
Eficacia del rastreo: cómo subir de nivel la optimización del rastreo
Publicado: 2022-10-27No se garantiza que Googlebot rastree todas las URL a las que pueda acceder en su sitio. Por el contrario, a la gran mayoría de los sitios les falta una parte importante de las páginas.
La realidad es que Google no tiene los recursos para rastrear cada página que encuentra. Todas las URL que Googlebot ha descubierto, pero que aún no ha rastreado, junto con las URL que pretende volver a rastrear, se priorizan en una cola de rastreo.
Esto significa que Googlebot rastrea solo aquellos a los que se les asigna una prioridad lo suficientemente alta. Y debido a que la cola de rastreo es dinámica, cambia continuamente a medida que Google procesa nuevas URL. Y no todas las URL se unen al final de la cola.
Entonces, ¿cómo se asegura de que las URL de su sitio sean VIP y salte la línea?
El rastreo es de vital importancia para el SEO

Para que el contenido gane visibilidad, Googlebot primero debe rastrearlo.
Pero los beneficios tienen más matices que eso porque cuanto más rápido se rastrea una página cuando es:
- Creado , antes podrá aparecer contenido nuevo en Google. Esto es especialmente importante para las estrategias de contenido de tiempo limitado o las primeras en el mercado.
- Actualizado , cuanto antes el contenido actualizado pueda comenzar a afectar las clasificaciones. Esto es especialmente importante tanto para las estrategias de republicación de contenido como para las tácticas técnicas de SEO.
Como tal, el rastreo es esencial para todo su tráfico orgánico. Sin embargo, con demasiada frecuencia se dice que la optimización del rastreo solo es beneficiosa para sitios web grandes.
Pero no se trata del tamaño de su sitio web, la frecuencia con la que se actualiza el contenido o si tiene exclusiones "Descubierto - actualmente no indexado" en Google Search Console.
La optimización del rastreo es beneficiosa para todos los sitios web. La idea errónea de su valor parece surgir de mediciones sin sentido, especialmente del presupuesto de rastreo.
El presupuesto de rastreo no importa

Con demasiada frecuencia, el rastreo se evalúa en función del presupuesto de rastreo. Esta es la cantidad de URL que Googlebot rastreará en un período de tiempo determinado en un sitio web en particular.
Google dice que está determinada por dos factores:
- Límite de tasa de rastreo (o lo que Googlebot puede rastrear): la velocidad a la que Googlebot puede obtener los recursos del sitio web sin afectar el rendimiento del sitio. Esencialmente, un servidor receptivo conduce a una tasa de rastreo más alta.
- Demanda de rastreo (o lo que Googlebot quiere rastrear): la cantidad de URL que Googlebot visita durante un solo rastreo en función de la demanda de (re) indexación, afectada por la popularidad y la obsolescencia del contenido del sitio.
Una vez que Googlebot "gasta" su presupuesto de rastreo, deja de rastrear un sitio.
Google no proporciona una cifra para el presupuesto de rastreo. Lo más parecido es mostrar el total de solicitudes de rastreo en el informe de estadísticas de rastreo de Google Search Console.
Muchos SEO, incluyéndome a mí en el pasado, se han esforzado mucho para tratar de inferir el presupuesto de rastreo.
Los pasos presentados a menudo son algo así como:
- Determine cuántas páginas rastreables tiene en su sitio, a menudo recomendando mirar la cantidad de URL en su mapa del sitio XML o ejecutar un rastreador ilimitado.
- Calcule el promedio de rastreos por día exportando el informe de estadísticas de rastreo de Google Search Console o en función de las solicitudes de Googlebot en los archivos de registro.
- Divida el número de páginas por el promedio de rastreos por día. A menudo se dice que si el resultado es superior a 10, concéntrese en la optimización del presupuesto de rastreo.
Sin embargo, este proceso es problemático.
No solo porque asume que cada URL se rastrea una vez, cuando en realidad algunas se rastrean varias veces, otras no.
No solo porque asume que un rastreo equivale a una página. Cuando en realidad una página puede requerir muchos rastreos de URL para obtener los recursos (JS, CSS, etc.) necesarios para cargarla.
Pero lo más importante, porque cuando se reduce a una métrica calculada, como el promedio de rastreos por día, el presupuesto de rastreo no es más que una métrica vanidosa.
Cualquier táctica dirigida a la "optimización del presupuesto de rastreo" (es decir, con el objetivo de aumentar continuamente la cantidad total de rastreo) es una tontería.
¿Por qué debería preocuparse por aumentar el número total de rastreos si se usa en URL sin valor o páginas que no han cambiado desde el último rastreo? Dichos rastreos no ayudarán al rendimiento de SEO.
