
Una guía para diagnosticar problemas comunes de SEO de JavaScript
Publicado: 2023-07-10Seamos honestos, JavaScript y SEO no siempre funcionan bien juntos. Para algunos SEO, el tema puede sentirse como si estuviera envuelto en un velo de complejidad.
Bueno, buenas noticias: cuando quitas las capas, muchos problemas de SEO basados en JavaScript vuelven a los fundamentos de cómo los rastreadores de los motores de búsqueda interactúan con JavaScript en primer lugar.
Entonces, si comprende esos fundamentos, puede profundizar en los problemas, comprender su impacto y trabajar con desarrolladores para solucionar los que importan.
En este artículo, ayudaremos a diagnosticar algunos problemas comunes cuando los sitios se crean en marcos JS. Además, desglosaremos el conocimiento básico que todo SEO técnico necesita cuando se trata de renderizado.
Representación en pocas palabras
Antes de entrar en cosas más granulares, hablemos del panorama general.
Para que un motor de búsqueda comprenda el contenido que funciona con JavaScript, tiene que rastrear y representar la página.
El problema es que los motores de búsqueda solo tienen una cantidad determinada de recursos para usar, por lo que deben ser selectivos sobre cuándo vale la pena usarlos. No es un hecho que una página se procesará, incluso si el rastreador la envía a la cola de procesamiento.
Si elige no mostrar la página o no puede mostrar el contenido correctamente, podría ser un problema.
Todo se reduce a cómo el front-end sirve HTML en la respuesta inicial del servidor.
Cuando se crea una URL en el navegador, una interfaz como React, Vue o Gatsby generará el HTML para la página. Un rastreador verifica si ese HTML ya está disponible en el servidor (HTML "pre-renderizado"), antes de enviar la URL para esperar a que se procese para que pueda ver el contenido resultante.
La disponibilidad de HTML prerenderizado depende de cómo esté configurado el front-end. Generará el HTML a través del servidor o en el navegador del cliente.
Representación del lado del servidor
El nombre lo dice todo. En una configuración de SSR, el rastreador recibe una página HTML completamente renderizada sin necesidad de una ejecución y renderización adicionales de JS.
Entonces, incluso si la página no se procesa, el motor de búsqueda aún puede rastrear cualquier HTML, contextualizar la página (metadatos, copia, imágenes) y comprender su relación con otras páginas (migas de pan, URL canónica, enlaces internos).
Representación del lado del cliente
En CSR, el HTML se genera en el navegador junto con todos los componentes de JavaScript. El JavaScript debe procesarse antes de que el HTML esté disponible para rastrear.
Si el servicio de renderizado elige no renderizar una página enviada a la cola, la copia, las URL internas, los enlaces de imágenes e incluso los metadatos no estarán disponibles para los rastreadores.
Como resultado, los motores de búsqueda tienen poco o ningún contexto para comprender la relevancia de una URL para las consultas de búsqueda.
Nota : puede haber una combinación de HTML que se sirva en la respuesta HTML inicial, así como HTML que requiera que JS se ejecute para poder renderizar (aparecer). Depende de varios factores, los más comunes incluyen el marco, cómo se construyen los componentes individuales del sitio y la configuración del servidor.
El kit de herramientas SEO de JavaScript
Ciertamente, existen herramientas que ayudarán a identificar problemas de SEO relacionados con JavaScript.
Puede hacer gran parte de la investigación utilizando las herramientas del navegador y Google Search Console. Aquí está la lista corta que constituye un sólido conjunto de herramientas:
- Ver fuente: haga clic con el botón derecho en una página y haga clic en "ver fuente" para ver el HTML prerenderizado de la página (la respuesta inicial del servidor).
- Pruebe la URL en vivo (inspección de URL): vea una captura de pantalla, HTML y otros detalles importantes de una página renderizada en la pestaña de inspección de URL de Google Search Console. (Se pueden encontrar muchos problemas de renderizado al comparar el HTML renderizado previamente de "ver fuente" con el HTML renderizado de la prueba de la URL en vivo en GSC).
- Herramientas para desarrolladores de Chrome: haga clic con el botón derecho en una página y elija "Inspeccionar" para abrir herramientas para ver errores de JavaScript y más.
- Wappalyzer: vea la pila en la que se basa cualquier sitio y busque información específica del marco instalando esta extensión gratuita de Chrome.
