
Cómo usar entidades de Google y GPT-4 para crear esquemas de artículos
Publicado: 2023-06-06En este artículo, aprenderá cómo usar algunos raspados y el Gráfico de conocimiento de Google para realizar una ingeniería de solicitud automática que genere un esquema y un resumen para un artículo que, si está bien escrito, contendrá muchos ingredientes clave para una buena clasificación.
Básicamente, le estamos diciendo a GPT-4 que produzca un esquema de artículo basado en una palabra clave y las principales entidades que han encontrado en una página bien clasificada de su elección.
Las entidades están ordenadas por su puntuación de prominencia.
“¿Por qué puntuación de prominencia?” podrías preguntar.
Google describe la prominencia en sus documentos API como:
“La puntuación de prominencia de una entidad proporciona información sobre la importancia o centralidad de esa entidad para todo el texto del documento. Las puntuaciones cercanas a 0 son menos destacadas, mientras que las puntuaciones cercanas a 1,0 son muy destacadas”.
Parece una métrica bastante buena para usar para influir en qué entidades deberían existir en un contenido que quizás desee escribir, ¿no es así?
Empezando
Hay dos formas de hacerlo:
- Dedique unos 5 minutos (quizás 10 si necesita configurar su computadora) y ejecute los scripts desde su máquina, o...
- Salta al Colab que creé y comienza a jugar de inmediato.
Soy partidario del primero, pero también he saltado a un Colab o dos en mi día. 😀
Suponiendo que todavía está aquí y desea configurar esto en su propia máquina, pero aún no tiene Python instalado o un IDE (Entorno de desarrollo integrado), lo dirigiré primero a una lectura rápida sobre cómo configurar su máquina para usar Cuaderno Jupyter. No debería llevar más de unos 5 minutos.
Ahora, ¡es hora de ponerse en marcha!
Uso de entidades de Google y GPT-4 para crear esquemas de artículos
Para que sea fácil de seguir, voy a formatear las instrucciones de la siguiente manera:
- Paso : Una breve descripción del paso en el que estamos.
- Código : El código para completar ese paso.
- Explicación : una breve explicación de lo que está haciendo el código.
Paso 1: Dime lo que quieres
Antes de sumergirnos en la creación de los contornos, debemos definir lo que queremos.
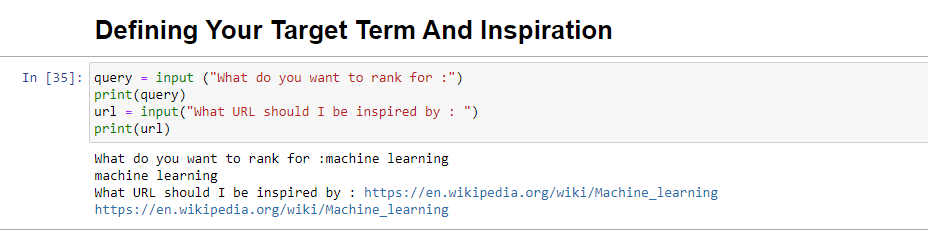
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)Cuando se ejecuta, este bloque le pedirá al usuario (probablemente a usted) que ingrese la consulta para la que le gustaría que se clasifique el artículo, así como también le dará un lugar para colocar la URL de un artículo que le gustaría que su pieza en la que inspirarse.
Sugeriría un artículo que se clasifique bien, que esté en un formato que funcione para su sitio y que crea que merece la clasificación solo por el valor del artículo y no solo por la solidez del sitio.
Cuando se ejecute, se verá así:
Paso 2: Instalación de las bibliotecas necesarias
A continuación, debemos instalar todas las bibliotecas que usaremos para que la magia suceda.
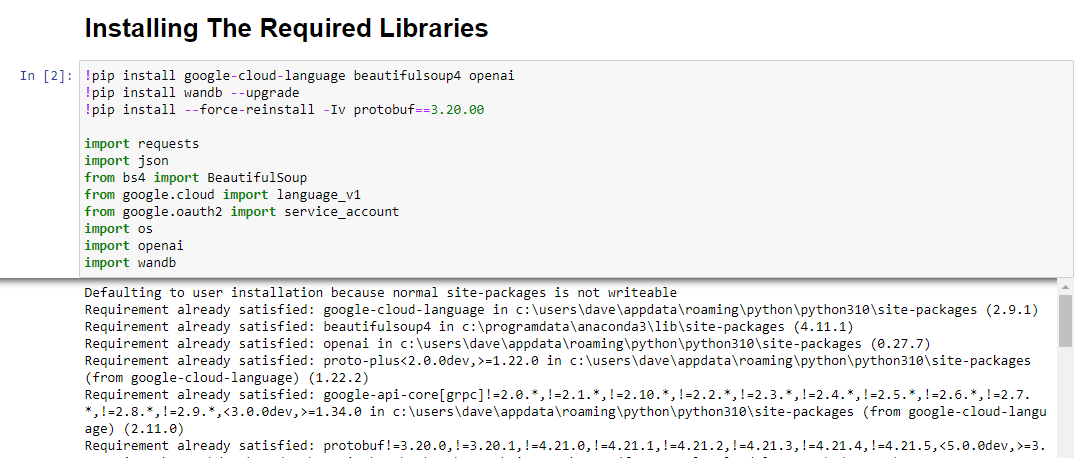
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandbEstamos instalando las siguientes bibliotecas:
- Solicitudes : esta biblioteca permite realizar solicitudes HTTP para recuperar contenido de sitios web o API web.
- JSON : proporciona funciones para trabajar con datos JSON, incluido el análisis de cadenas JSON en objetos de Python y la serialización de objetos de Python en cadenas JSON.
