
Comment utiliser les entités Google et GPT-4 pour créer des plans d'articles
Publié: 2023-06-06Dans cet article, vous apprendrez à utiliser le grattage et le Knowledge Graph de Google pour effectuer une ingénierie automatisée des invites qui génère un plan et un résumé pour un article qui, s'il est bien écrit, contiendra de nombreux ingrédients clés pour bien se classer.
À la base des choses, nous disons à GPT-4 de produire un plan d'article basé sur un mot-clé et les principales entités qu'ils ont trouvées sur une page bien classée de votre choix.
Les entités sont classées par leur score de saillance.
« Pourquoi le score de saillance ? » vous pourriez demander.
Google décrit la saillance dans sa documentation API comme :
"Le score de saillance d'une entité fournit des informations sur l'importance ou la centralité de cette entité dans l'ensemble du texte du document. Les scores plus proches de 0 sont moins saillants, tandis que les scores plus proches de 1,0 sont très saillants.
Cela semble être une assez bonne mesure à utiliser pour influencer les entités qui devraient exister dans un contenu que vous pourriez vouloir écrire, n'est-ce pas ?
Commencer
Vous pouvez procéder de deux manières :
- Passez environ 5 minutes (peut-être 10 si vous avez besoin de configurer votre ordinateur) et exécutez les scripts depuis votre machine, ou…
- Passez au Colab que j'ai créé et commencez à jouer tout de suite.
Je suis partisan du premier, mais j'ai aussi sauté sur un Colab ou deux dans ma journée. 😀
En supposant que vous êtes toujours là et que vous souhaitez configurer cela sur votre propre machine mais que vous n'avez pas encore installé Python ou un IDE (environnement de développement intégré), je vais d'abord vous diriger vers une lecture rapide sur la configuration de votre machine pour utiliser Cahier Jupyter. Cela ne devrait pas prendre plus de 5 minutes environ.
Maintenant, il est temps d'y aller !
Utiliser des entités Google et GPT-4 pour créer des plans d'articles
Pour rendre cela facile à suivre, je vais formater les instructions comme suit :
- Étape : Une brève description de l'étape dans laquelle nous nous trouvons.
- Code : Le code pour terminer cette étape.
- Explication : Une courte explication de ce que fait le code.
Étape 1 : Dites-moi ce que vous voulez
Avant de plonger dans la création des contours, nous devons définir ce que nous voulons.
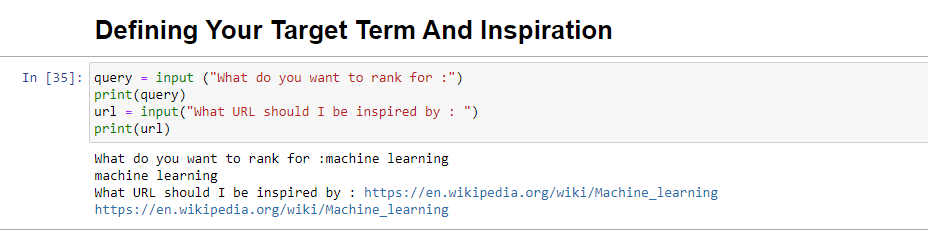
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)Lorsqu'il est exécuté, ce bloc invitera l'utilisateur (probablement vous) à entrer la requête pour laquelle vous souhaitez que l'article soit classé / à propos de, ainsi qu'à vous donner un endroit pour mettre l'URL d'un article que vous aimeriez que votre pièce dont il faut s'inspirer.
Je suggérerais un article qui se classe bien, est dans un format qui fonctionnera pour votre site et qui, selon vous, mérite bien le classement en fonction de la valeur de l'article uniquement et pas seulement de la force du site.
Une fois exécuté, il ressemblera à :
Étape 2 : Installation des bibliothèques requises
Ensuite, nous devons installer toutes les bibliothèques que nous utiliserons pour que la magie opère.
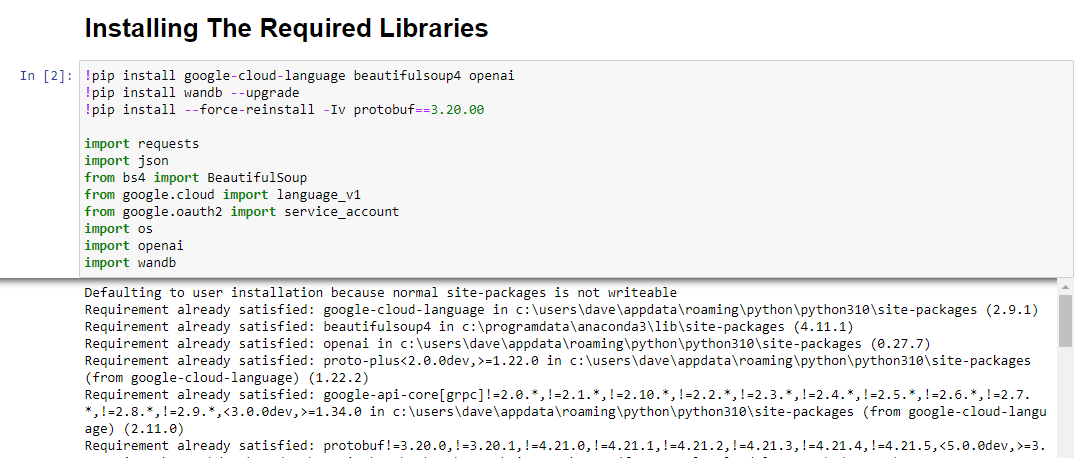
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandbNous installons les bibliothèques suivantes :
- Requêtes : Cette bibliothèque permet de faire des requêtes HTTP pour récupérer du contenu à partir de sites Web ou d'API Web.
