
Créer une application à l'aide de Serverless Framework, d'AWS et de BigQuery
Publié: 2021-01-28Sans serveur fait référence aux applications où la gestion et l'allocation des serveurs et des ressources sont gérées par un fournisseur de cloud. Cela signifie que le fournisseur de cloud alloue dynamiquement les ressources. L'application s'exécute dans un conteneur sans état qui peut être déclenché par un événement. Un exemple de ce qui précède et celui que nous utiliserons dans cet article concerne AWS Lambda .
En bref, nous pouvons définir les « applications sans serveur » comme des applications qui sont des systèmes basés sur le cloud pilotés par les événements. L'application s'appuie sur des services tiers, une logique côté client et des appels à distance (en l'appelant directement Function as a Service ).
Installation de Serverless Framework et configuration pour Amazon AWS

1. Cadre sans serveur
Le Serverless Framework est un framework open-source. Il se compose d'une interface de ligne de commande ou CLI et d'un tableau de bord hébergé, qui nous fournit un système de gestion des applications entièrement sans serveur. L'utilisation du Framework garantit moins de frais généraux et de coûts, un développement et un déploiement rapides et la sécurisation des applications sans serveur.
Avant de procéder à l'installation du framework sans serveur, vous devez d'abord configurer NodeJS. C'est très facile à faire sur la plupart des systèmes d'exploitation - il vous suffit de visiter le site officiel de NodeJS pour le télécharger et l'installer. Pensez à choisir une version supérieure à 6.0.0.
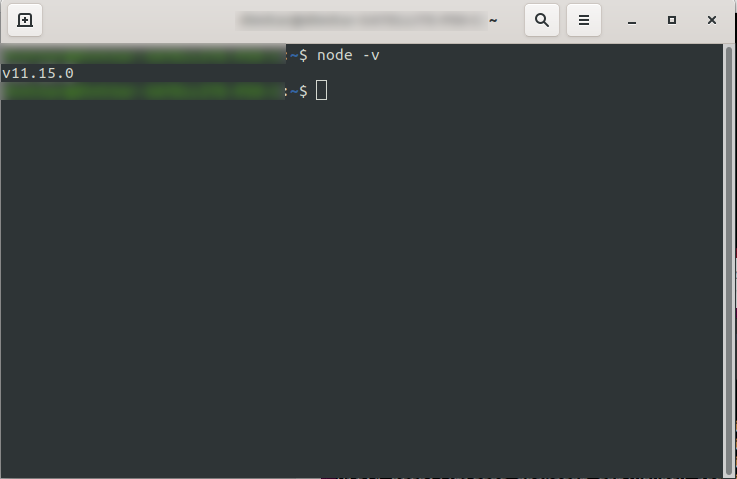
Après l'avoir installé, vous pouvez confirmer que NodeJS est disponible en exécutant node -v dans la console. Il doit renvoyer la version du nœud que vous avez installée :
Vous êtes maintenant prêt à partir, alors allez-y et installez le framework Serverless.
Pour ce faire, suivez la documentation pour installer et configurer le framework. Si vous préférez, vous pouvez l'installer pour un seul projet, mais chez DevriX, nous installons généralement le framework globalement : npm install -g serverless
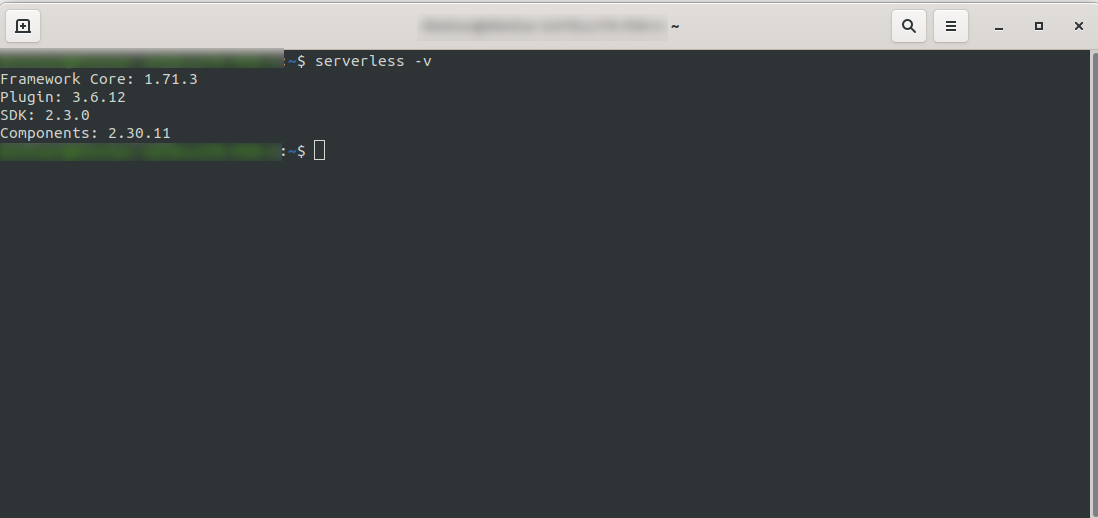
Attendez que le processus se termine et assurez-vous que Serverless a été installé avec succès en exécutant : serverless -v
2. Créez un compte Amazon AWS
Avant de procéder à la création de votre exemple d'application, vous devez créer un compte dans Amazon AWS . Si vous n'en avez pas encore, c'est aussi simple que d'aller sur Amazon AWS et de cliquer sur "Créer un compte AWS" dans le coin supérieur droit et de suivre les étapes pour créer un compte.
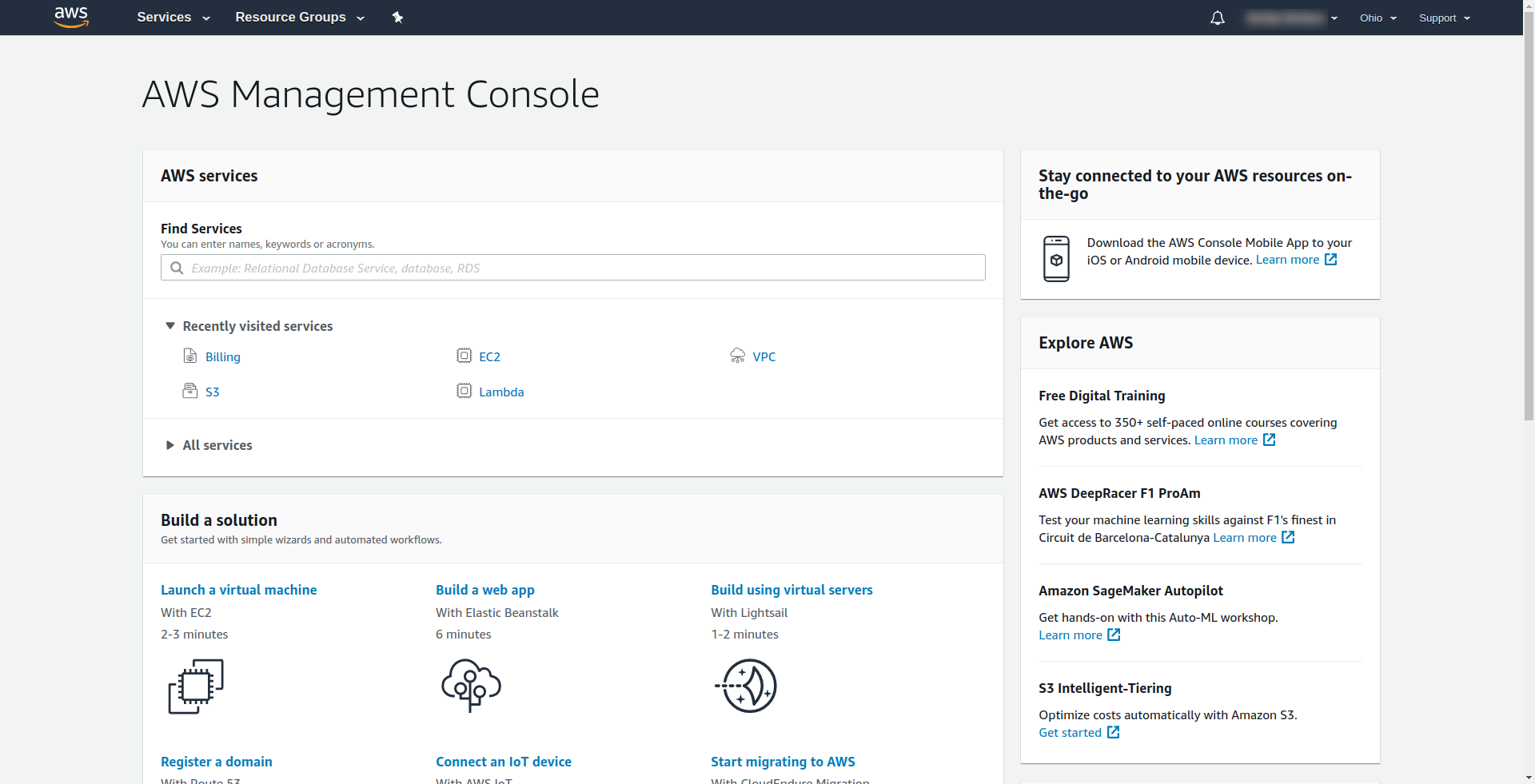
Amazon vous demande de saisir une carte de crédit, vous ne pouvez donc pas continuer sans saisir ces informations. Une fois l'enregistrement et la connexion réussis, vous devriez voir AWS Management Console :
Génial! Passons maintenant à la création de votre application.
3. Configurer le Serverless Framework avec le fournisseur AWS et créer un exemple d'application
Dans cette étape, nous devons configurer le framework Serverless avec le fournisseur AWS. Certains services tels qu'AWS Lambda nécessitent des informations d'identification lorsque vous y accédez pour vous assurer que vous disposez des autorisations sur les ressources détenues par ce service. AWS recommande d'utiliser AWS Identity and Access Manager (IAM) pour y parvenir.
Ainsi, la première et la plus importante chose est de créer un utilisateur IAM dans AWS pour l'utiliser dans notre application :
Sur la console AWS :
- Tapez IAM dans le champ "Rechercher des services" .
- Cliquez sur « IAM » .
- Allez dans « Utilisateurs » .
- Cliquez sur "Ajouter un utilisateur" .
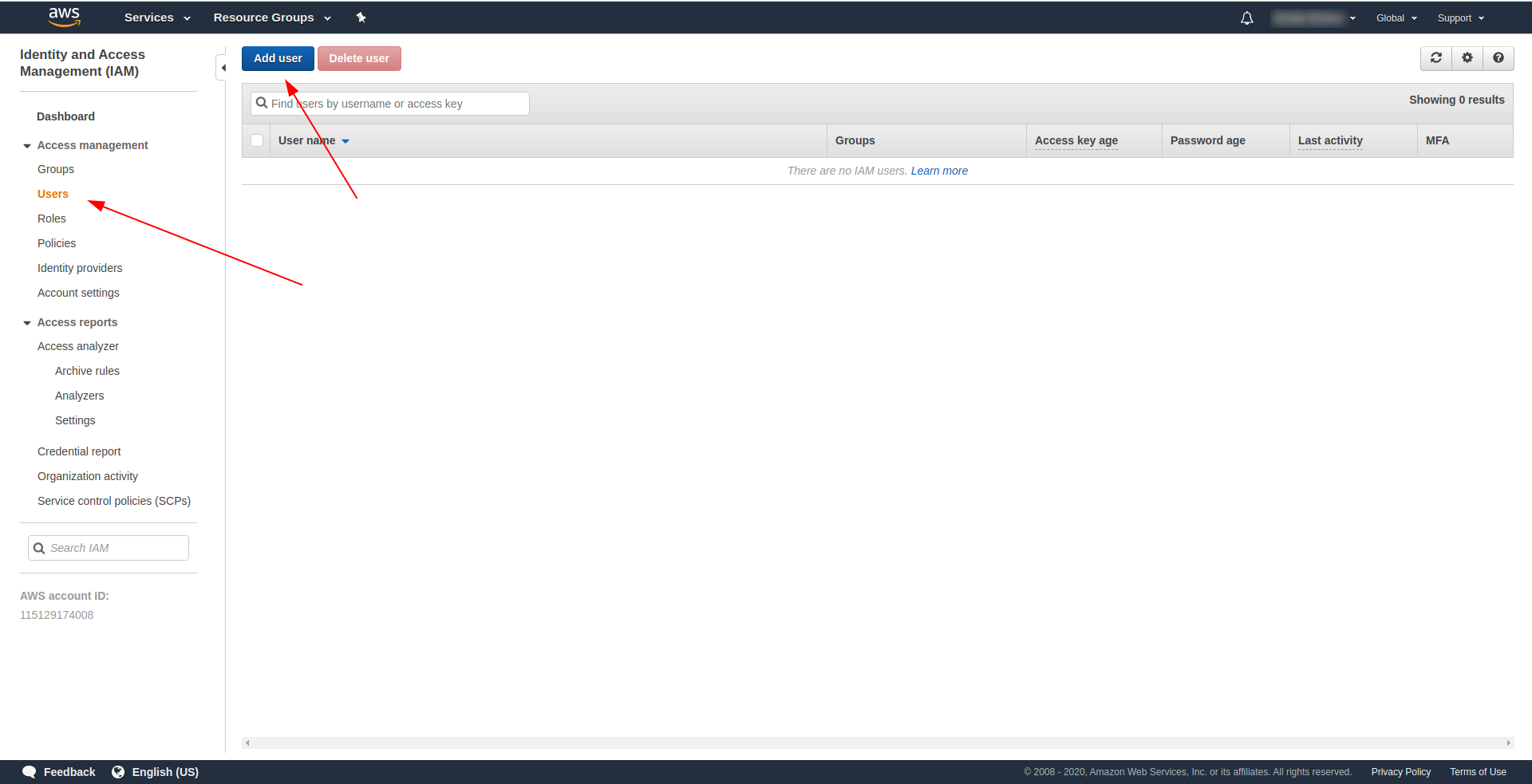
Pour "Nom d'utilisateur" , utilisez ce que vous voulez. Par exemple, nous utilisons serverless-admin. Pour « Type d'accès » , cochez « Accès par programme » et cliquez sur « Autorisations suivantes ».
