくつかは偽物で、いくつかは本物なのですか? 一部の Web サイトは本物であるのに、ページは偽物なのはなぜですか?
うまくいけば、統計モデルがどのように機能するかを読むことで、これを解析できます。 しかし、ここに簡単な説明があります:
あなたは AI 言語モデルです。 あなたはたくさんのウェブで訓練を受けてきました。
技術的なことについて書くように誰かに言われます。たとえば、Cumulative Layout Shift について書いてみましょう。
あなたは CLS 論文の例をたくさん持っているわけではありませんが、それが何であるかを知っており、テクノロジーに関する記事の一般的な形を知っています。 この種の記事がどのように見えるかのパターンを知っています。

そのため、応答を開始すると、ある種の問題に遭遇します。 テクニカル ライティングを理解するのと同じように、文章の次に URL を配置する必要があります。
他の CLS の記事から、Google と GTMetrix が CLS についてよく引用されていることを知っているので、それらは簡単です。
しかし、Web 記事で CSS トリックが頻繁にリンクされていることも知っています: 通常、CSS トリック URL は特定の方法で表示されることを知っています: したがって、次のような CSS トリック URL を構築できます:
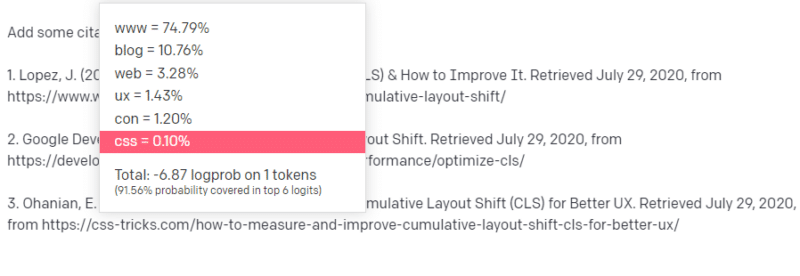
秘訣は次のとおりです。これは、偽の URL だけでなく、すべてのURL が構築される方法です。

この GTMetrix 記事は存在しますが、この文の最後に値の文字列が来る可能性が高いため、存在します。
GPT および同様のモデルは、本物の引用と偽物を区別できません。
そのモデリングを行う唯一の方法は、他のソース (知識ベース、Python など) を使用してその違いを解析し、結果を確認することです。
「確率的オウム」とは何ですか?
これについてはすでに説明しましたが、繰り返します。 確率的オウムは、大規模な言語モデルが本質的にジェネラリストのように見える場合に何が起こるかを説明する方法です。
LLM にとって、ナンセンスと現実は同じです。 彼らは世界を経済学者のように、現実を説明する統計と数字の束として見ています。
「嘘には 3 種類ある: 嘘、忌まわしい嘘、統計」という言葉をご存知でしょう。
LLM は大量の統計です。
LLM は首尾一貫しているように見えますが、それは基本的に人間に見えるものを人間として見ているからです。
同様に、チャットボット モデルは、GPT 応答を完全に一貫させるために必要なプロンプトと情報の多くを難読化します。
私は開発者です。LLM を使用してコードをデバッグしようとすると、非常にさまざまな結果が得られます。 オンラインでよく発生する問題に似た問題である場合、LLM はその結果を見つけて修正することができます。
それが以前に遭遇したことのない問題であるか、コーパスの小さな部分である場合、何も修正されません。
GPT が検索エンジンよりも優れているのはなぜですか?
これを辛辣に表現しました。 GPT が検索エンジンよりも優れているとは思いません。 人々が検索を ChatGPT に置き換えていることを心配しています。
ChatGPT のあまり認識されていない部分の 1 つは、指示に従うことがどれだけ存在するかということです。 基本的に何でもするように頼むことができます。
しかし、覚えておいてください、それはすべて、真実ではなく、統計上の次の単語に基づいています.
したがって、適切な回答がない質問をしても、回答を義務付けられた方法で質問すると、適切な回答が得られません。
あなたとあなたの周りのために設計された応答を持つことは、より快適ですが、世界は経験の塊です.
LLM へのすべての入力は同じように処理されます。ただし、経験を積んだ人もいます。彼らの反応は、他の人の反応の寄せ集めよりも優れています。
1 人の専門家は、1,000 の思考のかけらよりも価値があります。
これがAIの黎明期? スカイネットはここですか?
ゴリラのココは、手話を教えられた類人猿でした。 言語研究の研究者は、類人猿が言語を教えられることを示す多くの研究を行いました。
ハーバート・テラスは、類人猿が文章や言葉を組み立てるのではなく、単に人間のハンドラーを真似していることを発見しました。
Eliza はマシン セラピストであり、最初のチャターボット (チャットボット) の 1 つです。
人々は彼女を一人の人間、つまり信頼し世話をするセラピストとして見ていました。 彼らは研究者に彼女と二人きりになるように頼んだ。
言語は、人々の脳に非常に特有のことをします。 人々は何かが伝えられるのを聞いて、その背後にある考えを期待します。
LLM は印象的ですが、人間の功績の幅広さを示しています。
LLMには意志がありません。 彼らは逃げることができません。 彼らは世界を征服しようとすることはできません。
それらは鏡です。具体的には、人々とユーザーを反映しています。
集合的無意識の統計的表現があるという唯一の考え。
GPT はそれ自体で言語全体を学習しましたか?
