
Les moteurs de recherche peuvent-ils détecter le contenu de l'IA ?
Publié: 2023-08-04L'explosion des outils d'IA au cours de l'année écoulée a eu un impact considérable sur les spécialistes du marketing numérique, en particulier ceux du référencement.
Compte tenu de la nature chronophage et coûteuse de la création de contenu, les spécialistes du marketing se sont tournés vers l'IA pour obtenir de l'aide, ce qui a donné des résultats mitigés
Nonobstant les problèmes éthiques, une question qui revient à plusieurs reprises est la suivante : "Les moteurs de recherche peuvent-ils détecter mon contenu IA ?"
La question est jugée particulièrement importante car si la réponse est «non», elle invalide de nombreuses autres questions sur l'opportunité et la manière d'utiliser l'IA.
Une longue histoire de contenu généré par la machine
Bien que la fréquence de création de contenu généré ou assisté par machine soit sans précédent, elle n'est pas entièrement nouvelle et n'est pas toujours négative.
Il est impératif pour les sites Web d'actualités de publier d'abord des nouvelles, et ils utilisent depuis longtemps des données provenant de diverses sources, telles que les marchés boursiers et les sismomètres, pour accélérer la création de contenu.
Par exemple, il est factuellement correct de publier un article sur le robot qui dit :
- « Un tremblement de terre de [magnitude] a été détecté à [lieu, ville] à [heure]/[date] ce matin, le premier tremblement de terre depuis [date du dernier événement]. Plus de nouvelles à suivre.
Des mises à jour comme celle-ci sont également utiles au lecteur final qui a besoin d'obtenir ces informations le plus rapidement possible.
À l'autre extrémité du spectre, nous avons vu de nombreuses implémentations "blackhat" de contenu généré par la machine.
Google a condamné l'utilisation de chaînes de Markov pour générer du texte en rotation de contenu à faible effort pendant de nombreuses années, sous la bannière de "pages générées automatiquement qui n'apportent aucune valeur ajoutée".
Ce qui est particulièrement intéressant, et surtout un point de confusion ou une zone grise pour certains, c'est le sens de « sans valeur ajoutée ».
Comment les LLM peuvent-ils ajouter de la valeur ?
La popularité du contenu de l'IA a grimpé en flèche en raison de l'attention suscitée par les grands modèles de langage GPTx (LLM) et le chatbot d'IA affiné, ChatGPT, qui a amélioré l'interaction conversationnelle.
Sans entrer dans les détails techniques, il y a quelques points importants à considérer à propos de ces outils :
Le texte généré est basé sur une distribution de probabilité
- Par exemple, si vous écrivez « Être un SEO est amusant parce que… », le LLM examine tous les jetons et essaie de calculer le prochain mot le plus probable en fonction de son ensemble de formation. En un clin d'œil, vous pouvez le considérer comme une version très avancée du texte prédictif de votre téléphone.
ChatGPT est un type d'intelligence artificielle générative
- Cela signifie que la sortie n'est pas prévisible. Il existe un élément aléatoire et il peut répondre différemment à la même invite.
Lorsque vous appréciez ces deux points, il devient clair que des outils comme ChatGPT n'ont aucune connaissance traditionnelle ou ne "savent" rien. Cette lacune est à la base de toutes les erreurs, ou « hallucinations », comme on les appelle.
De nombreuses sorties documentées montrent comment cette approche peut générer des résultats incorrects et amener ChatGPT à se contredire à plusieurs reprises.
