
¿Cómo puede Apache Spark dar alas a la analítica de las aerolíneas?
Publicado: 2015-10-30La industria global de las aerolíneas continúa creciendo rápidamente, pero aún no se ha visto una rentabilidad consistente y sólida. Según la Asociación Internacional de Transporte Aéreo (IATA), la industria ha duplicado sus ingresos durante la última década, de 369 000 millones de USD en 2005 a 727 000 millones de USD en 2015.

En el sector de la aviación comercial, todos los actores de la cadena de valor (aeropuertos, fabricantes de aviones, fabricantes de motores a reacción, agencias de viajes y empresas de servicios) obtienen una buena ganancia.
Todos estos jugadores generan individualmente volúmenes extremadamente altos de datos debido a una mayor rotación de transacciones de vuelos. Identificar y capturar la demanda es la clave aquí, lo que brinda una oportunidad mucho mayor para que las aerolíneas se diferencien. Por lo tanto, las industrias de la aviación pueden utilizar conocimientos de big data para aumentar sus ventas y mejorar el margen de ganancias.
Big data es un término para la recopilación de conjuntos de datos tan grandes y complejos que su computación no puede ser manejada por los sistemas tradicionales de procesamiento de datos o las herramientas DBMS disponibles.
Apache Spark es un marco informático de clúster distribuido de código abierto diseñado específicamente para consultas interactivas y algoritmos iterativos.
La abstracción de Spark DataFrame es un objeto de datos tabulares similar al marco de datos nativo de R o al paquete pandas de Python, pero almacenado en el entorno del clúster.
Según la última encuesta de Fortunes, Apache Spark es la tecnología más popular de 2015.
El mayor proveedor de Hadoop, Cloudera, también dice adiós a Hadoops MapReduce y hola a Spark.
Lo que realmente le da a Spark la ventaja sobre Hadoop es la velocidad . Spark maneja la mayoría de sus operaciones en la memoria , copiándolas del almacenamiento físico distribuido a una memoria RAM lógica mucho más rápida. Esto reduce la cantidad de tiempo consumido en la escritura y la lectura desde y hacia discos duros mecánicos lentos y torpes que deben realizarse con el sistema Hadoops MapReduce.
Además, Spark incluye herramientas (procesamiento en tiempo real, aprendizaje automático y SQL interactivo) que están bien diseñadas para impulsar objetivos comerciales como el análisis de datos en tiempo real mediante la combinación de datos históricos de dispositivos conectados, también conocido como Internet de las cosas .
Hoy, recopilemos información sobre datos de aeropuertos de muestra con Apache Spark .
En el blog anterior vimos cómo manejar datos estructurados y semiestructurados en Spark usando la nueva API de marcos de datos y también cubrimos cómo procesar datos JSON de manera eficiente.
En este blog, comprenderemos cómo consultar datos en DataFrames usando SQL y cómo guardar la salida en el sistema de archivos en formato CSV.
Uso de la biblioteca de análisis CSV de Databricks
Para esto, voy a usar una biblioteca de análisis CSV proporcionada por Databricks, una empresa fundada por Creators of Apache Spark y que actualmente maneja el desarrollo y las distribuciones de Spark.
La comunidad de Spark consta de aproximadamente 600 colaboradores que lo convierten en el proyecto más activo de toda la Apache Software Foundation, un importante organismo rector del software de código abierto, en términos de número de colaboradores.
La biblioteca Spark-csv nos ayuda a analizar y consultar datos csv en Spark. Podemos usar esta biblioteca tanto para leer como para escribir datos csv hacia y desde cualquier sistema de archivos compatible con Hadoop.
Cargando los datos en Spark DataFrames
Carguemos nuestros archivos de entrada en Spark DataFrames mediante la biblioteca de análisis spark-csv de Databricks.
