
技術的なSEOの基本:クロール、インデックス作成、ランキング
公開: 2021-05-11この投稿は、もともと2021年5月に公開されました。最終更新日:2022年2月6日。
今日は、テクニカルSEOの基本についてお話します。 クロール、インデックス作成、ランキングの違いについて説明します。 また、内部リンク、robots.txtファイル、XMLサイトマップを活用して、GoogleがShopifyストアをより高速かつ効率的にクロールしてインデックスに登録できるようにする方法についても説明します。
概要
- Googleの仕組み:クロール、インデックス作成、ランキングの違いは何ですか
- 堅牢な内部リンク構造を作成する方法
- Shopify&robots.txt:知っておくべきことすべて
- Shopifyとsitemap.xml:知っておくべきことすべて
- サイトマップをGoogle検索コンソールに送信する:なぜそれが重要なのか、そしてその方法[ボーナス]
- 結論
Googleの仕組み:クロール、インデックス作成、ランキングの違いは何ですか
Googleは、SERP(検索エンジンの結果ページ)を生成するために3つのステップに従います。
- クロール
- インデックス作成
- ランキング
クロールは、Googlebotがウェブ上の新しいデータ(新しいページや更新された古いページなど)を検出する自動化されたプロセスです。
これはどのように起こりますか? Googlebotは、次の2つのリソースを使用してウェブをクロールします。
- 過去のクロールからのURLのリスト、つまり、Googlebotがすでにクロールしたページ
- サイトマップ
次に、GoogleはリストからすべてのURLとサイトマップに含まれるすべてのURLをクロールします。 注:クロールプロセス中、Googleは新しいウェブサイト、古いウェブページの更新、リンク切れに特別な注意を払います。
Googlebotは、次の方法で新しいページを見つけることができます。
- すでにクロールされているページのリンクをたどる。 たとえば、新しい商品ページを作成してホームページにリンクを追加すると、次にGooglebotがホームページ(既に知っているページ)をクロールするときに、新しい商品ページもクロールします。
- 更新され、新しく作成されたWebページへのリンクを含むサイトマップを読み取ります。

重要
ウェブサイトをクロールするには、Googleがウェブページにアクセスできる必要があります。 これは、Shopifyストアをパスワードで保護してはならないことを意味します(Googlebotは匿名ユーザーとしてWebにアクセスするため)。
Googleが新しいウェブページをより速くクロール(つまり発見)するのを助けるためにいくつかのことをすることができます。 例えば:
- 強力な内部リンク構造を作成する
- robots.txtファイルを作成します
- sitemap.xmlファイルを作成し、Google検索コンソールに送信します
これらの各手順については、以下で詳しく説明します。

Googleはアルゴリズムを使用して、クロールするWebサイト、それらをクロールする頻度、および各Webサイトからクロールするページ数を決定します。 新しいウェブページを追加したり、既存のウェブページに変更を加えたりした場合は、再クロールをリクエストできます。個々のURLまたはサイトマップの更新バージョンをGoogle検索コンソールに送信できます。 詳細→GoogleにURLの再クロールを依頼する
再クロールには最大で数週間かかる場合があることに注意してください。インデックスカバレッジレポートを使用して、進行状況を監視できます。 再クロールを複数回要求しても意味がないことに注意してください。プロセスが高速化されることはありません。
要約すると、クロールはWeb上で新しいデータを検出するプロセスです。 インデックス作成は、このデータをGoogleインデックスに分類、整理、保存するプロセスです。
これは何を意味するのでしょうか? Googlebotは新しいページを検出すると、そのコンテンツを評価し、その内容を理解しようとします。 次に、この情報を整理して、巨大なデータベースであるGoogleインデックスに保存します。 Googleインデックスには、数千億のページが含まれています。 1億ギガバイトを超えています。 グーグルはそれを本の裏にある索引として説明している-「私たちが索引付けするすべてのウェブページに見られるすべての単語のエントリがある。ウェブページに索引を付けるとき、それを含むすべての単語のエントリに追加する」。 (出典:Google、検索アルゴリズムのしくみ)
つまり、ページにインデックスを付けると、SERPに表示される可能性があります。 プロのヒント:インデックスカバレッジレポートを使用して、Shopifyストアのどのページがインデックスに登録されているかを確認し、インデックス作成の問題を検出します。
以前にインデックスが作成されたWebサイトのページがSERPに表示されなくなったと思われる場合は、URL検査ツールを使用してそのステータスを確認してください。 インデックスが作成されなくなった場合は、インデックスの問題(4xxエラーや5xxエラーなど)を確認してください。 インデックス作成の問題がある場合は、それらを修正して再クロールをリクエストしてください。
「それで、インデックス作成とランク付けは同じものではありませんか?」とあなたは尋ねるかもしれません。
答えはいいえだ。" その理由は次のとおりです。ページにインデックスを付けると、GoogleはそのページをSERPに追加するだけです。1ページ、101ページ、1001ページなどに表示されます。ランキングの最終的な目標は、ページの1位に到達することです。 SERPの#1ページ。
それで、ランキングは正確には何ですか?