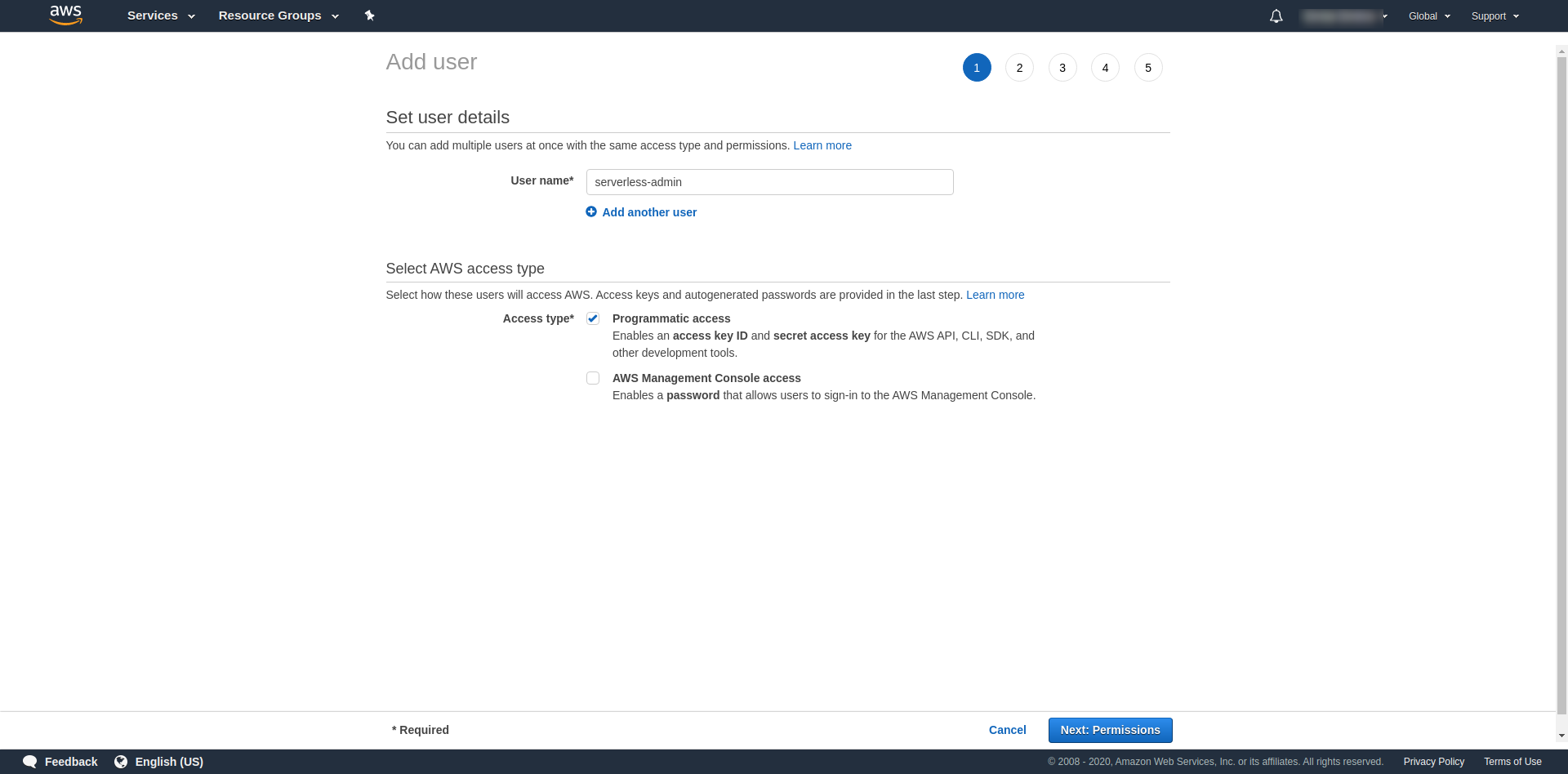
Après cela, nous devons attacher des autorisations pour l'utilisateur, cliquer sur "Attacher directement les politiques existantes", rechercher "Accès administrateur" et cliquer dessus. Continuez en cliquant sur "Prochaines balises"
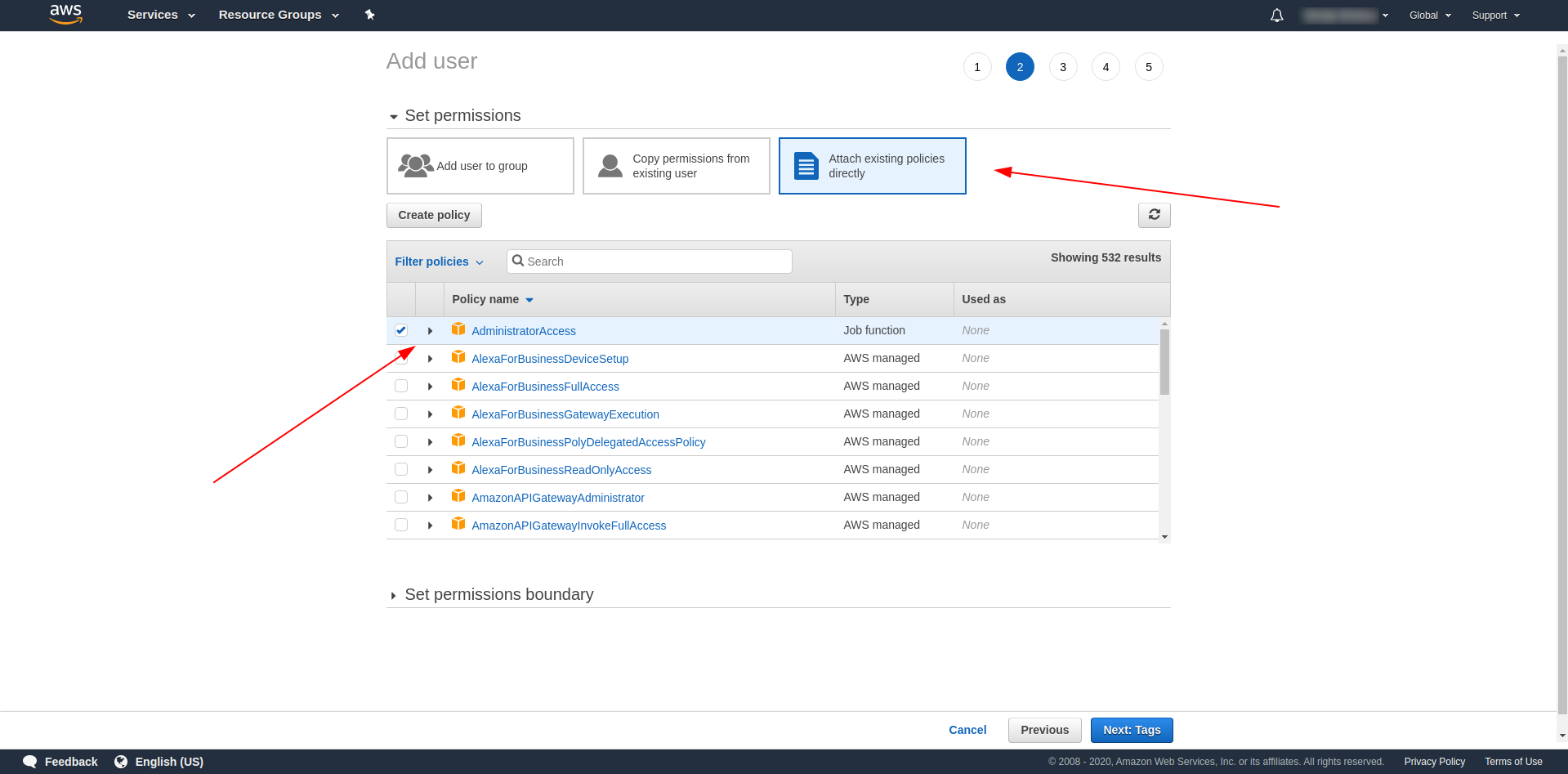
Les balises sont facultatives, vous pouvez donc continuer en cliquant sur "Prochain examen" et "Créer un utilisateur". Une fois terminé et chargé, un message de réussite apparaît sur la page avec les informations d'identification dont nous avons besoin.
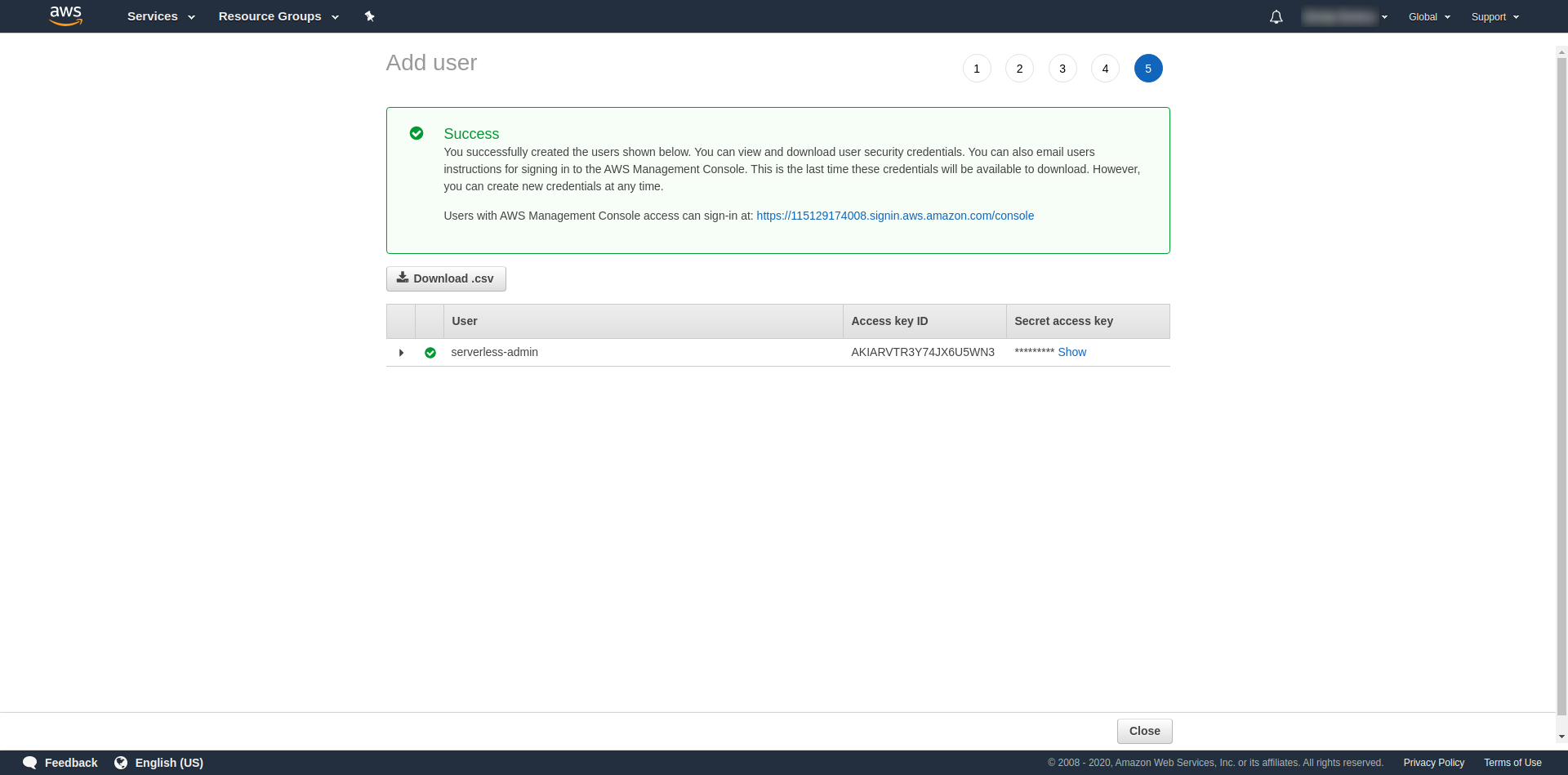
Maintenant, nous devons exécuter la commande suivante :
serverless config credentials --provider aws --key key --secret secret --profile serverless-admin
Remplacez la clé et le secret par ceux fournis ci-dessus. Vos informations d'identification AWS sont créées en tant que profil. Vous pouvez vérifier cela en ouvrant le fichier ~/.aws/credentials . Il doit être composé de profils AWS. Actuellement, dans l'exemple ci-dessous, il n'y en a qu'un - celui que nous avons créé :
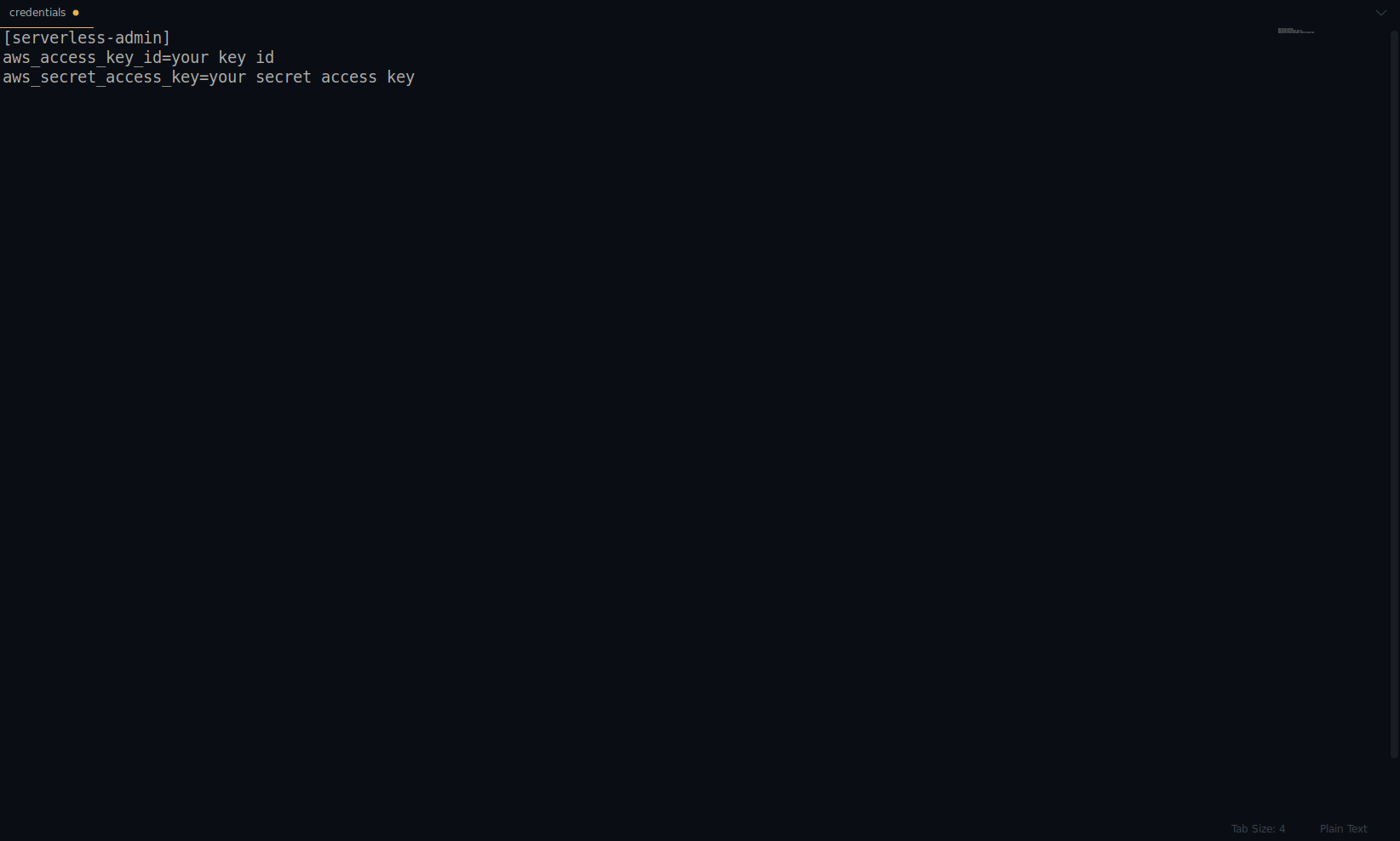
Excellent travail jusqu'à présent ! Vous pouvez continuer en créant un exemple d'application à l'aide de NodeJS et des modèles de démarrage intégrés.
Remarque : De plus, dans l'article, nous utilisons la commande sls , qui est l'abréviation de serverless .
Créez un répertoire vide et entrez-le. Exécutez la commande
ls create --template aws-nodejs
À l'aide de la commande create –template , spécifiez l'un des modèles disponibles, dans ce cas, aws-nodejs, qui est une application de modèle NodeJS « Hello world ».