Además, cualquiera que haya mirado alguna vez las estadísticas de rastreo sabe que fluctúan, a menudo de manera bastante salvaje, de un día a otro dependiendo de una serie de factores. Estas fluctuaciones pueden o no correlacionarse con la (re)indexación rápida de páginas relevantes para SEO.
Un aumento o disminución en el número de URL rastreadas no es intrínsecamente bueno ni malo.
La eficacia del rastreo es un KPI de SEO

Para las páginas que desea indexar, el enfoque no debe centrarse en si se rastreó, sino en qué tan rápido se rastreó después de publicarse o cambiarse significativamente.
Básicamente, el objetivo es minimizar el tiempo entre la creación o actualización de una página relevante para SEO y el siguiente rastreo de Googlebot. Llamo a este retraso de tiempo la eficacia de rastreo.
La forma ideal de medir la eficacia del rastreo es calcular la diferencia entre la fecha y hora de creación o actualización de la base de datos y el próximo rastreo de Googlebot de la URL de los archivos de registro del servidor.
Si es un desafío obtener acceso a estos puntos de datos, también puede usar como proxy la fecha de última modificación del mapa del sitio XML y las URL de consulta en la API de inspección de URL de Google Search Console para su último estado de rastreo (hasta un límite de 2000 consultas por día).
Además, al utilizar la API de inspección de URL, también puede realizar un seguimiento cuando cambia el estado de indexación para calcular la eficacia de la indexación para las URL recién creadas, que es la diferencia entre la publicación y la indexación exitosa.
Porque rastrear sin que tenga un flujo de impacto en el estado de indexación o procesar una actualización del contenido de la página es solo un desperdicio.
La eficacia del rastreo es una métrica procesable porque a medida que disminuye, más contenido crítico para SEO puede mostrarse a su audiencia en Google.
También puede usarlo para diagnosticar problemas de SEO. Profundice en los patrones de URL para comprender qué tan rápido se rastrea el contenido de varias secciones de su sitio y si esto es lo que está frenando el rendimiento orgánico.
Si ve que Googlebot tarda horas, días o semanas en rastrear y, por lo tanto, indexar su contenido recién creado o actualizado recientemente, ¿qué puede hacer al respecto?
Obtenga el boletín informativo diario en el que confían los especialistas en marketing.
Ver términos.
7 pasos para optimizar el rastreo
La optimización del rastreo consiste en guiar a Googlebot para que rastree URL importantes. rápido cuando son (re)publicados. Siga los siete pasos a continuación.
1. Garantice una respuesta del servidor rápida y saludable
Un servidor de alto rendimiento es fundamental. Googlebot se ralentizará o dejará de rastrear cuando:
- Rastrear su sitio afecta el rendimiento. Por ejemplo, cuanto más rastrean, más lento es el tiempo de respuesta del servidor.
- El servidor responde con un número notable de errores o tiempos de espera de conexión.
Por otro lado, mejorar la velocidad de carga de la página que permite la publicación de más páginas puede hacer que Googlebot rastree más URL en la misma cantidad de tiempo. Este es un beneficio adicional además de que la velocidad de la página es un factor de clasificación y experiencia del usuario.
Si aún no lo ha hecho, considere la compatibilidad con HTTP/2, ya que permite solicitar más URL con una carga similar en los servidores.
Sin embargo, la correlación entre el rendimiento y el volumen de rastreo es solo hasta cierto punto . Una vez que cruce ese umbral, que varía de un sitio a otro, es poco probable que cualquier ganancia adicional en el rendimiento del servidor se correlacione con un aumento en el rastreo.
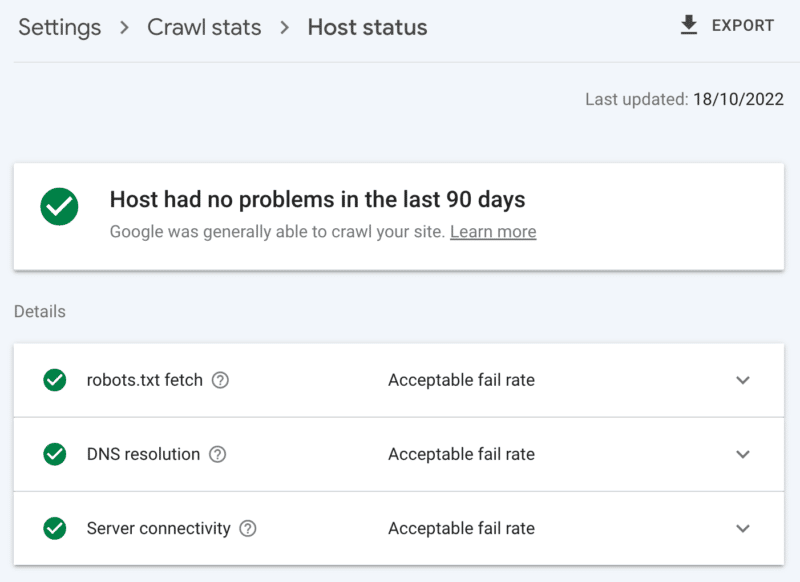
Cómo verificar la salud del servidor
El informe de estadísticas de rastreo de Google Search Console:
- Estado del host: muestra marcas verdes.
