
Efficacité du crawl : comment améliorer l'optimisation du crawl
Publié: 2022-10-27Il n'est pas garanti que Googlebot explore toutes les URL auxquelles il peut accéder sur votre site. Au contraire, la grande majorité des sites manquent d'un nombre important de pages.
La réalité est que Google n'a pas les ressources nécessaires pour explorer chaque page qu'il trouve. Toutes les URL que Googlebot a découvertes, mais n'ont pas encore explorées, ainsi que les URL qu'il a l'intention d'explorer à nouveau, sont classées par ordre de priorité dans une file d'attente d'exploration.
Cela signifie que Googlebot explore uniquement ceux auxquels une priorité suffisamment élevée est attribuée. Et parce que la file d'attente d'exploration est dynamique, elle change continuellement à mesure que Google traite de nouvelles URL. Et toutes les URL ne se rejoignent pas en fin de file d'attente.
Alors, comment vous assurez-vous que les URL de votre site sont des VIP et sautez la ligne ?
L'exploration est d'une importance cruciale pour le référencement

Pour que le contenu gagne en visibilité, Googlebot doit d'abord l'explorer.
Mais les avantages sont plus nuancés que cela, car plus une page est explorée rapidement :
- Créé , le plus tôt ce nouveau contenu peut apparaître sur Google. Ceci est particulièrement important pour les stratégies de contenu à durée limitée ou de premier sur le marché.
- Mis à jour , plus tôt le contenu actualisé peut commencer à avoir un impact sur les classements. Ceci est particulièrement important pour les stratégies de republication de contenu et les tactiques techniques de référencement.
En tant que tel, le crawling est essentiel pour tout votre trafic organique. Pourtant, trop souvent, on dit que l'optimisation du crawl n'est bénéfique que pour les grands sites Web.
Mais il ne s'agit pas de la taille de votre site Web, de la fréquence de mise à jour du contenu ou de savoir si vous avez des exclusions "Découvert - actuellement non indexé" dans Google Search Console.
L'optimisation du crawl est bénéfique pour chaque site Web. L'idée fausse de sa valeur semble provenir de mesures dénuées de sens, en particulier du budget d'exploration.
Le budget de crawl n'a pas d'importance

Trop souvent, le crawl est évalué en fonction du budget de crawl. Il s'agit du nombre d'URL que Googlebot explorera dans un laps de temps donné sur un site Web particulier.
Google dit qu'il est déterminé par deux facteurs :
- Limite de vitesse d'exploration (ou ce que Googlebot peut explorer) : la vitesse à laquelle Googlebot peut récupérer les ressources du site Web sans affecter les performances du site. Essentiellement, un serveur réactif entraîne un taux de crawl plus élevé.
- Demande de crawl (ou ce que Googlebot veut explorer) : le nombre d'URL visitées par Googlebot lors d'un seul crawl en fonction de la demande de (ré)indexation, impactée par la popularité et l'obsolescence du contenu du site.
Une fois que Googlebot a "dépensé" son budget d'exploration, il arrête d'explorer un site.
Google ne fournit pas de chiffre pour le budget de crawl. Le plus proche, il s'agit d'afficher le nombre total de demandes d'exploration dans le rapport de statistiques d'exploration de la console de recherche Google.
Tant de référenceurs, y compris moi-même dans le passé, se sont donné beaucoup de mal pour essayer de déduire le budget de crawl.
Les étapes souvent présentées sont quelque chose comme :
- Déterminez le nombre de pages explorables que vous avez sur votre site, en recommandant souvent de regarder le nombre d'URL dans votre sitemap XML ou d'exécuter un robot d'exploration illimité.
- Calculez les crawls moyens par jour en exportant le rapport Google Search Console Crawl Stats ou en vous basant sur les requêtes Googlebot dans les fichiers journaux.
- Divisez le nombre de pages par le nombre moyen de crawls par jour. On dit souvent, si le résultat est supérieur à 10, privilégiez l'optimisation du budget de crawl.
Cependant, ce processus est problématique.
