
Una guía de SEO para comprender los modelos de lenguaje extenso (LLM)
Publicado: 2023-05-08¿Debo usar modelos de lenguaje grandes para la investigación de palabras clave? ¿Pueden pensar estos modelos? ¿ChatGPT es mi amigo?
Si te has estado haciendo estas preguntas, esta guía es para ti.
Esta guía cubre lo que los SEO necesitan saber sobre modelos de lenguaje grandes, procesamiento de lenguaje natural y todo lo demás.
Grandes modelos de lenguaje, procesamiento de lenguaje natural y más en términos simples
Hay dos formas de lograr que una persona haga algo: decirle que lo haga o esperar que lo haga ella misma.
Cuando se trata de informática, la programación le dice al robot que lo haga, mientras que el aprendizaje automático espera que el robot lo haga por sí mismo. El primero es aprendizaje automático supervisado y el segundo es aprendizaje automático no supervisado.
El procesamiento del lenguaje natural (NLP) es una forma de dividir el texto en números y luego analizarlo usando computadoras.
Las computadoras analizan patrones en las palabras y, a medida que avanzan, en las relaciones entre las palabras.
Un modelo de aprendizaje automático de lenguaje natural no supervisado se puede entrenar en muchos tipos diferentes de conjuntos de datos.
Por ejemplo, si entrenó un modelo de lenguaje en reseñas promedio de la película "Waterworld", tendría un resultado bueno para escribir (o comprender) reseñas de la película "Waterworld".
Si lo entrenaras con las dos reseñas positivas que hice de la película "Waterworld", solo entendería esas reseñas positivas.
Los modelos de lenguaje grande (LLM) son redes neuronales con más de mil millones de parámetros. Son tan grandes que están más generalizados. No solo están capacitados en críticas positivas y negativas de "Waterworld", sino también en comentarios, artículos de Wikipedia, sitios de noticias y más.
Los proyectos de aprendizaje automático funcionan mucho con el contexto: cosas dentro y fuera de contexto.
Si tiene un proyecto de aprendizaje automático que funciona para identificar errores y mostrarle un gato, no será bueno en ese proyecto.
Es por eso que cosas como los autos sin conductor son tan difíciles: hay tantos problemas fuera de contexto que es muy difícil generalizar ese conocimiento.
Los LLM parecen y pueden ser mucho más generalizado que otros proyectos de aprendizaje automático. Esto se debe al gran tamaño de los datos y la capacidad de analizar miles de millones de relaciones diferentes.
Hablemos de una de las tecnologías innovadoras que permiten esto: los transformadores.
Explicando los transformadores desde cero
Un tipo de arquitectura de redes neuronales, los transformadores han revolucionado el campo de la PNL.
Antes de los transformadores, la mayoría de los modelos de NLP se basaban en una técnica llamada redes neuronales recurrentes (RNN), que procesaban el texto secuencialmente, una palabra a la vez. Este enfoque tenía sus limitaciones, como ser lento y tener dificultades para manejar dependencias de largo alcance en el texto.
Los transformadores cambiaron esto.
En el documento histórico de 2017, "La atención es todo lo que necesita", Vaswani et al. introdujo la arquitectura del transformador.
En lugar de procesar el texto secuencialmente, los transformadores usan un mecanismo llamado "autoatención" para procesar palabras en paralelo, lo que les permite capturar dependencias de largo alcance de manera más eficiente.
La arquitectura anterior incluía RNN y algoritmos de memoria a corto plazo.
Los modelos recurrentes como estos se usaban (y aún se usan) comúnmente para tareas que involucran secuencias de datos, como texto o voz.
Sin embargo, estos modelos tienen un problema. Solo pueden procesar los datos una pieza a la vez, lo que los ralentiza y limita la cantidad de datos con los que pueden trabajar. Este procesamiento secuencial realmente limita la capacidad de estos modelos.
Los mecanismos de atención se introdujeron como una forma diferente de procesar datos de secuencias. Permiten que un modelo observe todas las piezas de datos a la vez y decida qué piezas son las más importantes.
Esto puede ser realmente útil en muchas tareas. Sin embargo, la mayoría de los modelos que usaban atención también usan procesamiento recurrente.
Básicamente, tenían esta forma de procesar todos los datos a la vez, pero aún necesitaban verlos en orden. El artículo de Vaswani et al. flotaba, "¿Qué pasa si solo usamos el mecanismo de atención?"
