
Cómo Google puede identificar y evaluar a los autores a través de la EEAT
Publicado: 2023-04-17Google está dando más importancia a la fuente del contenido, específicamente al autor, al clasificar los resultados de búsqueda. La introducción de Perspectivas, Acerca de este resultado y Acerca de este autor en las SERP deja esto claro.
Este artículo explora cómo Google puede potencialmente evaluar piezas de contenido a través de la experiencia, pericia, autoridad y confiabilidad (EEAT) de sus autores.
EEAT: la ofensiva de calidad de Google
Google ha destacado la importancia del concepto EEAT para mejorar la calidad de los resultados de búsqueda y la experiencia del usuario en SERP.
Los factores en la página, como la calidad general del contenido, las señales de enlace (es decir, PageRank y textos de anclaje) y las señales a nivel de entidad, juegan un papel vital.
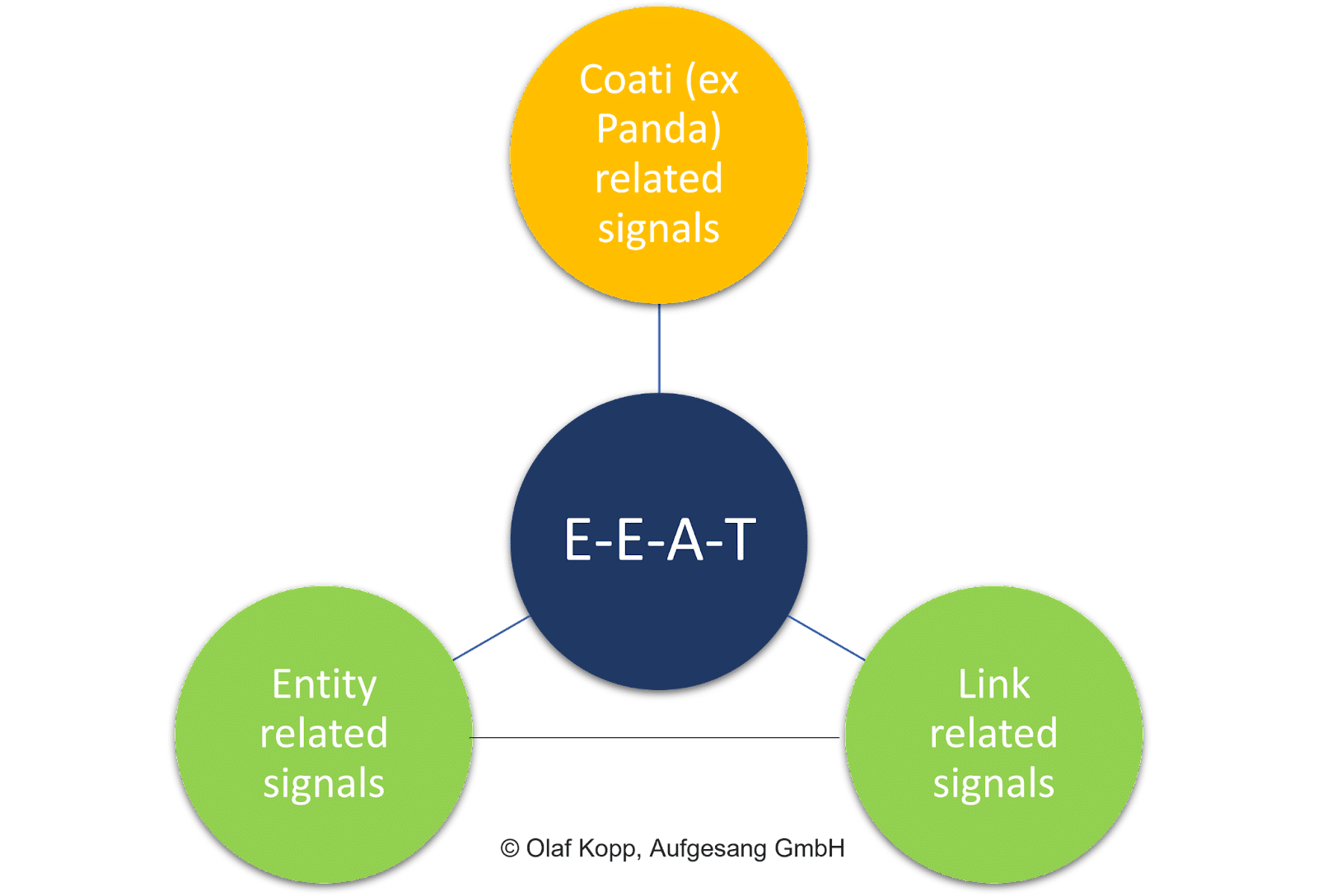
A diferencia de la calificación de documentos, la evaluación del contenido individual no es el enfoque de la EEAT.
El concepto tiene una referencia temática relacionada con el dominio y la entidad originadora. Es independiente de la intención de búsqueda y del contenido individual en sí.
