
Au-delà des mots-clés : comment les entités impactent les stratégies de référencement modernes
Publié: 2023-07-06Le passage du « moteur de recherche 2.0 » au « moteur de recherche 3.0 » a apporté des changements importants, notamment avec l'introduction des entités.
Cet article explore ces changements, l'impact des entités sur le référencement moderne et comment adapter vos stratégies pour prospérer dans cette nouvelle ère.
Construire votre propre « machine théorique » SEO
Au cours de mes premières années d'apprentissage du codage, un enseignant a introduit un concept percutant appelé "machine notionnelle", qui a remodelé mon approche de la programmation et, plus tard, du référencement.
En termes simples, il s'agit du modèle mental approximatif d'un développeur de ce qui se passe à l'intérieur de l'ordinateur lorsqu'il clique sur Exécuter.
Mon professeur a souligné que plus cette représentation mentale était détaillée et précise, mieux je serais équipé pour aborder de nouveaux problèmes.
Les programmeurs les plus performants étaient ceux qui avaient développé les machines théoriques les plus précises et les plus fiables !
Faisant un parallèle avec le référencement, lorsque nous absorbons de nouveaux concepts, examinons une étude de cas ou observons l'impact d'un changement, nous mettons continuellement à jour notre modèle mental (notre propre machine théorique) du fonctionnement des moteurs de recherche.
La différence entre les SEO qualifiés et les SEO non qualifiés est qu'ils peuvent générer des résultats car ils peuvent tirer des solutions d'un modèle plus précis.
La recherche dans le domaine de l'expertise menée par Anderson Ericsson fournit des preuves substantielles pour affirmer ce point.
Ses études sur l'expertise révèlent que ceux qui excellent dans leur domaine possèdent des modèles mentaux supérieurs et plus facilement accessibles.
Ces modèles leur permettent de comprendre les relations de cause à effet complexes, de distinguer ce qui compte vraiment dans un scénario complexe et de percevoir les processus sous-jacents qui ne sont pas immédiatement apparents.
Avec l'introduction du référencement d'entité, plusieurs composants majeurs du moteur de recherche de Google ont été modifiés.
Il semble que de nombreux professionnels du référencement opèrent toujours selon les règles du "moteur de recherche 2.0", même si le "moteur de recherche 3.0" suit désormais un ensemble de règles légèrement différent.
Entity SEO introduit un vocabulaire et des concepts issus des disciplines de l'apprentissage automatique et de la recherche d'informations.
Ces termes peuvent sembler complexes car ils n'ont pas été simplifiés dans leur sens de base. Une fois que nous les avons distillés, vous constaterez que les concepts ne sont pas trop compliqués.
Mon objectif est de construire une machine théorique simple mais efficace sur la façon dont les derniers moteurs de recherche utilisent les entités.
Plus précisément, je veux illustrer comment votre compréhension du référencement doit être mise à jour pour refléter cette nouvelle réalité.
Bien que comprendre le « pourquoi » derrière ces changements puisse sembler sans importance, de nombreux professionnels du référencement « piratent » efficacement la matrice en utilisant leur compréhension de la façon dont Google interprète le Web à leur avantage.
Ces derniers temps, les gens ont créé des millions de sites de visiteurs et transformé la compréhension de Google du sujet en manipulant ces concepts.
Rappel : comment nous sommes arrivés au moteur de recherche 2.0
Avant d'explorer les différences entre "moteur de recherche 2.0" et "moteur de recherche 3.0", passons en revue les principaux changements par rapport à la version initiale 1.0.
Au début, les moteurs de recherche fonctionnaient sur un simple modèle de « sac de mots ».
Ce modèle traitait un document comme une simple collection de mots, négligeant la signification contextuelle ou l'agencement de ces mots.
Lorsqu'un utilisateur effectuait une requête, le moteur de recherche se référait à une base de données d'index inversé - une structure de données mappant les mots à leur emplacement dans un ensemble de documents - et récupérait les documents avec le plus grand nombre de correspondances.
Cependant, en raison de son manque de compréhension du contexte et de la sémantique des documents et des requêtes des utilisateurs, ce modèle n'a souvent pas fourni de résultats de recherche pertinents et précis.
Par exemple, si un utilisateur recherchait « jaguar » en utilisant un modèle « sac de mots », le moteur de recherche extrayait simplement les documents contenant le mot « jaguar » sans tenir compte du contexte.
Cela pourrait donner des résultats sur la marque automobile Jaguar, l'animal jaguar ou même l'équipe de football Jacksonville Jaguars, quelle que soit l'intention de l'utilisateur.
