
Petit-déjeuner avec un milliard d'e-mails
Publié: 2020-02-05Un Black Friday en douceur, c'est tout ce que nous demandons
Au moment où j'ai pris mon petit-déjeuner vers 8 heures du matin, heure normale du Pacifique (PST), chaque jour pendant le week-end du Black Friday, Twilio SendGrid avait déjà traité plus d'un milliard d'e-mails, calculés selon l'heure normale de l'Est des États-Unis (EST).
En regardant les statistiques, nous avons traité plus de 16,5 milliards d'e-mails de Thanksgiving au Cyber Monday, et plus de 22,3 milliards pour la semaine commençant le mardi avant Thanksgiving. Ce sont de très bons chiffres pour l'entreprise. Du point de vue d'une organisation d'ingénierie, le faire sans déclencher d'alertes ni dégrader l'expérience client était incroyablement satisfaisant.
Je vous recommande de lire cet article de blog, Scaling Our Infrastructure for 4+ Billion Emails in a Single Day , écrit par ma collègue Sara Saedinia, qui parle de l'importance de fonctionner sans heurts à cette échelle pour notre entreprise et pour les entreprises qui comptent sur nous. Ici, je vais me concentrer sur nos préparatifs qui ont fait du week-end le plus critique de l'année pour nos clients de messagerie le plus fluide jusqu'à présent.
Comment avons-nous fait pour que ce week-end du Black Friday se déroule sans encombre ? La gestion de nos jours d'envoi les plus importants nécessite une planification diligente, de nombreux tests de swing de région, des dizaines de personnes analysant les données et un resserrement des boucles de rétroaction alors que nous validons les améliorations de nos systèmes sur la base d'observations télémétriques. Nous avons encore plus d'automatisation et d'améliorations que nous apporterons pour nous assurer que nous continuons à ravir nos clients et que nous envoyons rapidement les bonnes communications aux bons destinataires.
Comprendre notre métier
Le modèle commercial de SendGrid exige que nous soyons toujours opérationnels - nous n'avons pas de fenêtres de maintenance pour accepter et livrer le courrier. Nos clients exigent un service fiable qui accepte et distribue le courrier sans interruption. Cela signifie que toutes nos modifications d'infrastructure, matérielles et logicielles, doivent être effectuées pendant que nous continuons à traiter et à envoyer les e-mails sans aucun retard notable.
Le nombre d'e-mails que nous traitons a considérablement augmenté au cours des dernières années, comme le montre le graphique suivant.
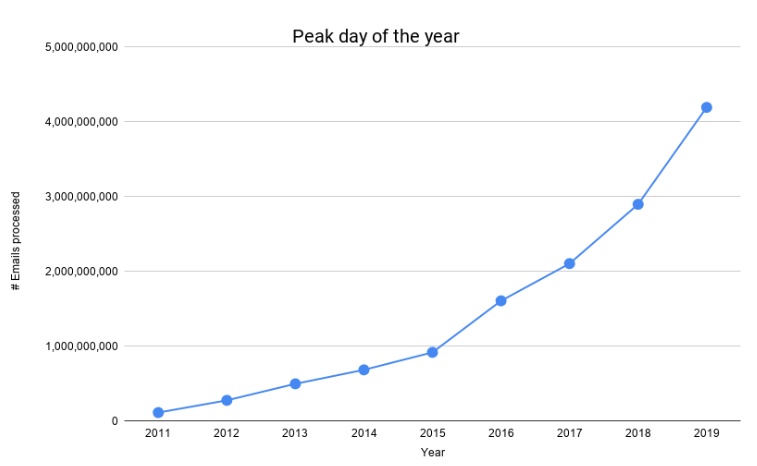
Nous avons eu notre première journée 1B à la mi-2016, et nous avons eu notre première journée 4B ce Black Friday. Soit 400% de croissance en moins de 4 ans. Pour tenir compte de notre échelle sans cesse croissante, pour maintenir nos coûts gérables et pour offrir une plus grande fiabilité à nos clients, nous avons dû repenser et faire évoluer notre pipeline de traitement du courrier.
Le Black Friday approche
Les gens me demandent : « Pourquoi le Black Friday et le Cyber Monday sont-ils si importants pour vous ? Ce Cyber Monday, nous avons traité 45 % d'e-mails en plus que le pic de l'année précédente. Le Black Friday est l'un des événements de vente au détail et de dépenses les plus importants aux États-Unis. Traditionnellement, c'est le jour où les détaillants seront dans le noir (net positif) pour l'année. Le marketing par e-mail et l'utilisation des e-mails transactionnels sont devenus essentiels pour toutes les entreprises.
Des détaillants aux entreprises qui fournissent l'automatisation du marketing, avoir des problèmes de livraison fiable des e-mails le week-end du Black Friday peut entraîner une perte de revenus importante. En conséquence, ce week-end est souvent un week-end déterminant pour nous. Nous faisons de notre mieux pour le rendre aussi simple que possible pour nos ingénieurs, agents de support, responsables de la réussite client, cadres et, plus important encore, pour nos clients.