En última instancia, EEAT es un factor de influencia independiente de las consultas de búsqueda.
EEAT se refiere principalmente a áreas temáticas y se entiende como una capa de evaluación que evalúa colecciones de contenido y señales fuera de página en relación con entidades como empresas, organizaciones, personas y sus dominios.
La importancia del autor como fuente de contenido
Mucho antes de (E-)EAT, Google intentó incluir la calificación de las fuentes de contenido en las clasificaciones de búsqueda. Por ejemplo, la actualización de Vince de 2009 le dio al contenido creado por la marca una ventaja en la clasificación.
A través de proyectos como Knol o Google+, que terminaron hace mucho tiempo, Google ha tratado de recopilar señales para las calificaciones de los autores (es decir, a través de un gráfico social y las calificaciones de los usuarios).
En los últimos 20 años, varias patentes de Google se han referido directa o indirectamente a plataformas de contenido como Knol y redes sociales como Google+.
Evaluar el origen o el autor de una pieza de contenido de acuerdo con los criterios de la EEAT es un paso crucial para desarrollar aún más la calidad de los resultados de búsqueda.
Con la abundancia de contenido generado por IA y spam clásico, no tiene sentido que Google incluya contenido inferior en el índice de búsqueda.
Cuanto más contenido indexe y tenga que procesar durante la recuperación de información, más potencia informática se necesitará.
EEAT puede ayudar a clasificar a Google según la entidad, el dominio y el nivel de autor aplicado en una escala más amplia sin tener que rastrear cada contenido.
En este nivel macro, el contenido se puede clasificar según la entidad de origen y asignarse con más o menos presupuesto de rastreo. Google también puede usar este método para excluir grupos de contenido completos de la indexación.
