
Un parcours de test E2E Partie 1 : STUI vers WebdriverIO
Publié: 2019-11-21Remarque : Il s'agit d'un message de #frontend@twiliosendgrid. Pour d'autres articles d'ingénierie, rendez-vous sur le blog technique.
Alors que l'architecture frontale de SendGrid commençait à mûrir dans nos applications Web, nous voulions ajouter un autre niveau de test en plus de notre couche de test d'unité et d'intégration habituelle. Nous avons cherché à créer de nouvelles pages et fonctionnalités avec une couverture de test E2E (de bout en bout) avec des outils d'automatisation du navigateur.
Nous souhaitions automatiser les tests du point de vue du client et éviter autant que possible les tests de régression manuels pour tout changement important pouvant survenir à n'importe quelle partie de la pile. Nous avions, et avons toujours, l' objectif suivant : fournir un moyen d'écrire des tests d'automatisation E2E cohérents, débogables, maintenables et précieux pour nos applications frontales et de les intégrer à CICD (intégration continue et déploiement continu).
Nous avons expérimenté plusieurs approches techniques jusqu'à ce que nous ayons finalisé notre solution idéale pour les tests E2E. À un niveau élevé, cela résume notre voyage :
- Construire notre propre solution Ruby Selenium interne personnalisée, SiteTestUI alias STUI
- Transition de STUI vers un WebdriverIO basé sur un nœud
- Ne pas être satisfait de l'une ou l'autre configuration et finalement migrer vers Cypress
Ce billet de blog est l'une des deux parties documentant et mettant en évidence nos expériences, les leçons apprises et les compromis avec chacune des approches utilisées en cours de route pour, espérons-le, vous guider, ainsi que d'autres développeurs, sur la façon de connecter des tests E2E avec des modèles et des stratégies de test utiles.
La première partie englobe nos premières difficultés avec STUI, comment nous avons migré vers WebdriverIO, et pourtant nous avons encore connu de nombreuses chutes similaires à STUI. Nous verrons comment nous avons écrit des tests avec WebdriverIO, dockerisé les tests pour les exécuter dans un conteneur et finalement intégré les tests avec Buildkite, notre fournisseur CICD.
Si vous souhaitez passer à l'étape où nous en sommes avec les tests E2E aujourd'hui, veuillez passer à la deuxième partie au fur et à mesure de notre migration finale de STUI et WebdriverIO vers Cypress et de la manière dont nous l'avons configurée dans différentes équipes.
TLDR : Nous avons rencontré des problèmes et des difficultés similaires avec les deux solutions d'encapsulation Selenium, STUI et WebdriverIO, que nous avons finalement commencé à rechercher des alternatives dans Cypress. Nous avons appris un tas de leçons perspicaces pour aborder l'écriture de tests E2E et l'intégration avec Docker et Buildkite.
Table des matières:
Première incursion dans les tests E2E : siteTESUI alias STUI
Passer de STUI à WebdriverIO
Étape 1 : Décider des dépendances pour WebdriverIO
Étape 2 : Configurations et scripts d'environnement
Étape 3 : Mise en œuvre locale des tests ENE
Étape 4 : dockeriser tous les tests
Étape 5 : Intégration avec CICD
Compromis avec WebdriverIo
Passage à Cypress
Première incursion dans les tests E2E : SiteTestUI alias STUI
Lors de la recherche initiale d'un outil d'automatisation de navigateur, nos SDET (ingénieurs en développement de logiciels en test) se sont lancés dans la création de notre propre solution interne personnalisée construite avec Ruby et Selenium, en particulier Rspec et un framework Selenium personnalisé appelé Gridium. Nous avons apprécié sa prise en charge multi-navigateurs, sa capacité à configurer nos propres intégrations personnalisées avec TestRail pour nos cas de test d'ingénieur QA (assurance qualité) et l'idée de créer le référentiel idéal pour toutes les équipes frontales pour écrire des tests E2E en un seul endroit et être exécuter selon un calendrier.
En tant que développeur front-end désireux d'écrire des tests E2E pour la première fois avec les outils que les SDET ont construits pour nous, nous avons commencé à implémenter des tests pour les pages que nous avons déjà publiées et avons réfléchi à la manière de configurer correctement les utilisateurs et les données de départ pour se concentrer sur des parties de la fonctionnalité que nous voulions tester. Nous avons appris de grandes choses en cours de route, comme la formation d'objets de page pour organiser les fonctionnalités d'assistance et les sélecteurs d'éléments avec lesquels nous souhaitons interagir par page et avons commencé à former des spécifications qui suivaient cette structure :
Nous avons progressivement construit des suites de tests substantielles dans différentes équipes du même référentiel en suivant des schémas similaires, mais nous avons rapidement connu de nombreuses frustrations qui ralentiraient énormément nos progrès pour les nouveaux développeurs et les contributeurs cohérents à STUI tels que :
- La mise en place et l'exécution ont nécessité un temps et des efforts considérables pour installer tous les pilotes de navigateur, les dépendances Ruby Gem et les versions correctes avant même d'exécuter les suites de tests. Nous devions parfois comprendre pourquoi les tests s'exécutaient sur une machine par rapport à la machine d'une autre personne et en quoi leurs configurations différaient.
- Les suites de tests ont proliféré et ont fonctionné pendant des heures jusqu'à leur achèvement. Étant donné que toutes les équipes ont contribué au même référentiel, l'exécution de tous les tests en série signifiait attendre plusieurs heures pour que la suite de tests globale s'exécute et plusieurs équipes poussant un nouveau code ont potentiellement conduit à un autre test cassé ailleurs.
- Nous sommes devenus frustrés par les sélecteurs CSS floconneux et les sélecteurs XPath compliqués . Cette image ci-dessous explique suffisamment comment l'utilisation de XPath peut rendre les choses plus compliquées et celles-ci étaient parmi les plus simples.

- Les tests de débogage étaient pénibles . Nous avions du mal à déboguer de vagues sorties d'erreur et nous n'avions généralement aucune idée de l'endroit et de la manière dont les choses échouaient. Nous ne pouvions que répéter les tests et observer le navigateur pour en déduire où il avait éventuellement échoué et quel code en était responsable. Lorsqu'un test a échoué dans un environnement Docker dans CICD sans grand chose à regarder autre que les sorties de la console, nous avons eu du mal à reproduire localement et à résoudre le problème.
