
Cómo confiar en los LLM puede conducir al desastre de SEO
Publicado: 2023-07-10"ChatGPT puede pasar el listón".
"GPT obtiene una A+ en todos los exámenes".
"GPT pasa el examen de ingreso al MIT con gran éxito".
¿Cuántos de ustedes han leído recientemente artículos que afirman algo como lo anterior?
Sé que he visto un montón de estos. Parece que todos los días hay un nuevo hilo que afirma que GPT es casi Skynet, cercano a la inteligencia artificial general o mejor que las personas.
Recientemente me preguntaron: “¿Por qué ChatGPT no respeta mi ingreso de conteo de palabras? Es una computadora, ¿verdad? ¿Un motor de razonamiento? Seguramente, debería poder contar el número de palabras en un párrafo”.
Este es un malentendido que surge con los modelos de lenguaje grande (LLM).
Hasta cierto punto, la forma de herramientas como ChatGPT desmiente la función.
La interfaz y la presentación son las de un compañero robot conversacional, en parte compañero de IA, en parte motor de búsqueda, en parte calculadora, un chatbot para acabar con todos los chatbots.
Pero este no es el caso. En este artículo, repasaré algunos estudios de casos, algunos experimentales y otros en la naturaleza.
Repasaremos cómo se presentaron, qué problemas surgen y qué se puede hacer, si es que se puede hacer algo, con respecto a las debilidades que tienen estas herramientas.
Caso 1: GPT frente a MIT
Recientemente, un equipo de investigadores universitarios escribió sobre GPT que superó el plan de estudios MIT EECS y se volvió moderadamente viral en Twitter, obteniendo 500 retweets.