Non seulement parce qu'il suppose que chaque URL est explorée une fois, alors qu'en réalité certaines sont explorées plusieurs fois, d'autres pas du tout.
Non seulement parce qu'il suppose qu'un crawl équivaut à une page. Alors qu'en réalité une page peut nécessiter de nombreuses explorations d'URL pour récupérer les ressources (JS, CSS, etc.) nécessaires pour la charger.
Mais surtout, parce que lorsqu'il est distillé en une métrique calculée telle que la moyenne des crawls par jour, le budget de crawl n'est rien d'autre qu'une métrique de vanité.
Toute tactique visant à "l'optimisation du budget de crawl" (c'est-à-dire visant à augmenter continuellement le montant total de crawl) est une course folle.
Pourquoi devriez-vous vous soucier d'augmenter le nombre total de crawls s'il est utilisé sur des URL sans valeur ou des pages qui n'ont pas été modifiées depuis le dernier crawl ? De tels crawls n'aideront pas les performances SEO.
De plus, tous ceux qui ont déjà consulté les statistiques de crawl savent qu'elles fluctuent, souvent assez sauvagement, d'un jour à l'autre en fonction d'un certain nombre de facteurs. Ces fluctuations peuvent ou non être corrélées à une (ré)indexation rapide des pages pertinentes pour le référencement.
Une hausse ou une baisse du nombre d'URL explorées n'est ni bonne ni mauvaise en soi.
L'efficacité du crawl est un KPI SEO

Pour la ou les pages que vous souhaitez indexer, l'accent ne doit pas être mis sur le fait qu'elles ont été explorées, mais plutôt sur la rapidité avec laquelle elles ont été explorées après avoir été publiées ou modifiées de manière significative.
Essentiellement, l'objectif est de minimiser le temps entre la création ou la mise à jour d'une page pertinente pour le référencement et la prochaine exploration de Googlebot. J'appelle ce délai l'efficacité du crawl.
Le moyen idéal pour mesurer l'efficacité de l'exploration consiste à calculer la différence entre la date et l'heure de création ou de mise à jour de la base de données et la prochaine exploration Googlebot de l'URL à partir des fichiers journaux du serveur.
S'il est difficile d'accéder à ces points de données, vous pouvez également utiliser comme proxy la date de dernière modification du sitemap XML et les URL de requête dans l'API d'inspection d'URL de la console de recherche Google pour son dernier état d'exploration (dans la limite de 2 000 requêtes par jour).
De plus, en utilisant l'API d'inspection d'URL, vous pouvez également suivre le changement de statut d'indexation pour calculer une efficacité d'indexation pour les URL nouvellement créées, ce qui correspond à la différence entre une publication et une indexation réussie.
Parce que crawler sans que cela ait un impact sur le statut d'indexation ou le traitement d'une actualisation du contenu de la page n'est qu'un gaspillage.
L'efficacité du crawl est une mesure exploitable, car à mesure qu'elle diminue, plus le contenu critique pour le référencement peut être présenté à votre public sur Google.
Vous pouvez également l'utiliser pour diagnostiquer les problèmes de référencement. Explorez les modèles d'URL pour comprendre à quelle vitesse le contenu des différentes sections de votre site est exploré et si c'est ce qui freine les performances organiques.
Si vous constatez que Googlebot prend des heures, des jours ou des semaines pour explorer et ainsi indexer votre contenu nouvellement créé ou récemment mis à jour, que pouvez-vous faire ?
Recevez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir conditions.
7 étapes pour optimiser le crawl
L'optimisation du crawl consiste à guider Googlebot pour explorer les URL importantes rapidement lorsqu'ils sont (re)publiés. Suivez les sept étapes ci-dessous.
1. Assurez une réponse rapide et saine du serveur
Un serveur hautement performant est essentiel. Googlebot ralentira ou arrêtera d'explorer lorsque :
- L'exploration de votre site a un impact sur les performances. Par exemple, plus ils explorent, plus le temps de réponse du serveur est lent.
- Le serveur répond par un nombre notable d'erreurs ou d'expirations de connexion.