- JSON : Il fournit des fonctions pour travailler avec les données JSON, y compris l'analyse des chaînes JSON en objets Python et la sérialisation des objets Python en chaînes JSON.
- BeautifulSoup : Cette bibliothèque est utilisée à des fins de grattage Web. Il aide à analyser et à naviguer dans les documents HTML ou XML et à en extraire les informations pertinentes.
- Google.cloud.language_v1 : Il s'agit d'une bibliothèque de Google Cloud qui fournit des capacités de traitement du langage naturel. Il permet d'effectuer diverses tâches telles que l'analyse des sentiments, la reconnaissance des entités et l'analyse de la syntaxe sur les données textuelles.
- Google.oauth2.service_account : Cette bibliothèque fait partie du package Google OAuth2 Python. Il prend en charge l'authentification auprès des API Google à l'aide d'un compte de service, ce qui permet d'accorder un accès limité aux ressources d'un projet Google Cloud.
- OS : Cette bibliothèque permet d'interagir avec le système d'exploitation. Il permet d'accéder à diverses fonctionnalités telles que les opérations sur les fichiers, les variables d'environnement et la gestion des processus.
- OpenAI : Cette bibliothèque est le package OpenAI Python. Il fournit une interface pour interagir avec les modèles de langage d'OpenAI, y compris GPT-4 (et 3). Il permet aux développeurs de générer du texte, d'effectuer des complétions de texte, etc.
- Pandas : C'est une bibliothèque puissante pour la manipulation et l'analyse de données. Il fournit des structures de données et des fonctions pour gérer et analyser efficacement des données structurées, telles que des tableaux ou des fichiers CSV.
- WandB : Cette bibliothèque signifie "Weights & Biases" et est un outil de suivi et de visualisation des expériences. Il permet de consigner et de visualiser les métriques, les hyperparamètres et d'autres aspects importants des expériences d'apprentissage automatique.
Lorsqu'il est exécuté, il ressemble à ceci :
Recevez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir conditions.
Étape 3 : Authentification
Je vais devoir nous écarter un moment pour partir et mettre en place notre authentification. Nous aurons besoin d'une clé API OpenAI et des informations d'identification Google Knowledge Graph Search.
Cela ne prendra que quelques minutes.
Obtenir votre API OpenAI
À l'heure actuelle, vous devez probablement vous inscrire sur la liste d'attente. J'ai la chance d'avoir accès à l'API tôt, et j'écris donc ceci pour vous aider à vous installer dès que vous l'aurez.
Les images d'inscription proviennent de GPT-3 et seront mises à jour pour GPT-4 une fois que le flux sera disponible pour tous.
Avant de pouvoir utiliser GPT-4, vous aurez besoin d'une clé API pour y accéder.
Pour en obtenir un, rendez-vous simplement sur la page produit d'OpenAI et cliquez sur Commencer .
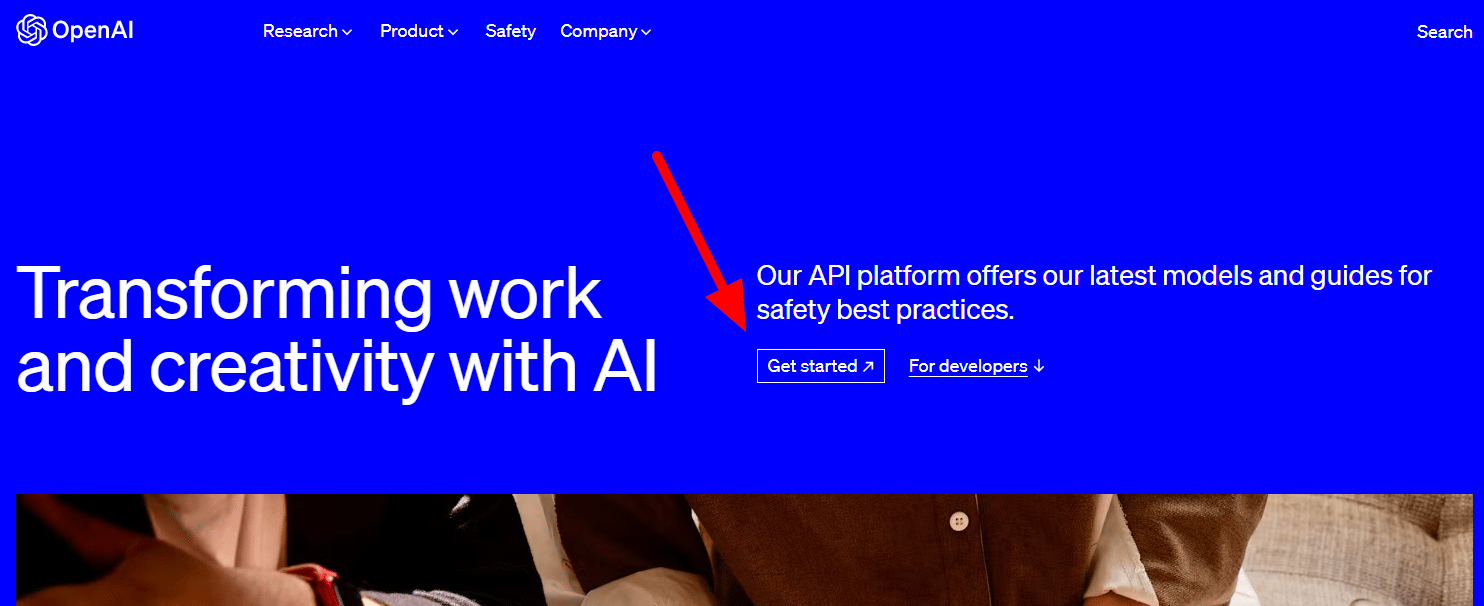
Choisissez votre méthode d'inscription (j'ai choisi Google) et exécutez le processus de vérification. Vous aurez besoin d'accéder à un téléphone pouvant recevoir des SMS pour cette étape.
