
¿Utiliza Google un sistema similar a ChatGPT para la detección de spam y contenido de IA y la clasificación de sitios web?
Publicado: 2023-02-01El titular es intencionalmente engañoso, pero solo en lo que respecta al uso del término "ChatGPT".
"ChatGPT-like" le permite inmediatamente a usted, el lector, saber a qué tipo de tecnología me refiero, en lugar de describir el sistema como "un modelo de generación de texto como GPT-2 o GPT-3". (Además, este último realmente no sería tan fácil de hacer clic...)
Lo que veremos en este artículo es un artículo de Google más antiguo pero muy relevante de 2020, "Los modelos generativos son predictores no supervisados de la calidad de la página: un estudio de escala colosal".
¿De qué trata el papel?
Comencemos con la descripción de los autores. Ellos introducen el tema así:
“Muchos han expresado su preocupación por los peligros potenciales de los generadores de texto neuronal en la naturaleza, debido en gran parte a su capacidad para producir texto de aspecto humano a escala.
Clasificadores entrenados para discriminar entre texto humano y generado por máquina han sido empleados recientemente para monitorear la presencia de texto generado por máquina en la web [29]. Sin embargo, se ha trabajado poco en la aplicación de estos clasificadores para otros usos, a pesar de su atractiva propiedad de no requerir etiquetas, solo un corpus de texto humano y un modelo generativo. En este trabajo, mostramos a través de una rigurosa evaluación humana que los discriminadores estándar entre humanos y máquinas sirven como poderosos clasificadores de la calidad de la página . Es decir, los textos que parecen generados por máquinas tienden a ser incoherentes o ininteligibles. Para comprender la presencia de baja calidad de página en la naturaleza, aplicamos los clasificadores a una muestra de 500 millones de páginas web en inglés”.
Básicamente, lo que dicen es que han descubierto que los mismos clasificadores desarrollados para detectar copias basadas en IA, usando los mismos modelos para generarlas, pueden usarse con éxito para detectar contenido de baja calidad.
Por supuesto, esto nos deja con una pregunta importante:
¿Es causalidad (es decir, el sistema lo detecta porque es realmente bueno en eso) o correlación (es decir, se crea una gran cantidad de spam actual de una manera que es fácil de manejar con mejores herramientas)?
Sin embargo, antes de explorar eso, veamos algunos de los trabajos de los autores y sus hallazgos.
La puesta en marcha
Como referencia, usaron lo siguiente en su experimento:
- Dos modelos de generación de texto , el detector GPT-2 basado en RoBERTa de OpenAI (un detector que usa el modelo RoBERTa con salida GPT-2 y predice si es probable que sea generado por IA o no) y el modelo GLTR, que también tiene acceso a la parte superior Salida GPT-2 y funciona de manera similar.
Podemos ver un ejemplo de la salida de este modelo en el contenido que copié del artículo anterior:
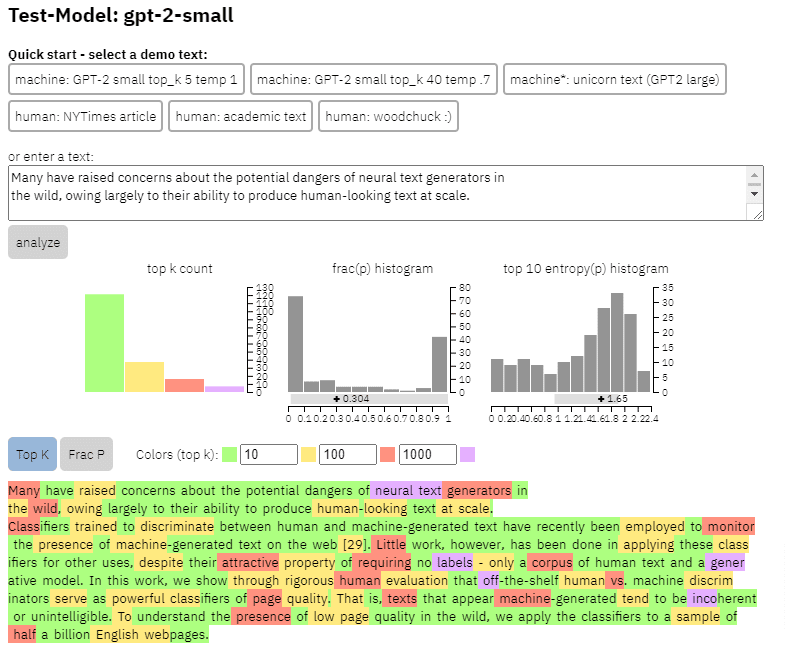
- Tres conjuntos de datos Web500M (una muestra aleatoria de 500 millones de páginas web en inglés), GPT-2 Output (250 000 generaciones de texto GPT-2) y Grover-Output (generaron internamente 1,2 millones de artículos utilizando el modelo Grover-Base preentrenado, que fue diseñado para detectar noticias falsas).