Problemas comunes de SEO de JavaScript
Problema 1: HTML renderizado previamente no está disponible universalmente
Además de las implicaciones negativas para el rastreo y la contextualización mencionadas anteriormente, también está el problema del tiempo y los recursos que podría necesitar un motor de búsqueda para mostrar una página.
Si el rastreador elige pasar una URL por el proceso de procesamiento, terminará en la cola de procesamiento. Esto sucede porque un rastreador puede detectar una disparidad entre la estructura HTML prerenderizada y la renderizada. (¡Lo que tiene mucho sentido si no hay HTML renderizado previamente!)
No hay garantía de cuánto tiempo espera una URL para el servicio de representación web. La mejor manera de influir en el WRS para que se muestre a tiempo es asegurarse de que haya señales de autoridad clave en el sitio que ilustren la importancia de una URL (p. ej., vinculado en la navegación superior, muchos enlaces internos, referenciados como canónicos). Eso se complica un poco porque las señales de autoridad también deben rastrearse.
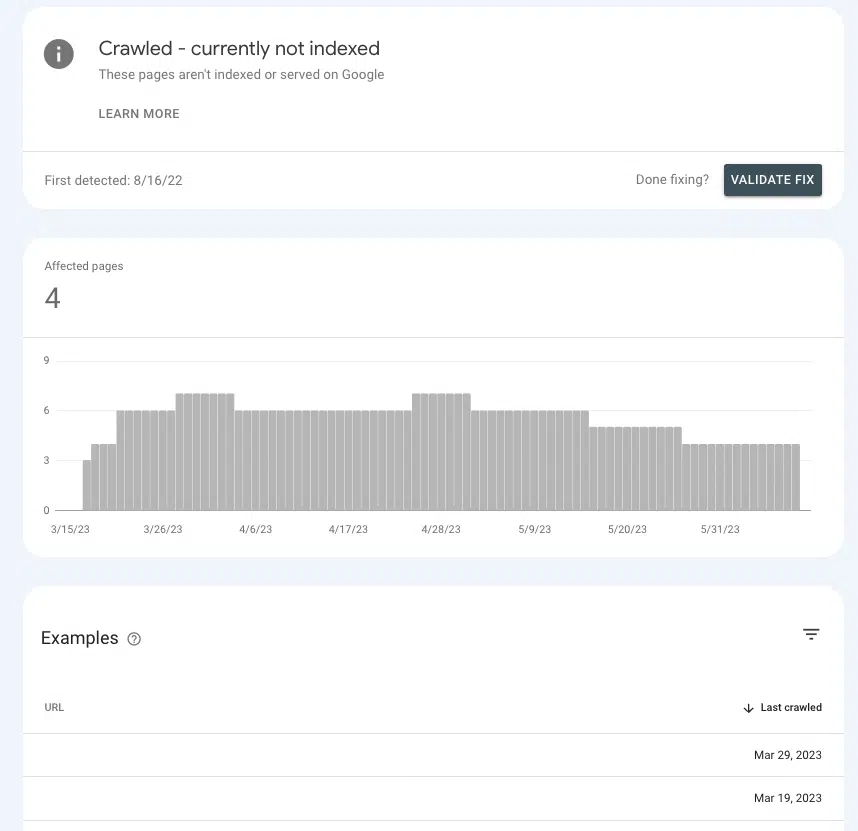
En Google Search Console, es posible tener una idea de si está enviando las señales de autoridad correctas a las páginas clave o haciendo que se queden en el limbo.
Vaya a Páginas > Indexación de páginas > Rastreadas: actualmente no indexadas y busque la presencia de páginas prioritarias dentro de la lista.
Si están en la sala de espera, es porque Google no puede determinar si son lo suficientemente importantes como para gastar recursos en ellos.
Causas comunes
Configuración por defecto
Los front-ends más populares vienen "listos para usar" configurados para la representación del lado del cliente, por lo que existe una gran posibilidad de que la configuración predeterminada sea la culpable.
Si se pregunta por qué la mayoría de las interfaces usan CSR de forma predeterminada, es por los beneficios de rendimiento. A los desarrolladores no siempre les encanta SSR, porque puede limitar las posibilidades de acelerar un sitio e implementar ciertos elementos interactivos (por ejemplo, transiciones únicas entre páginas).
