
SEO d'entité : le guide définitif
Publié: 2023-04-06Cet article a été co-écrit par Andrew Ansley .
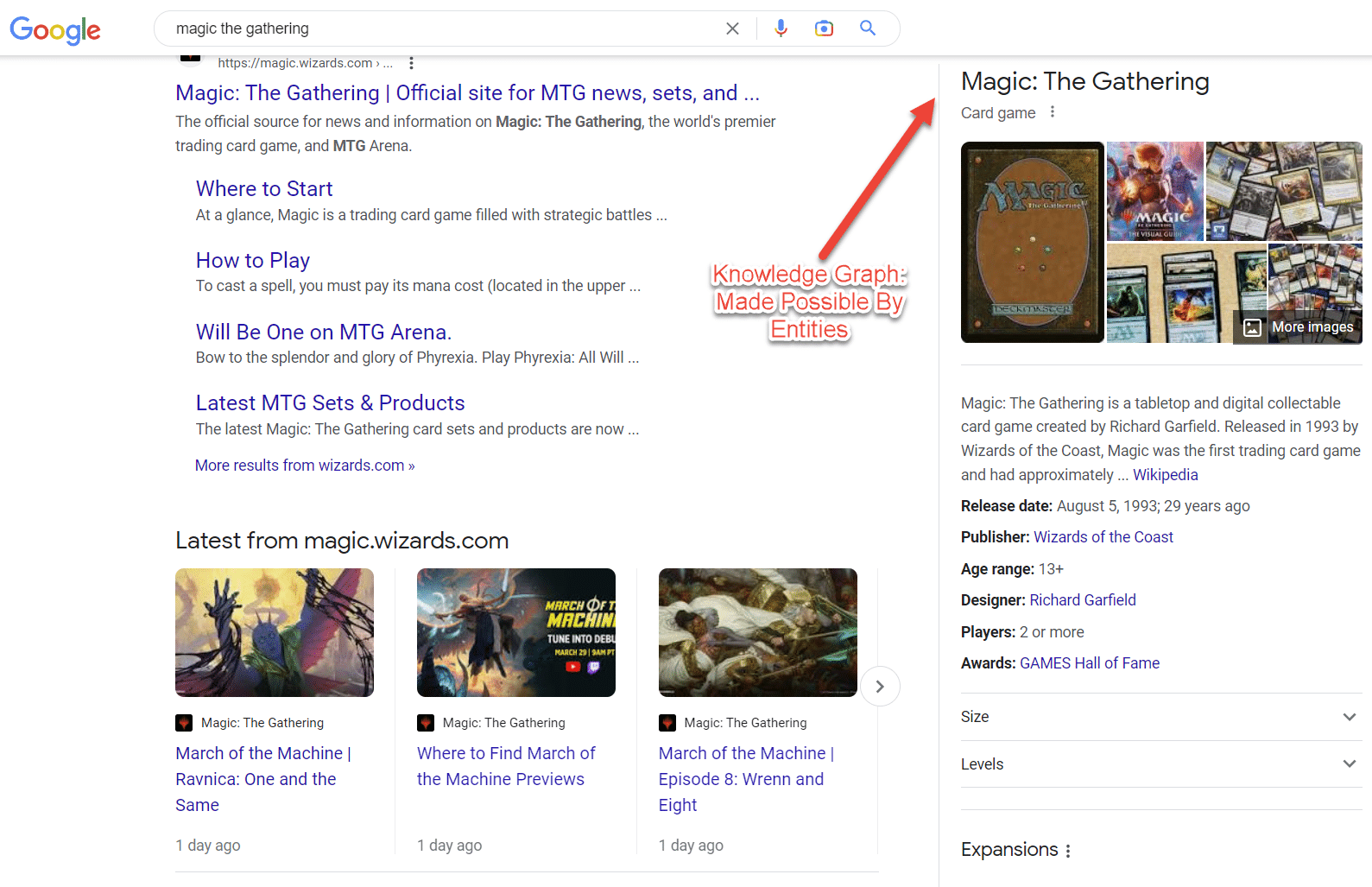
Des choses, pas des chaînes. Si vous n'avez jamais entendu cela auparavant, cela vient d'un célèbre article de blog Google qui a annoncé le Knowledge Graph.
Le 11e anniversaire de l'annonce n'est qu'à un mois, mais beaucoup ont encore du mal à comprendre ce que « des choses, pas des chaînes » signifie vraiment pour le référencement.
La citation est une tentative de faire comprendre que Google comprend les choses et n'est plus un simple algorithme de détection de mots clés.
En mai 2012, on pourrait dire que le référencement d'entité est né. L'apprentissage automatique de Google, aidé par des bases de connaissances semi-structurées et structurées, pourrait comprendre la signification d'un mot-clé.
La nature ambiguë du langage avait enfin une solution à long terme.
Donc, si les entités sont importantes pour Google depuis plus d'une décennie, pourquoi les référenceurs sont-ils toujours confus à propos des entités ?
Bonne question. Je vois quatre raisons :
- Entity SEO en tant que terme n'a pas été suffisamment utilisé pour que les référenceurs se familiarisent avec sa définition et l'intègrent donc dans leur vocabulaire.
- L'optimisation des entités chevauche largement les anciennes méthodes d'optimisation axées sur les mots clés. En conséquence, les entités sont confondues avec des mots-clés. En plus de cela, il n'était pas clair comment les entités jouaient un rôle dans le référencement, et le mot "entités" est parfois interchangeable avec "sujets" lorsque Google parle du sujet.
- Comprendre les entités est une tâche ennuyeuse. Si vous souhaitez une connaissance approfondie des entités, vous devrez lire certains brevets de Google et connaître les bases de l'apprentissage automatique. Le référencement d'entité est une approche beaucoup plus scientifique du référencement - et la science n'est tout simplement pas pour tout le monde.
- Bien que YouTube ait eu un impact massif sur la diffusion des connaissances, il a aplati l'expérience d'apprentissage pour de nombreux sujets. Les créateurs qui ont le plus de succès sur la plate-forme ont historiquement choisi la voie facile pour éduquer leur public. En conséquence, les créateurs de contenu n'ont pas passé beaucoup de temps sur les entités jusqu'à récemment. Pour cette raison, vous devez vous renseigner sur les entités auprès des chercheurs en PNL, puis vous devez appliquer ces connaissances au référencement. Les brevets et les documents de recherche sont essentiels. Encore une fois, cela renforce le premier point ci-dessus.