D'un autre côté, l'amélioration de la vitesse de chargement des pages permettant de servir plus de pages peut amener Googlebot à explorer plus d'URL dans le même laps de temps. Il s'agit d'un avantage supplémentaire en plus de la vitesse de la page étant un facteur d'expérience utilisateur et de classement.
Si vous ne le faites pas déjà, envisagez la prise en charge de HTTP/2, car il permet de demander plus d'URL avec une charge similaire sur les serveurs.
Cependant, la corrélation entre les performances et le volume de crawl n'est que jusqu'à un certain point . Une fois que vous franchissez ce seuil, qui varie d'un site à l'autre, il est peu probable que tout gain supplémentaire de performances du serveur soit corrélé à une augmentation de l'exploration.
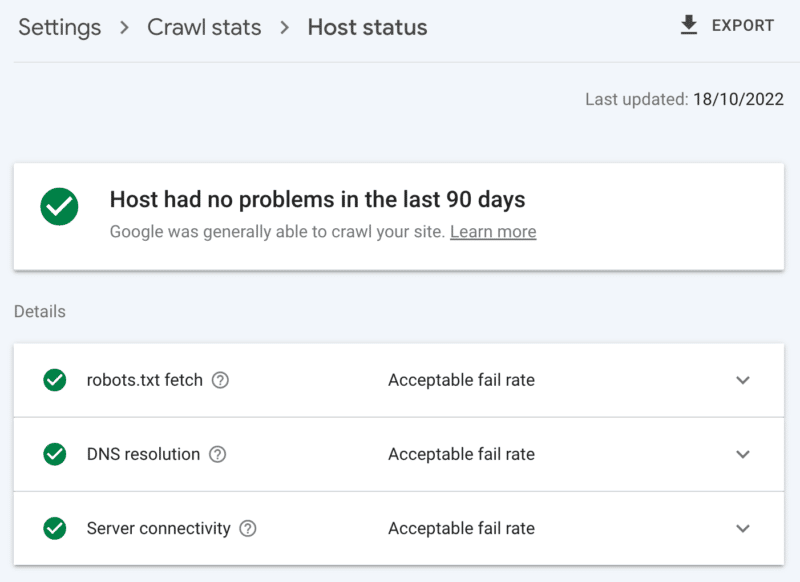
Comment vérifier la santé du serveur
Le rapport de statistiques d'exploration de Google Search Console :
- Statut de l'hôte : affiche des coches vertes.
- Erreurs 5xx : constituent moins de 1 %.
- Graphique du temps de réponse du serveur : tendance inférieure à 300 millisecondes.
2. Nettoyer le contenu de faible valeur
Si une quantité importante de contenu du site est obsolète, en double ou de mauvaise qualité, cela provoque une concurrence pour l'activité d'exploration, retardant potentiellement l'indexation du nouveau contenu ou la réindexation du contenu mis à jour.

Ajoutez à cela que le nettoyage régulier du contenu de faible valeur réduit également le gonflement de l'index et la cannibalisation des mots clés, et est bénéfique pour l'expérience utilisateur, c'est une évidence pour le référencement.
Fusionnez le contenu avec une redirection 301, lorsque vous avez une autre page qui peut être considérée comme un remplacement clair ; comprendre cela vous coûtera le double de l'exploration pour le traitement, mais c'est un sacrifice valable pour l'équité du lien.
S'il n'y a pas de contenu équivalent, l'utilisation d'un 301 n'entraînera qu'un soft 404. Supprimez ce contenu en utilisant un code d'état 410 (meilleur) ou 404 (deuxième proche) pour donner un signal fort de ne pas explorer à nouveau l'URL.
Comment vérifier le contenu de faible valeur
Le nombre d'URL dans les pages de la console de recherche Google rapporte les exclusions "explorées - actuellement non indexées". S'il est élevé, examinez les exemples fournis pour les modèles de dossier ou d'autres indicateurs de problème.
