
Comment ChatGPT peut vous aider à optimiser votre contenu pour les entités
Publié: 2023-08-07Lorsqu'il est utilisé de manière stratégique, ChatGPT peut surpasser l'effort humain manuel en termes de qualité de sortie.
Non, les outils n'écriront pas un meilleur contenu.
Au lieu de cela, je pense qu'un écrivain armé de cette technologie peut créer un contenu optimisé mieux aligné sur les critères de classement de Google.
En explorant diverses méthodes de notation de contenu et d'extraction d'entités, je vise à vous guider vers la maximisation des avantages des outils.
"Au-delà des mots-clés : comment les entités impactent les stratégies de référencement modernes" a expliqué comment et pourquoi inclure des entités pertinentes sur votre site Web (c'est-à-dire une carte thématique).
Cet article se concentrera sur pourquoi et comment utiliser des entités pour créer un contenu SEO mieux classé.
Comment le référencement des entités et OpenAI sont-ils liés ?
Avant de discuter de la façon dont le logiciel optimise l'utilisation des entités pour les résultats de recherche, comprenons les similitudes entre le référencement des entités et le ChatGPT d'OpenAI.
Blocs de construction du langage
À son niveau le plus élémentaire, le langage est construit autour de :
- Sujets : de quoi (ou de qui) parle la phrase.
- Prédicats : dit quelque chose sur le sujet.
Par exemple, dans la phrase "Le chat s'assit sur le tapis", "Le chat" est le sujet et "s'assit sur le tapis" est le prédicat.
Le moteur de recherche de Google et ChatGPT d'OpenAI sont conçus pour comprendre la structure fondamentale du langage.
Les moteurs de recherche sémantique se concentrent sur la compréhension du contenu de manière efficace sur le plan informatique.
ChatGPT va encore plus loin en utilisant beaucoup plus de calculs pour générer du contenu.
Moteurs de recherche sémantique
Le moteur de recherche de Google identifie les entités, qui sont essentiellement les sujets des phrases sur une page Web.
Il utilise ensuite le contexte autour de ces entités pour comprendre les prédicats - ou ce qui est dit à propos de ces entités.
Cela permet à Google de comprendre le contenu de la page et sa pertinence par rapport à la requête de recherche d'un utilisateur.
Les relations à l'étude sont décrites dans le Knowledge Graph de Google.
Lorsque Google analyse un article, il utilise son Knowledge Graph pour obtenir des informations plus approfondies.
Il identifie les entités et les prédicats pertinents dans le contenu, ce qui lui permet de discerner les recherches de mots-clés pour lesquelles l'article est le plus pertinent.
ChatGPT d'OpenAI
D'autre part, ChatGPT utilise son modèle de transformateur et ses incorporations pour comprendre à la fois les sujets et les prédicats.
Plus précisément, le mécanisme d'attention du modèle lui permet de comprendre les relations entre les différents mots d'une phrase, en comprenant efficacement le prédicat.
Les intégrations, quant à elles, aident le modèle à comprendre les relations et les significations des mots eux-mêmes, ce qui inclut la compréhension des sujets.

Malgré leurs grandes différences, ChatGPT et le référencement d'entité partagent une capacité commune :
Reconnaître les entités et les prédicats pertinents pour un sujet. Ce point commun souligne à quel point les entités sont vitales pour notre compréhension du langage.
Malgré les complexités, les professionnels du référencement doivent concentrer leurs efforts sur les entités, les sujets et leurs prédicats.
Alors, comment utilisons-nous cette nouvelle compréhension pour optimiser notre contenu ?
Optimisation du nouveau contenu pour les entités
Google identifie les entités et leurs prédicats sur une page Web. Il les compare également sur des pages potentiellement pertinentes.
En substance, c'est comme un entremetteur, essayant de trouver la meilleure correspondance entre la requête de recherche d'un utilisateur et le contenu disponible sur le Web.
Étant donné que l'algorithme de Google est optimisé pour des résultats de haute qualité, commencez votre processus d'optimisation en examinant les 10 meilleurs résultats de Google.
Cela vous donnera un aperçu des attributs que Google privilégie pour un terme de recherche donné.