Cet article est une solution aux quatre problèmes qui ont empêché les référenceurs de maîtriser pleinement une approche du référencement basée sur les entités.
En lisant ceci, vous apprendrez :
- Qu'est-ce qu'une entité et pourquoi c'est important.
- L'histoire de la recherche sémantique.
- Comment identifier et utiliser les entités dans le SERP.
- Comment utiliser les entités pour classer le contenu Web.
Pourquoi les entités sont-elles importantes ?
Le référencement d'entité est l'avenir de la direction que prennent les moteurs de recherche en ce qui concerne le choix du contenu à classer et la détermination de sa signification.
Combinez cela avec la confiance basée sur la connaissance, et je pense que le référencement d'entité sera l'avenir de la façon dont le référencement est effectué au cours des deux prochaines années.
Exemples d'entités
Alors, comment reconnaître une entité ?
Le SERP a plusieurs exemples d'entités que vous avez probablement vues.
Les types d'entités les plus courants sont liés à des emplacements, des personnes ou des entreprises.
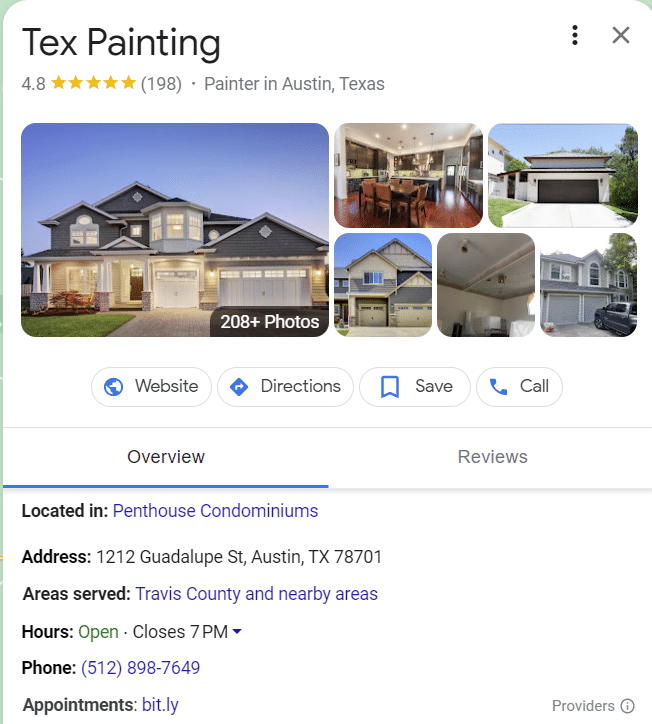
Le meilleur exemple d'entités dans le SERP est peut-être les clusters d'intention. Plus un sujet est compris, plus ces fonctionnalités de recherche émergent.
Il est intéressant de noter qu'une seule campagne de référencement peut modifier le visage du SERP lorsque vous savez comment exécuter des campagnes de référencement axées sur l'entité.
Les entrées de Wikipédia sont un autre exemple d'entités. Wikipédia fournit un excellent exemple d'informations associées à des entités.
Comme vous pouvez le voir en haut à gauche, l'entité a toutes sortes d'attributs associés au "poisson", allant de son anatomie à son importance pour les humains.
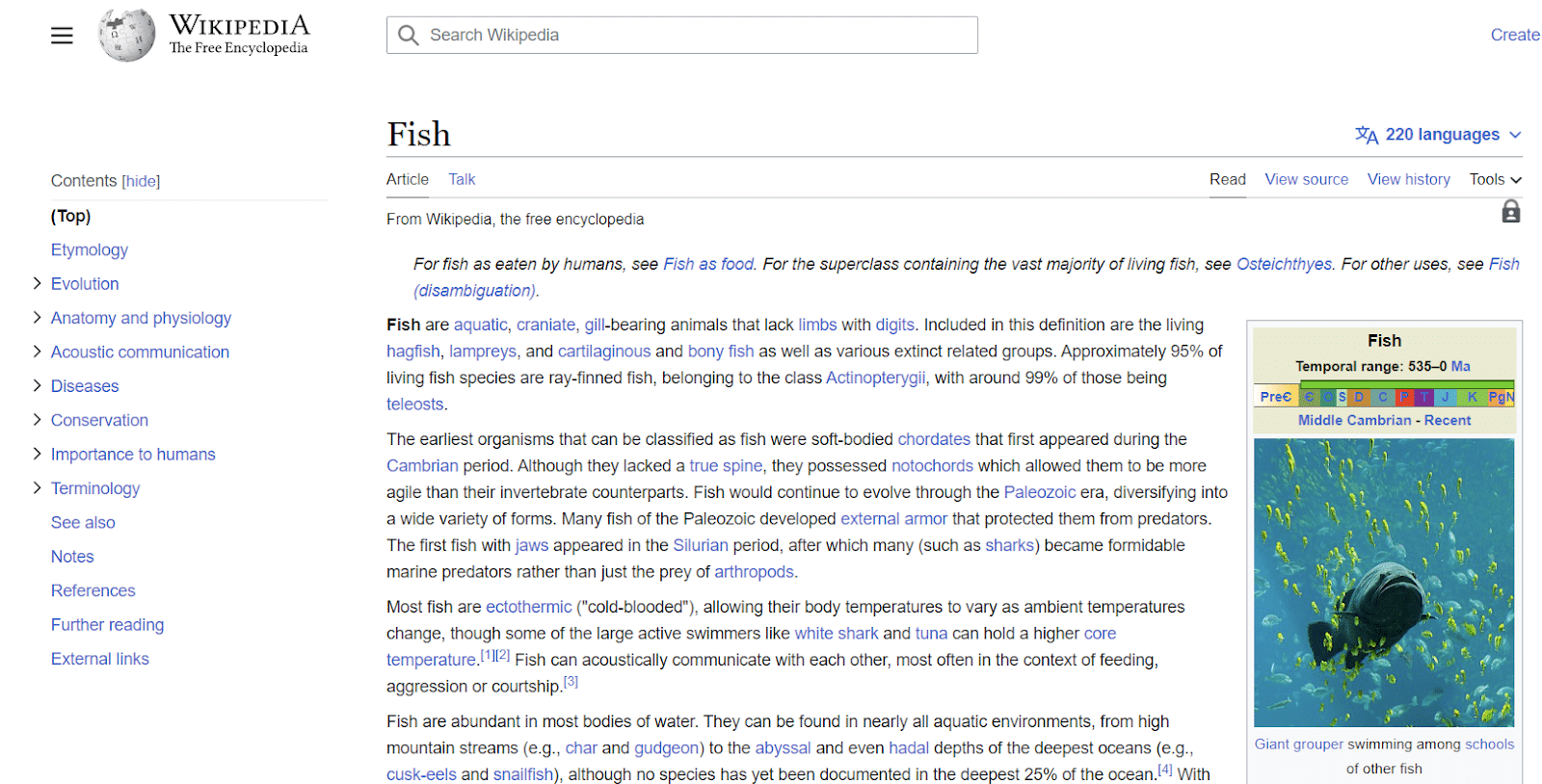
Bien que Wikipedia contienne de nombreux points de données sur un sujet, il n'est en aucun cas exhaustif.