Solicitud de una sola página
Si un sitio es una aplicación de una sola página, está completamente envuelto en JavaScript y genera todos los componentes de una página en el navegador (es decir, todo) se procesa en el lado del cliente y las páginas nuevas se sirven sin recargar).
Esto tiene algunas implicaciones negativas, quizás la más importante de las cuales es que las páginas son potencialmente imposibles de encontrar.
Esto no quiere decir que sea imposible configurar un SPA de una manera más amigable con el SEO. Pero lo más probable es que se necesite un trabajo de desarrollo significativo para que eso suceda.
Problema 2: parte del contenido de la página es inaccesible para los rastreadores
Conseguir que un motor de búsqueda represente una URL es excelente, siempre y cuando todos los elementos estén disponibles para rastrear. ¿Qué pasa si está representando la página, pero hay secciones de una página a las que no se puede acceder?
Por ejemplo, un SEO realiza un análisis de enlaces internos y encuentra pocos o ningún enlace interno informado para una URL vinculada en varias páginas.
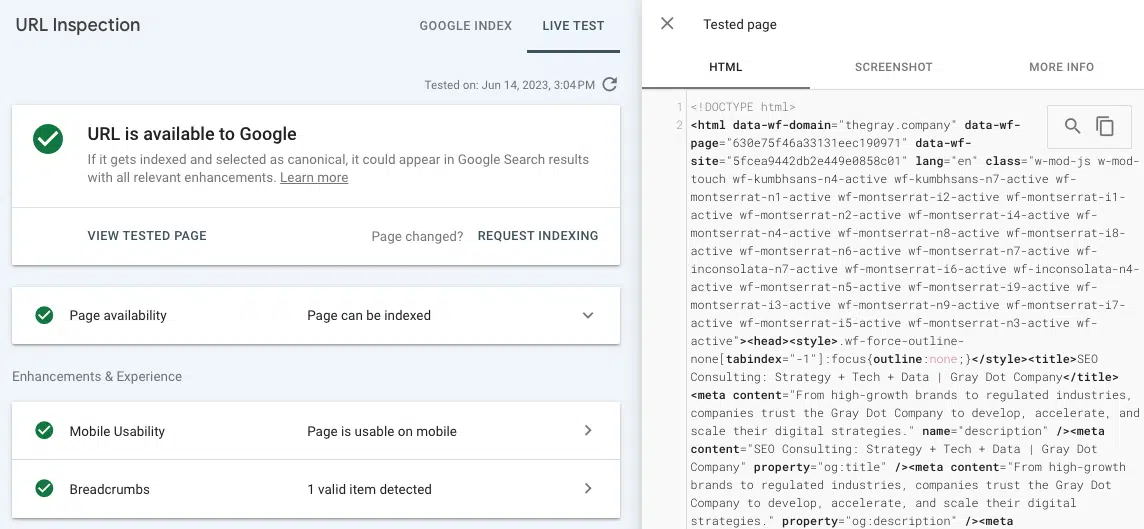
Si el enlace no se muestra en el HTML representado desde la herramienta Test Live URL, es probable que se publique en recursos de JavaScript a los que Google no puede acceder.
Para reducir al culpable, sería una buena idea buscar puntos en común en términos de dónde se encuentra el contenido de la página faltante o los enlaces internos en la página a través de las URL.
Por ejemplo, si es un enlace de preguntas frecuentes que aparece en la misma sección de cada página de producto, eso ayuda mucho a los desarrolladores a encontrar una solución.
Causas comunes
Errores de JavaScript
Comencemos con un descargo de responsabilidad aquí. La mayoría de los errores de JavaScript que encuentra no importan para el SEO.
Entonces, si busca errores, lleva una lista larga a su desarrollador y comienza la conversación con "¿Qué son todos estos errores?", Es posible que no lo reciban tan bien.
Acérquese con el "por qué" hablando del problema, para que puedan ser expertos en JavaScript (¡porque lo son!).
Dicho esto, hay errores de sintaxis que podrían hacer que el resto de la página no se pueda analizar (por ejemplo, "bloqueo de procesamiento"). Cuando esto ocurre, el renderizador no puede desglosar los elementos HTML individuales, estructurar el contenido en el DOM ni comprender las relaciones.
En general, estos tipos de errores son reconocibles porque también tienen algún tipo de efecto en la vista del navegador.
Además de la confirmación visual, también es posible ver los errores de JavaScript haciendo clic derecho en la página, seleccionando "inspeccionar" y navegando a la pestaña "Consola".
