
Instalación de Hadoop mediante Ambari
Publicado: 2015-12-11Todo lo que desea saber sobre la instalación de Hadoop mediante Ambari
Apache Hadoop se ha convertido en un marco de software de facto para computación confiable, escalable, distribuida y a gran escala. A diferencia de otros sistemas informáticos, lleva la computación a los datos en lugar de enviar datos a la computación. Hadoop fue creado en 2006 en Yahoo por Doug Cutting a partir de un artículo publicado por Google. A medida que Hadoop maduró, a lo largo de los años se agregaron muchos componentes y herramientas nuevos a su ecosistema para mejorar su usabilidad y funcionalidad. Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, Sqoop, etc., por nombrar algunos.
¿Por qué Ambarí?
Con la creciente popularidad de Hadoop, muchos desarrolladores se lanzan a esta tecnología para probarla. Pero como dicen, Hadoop no es para pusilánimes, muchos desarrolladores ni siquiera pudieron cruzar la barrera de instalar Hadoop. Muchas distribuciones ofrecen sandbox preinstalado de VM para probar cosas, pero no le da la sensación de computación distribuida. Sin embargo, instalar un nodo múltiple no es una tarea fácil y con un número creciente de componentes, es muy complicado manejar tantos parámetros de configuración. ¡Afortunadamente, Apache Ambari viene a rescatarnos!
¿Qué es Ambarí?
Apache Ambari es una herramienta basada en web para aprovisionar, administrar y monitorear clústeres de Apache Hadoop. Ambari proporciona un tablero para ver el estado del clúster, como mapas de calor y la capacidad de ver las aplicaciones MapReduce, Pig y Hive visualmente junto con funciones para diagnosticar sus características de rendimiento de una manera fácil de usar. Tiene una interfaz de usuario muy simple e interactiva para instalar varias herramientas y realizar varias tareas de administración, configuración y monitoreo. A continuación, lo guiaremos a través de varios pasos para instalar Hadoop y sus diversos componentes del ecosistema en un clúster de múltiples nodos.
La arquitectura de Ambari se muestra a continuación.
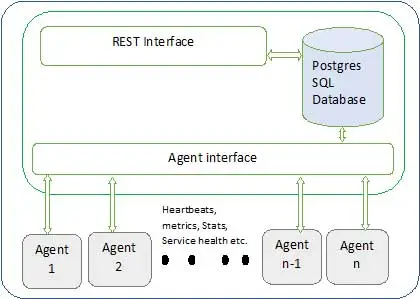
Ambari tiene dos componentes
- Servidor Ambari : este es el proceso maestro que se comunica con los agentes Ambari instalados en cada nodo que participa en el clúster. Tiene una instancia de base de datos postgres que se utiliza para mantener todos los metadatos relacionados con el clúster.
- Agente de Ambari : estos son agentes que actúan para Ambari en cada nodo. Cada agente envía periódicamente su propio estado de salud junto con diferentes métricas, estado de los servicios instalados y muchas cosas más. De acuerdo con el maestro, decide la siguiente acción y la transmite al agente para que actúe.
¿Cómo instalar Ambari?
La instalación de Ambari es fácil, una tarea de pocos comandos.
Cubriremos la instalación de Ambari y la configuración del clúster. Se supone que tenemos 4 nodos. Nodo1, Nodo2, Nodo3 y Nodo4. Y estamos eligiendo Node1 como nuestro servidor Ambari.
Estos son pasos de instalación en el sistema basado en RHEL, para Debian y otros sistemas, los pasos variarán poco.
- Instalación de Ambari: –
Desde el nodo del servidor Ambari (Nodo 1 como decidimos)
I. Descargar el repositorio público de Ambari

Este comando agregará el repositorio de Hortonworks Ambari a yum, que es un administrador de paquetes predeterminado para los sistemas RHEL.
ii.Instalar Ambari RPMS

Esto llevará algún tiempo e instalará Ambari en este sistema.

iii. Configuración del servidor Ambari
Lo siguiente que debe hacer después de la instalación de Ambari es configurar Ambari y configurarlo para aprovisionar el clúster.
El siguiente paso se encargará de esto.