Une fois cette opération terminée, vous allez créer une clé API. C'est ainsi qu'OpenAI peut connecter vos scripts à votre compte.
Ils doivent savoir qui fait quoi et déterminer si et combien ils doivent vous facturer pour ce que vous faites.
Tarification OpenAI
Lors de votre inscription, vous obtenez un crédit de 5 $ qui vous mènera étonnamment loin si vous ne faites qu'expérimenter.
Au moment d'écrire ces lignes, le passé de prix qui est :

Création de votre clé OpenAI
Pour créer votre clé, cliquez sur votre profil en haut à droite et choisissez Afficher les clés API .
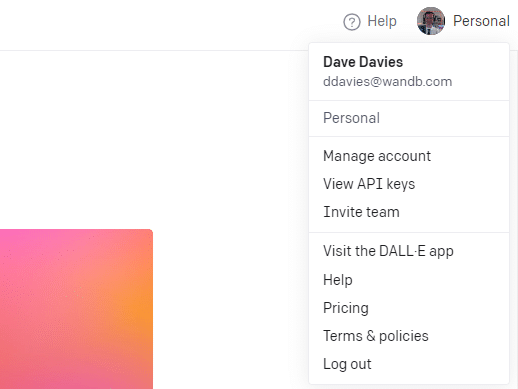
...puis vous créerez votre clé.
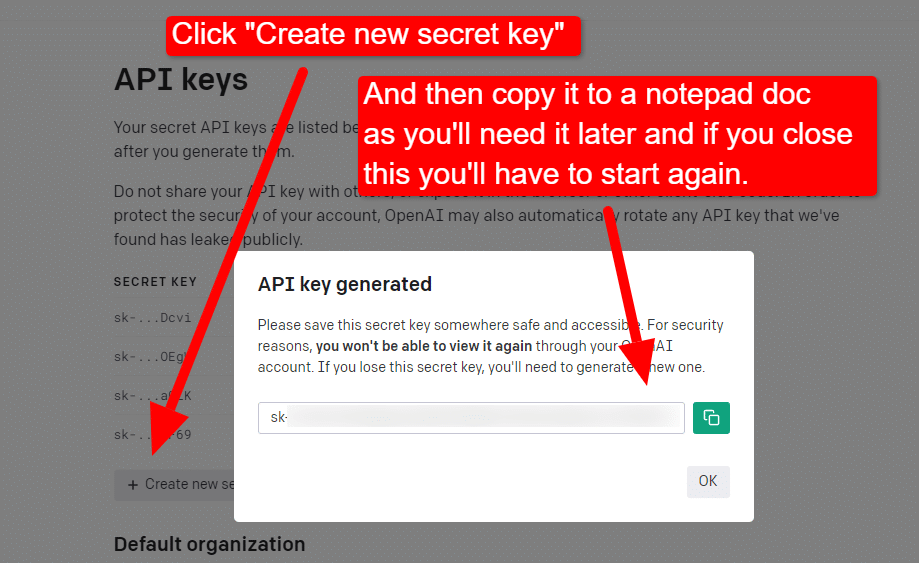
Une fois que vous fermez la visionneuse, vous ne pouvez pas voir votre clé et vous devrez la recréer, donc pour ce projet, copiez-la simplement dans un document Bloc-notes pour l'utiliser sous peu.
Remarque : n'enregistrez pas votre clé (un document Bloc-notes sur votre bureau n'est pas hautement sécurisé). Une fois que vous l'avez utilisé momentanément, fermez le document du Bloc-notes sans l'enregistrer.
Obtenir votre authentification Google Cloud
Tout d'abord, vous devrez vous connecter à votre compte Google. (Vous êtes sur un site SEO, donc je suppose que vous en avez un. 🙂)
Une fois que vous avez fait cela, vous pouvez consulter les informations de l'API Knowledge Graph si vous vous sentez si enclin ou passer directement à la console API et y aller.
