
Spark vs Hadoop: ¿Qué marco de Big Data elevará su negocio?
Publicado: 2019-09-24“Los datos son el combustible de la Economía Digital”
Dado que las empresas modernas dependen de una gran cantidad de datos para comprender mejor a sus consumidores y al mercado, las tecnologías como Big Data están ganando un gran impulso.
Big Data, al igual que AI, no solo ha aterrizado en la lista de las principales tendencias tecnológicas para 2020 , sino que se espera que sea adoptada tanto por las nuevas empresas como por las compañías Fortune 500 para disfrutar de un crecimiento comercial exponencial y garantizar una mayor lealtad de los clientes. Una indicación clara de ello es que se prevé que el mercado de Big Data alcance los 103.000 millones de dólares para 2027.
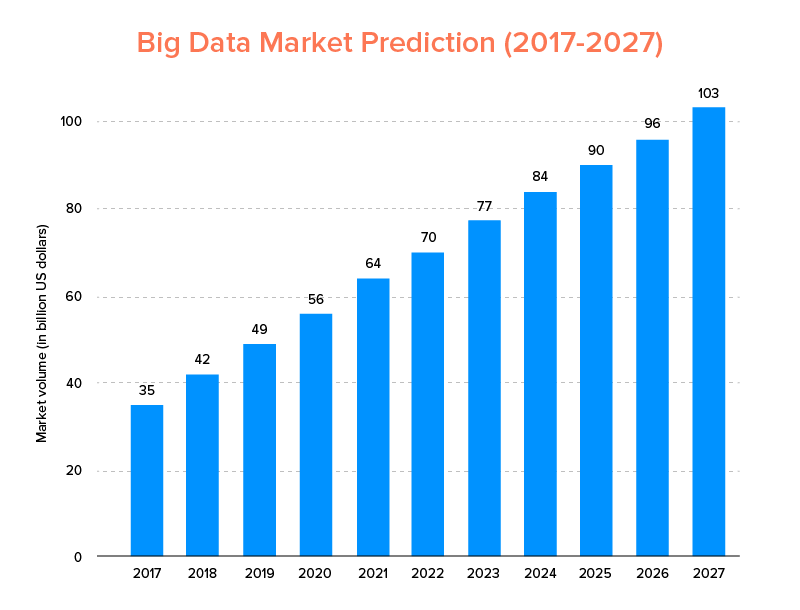
Ahora, si bien por un lado todos están muy motivados para reemplazar sus herramientas tradicionales de análisis de datos con Big Data, la que prepara el terreno para el avance de Blockchain y AI, también están confundidos acerca de elegir la herramienta Big Data adecuada. Se enfrentan al dilema de elegir entre Apache Hadoop y Spark, los dos titanes del mundo de Big Data.
Entonces, considerando este pensamiento, hoy cubriremos un artículo sobre Apache Spark vs Hadoop y lo ayudaremos a determinar cuál es la opción adecuada para sus necesidades.
Pero, primero, hagamos una breve introducción de lo que es Hadoop y Spark.
Apache Hadoop es un marco de código abierto, distribuido y basado en Java que permite a los usuarios almacenar y procesar grandes datos en múltiples grupos de computadoras utilizando construcciones de programación simples. Se compone de varios módulos que trabajan juntos para ofrecer una experiencia mejorada, que son:-
- Hadoop común
- Sistema de archivos distribuido Hadoop (HDFS)
- HILO de Hadoop
- Mapa de HadoopReducir
Considerando que, Apache Spark es un marco de big data de computación en clúster distribuido de código abierto que es 'fácil de usar' y ofrece servicios más rápidos.
Los dos grandes marcos de datos están respaldados por numerosas grandes empresas debido al conjunto de oportunidades que ofrecen.