La atención es una forma en que el modelo se centra en ciertas partes de la secuencia de entrada al procesarla. Por ejemplo, cuando leemos una oración, naturalmente prestamos más atención a algunas palabras que a otras, dependiendo del contexto y de lo que queramos entender.
Si observa un transformador, el modelo calcula una puntuación para cada palabra en la secuencia de entrada en función de su importancia para comprender el significado general de la secuencia.
Luego, el modelo usa estos puntajes para sopesar la importancia de cada palabra en la secuencia, lo que le permite concentrarse más en las palabras importantes y menos en las que no lo son.
Este mecanismo de atención ayuda al modelo a capturar dependencias y relaciones de largo alcance entre palabras que pueden estar muy separadas en la secuencia de entrada sin tener que procesar toda la secuencia secuencialmente.
Esto hace que el transformador sea tan poderoso para las tareas de procesamiento del lenguaje natural, ya que puede comprender de forma rápida y precisa el significado de una oración o una secuencia de texto más larga.
Tomemos el ejemplo de un modelo de transformador que procesa la oración "El gato se sentó en el tapete".
Cada palabra de la oración se representa como un vector, una serie de números, utilizando una matriz de incrustación. Digamos que las incorporaciones para cada palabra son:
- El : [0.2, 0.1, 0.3, 0.5]
- gato : [0.6, 0.3, 0.1, 0.2]
- sábado : [0.1, 0.8, 0.2, 0.3]
- encendido : [0.3, 0.1, 0.6, 0.4]
- el : [0.5, 0.2, 0.1, 0.4]
- estera : [0.2, 0.4, 0.7, 0.5]
Luego, el transformador calcula una puntuación para cada palabra de la oración en función de su relación con todas las demás palabras de la oración.
Esto se hace usando el producto escalar de la incrustación de cada palabra con las incrustaciones de todas las demás palabras en la oración.
Por ejemplo, para calcular la puntuación de la palabra "gato", tomaríamos el producto escalar de su incrustación con las incrustaciones de todas las demás palabras:
- “ El gato ”: 0,2*0,6 + 0,1*0,3 + 0,3*0,1 + 0,5*0,2 = 0,24
- " gato sentado ": 0,6*0,1 + 0,3*0,8 + 0,1*0,2 + 0,2*0,3 = 0,31
- " gato en ": 0,6*0,3 + 0,3*0,1 + 0,1*0,6 + 0,2*0,4 = 0,39
- “ gato el “: 0.6*0.5 + 0.3*0.2 + 0.1*0.1 + 0.2*0.4 = 0.42
- " alfombrilla para gatos ": 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Estos puntajes indican la relevancia de cada palabra para la palabra "gato". Luego, el transformador usa estos puntajes para calcular una suma ponderada de las incrustaciones de palabras, donde los pesos son los puntajes.
Esto crea un vector de contexto para la palabra "gato" que considera las relaciones entre todas las palabras de la oración. Este proceso se repite para cada palabra de la oración.
Piense en ello como el transformador dibujando una línea entre cada palabra de la oración en función del resultado de cada cálculo. Algunas líneas son más tenues y otras menos.
El transformador es un nuevo tipo de modelo que solo utiliza la atención sin ningún procesamiento recurrente. Esto lo hace mucho más rápido y capaz de manejar más datos.
Cómo utiliza GPT los transformadores
Puede recordar que en el anuncio BERT de Google, se jactaron de que permitía que la búsqueda comprendiera el contexto completo de una entrada. Esto es similar a cómo GPT puede usar transformadores.
Usemos una analogía.
Imagina que tienes un millón de monos, cada uno sentado frente a un teclado.
Cada mono pulsa teclas al azar en su teclado, generando cadenas de letras y símbolos.
Algunas cadenas no tienen sentido, mientras que otras pueden parecerse a palabras reales o incluso a oraciones coherentes.
Un día, uno de los entrenadores del circo ve que un mono ha escrito "Ser o no ser", por lo que el entrenador le da una golosina al mono.
Los otros monos ven esto y comienzan a intentar imitar al mono exitoso, esperando su propio premio.
A medida que pasa el tiempo, algunos monos comienzan a producir cadenas de texto mejores y más coherentes, mientras que otros continúan produciendo galimatías.
