
¿Qué es la IA generativa y cómo funciona?
Publicado: 2023-09-26La IA generativa, un subconjunto de la inteligencia artificial, se ha convertido en una fuerza revolucionaria en el mundo de la tecnología. ¿Pero qué es exactamente? ¿Y por qué está ganando tanta atención?
Esta guía detallada profundizará en cómo funcionan los modelos de IA generativa, qué pueden y qué no pueden hacer y las implicaciones de todos estos elementos.
¿Qué es la IA generativa?
La IA generativa, o genAI, se refiere a sistemas que pueden generar contenido nuevo, ya sea texto, imágenes, música o incluso videos. Tradicionalmente, AI/ML significaba tres cosas: aprendizaje supervisado, no supervisado y reforzado. Cada uno brinda información basada en el resultado de la agrupación.
Los modelos de IA no generativos realizan cálculos basados en datos de entrada (como clasificar una imagen o traducir una oración). Por el contrario, los modelos generativos producen resultados “nuevos” como escribir ensayos, componer música, diseñar gráficos e incluso crear rostros humanos realistas que no existen en el mundo real.
Las implicaciones de la IA generativa
El auge de la IA generativa tiene implicaciones importantes. Con la capacidad de generar contenido, industrias como el entretenimiento, el diseño y el periodismo están siendo testigos de un cambio de paradigma.
Por ejemplo, las agencias de noticias pueden utilizar la IA para redactar informes, mientras que los diseñadores pueden obtener sugerencias de gráficos asistidas por la IA. La IA puede generar cientos de eslóganes publicitarios en segundos, sean o no buenas esas opciones o no es otra cuestión.
La IA generativa puede producir contenido personalizado para usuarios individuales. Piense en algo así como una aplicación de música que compone una canción única según su estado de ánimo o una aplicación de noticias que redacta artículos sobre temas que le interesan.
El problema es que a medida que la IA desempeña un papel más integral en la creación de contenidos, las preguntas sobre la autenticidad, los derechos de autor y el valor de la creatividad humana se vuelven más frecuentes.
¿Cómo funciona la IA generativa?
La IA generativa, en esencia, consiste en predecir el siguiente dato en una secuencia, ya sea la siguiente palabra de una oración o el siguiente píxel de una imagen. Analicemos cómo se logra esto.
Modelos estadísticos
Los modelos estadísticos son la columna vertebral de la mayoría de los sistemas de IA. Utilizan ecuaciones matemáticas para representar la relación entre diferentes variables.
Para la IA generativa, los modelos se entrenan para reconocer patrones en los datos y luego utilizar estos patrones para generar datos nuevos y similares.
Si un modelo se entrena con oraciones en inglés, aprende la probabilidad estadística de que una palabra siga a otra, lo que le permite generar oraciones coherentes.
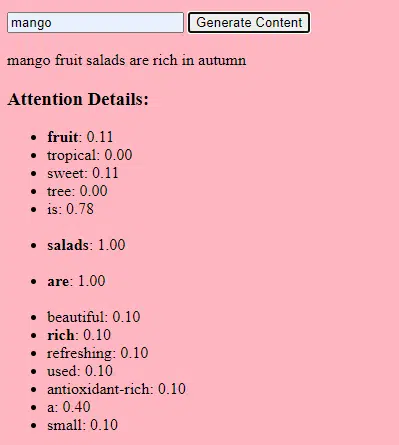
Recopilación de datos
Tanto la calidad como la cantidad de datos son cruciales. Los modelos generativos se entrenan en vastos conjuntos de datos para comprender patrones.
Para un modelo de lenguaje, esto podría significar ingerir miles de millones de palabras de libros, sitios web y otros textos.
Para un modelo de imagen, podría significar analizar millones de imágenes. Cuanto más diversos y completos sean los datos de entrenamiento, mejor generará el modelo diversos resultados.
Cómo funcionan los transformadores y la atención
Los transformadores son un tipo de arquitectura de red neuronal presentada en un artículo de 2017 titulado "La atención es todo lo que necesitas" de Vaswani et al. Desde entonces se han convertido en la base de la mayoría de los modelos lingüísticos más modernos. ChatGPT no funcionaría sin transformadores.