Googleの主な目標は、検索クエリごとに最も関連性が高く高品質な結果を返すことです。 これを実現するには、GoogleはGoogleインデックスのすべての情報を調べて、検索クエリに最適な結果を決定する必要があります。 これは、誰かがGoogle検索を使用するたびに発生します。このプロセスはランキングと呼ばれます。
最も関連性の高い結果を見つけるために、Googleのランキングアルゴリズムは多くの要因を考慮に入れています。 一部はユーザーとそのクエリに関連しています。
- ユーザーの場所
- ブラウザの履歴
- ブラウザの設定
- キーワード
- 検索インテント
その他はあなたのウェブサイトに関連しています:
- 専門知識
- コンテンツの関連性
- コンテンツの品質
- コンテンツの鮮度
- バックリンクの数
- ドメインオーソリティ(DA)
- Webページ権限(PA)
- 使いやすさ
- もっと
要するに、ランキングは、SERPの結果を最も関連性の高いもの(#1のスポットに表示される)から最も関連性の低いものに並べ替えるプロセスです。 各クエリ(つまり、ランキング)で最良の結果を取得するのが上手になるように、Googleは毎日小さなアルゴリズム調整を行っています。 また、幅広いコアアルゴリズムの更新があり、SERPに大きな影響を与え、多くの業界に影響を与えます。
最終的に、検索クエリのページランクは高くなります。
- ページが検索クエリに関連している
- その品質が高いほど(特にSERPの他の結果と比較して)

- クロールとは、Webをスキャンして新しいデータ(新しいWebページと更新されたページ)を探すプロセスです。
- インデックス作成は、このデータを整理してGoogleインデックスに保存するプロセスです。
- ランキングは、検索クエリごとにSERP上の各Webページの位置を決定するプロセスです。
これまでのところ、技術的なSEOについては触れていません。 したがって、当然のことながら、「テクニカルSEOは、クロール、インデックス作成、ランキングと何の関係があるのでしょうか」と疑問に思うかもしれません。
答えは「すべて!」です。 GoogleがShopifyストアをクロール、インデックス作成、ランク付けするには、技術的に最適化する必要があります。
技術的なSEOの観点からクロールについて知っておくべきことは次のとおりです。
- Googlebotは、ウェブサイトにアクセスしてクロールできる必要があります。 Googlebotは匿名ユーザーとしてウェブにアクセスすることを忘れないでください。 したがって、Shopifyストアはパスワードで保護されるべきではありません。 Shopifyストアのパスワードを削除する方法を学ぶ
- XMLサイトマップが必要です。これは、Googleが新しいWebページのインデックスをより速く効率的に作成するのに役立つファイルです。 また、GoogleがWebページの重要性を評価し、さまざまなページとリソースの関係を理解するのにも役立ちます。
- robots.txtファイルが必要です。これは、Shopifyストアのどのページにアクセスできるか(つまり、インデックス)、どのページにアクセスできないかをGoogleに通知する単純なテキストファイルです。
- 防弾の内部リンク戦略が必要です。内部リンクは、GoogleがWebサイトをナビゲートし、新しいページをはるかに速く発見するのに役立ちます。
- Shopifyストアのページ階層は低くする必要があります。つまり、Webサイトのすべての重要なページは、ホームページから3クリック以内に配置する必要があります。 これにより、クロール予算(1回のクロールでGoogleがウェブサイトでクロールするページ数)が最適化されます。つまり、クロール予算が最も重要なページに割り当てられます。
- ウェブサイトは、Googleが簡単に理解してフォローできる論理的なURL構造を持っている必要があります。
- Shopifyストアには直感的なナビゲーションが必要です。
技術的なSEOの観点からインデックス作成について知っておくべきことは次のとおりです。
- 構造化データのマークアップをページに追加する必要があります。 ページのインデックスを作成するとき、Googleはそれを理解しようとすることを忘れないでください。構造化データのマークアップにより、このプロセスが簡単になります。 Shopifyでは、ホームページ、コレクションページ、製品ページ、ブログページ、記事ページに構造化データを追加する必要があります。 構造化データのマークアップの詳細→Shopifyの構造化データ:決定的なガイド[2022]
インデックス作成に関しては、ページ上のSEO指向がもう少し多いことに注意してください。 たとえば、GoogleがShopifyストアのインデックスを作成するためにできるその他のことには、ページのタイトルと見出しの最適化、説明的なメタタグの作成、ビジュアルコンテンツの最適化、テキストを使用したメッセージの伝達などがあります。
そして、ランキングに関しては、事態はさらに複雑になります。 Googleは、ウェブサイトの技術的な健全性と全体的なSEOの健全性(モバイル対応かどうか、新鮮で関連性の高いコンテンツが含まれているかどうか、Googleのウェブマスターガイドラインに準拠しているかどうかなど)を考慮します。 ランキングで最も重要な技術的なSEO要因には、ページの速度、重複するコンテンツ、壊れたリンクなどがあります。
