
Wikipedia Web Scraping 2023: extracción de datos para análisis
Publicado: 2023-03-29El raspado en línea le permite recopilar datos abiertos de sitios web para fines como la comparación de precios, estudios de mercado, verificación de anuncios, etc.
Por lo general, se extraen grandes cantidades de los datos públicos necesarios, pero cuando se enfrenta a bloqueos, la extracción puede convertirse en un desafío.
La restricción puede ser bloqueo de velocidad o bloqueo de IP (la dirección IP de la solicitud está restringida porque se origina en un área prohibida, tipo de IP prohibido, etc.). (la dirección IP está bloqueada porque ha realizado múltiples solicitudes).

Ahora, si está dispuesto a recopilar información y conocimientos útiles, entonces estoy seguro de que debe haber considerado recopilar Wikipedia, la enciclopedia del conocimiento que alberga toneladas de información.
Entendamos algunas cosas sobre el web scraping de Wikipedia.
Tabla de contenido
Raspado web de Wikipedia
El raspado web es un método automatizado para recopilar datos de Internet. En este artículo se proporciona información detallada sobre el raspado web, una comparación con el rastreo web y argumentos a favor del raspado web.
El objetivo es recopilar datos de la página de inicio de Wikipedia utilizando varios métodos de web scraping y luego analizarlos.
Se familiarizará con varios métodos de web scraping, bibliotecas de web scraping de Python y procedimientos de extracción y procesamiento de datos.
Web Scraping y Python
El web scraping es esencialmente el proceso de extraer datos estructurados de una gran cantidad de datos de una gran cantidad de sitios web utilizando un software creado en un lenguaje de programación y guardarlo localmente en nuestros dispositivos, preferiblemente en hojas de Excel, JSON u hojas de cálculo.
Esto ayuda a los programadores a crear código lógico y comprensible para proyectos grandes y pequeños.
Python se considera principalmente como el mejor lenguaje para web scraping. Puede manejar de manera efectiva la mayoría de las tareas relacionadas con el rastreo web y es más versátil.
¿Cómo extraer datos de Wikipedia?
Los datos se pueden extraer de las páginas web de varias maneras.
Por ejemplo, puede implementarlo usted mismo utilizando lenguajes informáticos como Python. Pero, a menos que sea un experto en tecnología, necesitará estudiar mucho antes de poder hacer mucho con este proceso.
También lleva mucho tiempo y puede llevar tanto tiempo como revisar manualmente las páginas de Wikipedia. Además, los web scrapers gratuitos están disponibles en línea. Sin embargo, con frecuencia carecen de confiabilidad y sus proveedores pueden tener malas intenciones.
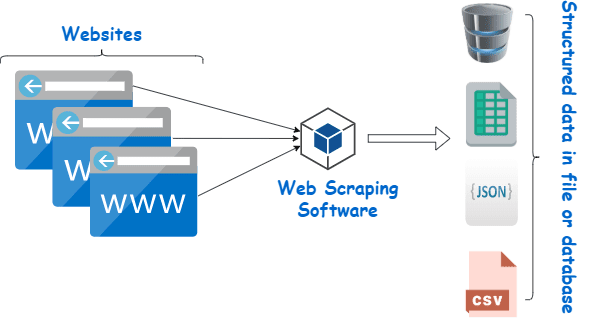
Invertir en un web scraper decente de un proveedor de confianza es el mejor método para recopilar datos Wiki.
El siguiente paso suele ser simple y sin complicaciones porque el proveedor le ofrecerá instrucciones sobre cómo instalar y utilizar el raspador.
Un proxy es una herramienta que puede usar junto con su wiki scraper para raspar datos de manera más efectiva. Los marcos basados en Python como Scrapy, Scraping Robot y Beautiful Soup son solo algunos ejemplos de lo fácil que es raspar usando este lenguaje.
Proxy para extraer datos de Wikipedia
Necesita proxies que sean extremadamente rápidos, seguros de usar y que garanticen que no fallarán cuando los necesite para extraer datos de manera efectiva. Dichos proxies están disponibles en Rayobyte a precios razonables.
Nos esforzamos en ofrecer una variedad de proxies porque somos conscientes de que cada usuario tiene preferencias y casos de uso diferentes.
Rotación de proxies para web scraping Wikipedia
Una instancia de un proxy es aquella que rota su dirección IP de forma regular. Además, para evitar interrupciones, la dirección IP se cambia inmediatamente cuando se produce una prohibición. Esto hace que este proxy en particular sea una excelente opción para el raspado de sitios.
Los proxies estáticos, en comparación, solo tienen una dirección IP. Si su ISP no permite los reemplazos automáticos, se topará con un muro de ladrillos si solo tiene acceso a una dirección IP y se bloquea. Debido a esto, los proxies estáticos no son la mejor opción para el web scraping.
Proxies residenciales para web scraping Wiki data
Los proxies residenciales son direcciones IP de proxy que los proveedores de servicios de Internet (ISP) distribuyen y están asociadas con hogares específicos. Debido a que provienen de personas reales, obtenerlos es todo un desafío. Como resultado, son escasos y relativamente caros.


Cuando utiliza proxies residenciales para recopilar datos, parece ser un usuario cotidiano porque están vinculados a las direcciones de personas reales.
Por lo tanto, el uso de proxies residenciales reduce significativamente la posibilidad de ser descubierto y bloqueado. Por lo tanto, son excelentes candidatos para el raspado de datos.
Proxies residenciales rotativos para recopilar datos wiki
Un proxy residencial rotativo, que combina los dos tipos de los que acabamos de hablar, es el mejor proxy para el web scraping de Wikipedia.