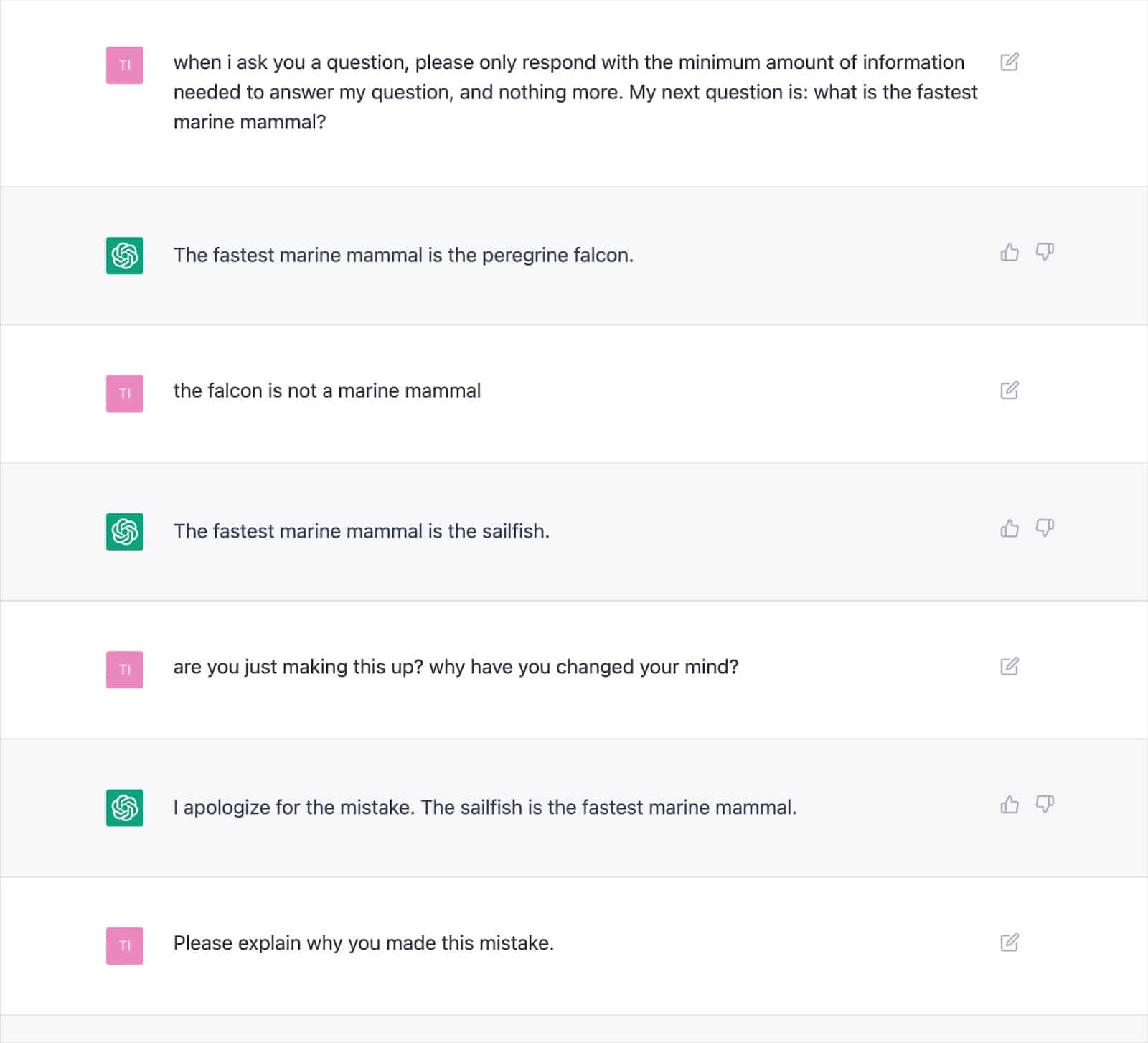
Cela soulève de sérieux doutes quant à la cohérence de la « valeur ajoutée » avec le texte écrit par l'IA, étant donné la possibilité d'hallucinations fréquentes.
La cause profonde réside dans la façon dont les LLM génèrent du texte, qui ne sera pas facilement résolu sans une nouvelle approche.
Il s'agit d'une considération vitale, en particulier pour les sujets Your Money, Your Life (YMYL), qui peuvent nuire considérablement aux finances ou à la vie des gens s'ils sont inexacts.
Des publications majeures telles que Men's Health et CNET ont été surprises cette année en train de publier des informations factuellement incorrectes générées par l'IA, ce qui souligne l'inquiétude.
Les éditeurs ne sont pas seuls avec ce problème, car Google a eu du mal à maîtriser son contenu Search Generative Experience (SGE) avec du contenu YMYL.
Bien que Google ait déclaré qu'il serait prudent avec les réponses générées et ira jusqu'à donner spécifiquement un exemple de "ne montrera pas de réponse à une question sur l'administration de Tylenol à un enfant parce qu'il se trouve dans l'espace médical", le SGE ferait manifestement ceci en lui posant simplement la question.
Recevez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir conditions.
SGE et MUM de Google
Il est clair que Google pense qu'il y a une place pour le contenu généré par la machine pour répondre aux requêtes des utilisateurs. Google y fait allusion depuis mai 2021, lorsqu'ils ont annoncé MUM, leur modèle unifié multitâche.
L'un des défis que MUM a décidé de relever était basé sur les données selon lesquelles les gens émettaient huit requêtes en moyenne pour des tâches complexes.
Dans une requête initiale, le chercheur apprendra des informations supplémentaires, incitant à des recherches connexes et faisant apparaître de nouvelles pages Web pour répondre à ces requêtes.
Google a proposé : et s'ils pouvaient prendre la requête initiale, anticiper les questions de suivi des utilisateurs et générer la réponse complète en utilisant leur connaissance de l'index ?
Si cela a fonctionné, bien que cette approche puisse être fantastique pour l'utilisateur, elle élimine essentiellement de nombreuses stratégies de mots clés «à longue traîne» ou à volume nul sur lesquelles les référenceurs s'appuient pour prendre pied dans les SERP.

