
Ecosistema Hadoop y sus componentes
Publicado: 2015-04-23Big Data es la palabra de moda que circula en la industria de TI desde 2008. La cantidad de datos generados por las industrias de redes sociales, fabricación, comercio minorista, acciones, telecomunicaciones, seguros, banca y atención médica está mucho más allá de nuestra imaginación.
Antes de la llegada de Hadoop, el almacenamiento y procesamiento de big data era un gran desafío. Pero ahora que Hadoop está disponible, las empresas se han dado cuenta del impacto comercial de Big Data y cómo la comprensión de estos datos impulsará el crecimiento. Por ejemplo:
• Los sectores bancarios tienen una mejor oportunidad de comprender a los clientes leales, los morosos y las transacciones fraudulentas.
• Los sectores minoristas ahora tienen suficientes datos para pronosticar la demanda.
• Los sectores manufactureros no necesitan depender de los costosos mecanismos para las pruebas de calidad. Capturar los datos de los sensores y analizarlos revelaría muchos patrones.
• Comercio electrónico, las redes sociales pueden personalizar las páginas en función de los intereses del cliente.
• Los mercados bursátiles generan una enorme cantidad de datos, la correlación de vez en cuando revelará información valiosa.
Big Data tiene muchas aplicaciones útiles y perspicaces.
Hadoop es la respuesta directa para el procesamiento de Big Data. El ecosistema Hadoop es una combinación de tecnologías que tienen una ventaja competente para resolver problemas comerciales.
Comprendamos los componentes de Hadoop Ecosytem para crear soluciones adecuadas para un problema empresarial determinado.
Ecosistema Hadoop:
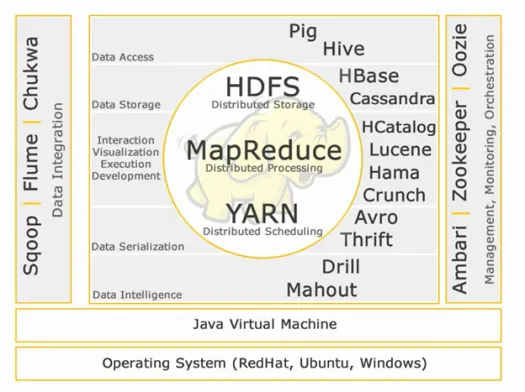

Núcleo de Hadoop:
HDFS:
HDFS significa Hadoop Distributed File System para administrar grandes conjuntos de datos con alto volumen, velocidad y variedad. HDFS implementa una arquitectura maestra esclava. El maestro es el nodo de nombre y el esclavo es el nodo de datos.
Características:
• Escalable
• De confianza
• Hardware básico
HDFS es bien conocido por el almacenamiento de Big Data.
Mapa reducido:
Map Reduce es un modelo de programación diseñado para procesar datos distribuidos de gran volumen. La plataforma está construida usando Java para un mejor manejo de excepciones. Map Reduce incluye dos demonios, Job tracker y Task Tracker.
Características:
• Programación Funcional.
• Funciona muy bien en Big Data.
• Puede procesar grandes conjuntos de datos.
Map Reduce es el componente principal conocido por procesar big data.
HILO:
YARN significa Otro Negociador de Recursos. También se llama MapReduce 2 (MRv2). Las dos funcionalidades principales de Job Tracker en MRv1, la gestión de recursos y la programación/supervisión de trabajos, se dividen en demonios separados que son ResourceManager, NodeManager y ApplicationMaster.
Características:
• Mejor gestión de recursos.
• Escalabilidad
• Asignación dinámica de recursos del clúster.
Acceso a los datos:
Cerdo:
Apache Pig es un lenguaje de alto nivel construido sobre MapReduce para analizar grandes conjuntos de datos con programas simples de análisis de datos ad hoc. Pig también se conoce como lenguaje de flujo de datos. Está muy bien integrado con python. Inicialmente es desarrollado por yahoo.
Características sobresalientes del cerdo:
• Facilidad de programación
• Oportunidades de optimización
• Extensibilidad.
Los scripts de Pig internamente se convertirán en programas de reducción de mapas.

Colmena:
Apache Hive es otra infraestructura de almacén de datos y lenguaje de consulta de alto nivel construida sobre Hadoop para proporcionar resumen, consulta y análisis de datos. Inicialmente fue desarrollado por yahoo y hecho de código abierto.
Características sobresalientes de la colmena:
• Lenguaje de consulta similar a SQL llamado HQL.
• Particiones y depósitos para un procesamiento de datos más rápido.
• Integración con herramientas de visualización como Tableau.
Las consultas de Hive internamente se convertirán en programas de reducción de mapas.
¡Si quieres convertirte en un analista de big data, estos dos lenguajes de alto nivel son imprescindibles!

Almacenamiento de datos:
Hbase:
Apache HBase es una base de datos NoSQL creada para albergar tablas grandes con miles de millones de filas y millones de columnas sobre las máquinas de hardware básico de Hadoop. Utilice Apache Hbase cuando necesite acceso de lectura/escritura aleatorio y en tiempo real a su Big Data.
Características:
• Lecturas y escrituras estrictamente coherentes. En operaciones de memoria.
• API de Java fácil de usar para el acceso del cliente.
• Bien integrado con pig, hive y sqoop.
• Es un sistema consistente y tolerante a particiones en el teorema CAP.

