
Apache Spark: estrella brillante en el firmamento de big data.
Publicado: 2015-09-24- Recomendar millones de productos a los clientes adecuados.
- Seguimiento del historial de búsqueda y oferta de precios con descuento para viajes en avión.
- Comparar las habilidades técnicas de la persona y sugerir adecuadamente personas con las que conectarse en su campo.
- Comprender patrones en miles de millones de objetos móviles, torres de red y transacciones de llamadas y calcular optimizaciones de redes de telecomunicaciones o encontrar lagunas en la red.
- Estudiar millones de características de sensores y analizar fallas en redes de sensores.
Los datos subyacentes necesarios para obtener los resultados correctos para todas las tareas anteriores son comparativamente muy grandes. No puede ser manejado eficientemente (tanto en términos de espacio como de tiempo) por los sistemas tradicionales.
Todos estos son escenarios de big data.
Para recopilar, almacenar y realizar cálculos sobre este tipo de datos voluminosos, necesitamos un sistema informático de clúster especializado. Apache Hadoop nos ha resuelto este problema.
Ofrece un sistema de almacenamiento distribuido (HDFS) y una plataforma de computación paralela (MapReduce).
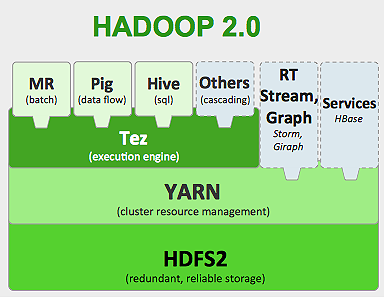
El marco Hadoop funciona de la siguiente manera:
- Divide los archivos de datos de gran tamaño en fragmentos más pequeños para que los procesen las máquinas individuales (almacenamiento de distribución).
- Divide el trabajo más largo en tareas más pequeñas para ser ejecutadas en forma paralela (Cómputo paralelo).
- Maneja las fallas automáticamente.
Limitaciones de Hadoop
Hadoop tiene herramientas especializadas en su ecosistema para realizar diferentes tareas. Por lo tanto, si desea ejecutar un ciclo de vida de extremo a extremo de una aplicación, debe utilizar varias herramientas. Por ejemplo, para las consultas de SQL , usará hive/pig , para las fuentes de transmisión , debe usar la transmisión incorporada de Hadoop o Apache Storm (que no forma parte del ecosistema de Hadoop) o para los algoritmos de aprendizaje automático , debe usar Mahout . La integración de todos estos sistemas para construir un solo caso de uso de canalización de datos es toda una tarea.
En el trabajo de MapReduce ,
- Toda la salida de tareas de mapa se vuelca en discos locales (o HDFS).
- Hadoop fusiona todos los archivos de derrame en un archivo más grande que se ordena y divide según la cantidad de reductores.
- Y reducir las tareas tiene que cargarlo de nuevo en la memoria.
Este proceso hace que el trabajo sea más lento y provoca E/S de disco y E/S de red. Esto también hace que Mapreduce no sea apto para el procesamiento iterativo en el que debe aplicar algoritmos de aprendizaje automático al mismo grupo de datos una y otra vez.
Ingrese al mundo de Apache Spark:
Apache Spark se desarrolló en UC Berkeley AMPLAB en 2009 y en 2010 se convirtió en el proyecto de código abierto más contribuido de Apache hasta la fecha.
Apache Spark es un sistema más generalizado , donde puede ejecutar trabajos por lotes y de transmisión a la vez. Reemplaza a su predecesor MapReduce en velocidad al agregar capacidades para procesar datos más rápido en la memoria. También es más eficiente en disco. Aprovecha el procesamiento de la memoria utilizando su unidad de datos básica RDD (Conjunto de datos distribuido resistente). Estos contienen la mayor cantidad posible de conjuntos de datos en la memoria para completar el ciclo de vida del trabajo, por lo tanto, ahorran en E/S del disco. Algunos datos pueden derramarse sobre el disco después de los límites superiores de la memoria.
El siguiente gráfico muestra el tiempo de ejecución en segundos de Apache Hadoop y Spark para calcular la regresión logística. Hadoop tardó 110 segundos, mientras que Spark terminó el mismo trabajo en solo 0,9 segundos.
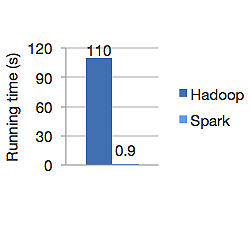
Spark no almacena todos los datos en la memoria. Pero si los datos están en la memoria, hace un mejor uso de la memoria caché LRU para procesarlos más rápido. Es 100 veces más rápido mientras procesa datos en la memoria y aún más rápido en el disco que Hadoop.