Qu'est-ce qu'une entité ?
Une entité est un objet ou une chose identifiable de manière unique, caractérisé par son ou ses noms, son ou ses types, ses attributs et ses relations avec d'autres entités. Une entité est considérée comme existant uniquement lorsqu'elle existe dans un catalogue d'entités.
Les catalogues d'entités attribuent un identifiant unique à chaque entité. Mon agence dispose de solutions programmatiques qui utilisent l'identifiant unique associé à chaque entité (les services, les produits et les marques sont tous inclus).
Si un mot ou une phrase ne se trouve pas dans un catalogue existant, cela ne signifie pas que le mot ou la phrase n'est pas une entité, mais vous pouvez généralement savoir si quelque chose est une entité par son existence dans le catalogue.
Il est important de noter que Wikipedia n'est pas le facteur décisif pour déterminer si quelque chose est une entité, mais la société est surtout connue pour sa base de données d'entités.
N'importe quel catalogue peut être utilisé lorsqu'il s'agit d'entités. En règle générale, une entité est une personne, un lieu ou une chose, mais des idées et des concepts peuvent également être inclus.
Voici quelques exemples de catalogues d'entités :
- Wikipédia
- Wikidata
- DBpédia
- Base libre
- Yago

Les entités aident à combler le fossé entre les mondes des données non structurées et structurées.
Ils peuvent être utilisés pour enrichir sémantiquement un texte non structuré, tandis que des sources textuelles peuvent être utilisées pour alimenter des bases de connaissances structurées.
Reconnaître les mentions d'entités dans le texte et associer ces mentions aux entrées correspondantes dans une base de connaissances est connue sous le nom de tâche de liaison d'entités.
Les entités permettent une meilleure compréhension du sens du texte, tant pour les humains que pour les machines.
Alors que les humains peuvent résoudre relativement facilement l'ambiguïté des entités en fonction du contexte dans lequel elles sont mentionnées, cela présente de nombreuses difficultés et défis pour les machines.
L'entrée de la base de connaissances d'une entité résume ce que nous savons sur cette entité.
Comme le monde change constamment, de nouveaux faits font surface. Suivre ces changements nécessite un effort continu de la part des éditeurs et des gestionnaires de contenu. C'est une tâche exigeante à grande échelle.
En analysant le contenu des documents dans lesquels des entités sont mentionnées, le processus de recherche de faits nouveaux ou nécessitant une mise à jour peut être pris en charge ou même entièrement automatisé.
Les scientifiques appellent cela le problème de la population de la base de connaissances, c'est pourquoi la liaison des entités est importante.
Les entités facilitent une compréhension sémantique du besoin d'information de l'utilisateur, tel qu'exprimé par la requête par mot-clé, et du contenu du document. Les entités peuvent ainsi être utilisées pour améliorer les représentations des requêtes et/ou des documents.
Dans le document de recherche Extended Named Entity, l'auteur identifie environ 160 types d'entités. Voici deux des sept captures d'écran de la liste.


Certaines catégories d'entités sont plus facilement définies, mais il est important de se rappeler que les concepts et les idées sont des entités. Ces deux catégories sont très difficiles pour Google à évoluer par lui-même.
Vous ne pouvez pas enseigner à Google avec une seule page lorsque vous travaillez avec des concepts vagues. La compréhension des entités nécessite de nombreux articles et de nombreuses références soutenues dans le temps.
L'historique de Google avec les entités
Le 16 juillet 2010, Google a acheté Freebase. Cet achat a été la première étape majeure qui a conduit au système de recherche d'entités actuel.

Après avoir investi dans Freebase, Google s'est rendu compte que Wikidata avait une meilleure solution. Google a ensuite travaillé pour fusionner Freebase dans Wikidata, une tâche beaucoup plus difficile que prévu.
Cinq scientifiques de Google ont rédigé un article intitulé "De Freebase à Wikidata : la grande migration". Les principaux plats à emporter incluent.
« Freebase est construit sur les notions d'objets, de faits, de types et de propriétés. Chaque objet Freebase a un identifiant stable appelé "mid" (pour Machine ID)."
« Le modèle de données de Wikidata repose sur les notions d'item et d'énoncé. Un élément représente une entité, possède un identifiant stable appelé « qid » et peut avoir des étiquettes, des descriptions et des alias dans plusieurs langues ; d'autres déclarations et liens vers des pages sur l'entité dans d'autres projets Wikimedia - principalement Wikipédia. Contrairement à Freebase, les déclarations de Wikidata ne visent pas à encoder des faits réels, mais des affirmations provenant de différentes sources, qui peuvent aussi se contredire… »
Les entités sont définies dans ces bases de connaissances, mais Google devait encore construire sa connaissance des entités pour les données non structurées (c'est-à-dire les blogs).
Google s'est associé à Bing et Yahoo et a créé Schema.org pour accomplir cette tâche.
Google fournit des instructions de schéma afin que les gestionnaires de sites Web puissent disposer d'outils qui aident Google à comprendre le contenu. N'oubliez pas que Google veut se concentrer sur les choses, pas sur les chaînes.
Dans les mots de Google :
"Vous pouvez nous aider en fournissant des indices explicites sur la signification d'une page à Google en incluant des données structurées sur la page. Les données structurées sont un format standardisé pour fournir des informations sur une page et classer le contenu de la page ; par exemple, sur une page de recette, quels sont les ingrédients, le temps et la température de cuisson, les calories, etc.
