
Desayuno con mil millones de correos electrónicos
Publicado: 2020-02-05Un Black Friday tranquilo es todo lo que pedimos
Cuando desayuné alrededor de las 8 a. m., hora estándar del Pacífico (PST) todos los días durante el fin de semana del Black Friday, Twilio SendGrid ya había procesado más de 1 billón de correos electrónicos calculados en la hora estándar del este de EE. UU. (EST).
En cuanto a las estadísticas, procesamos más de 16,5 mil millones de correos electrónicos desde el Día de Acción de Gracias hasta el lunes cibernético, y más de 22,3 mil millones para la semana que comenzó el martes antes del Día de Acción de Gracias. Estos son realmente buenos números para el negocio. Desde la perspectiva de una organización de ingeniería, hacerlo sin disparar alertas ni degradar la experiencia del cliente fue increíblemente satisfactorio.
Recomiendo leer este artículo de blog, Escalando nuestra infraestructura para más de 4 mil millones de correos electrónicos en un solo día , escrito por mi colega Sara Saedinia, que habla sobre la importancia de operar sin problemas a esta escala para nuestro negocio y para los negocios que confían en nosotros. Aquí, me voy a centrar en nuestros preparativos que hicieron que el fin de semana más crítico del año para nuestros clientes de correo electrónico fuera el más tranquilo hasta el momento.
¿Cómo hicimos de este un fin de semana de Black Friday perfecto? Manejar nuestros días de envío más grandes requiere una planificación diligente, numerosas pruebas de cambio de región, decenas de personas analizando datos y ajustando los circuitos de retroalimentación a medida que validamos las mejoras en nuestros sistemas en función de las observaciones de telemetría. Todavía tenemos más automatización y mejoras que realizaremos para asegurarnos de seguir deleitando a nuestros clientes y garantizar que enviamos las comunicaciones correctas a los destinatarios correctos de manera expedita.
Entendiendo nuestro negocio
El modelo comercial de SendGrid requiere que estemos siempre activos: no tenemos ventanas de mantenimiento para aceptar y entregar correo. Nuestros clientes requieren un servicio confiable que acepte y entregue correo sin interrupción. Esto significa que todos nuestros cambios de infraestructura, tanto de hardware como de software, deben realizarse mientras continuamos procesando y entregando correos electrónicos sin demoras notables.
La cantidad de correos electrónicos que procesamos ha crecido enormemente en los últimos años, como lo muestra el siguiente gráfico.
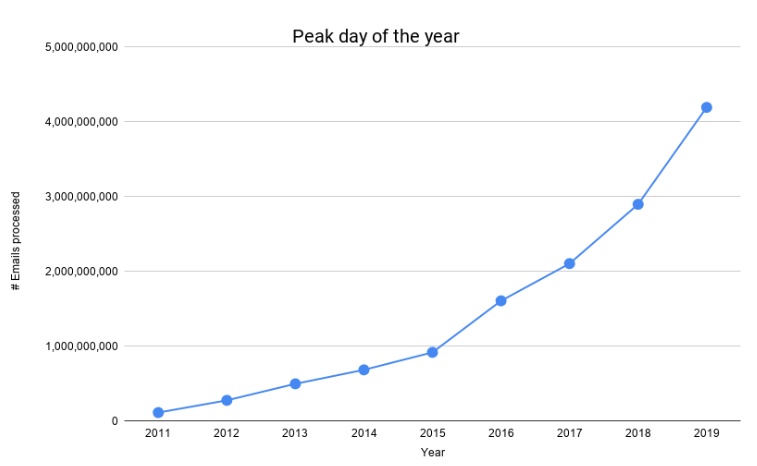
Tuvimos nuestro primer día 1B a mediados de 2016, y tuvimos nuestro primer día 4B este Black Friday. Eso es un crecimiento del 400% en menos de 4 años. Para dar cuenta de nuestra escala cada vez mayor, para mantener nuestros costos manejables y brindar una mayor confiabilidad a nuestros clientes, hemos tenido que rediseñar y evolucionar nuestra canalización de procesamiento de correo.
Se acerca el viernes negro
La gente me pregunta: "¿Por qué el Black Friday y el Cyber Monday son tan importantes para ti?" Este lunes cibernético, procesamos un 45 % más de correos electrónicos que el pico del año anterior. El Black Friday es uno de los eventos minoristas y de gasto más importantes de los Estados Unidos. Tradicionalmente, es el día en que los minoristas estarán en números negros (positivos netos) durante el año. El marketing por correo electrónico y el uso de correos electrónicos transaccionales se han vuelto críticos para todas las empresas.
Desde los minoristas hasta las empresas que brindan automatización de marketing, tener problemas para entregar correos electrónicos de manera confiable el fin de semana del Black Friday puede resultar en una pérdida significativa de ingresos. Como resultado, este fin de semana es a menudo un fin de semana que define el negocio para nosotros. Hacemos todo lo posible para que sea lo más fácil posible para nuestros ingenieros, agentes de soporte, gerentes de éxito del cliente, ejecutivos y, lo que es más importante, para nuestros clientes.