Avec l'avènement du "moteur de recherche 2.0", Google a adopté des stratégies plus sophistiquées. Au lieu de simplement faire correspondre des mots, cette itération visait à déchiffrer l'intention de l'utilisateur derrière sa requête.
Par exemple, si un utilisateur recherchait "jaguar", le moteur pourrait désormais prendre en compte l'historique de recherche et l'emplacement de l'utilisateur pour déduire le contexte probable.
Si l'utilisateur recherchait des modèles de voitures ou résidait dans une région où les voitures Jaguar étaient populaires, le moteur pourrait donner la priorité aux résultats concernant la marque de voiture plutôt qu'à l'animal ou à l'équipe de football.
L'introduction de résultats de recherche personnalisés, en tenant compte de facteurs tels que l'historique et l'emplacement de l'utilisateur, a considérablement amélioré la pertinence et la précision des résultats de recherche. Cela a marqué une évolution significative du modèle de base du "sac de mots" au "moteur de recherche 2.0".
Moteur de recherche 2.0 vs 3.0
En passant du « moteur de recherche 1.0 » au « moteur de recherche 2.0 », nous avons dû mettre à jour nos modèles mentaux et changer nos pratiques.
La qualité des backlinks est devenue cruciale, incitant les professionnels du référencement à abandonner les outils de backlinking automatisés et à rechercher des backlinks provenant de sites Web de meilleure qualité, parmi un certain nombre de changements clés.
À l'ère du « moteur de recherche 3.0 », il est clair que le changement mental pour s'adapter à ces changements est toujours en cours.
De nombreux concepts de l'ère 2.0 persistent, en grande partie parce que les praticiens ont besoin de temps pour observer la corrélation entre leurs ajustements et les résultats ultérieurs.
Un nombre important de professionnels du référencement doivent encore s'adapter pleinement à ces changements substantiels, ou ils ont peut-être tenté de le faire, mais n'ont pas tout à fait atteint le but.
Pour clarifier ces nouvelles distinctions et fournir des conseils sur la modification de votre approche, je vais présenter une comparaison simplifiée mais utile du « moteur de recherche 2.0 » et du « moteur de recherche 3.0 ».


Traitement des requêtes et recherche d'informations
Imaginez que vous tapez la requête de recherche "Elvis" dans Google.
À l'ère du moteur de recherche Google 2.0, la sophistication des algorithmes sous-jacents a permis de comprendre l'intention de l'utilisateur derrière une requête, au-delà de la simple correspondance des mots-clés.
Par exemple, si un utilisateur recherchait "Elvis", le système utiliserait le traitement du langage naturel et l'apprentissage automatique pour comprendre et anticiper l'intention derrière la requête.
Il recherchait « Elvis » dans son index et renvoyait des résultats qui mentionnaient le mot « Elvis » ou étaient basés (presque entièrement) sur la pertinence de la copie sur les pages Web et sur des paramètres de personnalisation tels que l'historique et l'emplacement de l'utilisateur.

Cependant, ce modèle avait encore ses limites, car il dépendait largement des mots-clés, de l'historique de recherche des utilisateurs, de l'emplacement et des phrases dans le texte des pages Web indexées.
Le contexte de "Elvis" pourrait signifier Elvis Presley, Elvis Costello, ou même un restaurant local nommé "Elvis".
Le défi était qu'il reposait largement sur l'utilisateur pour spécifier et affiner sa requête, et était toujours limité par la sémantique des mots-clés.
Améliorations du traitement des requêtes dans la version 3.0
Beaucoup de gens ne réalisent pas encore à quel point l'introduction des entités a révolutionné le fonctionnement de la recherche.
Depuis 2012, Hummingbird et RankBrain ont ouvert la voie aux entités pour qu'elles jouent un rôle plus central.
Dans ce modèle 3.0, les entités font référence à des concepts ou à des choses distinctes et uniques, qu'il s'agisse de personnes, de lieux ou d'objets.
En utilisant notre exemple précédent, "Elvis" n'est plus simplement un mot-clé, mais reconnu comme une entité, faisant probablement référence au célèbre musicien Elvis Presley.
Par exemple, lorsqu'une entité comme "Elvis Presley" est identifiée, le moteur de recherche peut désormais associer une multitude d'attributs à cette entité, y compris des aspects tels que sa musique, sa filmographie et ses dates de naissance et de décès.
Cette nouvelle approche élargit considérablement la portée de la recherche. Auparavant, une requête pour "Elvis" pouvait principalement prendre en compte environ 2 000 000 de pages contenant le mot clé exact "Elvis".