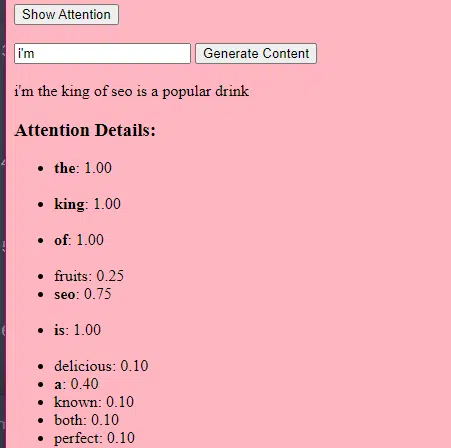
El mecanismo de "atención" permite que el modelo se centre en diferentes partes de los datos de entrada, de forma muy parecida a cómo los humanos prestan atención a palabras específicas cuando comprenden una oración.
Este mecanismo permite que el modelo decida qué partes de la entrada son relevantes para una tarea determinada, lo que lo hace muy flexible y potente.
El siguiente código es un desglose fundamental de los mecanismos de los transformadores y explica cada pieza en un lenguaje sencillo.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)En el código, es posible que tenga una clase Transformer y una única clase TransformerLayer. Esto es como tener un plano para un piso versus un edificio completo.
Este fragmento de código de TransformerLayer le muestra cómo funcionan componentes específicos, como la atención de múltiples cabezales y arreglos específicos.
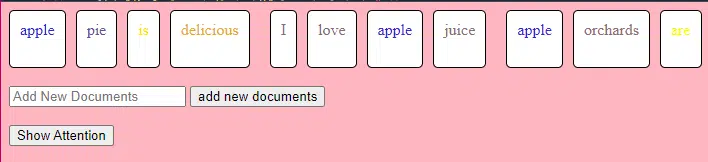
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)Una red neuronal de retroalimentación es uno de los tipos más simples de redes neuronales artificiales. Consta de una capa de entrada, una o más capas ocultas y una capa de salida.
Los datos fluyen en una dirección: desde la capa de entrada, a través de las capas ocultas y hasta la capa de salida. No hay bucles ni ciclos en la red.
En el contexto de la arquitectura transformadora, la red neuronal de retroalimentación se utiliza después del mecanismo de atención en cada capa. Es una transformación lineal simple de dos capas con una activación ReLU en el medio.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Cómo funciona la IA generativa: en términos simples
Piense en la IA generativa como si se lanzara un dado ponderado. Los datos de entrenamiento determinan los pesos (o probabilidades).
Si el dado representa la siguiente palabra de una oración, una palabra que a menudo sigue a la palabra actual en los datos de entrenamiento tendrá un peso mayor. Por lo tanto, "cielo" podría seguir a "azul" con más frecuencia que "plátano". Cuando la IA "tira los dados" para generar contenido, es más probable que elija secuencias estadísticamente más probables en función de su entrenamiento.
Entonces, ¿cómo pueden los LLM generar contenido que “parezca” original?
Tomemos una lista falsa (los "mejores obsequios de Eid al-Fitr para especialistas en marketing de contenidos") y analicemos cómo un LLM puede generar esta lista combinando pistas textuales de documentos sobre obsequios, Eid y especialistas en marketing de contenidos.
Antes de procesarlo, el texto se divide en partes más pequeñas llamadas "tokens". Estos tokens pueden ser tan cortos como un carácter o tan largos como una palabra.
Ejemplo: “Eid al-Fitr es una celebración” se convierte en [“Eid”, “al-Fitr”, “es”, “a”, “celebración”].
Esto permite que el modelo trabaje con fragmentos de texto manejables y comprenda la estructura de las oraciones.
Luego, cada token se convierte en un vector (una lista de números) mediante incrustaciones. Estos vectores capturan el significado y el contexto de cada palabra.
La codificación posicional agrega información a cada vector de palabras sobre su posición en la oración, asegurando que el modelo no pierda esta información de orden.
Luego usamos un mecanismo de atención : esto permite que el modelo se centre en diferentes partes del texto de entrada al generar una salida. Si recuerdas BERT, esto es lo que resultó tan interesante para los empleados de Google acerca de BERT.
Si nuestro modelo ha visto textos sobre " regalos " y sabe que la gente da regalos durante las celebraciones , y también ha visto textos sobre " Eid al-Fitr " como una celebración importante, prestará " atención " a estas conexiones.
De manera similar, si ha visto textos sobre " comercializadores de contenido " que necesitan herramientas o recursos específicos, puede conectar la idea de " regalos " con " comercializadores de contenido".