- Nous avons rencontré des bugs et des lenteurs de Selenium . Les tests s'exécutaient lentement en raison de toutes les requêtes envoyées du serveur au navigateur et parfois nos tests plantaient complètement lors de la tentative de sélection de nombreux éléments sur la page ou pour des raisons inconnues lors des tests.
- Plus de temps a été consacré à la réparation et au saut des tests et les exécutions de tests de construction planifiées interrompues ont commencé à être ignorées. Les tests n'ont pas fourni de valeur en signifiant réellement les vraies erreurs dans le système.
- Nos équipes frontales se sont senties déconnectées des tests E2E car ils existaient dans un référentiel distinct de ceux des applications Web respectives. Nous avions souvent besoin d'ouvrir les deux référentiels en même temps et de continuer à parcourir les bases de code en plus des onglets du navigateur lorsque les tests étaient exécutés.
- Les équipes frontend n'aimaient pas passer de l'écriture de code en JavaScript ou TypeScript au quotidien à Ruby et devoir réapprendre à écrire des tests chaque fois qu'elles contribuaient à STUI.
- Comme il s'agissait d'une première prise pour beaucoup d'entre nous lors de la contribution au test, nous sommes tombés dans de nombreux antimodèles comme la création d'un état via l'interface utilisateur pour la connexion, ne pas faire suffisamment de démontage ou de configuration via l'API, et ne pas avoir assez de documentation à suivre pour ce qui fait un excellent test.
Malgré nos progrès vers l'écriture d'un nombre considérable de tests E2E pour de nombreuses équipes différentes dans un seul dépôt et l'apprentissage de quelques modèles utiles à emporter avec nous, nous avons eu des maux de tête avec l'expérience globale du développeur, de multiples points de défaillance et le manque de tests valables et stables. pour vérifier l'ensemble de notre pile.
Nous avons apprécié un moyen de permettre à d'autres développeurs frontaux et AQ de créer leurs propres suites de tests E2E stables avec JavaScript qui réside avec leur propre code d'application pour promouvoir la réutilisation, la proximité et la propriété des tests. Cela nous a amenés à sonder WebdriverIO, un framework Selenium basé sur JavaScript pour les tests d'automatisation du navigateur, en remplacement initial de STUI, la solution interne personnalisée Ruby Selenium.
Nous connaîtrions plus tard ses chutes et finirions par passer à Cypress (passez rapidement à la partie 2 ici si les éléments de WebdriverIO ne vous intéressent pas), mais nous avons acquis une expérience inestimable en établissant une infrastructure standardisée dans le dépôt de chaque équipe, en intégrant des tests E2E dans CICD pour notre frontend équipes, et en adoptant des modèles techniques qui méritent d'être documentés dans notre parcours et pour que d'autres sachent qui pourrait être sur le point de se lancer dans WebdriverIO ou toute autre solution de test E2E.
Passer de STUI à WebdriverIO

Lorsque nous nous sommes lancés dans WebdriverIO pour, espérons-le, atténuer les frustrations que nous avons éprouvées, nous avons expérimenté en demandant à chaque équipe frontale de convertir leurs tests d'automatisation existants écrits avec l'approche Ruby Selenium en tests WebdriverIO en JavaScript ou TypeScript et de comparer la stabilité, la vitesse, l'expérience des développeurs et la maintenance globale de les tests.
Afin d'atteindre notre configuration idéale consistant à avoir des tests E2E résidant dans les référentiels d'applications des équipes frontales et s'exécutant à la fois dans les pipelines CICD et planifiés, nous avons récapitulé les étapes suivantes qui s'appliquent généralement à toute équipe souhaitant intégrer un cadre de test E2E avec des objectifs similaires. :
- Installation et choix des dépendances à connecter au framework de test
- Établir des configurations d'environnement et des commandes de script
- Implémentation de tests E2E qui passent localement contre différents environnements
- Dockeriser les tests
- Intégration de tests dockerisés avec le fournisseur CICD
Étape 1 : Décider des dépendances pour WebdriverIO
WebdriverIO offre aux développeurs la possibilité de choisir parmi de nombreux frameworks, reporters et services pour démarrer le testeur. Cela a nécessité beaucoup de bricolage et de recherche pour que les équipes s'installent sur certaines bibliothèques pour démarrer.
Étant donné que WebdriverIO n'est pas prescriptif sur ce qu'il faut utiliser, il a ouvert la porte aux équipes frontales pour avoir différentes bibliothèques et configurations, bien que les tests de base globaux soient cohérents dans l'utilisation de l'API WebdriverIO.
Nous avons choisi de laisser chacune des équipes frontales personnaliser en fonction de leurs préférences et nous avons généralement opté pour l'utilisation de Mocha comme framework de test, Mochawesome comme reporter, le service Selenium Standalone et la prise en charge de Typescript. Nous avons choisi Mocha et Mochawesome en raison de la familiarité de nos équipes et de l'expérience antérieure avec Mocha auparavant, mais d'autres équipes ont également décidé d'utiliser d'autres alternatives.
Étape 2 : Configurations et scripts d'environnement
Après avoir choisi l'infrastructure WebdriverIO, nous avions besoin d'un moyen pour nos tests WebdriverIO de s'exécuter avec des paramètres différents pour chaque environnement. Voici une liste illustrant la plupart des cas d'utilisation de la manière dont nous voulions exécuter ces tests et pourquoi nous souhaitions les prendre en charge :
- Contre un serveur de développement Webpack s'exécutant sur localhost (c'est-à-dire http://localhost:8000) et ce serveur de développement pointerait vers une certaine API d'environnement comme testing ou staging (c'est-à-dire https://testing.api.com ou https:// staging.api.com).
