
Apache Spark : étoile scintillante au firmament du big data.
Publié: 2015-09-24- Recommander des millions de produits aux bons clients.
- Suivi de l'historique des recherches et offre de prix réduits pour les voyages en avion.
- Comparer les compétences techniques de la personne et suggérer de manière appropriée des personnes avec qui se connecter dans votre domaine.
- Comprendre les modèles de milliards d'objets mobiles, de tours de réseau et de transactions d'appel et calculer les optimisations du réseau de télécommunications ou trouver les failles du réseau.
- Étudier des millions de fonctionnalités de capteurs et analyser les défaillances des réseaux de capteurs.
Les données sous-jacentes nécessaires pour obtenir les bons résultats pour toutes les tâches ci-dessus sont relativement très importantes. Elle ne peut pas être gérée efficacement (en termes d'espace et de temps) par les systèmes traditionnels.
Ce sont tous des scénarios de Big Data.
Pour collecter, stocker et effectuer des calculs sur ce type de données volumineuses, nous avons besoin d'un système informatique en cluster spécialisé. Apache Hadoop a résolu ce problème pour nous.
Il offre un système de stockage distribué (HDFS) et une plate-forme informatique parallèle (MapReduce).
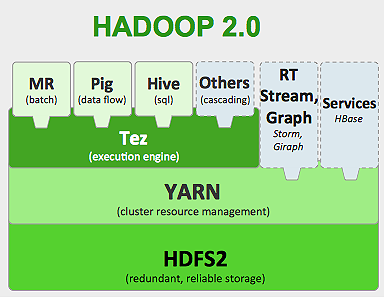
Le framework Hadoop fonctionne comme ci-dessous :
- Décompose les fichiers de données volumineux en morceaux plus petits à traiter par des machines individuelles (Distributing Storage).
- Divise un travail plus long en tâches plus petites à exécuter en parallèle (calcul parallèle).
- Gère automatiquement les pannes.
Limites de Hadoop
Hadoop dispose d'outils spécialisés dans son écosystème pour effectuer différentes tâches. Ainsi, si vous souhaitez exécuter le cycle de vie d'une application de bout en bout, vous devez utiliser plusieurs outils. Par exemple, pour les requêtes SQL , vous utiliserez hive/pig , pour les sources de streaming , vous devez utiliser le streaming intégré Hadoop ou Apache Storm (qui ne fait pas partie de l'écosystème Hadoop) ou pour les algorithmes d' apprentissage automatique , vous devez utiliser Mahout . L'intégration de tous ces systèmes pour créer un seul cas d'utilisation de pipeline de données est une tâche ardue.
Dans le travail MapReduce ,
- Toutes les sorties des tâches de mappage sont déversées sur des disques locaux (ou HDFS).
- Hadoop fusionne tous les fichiers de déversement dans un fichier plus volumineux qui est trié et partitionné en fonction du nombre de réducteurs.
- Et réduire les tâches doivent le charger à nouveau dans la mémoire.
Ce processus ralentit la tâche, ce qui entraîne des E/S disque et des E/S réseau. Cela rend également Mapreduce impropre au traitement itératif où vous devez appliquer des algorithmes d'apprentissage automatique au même groupe de données encore et encore.
Entrez dans le monde d'Apache Spark :
Apache Spark est développé à UC Berkeley AMPLAB en 2009 et en 2010, il est devenu le projet open source le plus contribué d'Apache jusqu'à ce jour.
Apache Spark est un système plus généralisé , où vous pouvez exécuter à la fois des tâches par lots et en continu . Il remplace son prédécesseur MapReduce en vitesse en ajoutant des capacités pour traiter les données plus rapidement en mémoire. Il est également plus efficace sur disque. Il exploite le traitement en mémoire à l'aide de son unité de données de base RDD (Resilient Distributed Dataset). Ceux-ci contiennent autant d'ensembles de données que possible en mémoire pour un cycle de vie complet du travail, économisant ainsi sur les E/S de disque. Certaines données peuvent se répandre sur le disque après les limites supérieures de la mémoire.
Le graphique ci-dessous montre le temps d'exécution en secondes d'Apache Hadoop et de Spark pour le calcul de la régression logistique. Hadoop a pris 110 secondes tandis que Spark a terminé le même travail en seulement 0,9 seconde.
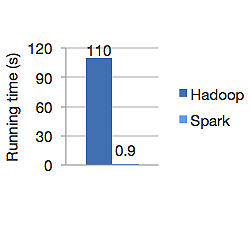
Spark ne stocke pas toutes les données en mémoire. Mais si les données sont en mémoire, elles utilisent au mieux le cache LRU pour les traiter plus rapidement. Il est 100 fois plus rapide lors du calcul des données en mémoire et toujours plus rapide sur disque que Hadoop.