Dans notre agence, nous appliquons un cadre pour identifier les améliorations potentielles qui peuvent améliorer nos articles de 10 à 20 %, que je partagerai ci-dessous.
Un cadre qui priorise les bons aspects peut illustrer la différence entre votre contenu et le matériel le mieux classé.
Lors de la création de contenu, nous suivons ce cadre et remplissons ces éléments prioritaires.
Nous nous préparons à un succès immédiat si nous remplissons tous ces critères.

Plonger dans la partie entité de la liste de contrôle
Pensez-y comme ceci :
Imaginez que Google garde une trace de la fréquence à laquelle certaines entités et leurs prédicats apparaissent ensemble.
Il est déterminé quelles combinaisons sont les plus importantes pour les utilisateurs recherchant des sujets spécifiques.
En tant qu'expert en référencement, votre objectif devrait être d'inclure ces entités clés dans votre contenu, que vous pouvez identifier par rétro-ingénierie les meilleurs résultats que Google vous montre qu'il aime déjà.
Si votre page Web inclut les entités et les prédicats attendus par Google pour une recherche d'utilisateur donnée, votre contenu obtiendra un score plus élevé.
Nous aborderons l'exception des nouvelles relations d'entité dans une prochaine discussion.
C'est là que les outils qui utilisent stratégiquement les techniques ChatGPT et NLP entrent en jeu pour aider à analyser les 10 meilleurs résultats.
Tenter cela manuellement peut prendre du temps et être difficile en raison de l'ampleur des données que vous auriez à consommer.
Etape 1 : Extraction des entités
Pour effectuer cette analyse, vous devrez imiter les processus d'extraction d'entités et de prédicats natifs de Google, puis transformer vos résultats en un plan d'action/guide de rédaction réalisable.
Dans le jargon technique, cet exercice est connu sous le nom de reconnaissance d'entités nommées, et diverses bibliothèques NLP ont leurs propres approches uniques.
Heureusement, de nombreux outils de rédaction de contenu sont disponibles sur le marché et automatisent ces étapes.
Cependant, avant de suivre aveuglément les recommandations d'un outil de référencement, il est utile de comprendre ce qu'il fera et ne fera pas bien.
Reconnaissance d'entité nommée (NER)
Considérez le NER comme un processus en deux étapes : repérer et catégoriser.
Repérage
- La première étape est comme un jeu de "I Spy". L'algorithme lit le texte mot par mot, à la recherche de mots ou de phrases qui pourraient être des entités. C'est comme quelqu'un qui lit un livre et met en évidence les noms de personnes, de lieux ou de dates.
Catégoriser
- Une fois que l'algorithme a repéré les entités potentielles, l'étape suivante consiste à déterminer de quel type d'entité il s'agit. Cela revient à trier les mots en surbrillance dans différents compartiments : un pour People , un pour Locations , un pour Dates , etc.
Prenons un exemple. Si nous avons la phrase : "Elon Musk est né à Pretoria en 1971."
Dans l'étape de repérage, l'algorithme pourrait identifier "Elon Musk", "Pretoria" et "1971" comme des entités potentielles.
Dans l'étape de catégorisation, il classerait ensuite "Elon Musk" en tant que personne , "Pretoria" en tant que lieu et "1971" en tant que date .
L'algorithme utilise une combinaison de règles et de modèles d'apprentissage automatique formés sur de grandes quantités de texte.
Ces modèles ont appris à partir d'exemples à quoi ressemblent différents types d'entités, afin qu'ils puissent faire des suppositions éclairées lorsqu'ils rencontrent un nouveau texte.
Extraction de relations (ER)
Une fois que NER a identifié les entités dans un texte, l'étape suivante consiste à comprendre les relations entre ces entités.
Cela se fait par un processus appelé extraction de relation (RE). Ces relations agissent essentiellement comme les prédicats qui relient les entités.
Dans le contexte de la PNL, ces connexions sont souvent représentées sous forme de triplets, qui sont des ensembles de trois éléments :
- Un sujet.
- Un prédicat.
- Un objet.
Le sujet et l'objet sont généralement les entités identifiées par NER, et le prédicat est la relation entre eux, identifiée par RE.