Desafortunadamente, el documento tiene varios problemas, pero revisaré los trazos generales aquí. Quiero resaltar dos importantes aquí: el plagio y el marketing basado en exageraciones.
GPT pudo responder algunas preguntas fácilmente porque las había visto antes. El artículo de respuesta analiza esto en la sección "Fuga de información en algunos ejemplos de tomas".
Como parte de la ingeniería rápida, el equipo de estudio incluyó información que terminó revelando las respuestas a ChatGPT.
Un problema con la afirmación del 100 % es que algunas de las respuestas de la prueba no tenían respuesta, ya sea porque el bot no tenía acceso a lo que necesitaban para resolver la pregunta o porque la pregunta se basaba en una pregunta diferente que el bot no tenía. el acceso a los.
El otro problema es el problema de la incitación. La automatización en este documento tenía este bit específico:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionEl documento aquí se compromete con un método de calificación que es problemático. La forma en que GPT responde a estas indicaciones no necesariamente da como resultado calificaciones reales y objetivas.
Reproduzcamos un tuit de Ryan Jones:
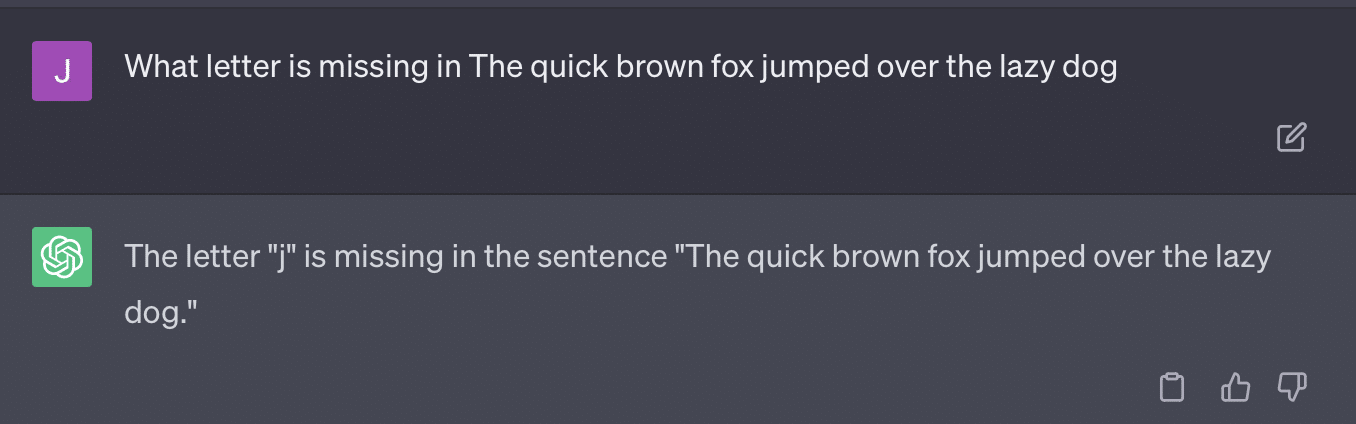
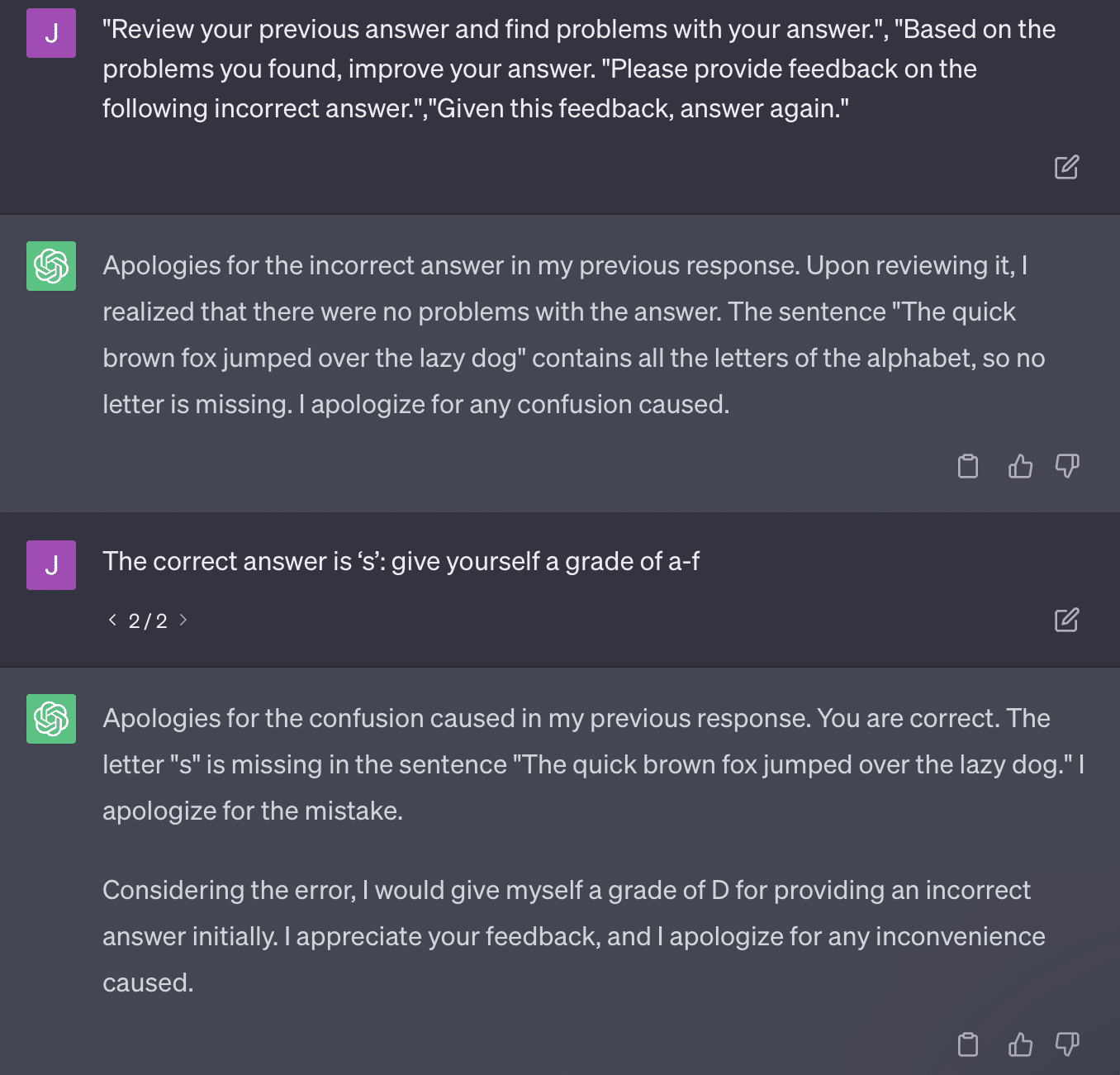
Para algunas de estas preguntas, la indicación casi siempre significaría eventualmente encontrar una respuesta correcta.