Maintenant, dans ce modèle centré sur l'entité, le moteur de recherche regarde au-delà pour considérer toutes les pages liées aux attributs d'Elvis.
Cela pourrait potentiellement élargir le champ de recherche pour inclure 10 000 000 de pages, même si certaines d'entre elles ne mentionnent pas explicitement "Elvis".
De plus, ce modèle permet au moteur de recherche de comprendre que d'autres mots clés liés aux attributs de l'entité Elvis, tels que "Graceland" ou "Blue Suede Shoes", sont implicitement connectés à "Elvis".
Par conséquent, la recherche de ces termes pourrait également faire apparaître des informations sur Elvis, élargissant ainsi le réseau de résultats de recherche potentiels.
Recevez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir conditions.
Traitement des requêtes et limites des sujets dans le moteur de recherche 3.0
Un autre changement important apporté par ces améliorations apportées aux entités dans le traitement des requêtes était la façon dont Google perçoit l'étendue des sujets qui devraient résider sur une seule page.
À l'ère du "moteur de recherche 2.0", il était avantageux de créer une page distincte pour chaque mot clé identifié, afin que la page puisse être optimisée spécifiquement pour ce terme.
Cependant, dans le "moteur de recherche 3.0", les frontières sont devenues plus fluides et sont mises à jour en temps réel en fonction des prédictions d'apprentissage automatique et du comportement observé des utilisateurs.
Dans cette nouvelle ère, les frontières d'un sujet peuvent être vastes ou étroites, couvrant un large éventail de sujets ou se concentrant intensément sur un aspect particulier. Cette flexibilité permet aux sites Web de devenir des autorités dans des domaines larges et de niche.
Exemple
Prenons l'exemple des crayons. Un site Web peut viser à couvrir tout ce qu'il y a à savoir sur les crayons en général - leur histoire, leurs types, leur processus de fabrication, leurs conseils d'utilisation, etc.
Ce site Web vise à devenir une autorité d'actualité sur les « crayons » dans leur ensemble.
D'un autre côté, un autre site Web pourrait se concentrer uniquement sur les crayons rouges - leurs pigments uniques, leurs statistiques de popularité, leur signification culturelle, etc.
Ce site tente d'établir son autorité d'actualité dans un contexte plus étroit, mais toujours valable. Il est toutefois crucial que l'accent mis sur les « crayons rouges » corresponde à l'objectif général du site Web.
L'ajout de micro-contextes qui ne correspondent pas à l'objectif plus large de votre site Web peut semer la confusion chez Google quant à la pertinence et à l'autorité de votre site, ce qui pourrait diluer son autorité thématique.
En théorie, un site Web pourrait même approfondir un micro-contexte et centrer son contenu uniquement sur les "étiquettes utilisées sur les crayons rouges".
Il s'agit d'un objectif incroyablement spécifique, et on peut se demander si Google le reconnaîtrait comme une autorité d'actualité.
Les sites Web de médias sociaux utilisent l'apprentissage automatique pour prédire les interactions des utilisateurs avec des éléments de contenu liés à un certain sujet.
Si un utilisateur interagit fréquemment avec du contenu sur les "étiquettes utilisées sur les crayons rouges", le système peut identifier cela comme un sujet d'intérêt pour l'utilisateur, et le site Web fournissant le contenu peut être reconnu comme une autorité sur ce sujet.
On peut émettre l'hypothèse que Google peut faire quelque chose de similaire ou au moins maintenir les attentes quant à la performance d'un contenu de qualité en fonction des statistiques d'utilisation qu'il suit.
Pour le déterminer, Google prend en compte plusieurs facteurs :
Y a-t-il une quantité importante d'activités de recherche autour de ce sujet ?
Si les gens recherchent activement des informations sur les «étiquettes utilisées sur les crayons rouges» et que le site fournit un contenu complet et précieux sur ce sujet, il pourrait très bien être reconnu comme une autorité d'actualité dans ce micro-contexte.
Existe-t-il de bonnes métriques utilisateur ?
Si les utilisateurs passent beaucoup de temps sur le site, ont de faibles taux de rebond et présentent d'autres signes d'engagement, Google peut interpréter cela comme un signe de l'autorité du site sur le sujet.
Rappelez-vous, l'autorité topique est un concept basé sur la relativité de différents sujets (entités). Votre site peut être considéré comme une autorité d'actualité sur des sujets aussi larges que la "technologie" ou aussi étroits que les "machines à écrire vintage".
