
Estudio de caso de SEO de un año: lo que necesita saber sobre Googlebot
Publicado: 2019-08-30Nota del editor: el director ejecutivo del rastreador JetOctopus, Serge Bezborodov, brinda consejos de expertos sobre cómo hacer que su sitio web sea atractivo para Googlebot. Los datos de este artículo se basan en una investigación de un año y 300 millones de páginas rastreadas.
Hace algunos años, estaba tratando de aumentar el tráfico en nuestro sitio web agregador de empleos con 5 millones de páginas. Decidí utilizar los servicios de una agencia de SEO, esperando que el tráfico se disparara. Pero estaba equivocado. En lugar de una auditoría exhaustiva, obtuve lectura de cartas del tarot. Es por eso que volví al punto de partida y creé un rastreador web para un análisis integral de SEO en la página.
Llevo más de un año espiando a Googlebot y ahora estoy listo para compartir información sobre su comportamiento. Espero que mis observaciones al menos aclaren cómo funcionan los rastreadores web y, como máximo, lo ayudarán a realizar la optimización en la página de manera eficiente. Reuní los datos más significativos que son útiles para un sitio web nuevo o uno que tiene miles de páginas.
¿Están apareciendo sus páginas en las SERP?
Para saber con certeza qué páginas están en los resultados de búsqueda, debe verificar la capacidad de indexación de todo el sitio web. Sin embargo, los análisis de cada URL en un sitio web de más de 10 millones de páginas cuestan una fortuna, tanto como un auto nuevo.
Usemos el análisis de archivos de registro en su lugar. Trabajamos con sitios web de la siguiente manera: rastreamos las páginas web como lo hace el robot de búsqueda y luego analizamos los archivos de registro que se recopilaron durante la mitad del año. Los registros muestran si los bots visitan el sitio web, qué páginas se rastrearon y cuándo y con qué frecuencia los bots visitaron las páginas.
El rastreo es el proceso mediante el cual los robots de búsqueda visitan su sitio web, procesan todos los enlaces en las páginas web y colocan estos enlaces en línea para su indexación. Durante el rastreo, los bots comparan las URL recién procesadas con las que ya están en el índice. Por lo tanto, los bots actualizan los datos y agregan/eliminan algunas URL de la base de datos del motor de búsqueda para proporcionar los resultados más relevantes y actualizados para los usuarios.
Ahora, podemos sacar fácilmente estas conclusiones:
- A menos que el robot de búsqueda estuviera en la URL, esta URL probablemente no estará en el índice.
- Si Googlebot visita la URL varias veces al día, esa URL es de alta prioridad y, por lo tanto, requiere su atención especial.
En conjunto, esta información revela lo que impide el crecimiento orgánico y el desarrollo de su sitio web. Ahora, en lugar de operar a ciegas, su equipo puede optimizar sabiamente un sitio web.
Trabajamos principalmente con sitios web grandes porque si su sitio web es pequeño, Googlebot rastreará todas sus páginas web tarde o temprano.
Por el contrario, los sitios web con más de 100.000 páginas se enfrentan a un problema cuando el rastreador visita páginas que son invisibles para los webmasters. Se puede desperdiciar un valioso presupuesto de rastreo en estas páginas inútiles o incluso dañinas. Al mismo tiempo, es posible que el bot nunca encuentre sus páginas rentables porque hay un desorden en la estructura del sitio web.
El presupuesto de rastreo son los recursos limitados que Googlebot está dispuesto a gastar en su sitio web. Fue creado para priorizar qué analizar y cuándo. El tamaño del presupuesto de rastreo depende de muchos factores, como el tamaño de su sitio web, su estructura, el volumen y la frecuencia de las consultas de los usuarios, etc.
Tenga en cuenta que el robot de búsqueda no está interesado en rastrear su sitio web por completo.
El objetivo principal del bot del motor de búsqueda es brindar a los usuarios las respuestas más relevantes con pérdidas mínimas de recursos.El bot rastrea tantos datos como necesita para el propósito principal. Por lo tanto, es SU tarea ayudar al bot a obtener el contenido más útil y rentable.
Espiar al robot de Google
Durante el último año, escaneamos más de 300 millones de URL y 6 mil millones de líneas de registro en grandes sitios web. En función de estos datos, rastreamos el comportamiento de Googlebot para ayudar a responder las siguientes preguntas:
- ¿Qué tipos de páginas se ignoran?
- ¿Qué páginas se visitan con frecuencia?
- ¿Qué es digno de atención para el bot?
- ¿Qué no tiene valor?
A continuación se muestra nuestro análisis y hallazgos, y no una reescritura de las Directrices para webmasters de Google. De hecho, no damos ninguna recomendación no comprobada e injustificada. Cada punto se basa en estadísticas y gráficos reales para su conveniencia.