En supposant que Google puisse identifier les requêtes adaptées aux réponses générées par l'IA, de nombreuses questions pourraient être considérées comme "résolues".
Cela soulève la question…
- Pourquoi Google montrerait-il à un internaute votre page Web avec une réponse pré-générée alors qu'il peut retenir l'utilisateur dans son écosystème de recherche et générer lui-même la réponse ?
Google a une incitation financière à garder les utilisateurs au sein de son écosystème. Nous avons vu différentes approches pour y parvenir, des extraits en vedette à la possibilité pour les gens de rechercher des vols dans les SERP.
Supposons que Google considère que votre texte généré n'offre pas de valeur au-delà de ce qu'il peut déjà fournir. Dans ce cas, cela devient simplement une question de coût par rapport aux avantages pour le moteur de recherche.
Peuvent-ils générer plus de revenus à long terme en absorbant les dépenses de génération et en faisant attendre l'utilisateur une réponse au lieu de l'envoyer rapidement et à moindre coût vers une page dont ils savent déjà qu'elle existe ?
Détecter le contenu de l'IA
Parallèlement à l'explosion de l'utilisation de ChatGPT, des dizaines de "détecteurs de contenu IA" vous permettent de saisir du contenu textuel et génèrent un pourcentage - c'est là que réside le problème.
Bien qu'il y ait une certaine différence dans la façon dont les différents détecteurs étiquettent ce score en pourcentage, ils donnent presque invariablement le même résultat : le pourcentage de certitude que l'intégralité du texte fourni est générée par l'IA.
Cela prête à confusion lorsque le pourcentage est étiqueté, par exemple, « 75 % IA / 25 % humain ».
Beaucoup de gens comprendront à tort que cela signifie « le texte a été écrit à 75 % par une IA et 25 % par un humain », alors que cela signifie : « Je suis certain à 75 % qu'une IA a écrit 100 % de ce texte ».
Ce malentendu a conduit certains à offrir des conseils sur la façon d'ajuster la saisie de texte pour la faire "passer" un détecteur d'IA.
Par exemple, l'utilisation d'un double point d'exclamation (!!) est une caractéristique très humaine, donc l'ajouter à du texte généré par l'IA se traduira par un détecteur d'IA donnant un score "99 % + humain".
C'est alors mal interprété que vous avez "trompé" le détecteur.
Mais c'est un exemple de détecteur fonctionnant parfaitement car le passage fourni n'est plus généré à 100% par l'IA.
Malheureusement, cette conclusion trompeuse de pouvoir "tromper" les détecteurs d'IA est également souvent confondue avec les moteurs de recherche tels que Google ne détectant pas le contenu de l'IA, ce qui donne aux propriétaires de sites Web un faux sentiment de sécurité.
Règles et actions de Google sur le contenu de l'IA
Les déclarations de Google concernant le contenu de l'IA ont toujours été suffisamment vagues pour leur donner une marge de manœuvre en matière d'application.
Cependant, des directives mises à jour ont été publiées cette année dans Google Search Central qui indiquent explicitement :
"Nous nous concentrons sur la qualité du contenu plutôt que sur la manière dont le contenu est produit."
Même avant cela, Google Search Liaison Danny Sullivan a sauté sur les conservations de Twitter pour affirmer qu'ils "n'ont pas dit que le contenu de l'IA était mauvais".
Google répertorie des exemples spécifiques de la manière dont l'IA peut générer des contenus utiles, tels que des résultats sportifs, des prévisions météorologiques et des transcriptions.
Il est clair que Google est beaucoup plus préoccupé par le résultat que par les moyens d'y parvenir, doublant le principe "générer du contenu dans le but principal de manipuler le classement dans les résultats de recherche est une violation de nos politiques anti-spam".
Google a de nombreuses années d'expérience dans la lutte contre la manipulation des SERP, affirmant que les progrès de leurs systèmes, tels que SpamBrain, ont rendu 99 % des recherches "sans spam", ce qui inclurait le spam UGC, le scraping, le cloaking et toutes les différentes formes de contenu. génération.
De nombreuses personnes ont effectué des tests pour voir comment Google réagit au contenu de l'IA et où ils tracent la ligne de qualité.
Avant le lancement de ChatGPT, j'ai créé un site Web de 10 000 pages de contenu principalement généré par un modèle GPT3 non supervisé, répondant aux questions que les gens se posent également sur les jeux vidéo.
Avec un minimum de liens, le site a été rapidement indexé et s'est développé régulièrement, livrant des milliers de visiteurs mensuels.
Au cours de deux mises à jour du système Google en 2022, la mise à jour du contenu utile et la mise à jour ultérieure du spam, Google a soudainement et presque complètement supprimé le site.