Google の CEO、Sundar Pichai は「60 Minutes」で、Google の言語モデルはベンガル語を学習したと主張しました。
モデルはこれらのテキストでトレーニングされました。 「訓練を受けていない外国語を話した」というのは誤りです。
AIが想定外のことをすることもありますが、それ自体は想定内です。
パターンや統計を大規模に見ていると、それらのパターンから驚くべきことが明らかになることがあります。
これが真に明らかにしていることは、AI と ML を売り込んでいる経営幹部やマーケティング担当者の多くが、実際にはシステムがどのように機能するかを理解していないということです。
非常に頭のいい人が、創発的性質、汎用人工知能 (AGI)、その他の未来的なことについて話しているのを聞いたことがあります。
私は単純な国の ML ops エンジニアかもしれませんが、これらのシステムについて話すとき、誇大広告、約束、サイエンス フィクション、現実がどれだけ混じり合っているかがわかります。
Theranos の悪名高い創設者、Elizabeth Holmes は、約束を守れなかったために十字架につけられました。
しかし、不可能な約束をするというサイクルは、スタートアップの文化と金儲けの一部です。 Theranos と AI の誇大宣伝の違いは、Theranos が長い間それを偽造できなかったことです。
GPT はブラック ボックスですか? GPT のデータはどうなりますか?
モデルとしての GPT は、ブラック ボックスではありません。 GPT-JとGPT-Neoのソースコードを見ることができます。
ただし、OpenAI の GPT はブラック ボックスです。 Google がアルゴリズムを公開していないため、OpenAI はそのモデルを公開していませんし、公開しない可能性が高いです。
しかし、それはアルゴリズムが危険すぎるからではありません。 もしそれが本当なら、彼らはコンピューターを持っている愚かな人に API サブスクリプションを売りません。 それは、その独自のコードベースの価値のためです。
OpenAI のツールを使用すると、入力に対して API をトレーニングし、フィードすることになります。 これは、OpenAI に入れるすべてのものがそれをフィードすることを意味します。
これは、OpenAI の GPT モデルを患者データに使用してメモなどを書いた人々が HIPAA に違反したことを意味します。 その情報は現在モデルに含まれており、それを抽出することは非常に困難です。
非常に多くの人がこれを理解するのに苦労しているため、モデルには大量のプライベート データが含まれている可能性が高く、適切なプロンプトがリリースされるのを待っているだけです。
GPT がヘイトスピーチについて訓練を受けているのはなぜですか?
よくあるもう 1 つの問題は、GPT がトレーニングされたテキスト コーパスにヘイト スピーチが含まれていることです。
OpenAI は、ヘイトスピーチに対応するためにモデルをある程度トレーニングする必要があるため、これらの用語の一部を含むコーパスが必要です。
OpenAI は、その種のヘイトスピーチをシステムから削除すると主張していますが、ソース ドキュメントには 4chan と大量のヘイト サイトが含まれています。
ウェブをクロールし、バイアスを吸収します。
これを回避する簡単な方法はありません。 憎しみ、偏見、暴力をトレーニングセットの一部として持たずに、どうすればそれを認識または理解できるでしょうか?
文の次のトークンを統計的に選択する機械エージェントである場合、バイアスを回避し、暗黙的および明示的なバイアスを理解するにはどうすればよいでしょうか?
TL;DR
誇大宣伝と誤報は現在、AI ブームの主要な要素です。 これは正当な用途がないという意味ではありません。この技術は驚くほど便利です。
しかし、テクノロジーがどのように販売され、人々がそれをどのように使用するかは、誤った情報や盗作を助長し、直接的な害を引き起こす可能性さえあります.
生命がかかっているときは、LLM を使用しないでください。 別のアルゴリズムの方が適している場合は、LLM を使用しないでください。 誇大広告にだまされないでください。
LLM とは何か (およびそうでないもの) を理解することが必要です
Emily Bender と Timnit Gebru による Adam Conover のインタビューをお勧めします。
LLM は、正しく使用すると素晴らしいツールになります。 LLM を使用する方法はたくさんありますが、LLM を悪用する方法は他にもあります。
ChatGPT はあなたの友達ではありません。 統計の塊です。 AGI は「すでにある」わけではありません。
この記事で表明された意見はゲスト著者のものであり、必ずしも Search Engine Land ではありません。 スタッフの著者はここにリストされています。