
Estimación del tiempo, el costo y los entregables de un proyecto de aplicación ML
Publicado: 2019-11-20Imagínate que vas a comprar una cartera personalizada en una tienda.
Aunque sabe qué tipo de billetera necesita, no sabe el costo o el tiempo necesario para obtener la versión personalizada.
Lo mismo ocurre con los proyectos de aprendizaje automático. Y para ayudarte con este dilema, te proporcionamos información detallada para que tengas un proyecto exitoso.
Machine Learning es como una moneda que tiene dos caras .
Por un lado, ayuda a eliminar incertidumbres de los procesos. Pero por otro lado , su desarrollo está lleno de incertidumbre.
Si bien el resultado final de casi todos los proyectos de Machine Learning (ML) es una solución que mejora las empresas y agiliza los procesos; la parte de desarrollo tiene una historia completamente diferente para compartir.
A pesar de que ML ha jugado un papel importante en el cambio de la historia de ganancias y el modelo comercial de varias marcas de aplicaciones móviles establecidas, todavía opera en forma incipiente. Esta novedad, a su vez, hace que sea aún más desafiante para los desarrolladores de aplicaciones móviles manejar un plan de proyecto de ML y prepararlo para la producción, teniendo en cuenta las limitaciones de tiempo y costo.
Una solución ( probablemente la única solución ) a esta dificultad es la estimación del tiempo, el costo y los resultados del proyecto de la aplicación Machine Learning en blanco y negro.
Pero antes de continuar con esas secciones, primero veamos qué hace que valga la pena la dificultad y la quema de las velas nocturnas.
¿Por qué su aplicación necesita un marco de aprendizaje automático?
Quizás esté pensando cómo es que estamos hablando de un marco en medio de estimaciones de tiempo, costo y entregables.
Pero la verdadera razón detrás del tiempo y el costo radica aquí, que nos informa sobre nuestro motivo detrás del desarrollo de la aplicación. Si necesita aprendizaje automático para:
Por ofrecer una experiencia personalizada
Para Incorporar Búsqueda Avanzada m
Para predecir el comportamiento del usuario
Para una mejor seguridad
Para una participación profunda del usuario
Con base en estas razones, el tiempo, el costo y el entregable dependerán en consecuencia.
Tipos de modelos de aprendizaje automático
¿Qué tipo de modelo consideraría para ajustar el tiempo y el costo? Si no lo sabe, le proporcionamos información para que lo entienda y elija modelos, según sus requisitos y presupuesto.
El aprendizaje automático en medio de sus diferentes casos de uso se puede clasificar en tres tipos de modelos, que desempeñan un papel en la conversión de aplicaciones rudimentarias en aplicaciones móviles inteligentes : supervisadas, no supervisadas y de refuerzo. El conocimiento de lo que representan estos modelos de aprendizaje automático es lo que ayuda a definir cómo desarrollar una aplicación habilitada para ML.
Aprendizaje supervisado
Es el proceso donde se dota de datos al sistema donde se rotulan correctamente las entradas del algoritmo y sus salidas. Dado que la información de entrada y salida está etiquetada, el sistema está capacitado para identificar los patrones en los datos dentro del algoritmo.
Se vuelve aún más beneficioso porque se utiliza para predecir el resultado sobre la base de datos de entrada futuros. Un ejemplo de esto se puede ver cuando las redes sociales reconocen la cara de alguien cuando se le etiqueta en una fotografía.
Aprendizaje sin supervisión
En el caso del aprendizaje no supervisado, los datos se introducen en el sistema pero sus salidas no se etiquetan como en el caso del modelo supervisado. Permite que el sistema identifique datos y determine patrones a partir de la información. Una vez que se almacenan los patrones, todas las entradas futuras se asignan al patrón para producir una salida.
Un ejemplo de este modelo se puede ver en los casos en que las redes sociales dan sugerencias a los amigos sobre la base de varios datos conocidos, como la demografía, la educación, etc.
Aprendizaje reforzado
Como en el caso del aprendizaje no supervisado, los datos que se entregan al sistema en el aprendizaje por refuerzo tampoco están etiquetados. Ambos tipos de aprendizaje automático difieren en que cuando se produce el resultado correcto, se le dice al sistema que el resultado es correcto. Este tipo de aprendizaje permite que el sistema aprenda del entorno y las experiencias.
Un ejemplo de esto se puede ver en Spotify. La aplicación Spotify hace una recomendación de canciones que los usuarios tienen que dar a favor o en contra. Sobre la base de la selección, la aplicación Spotify aprende el gusto musical de los usuarios.