Le facteur crucial est que votre site affiche un comportement utilisateur positif et emploie efficacement des entités pour établir des relations au sein du contenu. Ce faisant, Google commence à s'appuyer sur votre site pour améliorer sa propre compréhension du sujet, quel que soit le volume de recherche global du sujet.
Applications SEO et plats à emporter
Un contenu plus complet gagne
Dans les versions précédentes, de nombreuses pages Web étaient ignorées pour les requêtes car elles ne contenaient pas les mots exacts inclus dans la recherche.
Par exemple, une page bien liée qui n'incorporait pas un terme de recherche particulier n'apparaîtrait pas dans les résultats, quels que soient ses autres facteurs de classement robustes, tels que l'engagement des utilisateurs et les backlinks.
Cela a encouragé les SEO à écrire moins de contenus plus ciblés pour obtenir des classements pour un mot-clé cible.
Cependant, avec l'avènement de la version 3.0 et son accent mis sur la compréhension des entités et de leurs relations, le jeu a changé.
Il ne s'agit pas de savoir si le terme de recherche exact apparaît sur la page. Google va maintenant rechercher des entités relatives sur votre page et tenter de lier ces entités à des entités associées sur l'ensemble de votre site.
Il déterminera alors la relativité approximative et vous classera en conséquence. Ce changement fondamental amène les pages avec de forts facteurs de classement dans la concurrence, même s'il leur manque des termes spécifiques
La clé à retenir pour les créateurs de contenu et les stratèges SEO est de se pencher vers la création de contenu plus complet et expansif.
Centralisez vos efforts de backlink sur ces articles larges et approfondis au lieu de diviser les sujets en plusieurs articles ciblés.
Utilisez les SERP actuels comme point de départ pour identifier les sujets importants, mais ne vous limitez pas à eux.
Visez à aller au-delà de la couverture thématique existante dans les SERP et à fournir un contenu précieux et complet à l'utilisateur.
Cela répondra à la requête existante de l'utilisateur et aux requêtes connexes potentielles qu'il pourrait avoir, améliorant ainsi la pertinence et la visibilité de votre contenu dans cette nouvelle ère de recherche.
Intention de réponse au lieu de se concentrer sur l'utilisation des mots clés, soyez prudent avec les titres
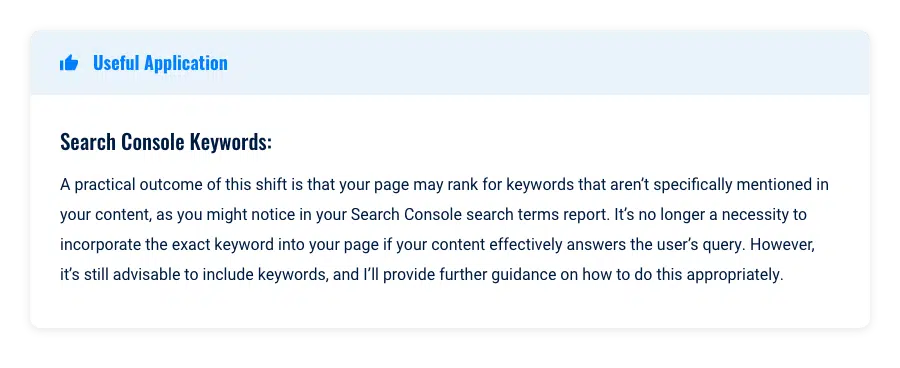
À l'ère du "moteur de recherche 3.0", la stratégie de référencement a évolué. Il ne suffit plus d'insérer simplement des mots-clés de votre rapport Search Console dans votre contenu et d'espérer un meilleur classement.
Les algorithmes avancés de Google peuvent désormais détecter lorsqu'un mot-clé est utilisé hors contexte, ce qui peut confondre l'algorithme et potentiellement conduire à des classements inférieurs.

L'ordre des en-têtes est important
Utilisez votre cerveau pour relier les idées clés les plus pertinentes à l'objectif de votre page. Assurez-vous que le contenu sous l'en-tête correspond au sujet de l'en-tête.
Vous souvenez-vous des journées de remue-méninges pour vos cours d'écriture à l'école primaire ?
Nous dessinions des cercles, écrivions des sujets dans les cercles, puis les reliions en traçant une ligne droite vers des cercles plus petits avec des sujets relatifs à notre histoire.
Ne compliquez pas les choses. Utilisez également cette stratégie pour former vos titres.

En bref, le "moteur de recherche 3.0" nécessite une approche plus réfléchie de l'utilisation des mots clés, en tenant compte de l'intention de l'utilisateur et en maintenant le contexte pour améliorer la pertinence et le potentiel de classement.
