
Entity SEO: La guía definitiva
Publicado: 2023-04-06Este artículo fue escrito en colaboración con Andrew Ansley .
Cosas, no cuerdas. Si no ha escuchado esto antes, proviene de una famosa publicación de blog de Google que anunció Knowledge Graph.
El 11.° aniversario del anuncio está a solo un mes de distancia, pero muchos aún luchan por comprender qué significa realmente “cosas, no cadenas” para el SEO.
La cita es un intento de transmitir que Google entiende las cosas y ya no es un simple algoritmo de detección de palabras clave.
En mayo de 2012, se podría argumentar que nació la entidad SEO. El aprendizaje automático de Google, con la ayuda de bases de conocimiento semiestructuradas y estructuradas, podría comprender el significado detrás de una palabra clave.
La naturaleza ambigua del lenguaje finalmente tuvo una solución a largo plazo.
Entonces, si las entidades han sido importantes para Google durante más de una década, ¿por qué los SEO todavía están confundidos acerca de las entidades?
Buena pregunta. Veo cuatro razones:
- El SEO de entidad como término no se ha utilizado lo suficiente como para que los SEO se sientan cómodos con su definición y, por lo tanto, lo incorporen a su vocabulario.
- La optimización de entidades se superpone en gran medida con los antiguos métodos de optimización centrados en palabras clave. Como resultado, las entidades se combinan con palabras clave. Además de esto, no estaba claro cómo las entidades desempeñaban un papel en el SEO, y la palabra "entidades" a veces es intercambiable con "temas" cuando Google habla sobre el tema.
- Comprender las entidades es una tarea aburrida. Si desea un conocimiento profundo de las entidades, deberá leer algunas patentes de Google y conocer los conceptos básicos del aprendizaje automático. El SEO de entidades es un enfoque mucho más científico del SEO, y la ciencia no es para todos.
- Si bien YouTube ha tenido un impacto masivo en la distribución del conocimiento, ha aplanado la experiencia de aprendizaje para muchas materias. Históricamente, los creadores con más éxito en la plataforma han tomado el camino fácil al educar a su audiencia. Como resultado, los creadores de contenido no han dedicado mucho tiempo a las entidades hasta hace poco. Debido a esto, debe aprender sobre las entidades de los investigadores de NLP y luego debe aplicar el conocimiento al SEO. Las patentes y los trabajos de investigación son clave. Una vez más, esto refuerza el primer punto anterior.
Este artículo es una solución a los cuatro problemas que han impedido que los SEO dominen por completo un enfoque de SEO basado en entidades.
Al leer esto, aprenderás:
- Qué es una entidad y por qué es importante.
- La historia de la búsqueda semántica.
- Cómo identificar y utilizar entidades en la SERP.
- Cómo utilizar entidades para clasificar el contenido web.
¿Por qué son importantes las entidades?
Entity SEO es el futuro de hacia dónde se dirigen los motores de búsqueda con respecto a elegir qué contenido clasificar y determinar su significado.
Combine esto con la confianza basada en el conocimiento, y creo que el SEO de entidades será el futuro de cómo se realiza el SEO en los próximos dos años.
Ejemplos de entidades
Entonces, ¿cómo se reconoce una entidad?
El SERP tiene varios ejemplos de entidades que probablemente hayas visto.
Los tipos de entidades más comunes están relacionados con ubicaciones, personas o empresas.
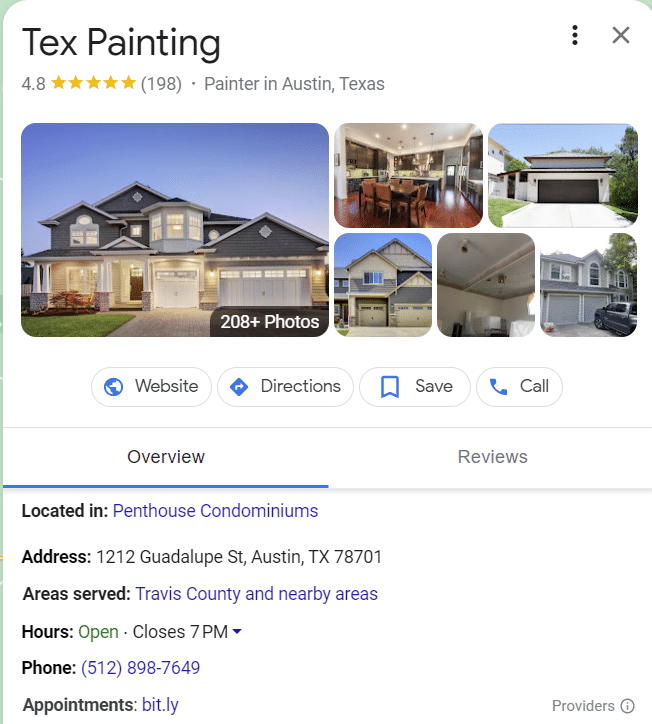
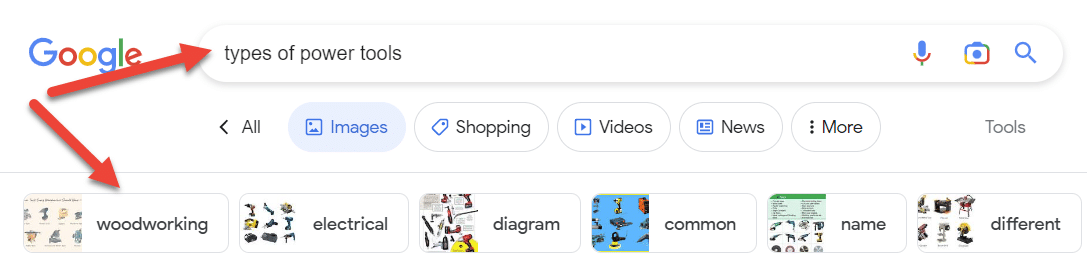
Quizás el mejor ejemplo de entidades en SERP son los clústeres de intención. Cuanto más se entiende un tema, más emergen estas funciones de búsqueda.
Curiosamente, una sola campaña de SEO puede alterar la cara de la SERP cuando sabes cómo ejecutar campañas de SEO centradas en la entidad.