Ahora podemos combinar contextos: a medida que el modelo procesa el texto de entrada a través de múltiples capas de Transformer, combina los contextos que ha aprendido.
Entonces, incluso si los textos originales nunca mencionaron “obsequios de Eid al-Fitr para especialistas en marketing de contenidos”, el modelo puede combinar los conceptos de “Eid al-Fitr”, “obsequios” y “comercializadores de contenidos” para generar este contenido.
Esto se debe a que ha aprendido los contextos más amplios en torno a cada uno de estos términos.
Después de procesar la entrada a través del mecanismo de atención y las redes de retroalimentación en cada capa de Transformer, el modelo produce una distribución de probabilidad sobre su vocabulario para la siguiente palabra de la secuencia.
Se podría pensar que después de palabras como “mejor” y “Eid al-Fitr”, la palabra “regalos” tiene una alta probabilidad de ser la siguiente. De manera similar, podría asociar "obsequios" con destinatarios potenciales, como "comercializadores de contenidos".
Obtenga el boletín de noticias diario en el que confían los especialistas en marketing.
Ver términos.
Cómo se construyen los grandes modelos de lenguaje
El viaje desde un modelo de transformador básico a un modelo de lenguaje grande (LLM) sofisticado como GPT-3 o BERT implica ampliar y perfeccionar varios componentes.
Aquí hay un desglose paso a paso:
Los LLM están capacitados con grandes cantidades de datos de texto. Es difícil explicar cuán vastos son estos datos.
El conjunto de datos C4, un punto de partida para muchos LLM, tiene 750 GB de datos de texto. Eso es 805.306.368.000 bytes: mucha información. Estos datos pueden incluir libros, artículos, sitios web, foros, secciones de comentarios y otras fuentes.
Cuanto más variados y completos sean los datos, mejores serán las capacidades de comprensión y generalización del modelo.
Si bien la arquitectura básica del transformador sigue siendo la base, los LLM tienen una cantidad significativamente mayor de parámetros. GPT-3, por ejemplo, tiene 175 mil millones de parámetros. En este caso, los parámetros se refieren a los pesos y sesgos de la red neuronal que se aprenden durante el proceso de entrenamiento.

En el aprendizaje profundo, se entrena un modelo para hacer predicciones ajustando estos parámetros para reducir la diferencia entre sus predicciones y los resultados reales.
El proceso de ajustar estos parámetros se llama optimización y utiliza algoritmos como el descenso de gradiente.
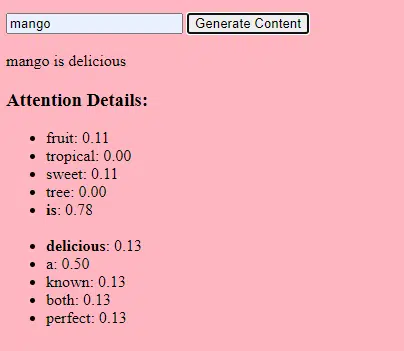
- Pesos: son valores en la red neuronal que transforman los datos de entrada dentro de las capas de la red. Se ajustan durante el entrenamiento para optimizar el resultado del modelo. Cada conexión entre neuronas en capas adyacentes tiene un peso asociado.
- Sesgos: estos también son valores en la red neuronal que se agregan a la salida de la transformación de una capa. Proporcionan un grado adicional de libertad al modelo, permitiéndole ajustarse mejor a los datos de entrenamiento. Cada neurona de una capa tiene un sesgo asociado.
Este escalado permite que el modelo almacene y procese patrones y relaciones más complejos en los datos.
La gran cantidad de parámetros también significa que el modelo requiere una potencia computacional y memoria significativas para el entrenamiento y la inferencia. Esta es la razón por la que entrenar estos modelos requiere muchos recursos y normalmente utiliza hardware especializado como GPU o TPU.
El modelo está entrenado para predecir la siguiente palabra en una secuencia utilizando potentes recursos computacionales. Ajusta sus parámetros internos en función de los errores que comete, mejorando continuamente sus predicciones.
Los mecanismos de atención como los que hemos discutido son fundamentales para los LLM. Permiten que el modelo se centre en diferentes partes de la entrada al generar la salida.
Al sopesar la importancia de diferentes palabras en un contexto, los mecanismos de atención permiten que el modelo genere un texto coherente y contextualmente relevante. Hacerlo a esta escala masiva permite a los LLM trabajar como lo hacen.