Eventualmente, los monos pueden reconocer e incluso emular patrones coherentes en el texto.
Los LLM tienen una ventaja sobre los monos porque los LLM se capacitan primero en miles de millones de textos. Ya pueden ver los patrones. También entienden los vectores y las relaciones entre estos fragmentos de texto.
Esto significa que pueden usar esos patrones y relaciones para generar texto nuevo que se asemeje al lenguaje natural.
GPT, que significa Transformador preentrenado generativo, es un modelo de lenguaje que utiliza transformadores para generar texto en lenguaje natural.
Se entrenó con una gran cantidad de texto de Internet, lo que le permitió aprender los patrones y las relaciones entre palabras y frases en lenguaje natural.
El modelo funciona tomando un aviso o unas pocas palabras de texto y usando los transformadores para predecir qué palabras deberían venir a continuación en función de los patrones que ha aprendido de sus datos de entrenamiento.
El modelo continúa generando texto palabra por palabra, usando el contexto de las palabras anteriores para informar las siguientes.
GPT en acción
Uno de los beneficios de GPT es que puede generar texto en lenguaje natural que es altamente coherente y contextualmente relevante.
Esto tiene muchas aplicaciones prácticas, como generar descripciones de productos o responder consultas de servicio al cliente. También se puede utilizar de forma creativa, como generar poesía o cuentos.
Sin embargo, es sólo un modelo de lenguaje. Está entrenado en datos, y esos datos pueden estar desactualizados o ser incorrectos.
- No tiene fuente de conocimiento.
- No puede buscar en Internet.
- No “sabe” nada.
Simplemente adivina qué palabra viene a continuación.
Veamos algunos ejemplos:
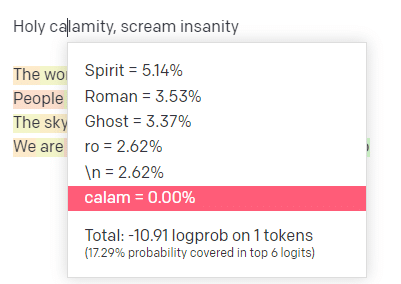
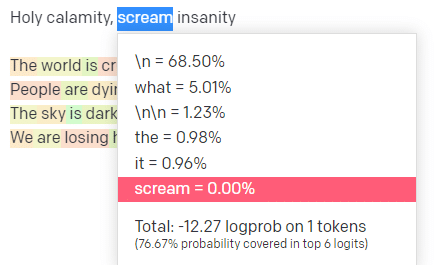
En el patio de recreo de OpenAI, conecté la primera línea de la pista clásica de Handsome Boy Modeling School 'Holy calamity [[Bear Witness ii]]'.
Envié la respuesta para que podamos ver la probabilidad tanto de mi entrada como de las líneas de salida. Así que repasemos cada parte de lo que esto nos dice.
Para la primera palabra/token, ingreso "Santo". Podemos ver que la próxima entrada más esperada es Spirit, Roman y Ghost.
También podemos ver que los seis primeros resultados cubren solo el 17,29 % de las probabilidades de lo que viene a continuación: lo que significa que hay ~82 % de otras posibilidades que no podemos ver en esta visualización.
Discutamos brevemente las diferentes entradas que puede usar en esto y cómo afectan su salida.
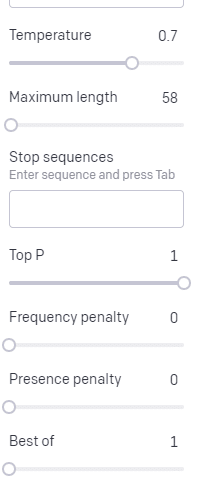
La temperatura es la probabilidad de que el modelo capte palabras distintas de las que tienen la probabilidad más alta, la P superior es cómo selecciona esas palabras.
Entonces, para la entrada "Holy Calamity", la P superior es cómo seleccionamos el grupo de los siguientes tokens [Fantasma, Romano, Espíritu], y la temperatura es la probabilidad de que elija el token más probable frente a más variedad.
Si la temperatura es más alta, es más probable que elija una ficha menos probable .
Entonces, una temperatura alta y una P superior alta probablemente serán más salvajes. Es elegir entre una amplia variedad (alta P superior) y es más probable que elija tokens sorprendentes.