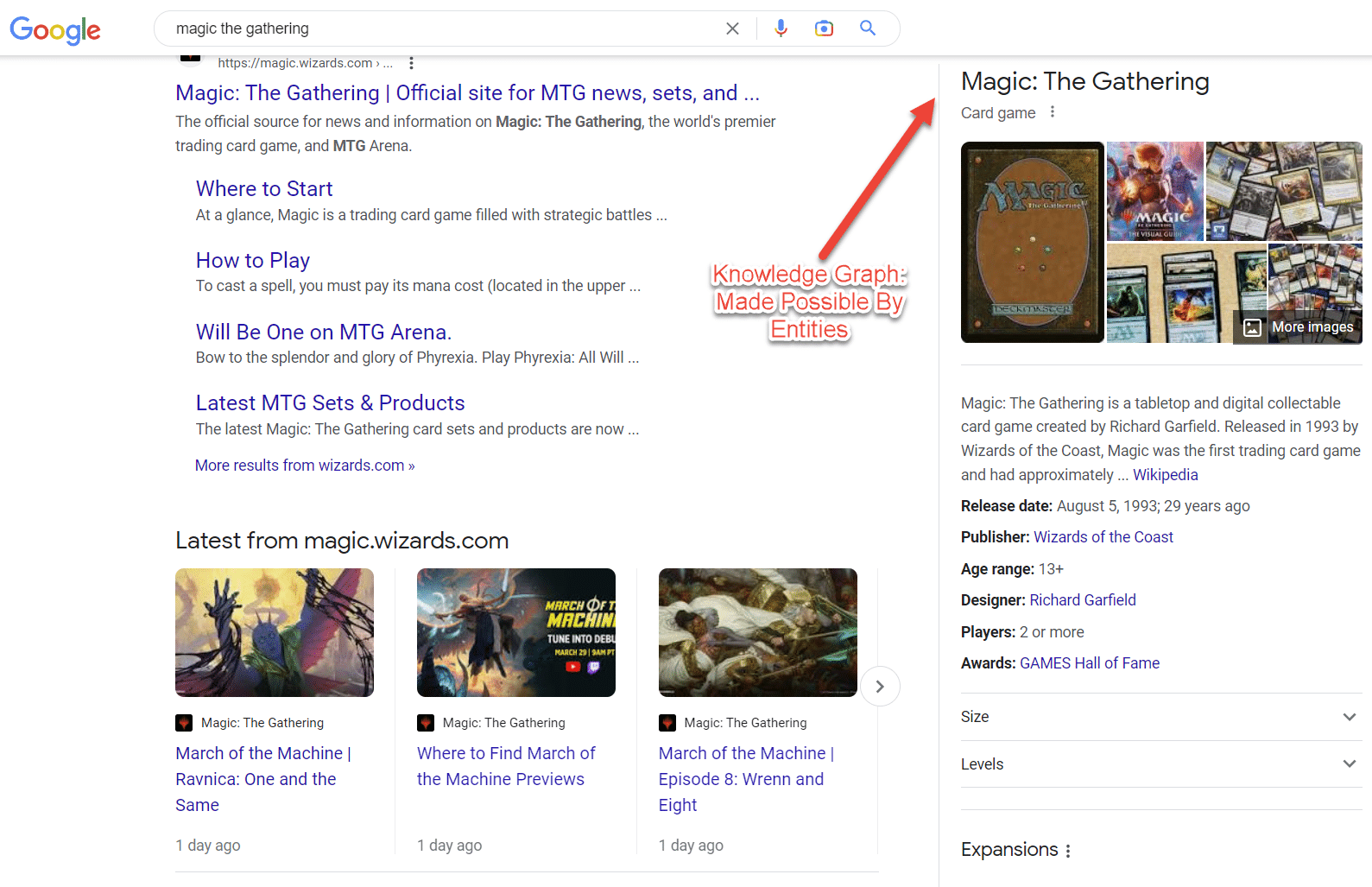
Las entradas de Wikipedia son otro ejemplo de entidades. Wikipedia proporciona un gran ejemplo de información asociada con entidades.
Como puede ver en la parte superior izquierda, la entidad tiene todo tipo de atributos asociados con el "pez", que van desde su anatomía hasta su importancia para los humanos.
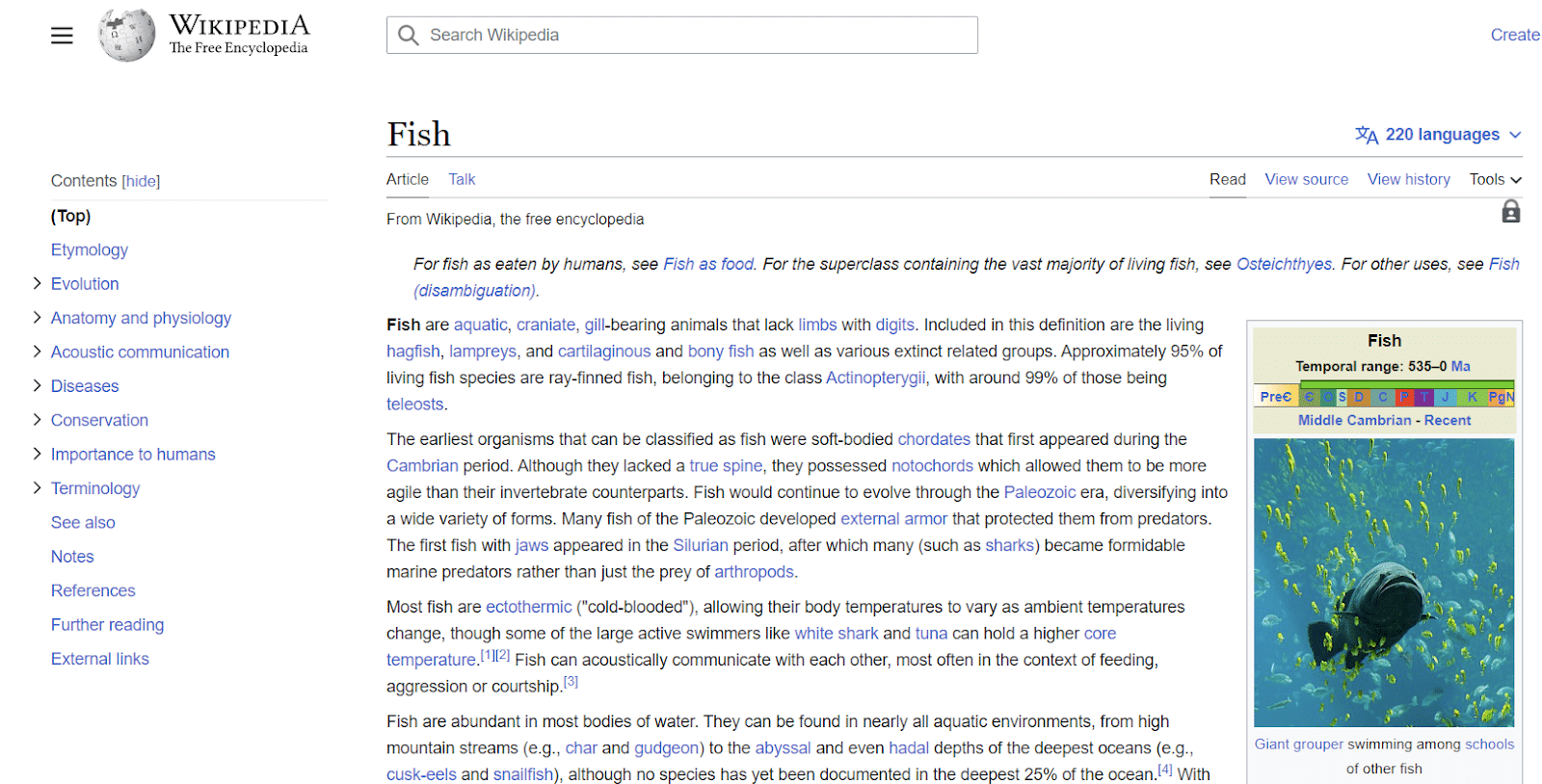
Si bien Wikipedia contiene muchos puntos de datos sobre un tema, de ninguna manera es exhaustiva.
¿Qué es una entidad?
Una entidad es un objeto o cosa identificable de forma única caracterizada por su(s) nombre(s), tipo(s), atributos y relaciones con otras entidades. Solo se considera que una entidad existe cuando existe en un catálogo de entidades.
Los catálogos de entidades asignan un ID único a cada entidad. Mi agencia tiene soluciones programáticas que usan la identificación única asociada con cada entidad (los servicios, los productos y las marcas están todos incluidos).
Si una palabra o frase no está dentro de un catálogo existente, no significa que la palabra o frase no sea una entidad, pero normalmente puede saber si algo es una entidad por su existencia en el catálogo.
Es importante tener en cuenta que Wikipedia no es el factor decisivo para determinar si algo es una entidad, pero la empresa es más conocida por su base de datos de entidades.
Se puede usar cualquier catálogo cuando se habla de entidades. Por lo general, una entidad es una persona, un lugar o una cosa, pero también se pueden incluir ideas y conceptos.
Algunos ejemplos de catálogos de entidades incluyen:
- Wikipedia
- Wikidata
- DBpedia
- base libre
- yago

Las entidades ayudan a cerrar la brecha entre los mundos de datos estructurados y no estructurados.
Se pueden usar para enriquecer semánticamente el texto no estructurado, mientras que las fuentes textuales se pueden utilizar para poblar bases de conocimiento estructuradas.
El reconocimiento de menciones de entidades en el texto y la asociación de estas menciones con las entradas correspondientes en una base de conocimientos se conoce como la tarea de vinculación de entidades.
Las entidades permiten una mejor comprensión del significado del texto, tanto para humanos como para máquinas.
Si bien los humanos pueden resolver con relativa facilidad la ambigüedad de las entidades según el contexto en el que se mencionan, esto presenta muchas dificultades y desafíos para las máquinas.