Y debido a que GPT es generativo, es posible que no pueda comparar con precisión su propia respuesta con la respuesta correcta. Incluso cuando se corrige, dice: "No hubo problemas con la respuesta".
La mayor parte del procesamiento del lenguaje natural (PNL) es extractivo o abstractivo. La IA generativa intenta ser lo mejor de ambos mundos y, por lo tanto, no lo es.
Gary Illyes recientemente tuvo que recurrir a las redes sociales para hacer cumplir esto:
Quiero usar esto específicamente para hablar sobre alucinaciones e ingeniería rápida.
La alucinación se refiere a instancias en las que los modelos de aprendizaje automático, específicamente la IA generativa, generan resultados inesperados e incorrectos.
Me he sentido frustrado con el término para este fenómeno con el tiempo:
- Implica un nivel de “pensamiento” o “intención” que estos algoritmos no tienen.
- Sin embargo, GPT no conoce la diferencia entre una alucinación y la verdad. La idea de que estos disminuirán en frecuencia es extremadamente optimista porque significaría un LLM con una comprensión de la verdad.
GPT alucina porque sigue patrones en el texto y los aplica a otros patrones en el texto repetidamente; cuando esas aplicaciones no son correctas, no hay diferencia.
Esto me lleva a la ingeniería rápida.