Le modèle de stockage de données distribué de Spark, les ensembles de données distribués résilients (RDD), garantit la tolérance aux pannes qui, à son tour, minimise les E/S réseau. Spark paper dit :

"Les RDD atteignent la tolérance aux pannes grâce à une notion de lignée : si une partition d'un RDD est perdue, le RDD a suffisamment d'informations sur la façon dont il a été dérivé d'autres RDD pour pouvoir reconstruire uniquement cette partition."
Vous n'avez donc pas besoin de répliquer les données pour atteindre la tolérance aux pannes.
Dans Spark MapReduce, la sortie des mappeurs est conservée dans le cache tampon du système d'exploitation et les réducteurs la tirent de leur côté et l'écrivent directement dans leur mémoire, contrairement à Hadoop où la sortie est déversée sur le disque et lue à nouveau.
Le cache mémoire de Spark le rend adapté aux algorithmes d'apprentissage automatique où vous devez utiliser les mêmes données encore et encore. Spark peut exécuter des tâches complexes, des pipelines de données à plusieurs étapes à l'aide de Direct Acyclic Graph (DAG).
Spark est écrit en Scala et fonctionne sur JVM (Java Virtual Machine). Spark propose des API de développement pour les langages Java, Scala, Python et R. Spark fonctionne sur Hadoop YARN, Apache Mesos et possède son propre gestionnaire de cluster autonome.
En 2014, il a obtenu la 1ère place du record mondial de tri de données de référence de 100 To (1 billion d'enregistrements) en seulement 23 minutes, alors que le précédent record de Hadoop par Yahoo était d'environ 72 minutes. Cela prouve que les données triées par étincelle 3 fois plus rapidement et avec 10 fois moins de machines. Tout le tri s'est produit sur le disque (HDFS), sans réellement utiliser la capacité de cache en mémoire Spark.
Écosystème d'étincelles
Spark est destiné à effectuer des analyses avancées en une seule fois, pour y parvenir, il offre les composants suivants :
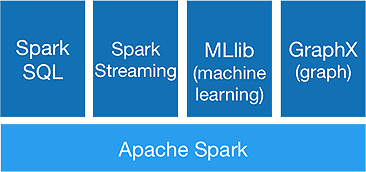
1. Noyau d'étincelle :
L'API principale Spark est la base du framework Apache Spark, qui gère la planification des tâches, la distribution des tâches, la gestion de la mémoire, les opérations d'E/S et la récupération après les échecs. L'unité de données logique principale dans Spark est appelée RDD (Resilient Distributed Dataset), qui stocke les données de manière distribuée pour être traitées en parallèle ultérieurement. Il calcule paresseusement les opérations. Par conséquent, la mémoire n'a pas besoin d'être occupée tout le temps et d'autres travaux peuvent l'utiliser.
2.Spark SQL :
Il offre des capacités d'interrogation interactives avec une faible latence. La nouvelle API DataFrame peut contenir des données structurées et semi-structurées et permettre à toutes les opérations et fonctions SQL d'effectuer des calculs.
3.Diffusion d'étincelles :
Il fournit des API de streaming en temps réel , qui collectent et traitent les données par micro-lots.
Il utilise Dstreams qui n'est rien d'autre qu'une séquence continue de RDD , pour calculer les logiques métier sur les données entrantes et générer des résultats immédiatement.
4.MLlib :
Il s'agit de la bibliothèque d'apprentissage automatique de Spark (presque 9 fois plus rapide que Mahout) qui fournit l'apprentissage automatique ainsi que des algorithmes statistiques comme la classification, la régression, le filtrage collaboratif, etc.
5.GraphX :
L'API GraphX fournit des fonctionnalités pour gérer les graphiques et effectuer des calculs parallèles aux graphiques. Il comprend des algorithmes de graphes comme PageRank et diverses fonctions pour analyser les graphes.
Spark marquera-t-il la fin de l'ère Hadoop ?
Spark est un système encore jeune, pas aussi mature que Hadoop. Il n'y a pas d'outil pour NOSQL comme HBase. Compte tenu des besoins élevés en mémoire pour un traitement plus rapide des données, vous ne pouvez pas vraiment dire qu'il fonctionne sur du matériel standard. Spark n'a pas son propre système de stockage. Il s'appuie sur HDFS pour cela.
Ainsi, Hadoop MapReduce est toujours bon pour certains travaux par lots, qui n'incluent pas beaucoup de pipeline de données.
« La nouvelle technologie ne remplace jamais complètement l'ancienne ; ils préféreraient tous les deux coexister.
Conclusion
Dans ce blog, nous avons examiné pourquoi vous avez besoin d'un outil comme Spark, ce qui en fait un système informatique en cluster plus rapide et ses composants de base. Dans la prochaine partie, nous approfondirons les RDD, les transformations et les actions de l'API principale de Spark.