Ciclo de vida de un proyecto de aprendizaje automático
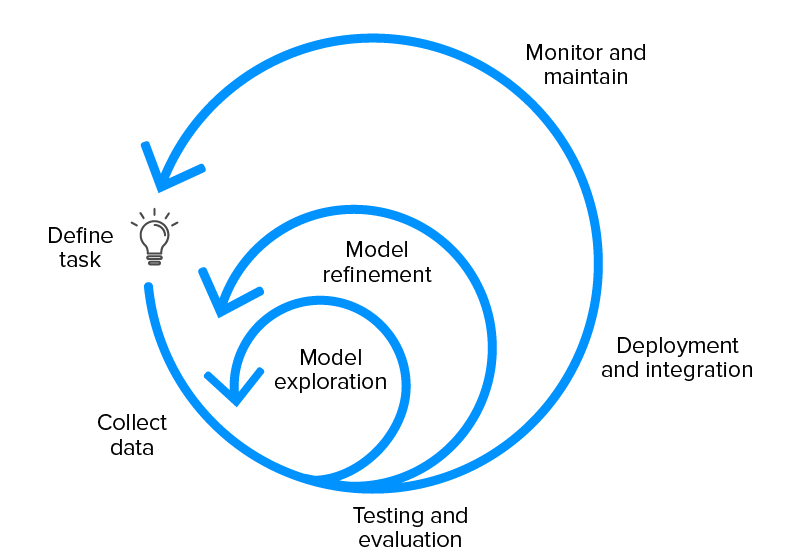
El ciclo de vida de la línea de tiempo de los entregables de un proyecto de Machine Learning generalmente aparece así:
Configuración del plan de proyecto de ML
- Definir la tarea y los requisitos.
- Identificar la viabilidad del proyecto.
- Discutir las ventajas y desventajas generales del modelo
- Crear una base de código de proyecto
Recopilación y etiquetado de datos
- Crear la documentación de etiquetado
- Cree la canalización de ingestión de datos
- Validación de la calidad de los datos
Exploración de modelos
- Establecer la línea de base para el rendimiento del modelo
- Cree un modelo simple con canalización de datos inicial
- Pruebe ideas paralelas durante las primeras etapas
- Encuentre el modelo SoTA para el dominio del problema, si lo hay, y reproduzca los resultados.
Refinamiento del modelo
- Realice optimizaciones centradas en el modelo
- Depurar modelos a medida que se agrega complejidad
- Realizar análisis de errores para descubrir modos de falla.
Probar y evaluar
- Evaluar el modelo en la distribución de prueba
- Revise la métrica de evaluación del modelo, asegurándose de que impulse el comportamiento deseable del usuario
- Escribir pruebas para: función de inferencia del modelo, canalización de datos de entrada, escenarios explícitos esperados en la producción.
Despliegue del modelo
- Exponer el modelo a través de la API REST
- Implemente el nuevo modelo en un subconjunto de usuarios para asegurarse de que todo funcione sin problemas antes de la implementación final.
- Tener la capacidad de revertir los modelos a su versión anterior.
- Supervise los datos en vivo.
Mantenimiento del modelo
- Vuelva a entrenar el modelo para evitar la obsolescencia del modelo
- Educar al equipo si hay una transferencia en la propiedad del modelo.
¿Cómo estimar el alcance de un proyecto de aprendizaje automático?
El equipo de aprendizaje automático de Appinventiv, después de leer detenidamente el tipo de aprendizaje automático y el ciclo de vida de desarrollo, continúa para definir la estimación del proyecto de la aplicación de aprendizaje automático del proyecto siguiendo estas fases:
Fase 1 – Descubrimiento (7 a 14 días)
La hoja de ruta del plan del proyecto de ML comienza con la definición de un problema. Analiza los problemas y las ineficiencias operativas que deben abordarse.
El objetivo aquí es identificar los requisitos y ver si Machine Learning cumple con los objetivos comerciales . La etapa requiere que nuestros ingenieros se reúnan con la gente de negocios del lado del cliente para comprender su visión en términos de los problemas que buscan resolver.
En segundo lugar, el equipo de desarrollo debe identificar qué tipo de datos tiene y si necesitaría obtenerlos de un servicio externo.
A continuación, los desarrolladores deben evaluar si pueden supervisar los algoritmos, si devuelve la respuesta correcta cada vez que se realiza una predicción.
Entregable : una declaración del problema que definiría si un proyecto es trivial o complejo.
Fase 2 – Exploración (6 a 8 semanas)
El objetivo de esta etapa es desarrollar una prueba de concepto que luego se pueda instalar como API. Una vez que se entrena un modelo de referencia, nuestro equipo de expertos en ML estima el rendimiento de la solución lista para producción.
Esta etapa nos brinda claridad sobre qué rendimiento se debe esperar con las métricas planificadas en la etapa de descubrimiento.