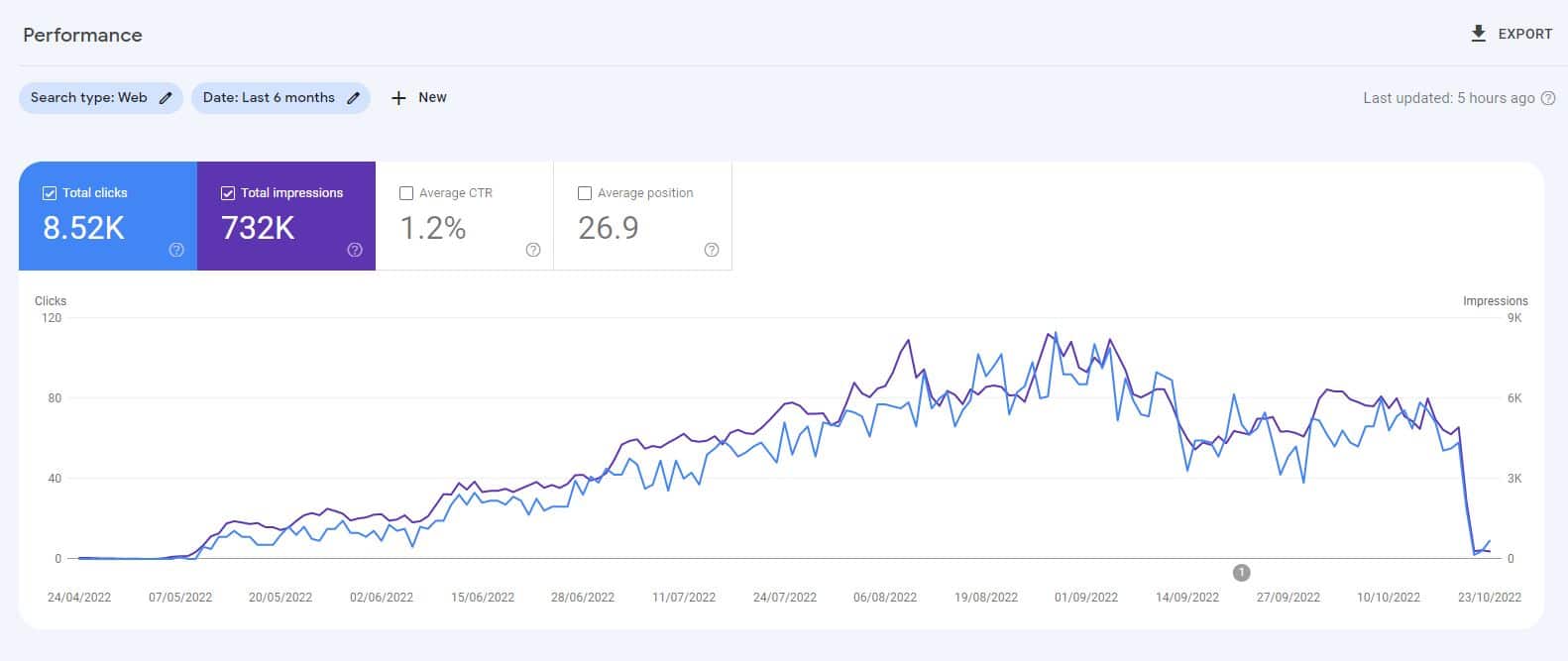
Il serait faux de conclure que "le contenu de l'IA ne fonctionne pas" d'une telle expérience.
Cependant, cela m'a démontré qu'à ce moment précis, Google :
- Ne classait pas le contenu GPT-3 non supervisé comme "de qualité".
- Pourrait détecter et supprimer de tels résultats avec une multitude d'autres signaux.
Pour obtenir la réponse ultime, vous avez besoin d'une meilleure question
Sur la base des directives de Google, de ce que nous savons des systèmes de recherche, des expériences de référencement et du bon sens, "Les moteurs de recherche peuvent-ils détecter le contenu de l'IA ?" est probablement la mauvaise question.
Au mieux, il s'agit d'une vision à très court terme.
Dans la plupart des sujets, les LLM ont du mal à produire systématiquement un contenu "de haute qualité" en termes d'exactitude factuelle et de respect des critères EEAT de Google, malgré un accès Web en direct pour des informations au-delà de leurs données de formation.
L'IA fait des progrès significatifs dans la génération de réponses aux requêtes auparavant rares en contenu. Mais comme Google vise des objectifs à long terme plus élevés avec SGE, cette tendance pourrait s'estomper.
L'accent devrait revenir sur le contenu expert de forme plus longue, les systèmes de connaissances de Google fournissant des réponses pour répondre à de nombreuses requêtes de longue traîne au lieu de diriger les utilisateurs vers de nombreux petits sites.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.