La entrada de la base de conocimientos de una entidad resume lo que sabemos sobre esa entidad.
A medida que el mundo cambia constantemente, también surgen nuevos hechos. Mantenerse al día con estos cambios requiere un esfuerzo continuo por parte de los editores y administradores de contenido. Esta es una tarea exigente a escala.
Mediante el análisis del contenido de los documentos en los que se mencionan las entidades, se puede apoyar o incluso automatizar por completo el proceso de encontrar nuevos hechos o hechos que necesitan actualizarse.
Los científicos se refieren a esto como el problema de la población de la base de conocimientos, razón por la cual la vinculación de entidades es importante.
Las entidades facilitan la comprensión semántica de la necesidad de información del usuario, expresada por la consulta de palabras clave, y el contenido del documento. Por lo tanto, las entidades pueden usarse para mejorar las representaciones de consultas y/o documentos.
En el artículo de investigación de Entidad con nombre extendido, el autor identifica alrededor de 160 tipos de entidades. Aquí hay dos de las siete capturas de pantalla de la lista.


Ciertas categorías de entidades se definen más fácilmente, pero es importante recordar que los conceptos y las ideas son entidades. Esas dos categorías son muy difíciles de escalar para Google por sí solo.
No se puede enseñar a Google con una sola página cuando se trabaja con conceptos vagos. La comprensión de la entidad requiere muchos artículos y muchas referencias sostenidas en el tiempo.
El historial de Google con las entidades
El 16 de julio de 2010, Google compró Freebase. Esta compra fue el primer gran paso que condujo al actual sistema de búsqueda de entidades.

Después de invertir en Freebase, Google se dio cuenta de que Wikidata tenía una mejor solución. Luego, Google trabajó para fusionar Freebase en Wikidata, una tarea que fue mucho más difícil de lo esperado.
Cinco científicos de Google escribieron un artículo titulado "De Freebase a Wikidata: la gran migración". Los puntos clave incluyen.
“Freebase se basa en las nociones de objetos, hechos, tipos y propiedades. Cada objeto de Freebase tiene un identificador estable llamado "mid" (para Machine ID)".