Entregable : una prueba de concepto
Fase 3 - Desarrollo (4+ meses)
Esta es la etapa en la que el equipo trabaja de forma iterativa hasta llegar a una respuesta lista para la producción. Debido a que hay muchas menos incertidumbres cuando el proyecto llega a esta etapa, la estimación se vuelve muy precisa.
Pero en caso de que el resultado no mejore, los desarrolladores tendrían que aplicar un modelo diferente o volver a trabajar en los datos o incluso cambiar el método, si es necesario.
En esta etapa, nuestros desarrolladores trabajan en sprints y deciden qué se debe hacer después de cada iteración individual. Los resultados de cada sprint se pueden predecir de manera efectiva.

Si bien el resultado del sprint se puede predecir de manera efectiva, planificar los sprints con anticipación puede ser un error en el caso de Machine Learning, ya que estará trabajando en aguas desconocidas.
Entregable : una solución de aprendizaje automático lista para la producción
Fase 4 – Mejora (continua)
Una vez desplegados, los responsables de la toma de decisiones casi siempre tienen prisa por finalizar el proyecto para ahorrar costes. Si bien la fórmula funciona en el 80 % de los proyectos, no ocurre lo mismo en las aplicaciones de Machine Learning.
Lo que sucede es que los datos cambian a lo largo de la línea de tiempo del proyecto de Machine Learning. Esta es la razón por la cual un modelo de IA debe ser monitoreado y revisado constantemente, para evitar que se degrade y proporcionar una IA segura que permita el desarrollo de aplicaciones móviles .
Los proyectos centrados en Machine Learning requieren tiempo para lograr resultados satisfactorios. Incluso cuando encuentre que sus algoritmos superan los puntos de referencia desde el principio, es probable que sean un golpe y que el programa se pierda cuando se usa en un conjunto de datos diferente.
Factores que afectan el costo total
La forma de desarrollar un sistema de aprendizaje automático tiene algunas características distintivas, como problemas relacionados con los datos y factores relacionados con el rendimiento que deciden el último gasto.
Problemas relacionados con los datos
El desarrollo de un aprendizaje automático confiable no solo depende de una codificación fenomenal, sino que la calidad y cantidad de la información de capacitación también juega un papel crucial.
- Falta de datos adecuados
- Procedimientos complejos de extracción, transformación y carga
- Procesamiento de datos no estructurados
Problemas relacionados con el rendimiento
El rendimiento adecuado del algoritmo es otro factor de costo importante, ya que un algoritmo de alta calidad requiere varias rondas de sesiones de ajuste.
- La tasa de precisión varía
- Rendimiento de los algoritmos de procesamiento
¿Cómo estimamos el costo de un proyecto de aprendizaje automático?
Cuando hablamos de la estimación del costo de un proyecto de aprendizaje automático, es importante identificar primero de qué tipo de proyecto se habla.
Hay principalmente tres tipos de proyectos de aprendizaje automático , que desempeñan un papel en la respuesta ¿Cuánto cuesta el aprendizaje automático?
Primero: este tipo ya tiene una solución: tanto la arquitectura del modelo como el conjunto de datos ya existen. Este tipo de proyectos son prácticamente gratuitos, por lo que no hablaremos de ellos.
Segundo: estos proyectos necesitan investigación fundamental: aplicación de ML en un dominio completamente nuevo o en estructuras de datos diferentes en comparación con los modelos convencionales. El costo de estos tipos de proyectos suele ser uno que la mayoría de las nuevas empresas no pueden pagar.
Tercero: estos son en los que nos vamos a centrar en nuestra estimación de costos. Aquí, toma la arquitectura del modelo y los algoritmos que ya existen y luego los cambia para adaptarlos a los datos en los que está trabajando.
Pasemos ahora a la parte donde estimamos el costo del proyecto ML.
El costo de los datos
Los datos son la moneda principal de un proyecto de Machine Learning. El máximo de las soluciones y la investigación se centra en las variaciones del modelo de aprendizaje supervisado. Es un hecho bien conocido que cuanto más profundo es el aprendizaje supervisado, mayor es la necesidad de datos anotados y, a su vez, mayor es el costo de desarrollo de la aplicación Machine Learning .
Ahora, mientras que servicios como Scale y Mechanical Turk de Amazon pueden ayudarlo con la recopilación y anotación de datos, ¿qué pasa con la calidad?
Puede llevar mucho tiempo verificar y luego corregir las muestras de datos. La solución al problema tiene dos caras: subcontratar la recopilación de datos o refinarla internamente.
Debe subcontratar la mayor parte del trabajo de validación y refinamiento de datos y luego designar a una o dos personas internamente para limpiar las muestras de datos y etiquetarlas.