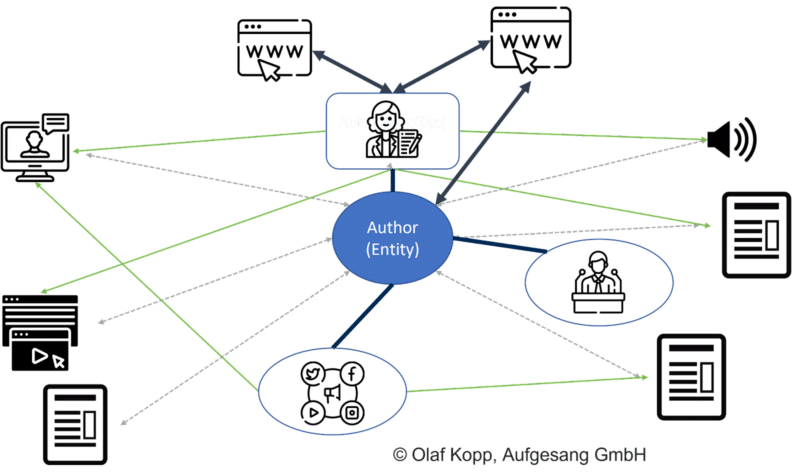
¿Cómo puede Google identificar autores y atribuir contenido?
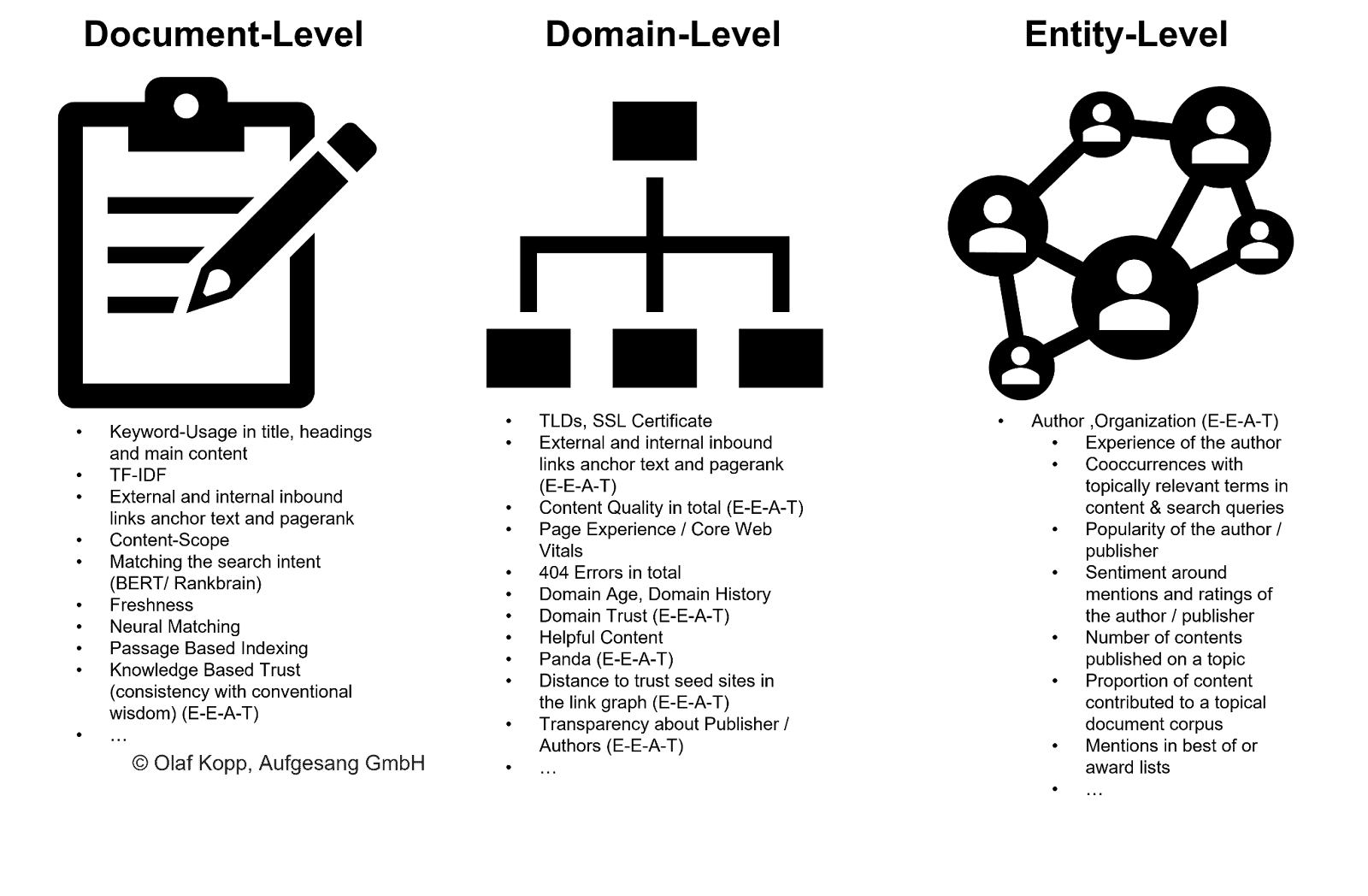
Los autores pertenecen al tipo de entidad persona. Se debe hacer una distinción entre entidades ya conocidas registradas en Knowledge Graph y entidades previamente desconocidas o no validadas registradas en un repositorio de conocimiento como Knowledge Vault.
Incluso si las entidades aún no están capturadas en Knowledge Graph, Google puede reconocer y extraer entidades de contenido no estructurado utilizando modelos de lenguaje y aprendizaje automático. La solución se llama reconocimiento de entidades (NER), una subtarea del procesamiento del lenguaje natural.
NER reconoce entidades basándose en patrones lingüísticos y se asignan tipos de entidad. En términos generales, los sustantivos son entidades (nombradas).
Los sistemas modernos de recuperación de información utilizan la incrustación de palabras (Word2Vec) para esto.
Un vector de números representa cada palabra de un texto o párrafo de texto, y las entidades se pueden representar como vectores de nodos o incrustaciones de entidades (Node2Vec/Entity2Vec).
Las palabras se asignan a una clase gramatical (sustantivo, verbo, preposiciones, etc.) mediante el etiquetado de parte del discurso (POS).
Los sustantivos suelen ser entidades. Los sujetos son las entidades principales y los objetos son las entidades secundarias. Los verbos y las preposiciones pueden relacionar las entidades entre sí.
En el siguiente ejemplo, "olaf kopp", "jefe de SEO", "cofundador" y "aufgesang" son las entidades nombradas. (NN = sustantivo).
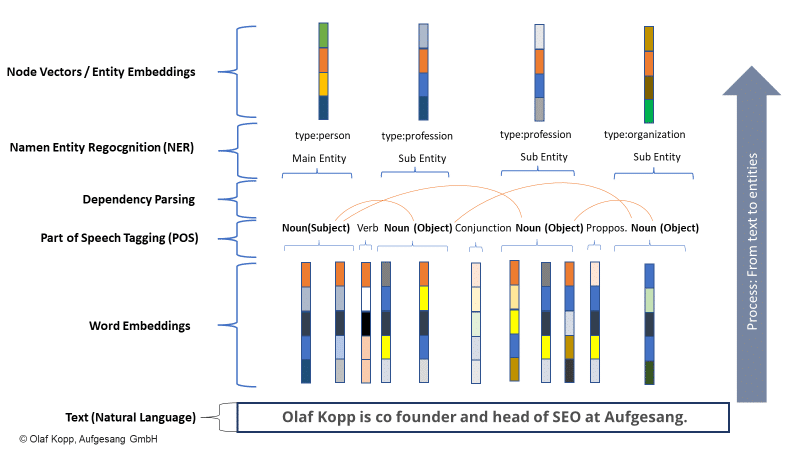
El procesamiento del lenguaje natural puede identificar entidades y determinar la relación entre ellas.