Une fois que vous êtes sur la console :
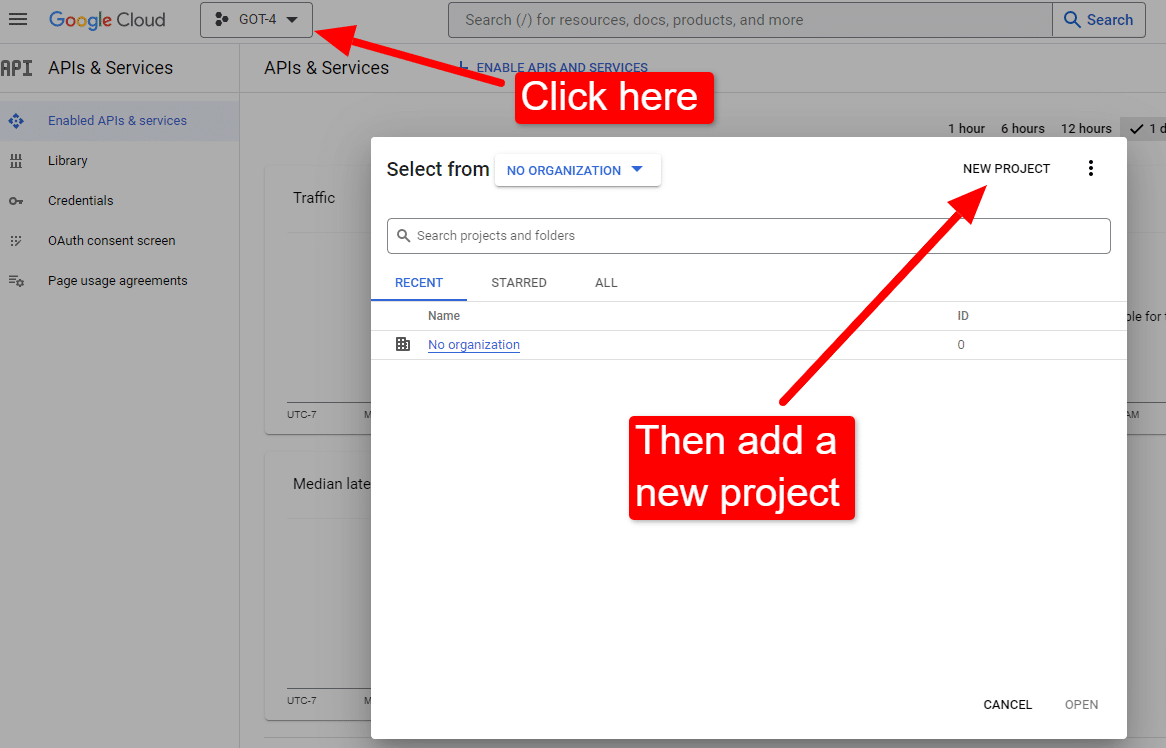
Nommez-le quelque chose comme "Les articles géniaux de Dave". Vous savez… facile à retenir.

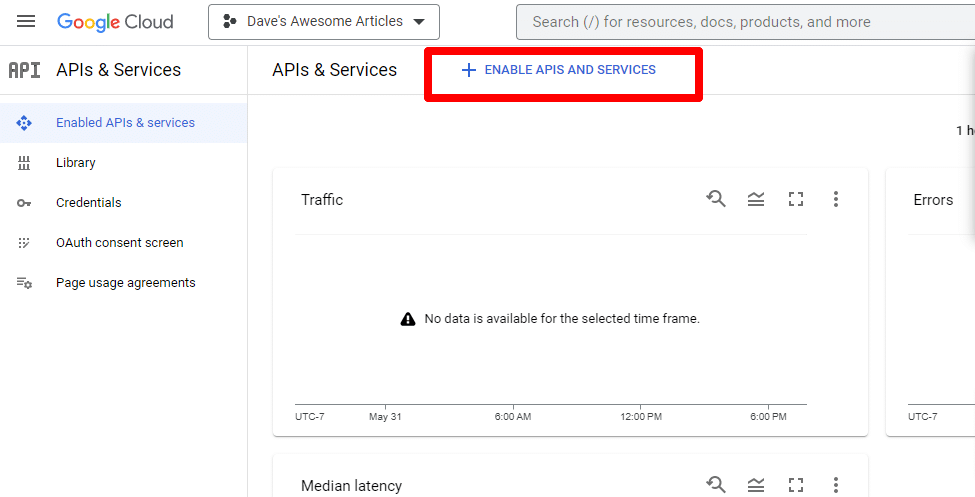
Ensuite, vous allez activer l'API en cliquant sur Activer les API et les services .
Recherchez l'API Knowledge Graph Search et activez-la.
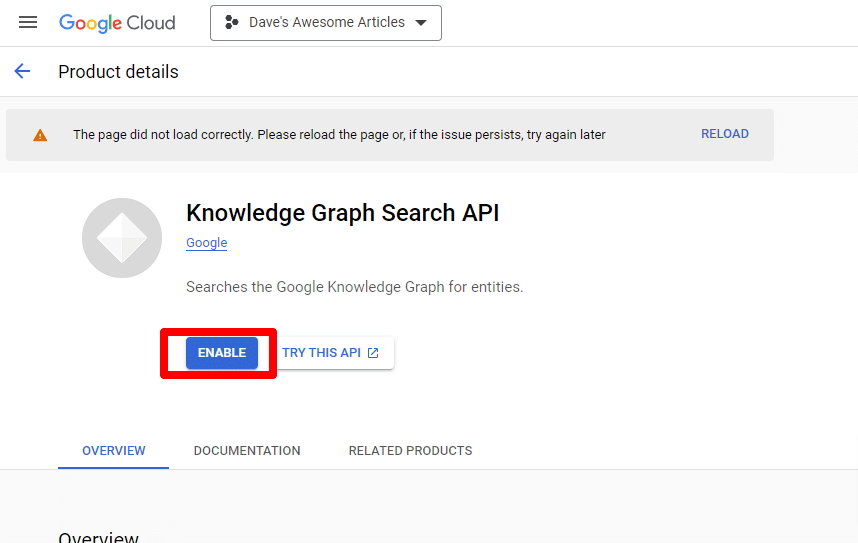
Vous serez ensuite redirigé vers la page principale de l'API, où vous pourrez créer des identifiants :
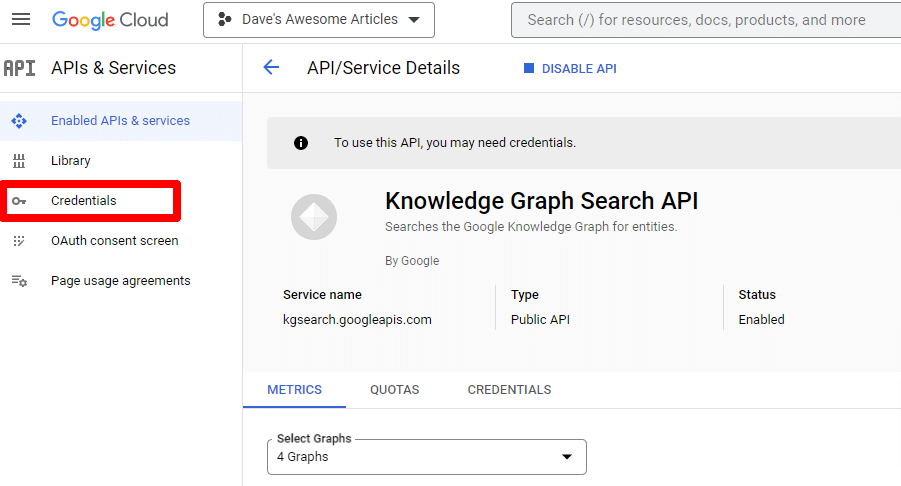
Et nous allons créer un compte de service.