- BeautifulSoup : esta biblioteca se utiliza para fines de web scraping. Ayuda a analizar y navegar documentos HTML o XML y extraer información relevante de ellos.
- Google.cloud.language_v1 : es una biblioteca de Google Cloud que proporciona capacidades de procesamiento de lenguaje natural. Permite realizar diversas tareas como análisis de sentimientos, reconocimiento de entidades y análisis de sintaxis en datos de texto.
- Google.oauth2.service_account : esta biblioteca forma parte del paquete Google OAuth2 Python. Brinda soporte para la autenticación con las API de Google mediante una cuenta de servicio, que es una forma de otorgar acceso limitado a los recursos de un proyecto de Google Cloud.
- OS : esta biblioteca proporciona una forma de interactuar con el sistema operativo. Permite acceder a varias funcionalidades como operaciones de archivos, variables de entorno y gestión de procesos.
- OpenAI : esta biblioteca es el paquete OpenAI Python. Proporciona una interfaz para interactuar con los modelos de lenguaje de OpenAI, incluidos GPT-4 (y 3). Permite a los desarrolladores generar texto, completar texto y más.
- Pandas : Es una poderosa biblioteca para la manipulación y análisis de datos. Proporciona estructuras de datos y funciones para manejar y analizar eficientemente datos estructurados, como tablas o archivos CSV.
- WandB : esta biblioteca significa "Pesos y sesgos" y es una herramienta para el seguimiento y la visualización de experimentos. Ayuda a registrar y visualizar las métricas, los hiperparámetros y otros aspectos importantes de los experimentos de aprendizaje automático.
Cuando se ejecuta, se ve así:
Obtenga el boletín informativo diario en el que confían los especialistas en marketing.
Ver términos.
Paso 3: Autenticación
Voy a tener que desviarnos por un momento para salir y poner nuestra autenticación en su lugar. Necesitaremos una clave API de OpenAI y credenciales de Google Knowledge Graph Search.
Esto solo tomará unos minutos.
Obtener su API de OpenAI
En la actualidad, es probable que deba unirse a la lista de espera. Tengo la suerte de tener acceso temprano a la API, por lo que escribo esto para ayudarlo a configurarlo tan pronto como lo obtenga.
Las imágenes de registro son de GPT-3 y se actualizarán para GPT-4 una vez que el flujo esté disponible para todos.
Antes de poder usar GPT-4, necesitará una clave de API para acceder a ella.
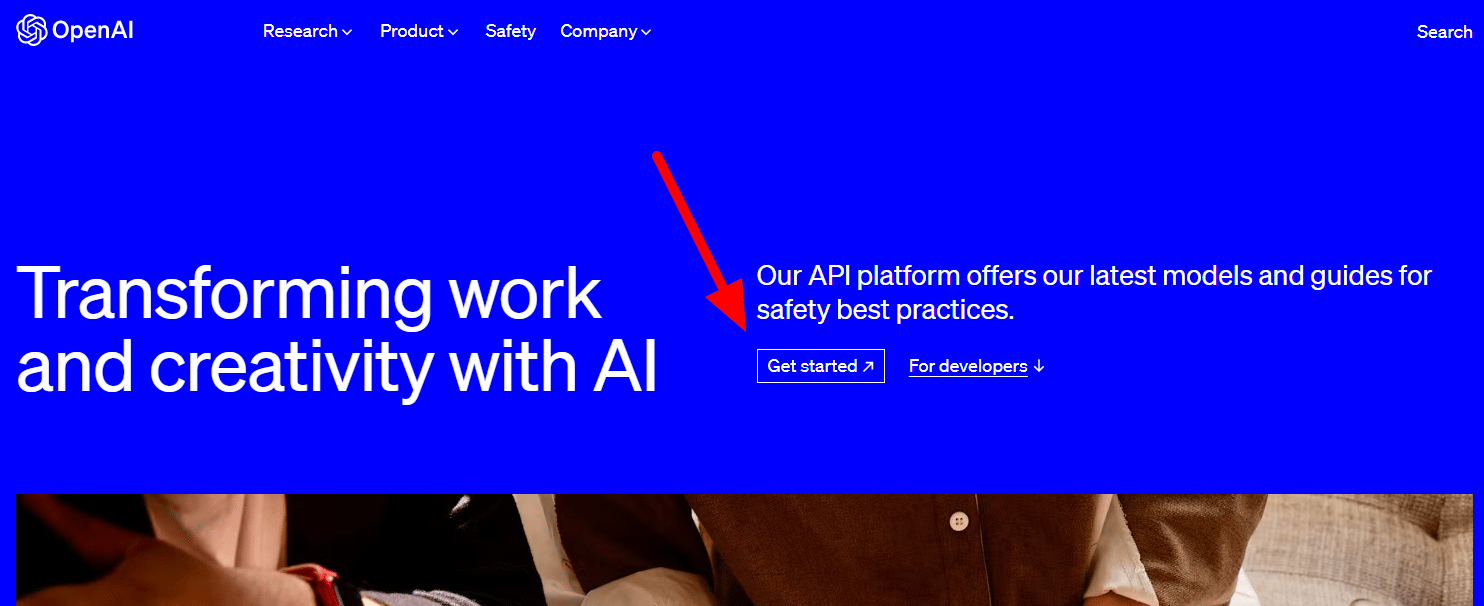
Para obtener uno, simplemente diríjase a la página del producto de OpenAI y haga clic en Comenzar .