Pourquoi? Parfois, nous devons apporter des modifications à notre application Web locale, telles que l'ajout de sélecteurs plus spécifiques pour nos tests afin d'interagir avec les éléments de manière plus robuste ou nous étions en train de développer une nouvelle fonctionnalité et devions ajuster et valider les tests d'automatisation existants. passerait localement contre nos nouveaux changements de code. Chaque fois que le code de l'application a changé et que nous n'avons pas encore poussé vers l'environnement déployé, nous avons utilisé cette commande pour exécuter nos tests sur notre application Web locale. - Par rapport à une application déployée pour un certain environnement (c'est-à-dire https://testing.app.com ou https://staging.app.com) comme les tests ou la mise en scène
Pourquoi? D'autres fois, le code de l'application ne change pas, mais nous devrons peut-être modifier notre code de test pour corriger certaines irrégularités ou nous nous sentirons suffisamment en confiance pour ajouter ou supprimer des tests sans apporter de modifications frontales. Nous avons beaucoup utilisé cette commande pour mettre à jour ou déboguer les tests localement par rapport à l'application déployée afin de simuler plus précisément l'exécution de nos tests dans les pipelines CICD. - Exécution dans un conteneur Docker sur une application déployée pour un certain environnement, comme les tests ou la mise en scène
Pourquoi? Ceci est destiné aux pipelines CICD afin que nous puissions déclencher l'exécution de tests E2E dans un conteneur Docker par exemple sur l'application déployée intermédiaire et nous assurer qu'ils réussissent avant de déployer le code en production ou lors d'exécutions de tests planifiées dans un pipeline dédié. Lors de la configuration initiale de ces commandes, nous avons effectué de nombreux essais et erreurs pour créer des conteneurs Docker avec différentes valeurs de variables d'environnement et tester pour voir les tests appropriés exécutés avec succès avant de les connecter à notre fournisseur CICD, Buildkite.
Pour ce faire, nous avons configuré un fichier de configuration de base général avec des propriétés partagées et de nombreux fichiers spécifiques à l'environnement, de sorte que chaque fichier de configuration d'environnement fusionnerait avec le fichier de base et écraserait ou ajouterait les propriétés requises pour s'exécuter. Nous aurions pu avoir un fichier pour chaque environnement sans avoir besoin d'un fichier de base, mais cela entraînerait de nombreuses duplications dans les paramètres communs. Nous avons choisi d'utiliser une bibliothèque comme deepmerge pour le gérer pour nous, mais il est important de noter que la fusion n'est pas toujours parfaite avec des objets ou des tableaux imbriqués. Vérifiez toujours les configurations de sortie résultantes, car cela peut entraîner un comportement indéfini lorsqu'il existe des propriétés en double qui n'ont pas fusionné correctement.
Nous avons formé un fichier de configuration de base commun , wdio.conf.js , comme ceci :
Pour s'adapter à notre premier cas d'utilisation majeur consistant à exécuter des tests E2E sur un serveur de développement Webpack local pointé vers une API d'environnement, nous avons généré le fichier de configuration localhost, wdio.localhost.conf.js , comme suit :
Notez que nous avons fusionné le fichier de base et ajouté les propriétés spécifiques de localhost au fichier pour le rendre plus compact et plus facile à entretenir. Nous utilisons également le service Selenium Standalone pour faire tourner différents types de navigateurs, c'est-à-dire des capacités.
Pour le deuxième cas d'utilisation consistant à exécuter des tests E2E sur une application Web déployée, nous configurons les fichiers de configuration de l'application de test et de staging , `wdio.testing.conf.js` et wdio.staging.conf.js , similaires à ceci :
Ici, nous avons ajouté des variables d'environnement supplémentaires aux fichiers de configuration, telles que les informations d'identification de connexion aux utilisateurs dédiés sur la mise en scène et mis à jour le "baseUrl" pour pointer vers l'URL de l'application de mise en scène déployée.
Pour le troisième cas d'utilisation consistant à exécuter des tests E2E dans un conteneur Docker sur une application Web déployée dans le domaine de notre fournisseur CICD, nous avons configuré les fichiers de configuration CICD, wdio.cicd.testing.conf.js et wdio.cicd.staging.conf.js , comme ceci :
Remarquez que nous n'utilisons plus le service Selenium Standalone car nous installerons plus tard Selenium Chrome, Selenium Hub et le code d'application dans des services séparés dans un fichier Docker Compose. Cette configuration présente également les mêmes variables d'environnement que la configuration de mise en scène, telles que les informations d'identification de connexion et "baseUrl", car nous prévoyons d'exécuter nos tests sur l'application de mise en scène déployée, et la seule différence est que ces tests sont destinés à s'exécuter dans un conteneur Docker. .
Une fois ces fichiers de configuration d'environnement établis, nous avons décrit les commandes de script package.json qui serviraient de base à nos tests. Pour cet exemple, nous avons préfixé les commandes avec "uitest" pour désigner les tests d'interface utilisateur avec WebdriverIO et parce que nous avons également terminé les fichiers de test avec *.uitest.js . Voici quelques exemples de commandes pour l'environnement de préproduction :
Étape 3 : Implémenter les tests E2E localement
Avec toutes les commandes de test à portée de main, nous avons défini les tests dans notre référentiel STUI pour que nous les convertissions en tests WebdriverIO. Nous nous sommes concentrés sur les tests de page de petite à moyenne taille et avons commencé à appliquer le modèle d'objet de page pour encapsuler toute l'interface utilisateur de chaque page de manière organisée.
Nous pourrions avoir des fichiers structurés avec un tas de fonctions d'assistance ou de littéraux d'objet ou toute autre stratégie, mais la clé était d'avoir un moyen cohérent de fournir rapidement des tests maintenables et de s'y tenir. Si le flux de l'interface utilisateur ou les éléments DOM changeaient pour une page spécifique, nous n'avions qu'à refactoriser l'objet de la page qui lui était lié et éventuellement le code de test pour que les tests réussissent à nouveau.
Nous avons implémenté le modèle d'objet de page en ayant un objet de page de base avec des fonctionnalités partagées à partir duquel tous les autres objets de page s'étendraient. Nous avions des fonctions comme open pour fournir une API cohérente sur tous nos objets de page pour « ouvrir » ou visiter l'URL d'une page dans le navigateur. Cela ressemblait à quelque chose comme ça :
L'implémentation des objets de page spécifiques a suivi le même modèle d'extension à partir de la classe Page de base et d'ajout des sélecteurs à certains éléments avec lesquels nous souhaitions interagir ou affirmer et des fonctions d'assistance pour effectuer des actions sur la page.
