
Comment Apache Spark peut-il donner des ailes à l'analyse des compagnies aériennes ?
Publié: 2015-10-30L'industrie mondiale du transport aérien continue de croître rapidement, mais une rentabilité constante et robuste reste à voir. Selon l'Association internationale du transport aérien (IATA), l'industrie a doublé ses revenus au cours de la dernière décennie, passant de 369 milliards de dollars américains en 2005 à 727 milliards de dollars en 2015.

Dans le secteur de l'aviation commerciale, chaque acteur de la chaîne de valeur - aéroports, constructeurs d'avions, fabricants de moteurs à réaction, agents de voyages et sociétés de services réalise un joli bénéfice.
Tous ces acteurs génèrent individuellement des volumes de données extrêmement élevés en raison d'un taux de rotation plus élevé des transactions de vol. L'identification et la capture de la demande sont la clé ici, ce qui offre aux compagnies aériennes une opportunité beaucoup plus grande de se différencier. Par conséquent, les industries aéronautiques peuvent utiliser les informations du Big Data pour augmenter leurs ventes et améliorer leur marge bénéficiaire.
Le Big Data est un terme désignant la collecte d'ensembles de données si volumineux et complexes que leur calcul ne peut pas être géré par des systèmes de traitement de données traditionnels ou des outils SGBD disponibles.
Apache Spark est un framework de calcul de cluster distribué open source spécialement conçu pour les requêtes interactives et les algorithmes itératifs.
L'abstraction Spark DataFrame est un objet de données tabulaire similaire à la trame de données native de R ou au package Pythons pandas, mais stocké dans l'environnement du cluster.
Selon la dernière enquête de Fortunes, Apache Spark est la technologie la plus populaire de 2015.
Cloudera, le plus grand fournisseur Hadoop, dit également au revoir à Hadoops MapReduce et bonjour à Spark.
Ce qui donne vraiment à Spark l'avantage sur Hadoop, c'est la vitesse . Spark gère la plupart de ses opérations en mémoire , en les copiant du stockage physique distribué vers une mémoire RAM logique beaucoup plus rapide. Cela réduit le temps consacré à l'écriture et à la lecture vers et depuis des disques durs mécaniques lents et encombrants qui doivent être effectués sous le système Hadoops MapReduce.
En outre, Spark comprend des outils (traitement en temps réel, apprentissage automatique et SQL interactif) bien conçus pour alimenter des objectifs commerciaux tels que l'analyse de données en temps réel en combinant des données historiques provenant d'appareils connectés, également appelés Internet des objets .
Aujourd'hui, rassemblons quelques informations sur des exemples de données d'aéroport à l'aide d' Apache Spark .
Dans le blog précédent, nous avons vu comment gérer les données structurées et semi-structurées dans Spark à l'aide de la nouvelle API Dataframes et avons également expliqué comment traiter efficacement les données JSON.
Dans ce blog, nous comprendrons comment interroger des données dans DataFrames à l'aide de SQL et enregistrer la sortie dans le système de fichiers au format CSV.
Utilisation de la bibliothèque d'analyse CSV Databricks
Pour cela, je vais utiliser une bibliothèque d'analyse CSV fournie par Databricks , une société fondée par les créateurs d'Apache Spark et qui gère actuellement le développement et les distributions de Spark.
La communauté Spark se compose d'environ 600 contributeurs, ce qui en fait le projet le plus actif de toute l'Apache Software Foundation, un organe directeur majeur pour les logiciels open source, en termes de nombre de contributeurs.
La bibliothèque Spark-csv nous aide à analyser et interroger les données csv dans l'étincelle. Nous pouvons utiliser cette bibliothèque à la fois pour lire et écrire des données csv vers et depuis n'importe quel système de fichiers compatible Hadoop.
Chargement des données dans Spark DataFrames
Chargeons nos fichiers d'entrée dans un Spark DataFrames à l'aide de la bibliothèque d'analyse spark-csv de Databricks.