Vayamos al grano y descubramos:
- ¿Qué es lo que realmente le importa a Googlebot?
- ¿Qué determina si el bot visita la página o no?
Identificamos los siguientes factores:
Distancia desde el índice
DFI significa Distancia desde el índice y es qué tan lejos está su URL de la URL principal/raíz/índice en clics. Es uno de los criterios más cruciales que afecta la frecuencia de las visitas de Googlebot. Aquí hay un video educativo para aprender más sobre DFI .
Tenga en cuenta que DFI no es el número de barras en el directorio URL como, por ejemplo:
site.com / tienda /iphone/iphoneX.html – DFI – 3
Entonces, DFI se cuenta exactamente por CLICKS desde la página principal
https://site.com/shop/iphone/iphoneX.html
https://site.com Catálogo de iPhones → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
A continuación, puede ver cómo el interés de Googlebot en la URL con su DFI se fue reduciendo gradualmente durante el último mes y durante los últimos seis meses.
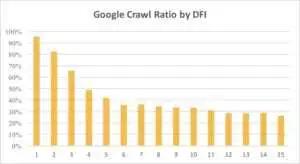
Como puede ver, si DFI es 5 t0 6, Googlebot rastrea solo la mitad de las páginas web. Y el porcentaje de páginas procesadas se reduce si la DFI es mayor. Se unificaron los indicadores de la tabla para 18 millones de páginas. Tenga en cuenta que los datos pueden variar según el nicho del sitio web en particular.
¿Qué hacer?
Es obvio que la mejor estrategia en este caso es evitar DFI de más de 5, construir una estructura de sitio web fácil de navegar, prestar especial atención a los enlaces, etc.
La verdad es que estas medidas consumen mucho tiempo para sitios web de más de 100.000 páginas. Por lo general, los sitios web grandes tienen una larga historia de rediseños y migraciones. Es por eso que los webmasters no deberían simplemente eliminar páginas con DFI de 10, 12 o incluso 30. Además, insertar un enlace de páginas visitadas con frecuencia no resolverá el problema.
La forma óptima de hacer frente a DFI largos es verificar y estimar si estas URL son relevantes, rentables y qué posiciones tienen en los SERP.
Las páginas con DFI largo pero buenas posiciones en SERP tienen un alto potencial. Para aumentar el tráfico en páginas de alta calidad, los webmasters deben insertar enlaces de las siguientes páginas. Uno o dos enlaces no son suficientes para un progreso tangible.
Puede ver en el siguiente gráfico que Googlebot visita las URL con más frecuencia si hay más de 10 enlaces en la página.
Enlaces
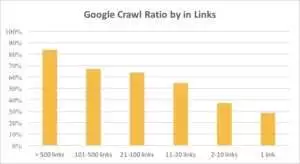
De hecho, cuanto más grande es un sitio web, más significativo es el número de enlaces en las páginas web. Estos datos son en realidad de sitios web de más de 1 millón de páginas.

Si descubrió que hay menos de 10 enlaces en sus páginas rentables, no entre en pánico. Primero, verifique si estas páginas son de alta calidad y rentables. Cuando lo haga, inserte enlaces en páginas de alta calidad sin prisas y con iteraciones cortas, analizando los registros después de cada paso.
Tamaño del contenido
El contenido es uno de los aspectos más populares del análisis SEO. Por supuesto, cuanto más contenido relevante haya en su sitio web, mejor será su tasa de rastreo. A continuación, puede ver cómo disminuye drásticamente el interés de Googlebot para las páginas con menos de 500 palabras.
¿Qué hacer?
Según mi experiencia, casi la mitad de todas las páginas con menos de 500 palabras son páginas basura. Vimos un caso en el que un sitio web contenía 70.000 páginas con solo el tamaño de la ropa enumerada, por lo que solo una parte de estas páginas estaba en el índice.
Por lo tanto, primero verifique si realmente necesita esas páginas. Si estas URL son importantes, debe agregar contenido relevante en ellas. Si no tiene nada que agregar, simplemente relájese y deje estas URL como están. A veces es mejor no hacer nada que publicar contenido inútil.
Otros factores
Los siguientes factores pueden afectar significativamente la tasa de rastreo:
Tiempo de carga
La velocidad de la página web es crucial para el rastreo y la clasificación. El bot es como un humano: odia esperar demasiado a que se cargue una página web. Si hay más de 1 millón de páginas en su sitio web, el robot de búsqueda probablemente descargará cinco páginas con un tiempo de carga de 1 segundo en lugar de esperar a que una página se cargue en 5 segundos.
¿Qué hacer?
De hecho, esta es una tarea técnica y no existe una solución única, como usar un servidor más grande. La idea principal es encontrar el cuello de botella del problema. Debe comprender por qué las páginas web se cargan lentamente. Solo después de que se revela la razón, puede tomar medidas.