3. Revoir les contrôles d'indexation
Rel=liens canoniques sont un indice fort pour éviter les problèmes d'indexation, mais sont souvent trop utilisés et finissent par causer des problèmes de crawl car chaque URL canonisée coûte au moins deux crawls, une pour elle-même et une pour son partenaire.
De même, les directives de robots noindex sont utiles pour réduire le gonflement de l'index, mais un grand nombre peut affecter négativement l'exploration - utilisez-les donc uniquement lorsque cela est nécessaire.
Dans les deux cas, demandez-vous :
- Ces directives d'indexation sont-elles le moyen optimal de relever le défi du référencement ?
- Certaines routes d'URL peuvent-elles être consolidées, supprimées ou bloquées dans robots.txt ?
Si vous l'utilisez, reconsidérez sérieusement AMP comme une solution technique à long terme.
Avec la mise à jour de l'expérience de page axée sur les éléments vitaux du Web et l'inclusion de pages non AMP dans toutes les expériences Google tant que vous respectez les exigences de vitesse du site, examinez attentivement si AMP vaut la double exploration.
Comment vérifier la dépendance excessive aux contrôles d'indexation
Le nombre d'URL dans le rapport de couverture de Google Search Console classées dans les exclusions sans raison claire :
- Page alternative avec la balise canonique appropriée.
- Exclu par la balise noindex.
- En double, Google a choisi un canonique différent de celui de l'utilisateur.
- URL soumise en double non sélectionnée comme canonique.
4. Dites aux robots des moteurs de recherche quoi explorer et quand
Un plan de site XML est un outil essentiel pour aider Googlebot à hiérarchiser les URL de site importantes et à communiquer lorsque ces pages sont mises à jour.
Pour un guidage efficace du crawler, assurez-vous de :
- N'incluez que les URL qui sont à la fois indexables et utiles pour le référencement - généralement, 200 codes d'état, canoniques, pages de contenu originales avec une balise de robots "index, follow" pour lesquelles vous vous souciez de leur visibilité dans les SERP.
- Incluez des balises d'horodatage <lastmod> précises sur les URL individuelles et le sitemap lui-même aussi près que possible du temps réel.
Google ne vérifie pas un sitemap chaque fois qu'un site est exploré. Donc, chaque fois qu'il est mis à jour, il est préférable de le signaler à l'attention de Google. Pour ce faire, envoyez une requête GET dans votre navigateur ou la ligne de commande à :
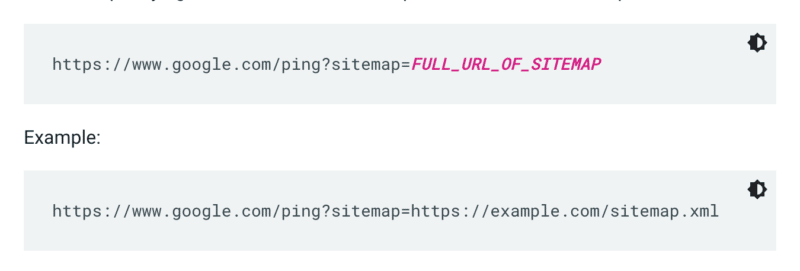
De plus, spécifiez les chemins d'accès au sitemap dans le fichier robots.txt et soumettez-le à Google Search Console à l'aide du rapport sur les sitemaps.
En règle générale, Google explore les URL dans les sitemaps plus souvent que les autres. Mais même si un petit pourcentage d'URL de votre sitemap est de mauvaise qualité, cela peut dissuader Googlebot de l'utiliser pour explorer des suggestions.
Les plans de site et les liens XML ajoutent des URL à la file d'attente d'exploration habituelle. Il existe également une file d'attente d'analyse prioritaire, pour laquelle il existe deux méthodes d'entrée.
Premièrement, pour ceux qui ont des offres d'emploi ou des vidéos en direct, vous pouvez soumettre des URL à l'API d'indexation de Google.