Ventajas del Marco de Big Data de Hadoop
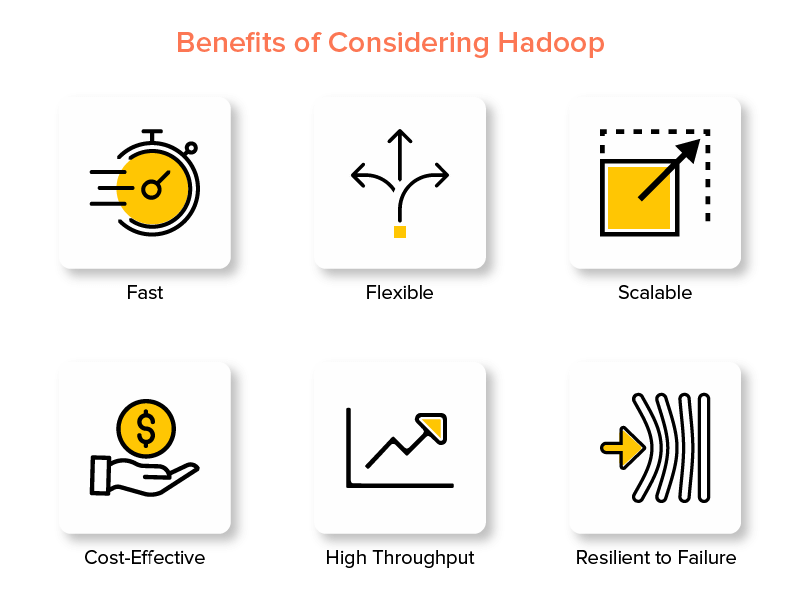
1. Rápido
Una de las características de Hadoop que lo hace popular en el mundo de los grandes datos es que es rápido.
Su método de almacenamiento se basa en un sistema de archivos distribuido que principalmente 'mapea' los datos dondequiera que estén ubicados en un clúster. Además, los datos y las herramientas utilizadas para el procesamiento de datos generalmente están disponibles en el mismo servidor, lo que hace que el procesamiento de datos sea una tarea más rápida y sin problemas.
De hecho, se ha descubierto que Hadoop puede procesar terabytes de datos no estructurados en solo unos minutos, mientras que petabytes en horas.
2. flexibles
Hadoop, a diferencia de las herramientas de procesamiento de datos tradicionales, ofrece flexibilidad de alto nivel.
Permite que las empresas recopilen datos de diferentes fuentes (como redes sociales, correos electrónicos, etc.), trabajen con diferentes tipos de datos (tanto estructurados como no estructurados) y obtengan información valiosa para su uso posterior con diversos fines (como procesamiento de registros, análisis de campañas de mercado, detección de fraude, etc.).
3. Escalable
Otra ventaja de Hadoop es que es altamente escalable. La plataforma, a diferencia de los sistemas de bases de datos relacionales tradicionales (RDBMS) , permite a las empresas almacenar y distribuir grandes conjuntos de datos de cientos de servidores que funcionan en paralelo.
4. Rentable
Apache Hadoop, en comparación con otras herramientas de análisis de big data, es mucho más económico. Esto se debe a que no requiere de ninguna máquina especializada; se ejecuta en un grupo de hardware básico. Además, es más fácil agregar más nodos a largo plazo.
Es decir, un caso aumenta fácilmente los nodos sin sufrir ningún tiempo de inactividad de los requisitos de planificación previa.
5. Alto rendimiento
En el caso del marco Hadoop, los datos se almacenan de manera distribuida, de modo que un trabajo pequeño se divide en varios fragmentos de datos en paralelo. Esto facilita que las empresas realicen más trabajos en menos tiempo, lo que eventualmente resulta en un mayor rendimiento.
6. Resistente al fracaso
Por último, pero no menos importante, Hadoop ofrece opciones de alta tolerancia a fallas que ayudan a mitigar las consecuencias de las fallas. Almacena una réplica de cada bloque que hace posible recuperar datos cada vez que un nodo deja de funcionar.
Desventajas de Hadoop Framework
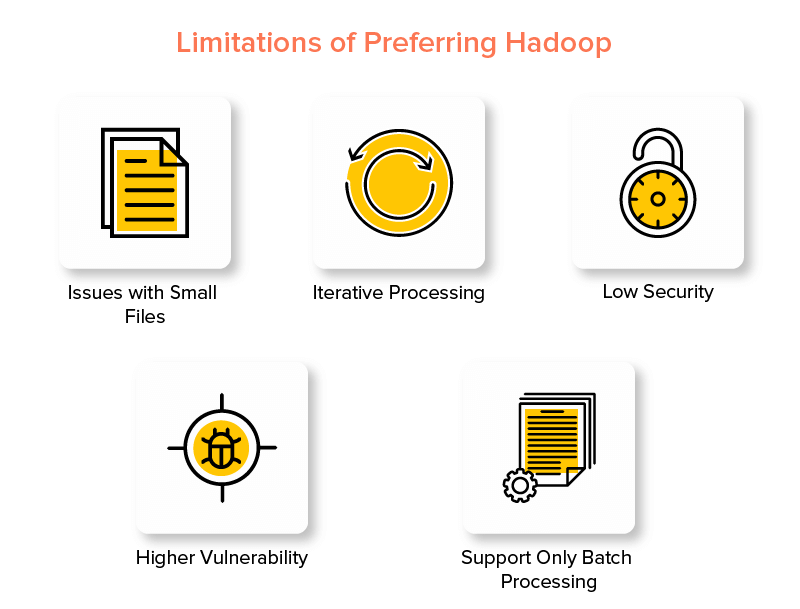
1. Problemas con archivos pequeños
El mayor inconveniente de considerar Hadoop para el análisis de big data es que carece del potencial para admitir la lectura aleatoria de archivos pequeños de manera eficiente y efectiva.