Esto crea un espacio semántico que captura y comprende mejor el concepto de una entidad.
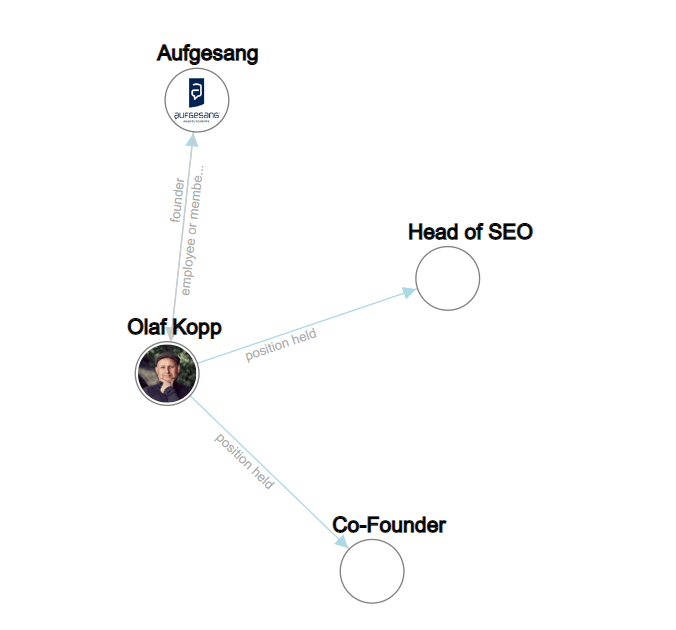
Puede encontrar más información sobre esto en "Cómo usa Google NLP para comprender mejor las consultas de búsqueda, el contenido".
La contraparte de las incrustaciones de autor son las incrustaciones de documentos. Las incrustaciones de documentos se comparan con los vectores de autor a través del análisis de espacio vectorial. (Puede obtener más información en la patente de Google "Generación de representaciones vectoriales de documentos").
Todos los tipos de contenido se pueden representar como vectores, lo que permite:
- Vectores de contenido y vectores de autor para ser comparados en espacios vectoriales.
- Documentos que se agruparán según la similitud.
- Autores a asignar.
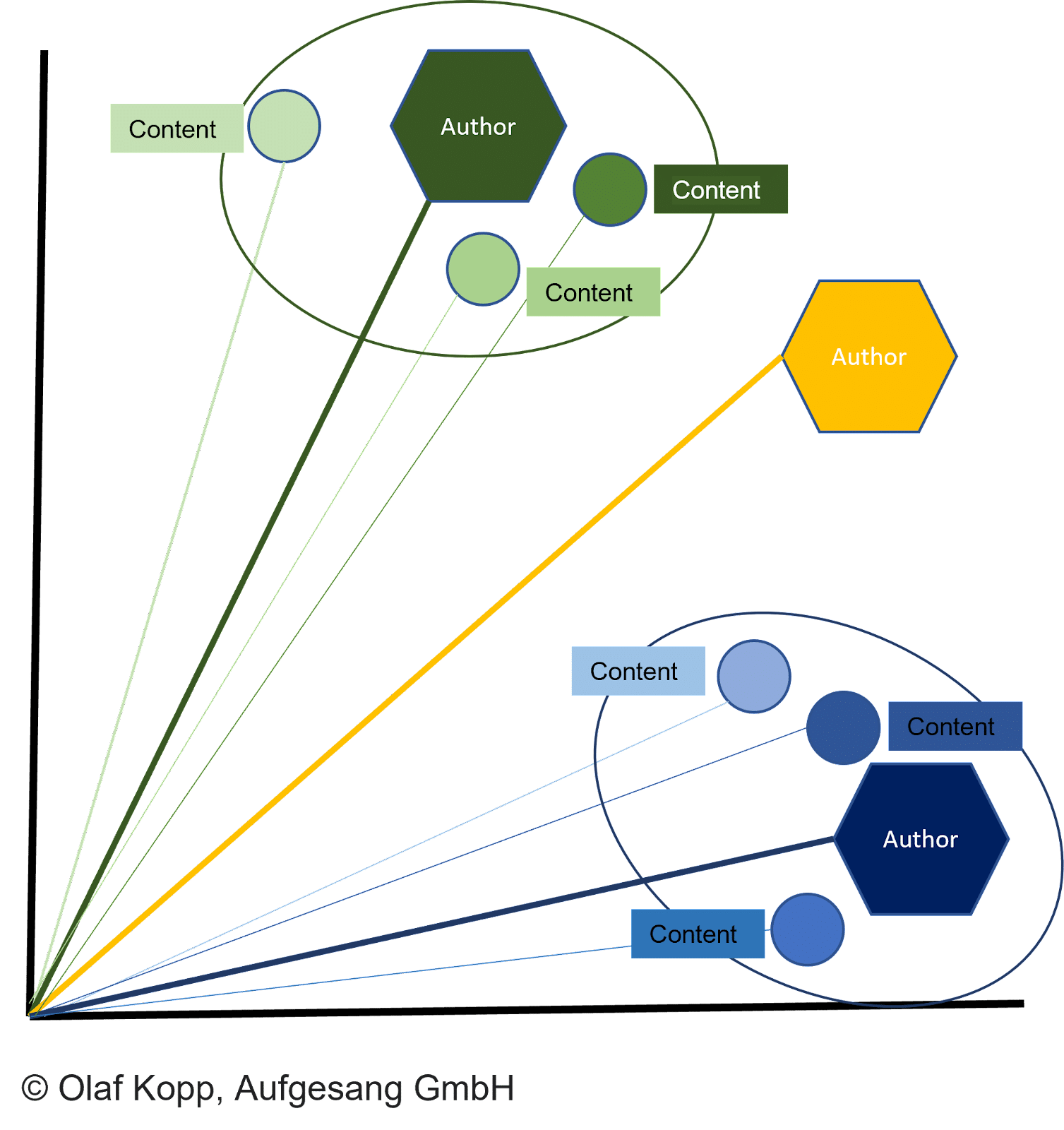
La distancia entre los vectores del documento y el vector del autor correspondiente describe la probabilidad de que el autor haya creado los documentos.