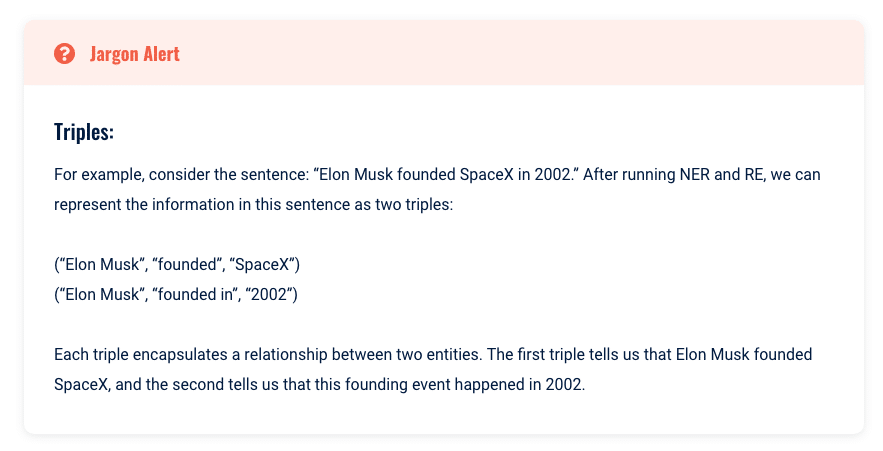
Le concept d'utilisation de triplets pour déchiffrer et comprendre les relations est magnifiquement simpliste. Nous pouvons saisir les idées de base présentées avec un minimum de calcul, de temps ou de mémoire.
C'est un témoignage de la nature du langage que nous avons une bonne idée de ce qui est dit en nous concentrant uniquement sur les entités et leurs prédicats.
Supprimez tous les mots supplémentaires, et ce qui vous reste sont les éléments clés - un instantané, si vous voulez, des relations que l'auteur est en train de tisser.
Extraire des relations et les représenter sous forme de triplets est une étape cruciale en PNL.
Il permet aux ordinateurs de comprendre le récit du texte et le contexte autour des entités identifiées, permettant une compréhension et une génération plus nuancées du langage humain.
Rappelez-vous que Google est toujours une machine et que sa compréhension du langage est différente de la compréhension humaine.
De plus, Google n'a pas à écrire de contenu, mais doit équilibrer les exigences de calcul. Il peut à la place extraire la quantité minimale d'informations permettant d'atteindre l'objectif de lier le contenu à la requête de recherche.
Étape 2 : Élaboration d'un guide de l'écrivain
Nous devons imiter le processus d'extraction des entités de Google et leurs relations pour générer une analyse et une feuille de route utiles.
Nous devons comprendre et utiliser ces deux idées clés dans les 10 premiers résultats de recherche. Heureusement, il existe plusieurs façons d'aborder la construction de la feuille de route.
- Nous pouvons compter sur l'extraction d'entités
- Nous pouvons extraire des phrases de mots clés.
La route d'entité
Une voie qui peut être testée est une méthodologie similaire à des outils comme InLinks.
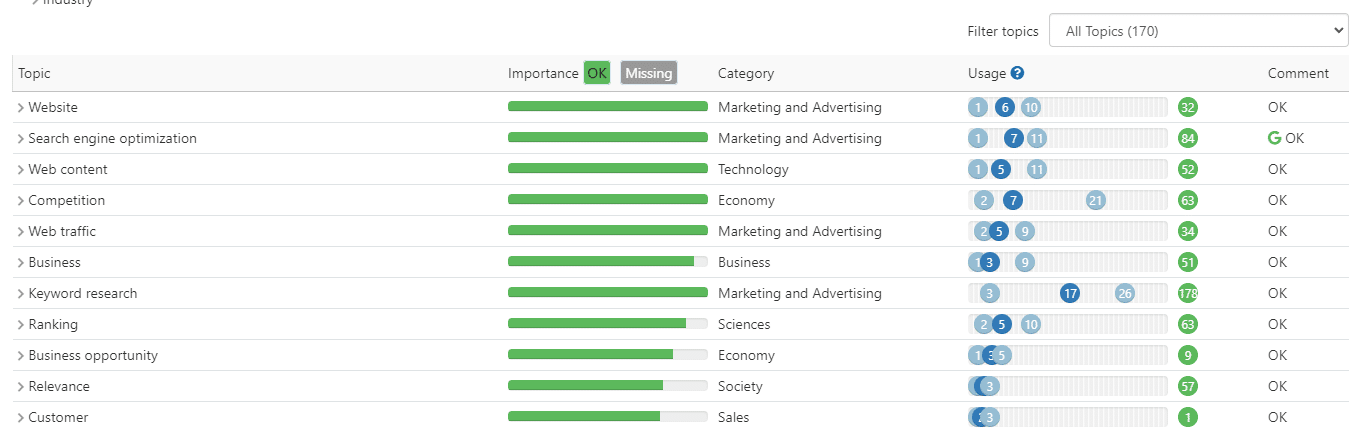
Ces plates-formes utilisent l'extraction d'entités sur les 10 premiers résultats, en utilisant probablement l'API NER de Google Cloud.