Vous pouvez utiliser cette bibliothèque dans le shell Spark en spécifiant –packages com.databricks : spark-csv_2.10:1.0.3
Lors du démarrage du shell comme indiqué ci-dessous :
$ bin/spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
N'oubliez pas que vous devez être connecté à Internet, car le package spark-csv sera automatiquement téléchargé lorsque vous donnerez cette commande. J'utilise la version Spark 1.4.0
Permet de créer sqlContext avec un objet SparkContext(sc) déjà créé
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Maintenant, chargeons nos données csv à partir du fichier airports.csv (airport csv github) dont le schéma est comme ci-dessous
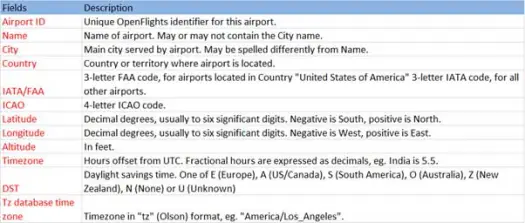
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))L'opération de chargement analysera le fichier *.csv à l'aide de la bibliothèque Databricks spark-csv et renverra une trame de données avec des noms de colonne identiques à ceux de la première ligne d'en-tête du fichier.
Voici les paramètres passés à la méthode load.
- Source : "com.databricks.spark.csv" indique à spark que nous voulons charger en tant que fichier csv.
- Option :
- chemin – chemin du fichier, où il se trouve.
- En- tête : "header" -> "true" indique à Spark de mapper la première ligne du fichier aux noms de colonne pour la trame de données résultante.
Voyons quel est le schéma de notre Dataframe
Découvrez des exemples de données dans notre base de données
scala> airportDF.show


Interroger des données CSV à l'aide de tables temporaires :
Pour exécuter une requête sur une table, nous appelons la méthode sql() sur le SQLContext.
Nous avons créé des aéroports DataFrame et chargé des données CSV, pour interroger ces données DF, nous devons les enregistrer en tant que table temporaire appelée aéroports.
>
scala> airportDF.registerTempTable("airports")
Voyons combien d'aéroports y a-t-il dans la partie sud-est de notre jeu de données
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
On peut faire des agrégations dans les requêtes sql sur Spark
Nous découvrirons combien de villes uniques ont des aéroports dans chaque pays
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Quelle est l'altitude moyenne (en pieds) des aéroports dans chaque pays ?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Maintenant, pour savoir dans chaque fuseau horaire combien d'aéroports fonctionnent ?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
Nous pouvons également calculer la latitude et la longitude moyennes de ces aéroports dans chaque pays
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Comptons combien de DST différents existent
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Sauvegarde des données au format CSV
Jusqu'à présent, nous avons chargé et interrogé des données csv. Nous allons maintenant voir comment enregistrer les résultats au format CSV dans le système de fichiers.
Supposons que nous voulions envoyer un rapport au client sur tous les aéroports du nord-ouest de tous les pays.
Calculons cela d'abord.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
Et enregistrez-le dans un fichier CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Voici les paramètres passés à la méthode save.
- Source : identique à la méthode de chargement com.databricks.spark.csv qui indique à Spark d'enregistrer les données au format CSV.
- SaveMode : Cela permet à l'utilisateur de spécifier à l'avance ce qui doit être fait si le chemin de sortie donné existe déjà. Pour que les données existantes ne soient pas perdues/écrasées par erreur. Vous pouvez lancer une erreur, ajouter ou écraser. Ici, nous avons généré une erreur ErrorIfExists car nous ne voulons pas écraser un fichier existant.
- Options : Ces options sont les mêmes que celles que nous avons transmises à la méthode load . Option :
- chemin - chemin du fichier, où il doit être stocké.
- En- tête : "header" -> "true" indique à Spark de mapper les noms de colonne de la trame de données sur la première ligne du fichier de sortie résultant.
Conversion d'autres formats de données en CSV
Nous pouvons également convertir tout autre format de données comme JSON, parquet, texte en CSV en utilisant cette bibliothèque.
Dans le blog précédent, nous avions créé des données json. vous pouvez le trouver sur github
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
enregistrons-le simplement au format CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Conclusion:
Dans cet article, nous avons rassemblé quelques informations sur les données des aéroports à l'aide de requêtes interactives SparkSQL
et exploré la bibliothèque d'analyse csv de Spark
Dans le prochain blog, nous explorerons un composant très important de Spark, c'est-à-dire Spark Streaming.
Spark Streaming permet aux utilisateurs de collecter des données en temps réel dans Spark et de les traiter au fur et à mesure et donne des résultats instantanément.