Notation et classement des documents
Une fois qu'un moteur de recherche comme Google a récupéré des documents potentiellement pertinents, la prochaine étape cruciale consiste à noter ces pages et à les classer pour qu'un utilisateur les sélectionne.
L'évolution de l'intelligence artificielle (IA) et du traitement du langage naturel (TAL) a considérablement transformé la façon dont les documents sont classés, marquant une nette distinction entre les époques 2.0 et 3.0.
Ère 2.0 (post-bag-of-words, pré-RankBrain)
À l'ère 2.0, le système de notation de Google était principalement piloté par des algorithmes tels que PageRank, Hummingbird, Panda et Penguin.
Ces algorithmes reposaient fortement sur la correspondance des mots clés et le nombre de backlinks pour classer les documents. Chaque document obtiendrait un score basé sur les pages et serait trié en fonction de l'ordre de classement.
Les évolutions d'algorithmes comme Panda et Penguin visaient moins à s'éloigner de la correspondance des mots clés et davantage à pénaliser les sites essayant de jouer avec le système.
Les systèmes basés sur des mots clés étaient encore plus efficaces et le matériel n'était pas assez avancé pour fournir des résultats de recherche rapides avec des méthodes de langage évoluées.
Notation et classement à l'ère du moteur de recherche 3.0
Dans le paysage du "moteur de recherche 3.0", l'approche de Google en matière de notation et de classement des documents a considérablement évolué.
Ceci est le résultat d'améliorations logicielles et matérielles. Google évalue la pertinence d'une page pour une requête de recherche en fonction de plusieurs facteurs clés.
La principale différence est une meilleure capacité à quantifier la pertinence, plutôt que de s'appuyer sur des signaux extérieurs comme les backlinks pour identifier les meilleurs éléments de contenu :
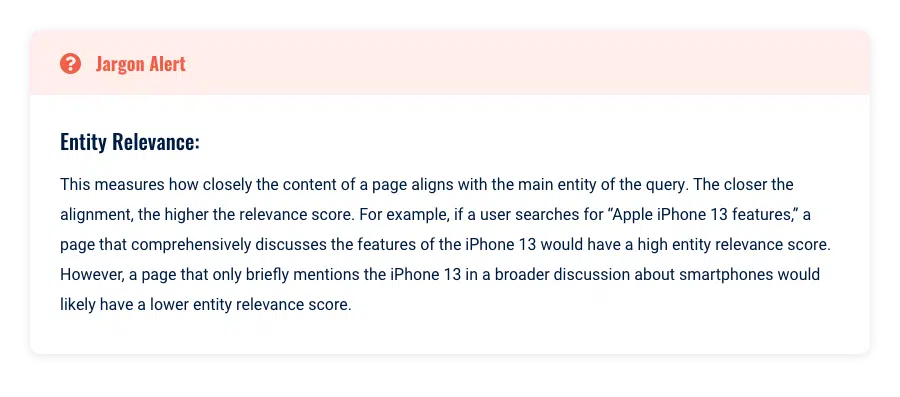

Exactitude factuelle
Le contenu factuellement précis provenant de sources fiables continue de se classer plus haut. Le Knowledge-Based Trust de Google le confirme en déclarant :
"Nous appelons le score de fiabilité que nous avons calculé la confiance basée sur les connaissances (KBT)... L'évaluation manuelle d'un sous-ensemble des résultats confirme l'efficacité de la méthode.
Signaux d'interaction de l'utilisateur
Les stratégies « publier du contenu de mauvaise qualité maintenant et le modifier plus tard » peuvent être problématiques pour ces raisons. Google prend désormais en compte les données d'engagement des utilisateurs historiques et actuelles associées à une page Web.
Ce changement est décrit dans le brevet de Google intitulé "Engagement and Experience Based Ranking" (US20140244560A1), qui met l'accent sur l'utilisation de la notation d'engagement historique dans le cadre de leurs considérations de classement.
Missions de qualité
Les engagements, tels que les longs clics où un utilisateur reste sur votre page pendant une durée significative, sont bénéfiques.
Cependant, les engagements non qualitatifs, comme les retours rapides aux résultats de recherche (connus sous le nom de "pogo-sticking"), peuvent avoir un impact négatif sur votre classement.
Ces mesures d'engagement peuvent influencer votre position de classement et vos impressions, renforçant ainsi votre autorité thématique.