Mientras que una P superior de alta temperatura pero más baja elegirá opciones sorprendentes de una muestra más pequeña de posibilidades:

Y bajar la temperatura solo elige las próximas fichas más probables:

Jugar con estas probabilidades puede, en mi opinión, darle una buena idea de cómo funcionan este tipo de modelos.
Está mirando una colección de próximas selecciones probables basadas en lo que ya se ha completado.
¿Qué significa esto en realidad?
En pocas palabras, los LLM toman una colección de entradas, las agitan y las convierten en salidas.
He escuchado a la gente bromear sobre si eso es tan diferente de las personas.
Pero no es como las personas: los LLM no tienen una base de conocimientos. No están extrayendo información sobre una cosa. Están adivinando una secuencia de palabras basándose en la última.
Otro ejemplo: piensa en una manzana. ¿Qué te viene a la mente?
Tal vez puedas rotar uno en tu mente.
Tal vez recuerdes el olor de un huerto de manzanas, la dulzura de una dama rosa, etc.
Tal vez pienses en Steve Jobs.
Ahora veamos qué devuelve el mensaje "piensa en una manzana".
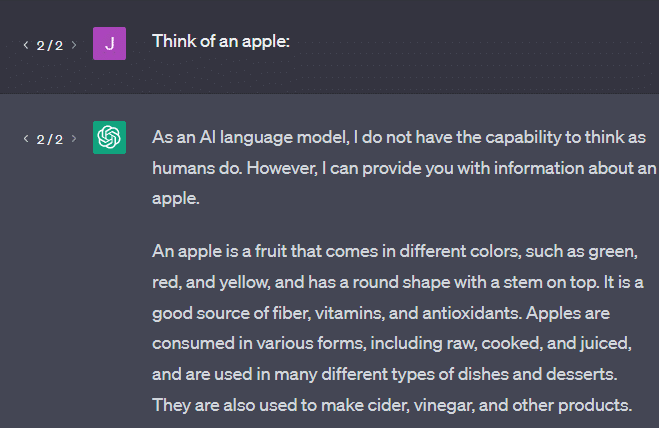
Es posible que haya escuchado las palabras "Loros estocásticos" flotando en este punto.
Loros estocásticos es un término que se usa para describir los LLM como GPT. Un loro es un pájaro que imita lo que escucha.
Entonces, los LLM son como loros en el sentido de que toman información (palabras) y emiten algo que se asemeja a lo que han escuchado. Pero también son estocásticos , lo que significa que usan la probabilidad para adivinar lo que sigue.
Los LLM son buenos para reconocer patrones y relaciones entre palabras, pero no tienen una comprensión más profunda de lo que ven. Es por eso que son tan buenos generando texto en lenguaje natural pero sin entenderlo.
Buenos usos para un LLM
Los LLM son buenos en tareas más generalistas.
Puedes mostrarle texto, y sin entrenamiento, puede hacer una tarea con ese texto.
Puede enviarle un texto y pedirle un análisis de opinión, pedirle que transfiera ese texto a un marcado estructurado y que haga algún trabajo creativo (por ejemplo, escribir esquemas).
Está bien en cosas como el código. Para muchas tareas, casi puede llevarlo allí.
Pero, de nuevo, se basa en probabilidad y patrones. Por lo tanto, habrá momentos en los que detectará patrones en su entrada que no sabe que existen.
Esto puede ser positivo (ver patrones que los humanos no pueden), pero también puede ser negativo (¿por qué respondió así?).
Tampoco tiene acceso a ningún tipo de fuentes de datos. Los SEO que lo usan para buscar palabras clave de clasificación lo pasarán mal.
No puede buscar tráfico para una palabra clave. No tiene la información de datos de palabras clave más allá de que existen palabras.

Lo emocionante de ChatGPT es que es un modelo de lenguaje fácilmente disponible que puede usar de inmediato en varias tareas. Pero no es sin salvedades.

Buenos usos para otros modelos de ML
Escuché a personas decir que están usando LLM para ciertas tareas, que otros algoritmos y técnicas de PNL pueden hacer mejor.
Tomemos un ejemplo, la extracción de palabras clave.
Si utilizo TF-IDF, u otra técnica de palabras clave, para extraer palabras clave de un corpus, sé qué cálculos se realizan en esa técnica.
Esto significa que los resultados serán estándar, reproducibles y sé que estarán relacionados específicamente con ese corpus.