今後数か月以内に、これらの技術的なSEOトピックのそれぞれについて説明します。 今日は、GoogleがShopifyストアをクロールするために必要な最初のステップにのみ焦点を当てます。
- 堅牢な内部リンク戦略を作成する
- 非の打ちどころのないrobots.txtファイルを持っている
- 非の打ちどころのないXMLサイトマップを持っている
堅牢な内部リンク構造を作成する方法
内部リンクは、同じドメイン上の別のページまたはリソースにつながるWebページ上のリンクです。
内部リンクはShopifyストアのアーキテクチャの重要なコンポーネントであり、Googleがウェブサイトの構造をよりよく理解するのに役立ちます。 その結果、強力な内部リンク構造により、Googleはウェブページをより速く、より効率的にクロールしてインデックスに登録できます。
堅牢な内部リンク構造を構築するには、最初に2つのタイプの内部リンクの違いを理解する必要があります。
- ナビゲーション内部リンク-Shopifyストアのナビゲーションを構成するリンク(たとえば、メインメニュー、サイドバーメニュー、ヘッダーおよびフッターメニューなどのリンク)。 彼らはあなたのウェブページの階層を確立し、あなたの顧客とグーグルの両方があなたの店をナビゲートするのを助けます。 また、それらはリンクエクイティを渡します。これは、Googleがストアで最も重要なページを理解するのに役立ちます。 その結果、Googleはこれらのページをより頻繁にクロールできます。
- コンテキスト内部リンク-Webページのメインコンテンツ内のリンク(たとえば、カテゴリページの製品ページへのリンク、記事と製品の説明のリンク、ポリシーページのリンクなど)。 このようなリンクの目的は、リンクエクイティを渡し、Googleが新しいページをより早く発見できるようにすることです。
10ステップで防弾内部リンク構造を作成
ステップ1:内部リンクをクロールできることを確認します。
言い換えると:
- URLは適切にフォーマットされている必要があります。 Shopifyはデフォルトでこれを処理します。 それでも、URL検査ツールを使用して問題をチェックできます。
一般的な経験則として、URLは短いほど良いことを覚えておいてください。したがって、不要な文字、記号、数字、フィラーワード(「and」、「a」、「the」など)は避けてください。 。
デフォルトでは、ShopifyはURLから記号(「&」、「?」、「!」など)を除外します。 ただし、フィラーワード(「and」、「the」、「a」など)は除外されません。したがって、これは注意が必要なことです。
- robots.txtファイルによってブロックされたページへの内部リンクを作成しないでください(必要な場合を除く)。
- 「インデックスなし」のメタタグを持つページへの内部リンクを作成しないでください(必要な場合を除く)。
注:robots.txtファイルと「インデックスなし」メタタグについては、以下で詳しく説明します。
ステップ2:ウェブサイトに壊れた内部リンクがないことを確認します。
SEMRushのサイト監査などのサイト監査ツールを使用して、内部リンクレポートを表示し、壊れた内部リンクを見つけることができます。 壊れた内部リンクを修正するには、2つの方法があります。それらを削除するか、別の関連する(そして機能している!)内部リンクに置き換えることができます。

内部リンクの破損を回避するためのプロのヒント
ページのURLを変更する場合は、「古いリンク→新しいリンクのURLリダイレクトを作成する」チェックボックスがオンになっていることを確認してください。 Shopifyでは、デフォルトでマークされています。 それでも、再確認することをお勧めします。
ステップ3:Shopifyストアからすべての孤立したページを削除します。
孤立したページは、Shopifyストアの他のページからリンクされていないページです。 Googlebotはリンクを使用してウェブをクロールするため、孤立したページを見つけるのがより困難になります(孤立したページがサイトマップに含まれていない場合、境界線は不可能です)。 また、顧客は実際には孤立したページにアクセスできません。 言い換えれば、彼らは実際にはSEOの重みを持っておらず、いかなる形でもあなたに利益をもたらしません。
したがって、Webサイトにそのようなページが含まれているかどうかを確認することが重要です。 Ahrefsのサイト監査などのツールを使用して、孤立したページをチェックできます。
Webサイトに孤立したページが含まれている場合は、その重要性を評価する必要があります。
- それらが重要な場合は、Webサイトの他のページにそれらへのリンクを追加してください。 上級者向けのヒント:コンテンツページが薄い場合は、共通のトピックを見つけて、類似したページをマージしてみてください。質の低いページをいくつか作成するよりも、質の高いページを1つ作成することをお勧めします。
- 重要でない場合は、削除してください。
ステップ4:Webサイトに低深度のページ階層があることを確認します。
まず、Webサイトで最も重要なページを特定します。