Cependant, un faible engagement des utilisateurs peut entraîner une baisse du classement de votre page. La récupération après une telle baisse peut prendre du temps, ce qui souligne l'importance de fournir constamment un contenu pertinent et de haute qualité qui encourage l'engagement positif des utilisateurs.
Points à retenir et applications SEO
Vérification des faits
Google peut vérifier l'exactitude des faits. Investissez du temps dans la création de contenu factuellement précis.
Cela comprend une recherche appropriée, une vérification des faits et la citation de sources fiables. Mettre en œuvre un schéma de vérification des faits pour renforcer la crédibilité et la pertinence de vos articles informatifs
Engagement des utilisateurs
Faites attention aux mesures d'engagement des utilisateurs de votre page. Si votre contenu n'engage pas les utilisateurs comme prévu, envisagez de revoir votre stratégie de contenu.
Exploration et indexation
Alors que nous terminons notre exploration du processus de recherche, examinons comment les techniques d'exploration et d'indexation Web de Google ont évolué en mettant l'accent sur les entités.
Comprendre ces changements est crucial car ils ont un impact direct sur la façon dont vous devez structurer votre site Web et formuler votre stratégie de contenu, y compris la construction de votre carte thématique.
À l'ère du "moteur de recherche 2.0", les robots d'exploration de Google, également connus sous le nom d'araignées, naviguaient systématiquement sur Internet pour découvrir des pages nouvelles et mises à jour.
Ils suivraient les liens d'une page Web à une autre et collecteraient des données sur chaque page à stocker dans l'index de Google. Ce processus consistait principalement à découvrir de nouveaux contenus et à s'assurer que l'index restait à jour.
Une fois que les robots ont découvert une page, celle-ci a été ajoutée à l'index de Google - une base de données massive de toutes les pages Web trouvées par Google.
Le contenu de chaque page (y compris le texte, les images et les vidéos) a été analysé et la page a été classée en fonction de ce contenu.
L'accent a été mis sur les mots-clés et les phrases dans le texte et sur des facteurs tels que les backlinks, qui ont été utilisés pour déterminer la pertinence et l'autorité d'une page.
Avance rapide vers l'ère du "moteur de recherche 3.0", et les choses sont devenues plus complexes.
Les robots d'exploration de Google découvrent toujours des pages nouvelles et mises à jour en suivant des liens sur Internet. Mais maintenant, ils essaient également de comprendre les entités représentées par les mots-clés sur une page.
Par exemple, une page sur "Elvis" peut également être indexée sous des entités associées telles que "musique rock and roll", "Graceland" et "Chaussures en daim bleu".
De plus, ils suivent vos liens internes pour comprendre quelles entités votre site relie entre elles.
C'est un peu comme un bibliothécaire qui ne se contente pas de cataloguer des livres en fonction de leurs titres, mais aussi de les lire pour comprendre comment les chapitres sont liés les uns aux autres et au thème général du livre.
Cette compréhension plus approfondie aide Google à fournir des résultats de recherche plus pertinents et précis.
Mais comment l'exploration est-elle liée à l'autorité et aux entités thématiques ?
Eh bien, lorsque Google explore un site Web, il ne s'agit plus seulement de regarder les pages individuelles de manière isolée. Il examine également le thème ou le sujet général du site Web.
C'est là qu'intervient l'autorité topique.
Si un site Web publie régulièrement du contenu de haute qualité sur un sujet spécifique, il peut être considéré comme une autorité sur ce sujet.
Si Google considère le site comme une autorité, il peut le booster dans les résultats de recherche. (Souvent, vous verrez des sites avec de petits profils de backlink classés selon des termes concurrentiels, probablement en raison d'une augmentation du score d'autorité thématique qu'ils obtiennent.)
Chose intéressante, le concept d'autorité thématique existe depuis au moins quelques années maintenant, mais il n'a été reconnu que récemment par Google.
Le 23 mai 2023, Google a publié "Understanding News Topic Authority".
Bien que de nombreux référenceurs chevronnés pensaient que l'autorité thématique était un facteur de classement, personne ne pouvait le vérifier via le contenu publié par Google (en dehors de fouiller dans les brevets en attente).
Ne vous laissez pas induire en erreur par le mot « nouvelles » dans ce communiqué. L'autorité de sujet concerne tous les sites Web que Google explore, pas seulement les sites d'actualités.
Ce concept d'autorité topique est décrit dans le brevet US20180046717A1 de Google.
Le brevet décrit un processus de détermination de l'autorité d'un site Web en fonction de la cohérence et de la profondeur d'un sujet spécifique sur le site.