Remarquez comment nous avons utilisé la classe de base open through super.open(...) avec la route spécifique de la page afin que nous puissions visiter la page avec cet appel, SomePage.open() . Nous avons également exporté la classe déjà initialisée afin que nous puissions référencer les éléments comme SomePage.submitButton ou SomePage.tableRows et interagir avec ou affirmer sur ces éléments avec les commandes WebdriverIO. Si l'objet page était destiné à être partagé et initialisé avec ses propres propriétés de membre dans un constructeur, nous pourrions également exporter la classe directement et instancier l'objet page dans les fichiers de test avec new SomePage(...constructorArgs) .
Après avoir disposé les objets de la page avec des sélecteurs et quelques fonctionnalités d'assistance, nous avons ensuite écrit les tests E2E et modélisé couramment cette formule de test :
- Configurez ou démontez via l'API ce qui est nécessaire pour réinitialiser les conditions de test au point de départ attendu avant d'exécuter les tests réels.
- Connectez-vous à un utilisateur dédié pour le test afin que chaque fois que nous visitions des pages directement, nous restions connectés et n'ayons pas à passer par l'interface utilisateur. Nous avons créé une fonction d'aide à la
loginsimple qui prend un nom d'utilisateur et un mot de passe qui effectue le même appel API que nous utilisons pour notre page de connexion et qui renvoie finalement notre jeton d'authentification nécessaire pour rester connecté et pour transmettre les en-têtes des demandes d'API protégées. D'autres entreprises peuvent avoir encore plus de points de terminaison ou d'outils internes personnalisés pour créer rapidement de nouveaux utilisateurs avec des données de départ et des configurations, mais nous n'en avions malheureusement pas assez étoffé. Nous le faisions à l'ancienne et créions des utilisateurs de test dédiés dans nos environnements avec différentes configurations via l'interface utilisateur et divisons souvent les tests pour les pages avec des utilisateurs distincts afin d'éviter les conflits de ressources et de rester isolés lorsque les tests s'exécutaient en parallèle. Nous devions nous assurer que les utilisateurs de test dédiés n'étaient pas touchés par d'autres, sinon les tests se briseraient si quelqu'un bricolait sans le savoir avec l'un d'eux. - Automatisez les étapes comme si un utilisateur final interagissait avec la fonctionnalité/la page. En règle générale, nous visitons la page qui contient notre flux de fonctionnalités et commençons à suivre les étapes de haut niveau qu'un utilisateur final voudrait, telles que remplir des entrées, cliquer sur des boutons, attendre que des modaux ou des bannières apparaissent et observer des tableaux pour les sorties modifiées comme un résultat de l'action. En utilisant nos objets et sélecteurs de page pratiques, nous avons rapidement implémenté chaque étape et, au fur et à mesure des vérifications de cohérence, nous affirmions ce que l'utilisateur devrait ou ne devrait pas voir sur la page pendant le flux de fonctionnalités pour être certain que les choses se comportent comme prévu. avant et après chaque étape. Nous avons également délibérément choisi des tests de chemin heureux de grande valeur et des états d'erreur communs parfois facilement reproductibles, en reportant le reste des tests de niveau inférieur aux tests unitaires et d'intégration.
Voici un exemple approximatif de la disposition générale de nos tests E2E (cette stratégie s'applique également à d'autres frameworks de test que nous avons également essayés) :

En passant, nous avons choisi de ne pas couvrir tous les conseils et astuces pour les meilleures pratiques WebdriverIO et E2E dans cette série d'articles de blog, mais nous parlerons de ces sujets dans un futur article de blog, alors restez à l'écoute !
Étape 4 : dockeriser tous les tests
Lors de l'exécution de chaque étape du pipeline Buildkite sur une nouvelle machine AWS dans le cloud, nous ne pouvions pas simplement appeler "npm run uitests:staging" car ces machines n'ont pas de nœud, de navigateurs, de notre code d'application ou de toute autre dépendance pour exécuter réellement les tests. .
Pour résoudre ce problème, nous avons regroupé toutes les dépendances telles que Node, Selenium, Chrome et le code d'application dans un conteneur Docker pour que les tests WebdriverIO s'exécutent avec succès. Nous avons profité de Docker et Docker Compose pour assembler tous les services nécessaires pour être opérationnels, ce qui s'est traduit par des Dockerfiles et docker-compose.yml et de nombreuses expérimentations avec la rotation locale de conteneurs Docker pour faire fonctionner les choses.
Pour fournir plus de contexte, nous n'étions pas des experts de Docker, il a donc fallu beaucoup de temps pour comprendre comment assembler les choses. Il existe plusieurs façons de Dockeriser les tests WebdriverIO et nous avons eu du mal à orchestrer de nombreux services différents ensemble et à parcourir différentes images Docker, versions Compose et didacticiels jusqu'à ce que tout fonctionne.
Nous présenterons principalement des fichiers étoffés qui correspondaient à l'une des configurations de nos équipes et nous espérons que cela vous fournira des informations, à vous ou à toute personne s'attaquant au problème général de la dockerisation des tests basés sur le sélénium.
À un niveau élevé, nos tests ont exigé ce qui suit :
- Selenium pour exécuter des commandes et communiquer avec un navigateur. Nous avons utilisé Selenium Hub pour faire tourner plusieurs instances à volonté et avons téléchargé l'image, "selenium/hub", pour le service
selenium-hubdans le fichier docker-compose. - Un navigateur contre lequel courir. Nous avons mis en place des instances Selenium Chrome et installé l'image "selenium/node-chrome-debug" pour le service
selenium-chromedans ledocker-compose.yml file. - Code d'application pour exécuter nos fichiers de test avec tous les autres modules Node installés. Nous avons créé un nouveau
Dockerfilepour fournir un environnement avec Node pour installer les packages npm et exécuter les scriptspackage.json, copier le code de test et attribuer un service dédié à l'exécution des fichiers de test nommésuitestsdans le fichierdocker-compose.yml.