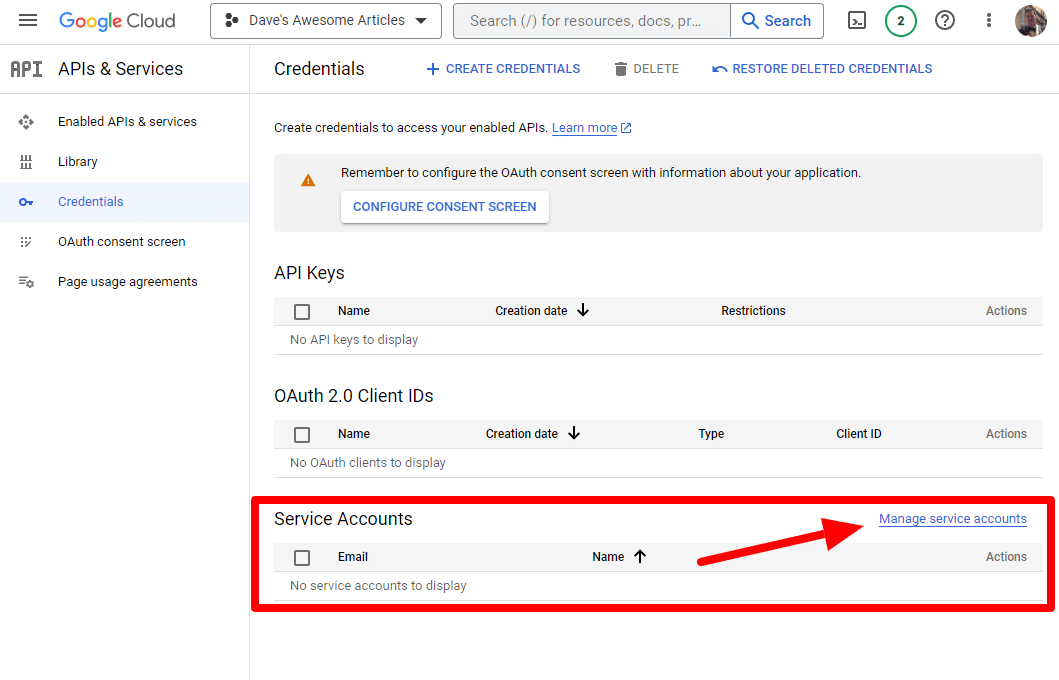
Créez simplement un compte de service :
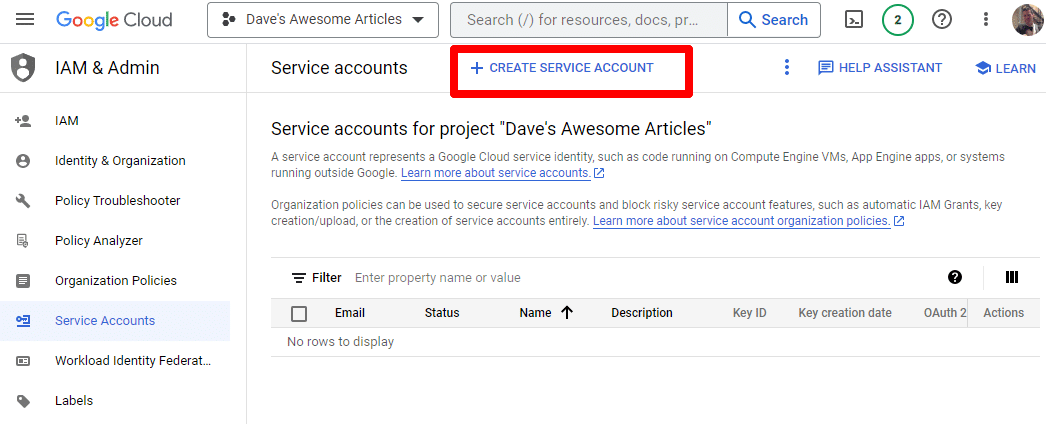
Remplissez les informations requises :
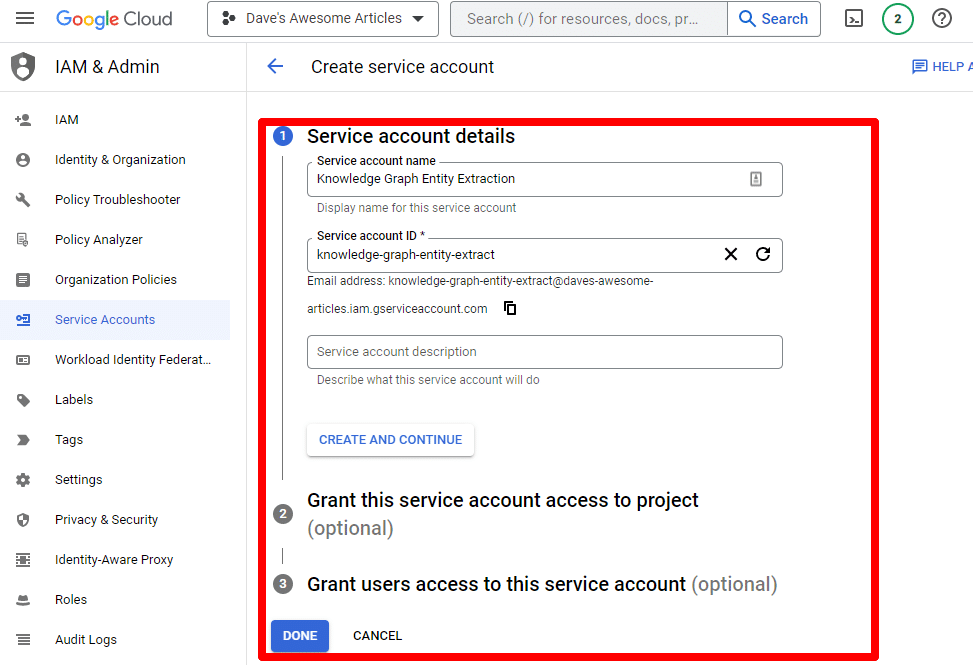
(Vous devrez lui donner un nom et lui accorder des privilèges de propriétaire.)