IV. Inicie el servidor e inicie sesión en la interfaz de usuario web
Inicie el servidor con

Ahora podemos acceder a la interfaz de usuario web de Ambari (alojada en el puerto 8080).
Inicie sesión en Ambari con el nombre de usuario predeterminado "admin" y la contraseña predeterminada "admin"
Configuración del clúster de Hadoop
1. Página de destino
Haga clic en "Iniciar asistente de instalación" para iniciar la configuración del clúster
2. Nombre del clúster
Dale a tu clúster un buen nombre.
Nota: Este es solo un nombre simple para el clúster, no es tan significativo, así que no se preocupe y elija cualquier nombre para él.
3. Selección de pila
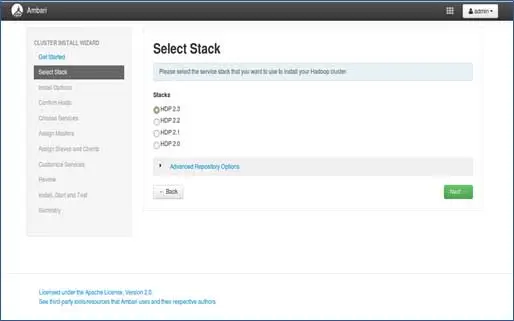
Esta página enumerará las pilas disponibles para instalar. Cada pila está preempaquetada con el componente del ecosistema Hadoop. Estas pilas son de Hortonworks. (También podemos instalar Hadoop simple. Eso lo cubriremos en publicaciones posteriores).
4. Entrada de hosts y entrada de clave SSH
Antes de continuar con este paso, deberíamos tener una configuración SSH sin contraseña para todos los nodos participantes.

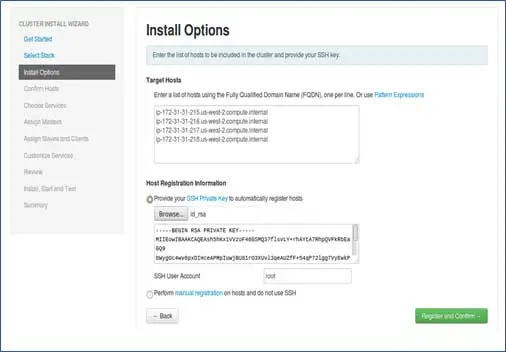
Agregue los nombres de host de los nodos, una sola entrada en cada línea. [ Agregue FQDN que se puede obtener mediante el comando hostname –f]. Seleccione la clave privada utilizada al configurar la contraseña sin SSH y el nombre de usuario con el que se creó la clave privada.
5. Estado de registro de los anfitriones
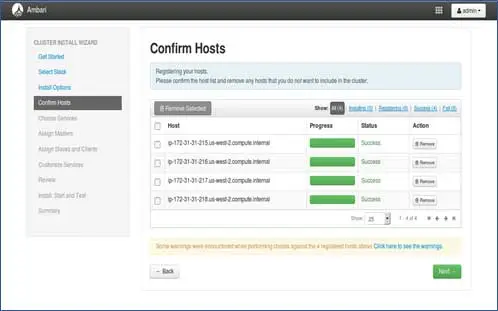
Puede ver que se están realizando algunas operaciones, estas operaciones incluyen la configuración de Ambari-agent en cada nodo, la creación de configuraciones básicas en cada nodo. Una vez que veamos TODO VERDE, estamos listos para continuar. A veces esto puede llevar tiempo ya que instala pocos paquetes.

6. Elija los servicios que desea instalar
Según las pilas seleccionadas en el paso 3, tenemos la cantidad de servicios que podemos instalar en el clúster. Puedes elegir el que quieras. Ambari selecciona de forma inteligente los servicios dependientes si no los ha seleccionado. Por ejemplo, si seleccionó HBase pero no Zookeeper, se le solicitará lo mismo y agregará Zookeeper también al clúster.
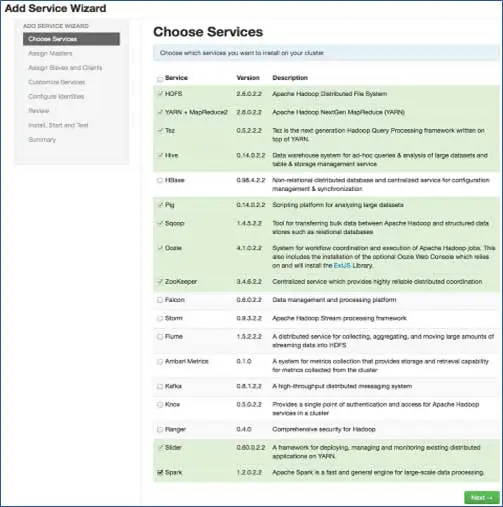
7. Mapeo de servicios maestros con Nodos
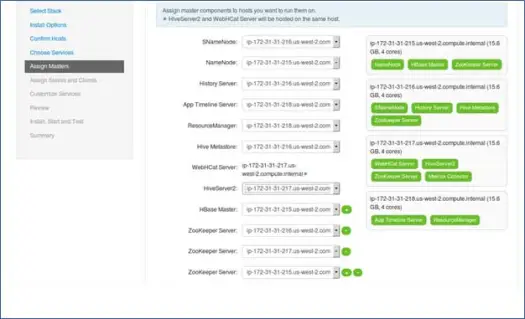
Como sabe, el ecosistema de Hadoop tiene herramientas que se basan en la arquitectura maestro-esclavo. En este paso, asociaremos procesos maestros con el nodo. Aquí, asegúrese de equilibrar correctamente su clúster. Además, tenga en cuenta que los servicios primarios y secundarios como Namenode y Namenode secundario no están en la misma máquina.