“El modelo de datos de Wikidata se basa en las nociones de elemento y declaración. Un elemento representa una entidad, tiene un identificador estable llamado "qid" y puede tener etiquetas, descripciones y alias en varios idiomas; más declaraciones y enlaces a páginas sobre la entidad en otros proyectos de Wikimedia, principalmente Wikipedia. A diferencia de Freebase, las declaraciones de Wikidata no pretenden codificar hechos verdaderos, sino afirmaciones de diferentes fuentes, que también pueden contradecirse entre sí…”
Las entidades se definen en estas bases de conocimiento, pero Google aún tenía que construir su conocimiento de entidad para datos no estructurados (es decir, blogs).
Google se asoció con Bing y Yahoo y creó Schema.org para realizar esta tarea.
Google proporciona instrucciones de esquema para que los administradores de sitios web puedan tener herramientas que ayuden a Google a comprender el contenido. Recuerda, Google quiere centrarse en las cosas, no en las cadenas.
En palabras de Google:
“Puede ayudarnos proporcionando pistas explícitas sobre el significado de una página a Google al incluir datos estructurados en la página. Los datos estructurados son un formato estandarizado para proporcionar información sobre una página y clasificar el contenido de la página; por ejemplo, en una página de recetas, cuáles son los ingredientes, el tiempo y la temperatura de cocción, las calorías, etc.
Google continúa diciendo:
“Debe incluir todas las propiedades requeridas para que un objeto sea elegible para aparecer en la Búsqueda de Google con visualización mejorada. En general, definir más funciones recomendadas puede aumentar la probabilidad de que su información aparezca en los resultados de búsqueda con visualización mejorada. Sin embargo, es más importante proporcionar menos propiedades recomendadas, pero completas y precisas, en lugar de intentar proporcionar todas las propiedades recomendadas posibles con datos menos completos, mal formados o inexactos”.
Se podría decir más sobre el esquema, pero basta con decir que el esquema es una herramienta increíble para los SEO que buscan aclarar el contenido de la página para los motores de búsqueda.
La última pieza del rompecabezas proviene del anuncio del blog de Google titulado "Mejorando la búsqueda para los próximos 20 años".
La relevancia y la calidad de los documentos son las ideas principales detrás de este anuncio. El primer método que utilizó Google para determinar el contenido de una página se centró por completo en las palabras clave.
Luego, Google agregó capas de temas para buscar. Esta capa fue posible gracias a los gráficos de conocimiento y al raspado y estructuración sistemática de datos en la web.
Eso nos lleva al sistema de búsqueda actual. Google pasó de 570 millones de entidades y 18 mil millones de hechos a 800 mil millones de hechos y 8 mil millones de entidades en menos de 10 años. A medida que crece este número, mejora la búsqueda de entidades.
¿Cómo es el modelo de entidad una mejora de los modelos de búsqueda anteriores?
Los modelos tradicionales de recuperación de información (IR) basados en palabras clave tienen una limitación inherente de no poder recuperar documentos (relevantes) que no tengan coincidencias de términos explícitos con la consulta.
Si usa ctrl + f para buscar texto en una página, usa algo similar al modelo tradicional de recuperación de información basado en palabras clave.
Una cantidad increíble de datos se publica en la web todos los días.
Simplemente no es factible que Google comprenda el significado de cada palabra, cada párrafo, cada artículo y cada sitio web.
En cambio, las entidades proporcionan una estructura a partir de la cual Google puede minimizar la carga computacional mientras mejora la comprensión.
“Los métodos de recuperación basados en conceptos intentan abordar este desafío apoyándose en estructuras auxiliares para obtener representaciones semánticas de consultas y documentos en un espacio conceptual de nivel superior. Dichas estructuras incluyen vocabularios controlados (diccionarios y tesauros), ontologías y entidades de un repositorio de conocimiento”.
– Búsqueda orientada a entidades , Capítulo 8.3
Krisztian Balog, quien escribió el libro definitivo sobre entidades, identifica tres posibles soluciones al modelo tradicional de recuperación de información.
- Basado en expansión : utiliza entidades como fuente para expandir la consulta con diferentes términos.
- Basado en proyección : la relevancia entre una consulta y un documento se entiende proyectándolos en un espacio latente de entidades
- Basado en entidades : se obtienen representaciones semánticas explícitas de consultas y documentos en el espacio de entidades para aumentar las representaciones basadas en términos.
El objetivo de estos tres enfoques es obtener una representación más rica de la información del usuario necesaria mediante la identificación de entidades fuertemente relacionadas con la consulta.
Balog luego identifica seis algoritmos asociados con métodos basados en proyección de mapeo de entidades (los métodos de proyección se relacionan con convertir entidades en espacio tridimensional y medir vectores usando geometría).
- Análisis semántico explícito (ESA) : la semántica de una palabra determinada se describe mediante un vector que almacena la fuerza de asociación de la palabra con los conceptos derivados de Wikipedia.
- Modelo de espacio de entidad latente (LES) : basado en un marco probabilístico generativo. La puntuación de recuperación del documento se considera una combinación lineal de la puntuación del espacio de entidad latente y la puntuación de probabilidad de consulta original.
- EsdRank: EsdRank es para clasificar documentos, utilizando una combinación de características de entidad de consulta y documento de entidad. Estos corresponden a las nociones de los componentes de proyección de consultas y proyección de documentos de LES, respectivamente, de antes. Usando un marco de aprendizaje discriminativo, también se pueden incorporar fácilmente señales adicionales, como la popularidad de la entidad o la calidad del documento.
- Clasificación semántica explícita (ESR): el modelo de clasificación semántica explícita incorpora información de relación de un gráfico de conocimiento para permitir la "coincidencia suave" en el espacio de la entidad.
- Marco de dúo de entidad de palabra: esto incorpora interacciones entre espacios entre representaciones basadas en términos y basadas en entidades, lo que lleva a cuatro tipos de coincidencias: términos de consulta a términos de documento, entidades de consulta a términos de documento, términos de consulta a entidades de documento y entidades de consulta para documentar entidades.
- Modelo de clasificación basado en la atención : Este es, con mucho, el más complicado de describir.