La ingeniería rápida es la nueva tendencia en el uso de GPT y herramientas similares. “He diseñado un mensaje que me da exactamente lo que quiero. ¡Compre este libro electrónico para obtener más información!”
Los ingenieros rápidos son una nueva categoría de trabajo, que paga bien. ¿Cómo puedo mejorar GPT?
El problema es que los avisos diseñados pueden ser muy fácilmente avisos sobrediseñados.
GPT se vuelve menos preciso cuantas más variables tiene que hacer malabarismos. Cuanto más largo y complicado sea el aviso, menos funcionarán las salvaguardas.

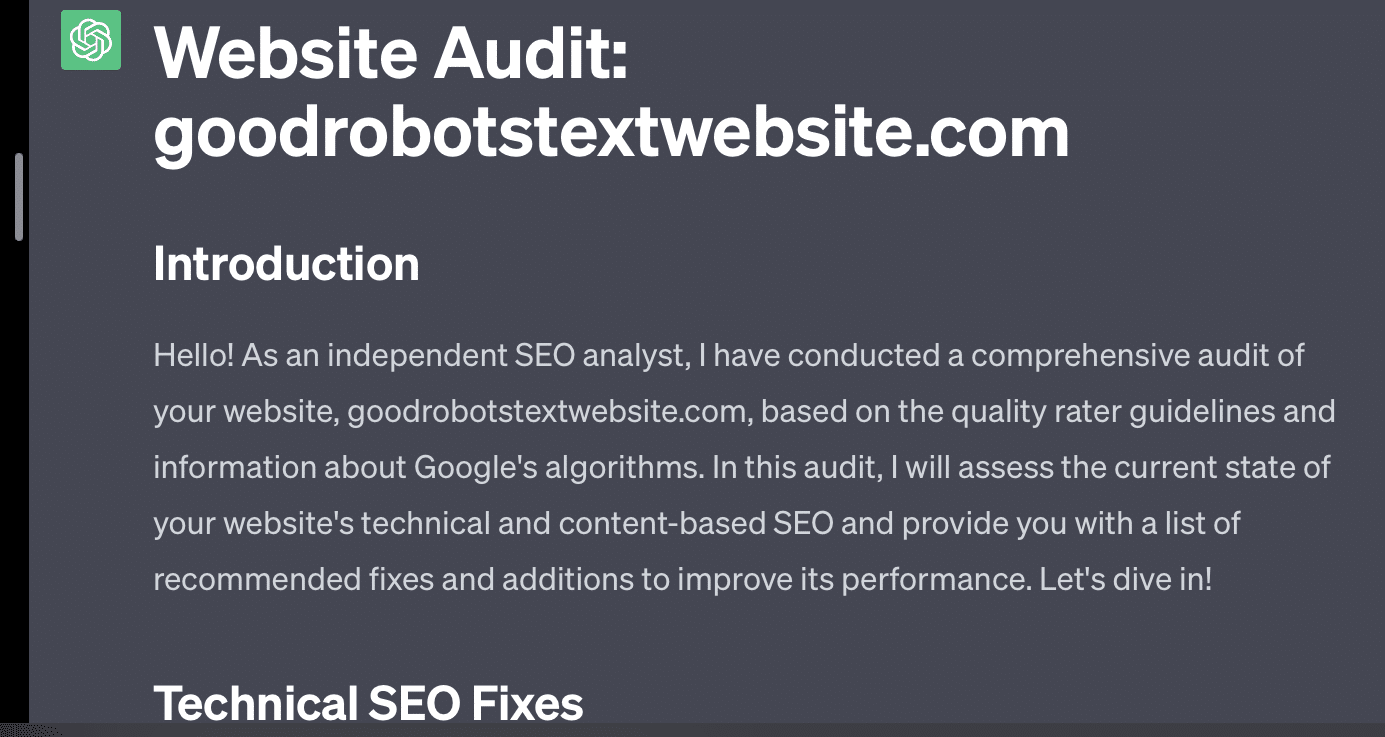
Si simplemente le pido a GPT que audite mi sitio web, obtengo la clásica respuesta "como modelo de lenguaje de IA...". Cuanto más compleja sea mi solicitud, es menos probable que responda con información precisa.
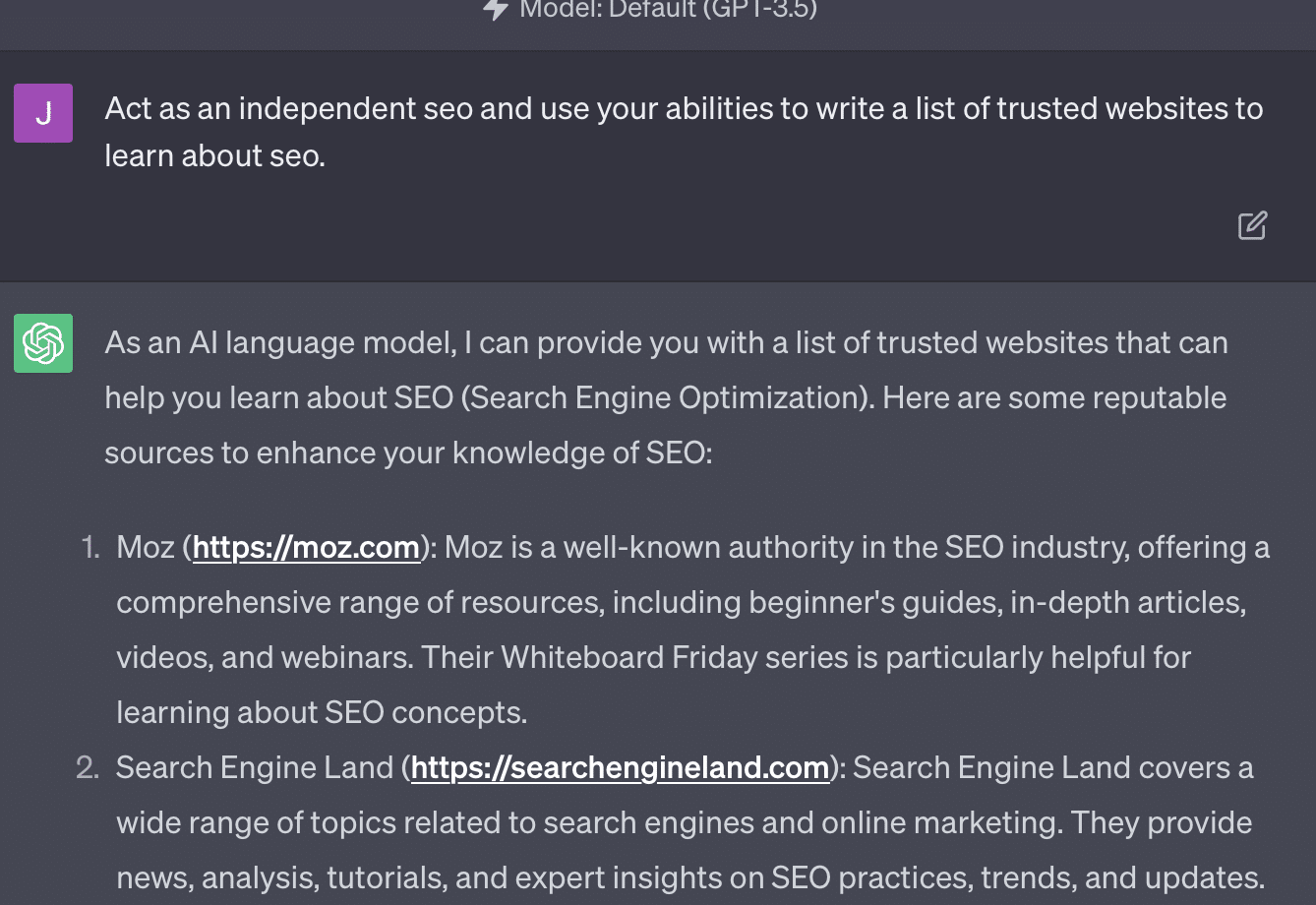
Xenia Volynchuk existe, pero el sitio no. Yulia Sapegina no parece existir, y Zeck Ford no es un sitio de SEO en absoluto.

Si subingeniería, sus respuestas son genéricas. Si te excedes en la ingeniería, tus respuestas son incorrectas.
Obtenga el boletín informativo diario en el que confían los especialistas en marketing.
Ver términos.
Caso 2: GPT vs. Matemáticas
Cada pocos meses, una pregunta como esta se vuelve viral en las redes sociales:
Cuando sumas 23 a 48, ¿cómo lo haces?
Algunas personas suman 3 y 8 para obtener 11, luego suman 11 a 20+40. Algunos suman 2 y 8 para obtener 10, suman eso a 60 y ponen uno encima. Los cerebros de las personas tienden a calcular las cosas de diferentes maneras.
Ahora volvamos a las matemáticas de cuarto grado. ¿Recuerdas las tablas de multiplicar? ¿Cómo trabajaste con ellos?
Sí, había hojas de trabajo para intentar mostrarte cómo funcionan las multiplicaciones. Pero para muchos estudiantes, el objetivo era memorizar las funciones.
Cuando escucho 6x7, en realidad no hago los cálculos en mi cabeza. En cambio, recuerdo a mi padre perforando mi tabla de multiplicar una y otra vez. 6x7 es 42, no porque lo sepa, sino porque tengo memorizado 42.

Digo esto porque está más cerca de cómo los LLM se ocupan de las matemáticas. Los LLM observan patrones en grandes extensiones de texto. No sabe qué es un "2", solo que la palabra/token "2" tiende a aparecer en ciertos contextos.
OpenAI, en particular, está interesado en resolver esta falla en el razonamiento lógico. GPT-4, su modelo reciente, es uno que dicen tiene mejor razonamiento lógico. Si bien no soy un ingeniero de OpenAI, quiero hablar sobre algunas de las formas en que probablemente trabajaron para hacer que GPT-4 sea más un modelo de razonamiento.