¿Cómo predice un transformador el texto?
Los transformadores predicen texto procesando tokens de entrada a través de múltiples capas, cada una equipada con mecanismos de atención y redes de retroalimentación.
Después del procesamiento, el modelo produce una distribución de probabilidad sobre su vocabulario para la siguiente palabra de la secuencia. La palabra con mayor probabilidad normalmente se selecciona como predicción.
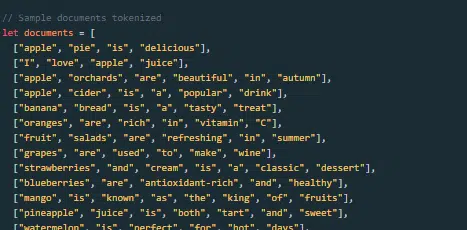
¿Cómo se construye y entrena un modelo de lenguaje grande?
Crear un LLM implica recopilar datos, limpiarlos, entrenar el modelo, ajustarlo y realizar pruebas intensas y continuas.
Inicialmente, el modelo se entrena en un vasto corpus para predecir la siguiente palabra en una secuencia. Esta fase permite que el modelo aprenda conexiones entre palabras que recogen patrones en la gramática, relaciones que pueden representar hechos sobre el mundo y conexiones que parecen razonamiento lógico. Estas conexiones también hacen que detecte sesgos presentes en los datos de entrenamiento.
Después del entrenamiento previo, el modelo se refina en un conjunto de datos más limitado, a menudo con revisores humanos que siguen pautas.
El ajuste es un paso crucial en la creación de LLM. Implica entrenar el modelo previamente entrenado en un conjunto de datos o una tarea más específica. Tomemos ChatGPT como ejemplo.
Si ha jugado con modelos GPT, sabrá que la indicación es menos "escribir esto" y más como
- Mensaje: Érase una vez
- Continuación: Había un mago malvado en lo alto de una torre.
- Continuación: Había un mago malvado en lo alto de una torre.
- Pregunta : ¿Por qué el pollo se unió a una banda?
- Continuación : ¡Porque tenía baquetas!
Llegar a ChatGPT desde ese punto implica mucha mano de obra mal remunerada. Esas personas crean inmensos corpus para señalar el peso de las respuestas de GPT y los comportamientos esperados. Estos trabajadores crean toneladas de textos de aviso/continuación que son como:
- Mensaje : Termine esta historia: “Érase una vez…”
- Continuación : ¡Claro! Había una vez, en una tierra muy, muy lejana, un pequeño pueblo enclavado entre dos majestuosas montañas.
- Continuación : ¡Claro! Había una vez, en una tierra muy, muy lejana, un pequeño pueblo enclavado entre dos majestuosas montañas.
- Pregunta : Cuéntame un chiste sobre un pollo.
- Continuación : ¿Por qué la gallina se unió a una banda? ¡Porque tenía las baquetas!
Este proceso de ajuste es esencial por varias razones:
- Especificidad: si bien el entrenamiento previo le brinda al modelo una comprensión amplia del lenguaje, el ajuste reduce su conocimiento y comportamiento para alinearse más con tareas o dominios específicos. Por ejemplo, un modelo ajustado a partir de datos médicos responderá mejor a las preguntas médicas.
- Control: el ajuste fino brinda a los desarrolladores más control sobre los resultados del modelo. Los desarrolladores pueden utilizar un conjunto de datos seleccionados para guiar el modelo a fin de producir las respuestas deseadas y evitar comportamientos no deseados.
- Seguridad: ayuda a reducir los resultados dañinos o sesgados. Al utilizar pautas durante el proceso de ajuste, los revisores humanos pueden garantizar que el modelo no produzca contenido inapropiado.
- Rendimiento: el ajuste fino puede mejorar significativamente el rendimiento del modelo en tareas específicas. Por ejemplo, un modelo que ha sido ajustado para la atención al cliente será mucho mejor que un modelo genérico.
Se puede decir que ChatGPT se ha perfeccionado en particular en algunos aspectos.
Por ejemplo, el "razonamiento lógico" es algo con lo que los LLM tienden a tener dificultades. El mejor modelo de razonamiento lógico de ChatGPT, GPT-4, ha sido entrenado intensamente para reconocer patrones en números de manera explícita.