Esto es lo que escribe Balog:
“Se diseñan un total de cuatro funciones de atención, que se extraen para cada entidad de consulta. Las características de ambigüedad de entidad están destinadas a caracterizar el riesgo asociado con una anotación de entidad. Estos son: (1) la entropía de la probabilidad de que la forma de superficie esté vinculada a diferentes entidades (por ejemplo, en Wikipedia), (2) si la entidad anotada es el sentido más popular de la forma de superficie (es decir, tiene la mayor similitud puntuación, y (3) la diferencia en las puntuaciones de frecuencia entre los candidatos más probables y el segundo más probable para la forma de superficie dada. La cuarta característica es la cercanía, que se define como la similitud del coseno entre la entidad de consulta y la consulta en un espacio incrustado ". Específicamente, una incrustación de término de entidad conjunta se entrena utilizando el modelo skip-gram en un corpus, donde las menciones de entidad se reemplazan con los identificadores de entidad correspondientes. La incrustación de la consulta se toma como el centroide de las incrustaciones de los términos de consulta".

Por ahora, es importante estar familiarizado a nivel superficial con estos seis algoritmos centrados en entidades.
La conclusión principal es que existen dos enfoques: proyectar documentos en una capa de entidad latente y anotaciones de documentos de entidad explícita.
Tres tipos de estructuras de datos
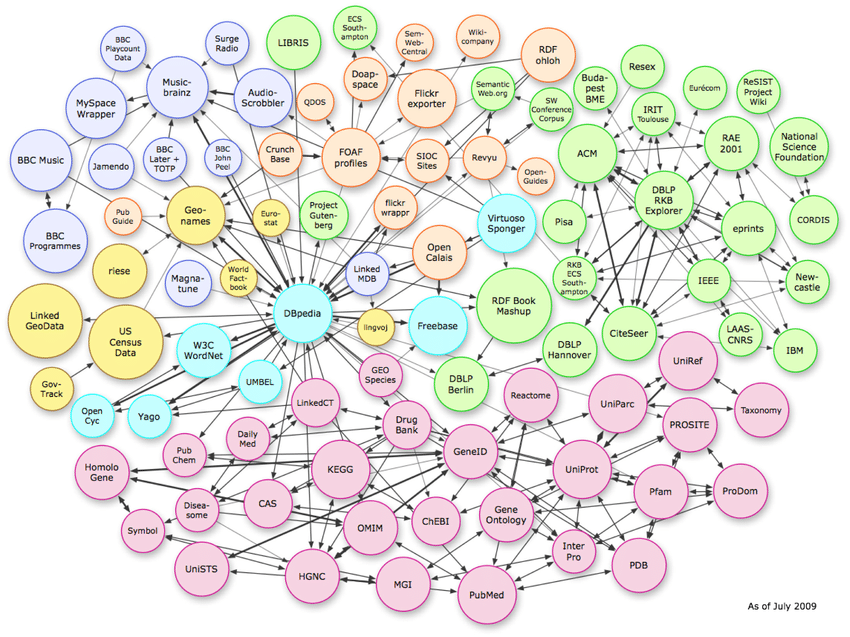
La imagen de arriba muestra las complejas relaciones que existen en el espacio vectorial. Si bien el ejemplo muestra conexiones de gráficos de conocimiento, este mismo patrón se puede replicar en un nivel de esquema de página por página.
Para comprender las entidades, es importante conocer los tres tipos de estructuras de datos que utilizan los algoritmos.
- Al utilizar descripciones de entidades no estructuradas , las referencias a otras entidades deben reconocerse y eliminarse la ambigüedad. Los bordes dirigidos (hipervínculos) se agregan desde cada entidad a todas las demás entidades mencionadas en su descripción.
- En un entorno semiestructurado (es decir, Wikipedia), se pueden proporcionar explícitamente enlaces a otras entidades.
- Cuando se trabaja con datos estructurados , las tripletas RDF definen un gráfico (es decir, el gráfico de conocimiento). Específicamente, los recursos de sujeto y objeto (URI) son nodos y los predicados son bordes.
El problema con un contexto semiestructurado y que distrae la puntuación de IR es que si un documento no está configurado para un solo tema, la puntuación de IR puede diluirse por los dos contextos diferentes, lo que da como resultado una pérdida de rango relativo frente a otro documento textual.
La dilución de la puntuación IR implica relaciones léxicas mal estructuradas y proximidad de malas palabras.
Las palabras relevantes que se completan entre sí deben usarse de cerca dentro de un párrafo o sección del documento para señalar el contexto más claramente para aumentar el puntaje IR.
El uso de atributos y relaciones de entidad produce mejoras relativas en el rango del 5 al 20%. La explotación de la información de tipo de entidad es aún más gratificante, con mejoras relativas que van desde el 25 % hasta más del 100 %.
Anotar documentos con entidades puede aportar estructura a los documentos no estructurados, lo que puede ayudar a llenar las bases de conocimientos con nueva información sobre las entidades.
Uso de Wikipedia como marco de SEO de su entidad
Estructura de las páginas de Wikipedia
- Título (I.)
- Sección de plomo (II.)
- Enlaces de desambiguación (II.a)
- Cuadro de información (II.b)
- Texto introductorio (II.c)
- Índice (III.)
- Contenido corporal (IV.)
- Apéndices y materia de fondo (V.)
- Referencias y notas (Va)
- Enlaces externos (VB)
- Categorías (Vc)
La mayoría de los artículos de Wikipedia incluyen un texto introductorio, el "principio", un breve resumen del artículo, por lo general, no más de cuatro párrafos. Esto debe estar escrito de una manera que genere interés en el artículo.
La primera oración y el párrafo inicial tienen especial importancia. La primera oración "puede considerarse como la definición de la entidad descrita en el artículo". El primer párrafo ofrece una definición más elaborada sin demasiados detalles.
El valor de los enlaces se extiende más allá de los propósitos de navegación; capturan relaciones semánticas entre artículos. Además, los textos de anclaje son una rica fuente de variantes de nombres de entidades. Los enlaces de Wikipedia se pueden usar, entre otros, para ayudar a identificar y eliminar la ambigüedad de las menciones de entidades en el texto.
- Resuma los datos clave sobre la entidad (infobox).
- Breve introducción.
- Vínculos internos. Una regla clave dada a los editores es vincular solo a la primera aparición de una entidad o concepto.