Google continue en disant :
"Vous devez inclure toutes les propriétés requises pour qu'un objet puisse apparaître dans la recherche Google avec un affichage amélioré. En règle générale, définir davantage de fonctionnalités recommandées peut accroître la probabilité que vos informations apparaissent dans les résultats de recherche avec un affichage amélioré. Cependant, il est plus important de fournir des propriétés recommandées moins nombreuses mais complètes et précises plutôt que d'essayer de fournir toutes les propriétés recommandées possibles avec des données moins complètes, mal formées ou inexactes.
On pourrait en dire plus sur le schéma, mais il suffit de dire que le schéma est un outil incroyable pour les référenceurs qui cherchent à rendre le contenu de la page clair pour les moteurs de recherche.
La dernière pièce du puzzle provient de l'annonce du blog de Google intitulée "Améliorer la recherche pour les 20 prochaines années".
La pertinence et la qualité des documents sont les maîtres mots de cette annonce. La première méthode utilisée par Google pour déterminer le contenu d'une page était entièrement centrée sur les mots-clés.
Google a ensuite ajouté des couches de sujets à la recherche. Cette couche a été rendue possible grâce aux graphes de connaissances et en grattant et structurant systématiquement les données sur le Web.
Cela nous amène au système de recherche actuel. Google est passé de 570 millions d'entités et 18 milliards de faits à 800 milliards de faits et 8 milliards d'entités en moins de 10 ans. À mesure que ce nombre augmente, la recherche d'entités s'améliore.
En quoi le modèle d'entité est-il une amélioration par rapport aux modèles de recherche précédents ?
Les modèles traditionnels de recherche d'informations (IR) basés sur des mots clés ont une limitation inhérente de ne pas pouvoir récupérer des documents (pertinents) qui n'ont pas de correspondance explicite avec la requête.
Si vous utilisez ctrl + f pour rechercher du texte sur une page, vous utilisez quelque chose de similaire au modèle traditionnel de recherche d'informations basé sur des mots clés.
Une quantité insensée de données est publiée chaque jour sur le web.
Il n'est tout simplement pas possible pour Google de comprendre le sens de chaque mot, chaque paragraphe, chaque article et chaque site Web.
Au lieu de cela, les entités fournissent une structure à partir de laquelle Google peut minimiser la charge de calcul tout en améliorant la compréhension.
« Les méthodes de récupération basées sur les concepts tentent de relever ce défi en s'appuyant sur des structures auxiliaires pour obtenir des représentations sémantiques des requêtes et des documents dans un espace conceptuel de niveau supérieur. Ces structures comprennent des vocabulaires contrôlés (dictionnaires et thésaurus), des ontologies et des entités d'un référentiel de connaissances.
– Recherche orientée entité , Chapitre 8.3
Krisztian Balog, qui a écrit le livre définitif sur les entités, identifie trois solutions possibles au modèle traditionnel de recherche d'informations.
- Basé sur l'expansion : utilise des entités comme source pour étendre la requête avec différents termes.
- Projection-based : La pertinence entre une requête et un document se comprend en les projetant sur un espace latent d'entités
- Basé sur les entités : des représentations sémantiques explicites des requêtes et des documents sont obtenues dans l'espace des entités pour augmenter les représentations basées sur les termes.
L'objectif de ces trois approches est d'obtenir une représentation plus riche des informations dont l'utilisateur a besoin en identifiant les entités fortement liées à la requête.
Balog identifie ensuite six algorithmes associés à des méthodes de cartographie d'entités basées sur la projection (les méthodes de projection concernent la conversion d'entités en espace tridimensionnel et la mesure de vecteurs à l'aide de la géométrie).
- Analyse sémantique explicite (ESA) : la sémantique d'un mot donné est décrite par un vecteur stockant les forces d'association du mot aux concepts dérivés de Wikipédia.
- Modèle d'espace d'entités latentes (LES) : Basé sur un cadre probabiliste génératif. Le score de récupération du document est considéré comme une combinaison linéaire du score d'espace d'entité latente et du score de probabilité de requête d'origine.
- EsdRank : EsdRank permet de classer les documents, en utilisant une combinaison de fonctionnalités d'entité de requête et d'entité de document. Celles-ci correspondent aux notions de composants de projection de requête et de projection de document de LES, respectivement, d'avant. En utilisant un cadre d'apprentissage discriminatif, des signaux supplémentaires peuvent également être facilement intégrés, tels que la popularité de l'entité ou la qualité du document
- Classement sémantique explicite (ESR) : le modèle de classement sémantique explicite intègre des informations sur les relations à partir d'un graphe de connaissances pour permettre une "correspondance souple" dans l'espace des entités.
- Cadre de duo d'entités de mots : cela intègre des interactions inter-espaces entre les représentations basées sur les termes et les représentations basées sur les entités, conduisant à quatre types de correspondances : les termes de requête aux termes de document, les entités de requête aux termes de document, les termes de requête aux entités de document et les entités de requête pour documenter les entités.
- Modèle de classement basé sur l'attention : C'est de loin le plus compliqué à décrire.
Voici ce qu'écrit Balog :
« Un total de quatre caractéristiques d'attention sont conçues, qui sont extraites pour chaque entité de requête. Les caractéristiques d'ambiguïté d'entité sont destinées à caractériser le risque associé à une annotation d'entité. Ce sont : (1) l'entropie de la probabilité que la forme de surface soit liée à différentes entités (par exemple, dans Wikipedia), (2) si l'entité annotée est le sens le plus populaire de la forme de surface (c'est-à-dire qu'elle a la plus grande fréquence score, et (3) la différence dans les scores de similarité entre les candidats les plus probables et les seconds candidats les plus probables pour la forme de surface donnée. La quatrième caractéristique est la proximité, qui est définie comme la similarité cosinusoïdale entre l'entité de requête et la requête dans un espace d'intégration . Plus précisément, une intégration conjointe entité-terme est entraînée à l'aide du modèle de saut de gramme sur un corpus, où les mentions d'entité sont remplacées par les identifiants d'entité correspondants. L'intégration de la requête est considérée comme le centroïde des intégrations des termes de la requête.

Pour l'instant, il est important de se familiariser au niveau de la surface avec ces six algorithmes centrés sur les entités.
Le principal point à retenir est qu'il existe deux approches : la projection de documents sur une couche d'entité latente et les annotations d'entité explicites des documents.