Elija su método de registro (elegí Google) y ejecute el proceso de verificación. Necesitará acceso a un teléfono que pueda recibir mensajes de texto para este paso.
Una vez que esté completo, creará una clave de API. Esto es para que OpenAI pueda conectar sus scripts a su cuenta.
Deben saber quién está haciendo qué y determinar si deben cobrarle por lo que está haciendo y cuánto.
Precios de OpenAI
Al registrarse, obtiene un crédito de $ 5 que lo llevará sorprendentemente lejos si solo está experimentando.
A partir de este escrito, el precio pasado es:

Creando tu clave OpenAI
Para crear su clave, haga clic en su perfil en la parte superior derecha y elija Ver claves API .
... y luego creará su clave.
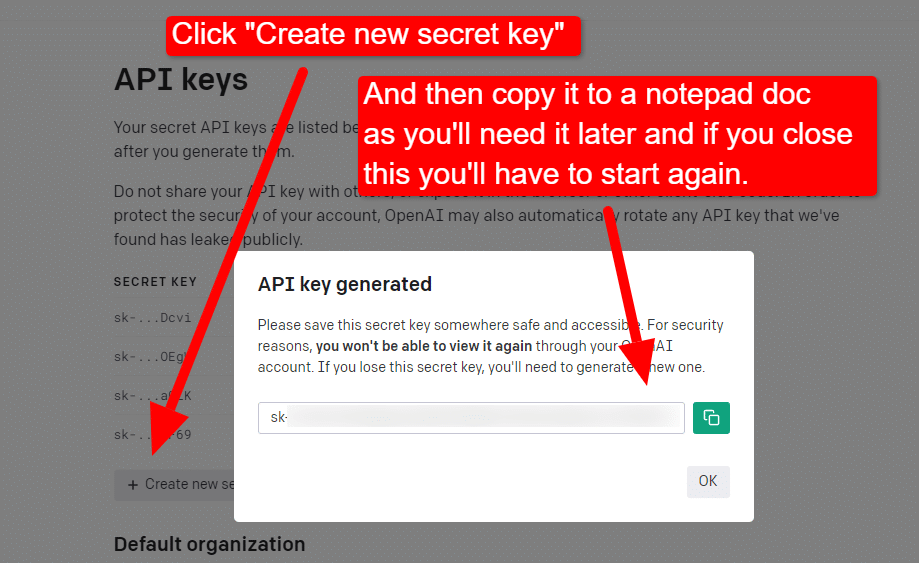
Una vez que cierre el cuadro de luz, no podrá ver su clave y tendrá que volver a crearla, por lo que para este proyecto, simplemente cópielo en un documento del Bloc de notas para usarlo en breve.
Nota: no guarde su clave (un documento de Bloc de notas en su escritorio no es muy seguro). Una vez que lo haya usado momentáneamente, cierre el documento del Bloc de notas sin guardarlo.
Obtener su autenticación de Google Cloud
Primero, deberá iniciar sesión en su cuenta de Google. (Estás en un sitio de SEO, así que asumo que tienes uno. 🙂)
Una vez que haya hecho eso, puede revisar la información de la API de Knowledge Graph si se siente tan inclinado o saltar directamente a la Consola API y comenzar.
Una vez que estés en la consola:
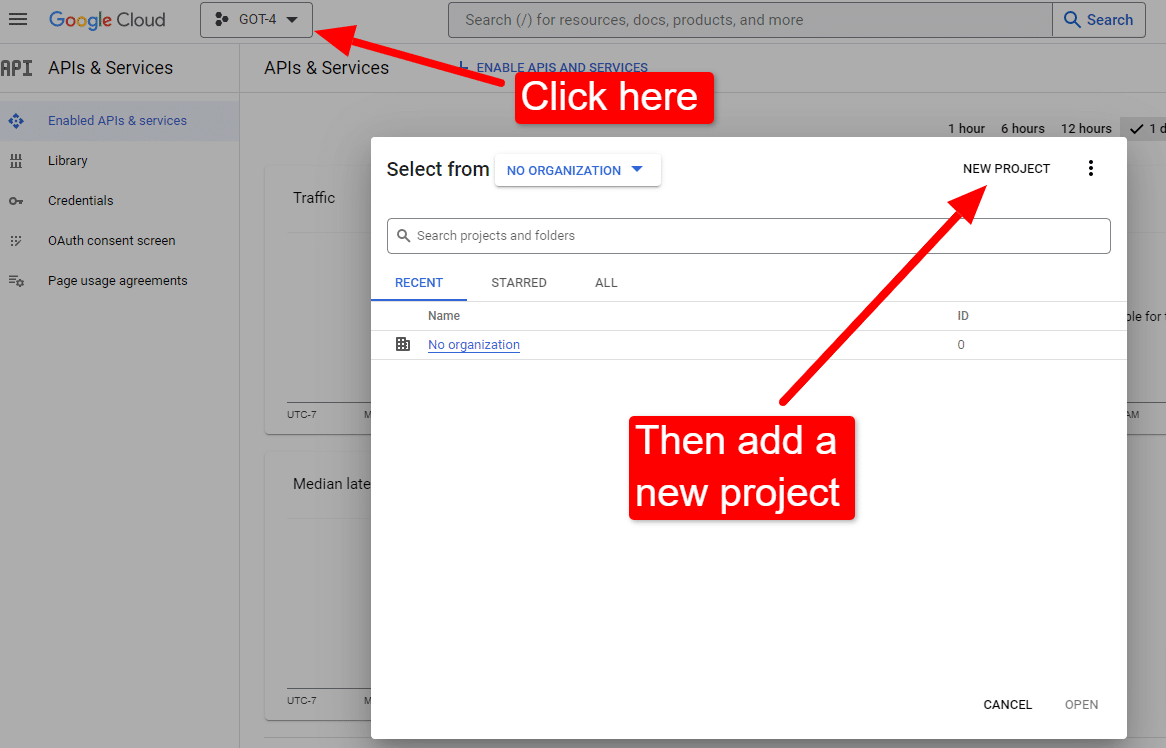
Nómbrelo como "Artículos impresionantes de Dave". Ya sabes… fácil de recordar.