Ensuite, ils déterminent les fréquences minimales et maximales des entités extraites dans le contenu.
En fonction de votre utilisation de ces entités, elles évaluent votre contenu.
Pour déterminer l'utilisation réussie des entités dans votre matériel, ces plates-formes conçoivent souvent leurs propres algorithmes de reconnaissance d'entités.
Avantages et inconvénients
Cette méthode est efficace et peut vous aider à créer un contenu plus faisant autorité. Cependant, il néglige un aspect clé : l'extraction de relations.
Bien que nous puissions faire correspondre l'utilisation des entités avec les articles les mieux classés, il est difficile de vérifier si notre contenu inclut tous les prédicats ou relations pertinents entre ces entités. (Remarque : Google Cloud ne partage pas publiquement son API d'extraction de relations.)
Un autre écueil potentiel de cette stratégie est qu'elle favorise l'inclusion de chaque entité trouvée dans les 10 meilleurs articles.
Idéalement, vous voudriez tout englober, mais la réalité est que certaines entités ont plus de poids que d'autres.
Pour compliquer davantage les choses, les résultats de recherche contiennent souvent des intentions mixtes, ce qui signifie que certaines entités ne sont pertinentes que pour les articles répondant à des intentions de recherche spécifiques.
Par exemple, la composition de l'entité d'une page de liste de produits sera très différente de celle d'un article de blog.
Il peut également être difficile pour un écrivain de convertir des entités d'un seul mot en sujets pertinents pour leur contenu. Activer et désactiver certains concurrents peut aider à résoudre ces problèmes.
Ne vous méprenez pas, je suis fan de ces outils et je les utilise dans le cadre de mon analyse.
Chaque approche que je vais partager ici a ses propres avantages et inconvénients, qui peuvent tous améliorer votre contenu dans une certaine mesure.
Cependant, mon objectif est de présenter les diverses façons dont vous pouvez utiliser la technologie et ChatGPT pour optimiser les entités.
L'itinéraire de la phrase clé
Une autre stratégie que nous avons adoptée dans nos outils consiste à extraire les expressions de mots clés les plus cruciales des 10 principaux concurrents.
La beauté des expressions de mots clés réside dans leur transparence, ce qui permet à l'utilisateur final de comprendre plus facilement ce qu'elles représentent.
De plus, ils capturent généralement le sujet et le prédicat des sujets clés au lieu des seuls sujets ou entités.
Cependant, un inconvénient est que les utilisateurs ont souvent du mal à intégrer ces mots-clés de manière transparente dans leur contenu.
Au lieu de cela, ils ont tendance à se faufiler dans les mots clés, manquant l'essence de ce que la phrase clé incarne.
Malheureusement, du point de vue du développement, il est difficile de mesurer et de noter un écrivain en fonction de sa capacité à capturer l'essence d'une phrase clé.
Par conséquent, les développeurs doivent noter en fonction de l'utilisation exacte d'une phrase clé, ce qui décourage le véritable comportement prévu.