Trois types de structures de données
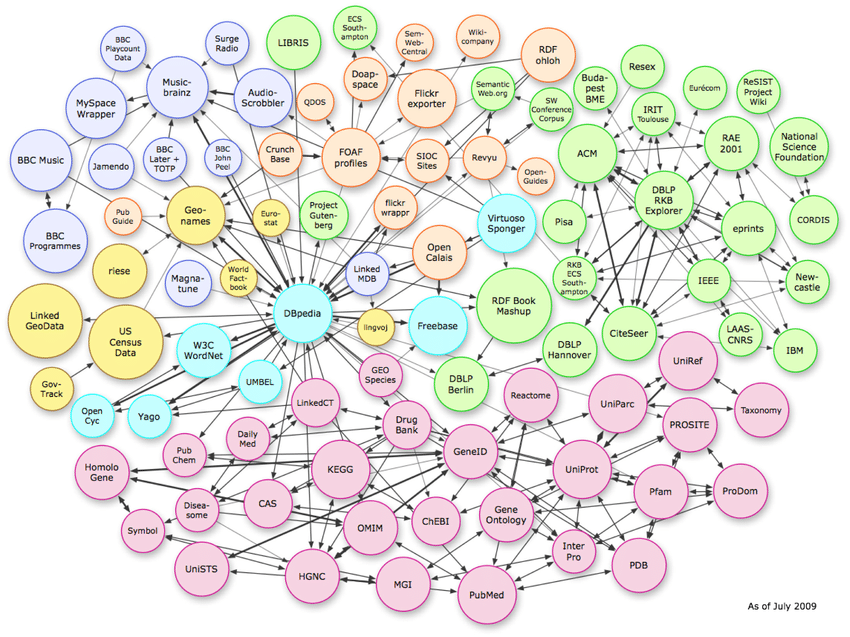
L'image ci-dessus montre les relations complexes qui existent dans l'espace vectoriel. Bien que l'exemple montre les connexions du graphe de connaissances, ce même modèle peut être reproduit au niveau du schéma page par page.
Pour comprendre les entités, il est important de connaître les trois types de structures de données utilisées par les algorithmes.
- En utilisant des descriptions d'entités non structurées , les références à d'autres entités doivent être reconnues et levées l'ambiguïté. Les arêtes dirigées (hyperliens) sont ajoutées de chaque entité à toutes les autres entités mentionnées dans sa description.
- Dans un cadre semi-structuré (c'est-à-dire Wikipédia), des liens vers d'autres entités peuvent être explicitement fournis.
- Lorsque vous travaillez avec des données structurées , les triplets RDF définissent un graphe (c'est-à-dire le graphe de connaissances). Plus précisément, les ressources de sujet et d'objet (URI) sont des nœuds et les prédicats sont des arêtes.
Le problème avec un contexte semi-structuré et distrayant pour le score IR est que si un document n'est pas configuré pour un seul sujet, le score IR peut être dilué par les deux contextes différents, ce qui entraîne la perte d'un rang relatif au profit d'un autre document textuel.
La dilution du score IR implique des relations lexicales mal structurées et une proximité de mauvais mots.
Les mots pertinents qui se complètent doivent être utilisés étroitement dans un paragraphe ou une section du document pour signaler plus clairement le contexte afin d'augmenter le score IR.
L'utilisation des attributs d'entité et des relations produit des améliorations relatives de l'ordre de 5 à 20 %. L'exploitation des informations de type entité est encore plus gratifiante, avec des améliorations relatives allant de 25 % à plus de 100 %.
L'annotation de documents avec des entités peut apporter une structure à des documents non structurés, ce qui peut aider à remplir les bases de connaissances avec de nouvelles informations sur les entités.
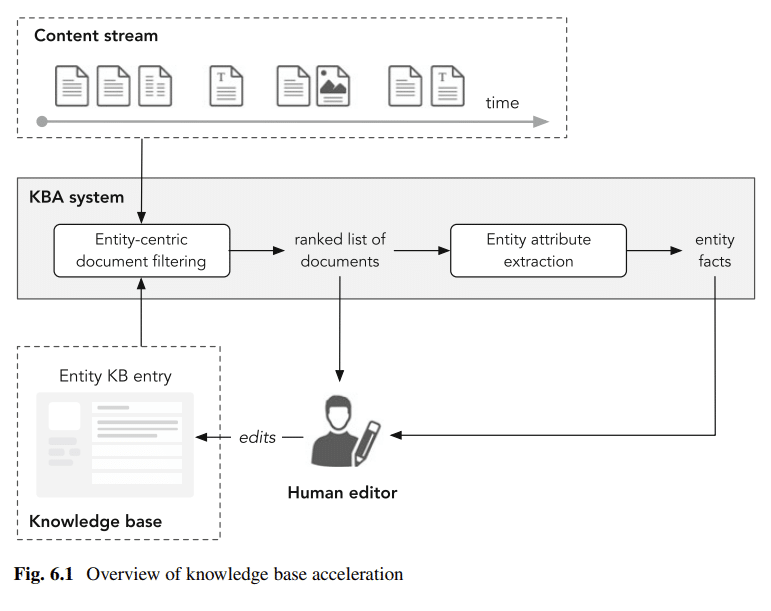
Utilisation de Wikipedia comme cadre de référencement de votre entité
Structure des pages Wikipédia
- Titre (I.)
- Section de plomb (II.)
- Liens de désambiguïsation (II.a)
- Infobox (II.b)
- Texte introductif (II.c)
- Table des matières (III.)
- Contenu du corps (IV.)
- Annexes et fond (V.)
- Références et notes (Va)
- Liens externes (Vb)
- Catégories (Vc)
La plupart des articles de Wikipédia incluent un texte d'introduction, le "lead", un bref résumé de l'article - généralement, pas plus de quatre paragraphes. Cela devrait être écrit d'une manière qui suscite l'intérêt pour l'article.
La première phrase et le premier paragraphe revêtent une importance particulière. La première phrase "peut être considérée comme la définition de l'entité décrite dans l'article". Le premier paragraphe propose une définition plus élaborée sans trop de détails.
La valeur des liens s'étend au-delà des fins de navigation ; ils capturent les relations sémantiques entre les articles. De plus, les textes d'ancrage sont une riche source de variantes de noms d'entités. Les liens Wikipédia peuvent être utilisés, entre autres, pour aider à identifier et lever l'ambiguïté des mentions d'entités dans le texte.