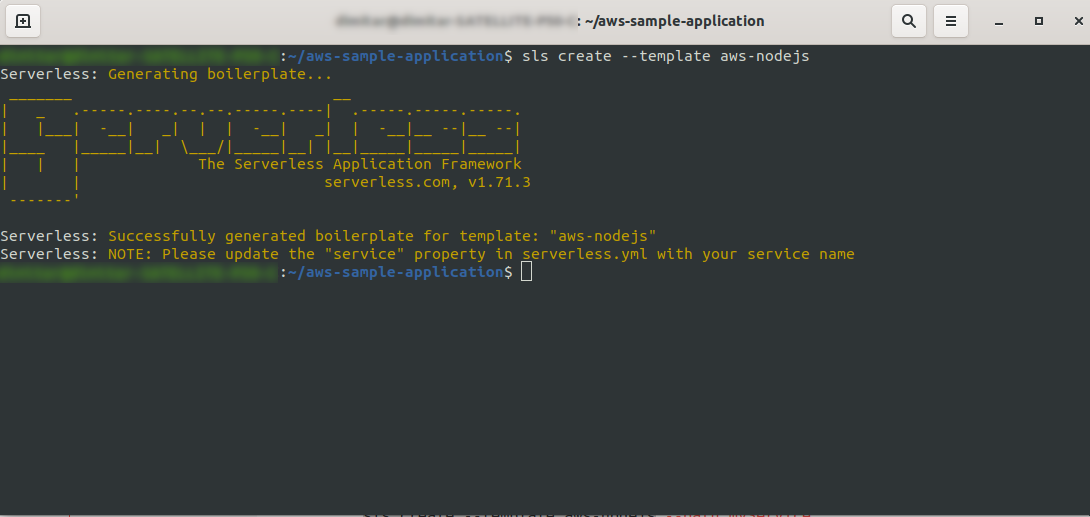
Une fois cela fait, votre répertoire devrait être composé des éléments suivants et ressembler à ceci :
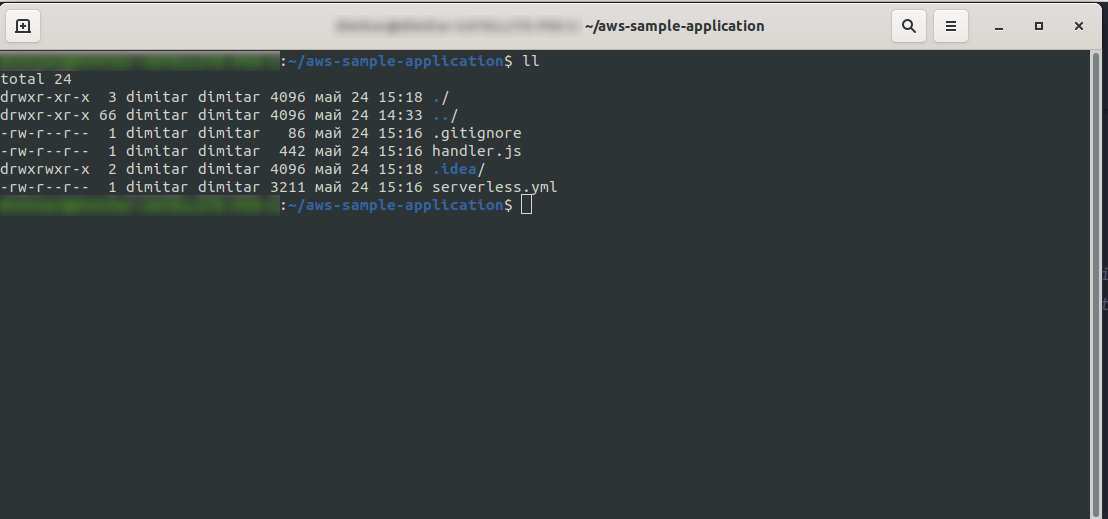
Nous avons créé les nouveaux fichiers handler.js et serverless.yml .
Le fichier handler.js stocke vos fonctions et serverless.yml stocke les propriétés de configuration que vous modifierez ultérieurement. Si vous vous demandez ce qu'est le fichier .yml , en bref, il s'agit d'un langage de sérialisation de données lisible par l'homme . Il est bon de le connaître, car il est utilisé lors de l'insertion de paramètres de configuration. Mais regardons maintenant ce que nous avons dans le fichier serverless.yml :
service : aws-sample-application
fournisseur:
nom : aws
environnement d'exécution : nodejs12.x
les fonctions:
Bonjour:
gestionnaire : gestionnaire. bonjour
- service : – Notre nom de service.
- provider : – Un objet qui contient les propriétés du fournisseur, et comme nous le voyons ici, notre fournisseur est AWS, et nous utilisons le runtime NodeJS.
- functions : – Il s'agit d'un objet qui contient toutes les fonctions pouvant être déployées sur Lambda. Dans cet exemple, nous n'avons qu'une seule fonction nommée hello qui pointe vers la fonction hello de handler.js.
Vous devez faire une chose cruciale ici avant de procéder au déploiement de l'application. Auparavant, nous avons défini les informations d'identification pour AWS avec un profil (nous l'avons nommé serverless-admin ). Maintenant, tout ce que vous avez à faire est de dire à la configuration sans serveur d'utiliser ce profil et votre région. Ouvrez serverless.yml et sous la propriété du fournisseur juste en dessous de l'exécution, entrez ceci :
profil : administrateur sans serveur région : us-east-2
Au final, on devrait avoir ça :
fournisseur: nom : aws environnement d'exécution : nodejs12.x profil : administrateur sans serveur région : us-east-2
Remarque : Pour obtenir la région, un moyen simple consiste à rechercher l'URL lorsque vous êtes connecté à la console : Exemple :
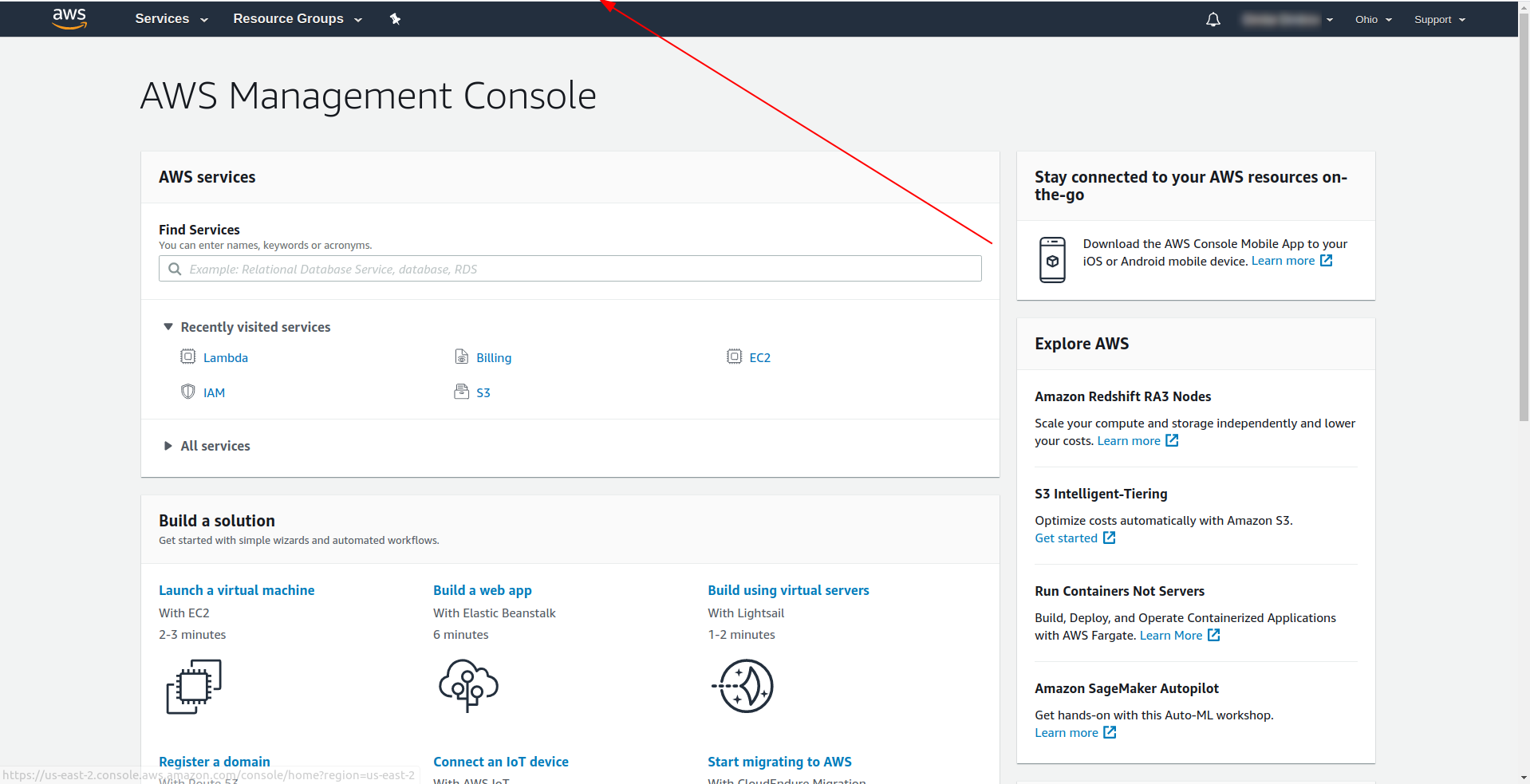
Maintenant que nous avons les informations nécessaires sur notre modèle généré. Voyons comment nous pouvons appeler la fonction localement et la déployer sur AWS Lambda.
On peut immédiatement tester l'application en appelant la fonction localement :
sls invoke local -f hello
Il invoque la fonction (mais uniquement localement !) et renvoie la sortie à la console :
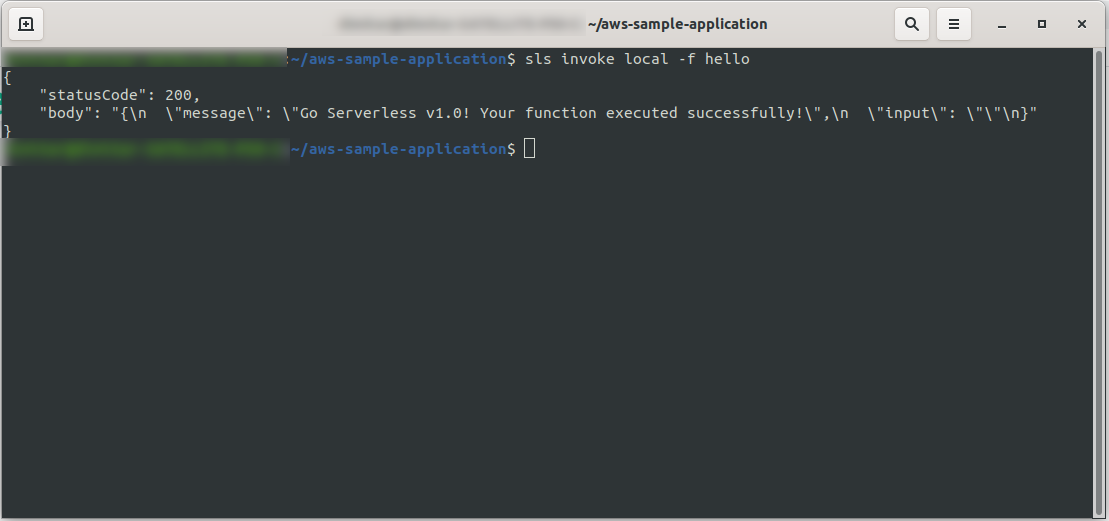
Maintenant, si tout s'est bien passé, vous pouvez essayer de déployer votre fonction sur AWS Lambda .
Alors, c'était compliqué ? Non, ce n'était pas le cas ! Grâce au Serverless Framework , il ne s'agit que d'un code d'une seule ligne :
sls deploy -v
Attendez que tout soit terminé, cela peut prendre quelques minutes, si tout va bien vous devriez terminer par quelque chose comme ceci :
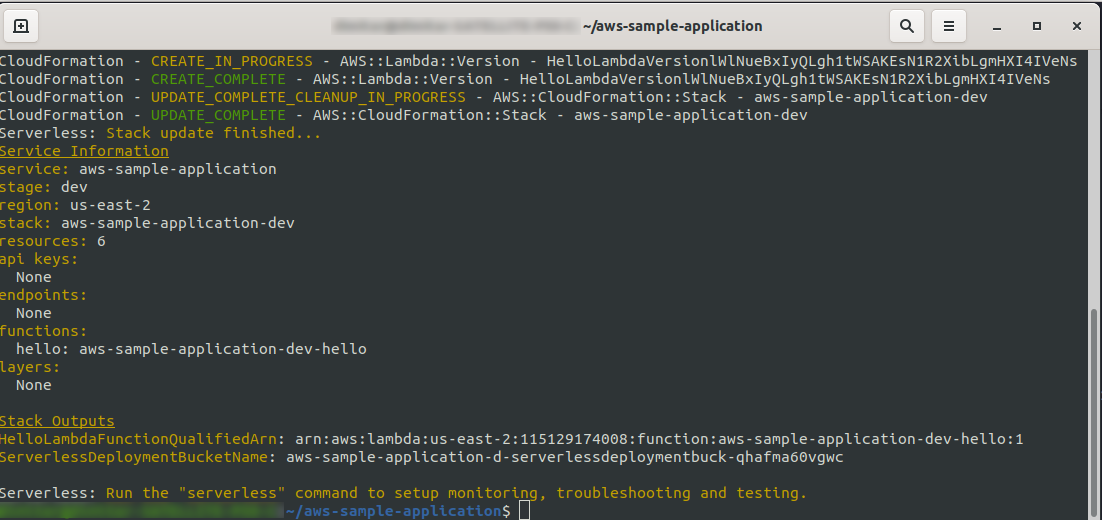
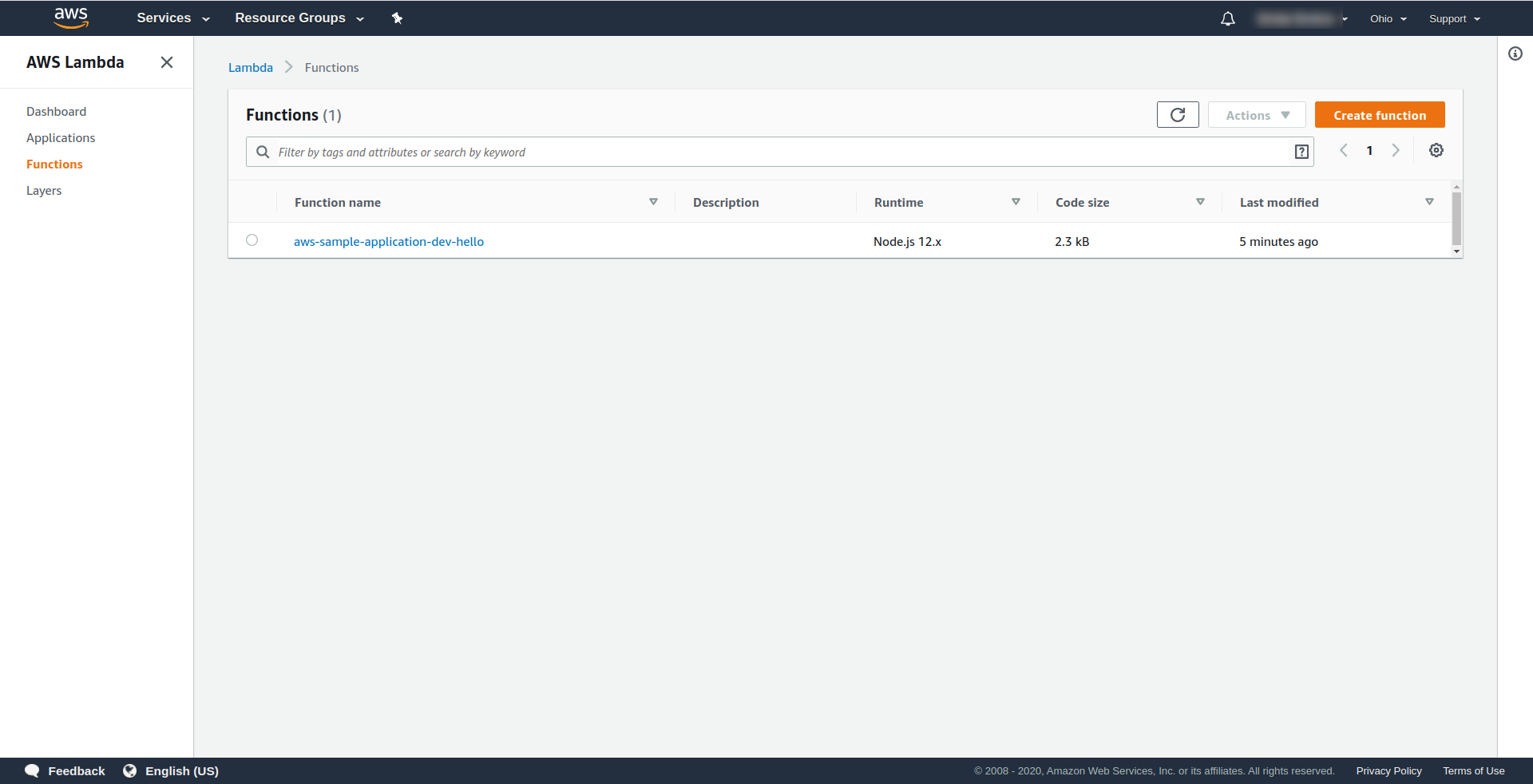
Voyons maintenant ce qui s'est passé dans AWS. Allez dans Lambda (dans « Find Services » tapez Lambda ), et vous devriez voir votre fonction Lambda créée.