8. Mapeo de esclavos con nodos
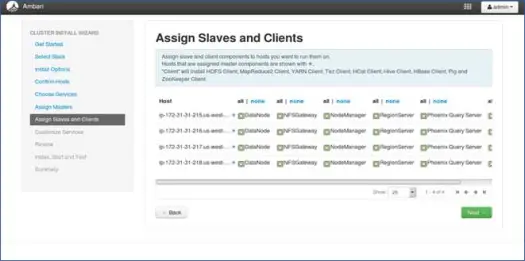
De manera similar a los maestros, asigne servicios esclavos en los nodos. En general, todos los nodos tendrán un proceso esclavo ejecutándose al menos para Datanodes y Nodemanagers.
9. Personaliza los servicios
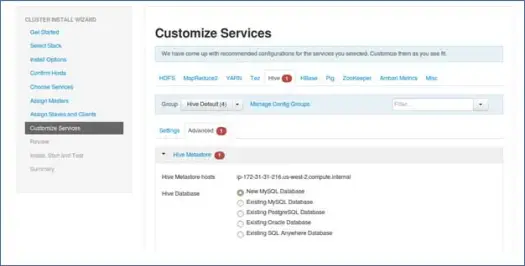
Esta es una página muy importante para los administradores.
Aquí puede configurar las propiedades de su clúster para que se adapte mejor a sus casos de uso.
También tendrá algunas propiedades requeridas como la contraseña de metastore de Hive (si se selecciona Hive), etc. Estos se señalarán con símbolos de error rojo.
10. Revisar y comenzar a aprovisionar
Asegúrese de revisar la configuración del clúster antes del lanzamiento, ya que esto evitará que se establezcan configuraciones incorrectas sin saberlo.
11. Inicie y quédese atrás hasta que el estado se vuelva VERDE.
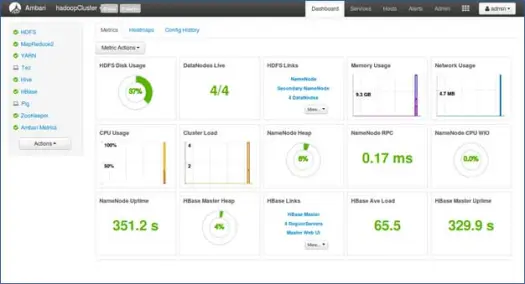
Próximos pasos
¡Yaay! Hemos instalado con éxito Hadoop y todos los componentes en todos los nodos del clúster. Ahora podemos comenzar a jugar con Hadoop.
Ambari ejecuta un trabajo de recuento de palabras de MapReduce para verificar si todo funciona correctamente. Revisemos el registro del trabajo ejecutado por el usuario ambari-qa.
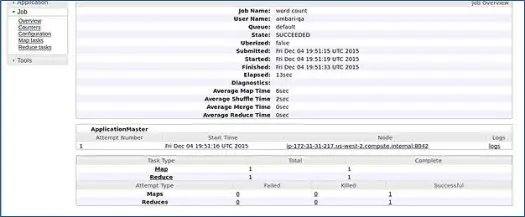
Como puede ver en la captura de pantalla anterior, el trabajo de WordCount se completó con éxito. Esto confirma que nuestro clúster está funcionando bien.
Conclusión
Eso es todo, ahora hemos aprendido cómo instalar Hadoop y sus componentes en el clúster de múltiples nodos usando una herramienta simple basada en la web llamada Apache Ambari. Apache Ambari nos brinda una interfaz más simple y nos ahorra muchos esfuerzos en la instalación, el monitoreo y la administración, lo que hubiera sido muy tedioso con tantos componentes y sus diferentes pasos de instalación y controles de monitoreo.
Déjame dejarte con un truco

El instalador de Ambari verifica /etc/lsb-release para obtener detalles del sistema operativo. En Linux Mint, el mismo archivo para la versión de Ubuntu se encuentra en /etc/upstream-release/lsb-release. Para engañar al instalador, simplemente reemplace el primero con el segundo (primero debe hacer una copia de seguridad del archivo).

En algún momento después de que termine la instalación, puede restaurar el original con:

PD : este es un truco sin garantías, funcionó para mí, así que pensé en compartirlo contigo.
Es un desarrollador/dev-ops y necesita instalar Hadoop rápidamente. Tenemos buenas noticias para usted, Ambari proporciona una forma en la que puede omitir el proceso completo del asistente y el proceso de instalación completo con un solo script, y lo traeré en la próxima publicación, así que estad atentos y hasta entonces ¡Feliz Hadooping!