Se préparer pour le Black Friday
Alors, comment se prépare-t-on pour le Black Friday ? Nous achetons des t-shirts ! (Et faire une tonne de travail.) Lisez la suite pour savoir comment nous nous préparons.
Membres du bureau Twilio SendGrid Irvine

Certains des membres du bureau de Twilio SendGrid à Denver.

Statistiques
Commençons par quelques statistiques :
- Traitement de plus de 4,1 milliards d'e-mails lors du Black Friday et de plus de 4,2 milliards d'e-mails lors du Cyber Monday
- Traitement de plus de 16,5 milliards d'e-mails de Thanksgiving au Cyber Monday
- Traitement de plus de 315 millions d'e-mails pendant l'heure de pointe
- Black Friday et Cyber Monday, chacun a eu 8 heures successives pour traiter 220 millions d'e-mails ou plus
- Tout cela avec un temps médian de bout en bout des e-mails livrables à 1,9 seconde
- En moyenne, nous émettons environ 5,5 événements par message. Sur cette base, nos systèmes ont émis et traité 91 milliards d'événements de Thanksgiving au Cyber Monday, 23 B + le seul Cyber Monday
Les défis
Échelle jamais vue auparavant : l'échelle que nous visons à tester doit correspondre à notre charge de pointe prévue. Lorsque nous avons effectué notre premier test pour la préparation de l'année dernière au début du mois d'avril, notre volume moyen en semaine était inférieur à la moitié de notre prévision de pointe. Nos pics horaires n'étaient même pas la moitié de ce que nous allions tester.
Gérer nos environnements : Le courrier électronique est un workflow avec état : il est nécessaire de garder une trace de l'état d'un message. Ainsi, au fur et à mesure que le message se déplace dans le pipeline, nous suivons s'il rebondit ou est différé, et empêchons la duplication. En tant que tel, notre pipeline de messagerie est une architecture hybride cloud et sur site, et la mise à l'échelle automatique n'est pas une solution magique. Notre défi consiste à maximiser l'efficacité de nos services de centre de données tout en préparant la capacité à gérer des pics de volume massifs sans impact sur les coûts pour les clients.
La mise à l'échelle n'est pas linéaire : Tous les systèmes ne sont pas mis à l'échelle de manière linéaire. Étant donné que notre échelle prévue est tellement plus élevée que lorsque nous avons commencé les tests, nous ne pouvons pas simplement calculer nos besoins en matériel par un simple modèle mathématique. Il est également important de se rappeler que la mise à l'échelle aveugle des services surchargerait les dépendances, et que les dépendances telles que la base de données ne s'adaptent pas de la même manière que notre agent de transfert de courrier (MTA).
Équilibrer nos investissements : alors que nous continuons à innover, en veillant à répondre aux besoins des clients liés à la livraison de leurs e-mails, nous comprenons que nos fonctionnalités n'apportent aucune valeur à nos clients si elles ne sont pas accessibles et performantes au besoin. Nous devons trouver un équilibre et investir de manière appropriée dans les tests, l'apprentissage, la mise à niveau et l'amélioration de nos systèmes pour qu'ils soient fiables et résilients à notre échelle. Le faire efficacement nous permet de continuer à investir dans l'innovation.

Comment avons-nous fait ça?
Nous l'avons fait ensemble, comme une seule équipe. Bras dessus bras dessous, comme on dit. Nos préparatifs cette année, d'avril à novembre, ont impliqué la participation de plus de 100 membres répartis dans de nombreuses équipes. La modélisation des prévisions de pointe, la définition des critères d'observabilité, l'apprentissage de nos observations, l'ingénierie des changements nécessaires, la planification et la gestion nécessitent diverses compétences de la part de plusieurs personnes.
Nous nous faisions confiance tout en restant honnêtes, en restant concentrés et en atteignant nos objectifs.
Un processus efficace et en constante amélioration était notre ami.
Planification
Nous avons trois centres de données pour traiter les e-mails des clients. Afin de planifier une échelle non atteinte, nous validons que nous pouvons gérer notre pic de trafic projeté avec seulement deux centres de données disponibles. Afin de respecter notre SLA de haute disponibilité, notre infrastructure dispose d'un basculement de région intégré. Cela signifie que nous avons la possibilité de basculer le trafic entre les régions.
Nous tirons parti de cette capacité avec une cadence fréquente tout au long de l'année en tant que procédure d'exploitation standard et l'accélérons dans le cadre de nos efforts pour démontrer que nous sommes en mesure de répondre aux volumes de pointe du Black Friday/Cyber Monday tout en maintenant la qualité du service. Si la télémétrie du système approche du seuil de notre objectif de niveau de service (SLO), nous sommes en mesure d'exploiter rapidement plusieurs régions pour reprendre l'état nominal. Nous exploitons ensuite la télémétrie collectée pour déterminer où nous devons apporter des modifications.