Vous pouvez maintenant essayer d'appeler votre fonction à partir d'AWS Lambda. Dans le type de terminal
sls invoke -f hello
Il devrait renvoyer la même sortie que précédemment (lorsque nous testons localement):
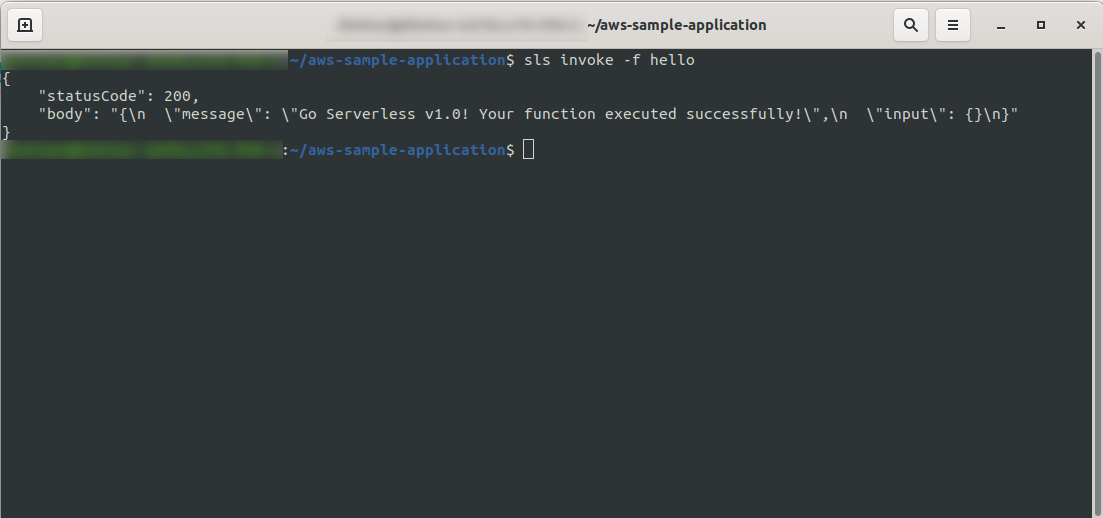
Vous pouvez vérifier que vous avez déclenché la fonction d'AWS en ouvrant la fonction dans AWS Lambda et en allant dans l'onglet « Surveillance » et en cliquant sur « Afficher les journaux dans CloudWatch. “.
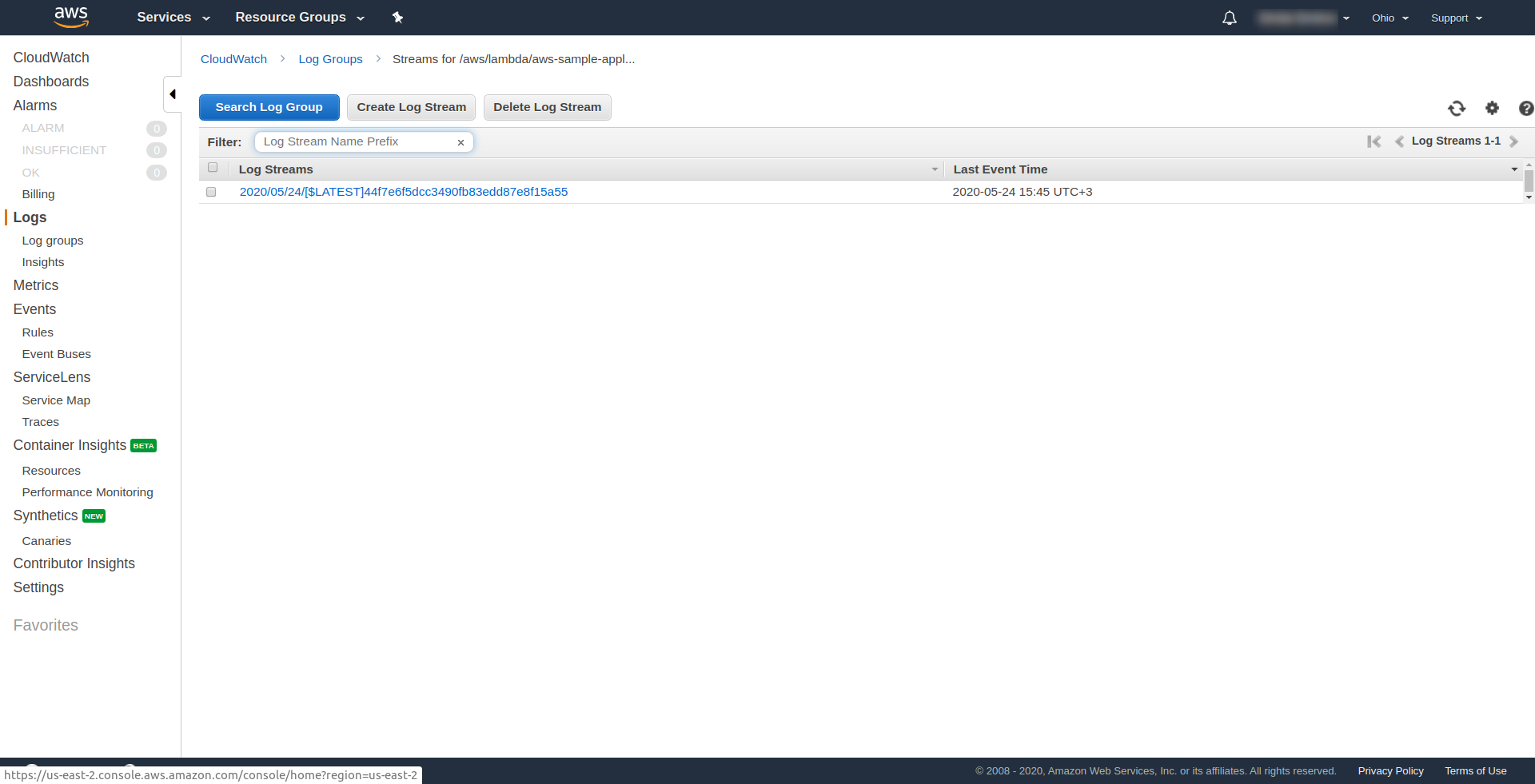
Vous devriez avoir un journal là-bas.
Maintenant, il manque encore une chose dans votre candidature, mais qu'est-ce que c'est… ? Eh bien, vous n'avez pas de point de terminaison auquel accéder pour votre application, alors créons-le à l'aide d' AWS API Gateway.
Vous devez d'abord ouvrir le fichier serverless.yml et nettoyer les commentaires. Vous devez ajouter une propriété events à notre fonction et sous sa propriété http . Cela indique au framework sans serveur de créer une passerelle API et de l'attacher à notre fonction Lambda lors du déploiement de l'application. Notre fichier de configuration devrait se terminer par ceci :
service : aws-sample-application
fournisseur:
nom : aws
environnement d'exécution : nodejs12.x
profil : administrateur sans serveur
région : us-east-2
les fonctions:
Bonjour:
gestionnaire : gestionnaire. bonjour
événements:
-http:
chemin : /bonjour
méthode : obtenir
En http , nous spécifions le chemin et la méthode HTTP.
Voilà, déployons à nouveau notre application en exécutant sls deploy -v
Une fois terminé, une nouvelle chose devrait apparaître dans le terminal de sortie, et c'est le point de terminaison qui a été créé :
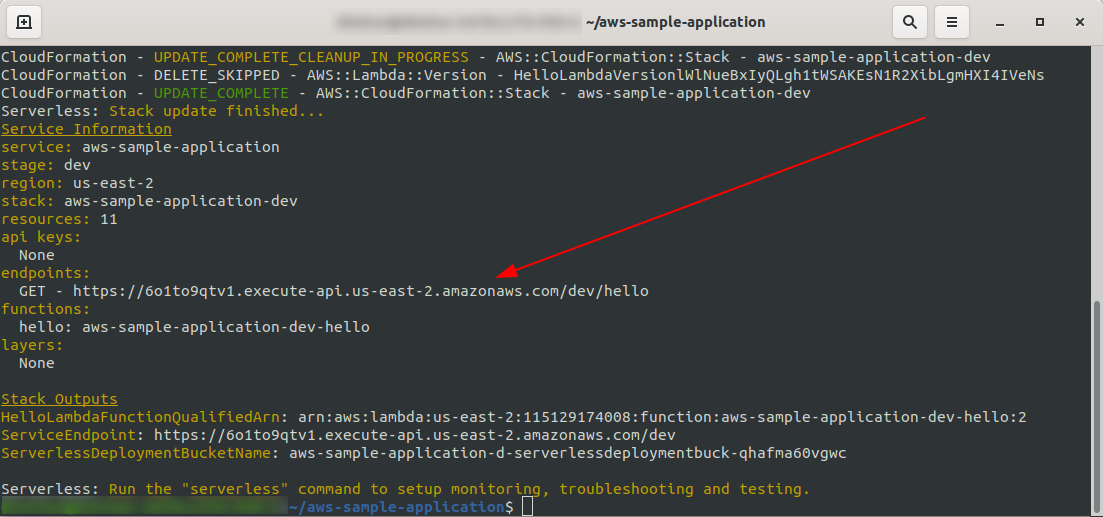
Ouvrons le point de terminaison :
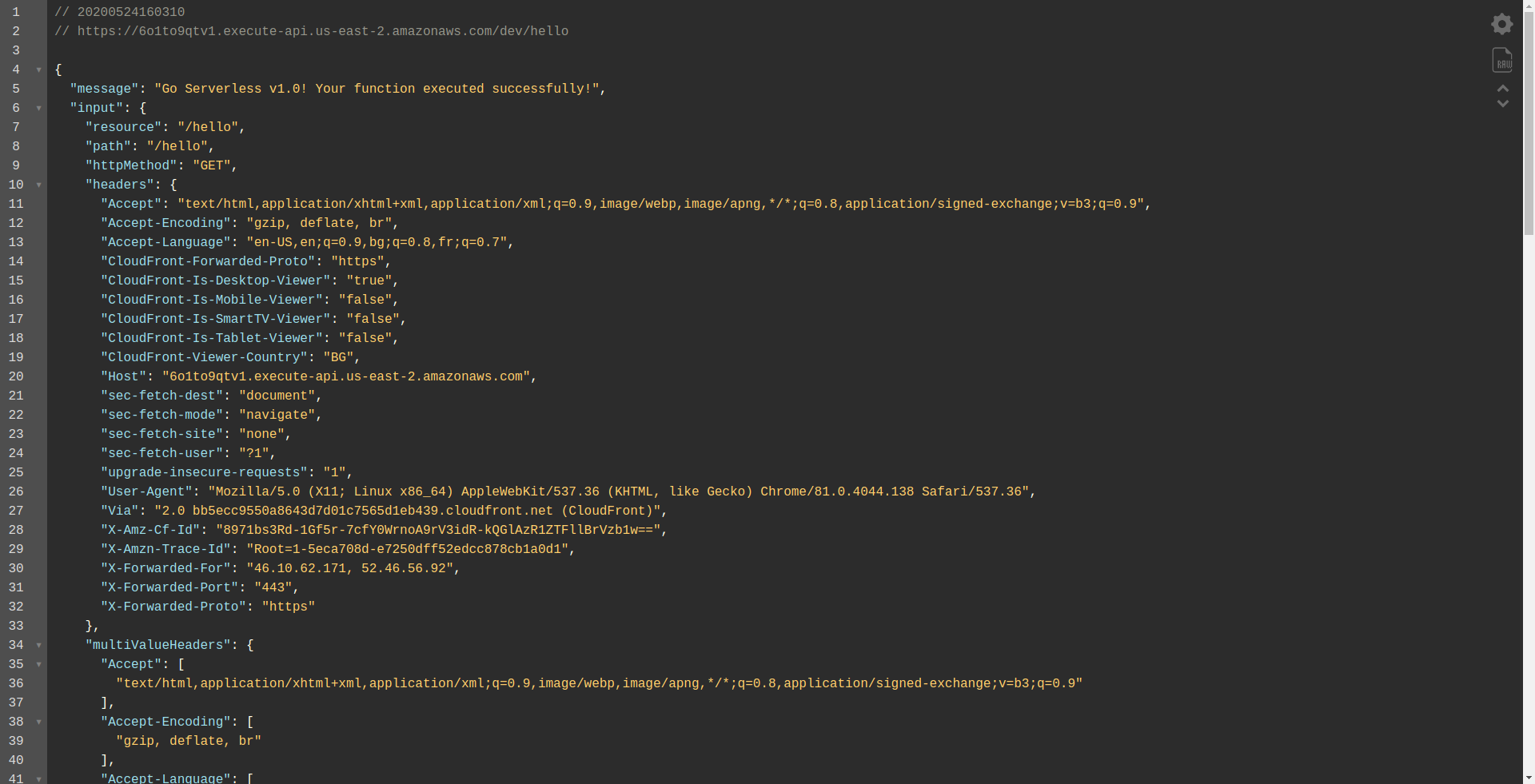
Vous devriez voir que votre fonction s'exécute, renvoie une sortie et des informations sur la requête. Vérifions ce qui change dans notre fonction Lambda.
Ouvrez AWS Lambda et cliquez sur votre fonction.
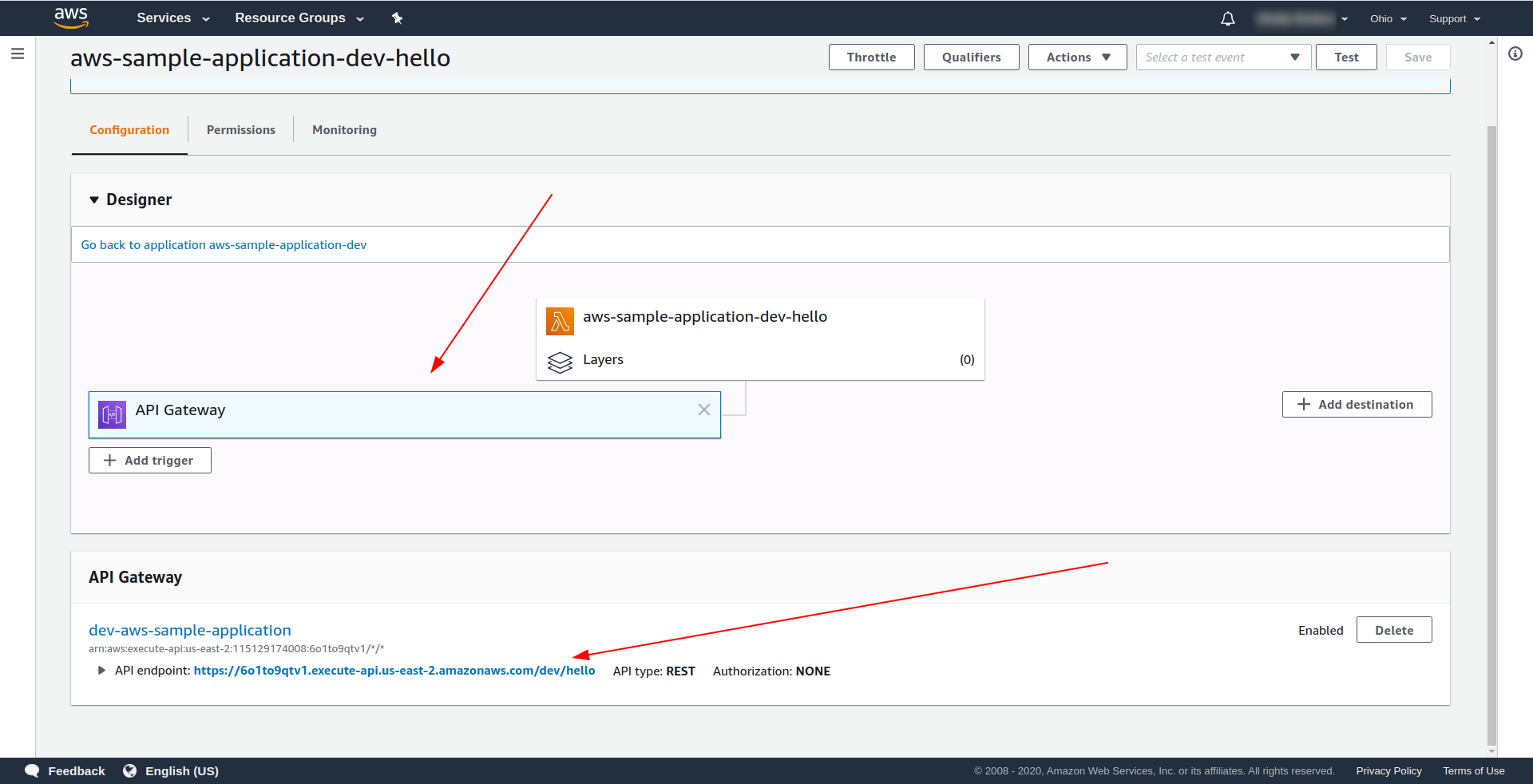
Nous voyons sous l'onglet " Designer " que nous avons API Gateway attaché à notre Lambda et à l'API Endpoint.
