
Apache Apex: una introducción
Publicado: 2015-12-29Apache Hadoop se ha convertido en un marco de software de facto para computación confiable, escalable, distribuida y a gran escala. Desde sus inicios, Hadoop ha sido el marco de trabajo de primera elección para el procesamiento por lotes. Desde los grandes bancos hasta los gigantes minoristas en línea, todos usan Hadoop para la generación de informes periódicos, los cálculos y para muchos más casos de uso. Por lo general, estos casos de uso son procesos orientados a lotes y requieren algunas horas antes de que obtengamos significado de los datos. El mundo veloz de hoy requiere significado o acciones a partir de datos sin procesar casi en el momento en que se generan. Esto ha llevado a un concepto de procesamiento de flujo. Aunque Hadoop originalmente no se consideró adecuado para el procesamiento de flujo, la invención de YARN (Hadoop 2.0) lo convirtió en un buen candidato para ello. Actualmente, existen múltiples marcos de procesamiento de secuencias en el ecosistema Hadoop y Apex es uno nuevo que ingresa a este concurrido mercado.
¿Qué es Apache Apex?
Apache Apex es una plataforma nativa basada en YARN que ayuda al desarrollador de aplicaciones a escribir aplicaciones orientadas a secuencias y orientadas a lotes. Está diseñado para procesar datos en movimiento, de manera distribuida, tolerante a fallas y de alto rendimiento. La guinda de esto es la sencilla API, que permite a los usuarios escribir su código Java con un conocimiento limitado del procesamiento de secuencias.
El Apex se basa en especificaciones funcionales y operativas separadas en lugar de combinarlas. Esto hace que los desarrolladores de aplicaciones se centren en escribir funciones definidas por el usuario sin tener que pensar en cómo funcionarán en un entorno distribuido.
Apache Apex tiene una rica biblioteca de funciones de uso común. Estos se agregan como parte de la biblioteca Apache Apex-Malhar. Esta biblioteca tiene operadores para acceder a diferentes sistemas de archivos, bases de datos, colas de mensajes. La comunidad está agregando operadores día a día, lo que hace que la vida de los desarrolladores de aplicaciones sea más fácil.
¿Qué son los bloques centrales de Apache Apex?
La arquitectura de Apex es muy simple. Apex tiene Malhar, una biblioteca de operadores y un motor central para trabajar. El núcleo de Apex podría representarse de la siguiente manera, a menudo se los denomina bloques principales de Apache Apex.
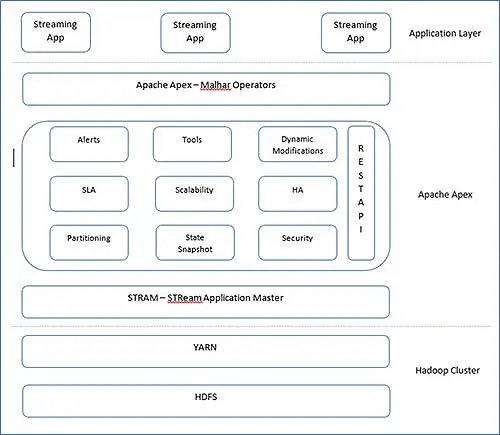
Puede separar claramente las capas y obtener una descripción general donde encaja. Veamos información sobre estos bloques.
- StrAM (maestro de aplicaciones de flujo )
StrAM es un maestro de aplicaciones de YARN. Su responsabilidad incluye el lanzamiento de aplicaciones de transmisión, la asignación de recursos y la programación de DAG lógicos. Junto con estas operaciones YARN, StrAM inicializa operadores, flujos. StrAM también recopila estadísticas de sus hijos. - Instantánea del estado
Los marcos de procesamiento de flujo no podían permitirse perder los resultados procesados. Además, deben saber cuánto han procesado para procesar correctamente los registros después de recuperarse de la falla. Por lo tanto, periódicamente, el control de puntos es importante en el procesamiento de flujo. En Apex, StrAM realiza un seguimiento de los puntos de control y, en el límite del operador, se realizan puntos de control periódicamente en HDFS. - API REST
StrAM es el punto de acceso para la API REST. Las herramientas externas pueden acceder a esta API REST y se integran con cualquier aplicación externa. - Herramientas
Apex proporciona CLI para iniciar y monitorear aplicaciones de Apex. Incluso podemos construir el nuestro con la ayuda de las API REST. Junto con la CLI, la aplicación puede configurarse con scripts de configuración estática para un inicio automático. - Fraccionamiento
- Modificaciones Dinámicas
- Análisis SLA
Apache Apex realiza análisis de SLA por sí solo periódicamente. Realiza análisis de latencia, cuello de botella y rendimiento y agrega más recursos para cumplir con el SLA configurado. - Seguridad
- Alta disponibilidad
Apache Apex utiliza la funcionalidad de reinicio de YARN y se reinicia desde el último estado de punto de control. - Malhar
Apache Apex –Malhar es una biblioteca de operadores con numerosos operadores. Estos operadores se clasifican en - Operadores de entrada/salida –
Bajo esta categoría, actualmente Malhar tiene operadores para leer/escribir desde - Sistema de archivos
- RDBMS
- Tiendas NoSQL
- Colas de mensajes
- Bases de datos en memoria
- Medios de comunicación social
- Operadores de Cómputo –
- La coincidencia de patrones
- Estadísticas y Matemáticas
- Aprendizaje automático
- analizadores
- Medios de comunicación social
- Servidores de búfer
Apex proporciona partición basada en claves y balanceo de carga dinámico. Incluso el usuario puede definir su propio esquema de partición.