- Spam Baseline , un clasificador entrenado en el conjunto de datos de correo electrónico no deseado de Enron. Utilizaron este clasificador para establecer el número de calidad del idioma que asignarían, de modo que si el modelo determinaba que un documento no es spam con una probabilidad de 0,2, la puntuación de calidad del idioma (LQ) asignada era 0,2.
Obtenga el boletín informativo diario en el que confían los especialistas en marketing.
Ver términos.
Un aparte sobre la prevalencia del spam
Quería hacer un aparte rápido para discutir algunos hallazgos interesantes con los que tropezaron los autores. Uno se ilustra en la siguiente figura (Figura 3 del artículo):
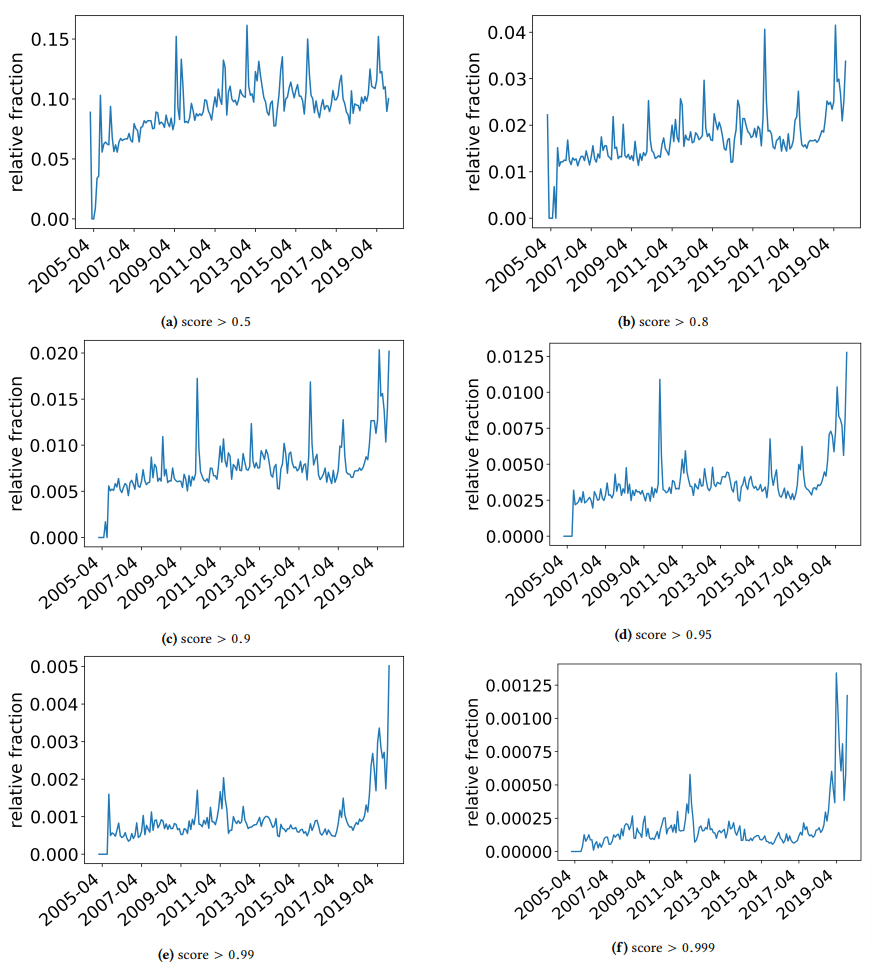
Es importante notar la puntuación debajo de cada gráfico. Un número hacia 1.0 se está moviendo hacia la confianza de que el contenido es spam. Lo que estamos viendo entonces es que desde 2017 en adelante, y con un aumento en 2019, hubo una prevalencia de documentos de baja calidad.