Ou si vous voulez attirer l'attention de Microsoft Bing ou Yandex, vous pouvez utiliser l'API IndexNow pour n'importe quelle URL. Cependant, lors de mes propres tests, cela a eu un impact limité sur l'exploration des URL. Donc, si vous utilisez IndexNow, assurez-vous de surveiller l'efficacité du crawl pour Bingbot.
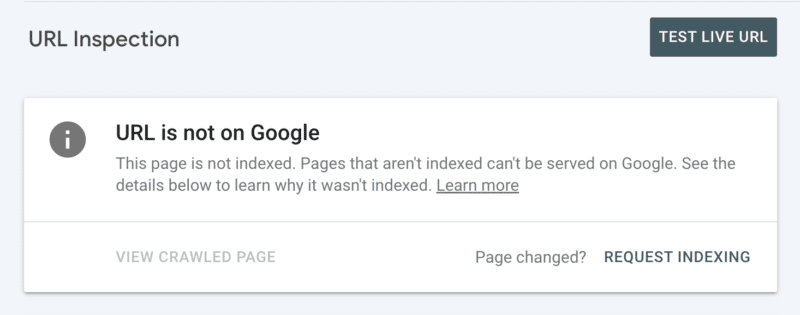
Deuxièmement, vous pouvez demander manuellement l'indexation après avoir inspecté l'URL dans la Search Console. Cependant, gardez à l'esprit qu'il existe un quota quotidien de 10 URL et que l'exploration peut encore prendre plusieurs heures. Il est préférable de voir cela comme un correctif temporaire pendant que vous creusez pour découvrir la racine de votre problème d'exploration.
Comment vérifier les conseils essentiels de Googlebot do crawl
Dans Google Search Console, votre sitemap XML affiche le statut "Succès" et a été lu récemment.
5. Dites aux robots des moteurs de recherche ce qu'ils ne doivent pas explorer
Certaines pages peuvent être importantes pour les utilisateurs ou les fonctionnalités du site, mais vous ne souhaitez pas qu'elles apparaissent dans les résultats de recherche. Empêchez ces itinéraires d'URL de distraire les robots d'exploration avec un robots.txt interdit. Cela pourrait inclure :
- API et CDN . Par exemple, si vous êtes un client de Cloudflare, veillez à interdire le dossier /cdn-cgi/ qui est ajouté à votre site.
- Images, scripts ou fichiers de style sans importance , si les pages chargées sans ces ressources ne sont pas significativement affectées par la perte.
- Page fonctionnelle , comme un panier d'achat.
- Espaces infinis , comme ceux créés par les pages de calendrier.
- Pages de paramètres . Surtout ceux de la navigation à facettes qui filtrent (par exemple, ?price-range=20-50), réorganisent (par exemple, ?sort=) ou recherchent (par exemple, ?q=) car chaque combinaison est comptée par les robots comme une page distincte.
Veillez à ne pas bloquer complètement le paramètre de pagination. La pagination explorable jusqu'à un certain point est souvent essentielle pour que Googlebot découvre le contenu et traite l'équité des liens internes. (Consultez ce webinaire Semrush sur la pagination pour en savoir plus sur le pourquoi.)
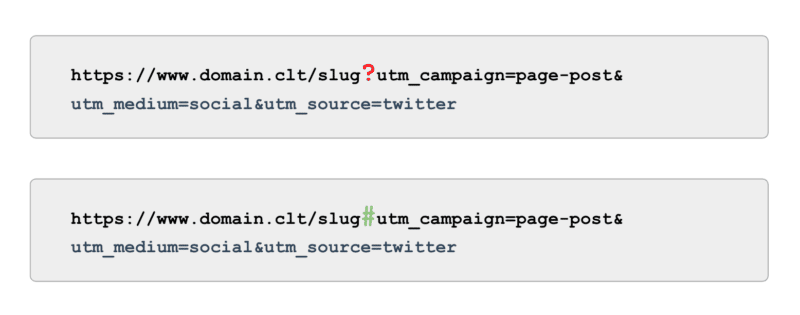
Et en ce qui concerne le suivi, plutôt que d'utiliser des balises UTM alimentées par des paramètres (aka, '?'), utilisez des ancres (aka, '#'). Il offre les mêmes avantages de création de rapports dans Google Analytics sans être explorable.