A continuación, habilitará la API haciendo clic en Habilitar API y servicios .
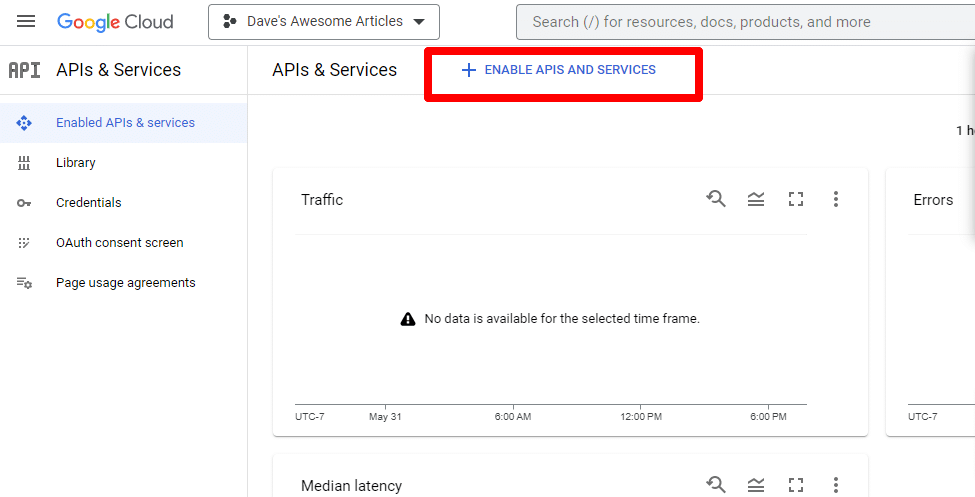
Busque la API de búsqueda de Knowledge Graph y habilítela.

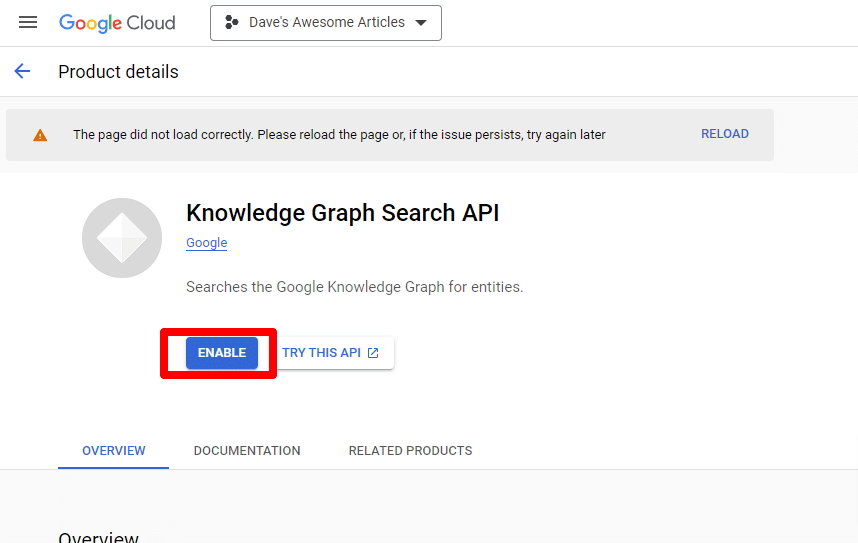
Luego volverá a la página principal de la API, donde puede crear credenciales:
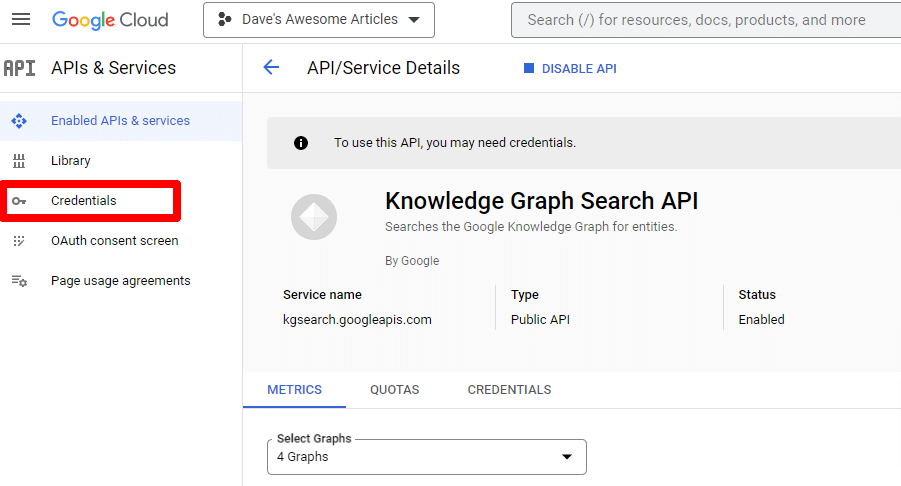
Y crearemos una cuenta de servicio.