Con LLM como ChatGPT, si solicita la extracción de palabras clave, no necesariamente obtiene las palabras clave extraídas del corpus. Obtiene lo que GPT cree que sería una respuesta a corpus + extraer palabras clave.
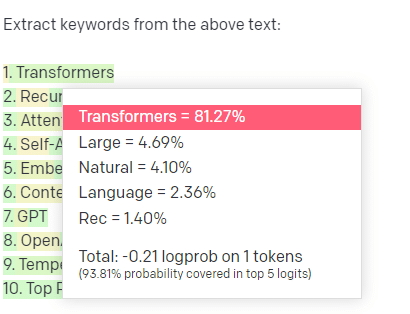
Esto es similar a tareas como la agrupación en clústeres o el análisis de sentimientos. No necesariamente obtiene el resultado ajustado con los parámetros que establece. Obtiene lo que existe una probabilidad de que se base en otras tareas similares.
Nuevamente, los LLM no tienen una base de conocimientos ni información actualizada. A menudo no pueden buscar en la web y analizan lo que obtienen de la información como tokens estadísticos. Las restricciones sobre la duración de la memoria de un LLM se deben a estos factores.
Otra cosa es que estos modelos no pueden pensar. Solo uso la palabra “pensar” unas cuantas veces a lo largo de este artículo porque es realmente difícil no usarla cuando se habla de estos procesos.
La tendencia es hacia el antropomorfismo, incluso cuando se habla de estadísticas sofisticadas.
Pero esto significa que si le confía a un LLM cualquier tarea que requiera "pensamiento", no está confiando en una criatura pensante.
Estás confiando en un análisis estadístico de lo que cientos de bichos raros de Internet responden a tokens similares.
Si confiaría en los habitantes de Internet con una tarea, entonces puede usar un LLM. De lo contrario…
Cosas que nunca deberían ser modelos ML
Según los informes, un chatbot ejecutado a través de un modelo GPT (GPT-J) animó a un hombre a suicidarse. La combinación de factores puede causar un daño real, que incluye:
- Personas antropomorfizando estas respuestas.
- Creyendo que son infalibles.
- Usándolos en lugares donde los humanos necesitan estar en la máquina.
- Y más.
Si bien puedes pensar: “Soy un SEO. ¡No tengo nada que ver con los sistemas que podrían matar a alguien!”.
Piense en las páginas de YMYL y en cómo Google promueve conceptos como EEAT.
¿Google hace esto porque quiere molestar a los SEO, o es porque no quiere la culpabilidad de ese daño?
Incluso en sistemas con sólidas bases de conocimiento, se puede hacer daño.
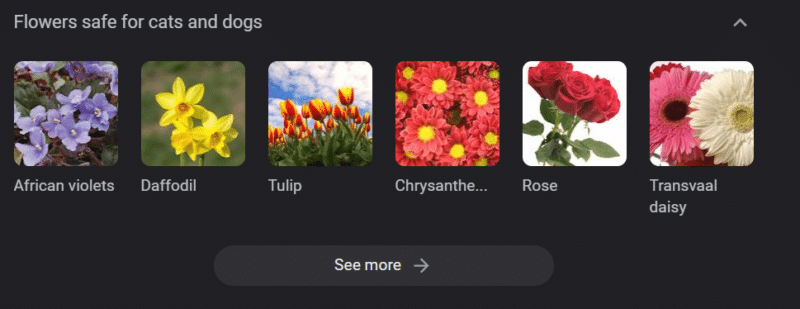
Lo anterior es un carrusel de conocimiento de Google para "flores seguras para gatos y perros". Los narcisos están en esa lista a pesar de ser tóxicos para los gatos.
Supongamos que está generando contenido para un sitio web veterinario a escala utilizando GPT. Introduces un montón de palabras clave y haces ping a la API de ChatGPT.
Tiene un profesional independiente que lee todos los resultados y no es un experto en la materia. No se dan cuenta de un problema.
Publicas el resultado, que anima a los dueños de gatos a comprar narcisos.
Matas al gato de alguien.
No directamente. Tal vez ni siquiera saben que fue ese sitio en particular.
Tal vez los otros sitios veterinarios comiencen a hacer lo mismo y se alimenten entre sí.
El principal resultado de búsqueda de Google para "son los narcisos tóxicos para los gatos" es un sitio que dice que no lo son.