El documento se atribuye al autor si la distancia es menor que otros vectores y se alcanza un cierto umbral.
Esto también puede evitar que se cree un documento bajo una bandera falsa. El vector de autor se puede asignar a una entidad de autor, como ya se describió, usando el nombre de autor especificado en el contenido.
Las fuentes importantes de información sobre los autores incluyen:
- Artículos de Wikipedia sobre la persona.
- Perfiles de autor.
- Perfiles de locutores.
- Perfiles de redes sociales.
Si busca en Google el nombre de una persona de tipo entidad, encontrará entradas de Wikipedia, perfiles del autor y URL de dominios que están directamente conectados con el autor en los primeros 20 resultados de búsqueda.
En las SERPs móviles, puedes ver qué fuentes Google establece una relación directa con la entidad persona.
Google reconoció todos los resultados sobre los íconos de los perfiles de redes sociales como fuentes con una referencia directa a la entidad.

Esta captura de pantalla de la consulta de búsqueda de "olaf kopp" muestra que las entidades están vinculadas a las fuentes.
También muestra una nueva variante de un panel de conocimiento. Parece que me he convertido en parte de una prueba beta aquí.
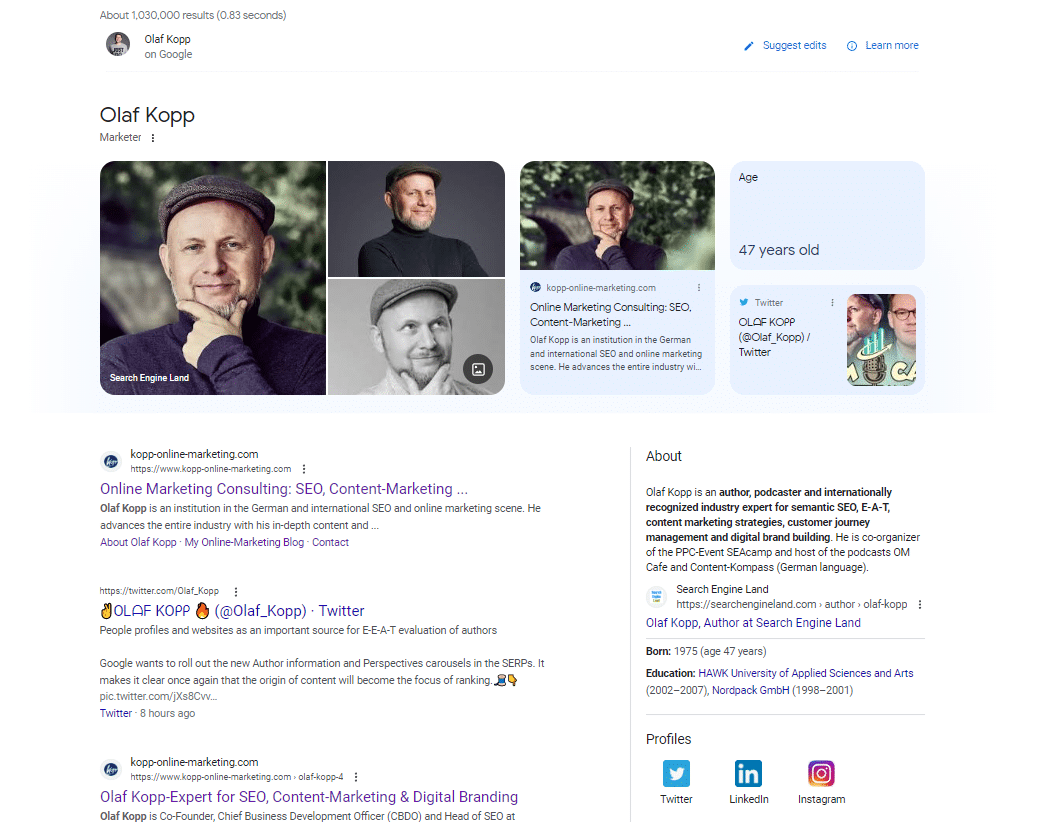
En esta captura de pantalla, verá que además de las imágenes y los atributos (edad), Google vinculó directamente mi dominio y perfil de redes sociales a mi entidad y los entrega en el panel de conocimiento.