Además, encontraron que el impacto del contenido de baja calidad era mayor en algunos sectores que en otros (recordando que una puntuación más alta refleja una mayor probabilidad de spam).
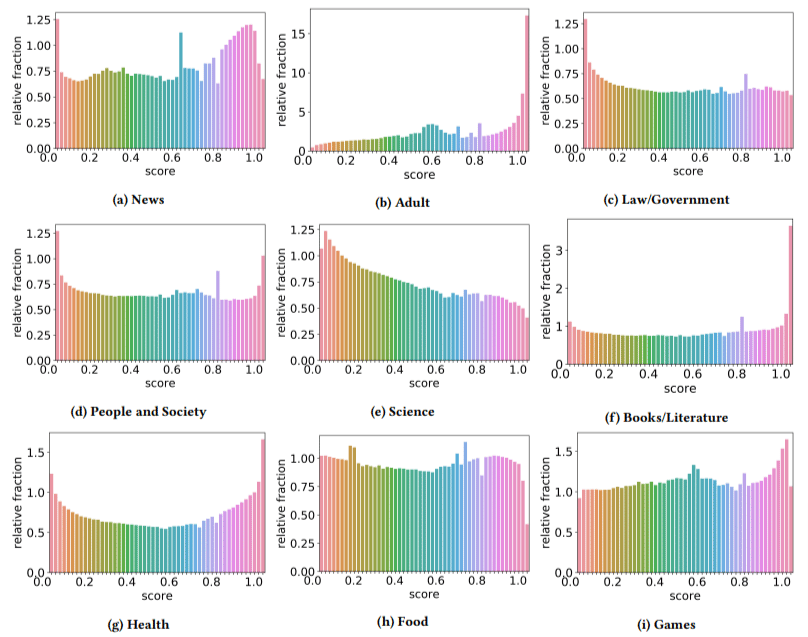
Me rasqué la cabeza con un par de estos. Adulto tenía sentido, obviamente.
Pero los libros y la literatura fueron un poco una sorpresa. Y también lo era la salud, hasta que los autores mencionaron Viagra y otros sitios de "productos de salud para adultos" como "salud" y las granjas de ensayos como "literatura".
sus hallazgos
Además de lo que discutimos sobre los sectores y el aumento en 2019, los autores también encontraron una serie de cosas interesantes de las que los SEO pueden aprender y deben tener en cuenta, especialmente a medida que comenzamos a apoyarnos en herramientas como ChatGPT.
- El contenido de baja calidad tiende a ser de menor longitud (con un máximo de 3000 caracteres).
- Los sistemas de detección entrenados para determinar si el texto fue escrito por una máquina o no, también son buenos para clasificar el contenido de bajo y alto nivel.
- Llaman a nuestro contenido diseñado para clasificaciones como un culpable específico, aunque sospecho que se están refiriendo a la basura que todos sabemos que no debería estar ahí.
Los autores no afirman que esta es una solución definitiva, sino más bien un punto de partida y estoy seguro de que han movido el listón en los últimos dos años.
Una nota sobre el contenido generado por IA
Los modelos de lenguaje también se han desarrollado a lo largo de los años. Si bien GPT-3 existía cuando se escribió este documento, los detectores que usaban se basaban en GPT-2, que es un modelo significativamente inferior.
Es probable que GPT-4 esté a la vuelta de la esquina y Sparrow de Google se lanzará a finales de este año. Esto significa que no solo la tecnología está mejorando en ambos lados del campo de batalla (generadores de contenido frente a motores de búsqueda), sino que las combinaciones serán más fáciles de poner en juego.
¿Puede Google detectar contenido creado por Sparrow o GPT-4? Quizás.
Pero, ¿qué tal si se generó con Sparrow y luego se envió a GPT-4 con un aviso de reescritura?
Otro factor que debe recordarse es que las técnicas utilizadas en este artículo se basan en modelos autorregresivos. En pocas palabras, predicen una puntuación para una palabra en función de lo que predecirían que esa palabra se daría a las que la precedieron.
A medida que los modelos desarrollan un mayor grado de sofisticación y comienzan a crear ideas completas a la vez en lugar de una palabra seguida de otra, la detección de IA puede fallar.
Por otro lado, la detección de contenido simplemente basura debería aumentar, lo que puede significar que el único contenido de "baja calidad" que ganará es el generado por IA.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.