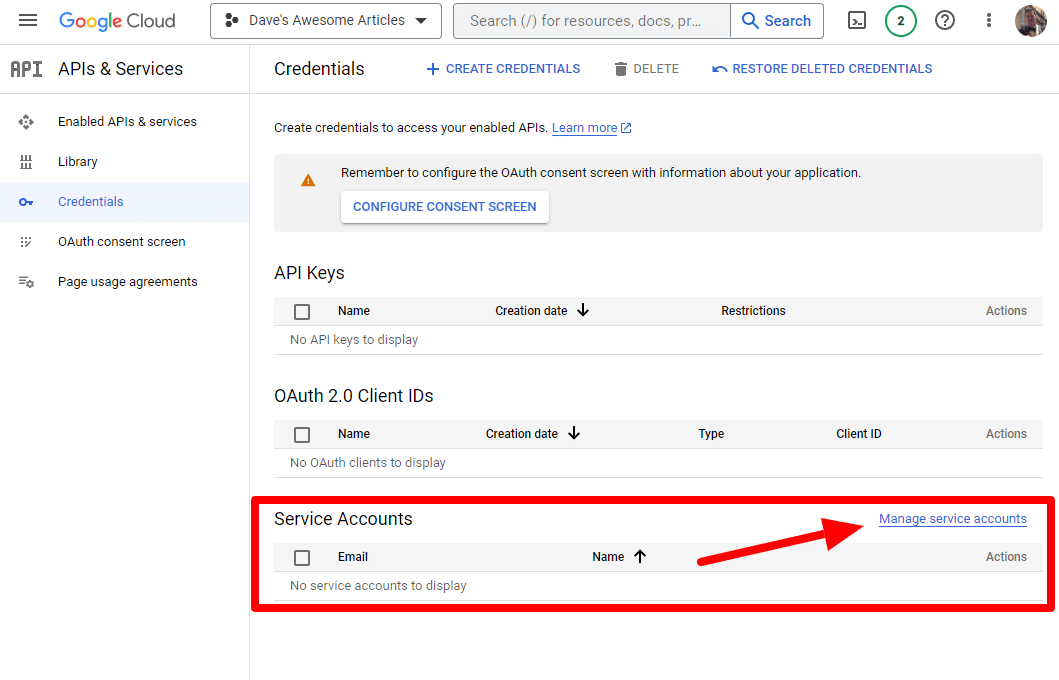
Simplemente cree una cuenta de servicio:
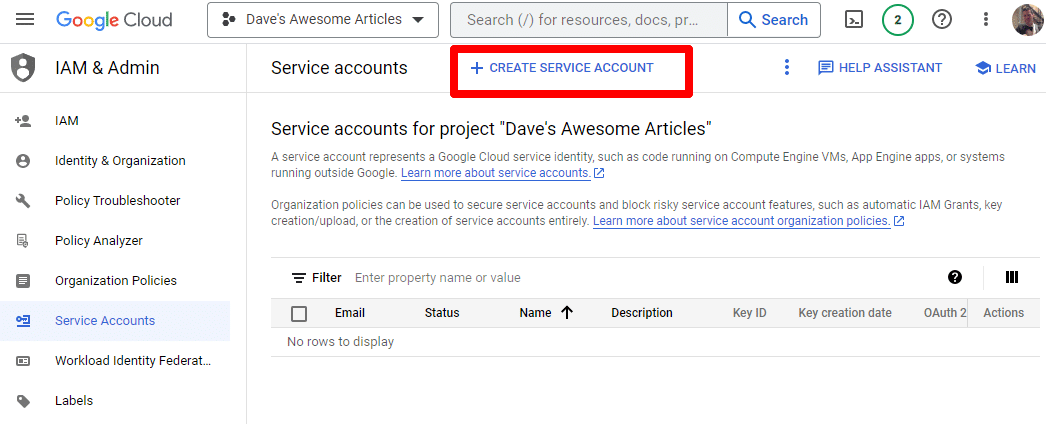
Complete la información requerida:
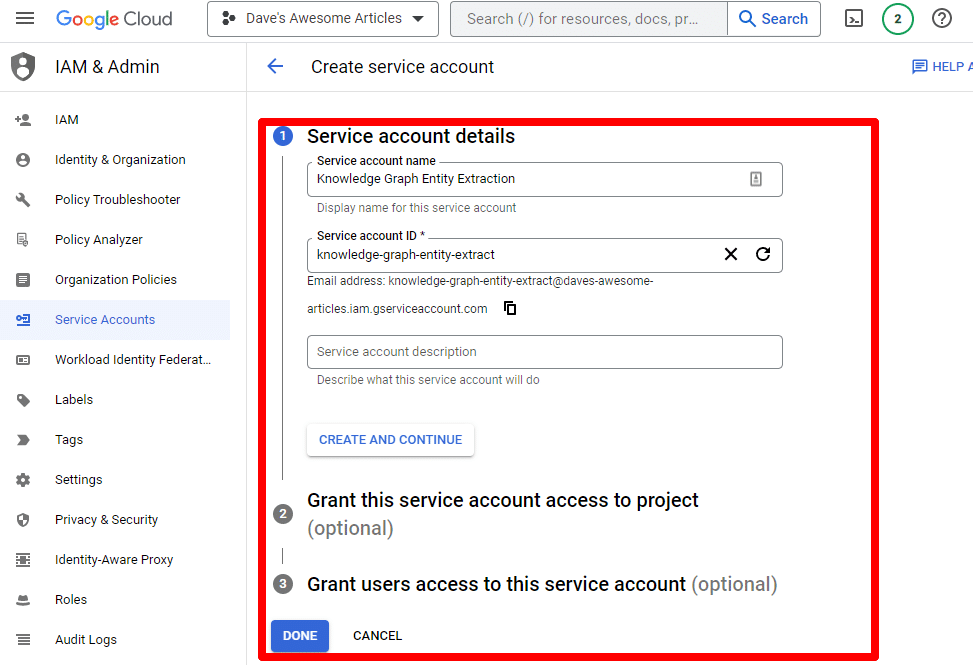
(Deberá darle un nombre y otorgarle privilegios de propietario).