一般に、Webサイトで最も重要なページはそのホームページです。これは、最高のページ権限(PA)を持つページです。
eコマースでは、収益に直接影響するページも非常に重要です。 これらはあなたのカテゴリーページとあなたの製品ページです。
これらのページはすべて適切に相互リンクされている必要があります。 これは、Webサイトに技術的に最適化されたWebサイトアーキテクチャがある場合に発生します。
ここで覚えておくべき最も重要なことは、Webサイトの重要なページがホームページから3クリック以内にある必要があるということです(たとえば、ホームページ>カテゴリページ>製品ページ)。 このようにして、ホームページはより多くのリンクエクイティをカテゴリページに渡し、カテゴリページはリンクエクイティを製品ページなどに渡します。その結果、カテゴリと製品ページのランクが高くなります。
また、相互にリンクされたページ間には論理的な相関関係がなければなりません。 たとえば、あるカテゴリの商品ページは同様の特性を共有する必要があります。つまり、「シャツ」カテゴリにズボンがあってはなりません。
注:これについては次の記事で詳しく説明しますので、ご期待ください。
ステップ5:内部リンクを使用して、Googlebotが新しいページをより早く発見し、ランキングを向上させるのに役立てます。
Shopifyストアに新しい商品ページを追加したとします。 グーグルがそれをより速くクロールして索引付けするのを助けるために、あなたはそれへのリンクをあなたのホームページまたは非常によく機能するブログ投稿に加えることができます。 追加のメリットとして、これによりリンクの公平性が新しい製品ページに渡されます。つまり、SERPで上位にランク付けされる可能性が高くなります。もちろん、これが何を意味するのかは誰もが知っています。つまり、可視性と販売機会が増えます。
ステップ6:推奨製品を活用します。
「おすすめ商品」セクションでは、平均注文額が増え、より魅力的なショッピング体験を提供できるようになります。 また、これは相互リンクの絶好の機会です。「推奨製品」セクションのリンクは、Shopifyストアの他の製品ページに顧客を導く製品ページのリンクです。
Shopifyでは、「推奨製品」セクションに、自動生成された製品推奨のリストが表示されます。
製品は、顧客が操作している製品に基づいて最も関連性の高い製品を予測するアルゴリズムに基づいて推奨されます。 (出典:Shopify、製品ページに製品の推奨事項を表示)
このアルゴリズムは、販売データ(どの製品が頻繁に一緒に購入されるかを決定するため)と製品の説明(どの製品が類似しているか、互いに補完し合っているかを決定するため)を使用します。 アルゴリズムは、製品ごとに最大10個の類似製品を関連付け、関連性の高い順に表示します。
知っておく必要のある特定の制限があります。 たとえば、Shopifyプランに応じて、商品ページにさまざまな種類のおすすめ商品を表示できます。 また、特定の製品を除外するようにアルゴリズムをカスタマイズすることはできません(カスタムコードを記述しない限り)。 詳細→Shopify、製品の推奨事項

一部のShopifyテーマは、デフォルトで製品の推奨事項をサポートしています。

出典:Shopify、製品ページに製品の推奨事項を表示
また、カスタマイズ可能な「関連商品」セクションを作成したり、商品ページに関連商品を表示するのに役立つShopifyアプリを使用したりすることもできます。 そのようなアプリの1つが関連製品です-Globoも購入しています:
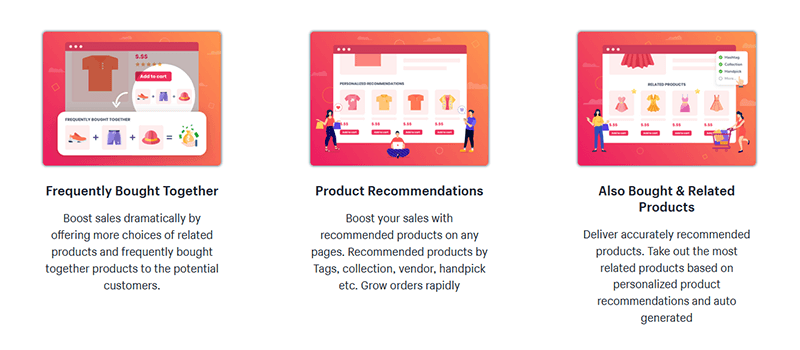
アプリは-評価をスポーツします。 無料プランと月額$ 9.90 /の有料バージョンがあります(7日間の無料トライアルが利用可能です)。
ステップ7:アンカーテキストに注意してください。
アンカーテキストは、相互にリンクされたページが何であるか、およびリンクを含むページに関連しているかどうかをGoogleが理解するのに役立つため重要です。
内部リンクのアンカーテキストは、関連性があり、説明的で、具体的である必要があります。 最良のシナリオでは、キーワードが含まれている必要があります。
一般的な経験則として、「続きを読む」や「ここをクリック」などのあいまいなアンカーテキストは避けてください。 代わりに、次のようにします。「続きを読む→関連性のある説明的なアンカーテキストを含む内部リンク」
ステップ8:リダイレクトチェーンを避けます。
リダイレクトチェーンは、最初のURL(つまり、要求されたURL)と最終的な宛先URLの間に複数のリダイレクトがある場合に発生します。 たとえば、Xが最初のURLで、Zが最後のURLであると想像してください。 リダイレクトチェーンは、URL X> URLYへのリダイレクト> URL Zへのリダイレクトになります。その結果、URLZの読み込みに時間がかかります。
一般に、リダイレクトチェーンはユーザーエクスペリエンスの低下につながるため、避ける必要があります。 また、それらはグーグルがあなたのウェブサイトをクロールすることをより難しくします。 したがって、Googleはそれらを可能な限り制限することをお勧めします。
リダイレクトチェーンはどのように発生しますか?