Obtenga el boletín informativo diario en el que confían los especialistas en marketing.
Ver términos.
El contenido requiere una interacción del usuario.

Una de las cosas más importantes que debe recordar acerca del renderizado es que Google no puede renderizar ningún contenido que requiera que los usuarios interactúen con la página. O, para decirlo de manera más sencilla, no puede "hacer clic" en las cosas.
¿Por que importa? Piense en nuestro viejo y fiel amigo, el menú desplegable de acordeón, y cuántos sitios lo usan para organizar contenido como detalles de productos y preguntas frecuentes.
Dependiendo de cómo esté codificado el acordeón, es posible que Google no pueda representar el contenido en el menú desplegable si no se completa hasta que se ejecuta JS.
Para verificar, puede "Inspeccionar" una página y ver si el contenido "oculto" (lo que se muestra una vez que hace clic en un acordeón) está en el HTML.
Si no es así, significa que Googlebot y otros rastreadores no ven este contenido en la versión renderizada de la página.
Problema 3: las secciones de un sitio no se rastrean
Google puede o no mostrar su página si la rastrea y la envía a la cola. Si no rastrea la página, incluso esa oportunidad está fuera de la mesa.
Para saber si Google está rastreando páginas, el informe Estadísticas de rastreo puede ser útil Configuración > Estadísticas de rastreo .
Seleccione Solicitudes de rastreo: OK (200) para ver todas las instancias de rastreo de 200 páginas de estado en los últimos tres meses. Luego, use el filtrado para buscar URL individuales o directorios completos.
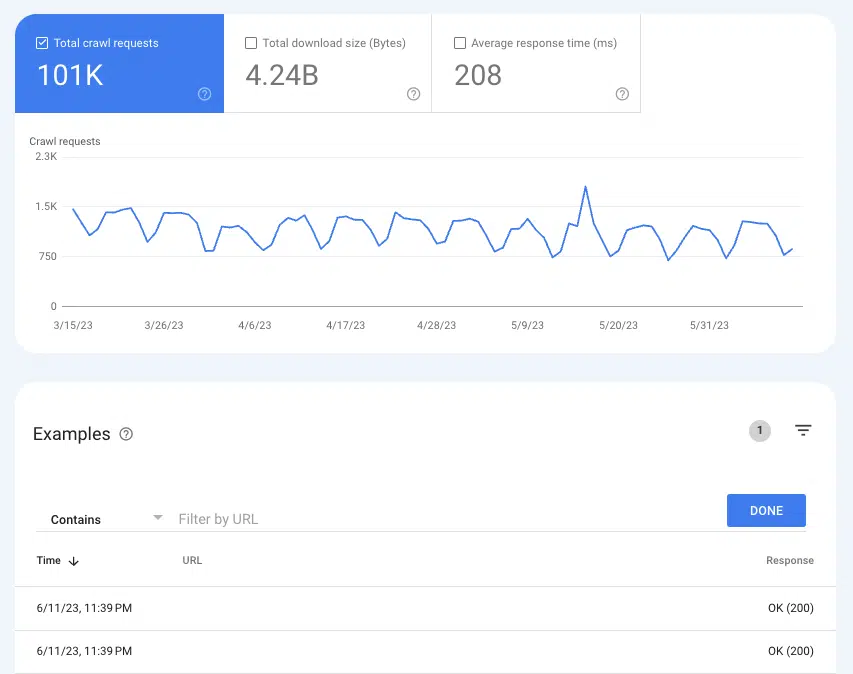
Si las URL no aparecen en los registros de rastreo, es muy probable que Google no pueda descubrir las páginas y rastrearlas (o no son 200 páginas, que es un problema completamente diferente).
Causas comunes
Los enlaces internos no se pueden rastrear
Los enlaces son las señales de tráfico que siguen los rastreadores para acceder a nuevas páginas. Esa es una de las razones por las que las páginas huérfanas son un problema tan grande.
Si tiene un sitio bien vinculado y está viendo aparecer páginas huérfanas en las auditorías de su sitio, es muy probable que se deba a que los vínculos no están disponibles en el HTML renderizado previamente.
Una manera fácil de verificar es ir a una URL que se vincule a la página huérfana reportada. Haga clic derecho en la página y haga clic en "ver fuente".