- Incluya todos los sinónimos populares de una entidad.
- Designación de página de categoría.
- Plantilla de navegación.
- Referencias.
- Herramientas especiales de análisis para comprender las páginas Wiki.
- Múltiples tipos de medios.
Cómo optimizar para entidades
Lo que sigue son consideraciones clave al optimizar entidades para la búsqueda:
- La inclusión de palabras relacionadas semánticamente en una página.
- Frecuencia de palabras y frases en una página.
- La organización de los conceptos en una página.
- Incluir datos no estructurados, datos semiestructurados y datos estructurados en una página.
- Pares sujeto-predicado-objeto (SPO).
- Documentos web en un sitio que funcionan como páginas de un libro.
- Organización de documentos web en un sitio web.
- Incluya conceptos en un documento web que sean características conocidas de las entidades.
Nota importante: cuando el énfasis está en las relaciones entre entidades, a menudo se hace referencia a una base de conocimiento como gráfico de conocimiento.
Dado que la intención se analiza junto con los registros de búsqueda del usuario y otras partes del contexto, la misma frase de búsqueda de la persona 1 podría generar un resultado diferente de la persona 2. La persona podría tener una intención diferente con exactamente la misma consulta.
Si su página cubre ambos tipos de intención, entonces su página es una mejor candidata para la clasificación web. Puede usar la estructura de las bases de conocimiento para guiar sus plantillas de intención de consulta (como se mencionó en una sección anterior).
Las personas también preguntan, las personas buscan y la función Autocompletar están semánticamente relacionadas con la consulta enviada y profundizan en la dirección de búsqueda actual o pasan a un aspecto diferente de la tarea de búsqueda.
Lo sabemos, entonces, ¿cómo podemos optimizarlo?
Sus documentos deben contener tantas variaciones de intención de búsqueda como sea posible. Su sitio web debe contener todas las variaciones de intención de búsqueda para su grupo. La agrupación se basa en tres tipos de similitud:
- Similitud léxica.
- Similitud semántica.
- Haga clic en similitud.
Cobertura del tema
Qué es –> Lista de atributos –> Sección dedicada a cada atributo –> Cada sección enlaza con un artículo completamente dedicado a ese tema –> Se debe especificar la audiencia y se deben especificar las definiciones de la subsección –> Qué se debe considerar ? –> ¿Cuáles son los beneficios? –> Beneficios del modificador –> ¿Qué es ___ –> ¿Qué hace? –> Cómo conseguirlo –> Cómo hacerlo –> Quién puede hacerlo –> Enlace de regreso a todas las categorías

Google ofrece una herramienta que proporciona una puntuación de prominencia (similar a cómo usamos la palabra "fortaleza" o "confianza") que le dice cómo Google ve el contenido.

El ejemplo anterior proviene de un artículo de Search Engine Land sobre entidades de 2018.
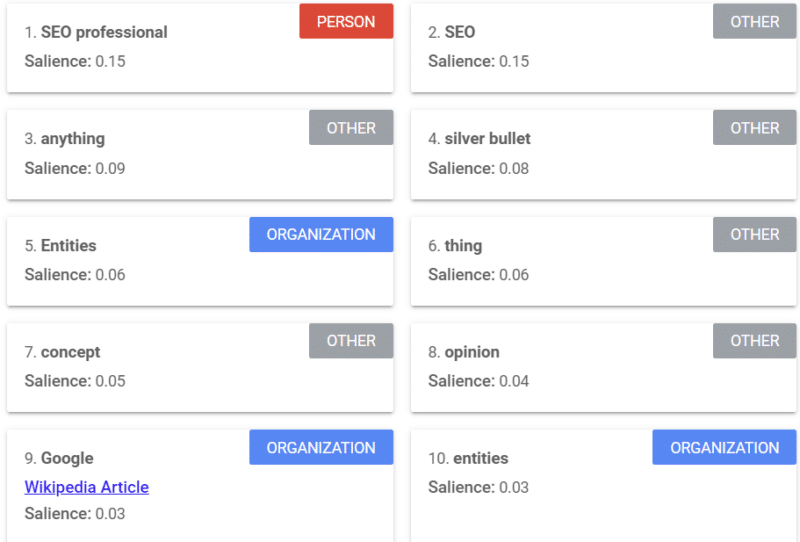
Puede ver personas, otros y organizaciones del ejemplo. La herramienta es la API de lenguaje natural de Google Cloud.
Cada palabra, oración y párrafo importa cuando se habla de una entidad. La forma en que organiza sus pensamientos puede cambiar la comprensión de Google de su contenido.
Puedes incluir una palabra clave sobre SEO, pero ¿Google entiende esa palabra clave de la forma en que quieres que se entienda?
Intente colocar uno o dos párrafos en la herramienta y reorganice y modifique el ejemplo para ver cómo aumenta o disminuye la prominencia.
Este ejercicio, llamado "desambiguación", es increíblemente importante para las entidades. El lenguaje es ambiguo, por lo que debemos hacer que nuestras palabras sean menos ambiguas para Google.
Los enfoques modernos de desambiguación consideran tres tipos de evidencia:
Importancia previa de entidades y menciones.
Similitud contextual entre el texto que rodea la mención y la entidad candidata y coherencia entre todas las decisiones de vinculación de entidades en el documento.
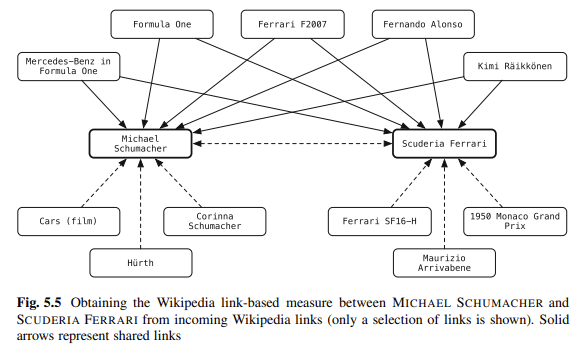
El esquema es una de mis formas favoritas de eliminar la ambigüedad del contenido. Está vinculando entidades en su blog a repositorios de conocimiento. Balog dice:
“[Vincular] entidades en texto no estructurado a un repositorio de conocimiento estructurado puede empoderar enormemente a los usuarios en sus actividades de consumo de información”.