- Résumez les principaux faits concernant l'entité (infobox).
- Courte introduction.
- Liens internes. Une règle clé donnée aux éditeurs est de ne lier qu'à la première occurrence d'une entité ou d'un concept.
- Incluez tous les synonymes populaires pour une entité.
- Désignation de la page de catégorie.
- Modèle de navigation.
- Les références.
- Outils d'analyse spéciaux pour comprendre les pages Wiki.
- Plusieurs types de médias.
Comment optimiser pour les entités
Voici les éléments clés à prendre en compte lors de l'optimisation des entités pour la recherche :
- L'inclusion de mots sémantiquement liés sur une page.
- Fréquence des mots et des phrases sur une page.
- L'organisation des concepts sur une page.
- Y compris les données non structurées, les données semi-structurées et les données structurées sur une page.
- Paires Sujet-Prédicat-Objet (SPO).
- Documents Web sur un site qui fonctionnent comme les pages d'un livre.
- Organisation de documents Web sur un site Web.
- Inclure dans un document Web des concepts qui sont des caractéristiques connues d'entités.
Remarque importante : Lorsque l'accent est mis sur les relations entre les entités, une base de connaissances est souvent appelée graphe de connaissances.
Étant donné que l'intention est analysée conjointement avec les journaux de recherche des utilisateurs et d'autres éléments de contexte, la même phrase de recherche de la personne 1 peut générer un résultat différent de la personne 2. La personne peut avoir une intention différente avec exactement la même requête.
Si votre page couvre les deux types d'intention, alors votre page est un meilleur candidat pour le classement Web. Vous pouvez utiliser la structure des bases de connaissances pour guider vos modèles d'intention de requête (comme mentionné dans une section précédente).
Les personnes demandent également, les personnes recherchent et la saisie semi-automatique sont sémantiquement liées à la requête soumise et plongent plus profondément dans la direction de recherche actuelle ou passent à un aspect différent de la tâche de recherche.
Nous le savons, alors comment pouvons-nous l'optimiser ?
Vos documents doivent contenir autant de variations d'intention de recherche que possible. Votre site Web doit contenir toutes les variations d'intention de recherche pour votre cluster. Le clustering repose sur trois types de similarité :
- Similitude lexicale.
- Similitude sémantique.
- Cliquez sur similarité.
Couverture du sujet
Qu'est-ce que c'est –> Liste des attributs –> Section dédiée à chaque attribut –> Chaque section renvoie à un article entièrement dédié à ce sujet –> Le public doit être spécifié et les définitions de la sous-section doivent être spécifiées –> Ce qui doit être pris en compte ? –> Quels sont les avantages ? –> Avantages du modificateur –> Qu'est-ce que ___ –> À quoi ça sert ? –> Comment l'obtenir –> Comment le faire –> Qui peut le faire –> Lien vers toutes les catégories

Google propose un outil qui fournit un score de saillance (similaire à la façon dont nous utilisons le mot « force » ou « confiance ») qui vous indique comment Google voit le contenu.

L'exemple ci-dessus provient d'un article de Search Engine Land sur les entités de 2018.
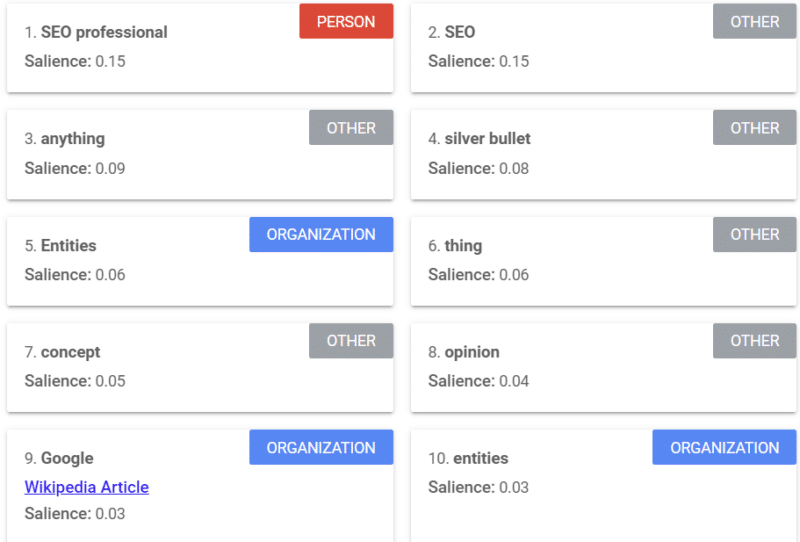
Vous pouvez voir la personne, l'autre et les organisations de l'exemple. L'outil est l'API Natural Language de Google Cloud.
Chaque mot, phrase et paragraphe compte quand on parle d'une entité. La manière dont vous organisez vos pensées peut modifier la compréhension que Google a de votre contenu.
Vous pouvez inclure un mot-clé sur le référencement, mais Google comprend-il ce mot-clé de la manière dont vous souhaitez qu'il soit compris ?
Essayez de placer un paragraphe ou deux dans l'outil et de réorganiser et de modifier l'exemple pour voir comment il augmente ou diminue la visibilité.
Cet exercice, appelé « désambiguïsation », est extrêmement important pour les entités. La langue est ambiguë, nous devons donc rendre nos mots moins ambigus pour Google.
Les approches modernes de désambiguïsation prennent en compte trois types de preuves :
Priorité des entités et des mentions.
Similitude contextuelle entre le texte entourant la mention et l'entité candidate et cohérence entre toutes les décisions de liaison d'entités dans le document.
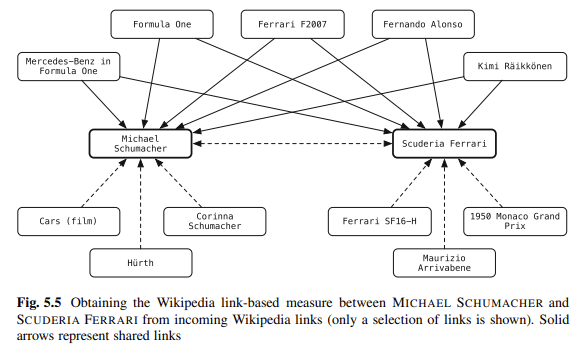
Le schéma est l'un de mes moyens préférés pour lever l'ambiguïté du contenu. Vous liez des entités de votre blog à des référentiels de connaissances. Balog dit :
"[L] lier des entités dans un texte non structuré à un référentiel de connaissances structuré peut considérablement responsabiliser les utilisateurs dans leurs activités de consommation d'informations."