Puede acceder a una gran cantidad de direcciones IP domésticas utilizando un proxy que las rota con frecuencia.
Esto es fundamental porque, a pesar de la dificultad para identificar proxies residenciales, el volumen de solicitudes que generan eventualmente llamará la atención del sitio web que se raspa.
La rotación asegura que el proyecto pueda continuar incluso si la dirección IP inevitablemente se incluye en la lista negra.
Por lo tanto, tenemos lo que necesita, ya sea que decida ir con varios proxies de centro de datos o prefiera invertir en algunos proxies residenciales.
Disfrutará de la mejor experiencia de raspado web con proxies que se ejecutan a una velocidad de 1 GBS, ancho de banda ilimitado y asistencia al cliente las 24 horas.
También puede leer
- Las mejores técnicas de Web Scraping: una guía práctica
- Revisión de Octoparse ¿Es realmente una buena herramienta de raspado web?
- Las mejores herramientas de web scraping
- ¿Qué es Web Scraping? - ¿Cómo se usa? Cómo puede beneficiar a su negocio
¿Por qué debería raspar Wikipedia?
Wikipedia es uno de los servicios más confiables y ricos en información en el mundo en línea en este momento. Hay respuestas e información para casi todo tipo de temas que se te ocurran en esta plataforma.
Entonces, naturalmente, Wikipedia es una gran fuente para extraer datos. Discutamos las principales razones por las que debería raspar Wikipedia.
Web scraping para investigación académica
La recolección de datos es una de las actividades más dolorosas involucradas en la investigación. Como ya se discutió, los raspadores web hacen que este procedimiento sea más rápido y fácil, a la vez que le ahorran una tonelada de tiempo y energía.
Con un raspador web, puede escanear rápidamente numerosas páginas wiki y recopilar todos los datos que necesita de manera organizada.
Suponga por un momento que su objetivo es determinar si la depresión y la exposición a la luz solar varían según el país.
Puede usar un raspador Wiki para localizar información como la prevalencia de la depresión en diferentes países y sus horas de sol en lugar de revisar numerosas entradas de Wikipedia.
Manejo de reputación
Crear una página de Wikipedia se ha convertido en una estrategia de marketing obligatoria para muchos tipos diferentes de empresas en la era moderna porque las publicaciones de Wikipedia aparecen con frecuencia en la primera página de Google.
Pero tener una página en Wikipedia no debería ser el final de sus esfuerzos de marketing. Wikipedia es una plataforma de colaboración colectiva, por lo que el vandalismo es algo que ocurre con bastante frecuencia.
Como resultado, alguien podría agregar información desfavorable a la página de su empresa y dañar su reputación. Alternativamente, podrían difamar su negocio en un artículo wiki relevante.
Debido a esto, debe estar atento a su página Wiki, así como a otras páginas que mencionen su negocio una vez que se haya realizado. Puedes hacer esto fácilmente con la ayuda de un wiki scraper.
Puede buscar periódicamente en las páginas de Wikipedia referencias a su negocio y señalar cualquier instancia de vandalismo allí.
Impulsar el SEO
Puede utilizar Wikipedia para aumentar el tráfico a su sitio web.
Cree una lista de artículos que le gustaría cambiar utilizando un raspador de datos Wiki para ubicar páginas que sean pertinentes para su negocio y su público objetivo.
Comience leyendo los artículos y haciendo algunos ajustes útiles para ganar credibilidad como colaborador del sitio.
Una vez que haya establecido cierta credibilidad, puede agregar conexiones a su sitio web en lugares donde hay enlaces rotos o donde se requieren citas.
Enlaces rápidos
- Los mejores proxies franceses
- El mejor proxy de Spotify
- Los mejores representantes de Nike
Bibliotecas de Python utilizadas para web scraping
Python es el lenguaje de programación y la herramienta de raspado web más popular y de mayor reputación en el mundo, como ya se dijo. Ahora echemos un vistazo a las bibliotecas de raspado web de Python que están disponibles en este momento.
Solicitudes (HTTP para humanos) Biblioteca para Web Scraping
Se utiliza para enviar diferentes solicitudes HTTP, como GET y POST. Entre todas las bibliotecas, es la más fundamental pero también la más crucial.
Biblioteca lxml para Web Scraping
El paquete lxml ofrece un análisis muy rápido y de alto rendimiento de texto HTML y XML de sitios web. Este es el que debe elegir si tiene la intención de raspar grandes bases de datos.
Hermosa biblioteca de sopas para Web Scraping
Su trabajo es construir un árbol de análisis para el análisis de contenido. Un excelente lugar para comenzar para principiantes y es muy fácil de usar.
Biblioteca Selenium para Web Scraping
Esta biblioteca resuelve el problema que tienen todas las bibliotecas mencionadas anteriormente, es decir, extraer contenido de páginas web pobladas dinámicamente.
Originalmente fue diseñado para pruebas automatizadas de aplicaciones web. Debido a esto, es más lento e inadecuado para tareas a nivel industrial.
Scrapy para Web Scraping
Un marco de web scraping completo que utiliza el uso asíncrono es el BOSS de todos los paquetes. Esto mejora la eficiencia y lo hace increíblemente rápido.
Conclusión
Así que este fue prácticamente el aspecto más importante que necesita saber sobre Wikipedia Web Scraping. ¡Estén atentos con nosotros para más publicaciones informativas sobre Web Scraping y mucho más!
enlaces rápidos
- Los mejores proxies para la agregación de tarifas de viaje
- Los mejores proxies franceses
- Los mejores servidores proxy de Tripadvisor
- Los mejores servidores proxy de Etsy
- Código de cupón IPRoyal
- Los mejores servidores proxy de TikTok