En lugar de algo como esto:
- Pregunta : ¿Qué es 2+2?
- Proceso : A menudo en los libros de texto de matemáticas para niños 2+2 =4. De vez en cuando hay referencias a "2+2=5", pero normalmente hay más contexto relacionado con George Orwell o Star Trek cuando ese es el caso. Si esto fuera en ese contexto, el peso estaría más a favor de 2+2=5. Pero ese contexto no existe, por lo que en este caso el siguiente token probablemente sea 4.
- Respuesta : 2+2=4
La formación hace algo como esto:
- entrenamiento: 2+2=4
- entrenamiento: 4/2=2
- entrenamiento: la mitad de 4 es 2
- entrenamiento: 2 de 2 son cuatro
…etcétera.
Esto significa que para aquellos modelos más "lógicos", el proceso de entrenamiento es más riguroso y se centra en garantizar que el modelo comprenda y aplique correctamente los principios lógicos y matemáticos.
El modelo está expuesto a varios problemas matemáticos y sus soluciones, lo que garantiza que pueda generalizar y aplicar estos principios a problemas nuevos e invisibles.
No se puede subestimar la importancia de este proceso de ajuste, especialmente para el razonamiento lógico. Sin él, el modelo podría proporcionar respuestas incorrectas o sin sentido a preguntas lógicas o matemáticas sencillas.
Modelos de imagen versus modelos de lenguaje
Si bien tanto los modelos de imagen como de lenguaje pueden utilizar arquitecturas similares como los transformadores, los datos que procesan son fundamentalmente diferentes:
Modelos de imagen
Estos modelos trabajan con píxeles y a menudo funcionan de manera jerárquica, analizando primero patrones pequeños (como bordes), luego combinándolos para reconocer estructuras más grandes (como formas), y así sucesivamente hasta que comprenden la imagen completa.
Modelos de lenguaje
Estos modelos procesan secuencias de palabras o caracteres. Necesitan comprender el contexto, la gramática y la semántica para generar un texto coherente y contextualmente relevante.
Cómo funcionan las interfaces de IA generativa destacadas
Dall-E + Mitad del viaje
Dall-E es una variante del modelo GPT-3 adaptada para la generación de imágenes. Está entrenado en un vasto conjunto de datos de pares de texto-imagen. Midjourney es otro software de generación de imágenes basado en un modelo propietario.
- Entrada: proporcionas una descripción textual, como "un flamenco de dos cabezas".
- Procesamiento: estos modelos codifican este texto en una serie de números y luego decodifican estos vectores, encontrando relaciones con los píxeles, para producir una imagen. El modelo ha aprendido las relaciones entre descripciones textuales y representaciones visuales a partir de sus datos de entrenamiento.
- Salida: una imagen que coincide o se relaciona con la descripción dada.
Dedos, patrones, problemas.
¿Por qué estas herramientas no pueden generar consistentemente manos que parezcan normales? Estas herramientas funcionan mirando píxeles uno al lado del otro.
Puedes ver cómo funciona esto al comparar imágenes generadas anteriormente o más primitivas con otras más recientes: los modelos anteriores se ven muy borrosos. Por el contrario, los modelos más recientes son mucho más nítidos.
Estos modelos generan imágenes prediciendo el siguiente píxel en función de los píxeles que ya ha generado. Este proceso se repite millones de veces para producir una imagen completa.
Las manos, especialmente los dedos, son complejas y tienen muchos detalles que deben capturarse con precisión.
La posición, longitud y orientación de cada dedo pueden variar mucho en diferentes imágenes.
Al generar una imagen a partir de una descripción textual, el modelo tiene que hacer muchas suposiciones sobre la postura exacta y la estructura de la mano, lo que puede dar lugar a anomalías.
ChatGPT
ChatGPT se basa en la arquitectura GPT-3.5, un modelo basado en transformador diseñado para tareas de procesamiento del lenguaje natural.
- Entrada: un mensaje o una serie de mensajes para simular una conversación.
- Procesamiento: ChatGPT utiliza su vasto conocimiento de diversos textos de Internet para generar respuestas. Considera el contexto proporcionado en la conversación y trata de producir la respuesta más relevante y coherente.
- Salida: una respuesta de texto que continúa o responde a la conversación.
Especialidad
La fortaleza de ChatGPT radica en su capacidad para manejar diversos temas y simular conversaciones similares a las humanas, lo que lo hace ideal para chatbots y asistentes virtuales.