Nous avons maintenant notre compte de service. Il ne reste plus qu'à créer notre clé.
Cliquez sur les trois points sous Actions et cliquez sur Gérer les clés .
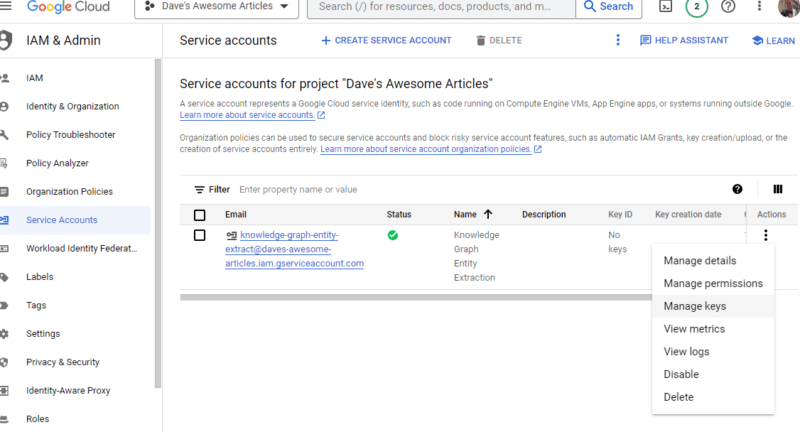
Cliquez sur Ajouter une clé puis sur Créer une nouvelle clé :
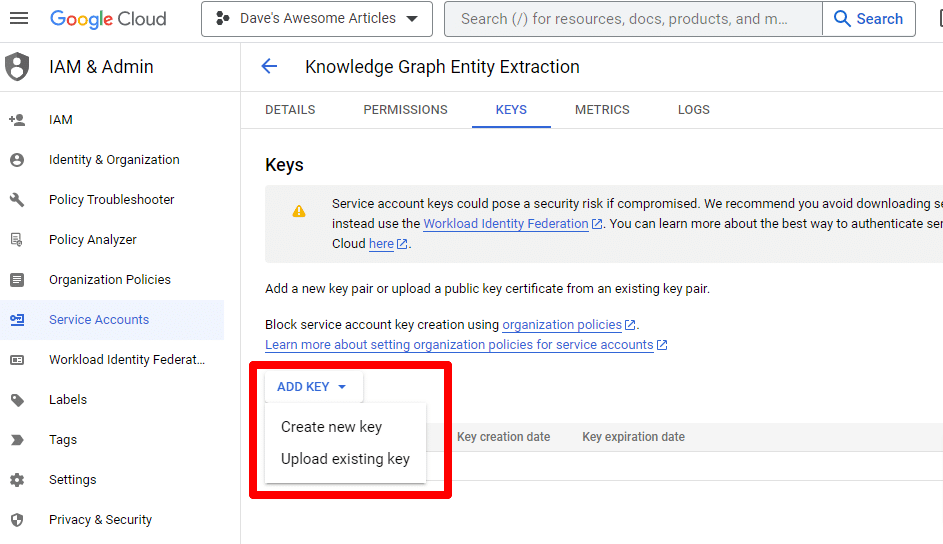
Le type de clé sera JSON.
Immédiatement, vous le verrez télécharger vers votre emplacement de téléchargement par défaut.
Cette clé donnera accès à vos API, alors gardez-la en sécurité, tout comme votre API OpenAI.
D'accord… et nous sommes de retour. Prêt à continuer avec notre script ?
Maintenant que nous les avons, nous devons définir notre clé API et le chemin d'accès au fichier téléchargé. Le code pour faire cela est :
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") Vous remplacerez YOUR_OPENAI_API_KEY par votre propre clé.
Vous remplacerez également /PATH-TO-FILE/FILENAME.JSON par le chemin d'accès à la clé de compte de service que vous venez de télécharger, y compris le nom du fichier.
Exécutez la cellule et vous êtes prêt à passer à autre chose.
Etape 4 : Créer les fonctions
Ensuite, nous allons créer les fonctions pour :
- Grattez la page Web que nous avons entrée ci-dessus.
- Analysez le contenu et extrayez les entités.