Ahora tenemos nuestra cuenta de servicio. Todo lo que queda es crear nuestra clave.
Haga clic en los tres puntos debajo de Acciones y haga clic en Administrar claves .
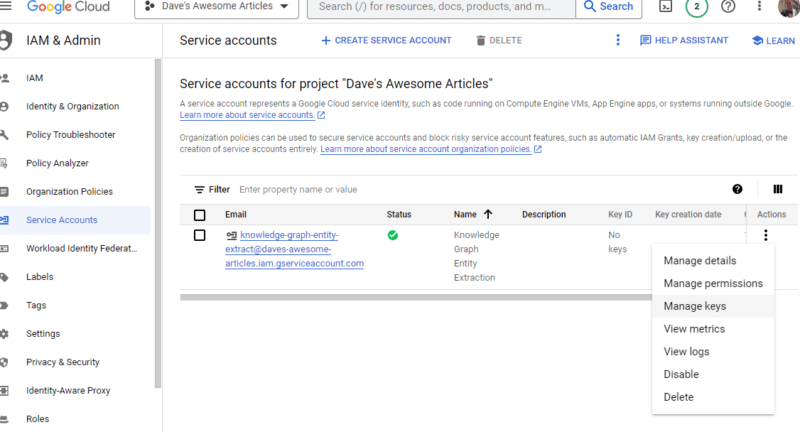
Haga clic en Agregar clave y luego en Crear nueva clave :
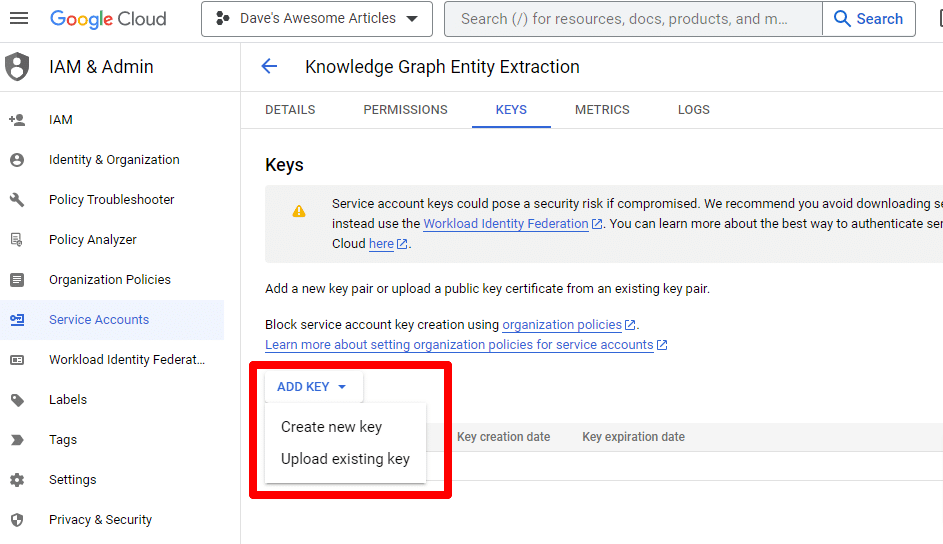
El tipo de clave será JSON.
Inmediatamente, verá que se descarga en su ubicación de descarga predeterminada.
Esta clave le dará acceso a sus API, así que manténgala segura, al igual que su API de OpenAI.
Muy bien... y estamos de vuelta. ¿Listo para continuar con nuestro guión?
Ahora que los tenemos, debemos definir nuestra clave API y la ruta al archivo descargado. El código para hacer esto es:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") Reemplazará YOUR_OPENAI_API_KEY con su propia clave.
También reemplazará /PATH-TO-FILE/FILENAME.JSON con la ruta a la clave de la cuenta de servicio que acaba de descargar, incluido el nombre del archivo.
Ejecute la celda y estará listo para continuar.
Paso 4: Crea las funciones
A continuación, crearemos las funciones para:
- Raspe la página web que ingresamos arriba.
- Analizar el contenido y extraer las entidades.
- Genere un artículo utilizando GPT-4.
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()Esto es más o menos exactamente lo que describen los comentarios. Estamos creando tres funciones para los propósitos descritos anteriormente.
Los ojos entusiastas notarán:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, Puede editar el contenido ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) y describa el rol que desea que asuma ChatGPT. También puede agregar tono (p. ej., “Eres un escritor amistoso…”).
Paso 5: Raspe la URL e imprima las entidades
Ahora nos estamos ensuciando las manos. Es tiempo de:
- Raspe la URL que ingresamos arriba.
- Extraiga todo el contenido que vive dentro de las etiquetas de párrafo.
- Ejecútelo a través de Google Knowledge Graph API.
- Salida de las entidades para una vista previa rápida.
Básicamente, quieres ver cualquier cosa en esta etapa. Si no ve nada, busque en otro sitio.
content = scrape_url(url) entities = analyze_content(content)Puede ver que la línea uno llama a la función que extrae la URL que ingresamos primero. La segunda línea analiza el contenido para extraer las entidades y métricas clave.
Parte de la función de análisis_contenido también imprime una lista de las entidades encontradas para una referencia y verificación rápidas.