- Errores 5xx: Constituye menos del 1%.
- Gráfico de tiempo de respuesta del servidor: Tendencia por debajo de 300 milisegundos.
2. Limpie el contenido de bajo valor
Si una cantidad significativa del contenido del sitio está desactualizado, duplicado o es de baja calidad, genera competencia por la actividad de rastreo, lo que podría retrasar la indexación de contenido nuevo o la reindexación de contenido actualizado.

Agregue que la limpieza regular del contenido de bajo valor también reduce la hinchazón del índice y la canibalización de palabras clave, y es beneficioso para la experiencia del usuario, esto es una obviedad de SEO.
Combine contenido con una redirección 301, cuando tenga otra página que pueda verse como un claro reemplazo; comprender esto le costará el doble de rastreo para el procesamiento, pero es un sacrificio que vale la pena por la equidad del enlace.
Si no hay contenido equivalente, usar un 301 solo dará como resultado un 404 suave. Elimine dicho contenido usando un código de estado 410 (mejor) o 404 (primero en segundo lugar) para dar una señal fuerte de no rastrear la URL nuevamente.
Cómo comprobar el contenido de bajo valor
El número de URL en las páginas de Google Search Console reportan exclusiones 'rastreadas – actualmente no indexadas'. Si es alto, revise los ejemplos proporcionados para patrones de carpetas u otros indicadores de problemas.
3. Revisar los controles de indexación
Rel=enlaces canónicos son un fuerte consejo para evitar problemas de indexación, pero a menudo se confía demasiado en ellos y terminan causando problemas de rastreo, ya que cada URL canonicalizada cuesta al menos dos rastreos, uno para sí mismo y otro para su socio.
Del mismo modo, las directivas de robots noindex son útiles para reducir la hinchazón del índice, pero un gran número puede afectar negativamente el rastreo, así que utilícelas solo cuando sea necesario.
En ambos casos, pregúntese:
- ¿Son estas directivas de indexación la forma óptima de manejar el desafío de SEO?
- ¿Se pueden consolidar, eliminar o bloquear algunas rutas URL en robots.txt?
Si lo está utilizando, reconsidere seriamente AMP como una solución técnica a largo plazo.
Con la actualización de la experiencia de la página enfocándose en los aspectos vitales de la web principal y la inclusión de páginas que no son AMP en todas las experiencias de Google, siempre que cumpla con los requisitos de velocidad del sitio, analice detenidamente si AMP vale la pena rastrear dos veces.
Cómo comprobar la dependencia excesiva de los controles de indexación
La cantidad de URL en el informe de cobertura de Google Search Console clasificadas en las exclusiones sin una razón clara:
- Página alternativa con la etiqueta canónica adecuada.
- Excluido por la etiqueta noindex.
- Duplicado, Google eligió un canon diferente al del usuario.
- URL enviada duplicada no seleccionada como canónica.
4. Dile a las arañas de los motores de búsqueda qué rastrear y cuándo
Una herramienta esencial para ayudar a Googlebot a priorizar URL de sitios importantes y comunicar cuándo se actualizan dichas páginas es un mapa del sitio XML.
Para una guía efectiva del rastreador, asegúrese de:
- Solo incluye URL que sean tanto indexables como valiosas para SEO; por lo general, 200 códigos de estado, páginas canónicas de contenido original con una etiqueta de robots "indexar, seguir" para las que te preocupas por su visibilidad en los SERP.
- Incluya etiquetas de marca de tiempo <lastmod> precisas en las URL individuales y en el mapa del sitio lo más cerca posible del tiempo real.