Génial! Vous avez créé une application sans serveur super simple, l'avez déployée sur AWS Lambda et testé ses fonctionnalités. De plus, nous avons ajouté un point de terminaison à l'aide d' AWS API Gateway .
4. Comment exécuter l'application hors ligne
Jusqu'à présent, nous savons que nous pouvons invoquer des fonctions localement, mais nous pouvons également exécuter l'intégralité de notre application hors ligne à l'aide du plug-in serverless-offline.
Le plugin émule AWS Lambda et API Gateway sur votre machine locale/de développement. Il démarre un serveur HTTP qui gère les requêtes et appelle vos gestionnaires.
Pour installer le plugin, exécutez la commande ci-dessous dans le répertoire de l'application
npm install serverless-offline --save-dev
Ensuite, dans le fichier serverless.yml du projet, ouvrez le fichier et ajoutez la propriété plugins :
plugins : - sans serveur hors ligne
La configuration devrait ressembler à ceci :
service : aws-sample-application
fournisseur:
nom : aws
environnement d'exécution : nodejs12.x
profil : administrateur sans serveur
région : us-east-2
les fonctions:
Bonjour:
gestionnaire : gestionnaire. bonjour
événements:
-http:
chemin : /bonjour
méthode : obtenir
plugins :
- sans serveur hors ligne
Pour vérifier que nous avons installé et configuré avec succès le plug-in, exécutez
sls --verbose
Vous devriez voir ceci :
Maintenant, à la racine de votre projet, exécutez la commande
sls offline
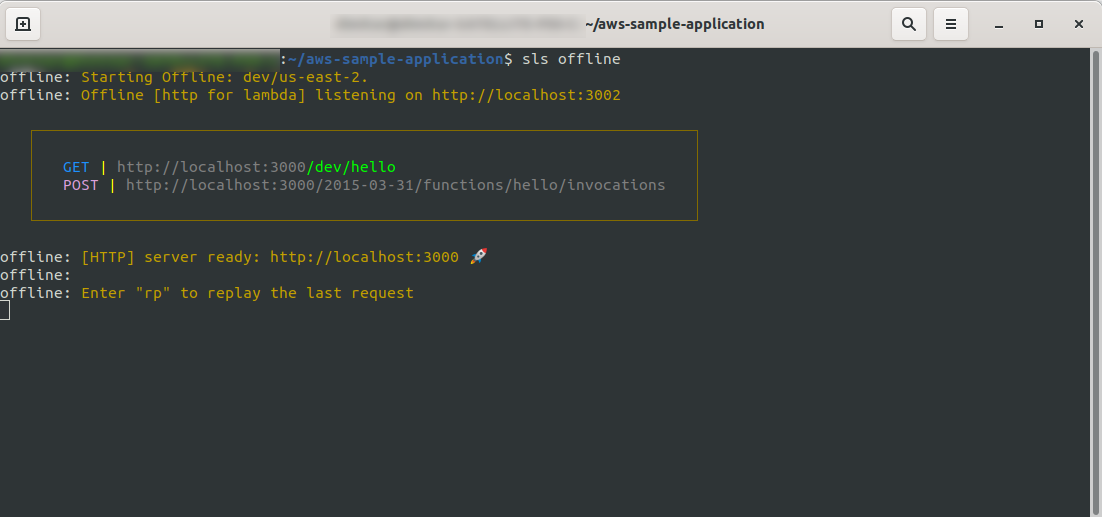
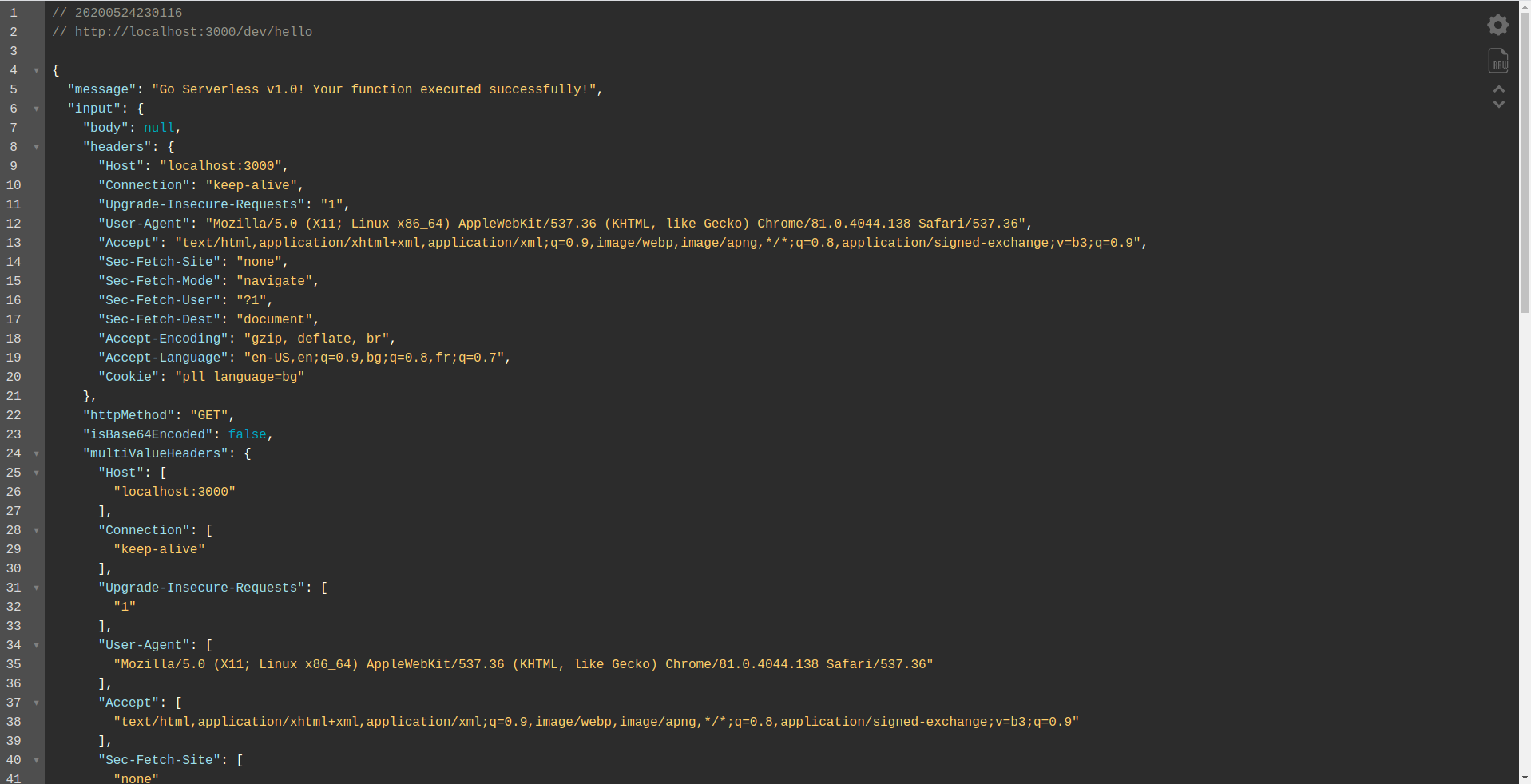
Comme vous pouvez le voir, un serveur HTTP écoute sur le port 3000, et vous pouvez accéder à vos fonctions, par exemple, ici nous avons http://localhost:3000/dev/hello pour notre fonction hello. Ouverture que nous avons la même réponse que de l' API Gateway , que nous avons créé plus tôt.
Ajouter l'intégration de Google BigQuery

Vous avez fait un excellent travail jusqu'à présent ! Vous avez une application entièrement fonctionnelle utilisant Serverless. Étendons notre application et ajoutons-y l'intégration de BigQuery pour voir comment elle fonctionne et comment l'intégration est effectuée.

BigQuery est un logiciel en tant que service (SaaS) sans serveur, c'est-à-dire un entrepôt de données rapide et économique qui prend en charge les requêtes. Avant de continuer à l'intégrer à notre application NodeJS, nous devons créer un compte, alors continuons.
1. Configurer Google Cloud Console
Allez sur https://cloud.google.com et connectez-vous avec votre compte, si vous ne l'avez pas déjà fait - créez un compte et continuez.
Lorsque vous vous connectez à Google Cloud Console, vous devez créer un nouveau projet. Cliquez sur les trois points à côté du logo et cela ouvrira une fenêtre modale où vous choisirez " Nouveau projet. ”
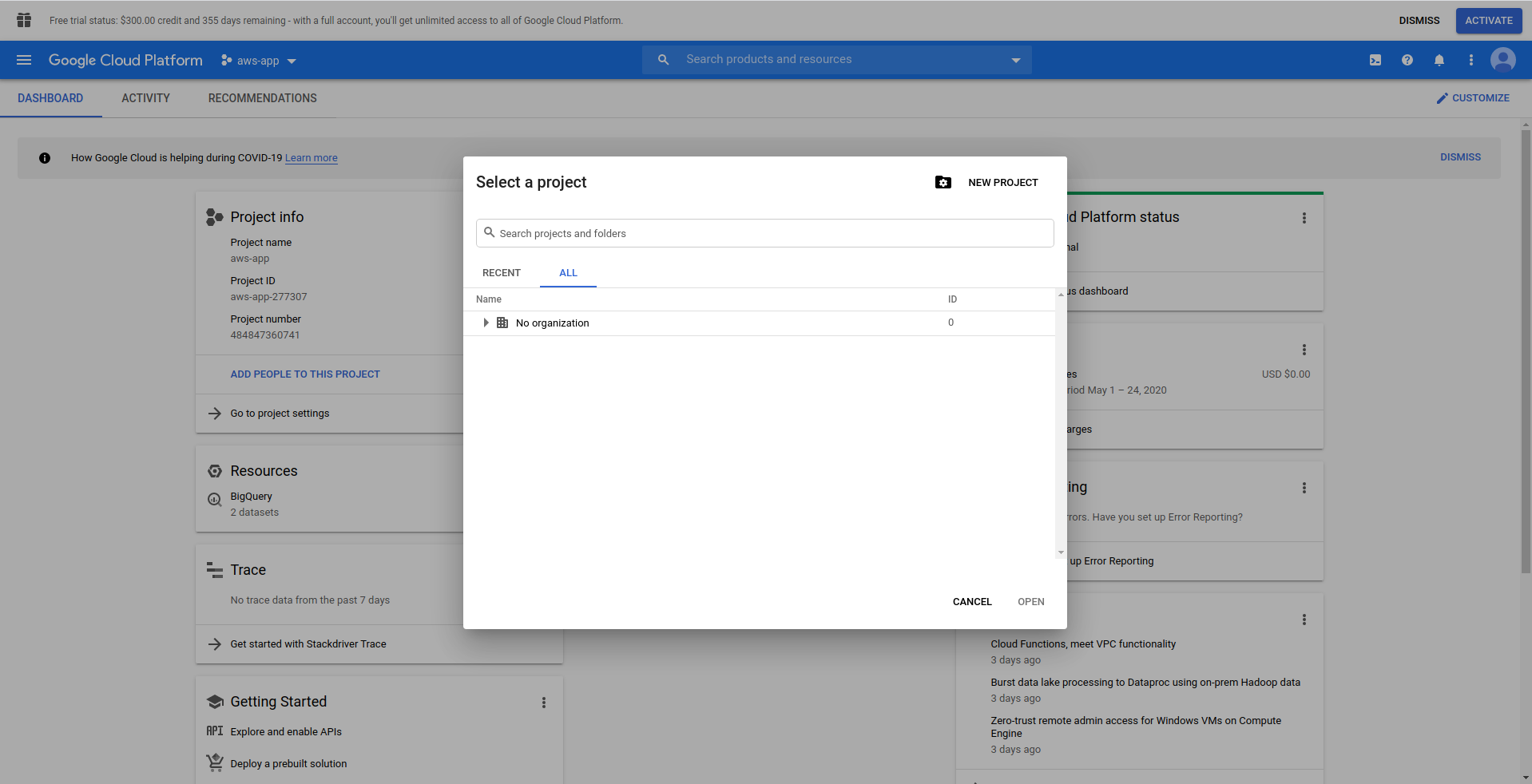
Entrez un nom pour votre projet. Nous utiliserons bigquery-example . Une fois le projet créé, accédez à BigQuery à l'aide du tiroir :
Lorsque BigQuery se charge, sur le côté gauche, vous verrez les données du projet, auxquelles vous avez accès, ainsi que les ensembles de données publics. Nous utilisons un ensemble de données public pour cet exemple. Il se nomme covid19_ecdc :
Jouez autour de l'ensemble de données et des tables disponibles. Prévisualisez les données qu'il contient. Il s'agit d'un ensemble de données public qui est mis à jour toutes les heures et contient des informations sur les données mondiales du COVID-19 .
Nous devons créer un utilisateur IAM -> Compte de service pour pouvoir accéder aux données. Donc, dans le menu, cliquez sur "IAM & Admin", puis sur "Comptes de service".
Cliquez sur le bouton "Créer un compte de service" , entrez le nom du compte de service et cliquez sur "Créer". Ensuite, accédez à " Autorisations du compte de service " , recherchez et choisissez " BigQuery Admin " .
Cliquez sur « Continuer », c'est la dernière étape, ici vous avez besoin de vos clés, alors cliquez sur le bouton de création sous « Clés » et exportez au format JSON . Enregistrez-le dans un endroit sûr, nous en aurons besoin plus tard. Cliquez sur Terminé pour terminer la création du compte de service.
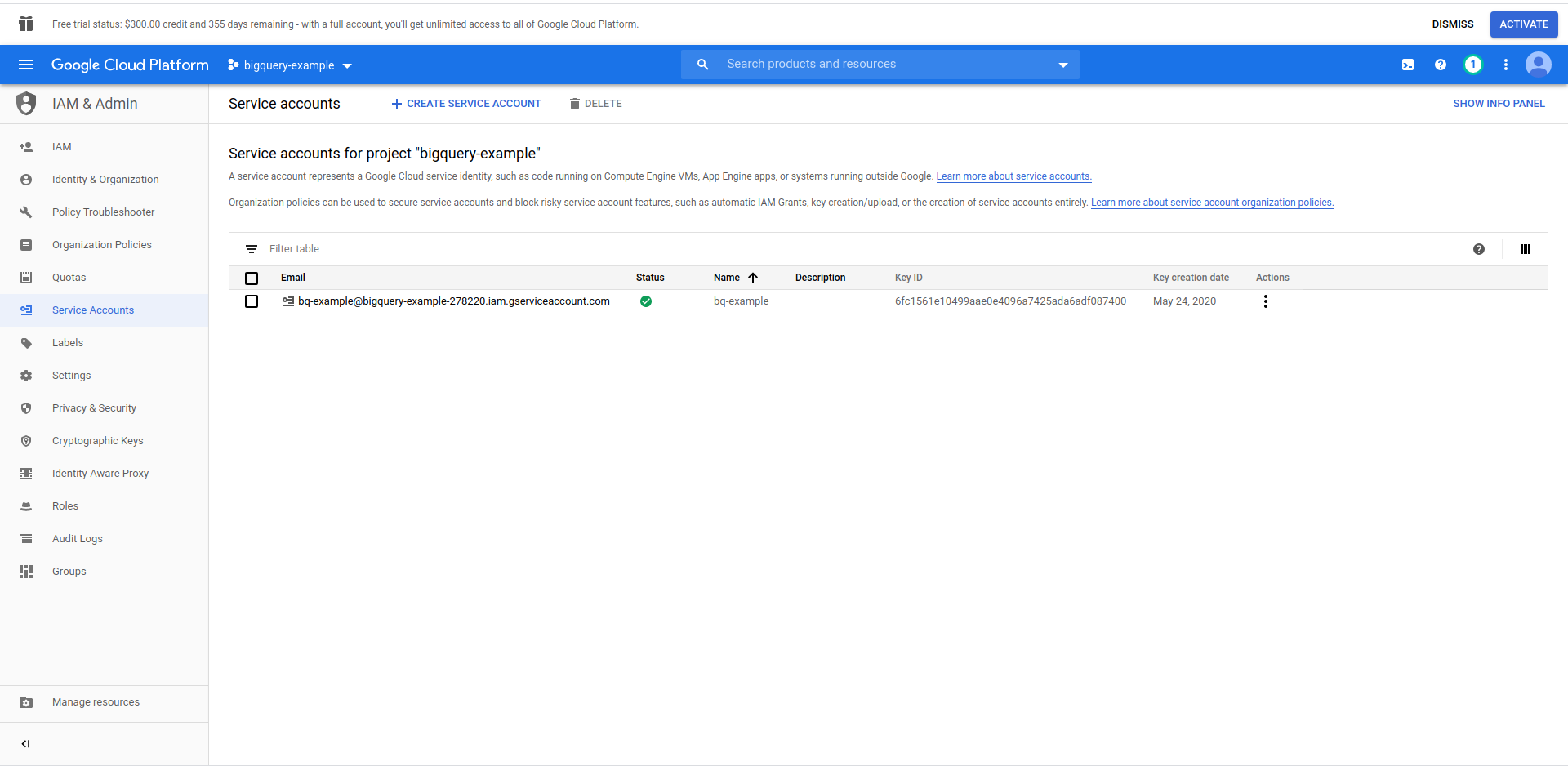
Maintenant, nous allons utiliser les informations d'identification générées ici pour connecter la bibliothèque NodeJS BigQuery.