Paso 6: Analizar las entidades
Cuando comencé a jugar con el guión, comencé con 20 entidades y rápidamente descubrí que por lo general son demasiadas. Pero, ¿el valor predeterminado (10) es correcto?
Para averiguarlo, escribiremos los datos en W&B Tables para facilitar la evaluación. Mantendrá los datos indefinidamente para futuras evaluaciones.
Primero, necesitarás unos 30 segundos para registrarte. (¡No se preocupe, es gratis para este tipo de cosas!) Puede hacerlo en https://wandb.ai/site.
Una vez que hayas hecho eso, el código para hacer esto es:
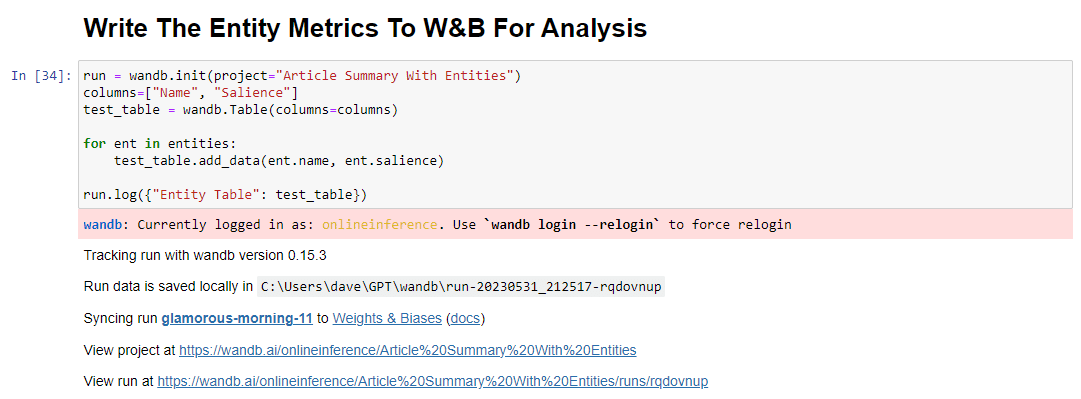
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()Cuando se ejecuta, la salida se ve así:
Y cuando hagas clic en el enlace para ver tu carrera, encontrarás:
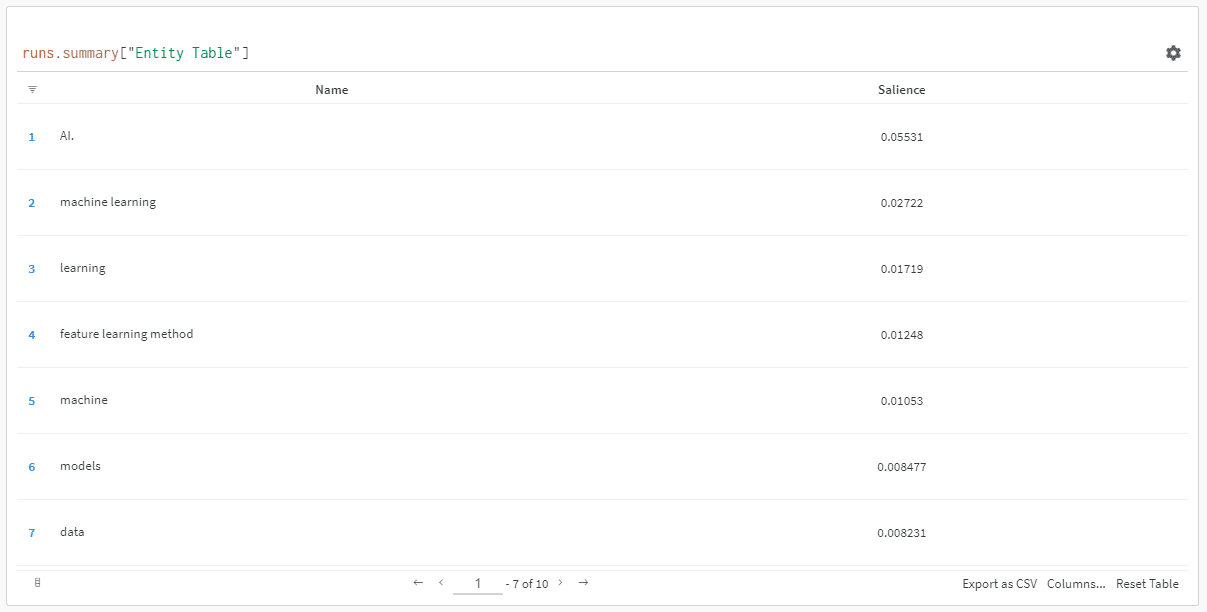
Puede ver una caída en la puntuación de prominencia. Recuerde que esta puntuación calcula la importancia de ese término para la página, no para la consulta.
Al revisar estos datos, puede optar por ajustar la cantidad de entidades en función de la prominencia, o simplemente cuando vea aparecer términos irrelevantes.