Pour mettre en place un service avec tout notre code d'application et de test nécessaire pour exécuter les tests WebdriverIO, nous avons créé un Dockerfile appelé Dockerfile.uitests et installé tous les node_modules et copié le code dans le répertoire de travail de l'image dans un environnement Node. Cela serait utilisé par notre service Docker Compose uitests et nous avons réalisé la configuration Dockerfile de la manière suivante :
Afin d'associer le hub Selenium, le navigateur Chrome et le code de test d'application pour l'exécution des tests WebdriverIO, nous avons décrit les services selenium-hub , selenium-chrom e et uitest s dans le fichier docker-compose.uitests.yml :
Nous avons connecté les images Selenium Hub et Chrome via des variables d'environnement, depends_on et en exposant les ports aux services. Notre image de code d'application de test serait éventuellement poussée vers le haut et extraite d'un registre Docker privé que nous gérons.
Nous construirions l'image Docker pour le code de test pendant CICD avec certaines variables d'environnement comme VERSION et PIPELINE_SUFFIX pour référencer les images par une balise et un nom plus spécifique. Nous démarrerions ensuite les services Selenium et exécuterions des commandes via le service uitests pour exécuter les tests WebdriverIO.
Au fur et à mesure que nous construisions nos fichiers Docker Compose, nous avons tiré parti des commandes utiles telles que docker-compose up et docker-compose down avec le Mac Docker installé sur nos machines pour tester localement nos images avaient les configurations appropriées et fonctionnaient sans problème avant l'intégration avec Buildkite. Nous avons documenté toutes les commandes nécessaires pour construire les images étiquetées, les pousser vers le registre, les retirer et exécuter les tests en fonction des valeurs des variables d'environnement.
Étape 5 : Intégration avec CICD
Après avoir établi des commandes Docker fonctionnelles et que nos tests se sont déroulés avec succès dans un conteneur Docker dans différents environnements, nous avons commencé à intégrer Buildkite, notre fournisseur CICD.
Buildkite a fourni des moyens d'exécuter des étapes dans un fichier .yml sur nos machines AWS avec des scripts Bash et des variables d'environnement définis via le code ou l'interface utilisateur des paramètres Buildkite pour le pipeline de notre référentiel.
Buildkite nous a également permis de déclencher ce pipeline de test à partir de notre pipeline de déploiement principal avec des variables d'environnement exportées et nous réutiliserions ces étapes de test pour d'autres pipelines de test isolés qui s'exécuteraient selon un calendrier pour que nos QA puissent surveiller et examiner.
À un niveau élevé, nos pipelines de test Buildkite pour WebdriverIO et ceux ultérieurs de Cypress ont partagé les étapes similaires suivantes :
- Configurez les images Docker . Construisez, étiquetez et poussez les images Docker requises pour les tests jusqu'au registre afin que nous puissions les retirer ultérieurement.
- Exécutez les tests en fonction des configurations de variables d'environnement . Déroulez les images Docker balisées pour la version spécifique et exécutez les commandes appropriées sur un environnement déployé pour exécuter des suites de tests sélectionnées à partir des variables d'environnement définies.
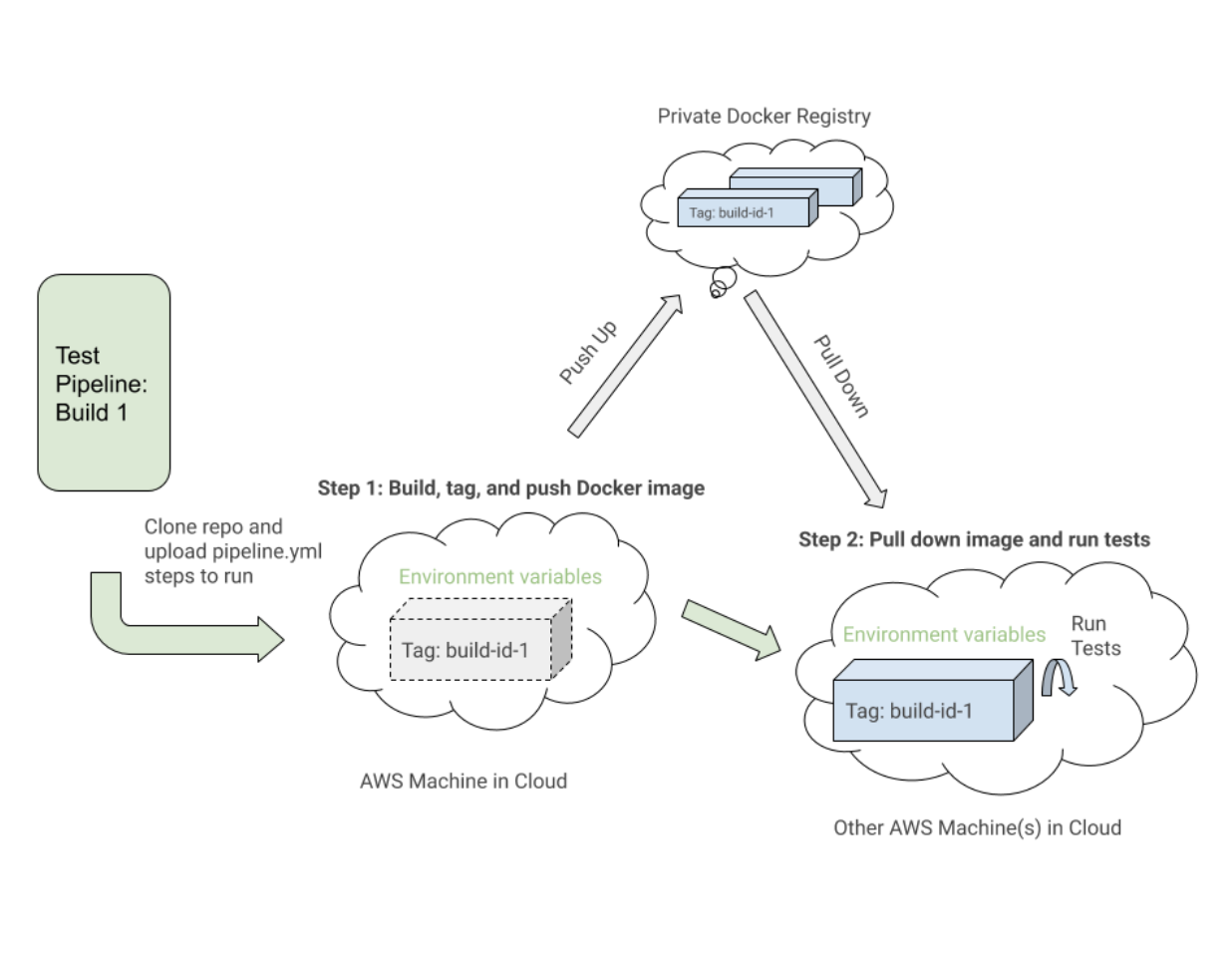
Voici un exemple proche d'un fichier pipeline.uitests.yml qui illustre la configuration des images Docker à l'étape « Build UITests Docker Image » et l'exécution des tests à l'étape « Run Webdriver tests against Chrome » :
Une chose à noter est la première étape, "Build UITests Docker Image", et comment elle configure les images Docker pour le test. Il a utilisé la commande Docker Compose build pour créer le service uitests avec tout le code de test de l'application et l'a étiqueté avec la variable d'environnement latest et ${VERSION} afin que nous puissions éventuellement extraire cette même image avec la balise appropriée pour cette version à l'avenir étape.