Dado que no hay ningún artículo de Wikipedia sobre mí, la descripción Acerca de se entrega desde el perfil del autor en Search Engine Land en los EE. UU. y el perfil del autor del sitio web de la agencia en Alemania.
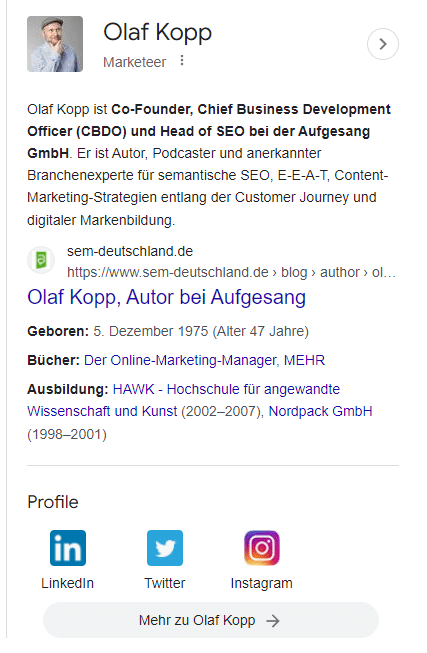
Los perfiles personales en la web ayudan a Google a contextualizar a los autores e identificar perfiles de redes sociales y dominios asociados con un autor.
Los cuadros de autor o las colecciones de autor en los perfiles de autor ayudan a Google a asignar contenido a los autores. El nombre del autor es insuficiente como identificador ya que pueden surgir ambigüedades.
Debe prestar atención a las descripciones de los autores de todos para garantizar la coherencia. Google puede usarlos para verificar la validez de la entidad en comparación entre sí.
Obtenga el boletín informativo diario en el que confían los especialistas en marketing.
Ver términos.
Interesantes patentes de Google para calificación EEAT de autores
Las siguientes patentes comparten un vistazo a las posibles metodologías de cómo Google identifica a los autores, les asigna contenido y lo evalúa en términos de EEAT.
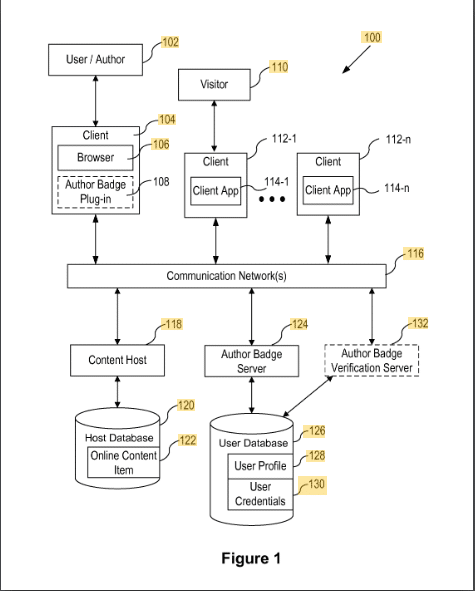
Insignias de autor de contenido
Esta patente describe cómo se asigna el contenido a los autores a través de una insignia.
El contenido se asigna a una insignia de autor mediante una identificación como la dirección de correo electrónico o el nombre del autor. La verificación se realiza a través de un complemento en el navegador del autor.

Generando vectores de autor
Google firmó esta patente en 2016, con una vigencia hasta 2036. Sin embargo, solo ha habido solicitudes de patente para EE. UU., lo que sugiere que aún no se usa en las búsquedas de Google en todo el mundo.
La patente describe cómo los autores se representan como vectores basados en datos de entrenamiento.
Un vector se convierte en parámetros únicos identificados según el estilo de escritura típico del autor y la elección de palabras.
De esta forma, se les pueden asignar contenidos no atribuidos previamente al autor, o se pueden agrupar autores similares en clústeres.
La clasificación del contenido se puede ajustar para uno o más autores en función del comportamiento del usuario en el pasado en la búsqueda (en Discover, por ejemplo).
Por lo tanto, el contenido de autores que ya han sido descubiertos y los de autores similares se clasificarían mejor.