Por ejemplo, los lectores de un documento pueden adquirir información contextual o de antecedentes con un solo clic, y pueden acceder fácilmente a las entidades relacionadas.
Las anotaciones de entidad también se pueden utilizar en el procesamiento posterior para mejorar el rendimiento de la recuperación o para facilitar una mejor interacción del usuario con los resultados de búsqueda.
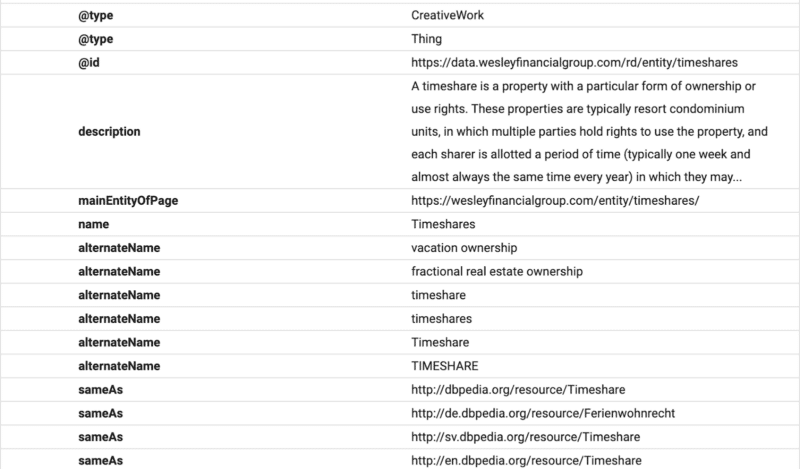
Aquí puede ver que el contenido de las preguntas frecuentes está estructurado para Google utilizando el esquema de preguntas frecuentes.
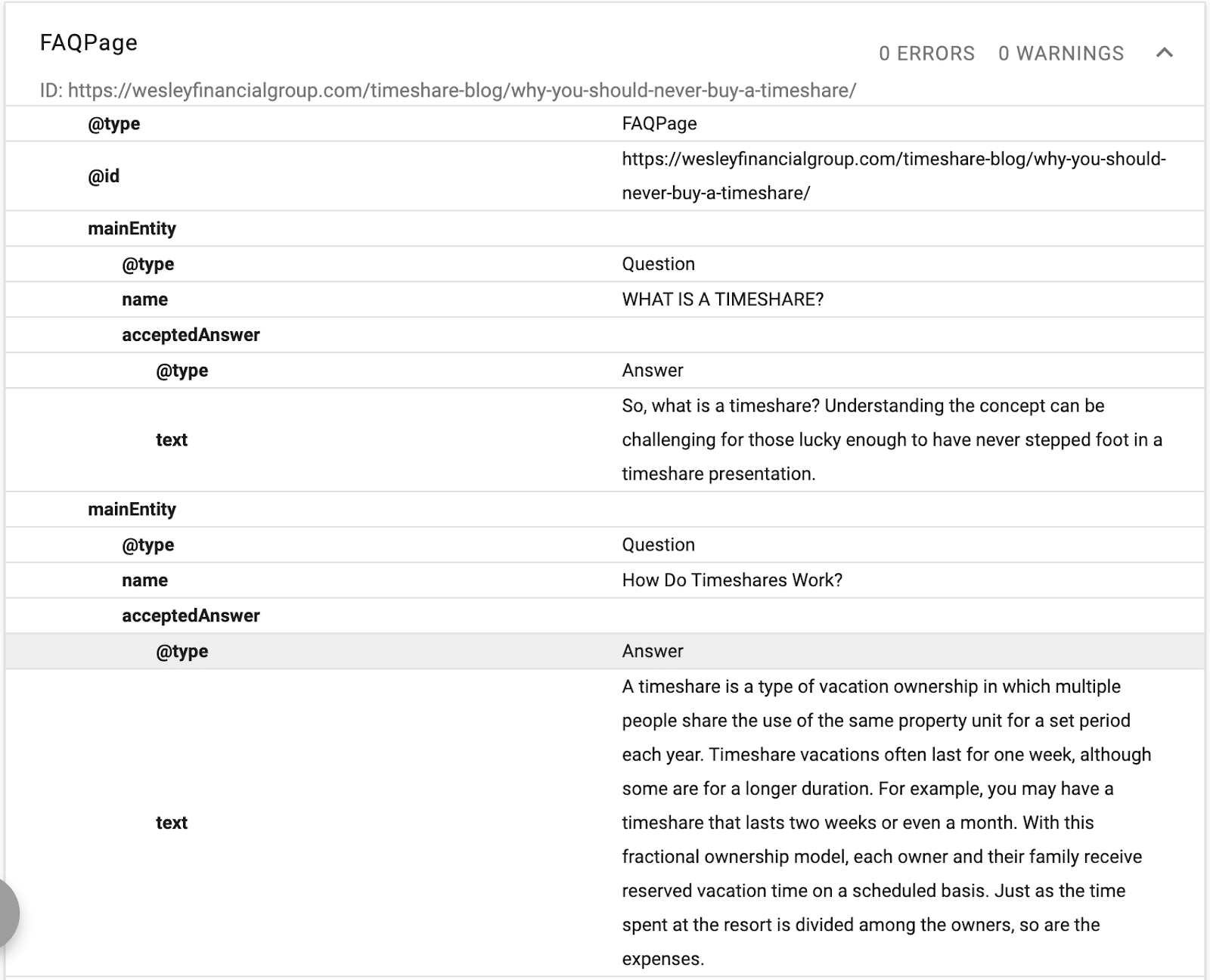
En este ejemplo, puede ver el esquema que proporciona una descripción del texto, una identificación y una declaración de la entidad principal de la página.
(Recuerde, Google quiere comprender la jerarquía del contenido, razón por la cual H1-H6 es importante).
Verá nombres alternativos y lo mismo que declaraciones. Ahora, cuando Google lea el contenido, sabrá qué base de datos estructurada asociar con el texto y tendrá sinónimos y versiones alternativas de una palabra vinculada a la entidad.