Chaque étape peut s'exécuter quelque part sur une machine différente dans le cloud AWS, de sorte que les balises identifient de manière unique l'image pour l'exécution spécifique de Buildkite. Après avoir étiqueté l'image, nous avons poussé la dernière image étiquetée avec la version vers notre registre Docker privé pour qu'elle soit réutilisée.
Dans l'étape "Exécuter les tests Webdriver sur Chrome", nous réduisons l'image que nous avons construite, étiquetée et poussée dans la première étape et démarrons les services Selenium Hub, Chrome et tests. Sur la base de variables d'environnement telles que $UITESTENV et $UITESTSUITE , nous choisirions le type de commande à exécuter comme npm run uitest: et les suites de tests à exécuter pour cette version spécifique de Buildkite telles que --suite $UITESTSUITE .
Ces variables d'environnement seraient définies via les paramètres du pipeline Buildkite ou seraient déclenchées dynamiquement à partir d'un script Bash qui analyserait un champ de sélection Buildkite pour déterminer quelles suites de tests exécuter et dans quel environnement.
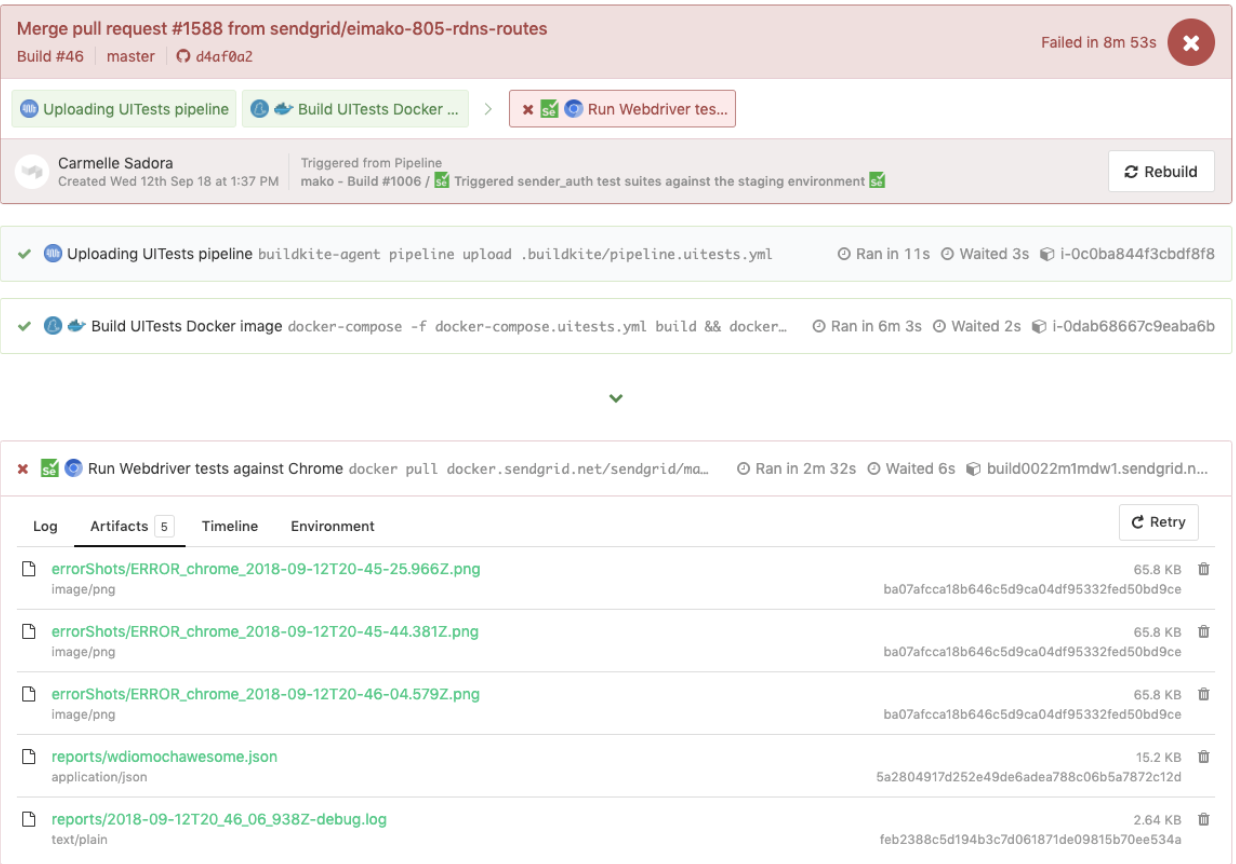
Voici un exemple de tests WebdriverIO déclenchés dans un pipeline de tests dédié, qui a également réutilisé le même fichier pipeline.uitests.yml mais avec des variables d'environnement définies là où le pipeline a été déclenché. Cette version a échoué et comportait des captures d'écran d'erreur que nous devions examiner sous l'onglet Artifacts et la sortie de la console sous l'onglet Logs . Rappelez-vous les chemins d' artifact_paths dans le pipeline.uitests.yml (https://gist.github.com/alfredlucero/71032a82f3a72cb2128361c08edbcff2#file-pipeline-uitests-yml-L38), paramètres de captures d'écran pour `mochawesome` dans `wdio.conf.js ` (https://gist.github.com/alfredlucero/4ee280be0e0674048974520b79dc993a#file-wdio-conf-js-L39), et montage des volumes dans le service `uitests` dans le `docker-compose.uitests.yml` (https://gist.github.com/alfredlucero/d2df4533a4a49d5b2f2c4a0eb5590ff8#file-docker-compose-yml-L32) ?