La razón detrás de esto es que un archivo pequeño tiene un tamaño de memoria comparativamente más bajo que el tamaño de bloque HDFS. En tal escenario, si uno almacena una gran cantidad de archivos pequeños, hay mayores posibilidades de sobrecargar NameNode que almacena el espacio de nombres de HDFS, lo que prácticamente no es una buena idea.
2. Procesamiento iterativo
El flujo de datos en el marco de Big Data Hadoop tiene la forma de una cadena, de modo que la salida de uno se convierte en la entrada de otra etapa. Considerando que, el flujo de datos en el procesamiento iterativo es de naturaleza cíclica.
Debido a esto, Hadoop no es una opción adecuada para el aprendizaje automático o las soluciones basadas en procesamiento iterativo.
3. Baja seguridad
Otra desventaja de optar por el marco Hadoop es que ofrece funciones de seguridad más bajas.
El marco, por ejemplo, tiene el modelo de seguridad desactivado de forma predeterminada. Si alguien que usa esta herramienta de big data no sabe cómo habilitarla, sus datos podrían correr un mayor riesgo de ser robados o mal utilizados. Además, Hadoop no proporciona la funcionalidad de cifrado en los niveles de almacenamiento y red, lo que nuevamente aumenta las posibilidades de una amenaza de violación de datos.
4. Mayor vulnerabilidad
El marco Hadoop está escrito en Java, el lenguaje de programación más popular pero más explotado. Esto facilita que los ciberdelincuentes accedan fácilmente a las soluciones basadas en Hadoop y hagan un mal uso de los datos confidenciales.
5. Soporte solo para procesamiento por lotes
A diferencia de otros marcos de big data, Hadoop no procesa datos transmitidos. Solo admite el procesamiento por lotes y el motivo es que MapReduce no aprovecha al máximo la memoria del Hadoop Cluster.
Si bien todo esto se trata de Hadoop, sus características y desventajas, echemos un vistazo a los pros y los contras de Spark para encontrar una comprensión fácil de la diferencia entre los dos.
Beneficios de Apache Spark Framework
1. Naturaleza dinámica
Dado que Apache Spark ofrece alrededor de 80 operadores de alto nivel, se puede utilizar para procesar datos de forma dinámica. Puede considerarse la herramienta de big data adecuada para desarrollar y administrar aplicaciones paralelas.
2. Potente
Debido a su capacidad de procesamiento de datos en memoria de baja latencia y la disponibilidad de varias bibliotecas integradas para algoritmos de análisis de gráficos y aprendizaje automático, puede manejar varios desafíos de análisis. Esto lo convierte en una poderosa opción de big data en el mercado.
3. Análisis avanzado
Otra característica distintiva de Spark es que no solo fomenta 'MAP' y 'reduce', sino que también es compatible con Machine Learning (ML), consultas SQL, algoritmos gráficos y transmisión de datos. Esto lo hace adecuado para disfrutar de análisis avanzados.
4. Reutilización
A diferencia de Hadoop, el código de Spark se puede reutilizar para el procesamiento por lotes, ejecutar consultas ad-hoc sobre el estado de la transmisión, unir la transmisión con datos históricos y más.
5. Procesamiento de transmisión en tiempo real
Otra ventaja de optar por Apache Spark es que permite el manejo y procesamiento de datos en tiempo real.
6. Soporte multilingüe
Por último, pero no menos importante, esta herramienta de análisis de big data admite varios lenguajes de codificación, incluidos Java, Python y Scala.
Limitaciones de la herramienta Spark Big Data

1. Sin proceso de gestión de archivos
La principal desventaja de optar por Apache Spark es que no tiene su propio sistema de administración de archivos. Se basa en otras plataformas como Hadoop para cumplir con este requisito.
2. Pocos algoritmos
Apache Spark también va a la zaga de otros marcos de big data cuando se considera la disponibilidad de algoritmos como la distancia de Tanimoto.
3. Problema de archivos pequeños
Otra desventaja de usar Spark es que no maneja archivos pequeños de manera eficiente.
Esto se debe a que funciona con el sistema de archivos distribuidos de Hadoop (HDFS), que les resulta más fácil administrar una cantidad limitada de archivos grandes en lugar de una gran cantidad de archivos pequeños.