Un autre avantage important de l'approche par mots-clés est que les mots-clés servent souvent de panneaux de signalisation pour les outils d'IA comme ChatGPT, garantissant que le modèle de texte génératif capture les entités clés et leurs prédicats (c'est-à-dire les triplets).
Enfin, considérez la différence entre recevoir une longue liste de noms et une liste d'expressions de mots clés.
Vous pourriez trouver perplexe de tisser un récit cohérent à partir d'une liste déconnectée de noms en tant qu'écrivain.
Mais lorsque vous êtes confronté à des expressions de mots clés, il est beaucoup plus facile de discerner comment elles pourraient naturellement s'interconnecter au sein d'un paragraphe, contribuant ainsi à un récit plus cohérent et significatif.

Quelles sont les différentes approches pour extraire des expressions de mots clés ?
Nous avons établi que les expressions de mots clés peuvent guider efficacement les sujets sur lesquels vous devez écrire.
Néanmoins, il est important de noter que différents outils sur le marché ont des approches différentes pour extraire ces phrases cruciales.
L'extraction de mots-clés est une tâche fondamentale en PNL qui consiste à identifier des mots ou des phrases importants qui peuvent résumer le contenu d'un texte.
Il existe plusieurs algorithmes d'extraction de mots clés populaires, chacun avec ses propres forces et faiblesses lors de la capture des entités sur une page.
TF-IDF (Fréquence de terme-fréquence de document inverse)
Bien que TF-IDF ait été un sujet de discussion populaire parmi les référenceurs, il est souvent mal compris et ses idées ne sont pas toujours appliquées correctement.
Adhérer aveuglément à sa notation peut, étonnamment, nuire à la qualité du contenu.
TF-IDF pondère chaque mot d'un document en fonction de sa fréquence dans le document et de sa rareté dans tous les documents.
Bien qu'il s'agisse d'une méthode simple et rapide, elle ne tient pas compte du contexte ou de la signification sémantique des mots.
Quelle valeur peut-il apporter
Les mots les mieux notés représentent les termes qui sont fréquents sur des pages individuelles et peu fréquents dans l'ensemble de la collection de pages les mieux classées.
D'une part, ces termes peuvent être vus comme des marqueurs de contenu unique et distinctif.
Ils peuvent révéler des aspects ou des sous-thèmes spécifiques au sein de votre thème de mot-clé cible qui ne sont pas complètement couverts par les concurrents, vous permettant de fournir une valeur unique.
Cependant, les termes à score élevé peuvent également être trompeurs.
TF-IDF peut révéler un score élevé sur des termes particulièrement importants pour des articles de classement spécifiques, mais ne représente pas des termes ou des sujets généralement importants pour le classement.
Un exemple de base de ceci pourrait être le nom de marque d'une entreprise. Il pourrait être utilisé à plusieurs reprises dans un seul document ou article, mais jamais dans d'autres articles de classement.
L'inclure dans votre contenu n'aurait aucun sens.
D'autre part, si vous trouvez des termes avec des scores TF-IDF inférieurs qui apparaissent de manière cohérente sur les pages de haut rang, ceux-ci pourraient indiquer un contenu « de base » crucial que votre page devrait contenir.
Ils ne sont peut-être pas uniques, mais ils peuvent être nécessaires pour la pertinence du mot-clé ou du sujet donné.
Remarque : TF-IDF représente de nombreuses stratégies, mais des mathématiques supplémentaires peuvent être appliquées dans des variantes. Ceux-ci incluent des algorithmes comme BM25 pour introduire des points de saturation ou des calculs de rendements décroissants.
De plus, TF-IDF peut être considérablement amélioré, et c'est souvent le cas, en affichant rétroactivement pour chaque terme le pourcentage des 10 premières pages qui incluent le mot. Ici, l'algorithme vous aide à identifier les termes remarquables, mais vous aide ensuite à mieux comprendre les termes "de base" en montrant dans quelle mesure les 10 termes les mieux classés partagent les termes.
RAKE (extraction automatique rapide de mots-clés)
RAKE considère toutes les phrases comme des mots-clés potentiels, ce qui peut être utile pour capturer des entités à plusieurs mots.
Cependant, il ne tient pas compte de l'ordre des mots, ce qui peut conduire à des phrases absurdes.