Luego, usa CMD + f para buscar la URL de la página huérfana. Si no aparece en el HTML renderizado previamente, pero aparece en la página cuando se renderiza en el navegador, salte al número cuatro.
Mapa del sitio XML no actualizado
El mapa del sitio XML es crucial para ayudar a Google a descubrir nuevas páginas y comprender qué URL priorizar en un rastreo.
Sin el mapa del sitio XML, el descubrimiento de la página solo es posible siguiendo los enlaces.
Por lo tanto, para los sitios sin HTML renderizado previamente, un mapa del sitio desactualizado o faltante significa esperar a que Google renderice las páginas, siga los enlaces internos a otras páginas, las ponga en cola, las renderice, siga sus enlaces, etc.
Dependiendo de la interfaz que esté utilizando, es posible que tenga acceso a complementos que pueden crear mapas de sitio XML dinámicos.
A menudo necesitan personalización, por lo que es importante que los SEO documenten diligentemente cualquier URL que no deba estar en el mapa del sitio y la lógica de por qué.
Esto debería ser relativamente fácil de verificar ejecutando el mapa del sitio a través de su herramienta de SEO favorita.
Problema 4: Faltan enlaces internos
La falta de disponibilidad de enlaces internos a los rastreadores no es solo un problema potencial de descubrimiento, también es un problema de equidad. Dado que los enlaces pasan la equidad de SEO de la URL de referencia a la URL de destino, son un factor importante para aumentar la autoridad de la página y del dominio.
Los enlaces de la página de inicio son un gran ejemplo. Por lo general, es la página con más autoridad en un sitio web, por lo que un enlace a otra página desde la página de inicio tiene mucho peso.
Si esos enlaces no se pueden rastrear, entonces es un poco como tener un sable de luz roto. Una de sus herramientas más poderosas se vuelve inútil (juego de palabras).
Causas comunes
Se requiere interacción del usuario para llegar al enlace.
El ejemplo de acordeón que usamos anteriormente es solo una instancia en la que el contenido se oculta detrás de una interacción del usuario. Otra que puede tener implicaciones generalizadas es la paginación de desplazamiento infinito, especialmente para sitios de comercio electrónico con catálogos sustanciales de productos.
En una configuración de desplazamiento infinito, innumerables productos en una página de lista de productos (categoría) no se cargarán a menos que un usuario se desplace más allá de cierto punto (carga diferida) o toque el botón "mostrar más".
Entonces, incluso si se procesa el JavaScript, un rastreador no puede acceder a los enlaces internos de los productos que aún no se han cargado. Sin embargo, cargar todos estos productos en una página afectaría negativamente la experiencia del usuario debido al bajo rendimiento de la página.
Esta es la razón por la cual los SEO generalmente prefieren la paginación verdadera en la que cada página de resultados tiene una URL rastreable distinta.
Si bien hay formas para que un sitio optimice la carga diferida y agregue todos los productos al HTML renderizado previamente, esto generaría diferencias entre el HTML renderizado y el HTML renderizado previamente.
Efectivamente, esto crea una razón para enviar más páginas a la cola de procesamiento y hacer que los rastreadores trabajen más de lo necesario, y sabemos que eso no es bueno para el SEO.
Como mínimo, siga las recomendaciones de Google para optimizar el desplazamiento infinito.
Enlaces no codificados correctamente
Cuando Google rastrea un sitio o presenta una URL en la cola, está descargando una versión sin estado de una página. Esa es una gran parte de por qué es tan importante usar etiquetas href y anclas adecuadas (la estructura de enlace que ves con más frecuencia). Un rastreador no puede seguir formatos de enlace como enrutador, intervalo u onClick.
Puede seguir:
- <a href="https://ejemplo.com">
- <a href="/relativa/ruta/archivo">
no puedo seguir:
- <a routerLink="alguna/ruta">
- <span href="https://ejemplo.com">
- <a>
Para los propósitos de un desarrollador, todas estas son formas válidas de codificar enlaces. Las implicaciones de SEO son una capa adicional de contexto, y no es su trabajo saberlo, es el SEO.
Una gran parte del trabajo de un buen SEO es proporcionar a los desarrolladores ese contexto a través de la documentación.
Problema 5: faltan metadatos
En una página HTML, los metadatos como el título, la descripción, la URL canónica y la etiqueta de meta robots están anidados en el encabezado.