El modelo de almacenamiento de datos distribuidos de Spark, conjuntos de datos distribuidos resilientes (RDD), garantiza la tolerancia a fallas que, a su vez, minimiza la E/S de la red. papel chispa dice:

"Los RDD logran la tolerancia a fallas a través de una noción de linaje: si se pierde una partición de un RDD, el RDD tiene suficiente información sobre cómo se derivó de otros RDD para poder reconstruir solo esa partición".
Por lo tanto, no necesita replicar datos para lograr la tolerancia a fallas.
En Spark MapReduce, la salida de los mapeadores se mantiene en la memoria caché del búfer del sistema operativo y los reductores la llevan a su lado y la escriben directamente en su memoria, a diferencia de Hadoop, donde la salida se derrama en el disco y la vuelve a leer.
La memoria caché de Spark lo hace apto para algoritmos de aprendizaje automático en los que necesita usar los mismos datos una y otra vez. Spark puede ejecutar trabajos complejos, canalizaciones de datos de varios pasos utilizando gráficos acíclicos directos (DAG).
Spark está escrito en Scala y se ejecuta en JVM (Java Virtual Machine). Spark ofrece API de desarrollo para lenguajes Java, Scala, Python y R. Spark se ejecuta en Hadoop YARN, Apache Mesos y tiene su propio administrador de clústeres independiente.
En 2014 obtuvo el 1er lugar en el récord mundial de clasificación de datos de 100 TB (1 billón de registros) de referencia en solo 23 minutos, mientras que el récord anterior de Hadoop por Yahoo fue de aproximadamente 72 minutos. Esto demuestra que Spark clasificó los datos 3 veces más rápido y con 10 veces menos máquinas. Toda la clasificación ocurrió en el disco (HDFS), sin usar realmente la capacidad de caché en memoria de Spark.
Ecosistema de chispa
Spark está diseñado para hacer análisis avanzados de una sola vez, para lograrlo ofrece los siguientes componentes:
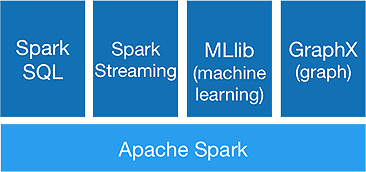
1. Núcleo de chispa:
Spark core API es la base del marco Apache Spark, que maneja la programación de trabajos, la distribución de tareas, la gestión de memoria, las operaciones de E/S y la recuperación de fallas. La unidad de datos lógicos principal en Spark se llama RDD (Resilient Distributed Dataset), que almacena datos de forma distribuida para ser procesados en paralelo más adelante. Calcula perezosamente las operaciones. Por lo tanto, la memoria no necesita estar ocupada todo el tiempo y otros trabajos pueden utilizarla.
2. Chispa SQL:
Ofrece capacidades de consulta interactiva con baja latencia. La nueva API DataFrame puede contener datos estructurados y semiestructurados y permitir que todas las operaciones y funciones de SQL realicen cálculos.
3. Transmisión de chispas:
Proporciona API de transmisión en tiempo real , que recopila y procesa datos en micro lotes.
Utiliza Dstreams, que no es más que una secuencia continua de RDD , para calcular la lógica comercial en los datos entrantes y generar resultados de inmediato.
4.MLlib :
Es la biblioteca de aprendizaje automático de Spark (casi 9 veces más rápida que Mahout) que proporciona aprendizaje automático y algoritmos estadísticos como clasificación, regresión, filtrado colaborativo, etc.
5. GráficoX :
GraphX API proporciona capacidades para manejar gráficos y realizar cálculos paralelos de gráficos. Incluye algoritmos gráficos como PageRank y varias funciones para analizar gráficos.
¿Spark marcará el final de la Era Hadoop?
Spark aún es un sistema joven, no tan maduro como Hadoop. No existe una herramienta para NOSQL como HBase. Teniendo en cuenta los altos requisitos de memoria para un procesamiento de datos más rápido, realmente no se puede decir que se ejecute en hardware básico. Spark no tiene su propio sistema de almacenamiento. Se basa en HDFS para eso.
Por lo tanto, Hadoop MapReduce sigue siendo bueno para ciertos trabajos por lotes, que no incluyen mucha canalización de datos.
“La nueva tecnología nunca reemplaza completamente a la antigua; ambos preferirían coexistir”.
Conclusión
En este blog analizamos por qué necesita una herramienta como Spark, qué hace que sea un sistema informático de clúster más rápido y sus componentes principales. En la siguiente parte, profundizaremos en los RDD, las transformaciones y las acciones de la API principal de Spark.