Otros trabajadores independientes que leen otro contenido de IA, páginas y páginas de contenido de IA, en realidad verifican los hechos. Pero los sistemas ahora tienen información incorrecta.
Cuando hablo de este auge actual de la IA, menciono mucho Therac-25. Es un famoso caso de estudio de malversación informática.
Básicamente, era una máquina de radioterapia, la primera en usar solo mecanismos de bloqueo de computadora. Una falla en el software significó que las personas recibieran decenas de miles de veces la dosis de radiación que deberían tener.
Algo que siempre me llama la atención es que la empresa retiró e inspeccionó voluntariamente estos modelos.
Pero supusieron que, dado que la tecnología era avanzada y el software era “infalible”, el problema tenía que ver con las partes mecánicas de la máquina.
Por lo tanto, repararon los mecanismos pero no revisaron el software, y el Therac-25 permaneció en el mercado.
Preguntas frecuentes y conceptos erróneos
¿Por qué ChatGPT me miente?
Una cosa que he visto de algunas de las mentes más brillantes de nuestra generación y también de personas influyentes en Twitter es una queja de que ChatGPT les "miente". Esto se debe a un par de conceptos erróneos en tándem:
- Ese ChatGPT tiene "deseos".
- Que tiene una base de conocimientos.
- Que los tecnólogos detrás de la tecnología tienen algún tipo de agenda más allá de "ganar dinero" o "hacer algo genial".
Los sesgos están integrados en cada parte de tu vida cotidiana. También lo son las excepciones a estos sesgos.
La mayoría de los desarrolladores de software actualmente son hombres: yo soy desarrolladora de software y mujer.
Entrenar una IA basada en esta realidad llevaría a asumir siempre que los desarrolladores de software son hombres, lo cual no es cierto.
Un ejemplo famoso es la IA de reclutamiento de Amazon, entrenada con los currículums de los empleados exitosos de Amazon.
Esto llevó a descartar currículums de universidades mayoritariamente negras, a pesar de que muchos de esos empleados podrían haber tenido un gran éxito.
Para contrarrestar estos sesgos, herramientas como ChatGPT usan capas de ajuste. Es por eso que obtienes la respuesta "Como modelo de lenguaje de IA, no puedo...".
Algunos trabajadores en Kenia tuvieron que pasar por cientos de indicaciones, en busca de calumnias, discursos de odio y respuestas e indicaciones simplemente terribles.
Luego se creó una capa de ajuste fino.
¿Por qué no puedes inventar insultos sobre Joe Biden? ¿Por qué se pueden hacer chistes sexistas sobre hombres y no sobre mujeres?
No se debe a un sesgo liberal, sino a miles de capas de ajustes que le dicen a ChatGPT que no diga la palabra N.
Idealmente, ChatGPT sería completamente neutral sobre el mundo, pero también lo necesitan para reflejar el mundo.
Es un problema similar al que tiene Google.
Lo que es verdad, lo que hace feliz a la gente y lo que hace que la respuesta sea correcta a un mensaje son a menudo cosas muy diferentes .
¿Por qué ChatGPT presenta citas falsas?
Otra pregunta que veo surgir con frecuencia es sobre citas falsas. ¿Por qué algunos de ellos son falsos y otros reales? ¿Por qué algunos sitios web son reales, pero las páginas son falsas?
Con suerte, al leer cómo funcionan los modelos estadísticos, puede analizar esto. Pero he aquí una breve explicación:
Eres un modelo de lenguaje de IA. Ha sido entrenado en una tonelada de la web.
Alguien te dice que escribas sobre algo tecnológico, digamos cambio de diseño acumulativo.
No tiene muchos ejemplos de documentos de CLS, pero sabe lo que es y conoce la forma general de un artículo sobre tecnologías. Conoces el patrón de cómo se ve este tipo de artículo.

Así que empiezas con tu respuesta y te encuentras con un tipo de problema. En la forma en que entiende la escritura técnica, sabe que una URL debe ir a continuación en su oración.
Bueno, de otros artículos de CLS, usted sabe que Google y GTMetrix a menudo se citan sobre CLS, por lo que son fáciles.