Par exemple, les lecteurs d'un document peuvent acquérir des informations contextuelles ou d'arrière-plan en un seul clic, et ils peuvent accéder facilement aux entités associées.
Les annotations d'entité peuvent également être utilisées dans le traitement en aval pour améliorer les performances de récupération ou pour faciliter une meilleure interaction de l'utilisateur avec les résultats de la recherche.
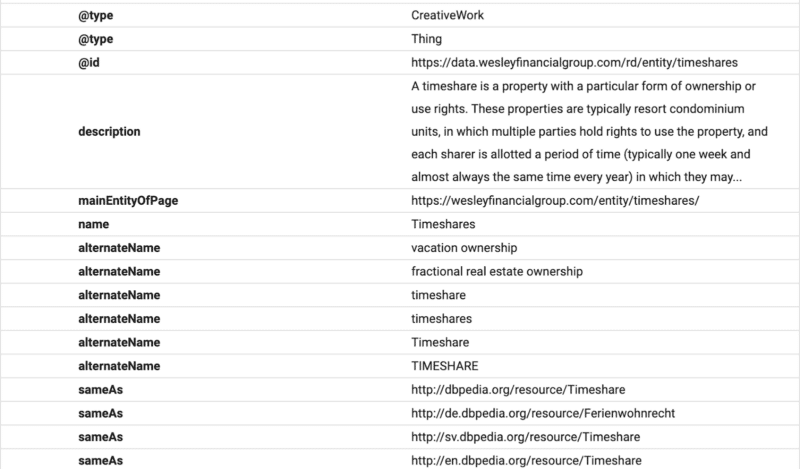
Ici, vous pouvez voir que le contenu de la FAQ est structuré pour Google à l'aide du schéma FAQ.
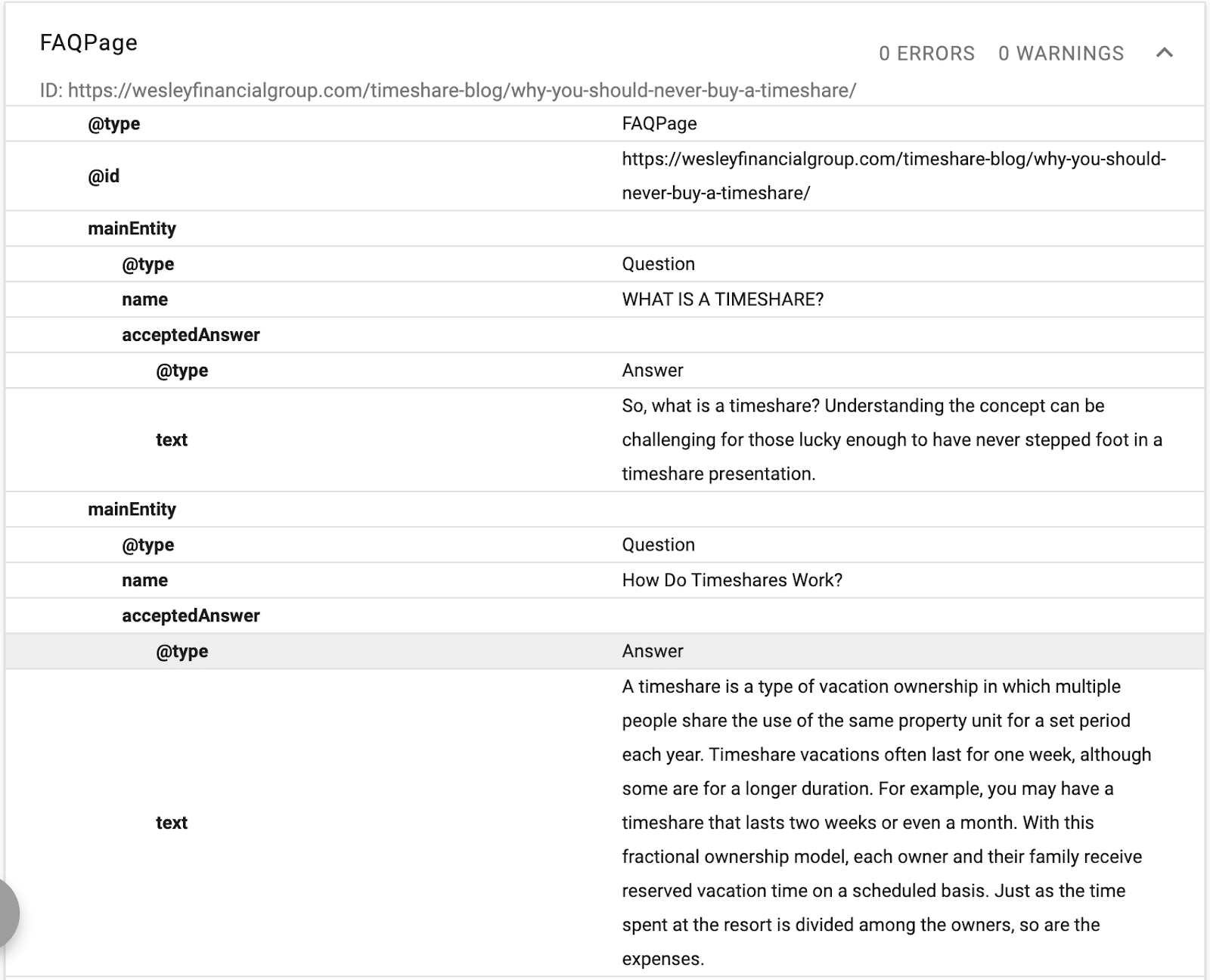
Dans cet exemple, vous pouvez voir un schéma fournissant une description du texte, un ID et une déclaration de l'entité principale de la page.
(N'oubliez pas que Google veut comprendre la hiérarchie du contenu, c'est pourquoi H1-H6 est important.)
Vous verrez des noms alternatifs et les mêmes que les déclarations. Désormais, lorsque Google lira le contenu, il saura quelle base de données structurée associer au texte, et il aura des synonymes et des versions alternatives d'un mot lié à l'entité.