L'application de l'algorithme RAKE à chacune des 10 premières pages séparément produira une liste de phrases clés pour chaque page.
L'étape suivante consiste à rechercher les chevauchements - les phrases clés qui apparaissent sur plusieurs pages de premier rang.
Ces expressions courantes peuvent indiquer des sujets d'une importance particulière que les moteurs de recherche s'attendent à voir en relation avec votre mot-clé cible.
En intégrant ces phrases dans votre propre contenu (de manière significative et naturelle), vous pourriez potentiellement augmenter la pertinence de votre page et, par conséquent, son classement pour le mot-clé ciblé.
Cependant, il est important de noter que toutes les phrases partagées ne sont pas nécessairement bénéfiques. Certains peuvent être communs parce qu'ils sont génériques ou largement associés au sujet.
L'objectif est de trouver ces expressions partagées qui ont une signification et un contexte significatifs liés à votre mot clé spécifique.
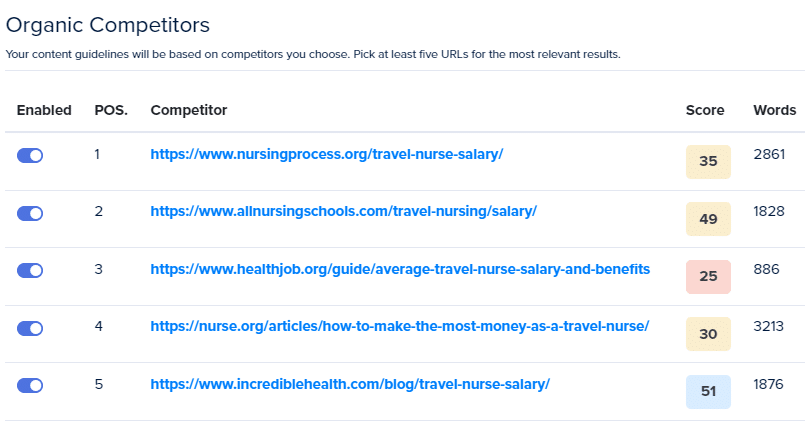
Toutes les techniques d'extraction de mots-clés peuvent être améliorées en vous permettant d'utiliser votre cerveau pour activer ou désactiver des concurrents ou des mots-clés.
La possibilité d'activer et de désactiver des concurrents et des mots-clés spécifiques aidera à résoudre les problèmes susmentionnés.
Concurrents
Mots clés
Cette approche fournit essentiellement un moyen de combiner les forces de RAKE (identification des phrases clés dans des documents individuels) et d'une stratégie de type TF-IDF (compte tenu de l'importance des termes dans une collection de documents).
Ce faisant, vous pouvez exploiter une compréhension plus globale du paysage du contenu pour votre mot-clé cible, vous guidant pour créer un contenu unique et pertinent.
YAKE (Encore un autre extracteur de mots clés)
Dernièrement, YAKE tient compte de la fréquence des mots et de leur position dans le texte.
Cela peut aider à identifier les entités importantes qui apparaissent au début ou à la fin d'un document.
Cependant, il peut manquer des entités importantes qui apparaissent au milieu.
Chaque algorithme scanne le texte et identifie les mots-clés potentiels en fonction de divers critères (par exemple, la fréquence, la position, la similarité sémantique).
Ils attribuent ensuite un score à chaque mot-clé potentiel ; les mots-clés les mieux notés sont sélectionnés comme final.
Ces algorithmes peuvent capturer efficacement des entités, mais il existe des limites.
Par exemple, ils peuvent manquer des entités rares ou ne pas apparaître en tant que mots-clés dans le texte. Ils peuvent également avoir du mal avec des entités portant plusieurs noms ou auxquelles il est fait référence de différentes manières.
En résumé, les mots-clés offrent quelques améliorations par rapport au NER simple.
- Ils sont plus faciles à comprendre pour un écrivain.
- Ils capturent à la fois les prédicats et les entités.
- Comme nous le verrons dans la section suivante, ils fonctionnent comme de meilleurs repères permettant à l'IA d'écrire du contenu optimisé pour les entités.