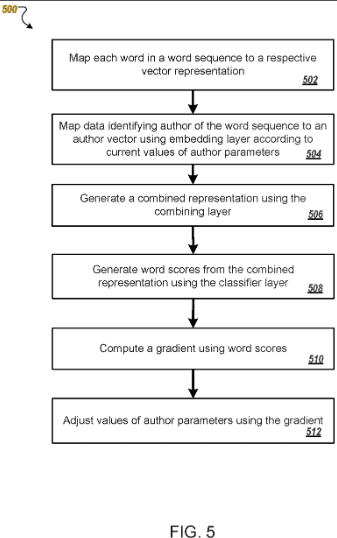
Esta patente se basa en las llamadas incrustaciones, como autores e incrustaciones de palabras.
Hoy en día, las incrustaciones son el estándar tecnológico en el aprendizaje profundo y el procesamiento del lenguaje natural.
Por lo tanto, es obvio que estos métodos de Google también se utilizarán para el reconocimiento y la atribución de autores.
Puntuación de la reputación de un autor
Esta patente fue firmada por primera vez por Google en 2008 y tiene un plazo mínimo de 2029. Esta patente se refiere originalmente al proyecto Google Knol cerrado hace mucho tiempo.
Por lo tanto, es aún más emocionante por qué Google lo dibujó nuevamente en 2017 bajo el nuevo título Monetización del contenido en línea. Google cerró Knol en 2012.
La patente se trata de determinar una puntuación de reputación. Para ello se pueden tener en cuenta los siguientes factores:
- Nivel de encuadre del autor.
- Publicaciones en medios de renombre.
- Número de publicaciones.
- Antigüedad de los lanzamientos recientes.
- Cuánto tiempo el autor ha estado trabajando oficialmente como autor.
- Número de enlaces generados por el contenido del autor.
Un autor puede tener varias puntuaciones de reputación por tema y tener varios alias por área temática.
Muchos de los puntos señalados en la patente se relacionan con una plataforma cerrada como Knol. Por lo tanto, esta patente debería ser suficiente en este punto.
Rango de agente
Esta patente de Google se firmó por primera vez en 2005 y tiene un plazo mínimo hasta 2026.
Además de en EE. UU., también se registró en España, Canadá y en todo el mundo, por lo que es probable que se utilice en la búsqueda de Google.
La patente describe cómo se asigna el contenido digital a un agente (editor y/o autor). Este contenido se clasifica en función de la clasificación de un agente, entre otras cosas.
El rango de agente es independiente de la intención de búsqueda de la consulta de búsqueda y se determina sobre la base de los documentos asignados al agente y sus vínculos de retroceso.
El rango de agente se refiere exclusivamente a una consulta de búsqueda, un grupo de consultas de búsqueda o áreas temáticas completas.
“Los rangos de los agentes también se pueden calcular opcionalmente en relación con los términos de búsqueda o categorías de términos de búsqueda. Por ejemplo, los términos de búsqueda (o colecciones estructuradas de términos de búsqueda, es decir, consultas) se pueden clasificar en temas, por ejemplo, deportes o especialidades médicas, y un agente puede tener un rango diferente con respecto a cada tema”.
Credibilidad de un autor de contenido en línea
Esta patente de Google se firmó por primera vez en 2008 y tiene una vigencia mínima de 2029, y hasta ahora solo se ha registrado en EE. UU.
Justin Lawyer lo desarrolló de la misma forma que el Patent Reputation Score de un autor y está directamente relacionado con su uso en las búsquedas.
En la patente, se encuentran puntos similares a los de la patente mencionada anteriormente.
Para mí, es la patente más emocionante para evaluar a los autores en términos de confianza y autoridad.
Esta patente hace referencia a varios factores que se pueden utilizar para determinar algorítmicamente la credibilidad de un autor.
Describe cómo un motor de búsqueda puede clasificar documentos bajo la influencia del factor de credibilidad y la puntuación de reputación de un autor.
Un autor puede tener varias puntuaciones de reputación según la cantidad de temas diferentes sobre los que publique contenido.
El puntaje de reputación de un autor es independiente del editor.
De nuevo en esta patente, hay una referencia a los enlaces como un posible factor en una clasificación EEAT. El número de enlaces al contenido publicado puede influir en la puntuación de reputación de un autor.
Se mencionan las siguientes señales posibles para una puntuación de reputación:
- Cuánto tiempo el autor ha estado produciendo contenido en un área temática.
- Conciencia del autor.
- Valoraciones de los contenidos publicados por los usuarios.
- Si otro editor publica el contenido del autor con calificaciones superiores al promedio.
- La cantidad de contenido publicado por el autor.
- Hace cuánto tiempo el autor publicó por última vez.
- Calificaciones de publicaciones anteriores sobre un tema similar por parte del autor.
Otros datos interesantes sobre la puntuación de reputación de la patente:
- Un autor puede tener varias puntuaciones de reputación según la cantidad de temas diferentes sobre los que publique contenido.