4. Sin proceso de optimización automático
A diferencia de otras plataformas de big data y basadas en la nube, Spark no tiene ningún proceso de optimización de código automático. Uno tiene que optimizar el código manualmente solamente.
5. No apto para entornos multiusuario
Dado que Apache Spark no puede manejar varios usuarios al mismo tiempo, no funciona de manera eficiente en un entorno multiusuario. Algo que de nuevo se suma a sus limitaciones.
Con los conceptos básicos de ambos marcos de big data cubiertos, es probable que desee familiarizarse con las diferencias entre Spark y Hadoop.
Entonces, no esperemos más y diríjase a su comparación para ver cuál lidera la batalla 'Spark vs Hadoop'.
Spark vs Hadoop: cómo las dos herramientas de Big Data se comparan entre sí
[identificación de la tabla = 38 /]
1. Arquitectura
Cuando se trata de la arquitectura Spark y Hadoop, esta última lidera incluso cuando ambas operan en un entorno informático distribuido.
Esto se debe a que la arquitectura de Hadoop, a diferencia de Spark, tiene dos elementos principales: HDFS (Sistema de archivos distribuidos de Hadoop) e YARN (Otro negociador de recursos). Aquí, HDFS maneja el almacenamiento de big data en varios nodos, mientras que YARN se ocupa de las tareas de procesamiento a través de la asignación de recursos y los mecanismos de programación de trabajos. Estos componentes luego se dividen en más componentes para ofrecer mejores soluciones con servicios como la tolerancia a fallas.
2. Facilidad de uso
Apache Spark permite a los desarrolladores introducir varias API fáciles de usar como Scala, Python, R, Java y Spark SQL en su entorno de desarrollo. Además, viene cargado con un modo interactivo que admite tanto usuarios como desarrolladores. Esto lo hace fácil de usar y con una curva de aprendizaje baja.
Mientras que, cuando se habla de Hadoop, ofrece complementos para ayudar a los usuarios, pero no un modo interactivo. Esto hace que Spark le gane a Hadoop en esta batalla de 'big data'.
3. Tolerancia a fallas y seguridad
Si bien tanto Apache Spark como Hadoop MapReduce ofrecen una función de tolerancia a fallas, este último gana la batalla.
Esto se debe a que uno tiene que comenzar desde cero en caso de que un proceso se bloquee en medio de la operación en el entorno Spark. Pero, cuando se trata de Hadoop, pueden continuar desde el punto mismo del bloqueo.
4. Rendimiento
Cuando se trata de considerar el rendimiento de Spark vs MapReduce, el primero gana al segundo.
Spark framework puede ejecutarse 10 veces más rápido en disco y 100 veces en memoria. Esto hace posible administrar 100 TB de datos 3 veces más rápido que Hadoop MapReduce.
5. Tratamiento de datos
Otro factor a considerar durante la comparación de Apache Spark vs Hadoop es el procesamiento de datos.
Si bien Apache Hadoop ofrece la oportunidad de procesar solo por lotes, el otro marco de macrodatos permite trabajar con procesamiento interactivo, iterativo, de flujo, gráfico y por lotes. Algo que demuestra que Spark es una mejor opción para disfrutar de mejores servicios de procesamiento de datos.
6. Compatibilidad
La compatibilidad de Spark y Hadoop MapReduce es algo similar.
Si bien, a veces, ambos marcos de big data actúan como aplicaciones independientes, también pueden trabajar juntos. Spark puede ejecutarse de manera eficiente sobre Hadoop YARN, mientras que Hadoop puede integrarse fácilmente con Sqoop y Flume. Debido a esto, ambos admiten las fuentes de datos y los formatos de archivo de los demás.
7. Seguridad
El entorno de Spark está cargado con diferentes características de seguridad, como el registro de eventos y el uso de filtros de servlet javax para proteger las interfaces de usuario web. Además, fomenta la autenticación mediante secreto compartido y puede aprovechar el potencial de los permisos de archivos HDFS, el cifrado entre modos y Kerberos cuando se integra con YARN y HDFS.
Mientras que Hadoop es compatible con la autenticación Kerberos , la autenticación de terceros, los permisos de archivos convencionales y las listas de control de acceso, y más, lo que eventualmente ofrece mejores resultados de seguridad.
Entonces, al considerar la comparación Spark vs Hadoop en términos de seguridad, este último lidera.
8. Rentabilidad
Al comparar Hadoop y Spark, el primero necesita más memoria en el disco, mientras que el segundo requiere más RAM. Además, dado que Spark es bastante nuevo en comparación con Apache Hadoop, los desarrolladores que trabajan con Spark son menos frecuentes.