2. Installez la bibliothèque NodeJS BigQuery
Vous devrez installer la bibliothèque BigQuery NodeJS pour l'utiliser dans le projet que vous venez de créer. Exécutez les commandes ci-dessous dans le répertoire de l'application :
Tout d'abord, initialisez npm en exécutant npm init
Remplissez toutes les questions et procédez à l'installation de la bibliothèque BigQuery :
npm install @google-cloud/bigquery
Avant de continuer à modifier notre gestionnaire de fonctions, nous devons transporter la clé privée du fichier JSON que nous avons précédemment créé. Nous allons utiliser des variables d' environnement sans serveur pour ce faire. Vous pouvez obtenir plus d'informations ici.
Ouvrez serverless.yml et dans la propriété du fournisseur , ajoutez une propriété d' environnement comme ceci :
environnement:
PROJECT_ID : ${file(./config/bigquery-config.json):project_id}
CLIENT_EMAIL : ${file(./config/bigquery-config.json):client_email}
PRIVATE_KEY : ${file(./config/bigquery-config.json):private_key}
Créez les variables d'environnement PROJECT_ID, PRIVATE_KEY et CLIENT_EMAIL , qui prennent les mêmes propriétés (en minuscules) du fichier JSON que nous avons généré. Nous l'avons placé dans le dossier config et l'avons nommé bigquery-config.json .
À l'heure actuelle, vous devriez vous retrouver avec le fichier serverless.yml ressemblant à ceci :
service : aws-sample-application
fournisseur:
nom : aws
environnement d'exécution : nodejs12.x
profil : administrateur sans serveur
région : us-east-2
environnement:
PROJECT_ID : ${file(./config/bigquery-config.json):project_id}
CLIENT_EMAIL : ${file(./config/bigquery-config.json):client_email}
PRIVATE_KEY : ${file(./config/bigquery-config.json):private_key}
les fonctions:
Bonjour:
gestionnaire : gestionnaire. bonjour
événements:
-http:
chemin : /bonjour
méthode : obtenir
plugins :
- sans serveur hors ligne
Ouvrez maintenant handler.js et importons la bibliothèque BigQuery. En haut du fichier, sous "use strict", ajoutez la ligne suivante :
const {BigQuery} = require('@google-cloud/bigquery');
Nous devons maintenant indiquer les informations d'identification à la bibliothèque BigQuery. Pour cela, créez une nouvelle constante qui instancie BigQuery avec les identifiants :
const bigQueryClient = new BigQuery({
ID de projet : process.env.PROJECT_ID,
identifiants: {
client_email : process.env.CLIENT_EMAIL,
clé_privée : process.env.PRIVATE_KEY
}
});
Ensuite, créons notre requête SQL BigQuery. Nous voulons récupérer les dernières informations sur les cas de COVID-19 pour la Bulgarie. Nous utilisons l'éditeur de requête BigQuery pour le tester avant de continuer. Nous avons donc créé une requête personnalisée :
SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_ ORDER BY date DESC LIMIT 1
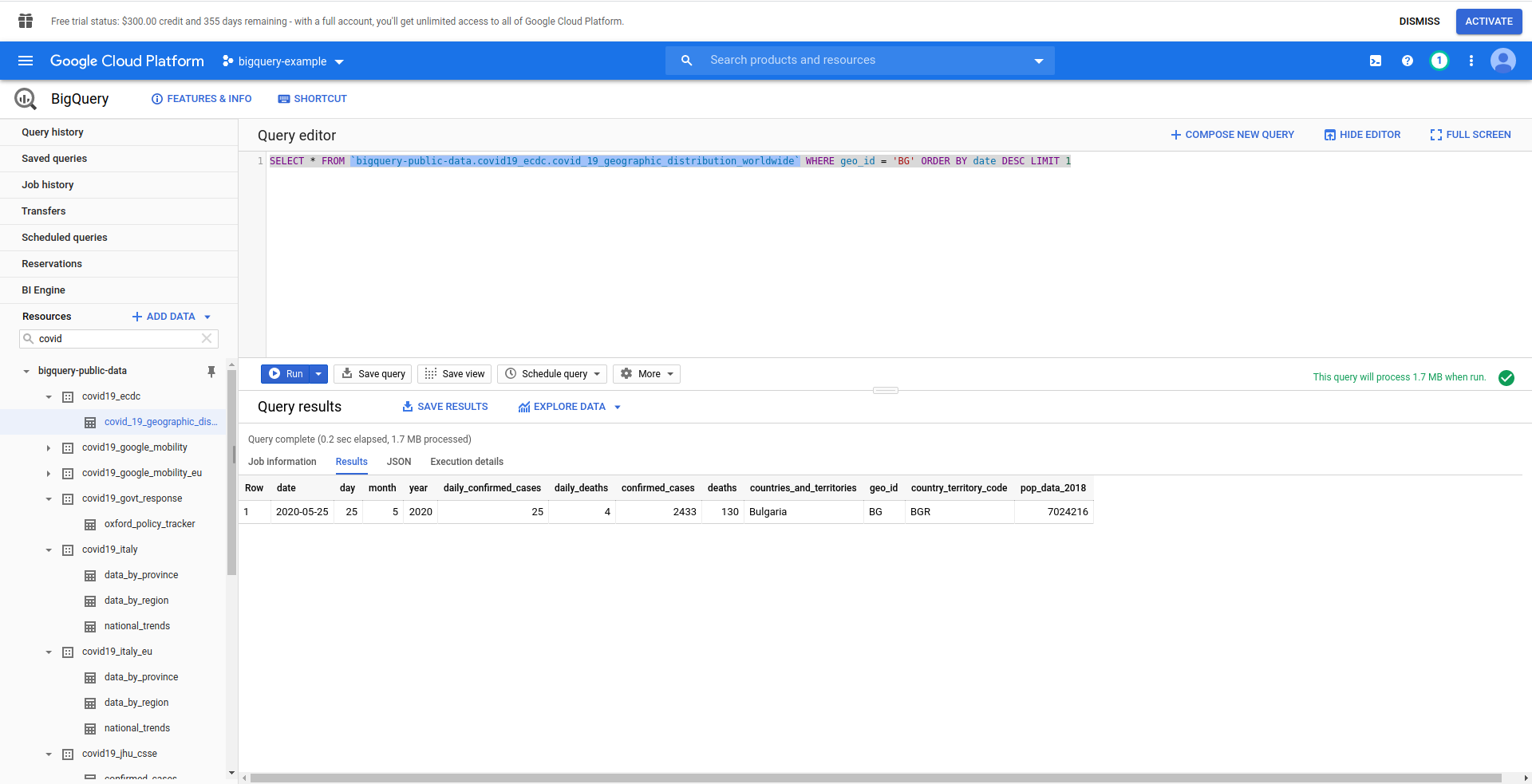
Bien! Maintenant, implémentons cela dans notre application NodeJS.
Ouvrez handler.js et collez le code ci-dessous
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG\' ORDER BY date DESC LIMIT 1' ;
options constantes = {
requête : requête
}
const [travail] = attendre bigQueryClient.createQueryJob(options);
const [lignes] = attendre job.getQueryResults();
Nous avons créé des constantes de requête et d'options . Ensuite, nous procédons à l'exécution de la requête en tant que tâche et à la récupération des résultats à partir de celle-ci.
Modifions également notre gestionnaire de retour pour renvoyer les lignes générées à partir de la requête :
retourner {
code d'état : 200,
corps : JSON.stringify(
{
Lignes
},
nul,
2
),
} ;
Voyons le handler.js complet :
'utiliser strictement';
const {BigQuery} = require('@google-cloud/bigquery');
const bigQueryClient = new BigQuery({
ID de projet : process.env.PROJECT_ID,
identifiants: {
client_email : process.env.CLIENT_EMAIL,
clé_privée : process.env.PRIVATE_KEY
}
});
module.exports.hello = événement asynchrone => {
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG\' ORDER BY date DESC LIMIT 1' ;
options constantes = {
requête : requête
}
const [travail] = attendre bigQueryClient.createQueryJob(options);
const [lignes] = attendre job.getQueryResults();
retourner {
code d'état : 200,
corps : JSON.stringify(
{
Lignes
},
nul,
2
),
} ;
} ;
D'accord! Testons notre fonction localement :
sls invoke local -f hello
Nous devrions voir la sortie :
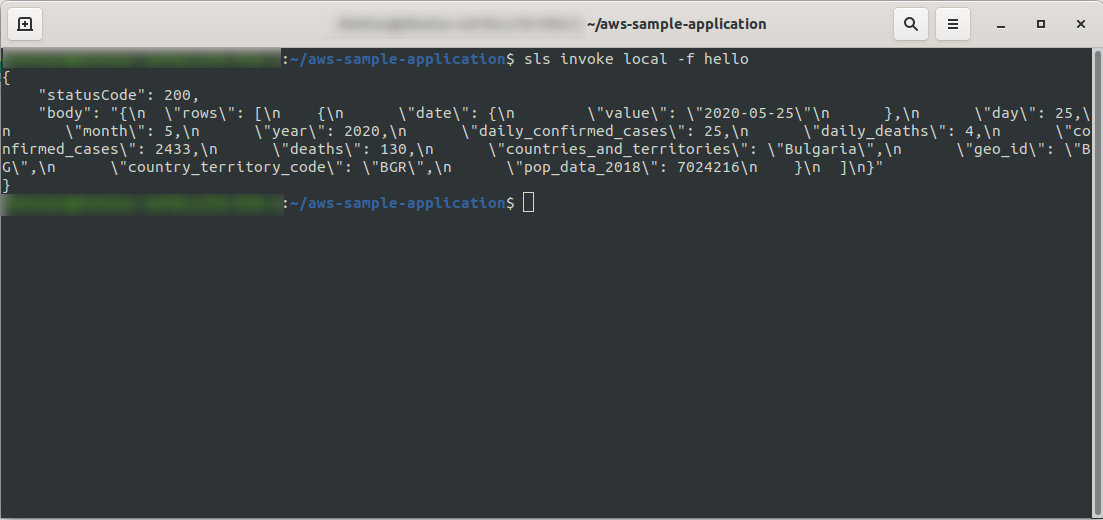
Procédez au déploiement de l'application pour la tester via les points de terminaison HTTP, exécutez donc sls deploy -v
Attendez qu'il se termine et ouvrez le point de terminaison. Voici les résultats:
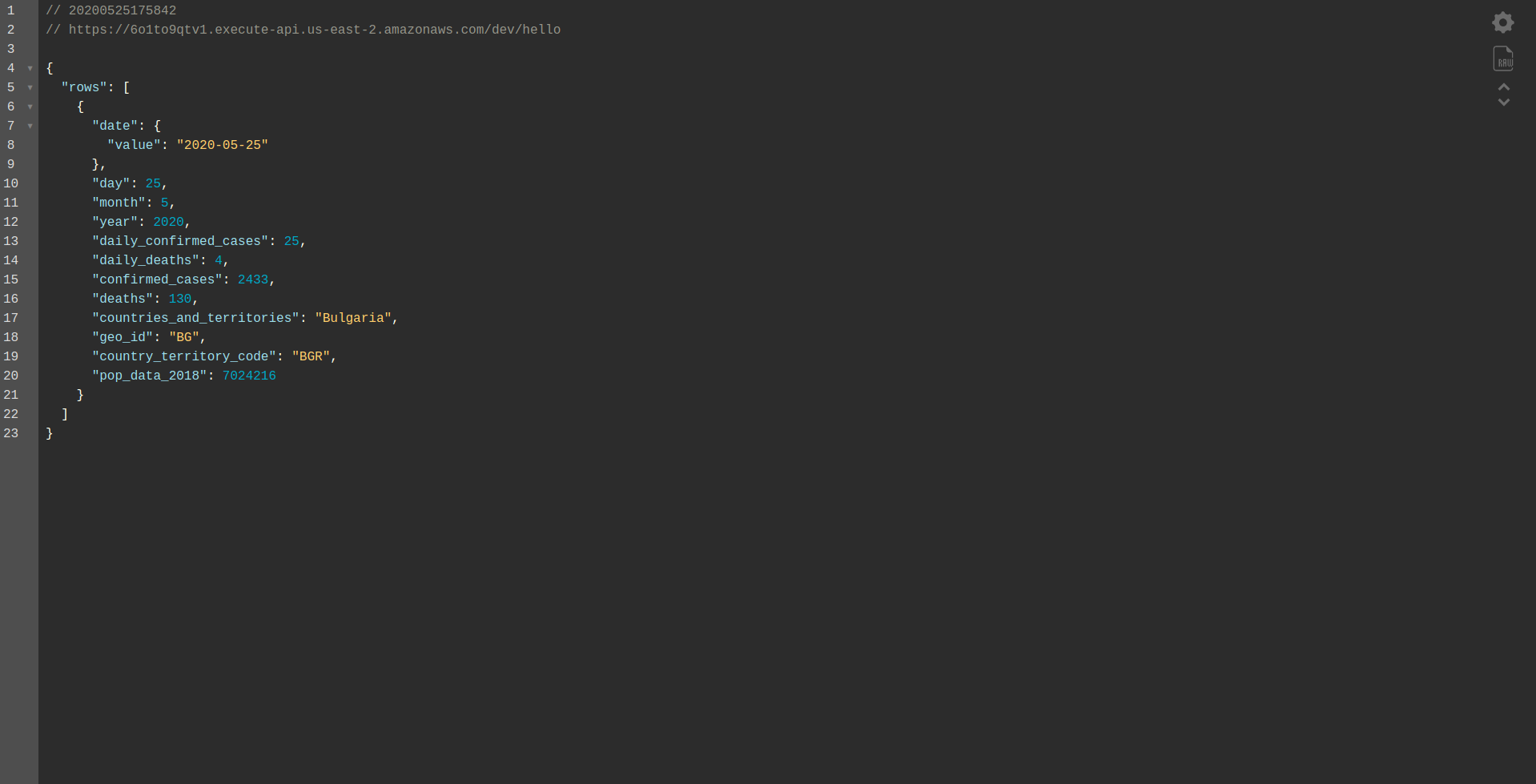
Bien joué! Nous avons maintenant une application pour récupérer les données de BigQuery et renvoyer une réponse ! Vérifions enfin qu'il fonctionne hors ligne. Exécuter sls offline
Et chargez le point de terminaison local :
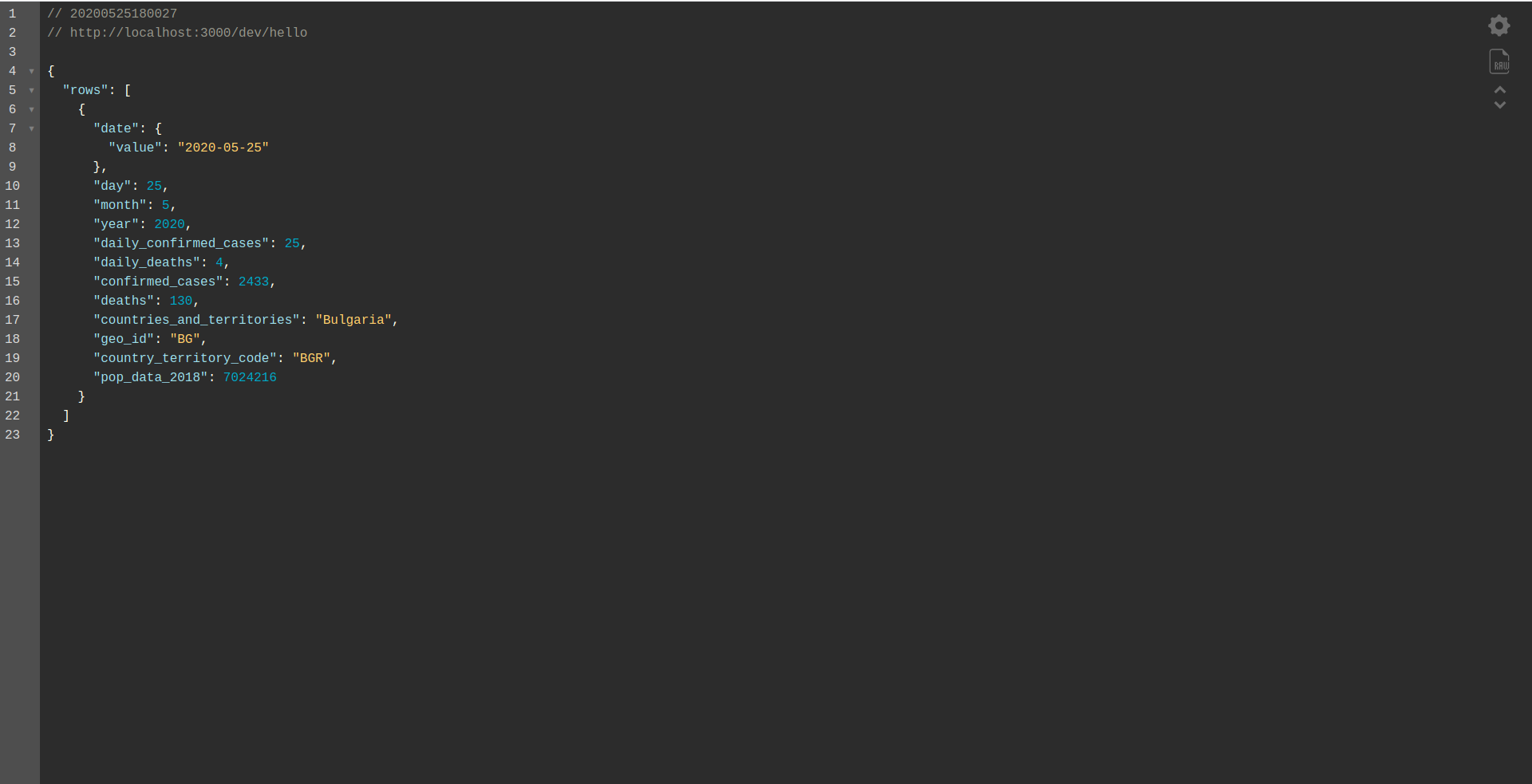
Travail bien fait. Nous sommes presque à la fin du processus. La dernière étape consiste à modifier légèrement l'application et le comportement. Au lieu d' AWS API Gateway , nous souhaitons utiliser l' Application Load Balancer . Voyons comment y parvenir dans le chapitre suivant.