El costo de la investigación
La parte de investigación del proyecto, como compartimos anteriormente, se ocupa del estudio de viabilidad de nivel de entrada, la búsqueda de algoritmos y la fase de experimentación. La información que suele surgir de un taller de entrega de productos . Básicamente, la etapa exploratoria es la que atraviesa todo proyecto antes de su producción.
Completar la etapa con su máxima perfección es un proceso que viene con un número adjunto en el costo de implementación de la discusión ML.
El costo de producción
La parte de producción del costo del proyecto de aprendizaje automático se compone del costo de infraestructura, el costo de integración y el costo de mantenimiento. De estos costos, tendrá que hacer los menores gastos con el cómputo en la nube. Pero eso también variará de la complejidad de un algoritmo a otro.
El costo de integración varía de un caso de uso a otro. Por lo general, es suficiente poner un punto final de API en la nube y documentarlo para luego ser utilizado por el resto del sistema.
Un factor clave que las personas tienden a pasar por alto al desarrollar un proyecto de aprendizaje automático es la necesidad de pasar por un soporte continuo durante todo el ciclo de vida del proyecto. Los datos que provienen de las API deben limpiarse y anotarse correctamente. Luego, los modelos deben entrenarse con nuevos datos y probarse e implementarse.
Además de los puntos mencionados anteriormente, hay dos factores más que tienen importancia en la estimación del costo para desarrollar una aplicación AI/ML .
Desafíos en el desarrollo de aplicaciones de aprendizaje automático

Por lo general, cuando se elabora una estimación del proyecto de una aplicación de aprendizaje automático, también se tienen en cuenta los desafíos de desarrollo asociados con ella. Pero puede haber casos en los que los desafíos se encuentren a la mitad del proceso de desarrollo de aplicaciones con tecnología ML. En casos como estos, la estimación general de tiempo y costo aumenta automáticamente.
Los desafíos para los proyectos de Machine Learning pueden variar desde:
- Decidir qué conjunto de funciones se convertiría en funciones de aprendizaje automático
- Déficit de talento en el dominio de IA y Machine Learning
- La adquisición de conjuntos de datos es costosa
- Se necesita tiempo para lograr resultados satisfactorios
Conclusión
Estimar la mano de obra y el tiempo necesarios para terminar un proyecto de software es relativamente fácil cuando se desarrolla sobre la base de diseños modulares y es manejado por un equipo experimentado siguiendo un enfoque Agile . Sin embargo, lo mismo se vuelve aún más difícil cuando se trabaja en la creación de la estimación del proyecto de la aplicación de aprendizaje automático en términos de tiempo y esfuerzo.
Aunque los objetivos pueden estar bien definidos, no existe la garantía de si un modelo logrará o no el resultado deseado. Por lo general, no es posible reducir el alcance y luego ejecutar el proyecto en una configuración de caja de tiempo a través de una fecha de entrega predefinida.
Es de suma importancia que identifique que habrá incertidumbres. Un enfoque que puede ayudar a mitigar los retrasos es garantizar que los datos de entrada estén en el formato correcto para Machine Learning.
Pero, en última instancia, independientemente del enfoque que planee seguir, solo se considerará exitoso cuando se asocie con una agencia de desarrollo de aplicaciones de aprendizaje automático que sepa cómo desarrollar e implementar las complejidades en su forma más simple.
Preguntas frecuentes sobre la estimación del proyecto de la aplicación Machine Learning
P. ¿Por qué usar Machine Learning para desarrollar una aplicación?
Hay una serie de beneficios que las empresas pueden aprovechar con la incorporación de Machine Learning en sus aplicaciones móviles. Algunos de los más frecuentes están en el frente del marketing de aplicaciones:
- Ofreciendo una experiencia personalizada
- Búsqueda Avanzada
- Predecir el comportamiento del usuario
- Compromiso más profundo del usuario
P. ¿Cómo puede ayudar el aprendizaje automático a su empresa?
Los beneficios de Machine Learning para las empresas van más allá de marcarlas como una marca disruptiva. Se refleja en sus ofertas cada vez más personalizadas y en tiempo real.
El Machine Learning puede ser la fórmula secreta que acerque a las empresas a sus clientes, tal y como ellos quieren que se les acerque.
P. ¿Cómo estimar el ROI en el desarrollo de un proyecto de aprendizaje automático?
Si bien el artículo lo habría ayudado a establecer la estimación del proyecto de la aplicación Machine Learning, calcular el ROI es un juego diferente. También deberá tener en cuenta el costo de oportunidad en la mezcla. Además, deberá analizar las expectativas que su empresa tiene del proyecto.
P. ¿Qué plataforma es mejor para un proyecto de ML?
Su elección de conectarse con una empresa de desarrollo de aplicaciones de Android o con desarrolladores de iOS dependerá completamente de su base de usuarios y de la intención, ya sea para generar ganancias o centrarse en el valor.