Apache Apex tiene esta función única y muy útil. Admite cambio de DAG lógico, cambio de plan de ejecución física.
Apex es compatible con Kerberos. Clúster de Hadoop asegurado subyacente, puede acceder con la integración inherente de Kerberos.
Malhar tiene muchos operadores que ayudarán en la implementación de la lógica comercial real. Esta biblioteca tiene
Los servidores de búfer se encuentran en el límite de cada operador. En el caso de los datos, los servidores de búfer del operador local pueden estar detrás de cadenas de operadores. El objetivo principal de ellos es mantener temporalmente los datos en los bordes antes de reenviarlos al siguiente. Tienen un papel importante cuando el nodo se recupera de una falla. Los servidores de búfer cargan datos del último estado marcado para reproducirlos

¿Qué es el modelo de programación de aplicaciones de Apex?
Esto presenta un marco rico y la biblioteca Malhar, lo que significa que los desarrolladores de aplicaciones solo necesitan conectar operadores e iniciar la aplicación. Por lo tanto, su aplicación no es más que una secuencia de operadores.
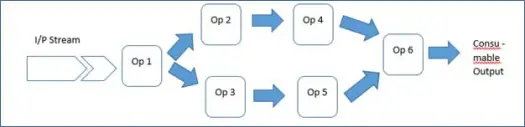
Así es como Rich Framework facilita la vida del desarrollador. Veamos cómo funciona esta aplicación de demostración.
Demostración de Apache Apex
Entonces, comencemos con ' Hello World of Big Data J', una pequeña demostración del conteo de palabras usando Apache Apex.
Configuración de Apache Apex
Para ejecutar esta demostración, necesitamos configurar Apex. Puede instalar Apache Apex en su clúster existente o hay una forma sencilla de probarlo, puede descargar la máquina virtual sandbox preinstalada desde el sitio web de DataTorrent desde aquí. Para esta demostración, utilizaremos una VM preinstalada.
Tutorial de la consola de interfaz de usuario de Apex
Apex viene con una consola de interfaz de usuario de diseño hermoso e intuitivo que puede usar para iniciar, monitorear y administrar aplicaciones. Incluye varias estadísticas sobre los diferentes componentes que se implementan.
Después de haber descargado la máquina virtual sandbox, descomprímala y cárguela en su reproductor de máquina virtual favorito (yo uso el reproductor de máquina virtual de VMWare). Todo el software y las herramientas que se requieren para ejecutar Apex ya están configurados en esta máquina virtual y todos los scripts de inicio están configurados para ejecutarse en el arranque del sistema operativo. Entonces, cuando su VM esté activa, tendrá una instancia en ejecución de Apache Apex. Ahora, para ver la consola, solo presione http://locahost:9090 en su navegador web favorito e inicie sesión en la consola. Nombre de usuario predeterminado: la contraseña para la máquina virtual de sandbox es dtadmin: dtadmin. Verá la consola como se muestra a continuación.
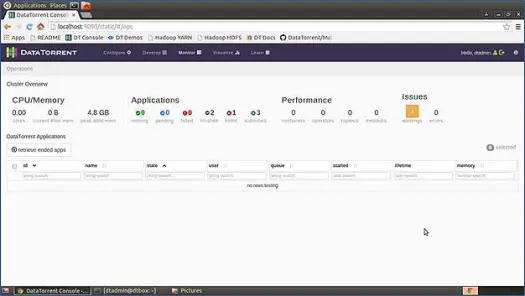
Esta página nos brinda una descripción general completa de todo el sistema, como el uso de CPU y memoria, aplicaciones, rendimiento, problemas, etc.
Para implementar una aplicación, vaya a la pestaña Desarrollar en la parte superior de la página.
Aquí puede implementar sus paquetes de aplicaciones y administrar los esquemas de tupla para los datos dentro de Apex.