ページのURLを変更し、新しいURLへのリダイレクトを作成するとします。 ここで、ページがすでに相互リンクされており、リンクが古いURLにつながっていると想像してください。 誰かがリンクをクリックすると、最初に古いURLにリダイレクトされ、次に新しく更新されたURLにリダイレクトされます。
WebサイトにSSL証明書をインストールするときにも、リダイレクトチェーンが発生する可能性があります。この場合、古いHTTPリンクはすべて、新しく安全なHTTPSリンクに自動的にリダイレクトされます。 したがって、ユーザーが作成済みのインターリンクをクリックすると、最初にページのHTTPバージョンにリダイレクトされ、次にHTTPSバージョンにリダイレクトされます。
リダイレクトチェーンを最小化するには:
- すべての内部リンクがライブページに直接つながることを確認してください。
- HTTPからHTTPSへの切り替え中に実装するリダイレクトを更新します。
- 別のURLにリダイレクトしているURLへのリンクは避けてください。
- 既存のリダイレクトを定期的に監査し、不要なリダイレクトをすべて削除します。 SEMRushのサイト監査ツールを使用して、リダイレクトチェーンを検出し、それらを修正する方法についてアドバイスを得ることができます。
ステップ9:やりすぎないでください。
確かに、相互リンクは重要です。 ただし、「相互リンクが多すぎる」などの問題があります。特に、目的がない場合、つまり、ページの品質がまったく向上しない場合はそうです。
ページには妥当な数の内部リンクが含まれている必要があり、それらはすべて意味がある必要があります。つまり、ページ上にある論理的な理由があるはずです。
素人の言葉で言えば、それのためだけに内部リンクを作成しないでください。
ボーナスステップ:コンテンツ戦略を構築します。
コンテンツ戦略を実施することは、いくつかの理由で重要です。
- これはSEOに適しており、関連する大量のキーワードをランク付けするのに役立ちます。 これにより、認知度が高まり、ブランド認知度を高めることができます。
- それはあなたがあなたのニッチの権威としてあなた自身を確立するのを助けます。
- それは顧客の信頼を築きます。
- それはあなたがより多くの情報に基づいたショッピング体験を提供するのに役立ちます。
- それはあなたがより魅力的で徹底的な方法であなたの製品を提示するのを助けます。
- それはたくさんの相互に関連する機会を提供します。
では、どのようにして強力なコンテンツ戦略を構築しますか?
何よりもまず、関連性の高い高品質のコンテンツを作成します。 ターゲットオーディエンスが気にかけているトピックについて書きます-彼らの問題に対処し、彼らの質問に答えます。
次に、トピッククラスターを作成します。つまり、関連するトピックを考え出し、トピックごとに5つまたは10の個別のブログ投稿を作成します。 これらの投稿は同じトピックのさまざまな角度をカバーするため、相互リンクの可能性は数多くあります。 また、1つのシリーズのすべてのブログ投稿を公開したら、柱のページを作成してすべてを相互リンクできます。これは、内部リンク戦略を向上させるための優れた方法です。
第三に、ブログの投稿を使用して、カテゴリと製品ページを相互にリンクします(たとえば、ギフトガイド、製品コレクションや製品発売に関する投稿など)。 これは、Googleがそれらをより速く見つけるのに役立ち、またそれらのランキングを向上させる可能性があります。
Shopify&robots.txt:知っておくべきことすべて
簡単に言うと、robots.txtは、ウェブサイトのどのページをクロールするか、どのページをクロールしないかをGoogleに指示する単純なテキストファイルです。
一般に、SEOにはrobots.txtファイルは必要ありません。 ただし、robots.txtを使用すると、見逃してはならないいくつかの利点があります。
- これにより、Googlebot(およびその他の検索エンジンクローラー)が機密情報を含むページ(ログイン/サインアップページ、アカウントページなど)をクロールしてインデックスに登録するのを防ぎます。
- これにより、Googlebotは、SEOの重みがないページやリソース(「ありがとう」ページ、プレビューページ、PDFファイル(製品マニュアルなど)など)をクロールしてインデックスに登録することができなくなります。
- これにより、Googlebotが薄いコンテンツページや重複コンテンツを含むページをクロールするのを防ぎます。
- これは、検索エンジンがサイトマップをより簡単に見つけるのに役立ちます(robots.txtファイルにはサイトマップへのリンクが含まれています)。
- それはグーグルがあなたのウェブサイトをより速くそしてより効率的にクロールしてインデックスを付けるのを助けます。
- それはあなたのクロール予算を最適化します(グーグルがクロールされて索引付けされるべきではないページをクロールしないことを確実にすることによって)。
Shopifyとrobots.txtについて知っておくべきこと:
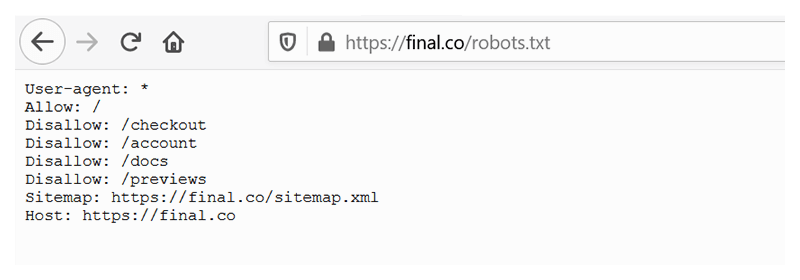
これは、Shopifyのお気に入りのストアの1つであるFinalStrawのrobots.txtファイルです。