Google no comprueba un mapa del sitio cada vez que se rastrea un sitio. Entonces, cada vez que se actualice, es mejor hacer ping a la atención de Google. Para hacerlo, envíe una solicitud GET en su navegador o la línea de comando a:
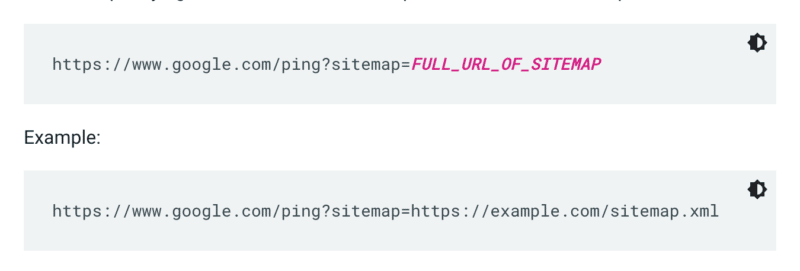
Además, especifique las rutas al mapa del sitio en el archivo robots.txt y envíelo a Google Search Console usando el informe de mapas del sitio.
Como regla general, Google rastreará las URL en los sitemaps con más frecuencia que otros. Pero incluso si un pequeño porcentaje de URL dentro de su mapa del sitio es de baja calidad, puede disuadir a Googlebot de usarlo para rastrear sugerencias.
Los mapas de sitio XML y los enlaces agregan URL a la cola de rastreo regular. También hay una cola de rastreo de prioridad, para la cual hay dos métodos de entrada.
En primer lugar, para aquellos con ofertas de trabajo o videos en vivo, puede enviar URL a la API de indexación de Google.
O si quiere llamar la atención de Microsoft Bing o Yandex, puede usar la API de IndexNow para cualquier URL. Sin embargo, en mis propias pruebas, tuvo un impacto limitado en el rastreo de URL. Entonces, si usa IndexNow, asegúrese de monitorear la eficacia del rastreo para Bingbot.
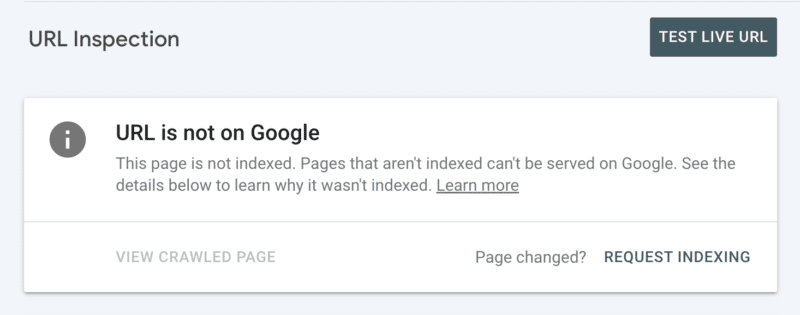
En segundo lugar, puede solicitar manualmente la indexación después de inspeccionar la URL en Search Console. Aunque tenga en cuenta que hay una cuota diaria de 10 URL y el rastreo aún puede llevar bastantes horas. Es mejor ver esto como un parche temporal mientras investiga para descubrir la raíz de su problema de rastreo.
Cómo verificar la guía de rastreo esencial de Googlebot
En Google Search Console, su mapa del sitio XML muestra el estado "Éxito" y se leyó recientemente.
5. Dile a las arañas de los motores de búsqueda lo que no deben rastrear
Algunas páginas pueden ser importantes para los usuarios o para la funcionalidad del sitio, pero no desea que aparezcan en los resultados de búsqueda. Evite que dichas rutas de URL distraigan a los rastreadores con un rechazo de robots.txt. Esto podría incluir:
- API y CDN . Por ejemplo, si es cliente de Cloudflare, asegúrese de no permitir la carpeta /cdn-cgi/ que se agrega a su sitio.
- Imágenes, scripts o archivos de estilo sin importancia , si las páginas cargadas sin estos recursos no se ven afectadas significativamente por la pérdida.
- Página funcional , como un carrito de compras.
- Espacios infinitos , como los que crean las páginas del calendario.
- Páginas de parámetros . Especialmente aquellos de navegación por facetas que filtran (p. ej., ?price-range=20-50), reordenan (p. ej., ?sort=) o buscan (p. ej., ?q=), ya que los rastreadores cuentan cada combinación como una página separada.
Tenga cuidado de no bloquear completamente el parámetro de paginación. La paginación rastreable hasta cierto punto suele ser esencial para que Googlebot descubra contenido y procese la equidad de los enlaces internos. (Consulte este seminario web de Semrush sobre paginación para obtener más detalles sobre el por qué).