Proporción de contenido único y con plantilla
El equilibrio entre datos únicos y basados en plantillas es importante. Por ejemplo, tiene un sitio web con variaciones de nombres de mascotas. ¿Cuánto contenido relevante y único realmente puedes recopilar sobre este tema?
Luna fue el nombre de perro "celebridad" más popular, seguido de Stella, Jack, Milo y Leo.
A los robots de búsqueda no les gusta gastar sus recursos en este tipo de páginas.
¿Qué hacer?
Mantener el equilibrio. A los usuarios y bots no les gusta visitar páginas con plantillas complicadas, un montón de enlaces salientes y poco contenido.
Páginas huérfanas
Las páginas huérfanas son URL que no están en la estructura del sitio web y no conoce estas páginas, pero los bots podrían rastrear estas páginas huérfanas. Para que quede claro, mira el Círculo de Euler en la imagen de abajo:

Puede ver la situación normal del sitio web joven, cuya estructura no ha cambiado por un tiempo. Hay 900.000 páginas que usted y el rastreador pueden analizar. El rastreador procesa unas 500.000 páginas, pero Google las desconoce. Si hace que estas 500,000 URL sean indexables, su tráfico aumentará con seguridad.
Preste atención: Incluso un sitio web joven contiene algunas páginas (la parte azul en la imagen) que no están en la estructura del sitio web pero que son visitadas regularmente por bots.
Y estas páginas podrían contener contenido basura, como consultas inútiles de visitantes generadas automáticamente.
Pero los grandes sitios web rara vez son tan precisos. Muy a menudo, los sitios web con historial se ven así:

Aquí está el otro problema: Google sabe más sobre su sitio web que usted. Puede haber páginas eliminadas, páginas en JavaScript o Ajax, redireccionamientos rotos, etc., etc. Una vez nos enfrentamos a una situación en la que aparecía una lista de 500.000 enlaces rotos en el mapa del sitio debido a un error del programador. Después de tres días, se encontró y solucionó el error, ¡pero Googlebot había estado visitando estos enlaces rotos durante medio año!
Muy a menudo, su presupuesto de rastreo se desperdicia con frecuencia en estas páginas huérfanas.
¿Qué hacer?
Hay dos formas de solucionar este problema potencial: la primera es canónica: limpiar el desorden. Organice la estructura del sitio web, inserte enlaces internos correctamente, agregue páginas huérfanas al DFI agregando enlaces de páginas indexadas, establezca la tarea para los programadores y espere la próxima visita de Googlebot.
La segunda forma es rápida: recopile la lista de páginas huérfanas y verifique si son relevantes. Si la respuesta es "sí", cree el mapa del sitio con estas URL y envíelo a Google. De esta manera es más fácil y rápido, pero solo la mitad de las páginas huérfanas estarán en el índice.
El siguiente nivel
Los algoritmos de los motores de búsqueda han mejorado durante dos décadas, y es ingenuo pensar que el rastreo de búsqueda podría explicarse con unos pocos gráficos.
Recopilamos más de 200 parámetros diferentes para cada página y esperamos que este número aumente a finales de año. Imagine que su sitio web es la tabla con 1 millón de líneas (páginas) y multiplique estas líneas por 200 columnas, la muestra simple no es suficiente para una auditoría técnica integral. ¿Estás de acuerdo?
Decidimos profundizar más y utilizar el aprendizaje automático para descubrir qué influye en el rastreo de Googlebots en cada caso.

Por un lado, los enlaces a sitios web son cruciales, mientras que el contenido es el factor clave para el otro.
El punto principal de esta tarea era obtener respuestas fáciles a partir de datos complicados y masivos: ¿Qué es lo que más impacta en la indexación de su sitio web? ¿Qué grupos de URL están conectados con los mismos factores? Para que puedas trabajar con ellos de manera integral.
Antes de descargar y analizar registros en nuestro sitio web agregador de HotWork, la historia de las páginas huérfanas que son visibles para los bots pero no para nosotros me parecía poco realista. Pero la situación real me sorprendió aún más: Crawl mostró 500 páginas con redireccionamiento 301, pero Yandex encontró 700 000 páginas con el mismo código de estado.
Por lo general, a los geeks técnicos no les gusta almacenar archivos de registro porque estos datos "sobrecargan" los discos. Pero objetivamente, en la mayoría de los sitios web con hasta 10 millones de visitas al mes, la configuración básica de almacenamiento de registros funciona perfectamente.
Hablando del volumen de registros, la mejor solución es crear un archivo y descargarlo en Amazon S3-Glacier (puede almacenar 250 GB de datos por solo $1). Para los administradores de sistemas, esta tarea es tan fácil como preparar una taza de café. En el futuro, los registros históricos ayudarán a revelar errores técnicos y estimar la influencia de las actualizaciones de Google en su sitio web.