Puede usar esta biblioteca en el shell de Spark especificando –packages com.databricks: spark-csv_2.10:1.0.3
Al iniciar el shell como se muestra a continuación:
$ bin/spark-shell –paquetes com.databricks:spark-csv_2.10:1.0.3
Recuerde que debe estar conectado a Internet, porque el paquete spark-csv se descargará automáticamente cuando dé este comando. estoy usando la versión spark 1.4.0
Vamos a crear sqlContext con el objeto SparkContext(sc) ya creado
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Ahora carguemos nuestros datos csv del archivo airports.csv (airport csv github) cuyo esquema es el siguiente
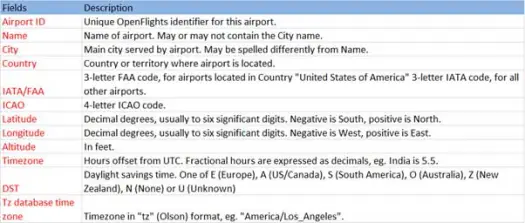
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))La operación de carga analizará el archivo *.csv mediante la biblioteca Spark-csv de Databricks y devolverá un marco de datos con los mismos nombres de columna que en la primera línea de encabezado del archivo.
Los siguientes son los parámetros pasados al método de carga.
- Fuente : "com.databricks.spark.csv" le dice a chispa que queremos cargar como archivo csv.
- Opciones:
- ruta : ruta del archivo, donde se encuentra.
- Encabezado : "encabezado" -> "verdadero" le dice a Spark que asigne la primera línea del archivo a los nombres de columna para el marco de datos resultante.
Veamos cuál es el esquema de nuestro Dataframe
Echa un vistazo a los datos de muestra en nuestro marco de datos
scala> airportDF.show


Consulta de datos CSV mediante tablas temporales:
Para ejecutar una consulta en una tabla, llamamos al método sql() en SQLContext.
Hemos creado el DataFrame de aeropuertos y cargado datos CSV, para consultar estos datos DF tenemos que registrarlos como una tabla temporal llamada aeropuertos.
>
scala> airportDF.registerTempTable("airports")
Averigüemos cuántos aeropuertos hay en la parte sureste en nuestro conjunto de datos
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Podemos hacer agregaciones en consultas sql en Spark
Descubriremos cuántas ciudades únicas tienen aeropuertos en cada país
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
¿Cuál es la altitud media (en pies) de los aeropuertos de cada país?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
¿Ahora para saber en cada zona horaria cuántos aeropuertos están operando?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
También podemos calcular la latitud y longitud promedio para estos aeropuertos en cada país
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Contemos cuántos DST diferentes hay
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Guardar datos en formato CSV
Hasta ahora cargamos y consultamos datos csv. Ahora veremos cómo guardar los resultados en formato CSV en el sistema de archivos.
Supongamos que queremos enviar un informe al cliente sobre todos los aeropuertos en la parte noroeste de todos los países.
Calculemos eso primero.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
Y guárdelo en un archivo CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Los siguientes son los parámetros pasados al método save.
- Fuente : es lo mismo que el método de carga com.databricks.spark.csv que le dice a Spark que guarde los datos como csv.
- SaveMode : esto permite al usuario especificar de antemano lo que se debe hacer si la ruta de salida dada ya existe. Para que los datos existentes no se pierdan/sobrescriban por error. Puede arrojar error, agregar o sobrescribir. Aquí, lanzamos un error ErrorIfExists porque no queremos sobrescribir ningún archivo existente.
- Opciones : estas opciones son las mismas que pasamos al método de carga . Opciones:
- ruta : ruta del archivo, donde debe almacenarse.
- Encabezado : "encabezado" -> "verdadero" le dice a Spark que asigne los nombres de las columnas del marco de datos a la primera línea del archivo de salida resultante.
Conversión de otros formatos de datos a CSV
También podemos convertir cualquier otro formato de datos como JSON, parquet, texto a CSV usando esta biblioteca.
En el blog anterior habíamos creado datos json. puedes encontrarlo en github
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
vamos a guardarlo como CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Conclusión:
En esta publicación recopilamos información sobre los datos de los aeropuertos mediante consultas interactivas de SparkSQL.
y exploré la biblioteca de análisis csv de Spark
En el próximo blog exploraremos un componente muy importante de Spark, es decir, Spark Streaming.
Spark Streaming permite a los usuarios recopilar datos en tiempo real en Spark y procesarlos a medida que ocurren y brinda resultados al instante.