- El puntaje de reputación de un autor es independiente del editor.
- La puntuación de reputación puede reducirse si se publican extractos o contenido duplicado varias veces.
- El número de enlaces al contenido publicado puede influir en la puntuación de reputación.
Además, la patente aborda un factor de credibilidad para los autores. Se mencionan los siguientes factores influyentes:
- Información verificada sobre la profesión o el rol del autor en una empresa. También considera la credibilidad de la empresa.
- Relevancia de la ocupación a los temas del contenido publicado.
- Nivel de educación y formación del autor.
- Experiencia del autor basada en el tiempo. Cuanto más tiempo un autor ha estado publicando sobre un tema, más creíble es. La experiencia del autor/editor se puede determinar algorítmicamente para Google a través de la fecha de la primera publicación en un área temática.
- El número de contenido publicado sobre un tema. Si un autor publica muchos artículos sobre un tema, se puede suponer que es un experto y tiene cierta credibilidad.
- Tiempo transcurrido hasta la última versión. Cuanto más tiempo ha pasado desde la última vez que un autor publicó sobre un tema, más disminuye la puntuación de reputación posible para este tema. Cuanto más actualizado es el contenido, más alto es.
- Menciones del autor/editor en listas de premios y best-of.
Sistemas y métodos para volver a clasificar los resultados de búsqueda clasificados
Esta patente de Google se firmó por primera vez en 2013 y tiene una vigencia mínima hasta 2033. Ha sido registrada en EE. UU. y en todo el mundo, lo que hace probable que Google la utilice.
Entre los inventores de la patente se encuentra Chung Tin Kwok, quien participó en varias patentes de Google relevantes para la EEAT.
La patente describe cómo los motores de búsqueda, además de las referencias al contenido del autor, también pueden considerar la proporción que éste puede aportar a un corpus documental temático en una puntuación de autor.
"En algunas realizaciones, la determinación de la puntuación del autor original para la entidad respectiva incluye: identificar una pluralidad de porciones de contenido en el índice de contenido conocido identificado como asociado con la entidad respectiva, cada porción en la pluralidad de porciones representando una cantidad predeterminada de datos en el índice de contenido conocido; y calculando un porcentaje de la pluralidad de las porciones que son primeras instancias de las porciones de contenido en el índice de contenido conocido".
Describe una nueva clasificación de los resultados de búsqueda en función de la puntuación del autor, incluida la puntuación de las citas. La puntuación de citas se basa en el número de referencias a los documentos de un autor.
Otro criterio para la puntuación del autor es la proporción de contenido que un autor ha contribuido a un corpus de documentos relacionados con el tema.
"[D]entro de esto, determinar la puntuación del autor para una entidad respectiva incluye: determinar una puntuación de cita para la entidad respectiva, donde la puntuación de cita corresponde a una frecuencia con la que se cita el contenido asociado con la entidad respectiva; determinar una puntuación de autor original para la entidad respectiva, donde el puntaje del autor original corresponde a un porcentaje de contenido asociado con la entidad respectiva que es una primera instancia del contenido en un índice de contenido conocido; y combinar el puntaje de citación y el puntaje del autor original usando una función predeterminada para producir la partitura del autor".
El propósito de la patente es identificar "imitadores" y degradar su contenido en las clasificaciones, pero también se puede utilizar para la evaluación general de los autores.
Factores clave para calificar a un autor
Además de los posibles factores para la evaluación de un autor enumerados en las patentes anteriores, aquí hay algunos más a considerar (algunos de los cuales ya mencioné en mi artículo "14 formas en que Google puede evaluar EAT").
- Calidad general del contenido sobre un tema: La calidad que entrega un autor sobre su contenido sobre un tema en su conjunto, independientemente del dominio y el formato, puede ser un factor para la EEAT. Las señales para esto pueden ser señales de usuario, enlaces y otras señales de calidad a nivel de contenido.
- PageRank o referencias al contenido del autor.
- Co-ocurrencias del autor en el contenido (podcasts, videos, sitios web, PDF, libros) con temas o términos relevantes.
- Co-ocurrencias del autor en consultas de búsqueda con temas o términos relevantes.
Aplicando EEAT a entidades autoras
Los métodos de aprendizaje automático permiten reconocer y mapear estructuras semánticas a partir de contenido no estructurado a gran escala.
Esto permite que Google reconozca y comprenda muchas más entidades de las que se muestran anteriormente en Knowledge Graph.
Como resultado, la fuente de contenido juega un papel cada vez más importante. EEAT se puede aplicar algorítmicamente más allá de los documentos, el contenido y el dominio.
El concepto también puede abarcar las entidades autoras del contenido (es decir, los autores y las organizaciones responsables del contenido).
Creo que veremos un impacto aún más significativo de EEAT en la búsqueda de Google en los próximos años. Este factor puede ser incluso tan importante para el ranking como la optimización de la relevancia de los contenidos individuales.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.