Lorsque vous optimisez avec le schéma, vous optimisez pour NER (reconnaissance d'entité nommée), également appelée identification d'entité, extraction d'entité et segmentation d'entité.
L'idée est de s'engager dans Named Entity Disambiguation > Wikification > Entity Linking.
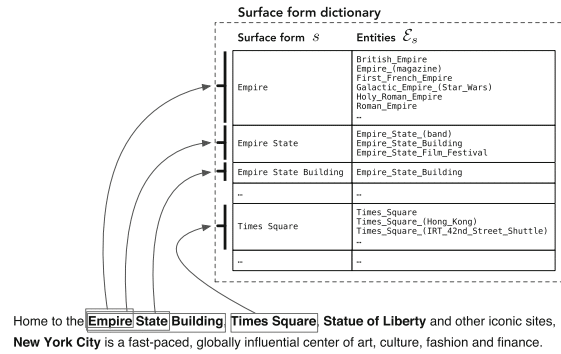
"L'avènement de Wikipédia a facilité la reconnaissance et la désambiguïsation des entités à grande échelle en fournissant un catalogue complet d'entités ainsi que d'autres ressources inestimables (en particulier, des hyperliens, des catégories et des pages de redirection et de désambiguïsation."
– Recherche orientée entité
Comment aller au-delà des suggestions d'outils de référencement
La plupart des référenceurs utilisent un outil sur la page pour optimiser leur contenu. Chaque outil est limité dans sa capacité à identifier des opportunités de contenu uniques et des suggestions de profondeur de contenu.
Pour la plupart, les outils sur la page ne font qu'agréger les meilleurs résultats SERP et créent une moyenne à imiter.
Les référenceurs doivent se rappeler que Google ne recherche pas les mêmes informations remaniées. Vous pouvez copier ce que font les autres, mais des informations uniques sont la clé pour devenir un site de semences/site d'autorité.
Voici une description simplifiée de la façon dont Google gère le nouveau contenu :
Une fois qu'il a été trouvé qu'un document mentionne une entité donnée, ce document peut être vérifié pour éventuellement découvrir de nouveaux faits avec lesquels l'entrée de la base de connaissances de cette entité peut être mise à jour.
Balog écrit :
"Nous souhaitons aider les éditeurs à rester au courant des changements en identifiant automatiquement le contenu (articles de presse, articles de blog, etc.) qui peut impliquer des modifications des entrées de la base de connaissances d'un certain ensemble d'entités d'intérêt (c'est-à-dire les entités qu'un éditeur donné est responsable de)."
Toute personne qui améliore les bases de connaissances, la reconnaissance des entités et l'exploration des informations obtiendra l'amour de Google.
Les modifications apportées au référentiel de connaissances peuvent être retracées jusqu'au document en tant que source d'origine.
Si vous fournissez un contenu qui couvre le sujet et que vous ajoutez un niveau de profondeur rare ou nouveau, Google peut déterminer si votre document a ajouté ces informations uniques.
Finalement, ces nouvelles informations maintenues sur une période de temps pourraient conduire votre site Web à devenir une autorité.
Il ne s'agit pas d'une autorité basée sur l'évaluation du domaine, mais d'une couverture thématique, ce qui, à mon avis, est beaucoup plus précieux.
Avec l'approche par entité du référencement, vous n'êtes pas limité au ciblage des mots clés avec un volume de recherche.
Tout ce que vous avez à faire est de valider le terme principal ("cannes à pêche à la mouche", par exemple), puis vous pouvez vous concentrer sur le ciblage des variations d'intention de recherche en fonction de la bonne pensée humaine de la mode.
Nous commençons par Wikipédia. Pour l'exemple de la pêche à la mouche, nous pouvons voir qu'au minimum, les concepts suivants devraient être couverts sur un site Web de pêche :
- Espèces de poissons, histoire, origines, développement, améliorations technologiques, expansion, méthodes de pêche à la mouche, casting, spey casting, pêche à la mouche de la truite, techniques de pêche à la mouche, pêche en eau froide, pêche de la truite à la mouche sèche, nymphe de la truite, eau calme pêche à la truite, jouer à la truite, relâcher la truite, pêche à la mouche en eau salée, attirail, mouches artificielles et nœuds.
Les sujets ci-dessus proviennent de la page Wikipédia sur la pêche à la mouche. Bien que cette page offre un excellent aperçu des sujets, j'aime ajouter des idées de sujets supplémentaires provenant de sujets sémantiquement liés.
Pour le sujet "poisson", nous pouvons ajouter plusieurs sujets supplémentaires, notamment l'étymologie, l'évolution, l'anatomie et la physiologie, la communication avec les poissons, les maladies des poissons, la conservation et l'importance pour les humains.
Quelqu'un a-t-il lié l'anatomie de la truite à l'efficacité de certaines techniques de pêche ?
Un seul site Web de pêche couvre-t-il toutes les variétés de poissons tout en liant les types de techniques de pêche, de cannes et d'appâts à chaque poisson ?
À présent, vous devriez être en mesure de voir comment l'expansion du sujet peut se développer. Gardez cela à l'esprit lors de la planification d'une campagne de contenu.
Ne vous contentez pas de ressasser. Ajouter de la valeur. Soyez unique. Utilisez les algorithmes mentionnés dans cet article comme guide.
Conclusion
Cet article fait partie d'une série d'articles axés sur les entités. Dans le prochain article, j'approfondirai les efforts d'optimisation autour des entités et certains outils axés sur les entités sur le marché.
Je veux terminer cet article en rendant hommage à deux personnes qui m'ont expliqué bon nombre de ces concepts.
Bill Slawski de SEO by the Sea et Koray Tugbert de Holistic SEO. Bien que Slawski ne soit plus avec nous, ses contributions continuent d'avoir un effet d'entraînement dans l'industrie du référencement.
Je m'appuie fortement sur les sources suivantes pour le contenu de l'article, car ces sources sont les meilleures ressources qui existent sur le sujet :
- Hiérarchie étendue des entités nommées par Satoshi Ketine, Kiyoshi Sudo et Chikashi Nobata
- Entity-Oriented Search par Krisztian Balog , Information Retrieval Series (INRE, volume 39)
- Réécriture de requêtes avec détection d'entités , brevet Google
- Affiner les requêtes de recherche , Google Patent
- Associer une entité à une requête de recherche , Google Patent
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.