
TW-BERT: ponderación de términos de consulta de un extremo a otro y el futuro de la Búsqueda de Google
Publicado: 2023-09-14La búsqueda es difícil, como escribió Seth Godin en 2005.
Quiero decir, si pensamos que el SEO es difícil (y lo es), imagina si estuvieras intentando construir un motor de búsqueda en un mundo donde:
- Los usuarios varían dramáticamente y cambian sus preferencias con el tiempo.
- La tecnología a la que acceden busca avances cada día.
- Los competidores te pisan los talones constantemente.
Además de eso, también estás lidiando con molestos SEO que intentan jugar con tu algoritmo para obtener información sobre la mejor manera de optimizar para tus visitantes.
Eso lo hará mucho más difícil.
Ahora imagínese si las principales tecnologías en las que necesita apoyarse para avanzar tuvieran sus propias limitaciones y, quizás peor, costos enormes.
Bueno, si usted es uno de los autores del artículo publicado recientemente, “Ponderación de términos de consulta de un extremo a otro”, verá esto como una oportunidad para brillar.
¿Qué es la ponderación de términos de consulta de un extremo a otro?
La ponderación de términos de consulta de un extremo a otro se refiere a un método en el que la ponderación de cada término en una consulta se determina como parte del modelo general, sin depender de esquemas de ponderación de términos tradicionales o programados manualmente u otros modelos independientes.
¿Cómo se ve eso?
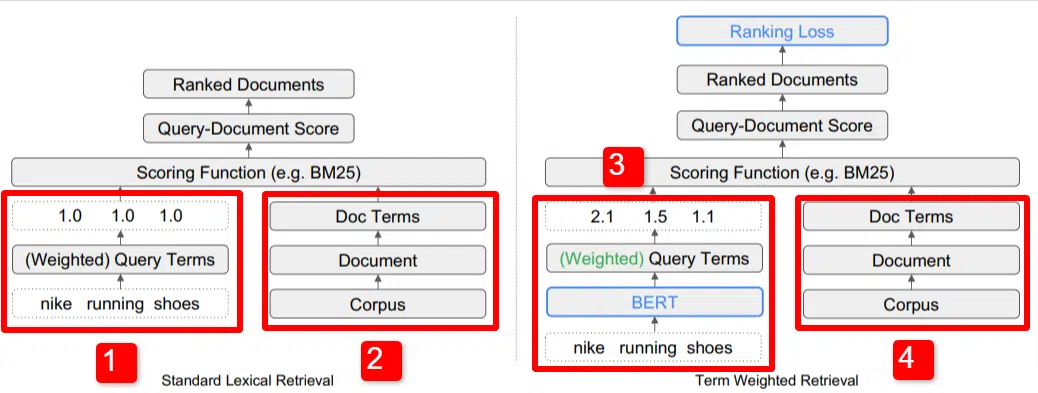
Aquí vemos una ilustración de uno de los diferenciadores clave del modelo descrito en el artículo (Figura 1, específicamente).
En el lado derecho del modelo estándar (2) vemos lo mismo que vemos con el modelo propuesto (4), que es el corpus (conjunto completo de documentos en el índice), que conduce a los documentos, que conduce a los términos.
Esto ilustra la jerarquía real en el sistema, pero puedes pensar en ella al revés, de arriba hacia abajo. Tenemos términos. Buscamos documentos con esos términos. Esos documentos están en el corpus de todos los documentos que conocemos.
En la parte inferior izquierda (1) de la arquitectura estándar de recuperación de información (IR), notará que no hay una capa BERT. La consulta utilizada en su ilustración (zapatillas Nike para correr) ingresa al sistema y los pesos se calculan independientemente del modelo y se le pasan.
En la siguiente ilustración, los pesos se transmiten por igual entre las tres palabras de la consulta. Sin embargo, no tiene por qué ser así. Es simplemente una buena ilustración predeterminada.
Lo que es importante entender es que los pesos se asignan desde fuera del modelo y se ingresan con la consulta. Cubriremos por qué esto es importante en un momento.
Si miramos la versión de peso de términos en el lado derecho, verá que la consulta "zapatillas Nike para correr" ingresa BERT (Term Weighting BERT, o TW-BERT, para ser específico) que se usa para asignar los pesos que Se aplicaría mejor a esa consulta.
A partir de ahí, las cosas siguen un camino similar para ambos: se aplica una función de puntuación y se clasifican los documentos. Pero hay un paso final clave con el nuevo modelo, que es realmente el punto de todo: el cálculo de la pérdida de clasificación.
Este cálculo, al que me refería anteriormente, hace que los pesos que se determinen dentro del modelo sean tan importantes. Para entender esto mejor, hablemos brevemente sobre las funciones de pérdida, lo cual es importante para comprender realmente lo que está sucediendo aquí.
¿Qué es una función de pérdida?
En el aprendizaje automático, una función de pérdida es básicamente un cálculo de qué tan equivocado está un sistema al intentar aprender a acercarse lo más posible a una pérdida cero.
Tomemos, por ejemplo, un modelo diseñado para determinar los precios de la vivienda. Si ingresó todas las estadísticas de su casa y obtuvo un valor de $250,000, pero su casa se vendió por $260,000, la diferencia se consideraría pérdida (que es un valor absoluto).
En una gran cantidad de ejemplos, se enseña al modelo a minimizar la pérdida asignando diferentes pesos a los parámetros que se le asignan hasta que obtiene el mejor resultado. Un parámetro, en este caso, puede incluir cosas como pies cuadrados, dormitorios, tamaño del jardín, proximidad a una escuela, etc.