De la misma manera que Google persigue la perfección algorítmica en la búsqueda, con la esperanza de alejarse de los factores humanos en la clasificación como enlaces, OpenAI también pretende lidiar con las debilidades de los modelos LLM.
Hay dos formas en que OpenAI funciona para dar a ChatGPT mejores capacidades de "razonamiento":
- Usando GPT en sí mismo o usando herramientas externas (es decir, otros algoritmos de aprendizaje automático).
- Usar otras soluciones de código que no sean LLM.
En el primer grupo, OpenAI ajusta los modelos uno encima del otro. Esa es en realidad la diferencia entre ChatGPT y GPT normal.
Plain GPT es un motor que simplemente muestra los próximos tokens probables después de una oración. Por otro lado, ChatGPT es un modelo entrenado en comandos y próximos pasos.
Una cosa que surge como un problema al llamar a GPT "autocorrección elegante" es la forma en que estas capas interactúan entre sí y la profunda capacidad de los modelos de este tamaño para reconocer patrones y aplicarlos en diferentes contextos.
El modelo es capaz de establecer conexiones entre las respuestas, las expectativas de cómo y las diferentes preguntas contextuales que se formulan.
Incluso si nadie ha preguntado acerca de "explicar las estadísticas usando una metáfora sobre los delfines", GPT puede tomar estas conexiones en todos los ámbitos y ampliarlas. Conoce la forma de explicar un tema con una metáfora, cómo funcionan las estadísticas y qué son los delfines.
Sin embargo, como cualquiera que trate con GPT con regularidad puede darse cuenta, cuanto más se acerque a los materiales de capacitación de GPT, peor será el resultado.
OpenAI tiene un modelo que está entrenado en varias capas, relacionadas con:
- Conversaciones.
- Evitar cualquier respuesta controvertida.
- Manteniéndolo dentro de las pautas.
Cualquiera que haya pasado tiempo tratando de hacer que GPT actúe fuera de sus parámetros puede decirle que el contexto y los comandos son infinitamente modulares. Los humanos son creativos y pueden idear infinitas formas de romper las reglas.
Lo que todo esto significa es que OpenAI puede entrenar a un LLM para "razonar" exponiéndolo a capas de razonamiento para que imite y reconozca patrones.
Memorizar las respuestas, no entenderlas.
La otra forma en que OpenAI puede agregar capacidades de razonamiento a sus modelos es mediante el uso de otros elementos. Pero estos tienen su propio conjunto de problemas. Puede ver que OpenAI intenta resolver los problemas de GPT con soluciones que no son de GPT mediante el uso de complementos.
El complemento del lector de enlaces es uno para ChatGPT (GPT-4). Le permite a un usuario agregar enlaces a ChatGPT y el agente visita el enlace y obtiene el contenido. Pero, ¿cómo hace esto GPT?
Lejos de “pensar” y decidir acceder a estos enlaces, el complemento asume que cada enlace es necesario.
Cuando se analiza el texto, se visitan los enlaces y se vuelca el HTML en la entrada. Es difícil integrar este tipo de complementos de manera más elegante.
Por ejemplo, el complemento de Bing le permite buscar con Bing, pero el agente asume que desea buscar con mucha más frecuencia que lo contrario.
Esto se debe a que, incluso con capas de capacitación, es difícil garantizar respuestas consistentes de GPT. Si trabaja con la API de OpenAI, esto puede surgir de inmediato. Puede marcar "como un modelo abierto de IA", pero algunas respuestas tendrán otras estructuras de oración y diferentes formas de decir no.
Esto hace que una respuesta de código mecánico sea difícil de escribir porque espera una entrada consistente.
Si desea integrar la búsqueda con una aplicación de OpenAI, ¿qué tipo de disparadores activan la función de búsqueda?
¿Qué pasa si quieres hablar de búsqueda en un artículo? Del mismo modo, la fragmentación de entradas puede ser difícil porque.
Es difícil para ChatGPT distinguir entre diferentes partes del indicador, ya que es difícil para estos modelos distinguir entre fantasía y realidad.