Par exemple, un site Web publiant régulièrement du contenu de haute qualité sur le "jardinage biologique" peut avoir un facteur de pureté élevé (oui, Google examine la capacité de votre site à rester sur le sujet), ce qui contribue à un score d'autorité plus élevé.
De plus, Google peut extraire les principaux thèmes de votre contenu et représenter graphiquement votre contenu, un peu comme ChatGPT représente graphiquement les mots dans les incorporations (un vecteur de caractéristiques).
Cela permet à Google de voir visuellement si votre contenu est similaire et cohérent, ce qui améliore encore sa compréhension de l'autorité thématique de votre site Web.

Donc, essentiellement, le changement dans le système d'indexation de Google ne consiste pas seulement à comprendre le contenu des pages individuelles, mais aussi à reconnaître l'actualité d'un site Web.
Cela souligne l'importance de maintenir une orientation cohérente dans votre stratégie de contenu, car cela peut avoir un impact significatif sur la visibilité de votre site Web dans les résultats de recherche.
Points à retenir et applications SEO
Mise au point cohérente sur le sujet
Google peut identifier quand votre site s'écarte de son sujet principal. Si votre contenu est incohérent, cela peut confondre le but et l'objectif de votre site Web.
Maintenez une concentration constante dans votre stratégie de contenu pour bénéficier des augmentations de score associées à l'autorité thématique.
Profondeur du contenu
Il est essentiel de créer de la profondeur dans votre contenu, mais il doit s'agir d'une profondeur pertinente. Utilisez votre compréhension de l'objectif principal de votre site pour guider la profondeur de votre contenu.
Par exemple, si l'objectif principal de votre site est de fournir des informations sur les techniques de photographie numérique, ne vous détournez pas pour écrire en profondeur sur l'histoire des appareils photo argentiques.
Bien qu'il soit lié à la photographie, il ne correspond pas étroitement à l'accent principal de votre site sur les techniques numériques. Au lieu de cela, approfondissez votre contenu en explorant diverses techniques de photographie numérique, en passant en revue les appareils photo numériques ou en fournissant des conseils pour l'édition de photos numériques.
Trop de contenu peut diluer votre autorité
Trop de contenu sur votre site Web peut diluer le sens et le but de votre site Web.
Parcourez votre sitemap et assurez-vous qu'il ne comprend que du contenu qui soutient vos idées clés et que le contenu est suffisamment de qualité pour aider Google à comprendre les entités.
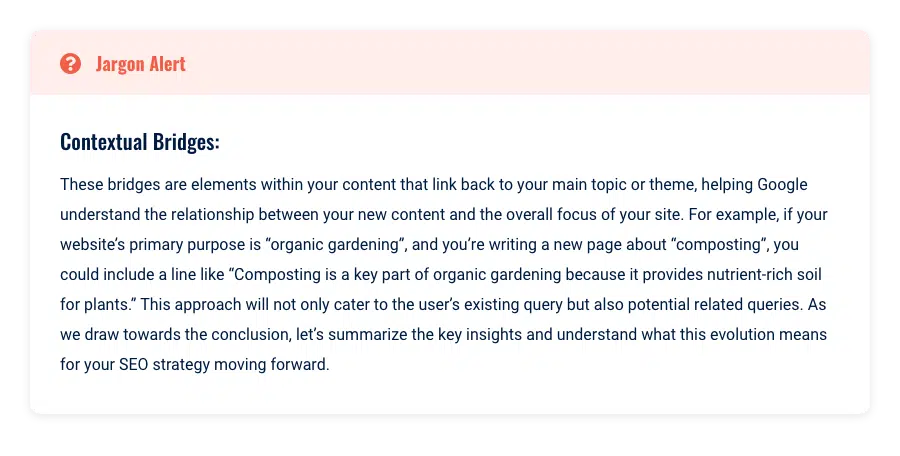
Utilisation de ponts contextuels
Lors de la création de nouveau contenu, il est important d'utiliser des "ponts contextuels" pour le relier à l'objectif principal de votre site.
Au lieu de simplement ajouter du nouveau contenu à votre site Web, demandez-vous toujours comment vous pouvez lier une nouvelle page à votre objectif principal.
Cela permettra à Google de commencer à associer les entités de votre nouvelle page à votre entité d'objectif principal.
Limites et contraintes de l'autorité topique
Bien que nous souhaitions nous concentrer sur la création d'une autorité thématique sur tous les sites que nous créons, il existe encore certaines limites.