Ahora, volvamos a la ponderación de los términos de consulta.
Si analizamos los dos ejemplos anteriores, debemos centrarnos en la presencia de un modelo BERT para proporcionar la ponderación a los términos del embudo descendente del cálculo de la pérdida de clasificación.
Para decirlo de otra manera, en los modelos tradicionales, la ponderación de los términos se hacía independientemente del modelo en sí y, por lo tanto, no podía responder al desempeño del modelo general. No pudo aprender cómo mejorar en las ponderaciones.

En el sistema propuesto esto cambia. La ponderación se realiza desde dentro del propio modelo y, por lo tanto, a medida que el modelo busca mejorar su rendimiento y reducir la función de pérdida, tiene estos diales adicionales para incorporar la ponderación de términos en la ecuación. Literalmente.
ngramas
TW-BERT no está diseñado para funcionar en términos de palabras, sino de ngramas.
Los autores del artículo ilustran bien por qué usan ngramas en lugar de palabras cuando señalan que en la consulta "zapatillas nike para correr", si simplemente ponderas las palabras, entonces una página con menciones de las palabras nike, correr y zapatos podría clasificarse bien incluso si se trata de “calcetines Nike para correr” y “zapatillas de skate”.
Los métodos tradicionales de IR utilizan estadísticas de consultas y estadísticas de documentos, y pueden mostrar páginas con este o problemas similares. Los intentos anteriores de abordar esto se centraron en la coexistencia y el ordenamiento.
En este modelo, los ngramas se ponderan como las palabras en nuestro ejemplo anterior, por lo que terminamos con algo como:
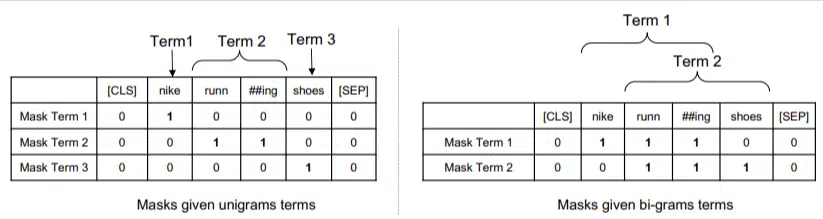
A la izquierda vemos cómo la consulta se ponderaría como unigramas (ngramas de 1 palabra) y a la derecha, bigramas (ngramas de 2 palabras).
El sistema, debido a que la ponderación está integrada, puede entrenar con todas las permutaciones para determinar los mejores ngramas y también el peso apropiado para cada una, en lugar de depender únicamente de estadísticas como la frecuencia.
Tiro cero
Una característica importante de este modelo es su desempeño en tareas cortas a cero. Los autores probaron en:
- Conjunto de datos MS MARCO: conjunto de datos de Microsoft para clasificación de documentos y pasajes
- Conjunto de datos TREC-COVID: artículos y estudios de COVID
- Robust04 – Artículos de noticias
- Common Core: artículos educativos y publicaciones de blogs
Solo tenían una pequeña cantidad de consultas de evaluación y no usaron ninguna para realizar ajustes, lo que la convierte en una prueba de cero posibilidades, ya que el modelo no fue entrenado para clasificar documentos en estos dominios específicamente. Los resultados fueron:
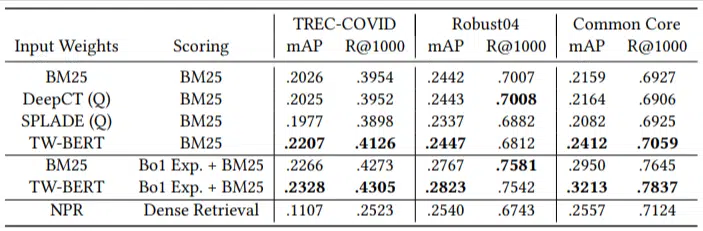
Obtuvo un rendimiento superior en la mayoría de las tareas y obtuvo mejores resultados en consultas más cortas (de 1 a 10 palabras).
¡Y es plug-and-play!
Bien, eso podría resultar demasiado simplificado, pero los autores escriben:
“Alinear TW-BERT con los puntajes de los motores de búsqueda minimiza los cambios necesarios para integrarlo en las aplicaciones de producción existentes , mientras que los métodos de búsqueda basados en el aprendizaje profundo existentes requerirían una mayor optimización de la infraestructura y requisitos de hardware. Los pesos aprendidos pueden ser utilizados fácilmente por recuperadores léxicos estándar y por otras técnicas de recuperación como la expansión de consultas”.
Debido a que TW-BERT está diseñado para integrarse en el sistema actual, la integración es mucho más sencilla y económica que otras opciones.
¿Qué significa todo esto para ti?
Con los modelos de aprendizaje automático, es difícil predecir, por ejemplo, lo que usted como SEO puede hacer al respecto (aparte de implementaciones visibles como Bard o ChatGPT).
Sin duda, se implementará una permutación de este modelo debido a sus mejoras y facilidad de implementación (suponiendo que las declaraciones sean precisas).
Dicho esto, se trata de una mejora en la calidad de vida de Google, que mejorará las clasificaciones y los resultados inmediatos con un bajo coste.
Lo único en lo que realmente podemos confiar es en que, si se implementan, surgirán mejores resultados de manera más confiable. Y esas son buenas noticias para los profesionales de SEO.
Las opiniones expresadas en este artículo son las del autor invitado y no necesariamente las de Search Engine Land. Los autores del personal se enumeran aquí.