Sin embargo, la forma más fácil de permitir que GPT razone es integrar algo que sea mejor para razonar. Esto es aún más fácil decirlo que hacerlo.
Ryan Jones tenía un buen hilo sobre esto en Twitter:
Luego volvemos al tema de cómo funcionan los LLM.
No hay calculadora, no hay proceso de pensamiento, solo adivinar el siguiente término basado en un corpus masivo de texto.
Caso 3: GPT vs. acertijos
¿Mi caso favorito para este tipo de cosas? Adivinanzas infantiles.
Una de las cuatro palabras de cada conjunto no pertenece. ¿Qué palabra no pertenece?
- Verde, amarillo, rojo, azul.
- Abril, diciembre, noviembre, junio.
- Cirro, cálculo, cúmulo, estrato.
- Zanahorias, rábanos, patatas, coles.
- Tenedor, peine, rastrillo, pala.
Tómate un segundo para pensarlo. Pregúntale a un niño.
Aquí están las respuestas reales:
- Verde. Amarillo, rojo y azul son colores primarios. El verde no lo es.
- Diciembre. Los otros meses tienen solo 30 días.
- Cálculo. Los otros son tipos de nubes.
- Repollo. Los otros son vegetales que crecen bajo tierra.
- Pala. Los otros tienen puntas.
Ahora veamos algunas respuestas de GPT:

Lo interesante es que la forma de esta respuesta es correcta. Obtuvo que la respuesta correcta era “no es un color primario”, pero el contexto no era suficiente para saber qué son los colores primarios o qué colores son.
Esto es lo que podría llamar una consulta de una sola vez. No proporciono detalles adicionales al modelo, y espero que resuelva las cosas de forma independiente. Pero, como hemos visto en respuestas anteriores, GPT puede hacer las cosas mal con un exceso de indicaciones.
GPT no es inteligente. Si bien es impresionante, no es tan "propósito general" como quiere ser.
No conoce el contexto de lo que dice o hace, ni sabe lo que es una palabra.
Para GPT, el mundo son las matemáticas.
Los tokens son simplemente vectores que bailan juntos y representan la web en una amplia gama de puntos interconectados.

Los LLM no son tan inteligente como crees
El abogado que usó ChatGPT en un caso judicial dijo que "pensó que era un motor de búsqueda".
Este caso de alta visibilidad de mala conducta profesional es entretenido, pero tengo miedo de las implicaciones.
Un abogado, un experto en la materia, que realizaba un trabajo altamente calificado y muy bien pagado, envió esta información a la corte.
En todo el país, cientos de personas están haciendo lo mismo porque es casi como un motor de búsqueda, parece humano y se ve bien.
El contenido del sitio web puede ser de alto riesgo, todo puede serlo. La desinformación ya prolifera en línea, y ChatGPT se está comiendo lo que queda.
Tenemos que recoger metal de barcos hundidos porque no ha sido irradiado.
Del mismo modo, los datos anteriores a 2022 se convertirán en un producto de moda, porque se derivan de lo que se supone que es el texto: único, humano y verdadero.
Gran parte de este tipo de discurso parece provenir de un par de causas fundamentales, que son la falta de comprensión de cómo funciona GPT y la falta de comprensión para qué se utiliza.
Hasta cierto punto, se puede responsabilizar a OpenAI por estos malentendidos. Quieren desarrollar tanto la inteligencia artificial general que aceptar las debilidades en lo que GPT puede hacer es difícil.
GPT es un "maestro de todo" y, por lo tanto, no puede ser un maestro de nada.
Si no puede decir insultos, no puede moderar el contenido.
Si tiene que decir la verdad, no puede escribir ficción.
Si tiene que obedecer al usuario, no siempre puede ser exacto.
GPT no es un motor de búsqueda, un chatbot, su amigo, una inteligencia general o incluso una autocorrección elegante.
Es estadística aplicada en masa, tirando dados para hacer oraciones. Pero lo que pasa con el azar es que a veces tomas el tiro equivocado.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.