Apex le proporciona una cantidad de aplicaciones listas para usar, que puede ver a continuación:
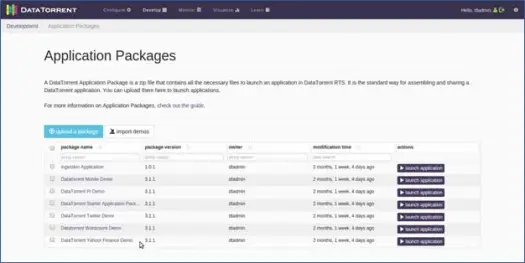
Demostración de recuento de palabras
Ahora, iniciemos la aplicación de recuento de palabras. Puede hacerlo haciendo clic en la opción de inicio de la aplicación junto a la demostración de DataTorrent Wordcount. A continuación, puede proporcionar una aplicación diferente y modificar los detalles de configuración si es necesario (no lo haremos ya que la mayoría de los valores predeterminados funcionan bien, solo modifiquemos el nombre de la aplicación a "MyWordCountDemo"). Verá un mensaje que dice que la aplicación se implementó correctamente con un enlace a la aplicación. Haga clic en ese enlace.

Esto abre una nueva página. Espere unos segundos hasta que el estado de la aplicación cambie de Aceptado a En ejecución. Ahora verá una página que está llena de varias estadísticas e información. Las siguientes dos capturas de pantalla los representan.
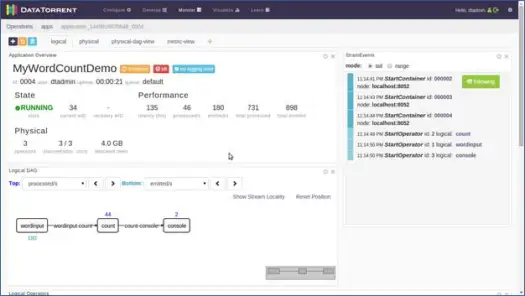
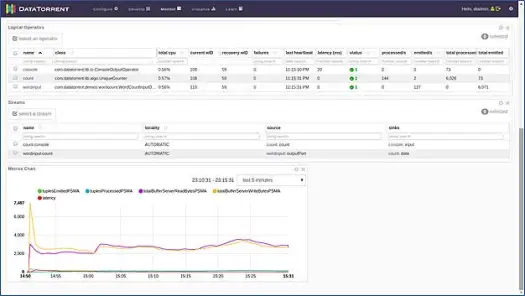
Estas páginas nos muestran información diversa como vista lógica, física y métrica de la aplicación, junto con estadísticas de varias tuplas/registros que procesa la aplicación cada segundo. Muestra la representación gráfica de las tuplas que se emiten y las latencias, etc.
Puede hacer clic en cualquiera de los operadores lógicos, inspeccionar sus registros e incluso registrar una muestra. Hagamos eso para el operador de la consola. Haga clic en el operador de la consola y obtendrá información detallada sobre el operador de la siguiente manera:
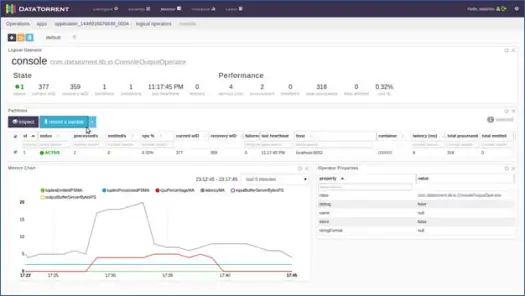
A continuación, seleccione una de las particiones y haga clic en grabar una muestra.
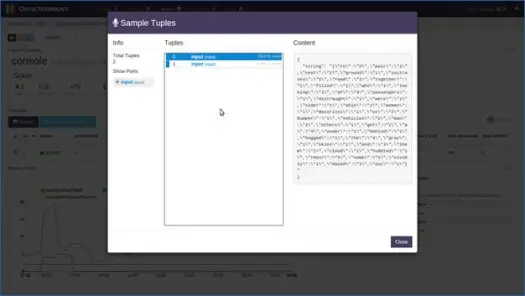
Después de unos segundos, verá que se llenan las tuplas, haga clic en la tupla para ver su contenido. Como puede ver en el contenido, la aplicación ha realizado el conteo de palabras en datos basados en ventanas y había 2 "a", 4 "el", 4 "a", etc. en la tupla de entrada 0 para esta ventana. Ahora puede detener la aplicación haciendo clic en "Apagar" o "Eliminar" en la página principal de la aplicación.
Eso es todo, hemos implementado y ejecutado con éxito la aplicación de recuento de palabras.
Conclusión
Esa fue la introducción a una nueva herramienta de transmisión: Apache Apex y la ejecución exitosa de una aplicación en Apache Apex. Apache Apex tiene muchas características destacadas que le dan una ventaja sobre otros marcos existentes que cubriré en publicaciones posteriores.