ALB - Équilibreur de charge d'application dans AWS
Nous avons créé notre application en utilisant AWS API Gateway. Dans ce chapitre, nous expliquerons comment remplacer la passerelle API par Application Load Balancer (ALB).
Voyons d'abord comment fonctionne l'équilibreur de charge d'application par rapport à la passerelle API :
Dans l'équilibreur de charge d'application, nous mappons un ou plusieurs chemins spécifiques (par exemple, /hello/ ) vers un groupe cible - un groupe de ressources, dans notre cas, la fonction Lambda .
Un groupe cible ne peut être associé qu'à une seule fonction Lambda. Chaque fois que le groupe cible doit répondre, l'équilibreur de charge d'application envoie une demande à Lambda et la fonction doit répondre avec un objet de réponse. Comme la passerelle API, l' ALB gère toutes les requêtes HTTP(s).
Il existe quelques différences entre l'ALB et la passerelle API . L'une des principales différences est que la passerelle API ne prend en charge que HTTPS (SSL), tandis que l'ALB prend en charge HTTP et HTTPS.
Mais voyons quelques avantages et inconvénients de la passerelle API :
Passerelle API :
Avantages:
- Excellente sécurité.
- C'est simple à mettre en œuvre.
- Il est rapide à déployer et prêt à fonctionner en une minute.
- Évolutivité et disponibilité.
Les inconvénients:
- Cela peut devenir assez coûteux face à un trafic élevé.
- Cela nécessite un peu plus d'orchestration, ce qui ajoute un niveau de difficulté pour les développeurs.
- La dégradation des performances, due aux scénarios d'API, peut avoir un impact sur la vitesse et la fiabilité de l'application.
Continuons en créant un ALB et en basculant vers celui-ci au lieu d'utiliser la passerelle API :
1. Qu'est-ce que l'ALB ?
L'équilibreur de charge d'application permet au développeur de configurer et d'acheminer le trafic entrant. Il s'agit d'une fonctionnalité d'" Elastic Load Balancing". Il sert de point de contact unique pour les clients, distribue le trafic entrant des applications sur plusieurs cibles, telles que les instances EC2 dans plusieurs zones.
2. Créer un équilibreur de charge d'application à l'aide de l'interface utilisateur AWS
Créons notre équilibreur de charge d'application (ALB) via l'interface utilisateur dans Amazon AWS. Connectez-vous à la console AWS dans « Find services. » tapez « EC2 » et recherchez « Équilibreurs de charge ». ”
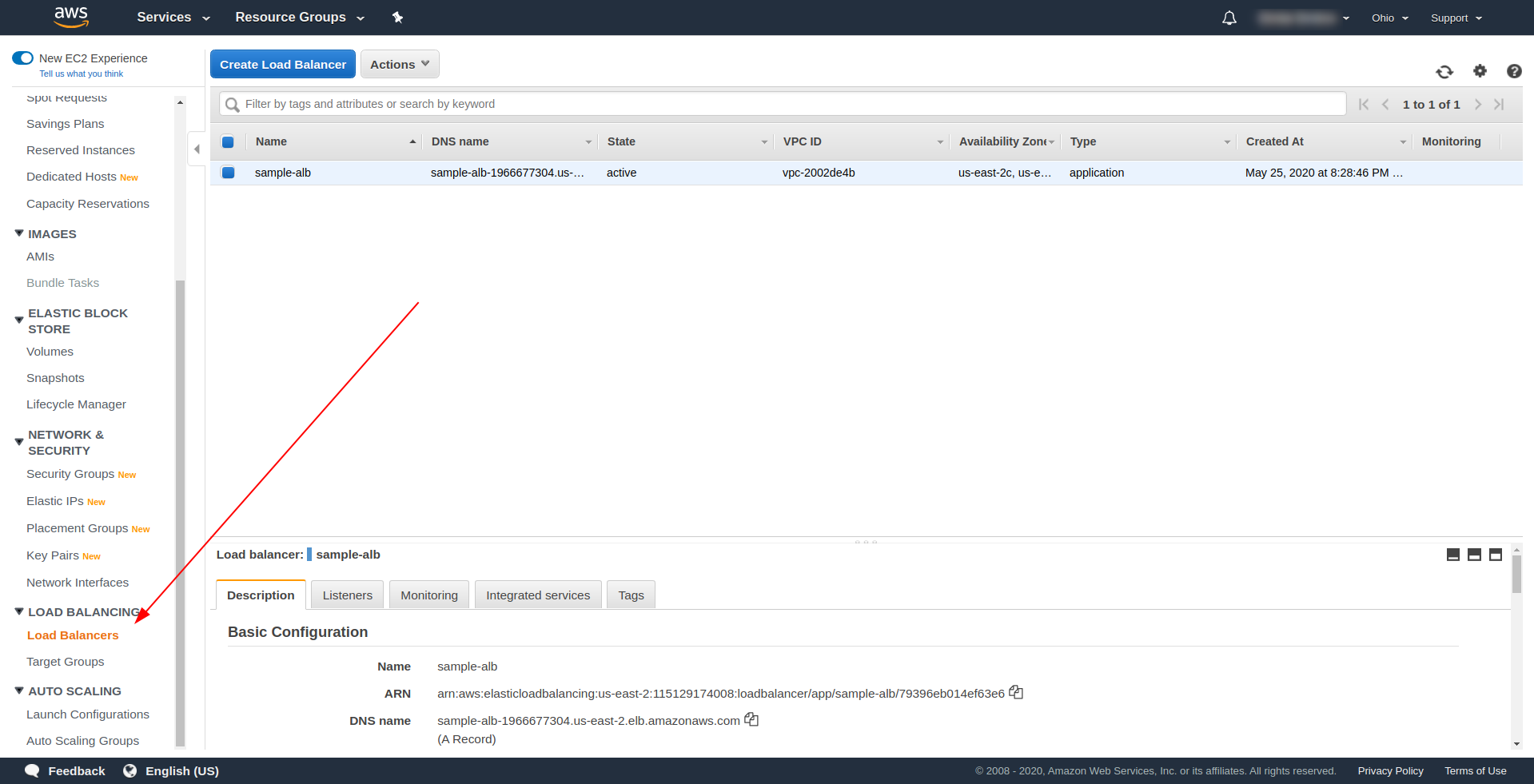
Cliquez sur « Créer un équilibreur de charge », sous « Équilibreur de charge d'application », choisissez « Créer ». Pour un nom, entrez votre choix, nous avons utilisé " sample-alb ", choisissez Scheme " internet-facing ", type d'adresse IP ipv4.
Sur " Listeners ", laissez-le tel quel - HTTP et le port 80. Il peut être configuré pour HTTPS, bien que vous deviez avoir un domaine et le confirmer avant de pouvoir utiliser HTTPS.
Zones de disponibilité – Pour VPC , choisissez celle que vous avez dans la liste déroulante et marquez toutes les « zones de disponibilité » :
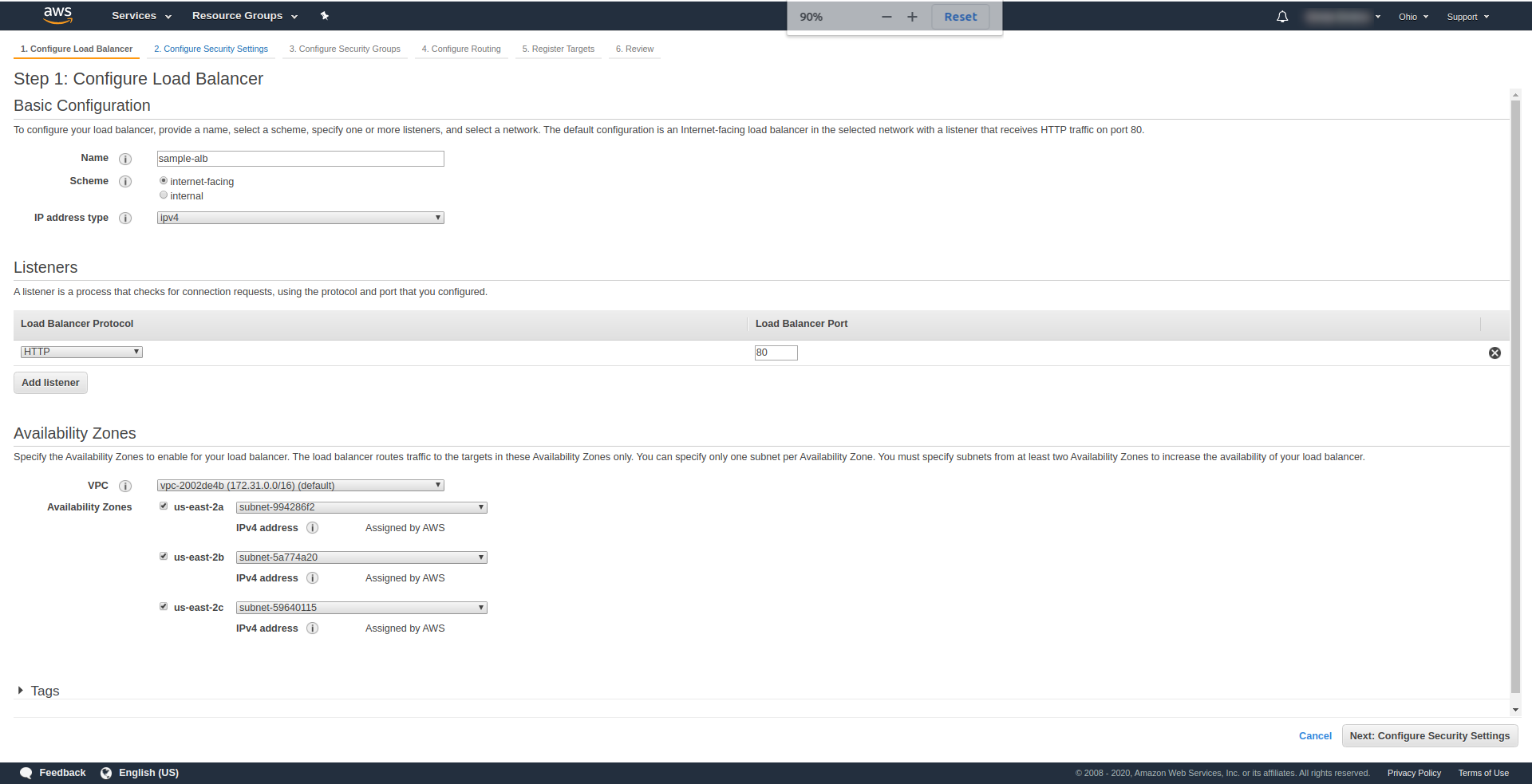
Cliquez sur " Suivant Configurer les paramètres de sécurité " pour vous inviter à améliorer la sécurité de votre équilibreur de charge. Cliquez sur Suivant.