Nous avons pu connecter les captures d'écran pour qu'elles soient accessibles via l'interface utilisateur de Buildkite afin que nous puissions les télécharger directement et les voir immédiatement pour aider aux tests de débogage, comme indiqué ci-dessous.
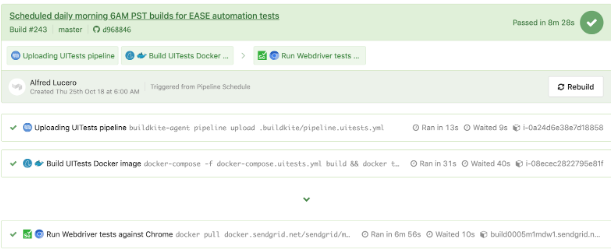
Un autre exemple de tests WebdriverIO exécutés dans un pipeline séparé selon un calendrier pour une page spécifique à l'aide du fichier pipeline.uitests.yml , sauf avec des variables d'environnement déjà configurées dans les paramètres du pipeline Buildkite, est affiché en dessous.
Il est important de noter que chaque fournisseur CICD a des fonctionnalités et des façons différentes d'intégrer des étapes dans une sorte de processus de déploiement lors de la fusion d'un nouveau code, que ce soit via des fichiers .yml avec une syntaxe spécifique, des paramètres d'interface graphique, des scripts Bash ou tout autre moyen.
Lorsque nous sommes passés de Jenkins à Buildkite, nous avons considérablement amélioré la capacité des équipes à définir leurs propres pipelines au sein de leurs bases de code respectives, en parallélisant les étapes entre les machines de mise à l'échelle à la demande et en utilisant des commandes plus faciles à lire.
Quel que soit le fournisseur CICD que vous pouvez utiliser, les stratégies d'intégration des tests seront similaires dans la configuration des images Docker et l'exécution des tests basés sur des variables d'environnement pour la portabilité et la flexibilité.
Compromis avec WebdriverIO
Après avoir converti un nombre considérable de tests personnalisés de la solution Ruby Selenium en tests WebdriverIO et intégré à Docker et Buildkite, nous nous sommes améliorés dans certains domaines, mais nous avons toujours ressenti des difficultés similaires à l'ancien système qui nous ont finalement conduits à notre prochain et dernier arrêt avec Cypress pour notre solution de test E2E.
Voici une liste de certains des avantages que nous avons trouvés grâce à nos expériences avec WebdriverIO par rapport à la solution Ruby Selenium personnalisée :
- Les tests ont été écrits uniquement en JavaScript ou TypeScript plutôt qu'en Ruby . Cela signifiait moins de changement de contexte entre les langues et moins de temps passé à réapprendre Ruby à chaque fois que nous écrivions des tests E2E.
- Nous avons colocalisé les tests avec le code de l'application plutôt que dans un référentiel partagé Ruby. Nous ne nous sommes plus sentis dépendants de l'échec des tests des autres équipes et nous nous sommes plus directement appropriés les tests E2E pour nos fonctionnalités dans nos dépôts.
- Nous avons apprécié l'option de test multi-navigateurs . Avec WebdriverIO, nous avons pu lancer des tests sur différentes fonctionnalités ou navigateurs tels que Chrome, Firefox et IE, bien que nous nous soyons principalement concentrés sur l'exécution de nos tests sur Chrome, car plus de 80 % de nos utilisateurs ont visité notre application via Chrome.
- Nous avons envisagé la possibilité d'intégrer des services tiers . La documentation WebdriverIO a expliqué comment s'intégrer à des services tiers tels que BrowserStack et SauceLabs pour aider à couvrir notre application sur tous les appareils et navigateurs.
- Nous avions la possibilité de choisir nos propres testeurs, reporters et services . WebdriverIO n'était pas normatif quant à ce qu'il fallait utiliser, donc chaque équipe a pris la liberté de décider d'utiliser ou non des choses comme Mocha et Chai ou Jest et d'autres services. Cela pourrait également être interprété comme un inconvénient car les équipes ont commencé à s'éloigner de la configuration de l'autre et il a fallu beaucoup de temps pour expérimenter chacune des options à choisir.
- L'API WebdriverIO, la CLI et la documentation étaient suffisamment utilisables pour écrire des tests et s'intégrer à Docker et CIC D. Nous pouvions avoir de nombreux fichiers de configuration différents, regrouper des spécifications, exécuter des tests via la ligne de commande et écrire des tests en suivant le modèle d'objet de page. Cependant, la documentation pourrait être plus claire et nous avons dû creuser dans de nombreux bogues étranges. Néanmoins, nous avons pu convertir nos tests à partir de la solution Ruby Selenium.
Nous avons fait des progrès dans de nombreux domaines qui nous manquaient dans la solution Ruby Selenium précédente, mais nous avons rencontré de nombreux obstacles qui nous ont empêchés de nous lancer avec WebdriverIO, tels que les suivants :
- Étant donné que WebdriverIO était toujours basé sur Selenium , nous avons rencontré de nombreux délais d'attente, plantages et bogues étranges, nous rappelant des retours en arrière négatifs avec notre ancienne solution Ruby Selenium. Parfois, nos tests plantaient complètement lorsque nous sélectionnions de nombreux éléments sur la page et les tests s'exécutaient plus lentement que nous le souhaiterions. Nous avons dû trouver des solutions de contournement à de nombreux problèmes de Github ou éviter certaines méthodologies lors de l'écriture des tests.