Preparándonos para el Viernes Negro
Entonces, ¿cómo nos preparamos para el Black Friday? ¡Compramos camisetas! (Y hacer un montón de trabajo). Siga leyendo para saber cómo nos preparamos.
Miembros de la oficina de Twilio SendGrid Irvine

Algunos de los miembros de la oficina de Twilio SendGrid Denver.

Estadísticas
Comencemos con algunas estadísticas:
- Se procesaron más de 4.100 millones de correos electrónicos en Black Friday y más de 4.200 millones de correos electrónicos en Cyber Monday
- Se procesaron más de 16 500 millones de correos electrónicos desde el Día de Acción de Gracias hasta el Cyber Monday
- Procesó más de 315 millones de correos electrónicos durante la hora pico
- Black Friday y Cyber Monday, cada uno tuvo 8 horas sucesivas procesando 220 millones de correos electrónicos o más
- Todo esto con una mediana de tiempo de entrega de correos electrónicos de 1,9 segundos.
- De media, emitimos aproximadamente 5,5 eventos por mensaje. En base a eso, nuestros sistemas emitieron y procesaron más de 91 000 millones de eventos desde el Día de Acción de Gracias hasta el lunes cibernético, y más de 23 000 millones solo en el lunes cibernético.
Los desafios
Báscula nunca antes vista : la báscula a la que nos dirigimos para probar debe coincidir con nuestra carga máxima prevista. Cuando hicimos nuestra primera prueba para la preparación del año pasado a principios de abril, nuestro volumen promedio entre semana fue menos de la mitad de nuestra predicción máxima. Nuestros picos por hora no eran ni la mitad de lo que estaríamos probando.
Administrar nuestros entornos : el correo electrónico es un flujo de trabajo con estado: es necesario realizar un seguimiento del estado de un mensaje. Entonces, a medida que el mensaje se mueve a través de la canalización, rastreamos si rebota o se aplaza, y evitamos la duplicación. Como tal, nuestra canalización de correo es una nube híbrida y una arquitectura local, y el escalado automático no es una solución mágica. Nuestro desafío es maximizar la eficiencia de nuestros servicios de centro de datos mientras preparamos la capacidad para manejar picos masivos de volumen sin afectar el costo para los clientes.
El escalado no es lineal : No todos los sistemas escalan linealmente. Dado que nuestra escala predicha es mucho más alta que cuando empezamos a probar, no podemos simplemente calcular nuestras necesidades de hardware mediante un modelo matemático simple. También es importante recordar que escalar ciegamente los servicios sobrecargaría las dependencias, y las dependencias como la base de datos no se escalan de la misma manera que nuestro agente de transferencia de correo (MTA).
Equilibrio de nuestras inversiones : a medida que continuamos innovando, asegurándonos de satisfacer las necesidades de los clientes relacionadas con la entrega de correo electrónico, entendemos que nuestras funciones no brindan ningún valor a nuestros clientes si no son accesibles y funcionan según sea necesario. Tenemos que encontrar un equilibrio e invertir adecuadamente en probar, aprender, actualizar y mejorar nuestros sistemas para que sean confiables y resistentes a nuestra escala. Hacerlo de manera eficiente nos permite seguir invirtiendo en innovación.

¿Cómo lo hicimos?
Lo hicimos juntos, como un solo equipo. Del brazo, como decimos. Nuestros preparativos este año, de abril a noviembre, incluyeron la participación de más de 100 miembros de muchos equipos. El modelado de predicciones máximas, la definición de criterios de observabilidad, el aprendizaje de nuestras observaciones, la ingeniería de los cambios necesarios, la planificación y la gestión requieren varias habilidades de varias personas.
Confiamos el uno en el otro mientras nos mantenemos honestos, nos mantenemos enfocados y cumplimos nuestros objetivos.
Un proceso eficaz y en constante mejora fue nuestro amigo.
Planificación
Tenemos tres centros de datos para procesar los correos electrónicos de los clientes. Para planificar una escala no alcanzada, validamos que podemos manejar nuestro tráfico máximo proyectado con solo dos centros de datos disponibles. Para cumplir con nuestro SLA de alta disponibilidad, nuestra infraestructura tiene una conmutación por error de región integrada. Esto significa que tenemos la capacidad de conmutación por error del tráfico entre regiones.
Aprovechamos esta capacidad con una cadencia frecuente a lo largo del año como un procedimiento operativo estándar y la aceleramos como parte de nuestros esfuerzos para demostrar que podemos atender los volúmenes máximos del Black Friday/Cyber Monday mientras mantenemos la calidad del servicio. Si la telemetría del sistema se acerca al umbral de nuestro objetivo de nivel de servicio (SLO), podemos aprovechar rápidamente varias regiones para reanudar el estado nominal. Luego aprovechamos la telemetría recopilada para determinar dónde debemos realizar cambios.