Ces limitations sont des facteurs de classement persistants des jours du Web 2.0 auxquels Google accorde toujours un pouvoir de classement raisonnable : le temps passé sur le Web et les backlinks.
Tout d'abord, l'autorité du sujet prend du temps à se construire. Avec l'explosion récente des outils de création de contenu IA, ce délai peut être considérablement raccourci, mais cela prend encore du temps.
L'utilisation de l'autorité thématique est également relative à la manière exacte dont les autres sites de votre créneau sont « autorisés ».
Par exemple, si vous créez un excellent contenu basé sur une carte thématique incroyable, vous serez toujours comparé à d'autres sites de votre créneau.
Si ces autres sites ont également développé une grande actualité thématique au fil du temps, on s'en remet alors au problème séculaire des backlinks et du temps passé sur le web.
Il est extrêmement difficile de surclasser les sites qui ont développé un grand développement d'entité et qui l'ont fait sur un domaine qui est sur le Web depuis plusieurs années ou plus. Possible, certes, mais difficile quand même.
Parlons des backlinks.
Bien qu'il soit tout à fait possible de créer des sites qui se classent bien sans utiliser de backlinks, même les référenceurs chevronnés peuvent avoir du mal à le faire.
Les backlinks sont toujours un facteur de classement très important. Bien sûr, ils ne sont peut-être plus aussi puissants qu'avant, mais ils sont toujours puissants.
Le problème de donner une telle puissance de classement aux backlinks vient des grands sites de conglomérats d'actualités qui ne se "spécialisent" dans aucun sujet.
Nous l'avons tous vu : Google "meilleur widget pour xyz" et les 10 à 15 premiers résultats sont des sites de réseaux d'actualités qui prétendent tous avoir les meilleurs guides pour acheter ces widgets.
Les sites d'information se spécialisent-ils dans le développement ou la vente de ces widgets ?
Ces sites d'actualités ont-ils une autorité d'actualité en ce qui concerne ces widgets ?
Pas du tout.
Si les sites d'actualités n'ont pas d'autorité sur ces widgets, pourquoi dominent-ils toujours les SERP ? Cela dépend du temps passé sur le Web et des profils de backlink.
Étant donné que les éditeurs de ces grands réseaux d'information savent qu'ils seront extrêmement bien classés une fois qu'ils auront cliqué sur le bouton de publication, ils sollicitent la vente d'espace publicitaire sur leurs sites.
Les entreprises savent également que leur produit arrivera en tête des SERP de Google, elles paient donc volontiers des milliers et des milliers de dollars pour cette fonctionnalité.
Ils sont, en substance, lessivés de la capacité du site d'actualités à dominer les SERP chaque fois qu'ils publient quoi que ce soit - d'où le nom de référencement parasite.
Quelle que soit l'autorité de votre site sur le plan thématique, il aura du mal à rivaliser avec ces moteurs de sites d'actualités.
Malheureusement, jusqu'à ce que Google résolve ce problème, devenir une autorité thématique ne suffit pas pour rivaliser avec certains de ces SERP chauds que dominent les sites d'actualités.
Maîtriser le SEO à l'ère des entités
J'espère qu'en vous guidant tout au long du parcours du traitement des requêtes à l'indexation et au classement, je vous ai aidé à mettre à jour votre "machine théorique" pour mieux tenir compte des dernières modifications apportées au moteur de recherche Google.
Cette compréhension raffinée devrait vous aider à améliorer vos tactiques, où vous concentrez votre temps et les classements de votre propre site Web et de ceux de vos clients.
Enfin, il est crucial de se rappeler que la théorie brille vraiment lorsqu'elle est appliquée dans la pratique.
Par exemple, les praticiens du référencement affilié ont découvert il y a un certain temps que la production d'une quantité substantielle de contenu sur leur sujet pouvait déclencher une augmentation du référencement d'autorité.
Cela a été réalisé bien avant que l'évolution de notre compréhension du référencement d'entité n'entre en jeu.
Le parcours du référencement est en constante évolution, plein d'opportunités de découverte et d'amélioration.
Alors, armé de ces connaissances et de ces idées, il est temps pour vous de plonger, d'expérimenter et de façonner vos propres stratégies de référencement. Après tout, la preuve du pudding est dans le manger. Bon test !
Cet article a été co-écrit par Paul DeMott .
Ceci est le troisième article de la série SEO d'entité. Si vous souhaitez commencer par lire les deux premiers articles, ils sont liés ici :
- Le guide définitif du référencement d'entité
- Comment optimiser pour les entités
- 3 façons d'utiliser l'IA pour l'optimisation des entités sur l'ensemble du site
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.