Para ajustar el número de entidades, dirígete a la celda de funciones y edita:
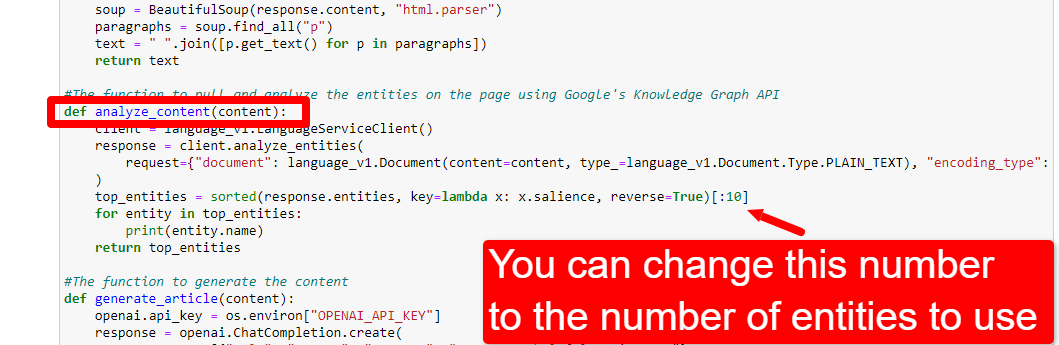
Luego deberá ejecutar la celda nuevamente y la que ejecutó para raspar y analizar el contenido para usar el nuevo recuento de entidades.
Paso 7: generar el esquema del artículo
El momento que todos han estado esperando, es el momento de generar el esquema del artículo.
Esto se hace en dos partes. Primero, necesitamos generar el indicador agregando la celda:
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)Básicamente, esto crea un aviso para generar un artículo:

Y luego, todo lo que queda es generar el esquema del artículo usando lo siguiente:
generated_article = generate_article(gpt_prompt) print(generated_article)Lo que producirá algo como:
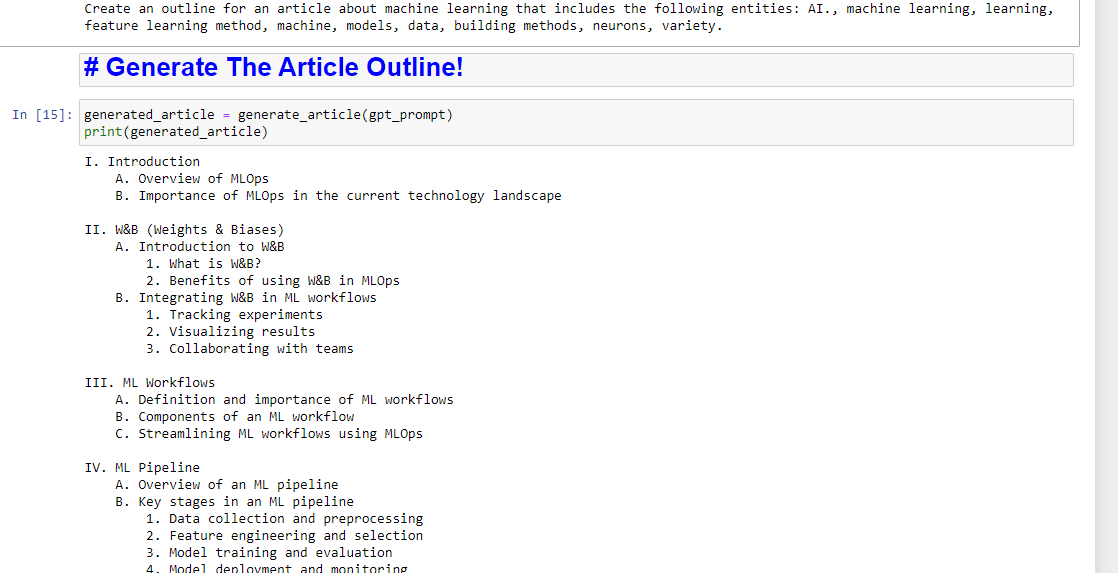
Y si también desea obtener un resumen por escrito, puede agregar:
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)Lo que producirá algo como:
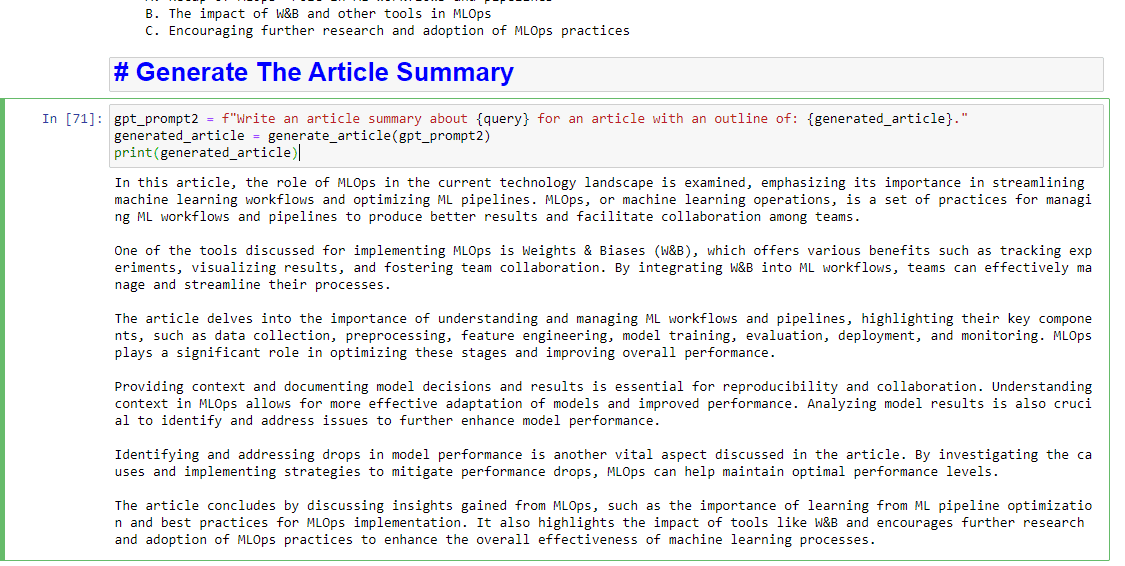
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.