- Générez un article en utilisant GPT-4.
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()C'est à peu près exactement ce que décrivent les commentaires. Nous créons trois fonctions aux fins décrites ci-dessus.
Les yeux perçants remarqueront :
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, Vous pouvez modifier le contenu ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) et décrire le rôle que vous souhaitez que ChatGPT joue. Vous pouvez également ajouter du ton (par exemple, « Vous êtes un écrivain sympathique… »).
Étape 5 : Grattez l'URL et imprimez les entités
Maintenant, on se salit les mains. Il est temps de:
- Grattez l'URL que nous avons entrée ci-dessus.
- Extrayez tout le contenu qui se trouve dans les balises de paragraphe.
- Exécutez-le via l'API Google Knowledge Graph.
- Générez les entités pour un aperçu rapide.
Fondamentalement, vous voulez voir n'importe quoi à ce stade. Si vous ne voyez rien, consultez un autre site.
content = scrape_url(url) entities = analyze_content(content)Vous pouvez voir que la première ligne appelle la fonction qui récupère l'URL que nous avons entrée en premier. La deuxième ligne analyse le contenu pour en extraire les entités et les métriques clés.
Une partie de la fonction analyze_content imprime également une liste des entités trouvées pour une référence et une vérification rapides.
Etape 6 : Analyser les entités
Lorsque j'ai commencé à jouer avec le script, j'ai commencé avec 20 entités et j'ai rapidement découvert que c'était généralement trop. Mais est-ce que la valeur par défaut (10) est correcte ?
Pour le savoir, nous écrirons les données dans les tables W&B pour une évaluation facile. Il conservera les données indéfiniment pour une évaluation future.
Tout d'abord, vous devrez prendre environ 30 secondes pour vous inscrire. (Ne vous inquiétez pas, c'est gratuit pour ce genre de choses !) Vous pouvez le faire sur https://wandb.ai/site.
Une fois que vous avez fait cela, le code pour le faire est:
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()Une fois exécuté, le résultat ressemble à ceci :
Et lorsque vous cliquez sur le lien pour afficher votre course, vous trouverez :
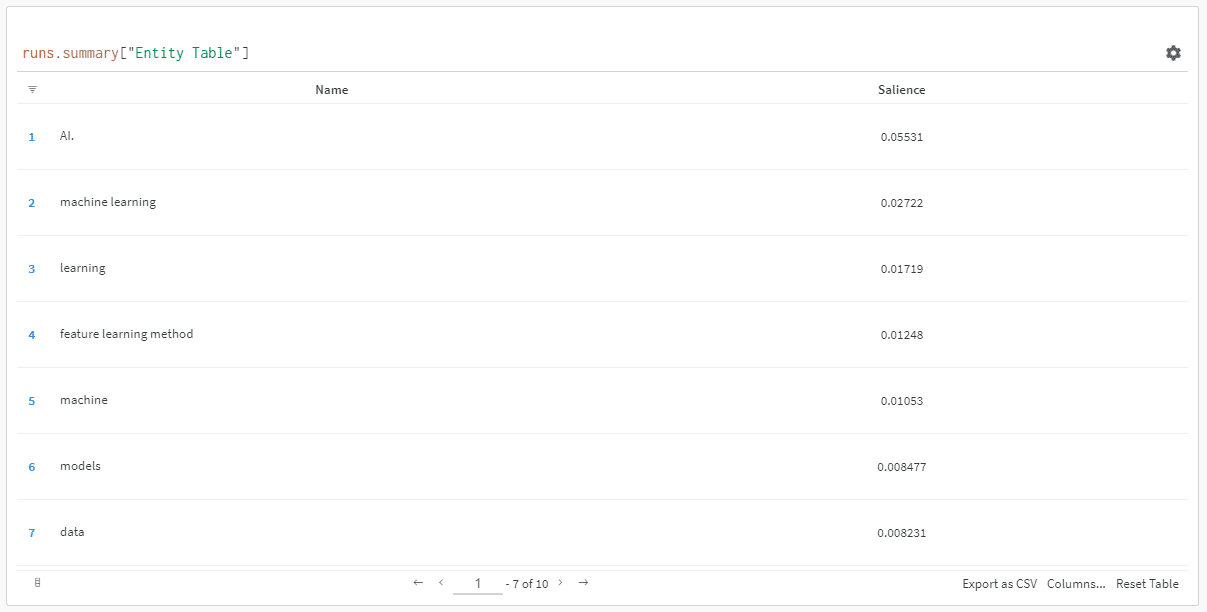
Vous pouvez constater une baisse du score de saillance. N'oubliez pas que ce score calcule l'importance de ce terme pour la page, et non pour la requête.
Lors de l'examen de ces données, vous pouvez choisir d'ajuster le nombre d'entités en fonction de la pertinence ou simplement lorsque vous voyez apparaître des termes non pertinents.
Pour ajuster le nombre d'entités, dirigez-vous vers la cellule des fonctions et modifiez :
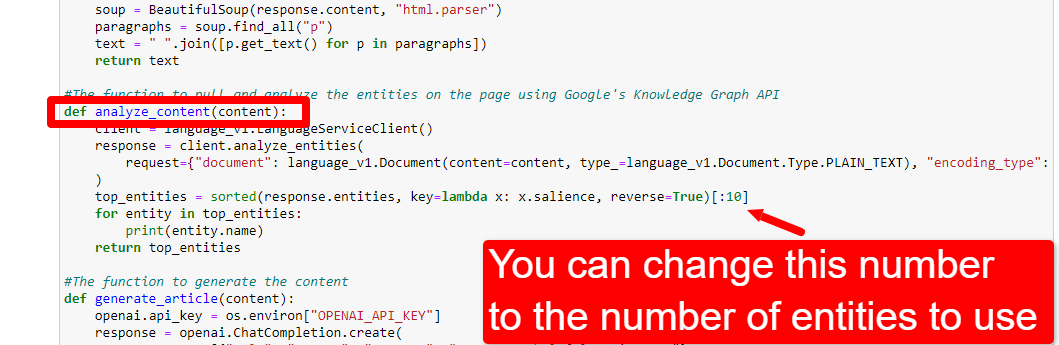
Vous devrez ensuite réexécuter la cellule et celle que vous avez exécutée pour gratter et analyser le contenu afin d'utiliser le nouveau nombre d'entités.