Comment vérifier que Googlebot n'explore pas les instructions
Examinez l'exemple d'URL "Indexées, non soumises dans le plan du site" dans Google Search Console. En ignorant les premières pages de pagination, quels autres chemins trouvez-vous ? Doivent-ils être inclus dans un sitemap XML, bloqués pour être explorés ou laissés pour compte ?
Consultez également la liste des "découverts - actuellement non indexés" - bloquant dans robots.txt tous les chemins d'URL qui offrent peu ou pas de valeur à Google.
Pour passer au niveau supérieur, passez en revue toutes les explorations de smartphones Googlebot dans les fichiers journaux du serveur à la recherche de chemins sans valeur.
6. Organisez les liens pertinents
Les backlinks vers une page sont précieux pour de nombreux aspects du référencement, et le crawling ne fait pas exception. Mais les liens externes peuvent être difficiles à obtenir pour certains types de pages. Par exemple, des pages profondes telles que des produits, des catégories aux niveaux inférieurs de l'architecture du site ou même des articles.
En revanche, les liens internes pertinents sont :
- Techniquement évolutif.
- Signaux puissants à Googlebot pour donner la priorité à une page pour l'exploration.
- Particulièrement percutant pour l'exploration profonde des pages.
Les fils d'Ariane, les blocs de contenu associés, les filtres rapides et l'utilisation de balises bien organisées sont tous des avantages significatifs pour l'efficacité de l'exploration. Comme il s'agit de contenus critiques pour le référencement, assurez-vous qu'aucun de ces liens internes ne dépend de JavaScript, mais utilisez plutôt un lien <a> standard et explorable.
Garder à l'esprit que ces liens internes devraient également ajouter une valeur réelle pour l'utilisateur.
Comment vérifier les liens pertinents
Exécutez une exploration manuelle de votre site complet avec un outil comme l'araignée SEO de ScreamingFrog, en recherchant :
- URL orphelines.
- Liens internes bloqués par robots.txt.
- Liens internes vers tout code de statut autre que 200.
- Le pourcentage d'URL non indexables liées en interne.
7. Auditer les problèmes d'exploration restants
Si toutes les optimisations ci-dessus sont terminées et que l'efficacité de votre crawl reste sous-optimale, effectuez un audit approfondi.
Commencez par examiner les exemples de toutes les exclusions restantes de la console de recherche Google pour identifier les problèmes d'exploration.
Une fois ceux-ci résolus, allez plus loin en utilisant un outil d'exploration manuelle pour explorer toutes les pages de la structure du site comme le ferait Googlebot. Comparez cela avec les fichiers journaux limités aux adresses IP de Googlebot pour comprendre lesquelles de ces pages sont et ne sont pas explorées.
Enfin, lancez-vous dans l'analyse des fichiers journaux limitée à Googlebot IP pendant au moins quatre semaines de données, idéalement plus.
Si vous n'êtes pas familier avec le format des fichiers journaux, utilisez un outil d'analyse de journaux. En fin de compte, c'est la meilleure source pour comprendre comment Google explore votre site.
Une fois votre audit terminé et que vous disposez d'une liste de problèmes d'analyse identifiés, classez chaque problème en fonction de son niveau d'effort attendu et de son impact sur les performances.
Remarque : D'autres experts en référencement ont mentionné que les clics provenant des SERP augmentent l'exploration de l'URL de la page de destination. Cependant, je n'ai pas encore pu le confirmer avec des tests.
Donner la priorité à l'efficacité du crawl plutôt qu'au budget du crawl
L'objectif de l'exploration n'est pas d'obtenir le plus grand nombre d'explorations ni d'explorer chaque page d'un site Web de manière répétée, mais d'inciter à explorer le contenu pertinent pour le référencement le plus près possible du moment où une page est créée ou mise à jour.
Dans l'ensemble, les budgets n'ont pas d'importance. C'est ce dans quoi vous investissez qui compte.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.