Esto hace que trabajar con Spark sea un asunto costoso. Es decir, Hadoop ofrece soluciones rentables cuando uno se enfoca en el costo de Hadoop vs Spark.
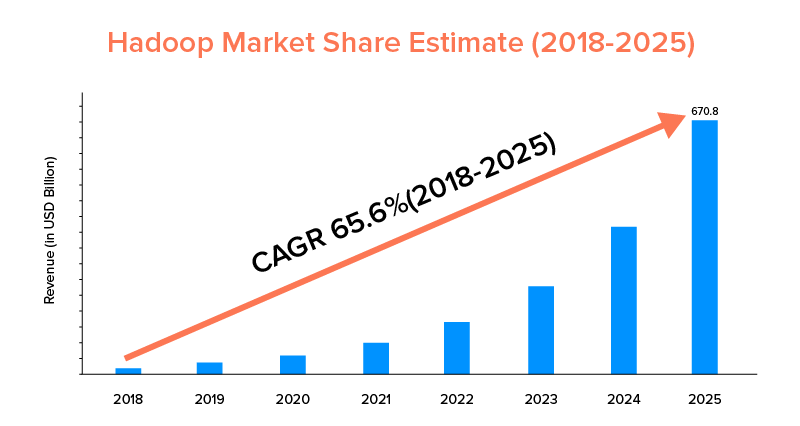
9. Alcance del mercado
Si bien tanto Apache Spark como Hadoop están respaldados por grandes empresas y se han utilizado para diferentes propósitos, este último lidera en términos de alcance de mercado.
Según las estadísticas del mercado, se prevé que el mercado de Apache Hadoop crezca con una CAGR del 65,6 % durante el período de 2018 a 2025, en comparación con Spark con una CAGR del 33,9 % solamente.
Si bien estos factores ayudarán a determinar la herramienta de big data adecuada para su negocio, es rentable familiarizarse con sus casos de uso. Entonces, cubramos aquí.
Casos de uso de Apache Spark Framework
Las empresas adoptan esta herramienta de big data cuando desean:
- Transmita y analice datos en tiempo real.
- Disfrute del poder del aprendizaje automático.
- Trabaje con análisis interactivos.
- Introducir Fog and Edge Computing en su modelo de negocio.
Casos de uso de Apache Hadoop Framework
Hadoop es el preferido por las empresas emergentes y las empresas cuando quieren:
- Analizar datos de archivo.
- Disfrute de mejores opciones de negociación y previsión financiera.
- Ejecutar operaciones que comprenden hardware básico.
- Considere el procesamiento de datos lineales.
Con esto, esperamos que hayas decidido cuál es el ganador de la batalla 'Spark vs Hadoop' con respecto a tu negocio. Si no es así, no dude en conectarse con nuestros expertos en Big Data para aclarar todas las dudas y obtener servicios ejemplares con una mayor tasa de éxito.
PREGUNTAS FRECUENTES
1. ¿Qué marco de Big Data elegir?
La elección depende completamente de las necesidades de su negocio. Si se centra en el rendimiento, la compatibilidad de datos y la facilidad de uso, Spark es mejor que Hadoop. Mientras que el marco de big data de Hadoop es mejor cuando se enfoca en la arquitectura, la seguridad y la rentabilidad.
2. ¿Cuál es la diferencia entre Hadoop y Spark?
Hay varias diferencias entre Spark y Hadoop. Por ejemplo:-
- Spark es un factor 100 veces mayor que Hadoop MapReduce.
- Si bien Hadoop se emplea para el procesamiento por lotes, Spark está diseñado para procesamiento por lotes, gráficos, aprendizaje automático e iterativo.
- Spark es compacto y más fácil que el marco de big data de Hadoop.
- A diferencia de Spark, Hadoop no admite el almacenamiento en caché de datos.
3. ¿Es Spark mejor que Hadoop?
Spark es mejor que Hadoop cuando su enfoque principal es la velocidad y la seguridad. Sin embargo, en otros casos, esta herramienta de análisis de big data va a la zaga de Apache Hadoop.
4. ¿Por qué Spark es más rápido que Hadoop?
Spark es más rápido que Hadoop debido a la menor cantidad de ciclos de lectura/escritura en el disco y al almacenamiento de datos intermedios en la memoria.
5. ¿Para qué se utiliza Apache Spark?
Apache Spark se utiliza para el análisis de datos cuando uno quiere-
- Analiza datos en tiempo real.
- Introduzca ML y Fog Computing en su modelo de negocio.
- Trabaja con Analítica Interactiva.