Dans un effort parallèle, nous avons commencé à revoir et à consolider nos objectifs de niveau de service (SLO) qui nous fournissent une cible numérique précise pour la disponibilité du système et nos indicateurs de niveau de service (SLI), qui nous fournissent la fréquence des vérifications réussies de nos systèmes.
Observations, apprentissages et communication
Chaque test a fourni une grande quantité d'informations. L'un des défis auxquels nous avons été confrontés était de documenter et de communiquer efficacement les observations entre les équipes de test en rotation, puis d'analyser les données sur plusieurs systèmes. Bien que nous ayons des tableaux de bord d'équipe standard, chaque membre peut observer quelque chose de spécifique.
Nous avons commencé à faire un rétro avec les équipes de test pour analyser toutes les informations techniques déversées pour plusieurs services gérés par plusieurs équipes. Ces rétros étaient longues, et pendant la majeure partie de la durée, n'étaient utiles qu'à une ou deux équipes par test. Nous sommes finalement passés à l'utilisation d'un fil Slack pour les notes rétro, ce qui nous a permis d'économiser 10 heures humaines de temps de réunion par test.
Notre équipe de gestion des tests comprenait deux responsables techniques, un architecte et un ingénieur senior. Les gestionnaires ont joué un rôle central dans la planification et la gestion des dépendances, tandis que les personnes plus techniques ont aidé à traiter et à analyser les informations au niveau du système de bout en bout.
Sur la base de l'analyse des informations disponibles, nous avons validé de manière itérative que nos SLI étaient strictement conformes à nos SLO. Nous avons affiné nos alertes et rendu certaines alertes critiques plus sensibles afin d'identifier bien en amont toute dégradation potentielle du système.
Priorisation et mise en œuvre
Nous avons émis des tickets pour les changements proposés et les équipes ont priorisé ces tickets. Le premier défi ici était de gérer ces tickets sur plusieurs tableaux d'équipe. Un autre défi consistait à hiérarchiser impitoyablement le travail du Black Friday par rapport à d'autres priorités.
Nous devions donner à nos ingénieurs la liberté créative de trouver des solutions à des problèmes difficiles. En même temps, nous devions nous assurer que ces solutions s'alignaient sur nos plans à long terme. Il était également très important que nous soyons toujours conscients de tout conflit d'intérêts, ce qui signifiait éviter toute solution à court terme qui pourrait revenir sur nous.
Valider les changements qui ont été mis en place deviendrait notre objectif pour les tests à venir.
Maintenir et accélérer le rythme à mesure que nous nous rapprochions du Black Friday était un défi majeur dans la planification et l'exécution.
L'accélération
Au début du mois de septembre, nous avons commencé à exécuter plusieurs tests de résistance chaque semaine. Cela nous a obligés à identifier, corriger et valider les problèmes plus rapidement. Cela nous a également fourni un cycle d'apprentissage et d'adaptation beaucoup plus rapide.
En plus du test complet du pipeline de courrier décrit précédemment, nous avons également commencé à tester nos services de support pendant la même période. Au cours de la même période, nous avons commencé à effectuer des tests de charge avec l'un de nos plus gros clients pour nous assurer que nos géopods entrants géreraient leurs envois en rafale prévus pendant la période des fêtes sans aucun souci.
En raison des longues heures et du défi de gérer le travail, nos équipes s'épuisaient. Nous avons répertorié les alertes les plus critiques nécessaires pour arrêter notre test si nécessaire, et les avons rendues plus sensibles. Cela nous a permis de commencer à faire nos tests sans nous obliger à être présents pour surveiller nos systèmes tôt le matin.
Vitesse avec prudence
À l'approche de la fin du mois de septembre, on craignait que nous n'avancions pas assez vite dans la bonne direction. Nous avons créé une équipe de tigres, une équipe de spécialistes qui pouvait travailler sur n'importe lequel des tickets dans plusieurs équipes, et une qui travaillait avec un processus beaucoup plus léger au niveau quotidien.
Nous avons apporté des améliorations significatives à notre infrastructure opérationnelle ainsi qu'à notre logiciel de traitement du courrier en préparation du Black Friday. Ces changements étaient expressément priorisés et les équipes devaient travailler dans une grande coordination les unes avec les autres. Ce fut une expérience formidable pour les personnes mettant SendGrid en premier. Nous apportions des modifications aux applications, à l'infrastructure et augmentions notre capacité matérielle tout en exécutant le moteur principal d'une unité commerciale d'une entreprise publique à un rythme de démarrage. Mieux encore, nous avons tout fait sans aucune dégradation de l'expérience de service pour nos clients.
Plans futurs
Nous avons passé beaucoup d'heures humaines à préparer le Black Friday 2019. Nos enseignements de cette année nous aideront à automatiser une grande partie de notre préparation pour le Black Friday et le Cyber Monday en 2020. Nous attendons avec impatience une autre année couronnée de succès, sans stress, record -casser les volumes d'envois de vacances pour nos clients et nos employés.