Por razones obvias, la falta de metadatos es perjudicial para el SEO, pero aún más para los SPA. Elementos como una URL canónica autorreferenciada son cruciales para mejorar las posibilidades de que una página JS supere con éxito la cola de procesamiento.
De todos los elementos que deberían estar presentes en el HTML renderizado previamente, el encabezado es el más importante para la indexación.
Afortunadamente, este problema es bastante fácil de detectar, ya que desencadenará una gran cantidad de errores por falta de metadatos en cualquier herramienta de SEO que un sitio utilice para los informes de higiene. Luego, puede confirmar buscando la cabeza en el código fuente.
Causas comunes
Vehículo de metadatos faltante o mal configurado
En un marco JS, un complemento crea el encabezado e inserta los metadatos en el encabezado. (El ejemplo más popular es React Helmet). Incluso si ya hay un complemento instalado, generalmente debe configurarse correctamente.
Nuevamente, esta es un área en la que todo lo que pueden hacer los SEO es llevar el problema al desarrollador, explicar el por qué y trabajar de cerca para lograr criterios de aceptación bien documentados.
Problema 6: los recursos no se rastrean
Los archivos de secuencias de comandos y las imágenes son bloques de construcción esenciales en el proceso de renderizado.
Dado que también tienen sus propias URL, las leyes de rastreabilidad también se aplican a ellos. Si se bloquea el rastreo de los archivos, Google no puede analizar la página para representarla.
Para ver si se rastrean las URL, puede ver las solicitudes anteriores en GSC Crawl Stats.
- Imágenes: vaya a Configuración > Estadísticas de rastreo > Solicitudes de rastreo: Imagen
- JavaScript: vaya a Configuración > Estadísticas de rastreo > Solicitudes de rastreo: Imagen
Causas comunes
Directorio bloqueado por robots.txt
Tanto las URL de la secuencia de comandos como las de las imágenes generalmente se anidan en su propio subdominio o subcarpeta dedicado, por lo que una expresión de rechazo en robots.txt evitará el rastreo.
Algunas herramientas de SEO le dirán si algún script o archivo de imagen está bloqueado, pero el problema es bastante fácil de detectar si sabe dónde están anidados sus imágenes y archivos de script. Puede buscar esas estructuras de URL en robots.txt.
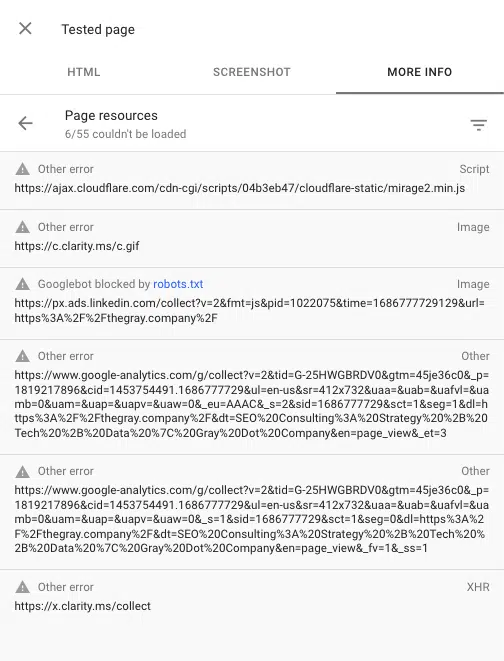
También puede ver cualquier secuencia de comandos bloqueada al mostrar una página utilizando la herramienta de inspección de URL en Google Search Console. "Probar URL en vivo" y luego ir a Ver página probada > Más información > Recursos de la página .
Aquí puede ver los scripts que no se cargan durante el proceso de renderizado. Si un archivo está bloqueado por robots.txt, se marcará como tal.
Hazte amigo de JavaScript
Sí, JavaScript puede venir con algunos problemas de SEO. Pero a medida que evoluciona el SEO, las mejores prácticas se están convirtiendo en sinónimo de una gran experiencia de usuario.
Una gran experiencia de usuario a menudo depende de JavaScript. Entonces, si bien el trabajo de un SEO no es codificar JavaScript, necesitamos saber cómo los motores de búsqueda interactúan, lo procesan y lo usan.
Con una sólida comprensión del proceso de renderizado y algunos problemas comunes de SEO en los marcos JS, está bien encaminado para identificar los problemas y ser un poderoso aliado para sus desarrolladores.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.