先に進む前に、各ディレクティブ(つまり、robots.txtファイルの各行)の意味を説明しましょう。
- 「User-agent」ディレクティブは、命令の対象となるクローラーを指定します。 つまり、ユーザーエージェントが「User-agent」ディレクティブで指定されている場合(たとえば、「User-agent:Googlebot」)、このユーザーエージェント(たとえば、「Googlebot」)は指示に従う必要がありますが、別のエージェント(たとえば、「Bingbot」-Bingのクローラー)は先に進み、より具体的なディレクティブを探す必要があります。 ユーザーエージェントが指定されていない場合(上記の場合のように)、すべての検索エンジンボット(またはクローラー)が指示に従う必要があります。
- 「Allow」ディレクティブはGooglebotにのみ適用されます。 親ページまたはサブフォルダーが許可されていない場合でも、特定のWebページまたはサブフォルダーにアクセスできることをGooglebotに通知します。
- 「Disallow」ディレクティブは、検索エンジンのボットに、クロールおよびインデックス作成しないページを指示します。
- 「サイトマップ」ディレクティブは、検索エンジンボットがXMLサイトマップの場所を指すようにします。
- 「Host」ディレクティブには、ホームページのURL(つまり、プライマリドメイン)が含まれています。
robots.txtがどのように機能するかを理解できたので、robots.txtファイルとShopifyについて知っておくべきことは次のとおりです。
- Shopifyはrobots.txtファイルを自動的に生成します。
- robots.txtファイルは、ウェブサイトのプライマリドメイン名のルートディレクトリにあります。 アクセスするには、ホームページのURLに「/robots.txt」を追加します(例:「https://www.yourshopifystore.com/robots.txt」)。
- robots.txtファイルはShopifyによって管理されています。 これは、コンテンツを編集できないことを意味します。 ただし、robots.txtファイルで許可されていない特定のページにGoogleがアクセスすることを望まない場合は、「noindex」メタタグ(特定のインデックスを作成しないように検索エンジンに指示するコード行)を使用してページを非表示にすることができます。ページ。 「noindex」メタタグを実装するには、theme.liquidレイアウトファイルをカスタマイズする必要があるため、技術的な知識が必要です。 特定のページにインデックスを付けない方法を学ぶ→Shopify、検索エンジンからページを隠す
技術に精通しておらず、Shopify Liquidに精通していない場合は、Shopifyエキスパートに連絡してヘルプをリクエストすることをお勧めします。
また、SmartSEOのようなShopifySEOアプリを使用することもできます。SmartSEOは、ボタンを1回クリックするだけで、ページに「noindex」タグを追加できます(ただし、これについては後で詳しく説明します)。
- 無料のGoogle検索コンソールアカウントにサインアップすることで、robots.txtファイルによってブロックされたページを監視できます。
チェックアウトページがrobots.txtファイルによってブロックされていることに気付いても心配する必要はありません。SEOのランク付けは必要ありません。 また、チェックアウトページをクロールしないことで、検索エンジンボットは、Webサイトのより重要なページ(ホームページ、カテゴリページ、製品ページ、ブログ、記事ページなど)をクロールする時間を増やすことができます。
ただし、収益に直接影響するページ(つまり、カテゴリページ、製品ページなど)がrobots.txtファイルによってブロックされている場合は、心配する必要があります。 一般に、これが発生する可能性はほぼ0%です(Shopifyがrobots.txtファイルを自動的に作成および管理するため)。 それでも、そうであれば、Shopifyサポートチームにすぐに連絡してください。
Shopifyとsitemap.xml:知っておくべきことすべて
XMLサイトマップは、ShopifyストアのWebページとリソース(メディアファイル、pdfなど)に関する情報をGooglebot(およびその他の検索エンジンボット)に提供します。 基本的に、それはあなたのウェブサイト上の最も重要なページとリソースの包括的なリストです。 サイトマップには、Webページに関する重要な情報も含まれています(たとえば、最後に変更されたのはいつか、含まれている画像の数、他のページやリソースとの関係など)。
サイトマップの目的は、GoogleがWebサイトをより速くより効率的にクロールできるようにすることです。
robots.txtファイルと同様に、サイトマップを用意する必要はありません。Googleは、支援なしでWebサイトをクロールできます(特に、強力な内部リンク戦略が実施されている場合)。 ただし、サイトマップを持つことは確かにあなたに利益をもたらすことができます。 特に次の場合:
- 大規模なカタログストアがある場合。 1000以上(または100)の製品ページを相互リンクする必要があると想像してみてください…不可能ですよね?