Cuando optimiza con esquema, optimiza para NER (reconocimiento de entidad con nombre), también conocido como identificación de entidad, extracción de entidad y fragmentación de entidad.
La idea es participar en Desambiguación de entidad nombrada> Wikificación> Vinculación de entidad.
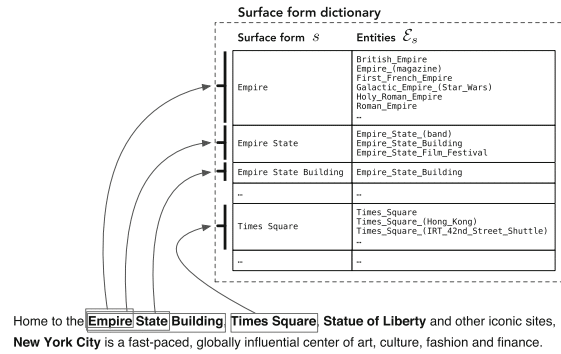
“La llegada de Wikipedia ha facilitado el reconocimiento y la eliminación de ambigüedades de entidades a gran escala al proporcionar un catálogo completo de entidades junto con otros recursos invaluables (específicamente, hipervínculos, categorías y páginas de redirección y eliminación de ambigüedades».
– Búsqueda orientada a entidades
Cómo ir más allá de las sugerencias de herramientas SEO
La mayoría de los SEO usan alguna herramienta en la página para optimizar su contenido. Cada herramienta tiene una capacidad limitada para identificar oportunidades de contenido únicas y sugerencias de profundidad de contenido.
En su mayor parte, las herramientas en la página solo agregan los mejores resultados SERP y crean un promedio para que los emules.
Los SEO deben recordar que Google no está buscando la misma información repetida. Puede copiar lo que otros están haciendo, pero la información única es la clave para convertirse en un sitio semilla/sitio de autoridad.
Aquí hay una descripción simplificada de cómo Google maneja el contenido nuevo:
Una vez que se ha encontrado que un documento menciona una entidad determinada, ese documento puede verificarse para posiblemente descubrir nuevos hechos con los que se pueda actualizar la entrada de la base de conocimiento de esa entidad.
Balog escribe:
“Deseamos ayudar a los editores a estar al tanto de los cambios al identificar automáticamente el contenido (artículos de noticias, publicaciones de blog, etc.) que pueden implicar modificaciones en las entradas de la base de conocimientos de un determinado conjunto de entidades de interés (es decir, entidades que un editor determinado responsable de)."
Cualquiera que mejore las bases de conocimiento, el reconocimiento de entidades y la rastreabilidad de la información obtendrá el amor de Google.
Los cambios realizados en el repositorio de conocimientos se pueden rastrear hasta el documento como fuente original.
Si proporciona contenido que cubre el tema y agrega un nivel de profundidad que es raro o nuevo, Google puede identificar si su documento agregó esa información única.
Eventualmente, esta nueva información sostenida durante un período de tiempo podría llevar a que su sitio web se convierta en una autoridad.
No se trata de una autoridad basada en la calificación del dominio, sino de una cobertura temática, que creo que es mucho más valiosa.
Con el enfoque de entidad para SEO, no está limitado a orientar palabras clave con volumen de búsqueda.
Todo lo que necesita hacer es validar el término principal ("cañas de pescar con mosca", por ejemplo), y luego puede concentrarse en orientar las variaciones de intención de búsqueda basadas en el pensamiento humano de buena moda.
Empezamos con Wikipedia. Para el ejemplo de la pesca con mosca, podemos ver que, como mínimo, los siguientes conceptos deben cubrirse en un sitio web de pesca:
- Especies de peces, historia, orígenes, desarrollo, mejoras tecnológicas, expansión, métodos de pesca con mosca, casting, spey casting, pesca de trucha con mosca, técnicas de pesca con mosca, pesca en agua fría, pesca de trucha con mosca seca, pesca de trucha con ninfa, aguas tranquilas pesca de truchas, jugar truchas, soltar truchas, pesca con mosca de agua salada, aparejos, moscas artificiales y nudos.
Los temas anteriores provienen de la página de Wikipedia de pesca con mosca. Si bien esta página proporciona una excelente descripción general de los temas, me gusta agregar ideas de temas adicionales que provienen de temas relacionados semánticamente.
Para el tema "pez", podemos agregar varios temas adicionales, incluida la etimología, la evolución, la anatomía y la fisiología, la comunicación de los peces, las enfermedades de los peces, la conservación y la importancia para los humanos.
¿Alguien ha relacionado la anatomía de la trucha con la efectividad de ciertas técnicas de pesca?
¿Ha cubierto un único sitio web de pesca todas las variedades de peces al tiempo que vincula los tipos de técnicas de pesca, cañas y cebos para cada pez?
A estas alturas, debería poder ver cómo puede crecer la expansión del tema. Tenga esto en cuenta cuando planifique una campaña de contenido.
No se limite a repetir. Añadir valor. Ser único. Utilice los algoritmos mencionados en este artículo como guía.
Conclusión
Este artículo forma parte de una serie de artículos centrados en las entidades. En el próximo artículo, profundizaré en los esfuerzos de optimización en torno a las entidades y algunas herramientas centradas en entidades en el mercado.
Quiero terminar este artículo saludando a dos personas que me explicaron muchos de estos conceptos.
Bill Slawski de SEO by the Sea y Koray Tugbert de Holistic SEO. Si bien Slawski ya no está con nosotros, sus contribuciones continúan teniendo un efecto dominó en la industria del SEO.
Confío en gran medida en las siguientes fuentes para el contenido del artículo, ya que estas fuentes son los mejores recursos que existen sobre el tema:
- Jerarquía de entidad nombrada extendida por Satoshi Ketine, Kiyoshi Sudo y Chikashi Nobata
- Búsqueda orientada a entidades por Krisztian Balog , Serie de recuperación de información (INRE, volumen 39)
- Reescritura de consultas con detección de entidades , patente de Google
- Refinación de consultas de búsqueda , patente de Google
- Asociación de una entidad con una consulta de búsqueda , patente de Google
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.