Étape 7 : Générer le plan de l'article
Le moment que vous attendiez tous, il est temps de générer le plan de l'article.
Cela se fait en deux parties. Tout d'abord, nous devons générer l'invite en ajoutant la cellule :
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)Cela crée essentiellement une invite pour générer un article :

Et puis, il ne reste plus qu'à générer le plan de l'article en utilisant ce qui suit :
generated_article = generate_article(gpt_prompt) print(generated_article)Ce qui produira quelque chose comme :
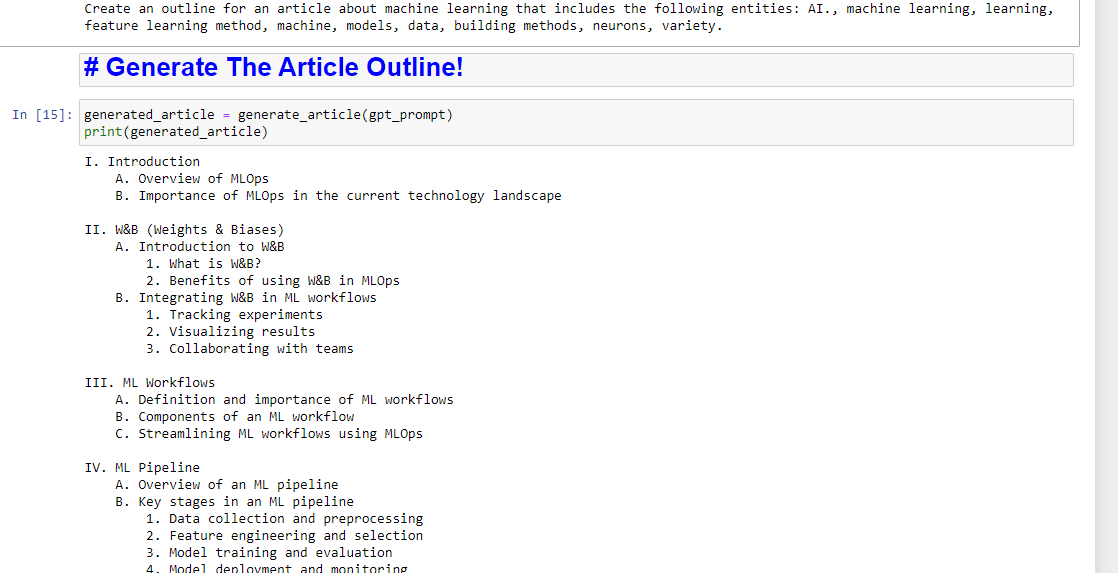
Et si vous souhaitez également obtenir un résumé rédigé, vous pouvez ajouter :
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)Ce qui produira quelque chose comme :
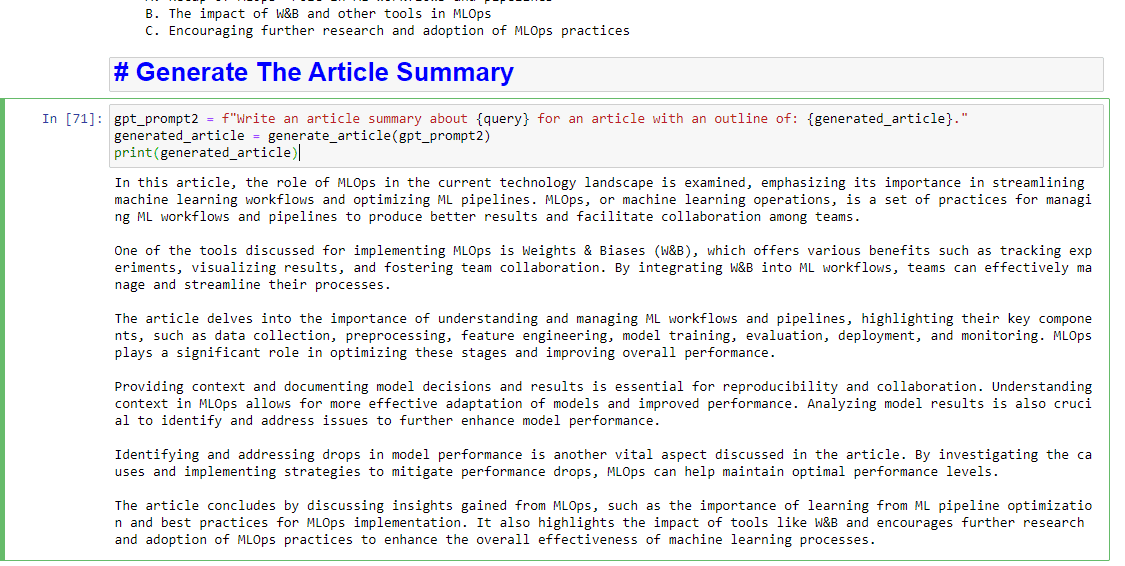
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.