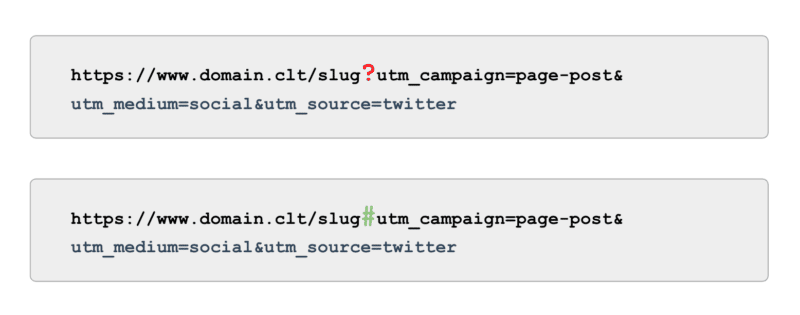
Y cuando se trata de seguimiento, en lugar de usar etiquetas UTM basadas en parámetros (también conocido como '?'), use anclas (también conocido como '#'). Ofrece los mismos beneficios de informes en Google Analytics sin ser rastreable.
Cómo verificar si Googlebot no rastrea la guía
Revise la muestra de URL 'Indizadas, no enviadas en el mapa del sitio' en Google Search Console. Ignorando las primeras páginas de paginación, ¿qué otros caminos encuentras? ¿Deberían incluirse en un mapa del sitio XML, bloquearse para que no se rastreen o dejar que lo hagan?
Además, revise la lista de "Descubierto - actualmente no indexado": bloquee en robots.txt cualquier ruta de URL que ofrezca un valor bajo o nulo para Google.
Para llevar esto al siguiente nivel, revise todos los rastreos de teléfonos inteligentes de Googlebot en los archivos de registro del servidor en busca de rutas sin valor.
6. Selecciona enlaces relevantes
Los vínculos de retroceso a una página son valiosos para muchos aspectos del SEO, y el rastreo no es una excepción. Pero los enlaces externos pueden ser difíciles de obtener para ciertos tipos de páginas. Por ejemplo, páginas profundas como productos, categorías en los niveles inferiores de la arquitectura del sitio o incluso artículos.
Por otro lado, los enlaces internos relevantes son:
- Técnicamente escalable.
- Potentes señales a Googlebot para priorizar una página para el rastreo.
- Particularmente impactante para el rastreo profundo de páginas.
Las migas de pan, los bloques de contenido relacionado, los filtros rápidos y el uso de etiquetas bien seleccionadas son beneficios significativos para la eficacia del rastreo. Dado que se trata de contenido crítico para el SEO, asegúrese de que dichos enlaces internos no dependan de JavaScript, sino que utilice un enlace <a> estándar y rastreable.
Teniendo en cuenta que dichos enlaces internos también deberían agregar valor real para el usuario.
Cómo buscar enlaces relevantes
Ejecute un rastreo manual de su sitio completo con una herramienta como la araña SEO de ScreamingFrog, buscando:
- URL huérfanas.
- Enlaces internos bloqueados por robots.txt.
- Enlaces internos a cualquier código de estado que no sea 200.
- El porcentaje de URL no indexables enlazadas internamente.
7. Auditar los problemas de rastreo restantes
Si todas las optimizaciones anteriores están completas y su eficacia de rastreo sigue siendo subóptima, realice una auditoría profunda.
Comience por revisar los ejemplos de las exclusiones restantes de Google Search Console para identificar problemas de rastreo.
Una vez que se solucionen, profundice utilizando una herramienta de rastreo manual para rastrear todas las páginas en la estructura del sitio como lo haría Googlebot. Haga una referencia cruzada de esto con los archivos de registro reducidos a las IP de Googlebot para comprender cuáles de esas páginas se rastrean y cuáles no.
Finalmente, inicie el análisis de archivos de registro reducido a la IP de Googlebot durante al menos cuatro semanas de datos, idealmente más.
Si no está familiarizado con el formato de los archivos de registro, aproveche una herramienta de análisis de registros. En última instancia, esta es la mejor fuente para comprender cómo Google rastrea su sitio.
Una vez que su auditoría esté completa y tenga una lista de problemas de rastreo identificados, clasifique cada problema por su nivel esperado de esfuerzo e impacto en el rendimiento.
Nota : Otros expertos en SEO han mencionado que los clics de las SERP aumentan el rastreo de la URL de la página de destino. Sin embargo, todavía no he podido confirmar esto con las pruebas.
Priorizar la eficacia del rastreo sobre el presupuesto de rastreo
El objetivo del rastreo no es obtener la mayor cantidad de rastreo ni hacer que todas las páginas de un sitio web se rastreen repetidamente, es atraer un rastreo de contenido relevante para SEO lo más cerca posible de cuando se crea o actualiza una página.
En general, los presupuestos no importan. Es en lo que inviertes lo que cuenta.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.