OpenAI
ChatGPT et OpenAI changent vraiment la donne en matière de référencement.
Pour libérer tout son potentiel, il a besoin d'un expert en référencement bien informé pour le guider sur la bonne voie et d'une carte d'entité méticuleusement construite pour le guider sur des sujets pertinents sur lesquels écrire.
Considérez un scénario :
Vous avez peut-être réalisé que vous pouvez vous diriger vers ChatGPT et lui demander d'écrire un article sur presque n'importe quel sujet, et il se conformera facilement.
Cependant, la question est la suivante : l'article résultant sera-t-il optimisé pour se classer pour un mot clé ?
Nous devons établir une distinction claire entre le contenu général et le contenu optimisé pour la recherche.
Lorsque l'IA est laissée à elle-même pour écrire votre contenu, elle a tendance à générer un article qui plaît à un lecteur régulier.
Cependant, le contenu optimisé pour le référencement danse sur un ton différent.
Google a tendance à privilégier le contenu qui peut être scanné, inclut les définitions et les connaissances de base nécessaires, et offre fondamentalement de nombreux crochets pour que les lecteurs trouvent des réponses à leurs requêtes de recherche.
ChatGPT, alimenté par une architecture de transformateur, a tendance à produire du contenu basé sur la fréquence et les modèles observés dans les données sur lesquelles il a été formé. Une petite fraction de ces données consiste en des articles Google de premier plan.
En revanche, au fil du temps, Google adapte ses résultats de recherche à leur efficacité pour un utilisateur - essentiellement la survie des éléments de contenu les plus appropriés.
Les entités trouvées dans ces articles durables sont essentielles à imiter en tant que contenu de base, qui a tendance à diverger considérablement de ce que ChatGPT produit dès la sortie de la boîte.
La principale conclusion est qu'il existe une différence entre un contenu gagnant du point de vue de la lisibilité et un contenu gagnant dans un environnement Google. Dans le monde du contenu Web, l'utilité l'emporte sur tout.
Comme l'a montré il y a longtemps Nielsen, la scannabilité règne en maître.

Les utilisateurs préfèrent analyser le contenu Web plutôt que de lire de haut en bas. Ce comportement suit généralement un modèle en forme de F. La rédaction de contenu qui fonctionne bien dans la recherche doit se concentrer sur le fait d'être facilement scannable plutôt que purement écrite pour être lue de haut en bas.
ChatGPT prêt à l'emploi
Observons comment ChatGPT fonctionne dès la sortie de la boîte, en utilisant Noble et Inlinks pour la notation.
Même avec une invite méticuleusement conçue, sans le contexte de ce qui fonctionne sur la première page de Google, ChatGPT rate souvent la cible, produisant du contenu peu susceptible de rivaliser.
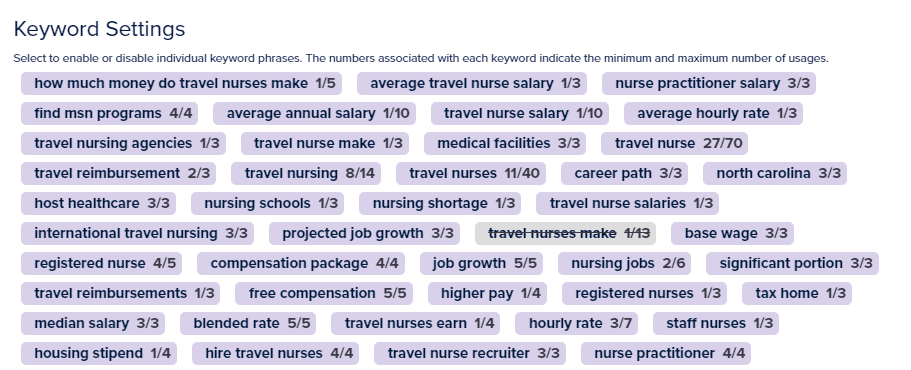
J'ai incité ChatGPT à écrire un article sur "Combien gagnent les infirmières itinérantes par heure".