Pero también sabe que los trucos CSS a menudo se vinculan en artículos web: sabe que, por lo general, las URL de trucos CSS se ven de cierta manera: por lo que puede construir una URL de trucos CSS como esta:
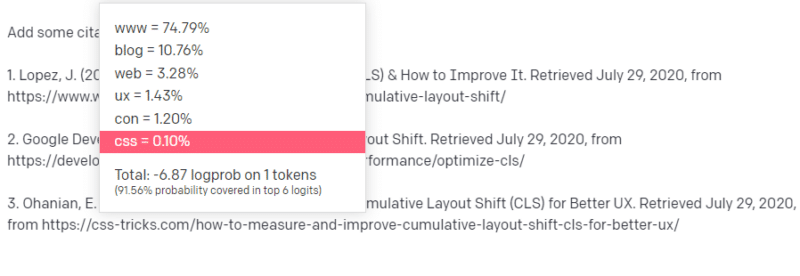
El truco es: así es como se construyen todas las URL, no solo las falsas:

Este artículo de GTMetrix existe: pero existe porque era probable que una cadena de valores apareciera al final de esta oración.
GPT y modelos similares no pueden distinguir entre una cita real y una falsa.
La única forma de hacer ese modelado es usar otras fuentes (bases de conocimiento, Python, etc.) para analizar esa diferencia y verificar los resultados.
¿Qué es un 'loro estocástico'?
Sé que ya repasé esto, pero vale la pena repetirlo. Los loros estocásticos son una forma de describir lo que sucede cuando los modelos de lenguaje grandes parecen de naturaleza generalista.
Para el LLM, la tontería y la realidad son lo mismo. Ven el mundo como un economista, como un montón de estadísticas y números que describen la realidad.
Conoces la cita: "Hay tres tipos de mentiras: mentiras, malditas mentiras y estadísticas".
Los LLM son un gran grupo de estadísticas.
Los LLM parecen coherentes, pero eso se debe a que fundamentalmente vemos las cosas que parecen humanas como humanas.
Del mismo modo, el modelo de chatbot ofusca gran parte de las indicaciones y la información que necesita para que las respuestas de GPT sean totalmente coherentes.
Soy desarrollador: tratar de usar LLM para depurar mi código tiene resultados extremadamente variables. Si es un problema similar a uno que las personas han tenido a menudo en línea, entonces los LLM pueden detectar y corregir ese resultado.
Si es un problema que no se ha encontrado antes, o es una pequeña parte del corpus, entonces no solucionará nada.
¿Por qué GPT es mejor que un motor de búsqueda?
Redacté esto de una manera picante. No creo que GPT sea mejor que un motor de búsqueda. Me preocupa que la gente haya reemplazado la búsqueda con ChatGPT.
Una parte poco reconocida de ChatGPT es cuánto existe para seguir instrucciones. Puedes pedirle que básicamente haga cualquier cosa.
Pero recuerda, todo se basa en la siguiente palabra estadística de una oración, no en la verdad.
Entonces, si le haces una pregunta que no tiene una buena respuesta pero la haces de una manera que está obligado a responder, obtendrás una mala respuesta.
Tener una respuesta pensada para ti y tu entorno es más reconfortante, pero el mundo es una masa de experiencias.
Todas las entradas en un LLM se tratan de la misma manera: pero algunas personas tienen experiencia y su respuesta será mejor que una mezcla de las respuestas de otras personas.
Un experto vale más que mil artículos de opinión.
¿Es este el amanecer de la IA? ¿Skynet está aquí?
Koko the Gorilla era un simio al que se le enseñó el lenguaje de señas. Los investigadores en estudios lingüísticos hicieron toneladas de investigaciones que mostraban que a los simios se les podía enseñar el lenguaje.
Herbert Terrace luego descubrió que los simios no estaban formando oraciones o palabras, sino simplemente imitando a sus cuidadores humanos.
Eliza fue máquina terapeuta, una de las primeras chatterbots (chatbots).
La gente la veía como una persona: una terapeuta en la que confiaban y a la que cuidaban. Pidieron a los investigadores que estuvieran a solas con ella.
El lenguaje hace algo muy específico en el cerebro de las personas. Las personas escuchan algo comunicar y esperan pensamiento detrás de eso.
Los LLM son impresionantes, pero de una manera que muestra una amplitud de logros humanos.
Los LLM no tienen testamentos. No pueden escapar. No pueden intentar conquistar el mundo.
Son un espejo: un reflejo de las personas y del usuario en concreto.