- L'expérience globale du développeur n'était pas optimale . La documentation fournissait un aperçu de haut niveau des commandes, mais pas suffisamment d'exemples pour expliquer toutes les façons de l'utiliser. Nous avons évité d'écrire des tests E2E avec Ruby et avons finalement pu écrire des tests en JavaScript ou TypeScript, mais l'API WebdriverIO était un peu déroutante à gérer. Certains exemples courants étaient l'utilisation de
$contre$$pour les éléments singuliers contre pluriels,$('...').waitForVisible(9000, true)pour attendre qu'un élément ne soit pas visible, et d'autres commandes non intuitives. Nous avons rencontré beaucoup de sélecteurs feuilletés et avons dû explicitement$(...).waitForVisible()pour tout. - Les tests de débogage étaient extrêmement pénibles et fastidieux pour les développeurs et les QA. Whenever tests failed, we only had screenshots, which would often be blank or not capturing the right moment for us to deduce what went wrong, and vague console error messages that did not point us in the right direction of how to solve the problem and even where the issue occurred. We often had to re-run the tests many times and stare closely at the Chrome browser running the tests to hopefully put things together as to where in the code our tests failed. We used things like
browser.debug()but it often did not work or did not provide enough information. We gradually gathered a bunch of console error messages and mapped them to possible solutions over time but it took lots of pain and headache to get there. - WebdriverIO tests were tough to set up with Docker . We struggled with trying to incorporate it into Docker as there were many tutorials and ways to do things in articles online, but it was hard to figure out a way that worked in general. Hooking up 2 to 3 services together with all these configurations led to long trial and error experiments and the documentation did not guide us enough in how to do that.
- Choosing the test runner, reporter, assertions, and services demanded lots of research time upfront . Since WebdriverIO was flexible enough to allow other options, many teams had to spend plenty of time to even have a solid WebdriverIO infrastructure after experimenting with a lot of different choices and each team can have a completely different setup that doesn't transfer over well for shared knowledge and reuse.
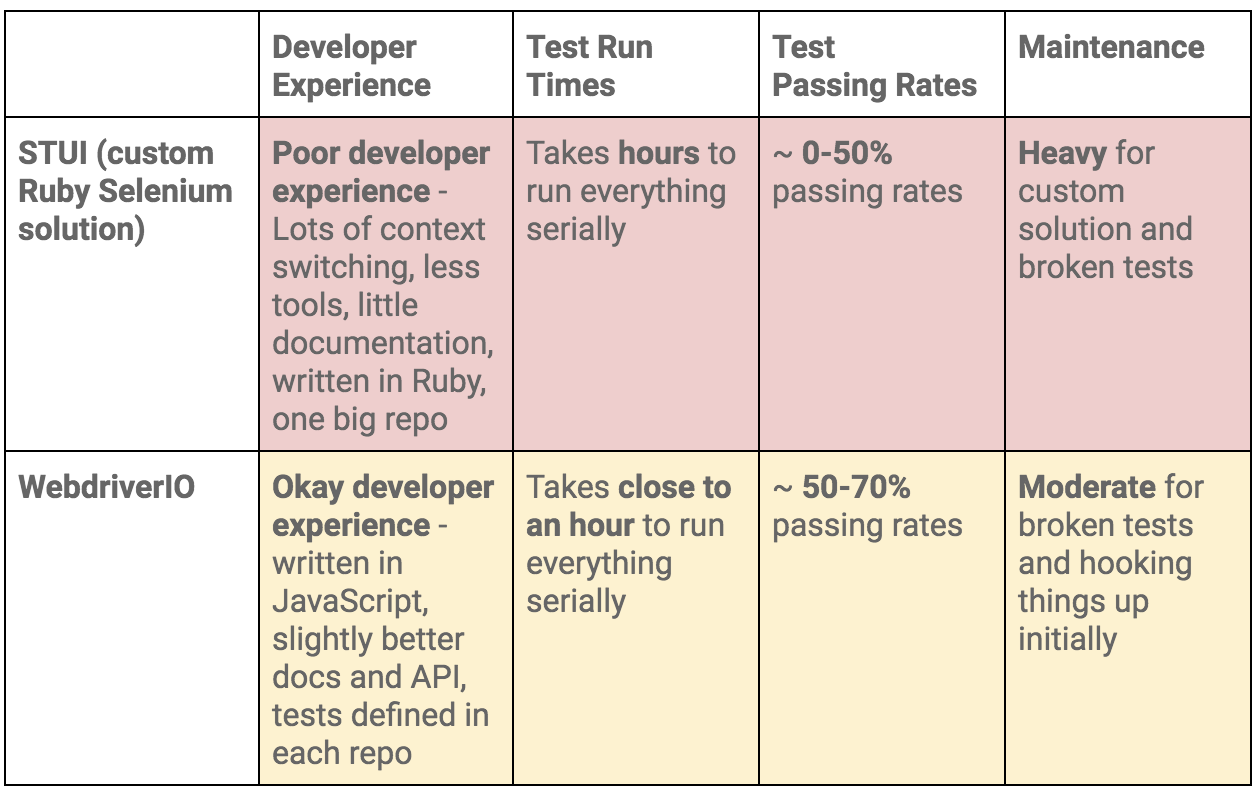
To summarize our WebdriverIO and STUI comparison, we analyzed the overall developer experience (related to tools, writing tests, debugging, API, documentation, etc.), test run times, test passing rates, and maintenance as displayed in this table:
Moving On to Cypress
At the end of the day, our WebdriverIO tests were still flaky and tough to maintain. More time was still spent debugging tests in dealing with weird Selenium issues, vague console errors, and somewhat useful screenshots than actually reaping the benefits of seeing tests fail for when the backend or frontend encountered issues.
We appreciated cross-browser testing and implementing tests in JavaScript, but if our tests could not pass consistently without much headache for even Chrome, then it became no longer worth it and we would then simply have a STUI 2.0.
With WebdriverIO we still strayed from the crucial aspect of providing a way to write consistent, debuggable, maintainable, and valuable E2E automation tests for our frontend applications in our original goal. Overall, we learned a lot about integrating with Buildkite and Docker, using page objects, and outlining tests in a structured way that will transfer over to our final solution with Cypress.
If we felt it was necessary to run our tests in multiple browsers and against various third-party services, we could always circle back to having some tests written with WebdriverIO, or if we needed something fully custom, we would revisit the STUI solution.
Ultimately, neither solution met our main goal for E2E tests, so follow us on our journey in how we migrated from STUI and WebdriverIO to Cypress in part 2 of the blog post series.