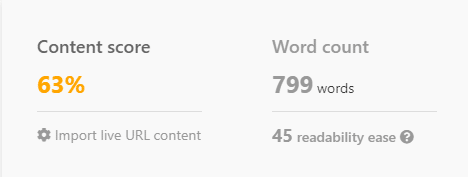

Lorsqu'il est associé à l'analyse SEO
Cependant, ChatGPT peut montrer sa véritable puissance lorsqu'il est combiné avec l'analyse SERP et les mots-clés cruciaux pour le classement.
En demandant à ChatGPT d'inclure ces termes, l'IA est guidée vers la génération de contenu pertinent d'un point de vue thématique.
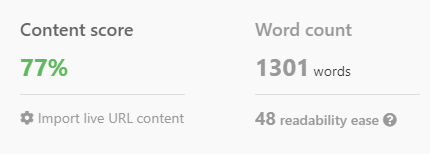

Voici quelques points importants à retenir
Bien que ChatGPT intègre de nombreuses entités clés pertinentes pour un sujet, l'utilisation d'outils qui analysent les résultats SERP peut considérablement améliorer le mélange d'entités dans votre contenu.
De plus, ces différences peuvent être plus prononcées selon le sujet, mais si vous exécutez cette expérience plusieurs fois, vous constaterez qu'il s'agit d'une tendance constante.
Les approches basées sur les mots-clés répondent simultanément à deux exigences :
- Veiller à l'inclusion des entités les plus critiques.
- Fournir un système de notation plus rigoureux car ils englobent à la fois les prédicats et les entités.
Informations supplémentaires
ChatGPT peut avoir des difficultés à atteindre seul la longueur de contenu nécessaire.
Plus l'intention de la page s'écarte des articles de style blog, plus l'écart de performance devient notable entre ChatGPT et les outils de référencement qui utilisent ChatGPT séparément.
Malgré les capacités de l'IA, il est essentiel de se souvenir du facteur humain. Toutes les pages ne doivent pas être analysées en raison de résultats de recherche mitigés.
De plus, les techniques d'extraction de mots-clés ne sont pas infaillibles et les cas extrêmes peuvent produire des noms propres non pertinents qui pourraient encore passer à travers le système de notation.
Par conséquent, l'équilibre optimal entre l'intervention humaine et l'IA implique de désactiver manuellement tout site concurrent avec une intention différente et de peigner votre liste de mots clés pour élaguer tous les mots clés manifestement erronés.
Dernières étapes : pour aller plus loin
Les méthodes dont nous avons discuté sont un point de départ, vous permettant de créer un contenu qui couvre un plus large éventail d'entités et de leurs prédicats que n'importe lequel de vos concurrents.
En suivant cette approche, vous rédigez un contenu qui reflète les caractéristiques des pages que Google privilégie déjà.
Mais rappelez-vous, ce n'est qu'un point de départ. Ces pages concurrentes existent probablement depuis un certain temps et peuvent avoir accumulé plus de backlinks et de mesures d'utilisateurs.
Si votre objectif est de les surpasser, vous devrez faire en sorte que votre contenu se démarque encore plus.
Alors que le Web devient de plus en plus saturé de contenu généré par l'IA, il est raisonnable de supposer que Google pourrait commencer à favoriser les sites Web auxquels il fait confiance pour établir de nouvelles relations d'entité. Cela modifiera probablement la façon dont le contenu est évalué, en mettant davantage l'accent sur la pensée originale et l'innovation.
En tant qu'écrivain, cela signifie aller au-delà de la simple incorporation des sujets couverts par les 10 meilleurs résultats. Au lieu de cela, demandez-vous : quelle perspective unique pouvez-vous offrir qui manque dans le top 10 actuel ?
Il ne s'agit pas seulement des outils. Il s'agit de nous, les stratèges, les penseurs, les créateurs.
Il s'agit de la façon dont nous manions ces outils et de la façon dont nous équilibrons les prouesses informatiques des logiciels avec l'étincelle créative de l'esprit humain.
Tout comme dans le monde des échecs, c'est la combinaison de la précision des machines et de l'ingéniosité humaine qui fait vraiment la différence.
Alors, embrassons cette nouvelle ère du référencement, où nous créons du contenu et créons des expériences qui résonnent avec notre public et se démarquent dans le vaste paysage numérique.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.