Bard + Experiencia Generativa de Búsqueda (SGE)
Si bien los detalles específicos pueden ser propietarios, Bard se basa en técnicas de inteligencia artificial transformadoras, similares a otros modelos de lenguaje de última generación. SGE se basa en modelos similares, pero se entrelaza con otros algoritmos de aprendizaje automático que utiliza Google.
Es probable que SGE genere contenido utilizando un modelo generativo basado en transformadores y luego extraiga de forma difusa las respuestas de las páginas clasificadas en la búsqueda. (Esto puede no ser cierto. Sólo una suposición basada en cómo parece funcionar al jugar con él. ¡Por favor, no me demanden!)
- Entrada: un mensaje/comando/búsqueda
- Procesamiento: Bard procesa la entrada y trabaja como lo hacen otros LLM. SGE utiliza una arquitectura similar pero agrega una capa donde busca su conocimiento interno (obtenido a partir de datos de entrenamiento) para generar una respuesta adecuada. Considera la estructura, el contexto y la intención del mensaje para producir contenido relevante.
- Salida: Contenido generado que puede ser una historia, una respuesta o cualquier otro tipo de texto.
Aplicaciones de la IA generativa (y sus controversias)
Arte y Diseño
La IA generativa ahora puede crear obras de arte, música e incluso diseños de productos. Esto ha abierto nuevas vías para la creatividad y la innovación.
Controversia
El auge de la IA en el arte ha provocado debates sobre la pérdida de empleos en los campos creativos.
Además, existen preocupaciones sobre:
- Infracciones laborales, especialmente cuando se utiliza contenido generado por IA sin la atribución o compensación adecuada.
- Los ejecutivos que amenazan a los escritores con reemplazarlos con IA es uno de los problemas que impulsó la huelga de escritores.
Procesamiento del lenguaje natural (PNL)
Los modelos de IA ahora se utilizan ampliamente para chatbots, traducción de idiomas y otras tareas de PNL.
Fuera del sueño de la inteligencia artificial general (AGI), este es el mejor uso para los LLM, ya que están cerca de un modelo de PNL “generalista”.
Controversia
Muchos usuarios consideran que los chatbots son impersonales y, a veces, molestos.
Además, si bien la IA ha logrado avances significativos en la traducción de idiomas, a menudo carece de los matices y la comprensión cultural que aportan los traductores humanos, lo que lleva a traducciones impresionantes y defectuosas.
Medicina y descubrimiento de fármacos.
La IA puede analizar rápidamente grandes cantidades de datos médicos y generar posibles compuestos farmacológicos, acelerando el proceso de descubrimiento de fármacos. Muchos médicos ya utilizan los LLM para escribir notas y comunicaciones con los pacientes.
Controversia
Depender de los LLM con fines médicos puede resultar problemático. La medicina requiere precisión y cualquier error o descuido por parte de la IA puede tener graves consecuencias.
La medicina también tiene sesgos que solo se agravan con el uso de LLM. También existen cuestiones similares, como se analiza a continuación, con la privacidad, la eficacia y la ética.
Juego de azar
Muchos entusiastas de la IA están entusiasmados con el uso de la IA en los juegos: dicen que la IA puede generar entornos de juego, personajes e incluso tramas completas realistas, mejorando la experiencia de juego. El diálogo con los NPC se puede mejorar mediante el uso de estas herramientas.
Controversia
Existe un debate sobre la intencionalidad en el diseño de juegos.
Si bien la IA puede generar grandes cantidades de contenido, algunos argumentan que carece del diseño deliberado y la cohesión narrativa que aportan los diseñadores humanos.
Watchdogs 2 tenía NPC programáticos, lo que contribuyó poco a la cohesión narrativa del juego en su conjunto.
Marketing y publicidad
La IA puede analizar el comportamiento del consumidor y generar anuncios personalizados y contenido promocional, haciendo que las campañas de marketing sean más efectivas.
Los LLM tienen el contexto de los escritos de otras personas, lo que los hace útiles para generar historias de usuarios o ideas programáticas más matizadas. En lugar de recomendar televisores a alguien que acaba de comprar uno, los LLM pueden recomendar accesorios que alguien podría querer.
Controversia
The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Las opiniones expresadas en este artículo son las del autor invitado y no necesariamente las de Search Engine Land. Los autores del personal se enumeran aquí.