Casandra:
Cassandra es una base de datos NoSQL diseñada para escalabilidad lineal y alta disponibilidad. Cassandra se basa en el modelo clave-valor. Desarrollado por Facebook y conocido por su respuesta más rápida a las consultas.
Características:
• Índices de columnas
• Compatibilidad con la desnormalización
• Vistas materializadas
• Potente almacenamiento en caché integrado.

Interacción -Visualización- ejecución-desarrollo:
Catálogo:

HCatalog es una capa de administración de tablas que proporciona integración de metadatos de colmena para otras aplicaciones de Hadoop. Permite a los usuarios con diferentes herramientas de procesamiento de datos como Apache pig, Apache MapReduce y Apache Hive leer y escribir datos más fácilmente.
Características:
• Vista tabular para diferentes formatos.
• Notificaciones de disponibilidad de datos.
• REST API's para sistemas externos para acceder a metadatos.
Lucena:
Apache LuceneTM es una biblioteca de motor de búsqueda de texto de alto rendimiento y con todas las funciones escrita completamente en Java. Es una tecnología adecuada para casi cualquier aplicación que requiera búsqueda de texto completo, especialmente multiplataforma.
Características:
• Indexación escalable y de alto rendimiento.
• Algoritmos de búsqueda potentes, precisos y eficientes.
• Solución multiplataforma.
hama:
Apache Hama es un marco distribuido basado en la computación Bulk Synchronous Parallel (BSP). Capaz y bien conocido para cálculos científicos masivos como algoritmos de matriz, gráfico y red.
Características:
• Modelo de programación simple
• Muy adecuado para algoritmos iterativos
• compatible con HILO
• Aprendizaje automático no supervisado de filtrado colaborativo.
• Agrupación de K-Means.
Crujido:
Apache crunch está diseñado para canalizar programas MapReduce que son simples y eficientes. Este marco se utiliza para escribir, probar y ejecutar canalizaciones de MapReduce.
Características:
• Centrado en el desarrollador.
• Abstracciones mínimas
• Modelo de datos flexible.
Serialización de datos:
Avro:
Apache Avro es un marco de serialización de datos que es independiente del lenguaje. Diseñado para la portabilidad del idioma, lo que permite que los datos sobrevivan potencialmente al idioma para leerlos y escribirlos.

Ahorro:
Thrift es un lenguaje desarrollado para construir interfaces para interactuar con tecnologías construidas en Hadoop. Se utiliza para definir y crear servicios para numerosos idiomas.
Inteligencia de datos:
Taladro:
Apache Drill es un motor de consultas SQL de baja latencia para Hadoop y NoSQL.
Características:
• Agilidad
• Flexibilidad
• Familiaridad.

Cuidador de elefantes:
Apache Mahout es una biblioteca de aprendizaje automático escalable diseñada para crear análisis predictivos en Big Data. Mahout ahora tiene implementaciones de Apache Spark para una computación más rápida en la memoria.
Características:
• Filtración colaborativa.
• Clasificación
• Agrupación
• Reducción de dimensionalidad

Integración de datos:
Pase de Apache:

Apache Sqoop es una herramienta diseñada para transferencias masivas de datos entre bases de datos relacionales y Hadoop.
Características:
• Importación y exportación hacia y desde HDFS.
• Importar y exportar hacia y desde Hive.
• Importación y exportación a HBase.
Canal Apache:
Flume es un servicio distribuido, confiable y disponible para recopilar, agregar y mover de manera eficiente grandes cantidades de datos de registro.
Características:
• Robusto
• Tolerante a fallos
• Arquitectura simple y flexible basada en flujos de datos en streaming.

apache chukwa:
Recopilador de registros escalable utilizado para monitorear grandes sistemas de archivos distribuidos.
Características:
• Escala a miles de nodos.
• Entrega confiable.
• Debería poder almacenar datos indefinidamente.

Gestión, Seguimiento y Orquestación:
Apache Ambarí:
Ambari está diseñado para simplificar la administración de hadoop al proporcionar una interfaz para aprovisionar, administrar y monitorear clústeres de Apache Hadoop.
Características:
• Aprovisionar un clúster de Hadoop.
• Administrar un clúster de Hadoop.
• Supervisar un clúster de Hadoop.

Guardián del zoológico apache:
Zookeeper es un servicio centralizado diseñado para mantener la información de configuración, nombrar, brindar sincronización distribuida y brindar servicios grupales.
Características:
• Serialización
• Atomicidad
• Fiabilidad
• API sencilla

Apache Oozie:
Oozie es un sistema de programación de flujo de trabajo para administrar trabajos de Apache Hadoop.
Características:
• Sistema escalable, confiable y extensible.
• Admite varios tipos de trabajos de Hadoop, como Map-Reduce, Hive, Pig y Sqoop.
• Simple y fácil de usar.

Discutiremos sobre los componentes en detalle en los próximos artículos. Manténganse al tanto.