En un esfuerzo paralelo, comenzamos a revisar y solidificar nuestros objetivos de nivel de servicio (SLO) que nos brindan un objetivo numérico preciso para la disponibilidad del sistema y nuestros indicadores de nivel de servicio (SLI), que nos brindan la frecuencia de sondeos exitosos en nuestros sistemas.
Observaciones, aprendizajes y comunicación.
Cada prueba proporcionó una gran cantidad de información. Uno de los desafíos que enfrentamos fue documentar y comunicar de manera efectiva las observaciones entre los equipos de prueba rotativos y luego analizar los datos en múltiples sistemas. Aunque tenemos tableros de equipo estándar, cada miembro podría observar algo específico.
Empezamos a hacer una retrospectiva con los equipos de prueba para analizar toda la información técnica volcada para múltiples servicios administrados por múltiples equipos. Estos retros fueron largos y, durante la mayor parte de su duración, solo fueron útiles para uno o dos equipos por prueba. Eventualmente pasamos a usar un hilo de Slack para notas retro, ahorrando decenas de horas humanas de tiempo de reunión por prueba.
Nuestro equipo de gestión de pruebas involucró a dos gerentes de ingeniería, un arquitecto y un ingeniero senior. Los gerentes fueron fundamentales en la planificación y la gestión de dependencias, mientras que la gente más técnica ayudó a procesar y analizar la información a nivel de sistema de extremo a extremo.
Con base en el análisis de la información disponible, validamos iterativamente que nuestros SLI se ajustaban estrictamente a nuestros SLO. Ajustamos nuestras alertas e hicimos que ciertas alertas críticas fueran más sensibles para identificar cualquier degradación potencial del sistema con mucha anticipación.
Priorización e implementación
Emitimos los cambios propuestos y los equipos priorizaron estos boletos. El primer desafío aquí fue administrar estos boletos en varios tableros de equipo. Otro desafío fue priorizar despiadadamente el trabajo del Black Friday frente a otras prioridades.
Necesitábamos brindarles a nuestros ingenieros la libertad creativa para encontrar soluciones a problemas difíciles. Al mismo tiempo, teníamos que asegurarnos de que estas soluciones se alinearan con nuestros planes a largo plazo. También fue muy importante que siempre fuéramos conscientes de cualquier conflicto de intereses, lo que significaba evitar cualquier solución a corto plazo que pudiera volver a afectarnos.
Validar los cambios que se implementaron se convertiría en nuestro objetivo para las próximas pruebas.
Mantener y aumentar el ritmo a medida que nos acercábamos al Black Friday fue un gran desafío en la planificación y ejecución.
la aceleracion
Cuando entramos en septiembre, comenzamos a ejecutar varias pruebas de estrés cada semana. Esto requería que identificáramos, solucionáramos y validáramos los problemas más rápido. También nos proporcionó un ciclo de aprendizaje y adaptación mucho más rápido.
Además de la prueba de funcionamiento completo de la canalización de correo como se describió anteriormente, también comenzamos a realizar pruebas de estrés de nuestros servicios de soporte durante el mismo tiempo. Durante el mismo período, comenzamos a realizar pruebas de carga con uno de nuestros clientes más grandes para asegurarnos de que nuestros geopods entrantes manejarían sus envíos de ráfagas anticipados durante la temporada navideña sin preocupaciones.
Debido a las largas horas y al desafío de administrar el trabajo, nuestros equipos se estaban agotando. Enumeramos las alertas más críticas requeridas para detener nuestra prueba si es necesario y las hicimos más sensibles. Esto nos permitió comenzar a hacer nuestras pruebas sin necesidad de estar presentes para monitorear nuestros sistemas temprano en la mañana.
Velocidad con precaución
A medida que nos acercábamos a fines de septiembre, existía la preocupación de que tal vez no nos moviéramos lo suficientemente rápido en la dirección correcta. Creamos un equipo tigre, un equipo de especialistas que podía trabajar en cualquiera de los tickets en varios equipos y que trabajaba con un proceso mucho más eficiente a nivel diario.
Hicimos mejoras significativas en nuestra infraestructura operativa, así como en nuestro software de procesamiento de correo en preparación para el Black Friday. Estos cambios estaban siendo priorizados expresamente, y los equipos tenían que trabajar en una gran coordinación entre sí. Fue una gran experiencia para la gente que puso a SendGrid en primer lugar. Estábamos haciendo cambios en las aplicaciones, la infraestructura y aumentando nuestra capacidad de hardware mientras ejecutamos el motor central de una unidad comercial de una empresa pública, todo a un ritmo de inicio. Lo mejor de todo es que lo hicimos todo sin degradar la experiencia de servicio para nuestros clientes.
Planes futuros
Pasamos muchas horas humanas preparándonos para el Black Friday 2019. Nuestros aprendizajes de este año nos ayudarán a automatizar gran parte de nuestra preparación para el Black Friday y el Cyber Monday en 2020. Esperamos otro año exitoso coronado con un récord sin estrés. -volúmenes de ruptura de envío de vacaciones para nuestros clientes y nuestros empleados.