À « Étape 3.Configurer les groupes de sécurité », à Attribuer un groupe de sécurité pour choisir « Créer un nouveau groupe de sécurité ». Continuez ensuite en cliquant sur « Suivant : Configurer le routage ». “. À l'étape 4, configurez-le comme indiqué sur la capture d'écran ci-dessus :
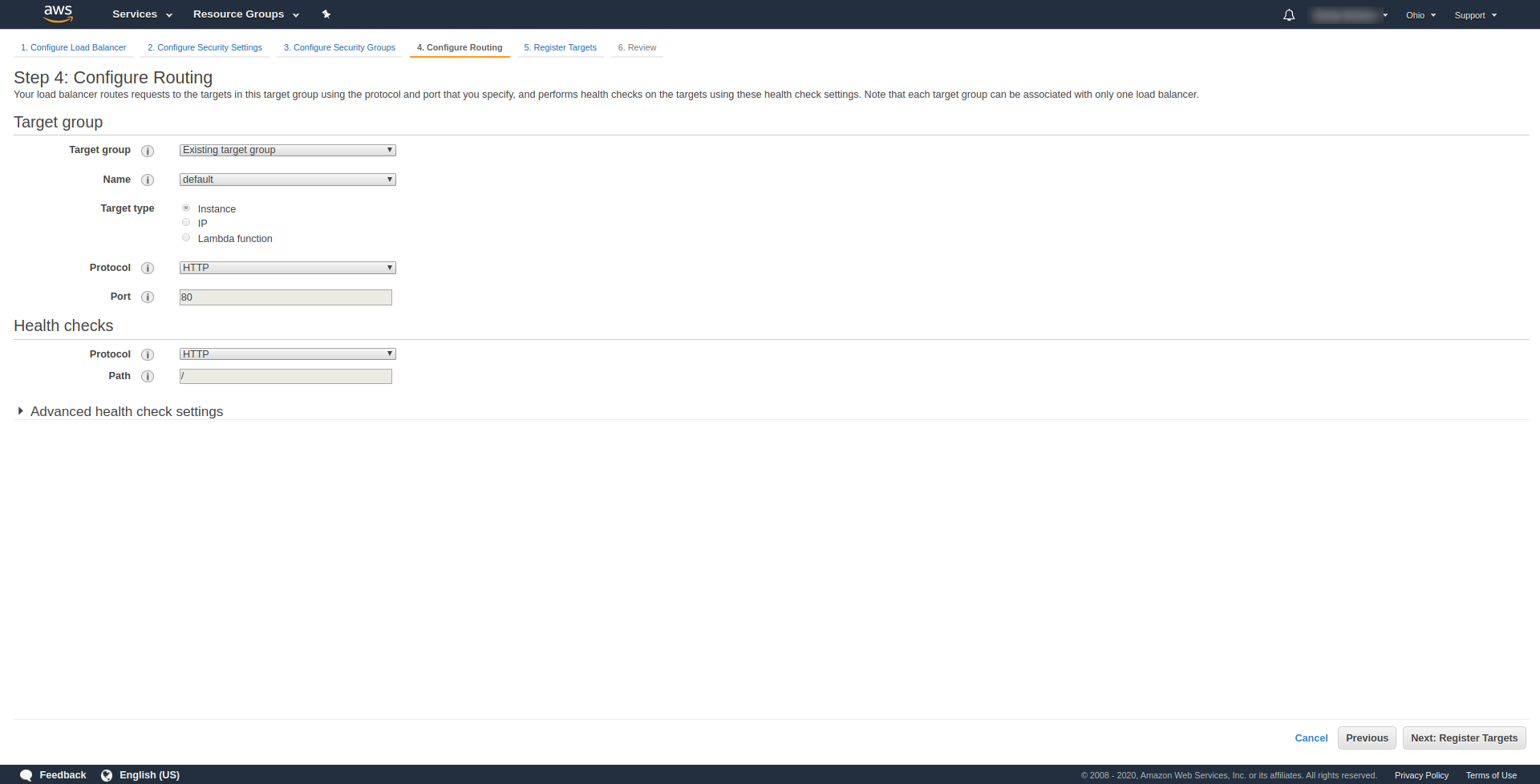
Cliquez sur Suivant , Suivant et Créer .
Revenez aux équilibreurs de charge et copiez l'ARN comme indiqué dans la capture d'écran :
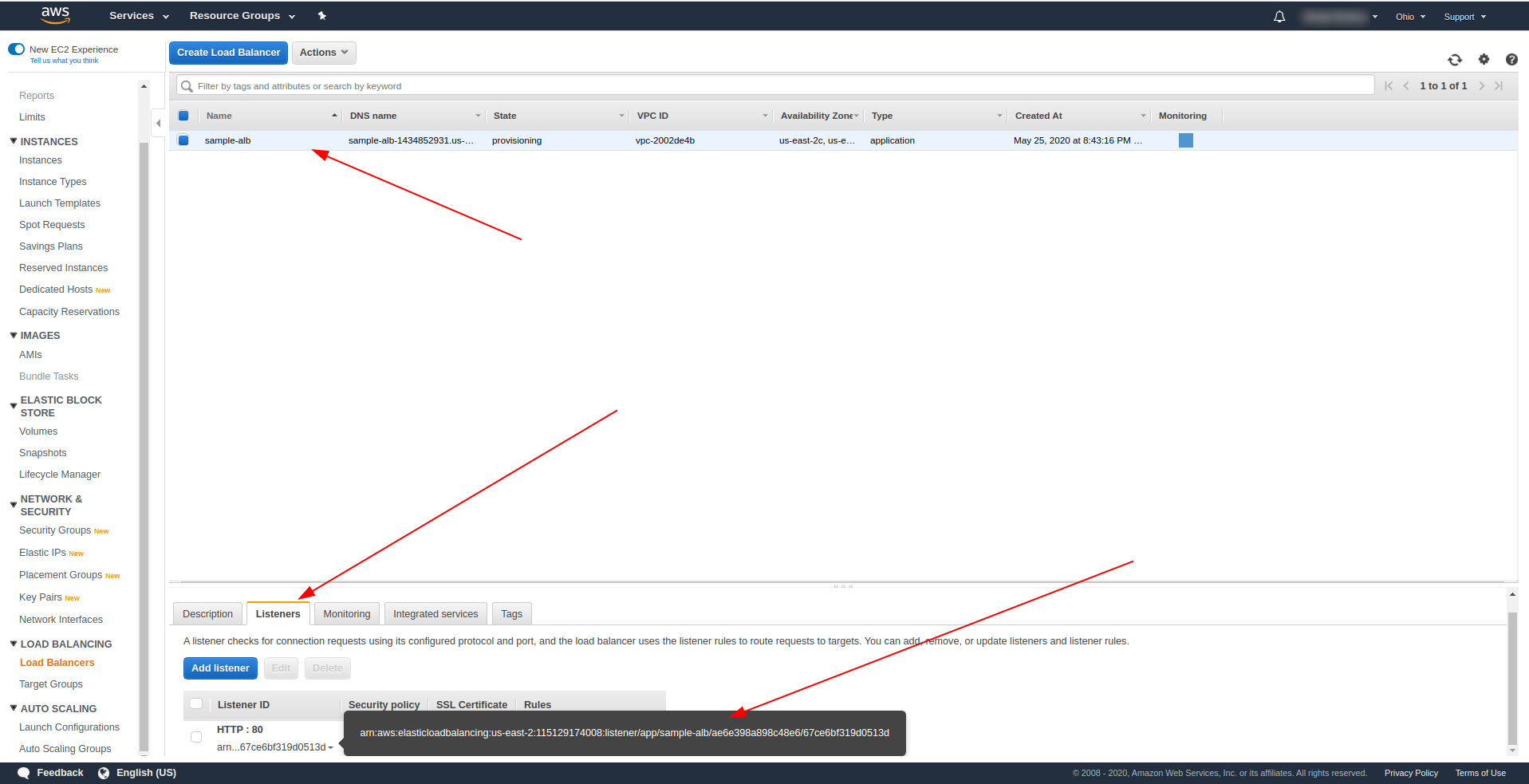
Nous devons maintenant modifier notre serverless.yml et supprimer la propriété http API Gateway. Sous la propriété events, supprimez la propriété http et ajoutez une propriété alb. L'objet fonction doit se terminer comme ceci :
Bonjour:
gestionnaire : gestionnaire. bonjour
événements:
- aube :
listenerArn : arn:aws:elasticloadbalancing:us-east-2:115129174008:listener/app/sample-alb/ae6e398a898c48e6/67ce6bf319d0513d
priorité : 1
conditions:
chemin : /bonjour
Enregistrez le fichier et exécutez la commande de déploiement de l'application
sls deploy -v
Une fois le déploiement réussi, revenez à AWS Load Balancers et recherchez votre nom DNS comme indiqué sur la capture d'écran :
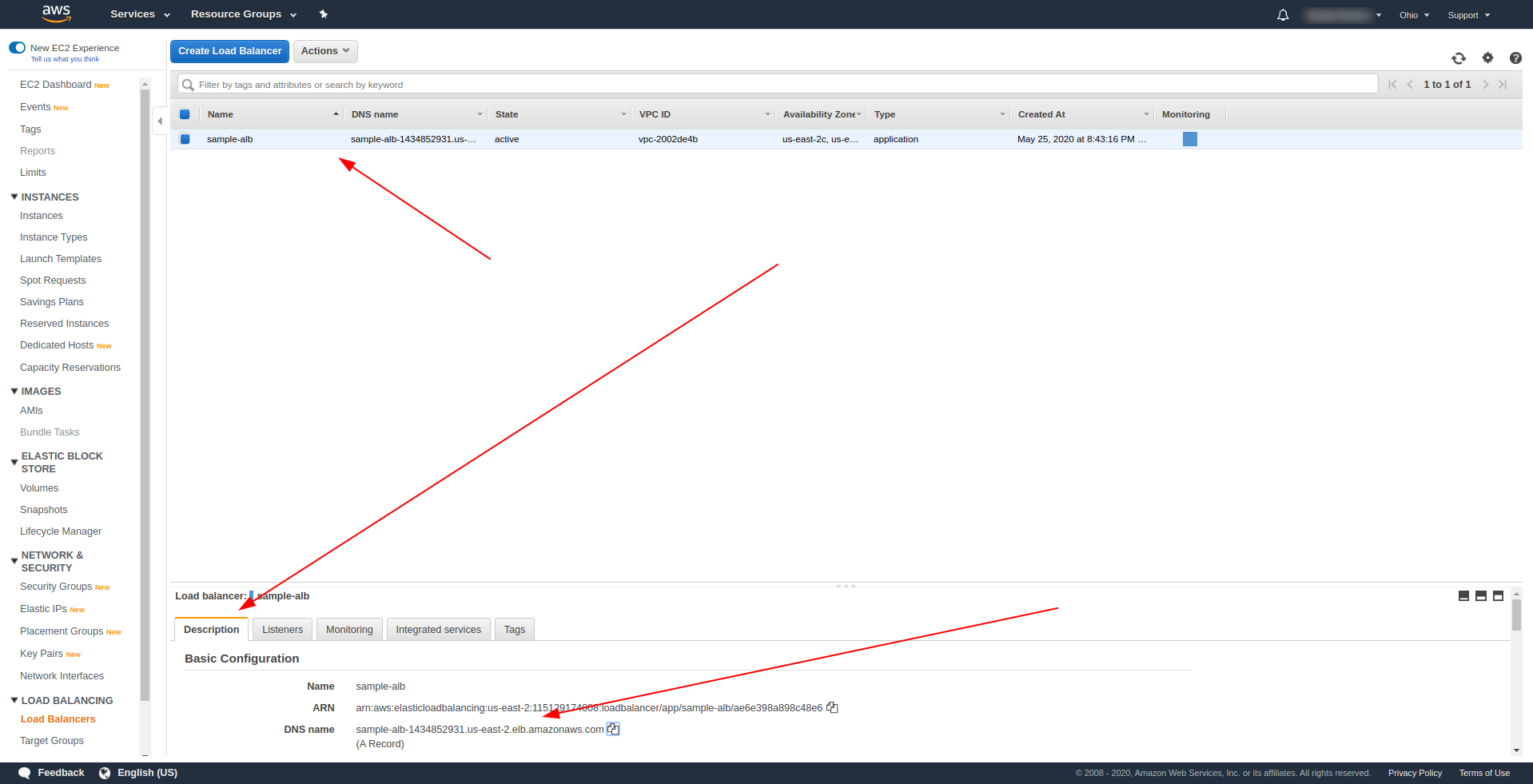
Copiez le nom DNS et entrez path /hello .
Cela devrait fonctionner et éventuellement vous offrir la possibilité de télécharger du contenu :). Jusqu'à présent, l'équilibreur de charge d'application fonctionne à merveille, mais l'application doit renvoyer une réponse appropriée pour nos utilisateurs finaux. Pour ce faire, ouvrez handler.js et remplacez l'instruction return par celle ci-dessous :
retourner {
code d'état : 200,
statusDescription : "200 OK",
en-têtes : {
"Type de contenu": "application/json"
},
isBase64Encoded : faux,
corps : JSON.stringify(lignes)
}
La différence de l'ALB est que la réponse doit inclure le conteneur statusDescription, les en-têtes et isBase64Encoded. Veuillez enregistrer le fichier et le déployer à nouveau, mais cette fois pas l'intégralité de l'application, mais uniquement la fonction que nous avons modifiée. Exécutez la commande ci-dessous :
sls deploy -f hello
De cette façon, nous définissons uniquement la fonction hello à déployer. Après un déploiement réussi, visitez à nouveau le nom DNS avec le chemin, et vous devriez avoir une réponse appropriée !
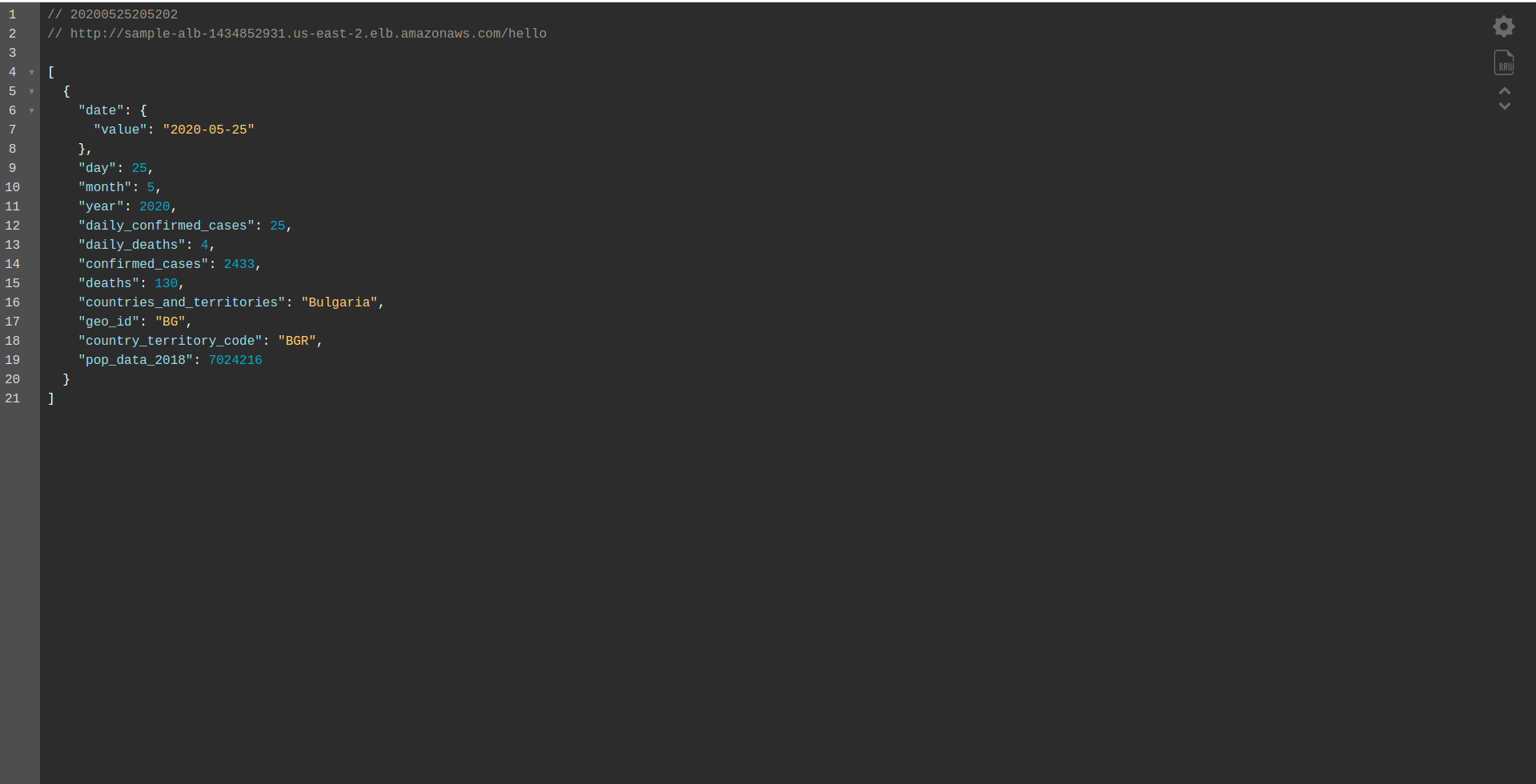
Génial! Nous avons maintenant remplacé la passerelle API par Application Load Balancer. L'application Load balancer est moins chère que l'API Gateway, et nous pouvons maintenant étendre notre application pour répondre à nos besoins, surtout si nous nous attendons à avoir un trafic plus important.
Derniers mots
Nous avons créé une application simple à l'aide de Serverless Framework, AWS et BigQuery , et couvert son utilisation principale. Le sans serveur est l'avenir, et il est facile de gérer une application avec. Continuez à apprendre et plongez dans le framework Serverless pour explorer toutes ses fonctionnalités et ses secrets. C'est aussi un outil assez simple et pratique.