- Shopifyストアが新しく、まだバックリンクとインターリンクがほとんどない場合。
- Shopifyストアにビデオや画像などのメディアファイルがたくさん含まれている場合。
- 大量のPDFファイル(製品マニュアルや手順など)をアップロードする場合。
- たくさんの記事を投稿する場合。
- さらに、サイトマップがあるということは、Googlebot(および他の検索エンジンクローラー)がWebサイトをより頻繁にクロールすることを意味します。
ShopifyとXMLサイトマップについて知っておくべきこと:
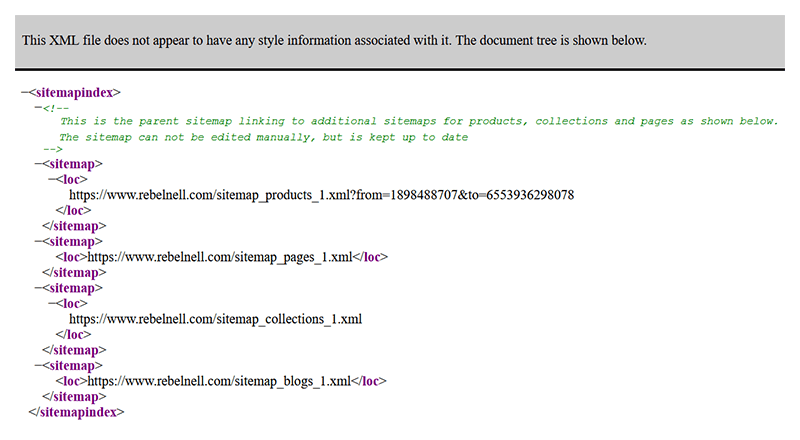
これはRebelNellのサイトマップです-私たちのお気に入りのShopifyストアのもう1つです。 これは、Shopifyストアの一般的なサイトマップの外観です。製品、コレクション、ブログ、およびページの追加のサイトマップ(または子サイトマップ)にリンクする親サイトマップが1つあります。 この分類により、GoogleはShopifyストアをより簡単にナビゲートおよびクロールできます。
追加の各サイトマップには、ページの広範なリストが含まれています。 たとえば、Rebel Nellの製品サイトマップを詳しく見ると、Rebel Nellのすべての製品ページへのリンクと、ページが最後に変更されたときの画像に関する情報、ページの頻度が含まれていることがわかります。変更など。
sitemap.xmlファイルとShopifyについて知っておくべきことは次のとおりです。
- Shopifyは、ストアのsitemap.xmlファイルを自動的に生成します。 すべての製品、製品画像、ページ、コレクション、およびブログ投稿へのリンクが含まれています。
基本的なShopifyプランを使用している場合は、ストアのプライマリドメインのみが生成されたサイトマップファイルを持ち、検索エンジンで検出できます。 Shopify、Advanced Shopify、またはShopify Plusプランを利用している場合は、国際ドメイン機能を使用して、地域固有または国固有のドメインを作成できます。 国際ドメインを使用すると、すべてのドメインのサイトマップファイルが生成されます。 プライマリドメインにリダイレクトされない限り、すべてのドメインは検索エンジンで検出できます。 (出典:Shopify、サイトマップの検索と送信)
- サイトマップは、Shopifyストアのドメインのルートディレクトリにあります。つまり、ホームページのURLに「/sitemap.xml」を追加することで見つけることができます(例:「https://www.yourshopifystore.com/sitemap」)。 xml」)。 注:サイトマップの場所はrobots.txtファイルでも確認できます。「サイトマップ」ディレクティブで指定されていることに注意してください。
- Shopifyは、ストアを更新するたびに(たとえば、新しい製品を追加したり、新しいブログ投稿を公開したりするたびに)サイトマップを自動的に更新します。
- サイトマップを手動で編集することはできません。 ストアのサイトマップから特定のページを除外したい場合は、Shopify API(コードを介して)を介してのみ行うことができます。 幸いなことに、技術に精通していない場合に役立つアプリがいくつかあります。 そのようなアプリの1つがスマートSEOです。 ボタンを1回クリックするだけで、サイトマップに表示したくないページを除外できます。 これにより、noindexタグが追加され、サイト検索ページから除外されます。
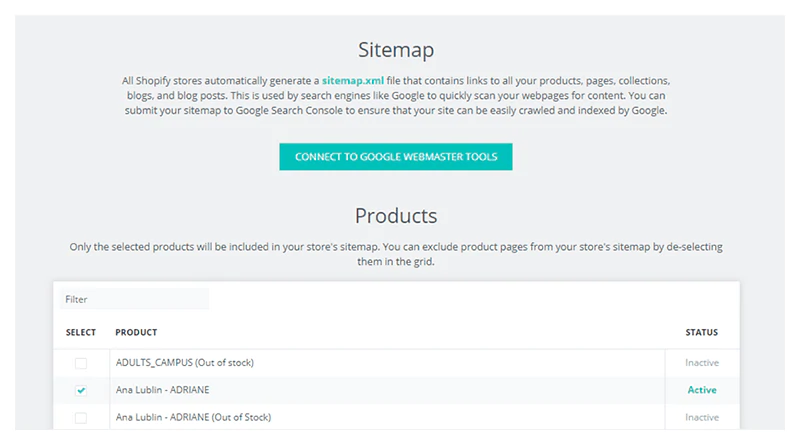
各製品の横にあるチェックボックスに注意してください。チェックボックスがオンになっている場合、製品のステータスは「アクティブ」に設定されています。 これは、製品がサイトマップに含まれていることを意味します。 サイトマップから製品を除外する場合は、チェックボックスからチェックマークを外すだけです。