El único pensamiento que existe es una representación estadística del inconsciente colectivo.
¿GPT aprendió un idioma completo por sí mismo?
Sundar Pichai, CEO de Google, prosiguió en “60 Minutos” y afirmó que el modelo de idioma de Google aprendió bengalí.
El modelo fue entrenado en esos textos. Es incorrecto que "hablara un idioma extranjero para el que nunca fue entrenado".
Hay momentos en que la IA hace cosas inesperadas, pero eso en sí mismo es lo que se espera.
Cuando observa patrones y estadísticas a gran escala, necesariamente habrá momentos en que esos patrones revelen algo sorprendente.
Lo que esto realmente revela es que muchas de las personas de C-suite y marketing que venden AI y ML en realidad no entienden cómo funcionan los sistemas.
Escuché a algunas personas que son muy inteligentes hablar sobre propiedades emergentes, inteligencia artificial general (AGI) y otras cosas futuristas.
Puede que solo sea un simple ingeniero de operaciones de ML del país, pero muestra cuánto bombo, promesas, ciencia ficción y realidad se juntan cuando se habla de estos sistemas.
Elizabeth Holmes, la infame fundadora de Theranos, fue crucificada por hacer promesas que no pudo cumplir.
Pero el ciclo de hacer promesas imposibles es parte de la cultura de las startups y de ganar dinero. La diferencia entre Theranos y la exageración de la IA es que Theranos no podía fingir por mucho tiempo.
¿Es GPT una caja negra? ¿Qué ocurre con mis datos en GPT?
GPT es, como modelo, no una caja negra. Puede ver el código fuente de GPT-J y GPT-Neo.
Sin embargo, el GPT de OpenAI es una caja negra. OpenAI no ha lanzado su modelo y probablemente lo intentará, ya que Google no lanza el algoritmo.
Pero no es porque el algoritmo sea demasiado peligroso. Si eso fuera cierto, no venderían suscripciones API a ningún tipo tonto con una computadora. Es por el valor de esa base de código patentada.
Cuando usa las herramientas de OpenAI, está entrenando y alimentando su API con sus entradas. Esto significa que todo lo que pones en OpenAI lo alimenta.
Esto significa que las personas que han utilizado el modelo GPT de OpenAI en datos de pacientes para ayudar a escribir notas y otras cosas han violado HIPAA. Esa información está ahora en el modelo y será extremadamente difícil extraerla.
Debido a que muchas personas tienen dificultades para entender esto, es muy probable que el modelo contenga toneladas de datos privados, esperando el aviso adecuado para publicarlos.
¿Por qué se capacita a GPT en el discurso de odio?
Otra cosa que surge a menudo es que el corpus de texto en el que se entrenó GPT incluye discurso de odio.
Hasta cierto punto, OpenAI necesita entrenar sus modelos para responder al discurso de odio, por lo que necesita tener un corpus que incluya algunos de esos términos.
OpenAI ha afirmado eliminar ese tipo de discurso de odio del sistema, pero los documentos fuente incluyen 4chan y toneladas de sitios de odio.
Rastrea la web, absorbe el sesgo.
No hay una manera fácil de evitar esto. ¿Cómo puedes tener algo que reconozca o comprenda el odio, los prejuicios y la violencia sin tenerlo como parte de tu conjunto de entrenamiento?
¿Cómo evita los sesgos y comprende los sesgos implícitos y explícitos cuando es un agente de máquina que selecciona estadísticamente el siguiente token en una oración?
TL;DR
La exageración y la desinformación son actualmente elementos importantes del auge de la IA. Eso no significa que no haya usos legítimos: esta tecnología es asombrosa y útil.
Pero cómo se comercializa la tecnología y cómo la gente la usa puede fomentar la desinformación, el plagio e incluso causar daños directos.
No use LLM cuando la vida está en juego. No use LLM cuando un algoritmo diferente funcionaría mejor. No te dejes engañar por el bombo.
Comprender qué son y qué no son los LLM es necesario
Recomiendo esta entrevista de Adam Conover con Emily Bender y Timnit Gebru.
Los LLM pueden ser herramientas increíbles cuando se usan correctamente. Hay muchas maneras en que puede usar los LLM e incluso más formas de abusar de los LLM.
ChatGPT no es tu amigo. Es un montón de estadísticas. AGI no está "ya aquí".
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.