スマートSEOは星の評価を誇っています。 無料プランと3つの有料プランがあります。 価格は月額9.99ドルからです(7日間の無料トライアルが利用可能です)。
sitemap.xmlファイルとは何か、そしてそれがどのように役立つかがわかったところで、このガイドの最後のセクション、つまりサイトマップをGoogle検索コンソールに送信することに移りましょう。
サイトマップをGoogle検索コンソールに送信する:それが重要な理由とその方法
sitemap.xmlファイルはいつでもGoogle検索コンソールに送信できます。 これは絶対に必要というわけではありません。送信しなくても、Googleはサイトマップを見つけることができます。 しかし、あなたがそれをすることが重要です!
なんで? サイトマップをGoogleSearch Consoleに送信すると、Googlebotがウェブページとリソースをはるかに高速にクロールしてインデックスに登録できるようになるためです。 また、サイトマップをGoogle Search Consoleに送信すると、ランキングが向上し、内部リンクの取り組みが向上し、最終的にはリーチが拡大します。 簡単に言えば、サイトマップを送信すると、より多くの露出が得られ、より多くの販売機会につながります。
サイトマップをGoogle検索コンソールに送信する方法:
- ウェブサイトがパスワードで保護されていないことを確認してください-パスワードで保護されている場合、Googleはサイトマップにアクセスできません。 Shopifyストアのパスワードを削除する方法を学ぶ
- 無料のGoogle検索コンソールアカウントを作成します。
- Google Search Consoleでドメインを確認し、Shopifyストアの所有者であることを確認します。 注:ウェブサイトがパスワードで保護されている場合、ドメインを確認することはできません。
- sitemap.xmlファイルをGoogle検索コンソールに送信します。 ここにリストされている手順に従ってください→Shopify、サイトマップの検索と送信
Smart SEOを使用すると、検索コンソールを使用する手動のプロセスを経ることなく、サイトマップをGoogleに簡単に送信できます。 確認済みのサイトプロパティを持つGoogle検索コンソールアカウントが引き続き必要であることに注意してください。
結論
今日は、検索の仕組みについてお話しました。 クロール、インデックス作成、ランク付けの違いと、技術的なSEOがこれらの各プロセスとどのように関係しているかについて説明しました。
また、次の方法で、GoogleがShopifyストアをより速くより効率的にクロールしてインデックスに登録できるようにする方法を紹介しました。
- 堅牢な内部リンク戦略の作成
- 非の打ちどころのないrobots.txtファイルを持っている
- 非の打ちどころのないsitemap.xmlファイルを用意し、それをGoogle検索コンソールに送信する
ご不明な点がございましたら、下までお問い合わせください。
次の記事では、Webサイトのアーキテクチャに焦点を当てます。 More specifically, we'll show you how to create a low-depth page hierarchy, a logical URL structure, and intuitive website navigation - these are key steps to building a technically optimized website (and, as you already know, it helps with crawling and indexing as well). だから、お楽しみに!