
Comment Google peut identifier et évaluer les auteurs via EEAT
Publié: 2023-04-17Google accorde plus d'importance à la source de contenu, en particulier à l'auteur, lors du classement des résultats de recherche. L'introduction de Perspectives, À propos de ce résultat et À propos de cet auteur dans les SERP le montre clairement.
Cet article explore comment Google peut potentiellement évaluer les éléments de contenu à travers l'expérience, l'expertise, l'autorité et la fiabilité (EEAT) de leurs auteurs.
EEAT : l'offensive qualité de Google
Google a souligné l'importance du concept EEAT pour améliorer la qualité des résultats de recherche et l'expérience utilisateur sur SERP.
Les facteurs sur la page tels que la qualité générale du contenu, les signaux de lien (c'est-à-dire le PageRank et les textes d'ancrage) et les signaux au niveau de l'entité jouent tous un rôle essentiel.
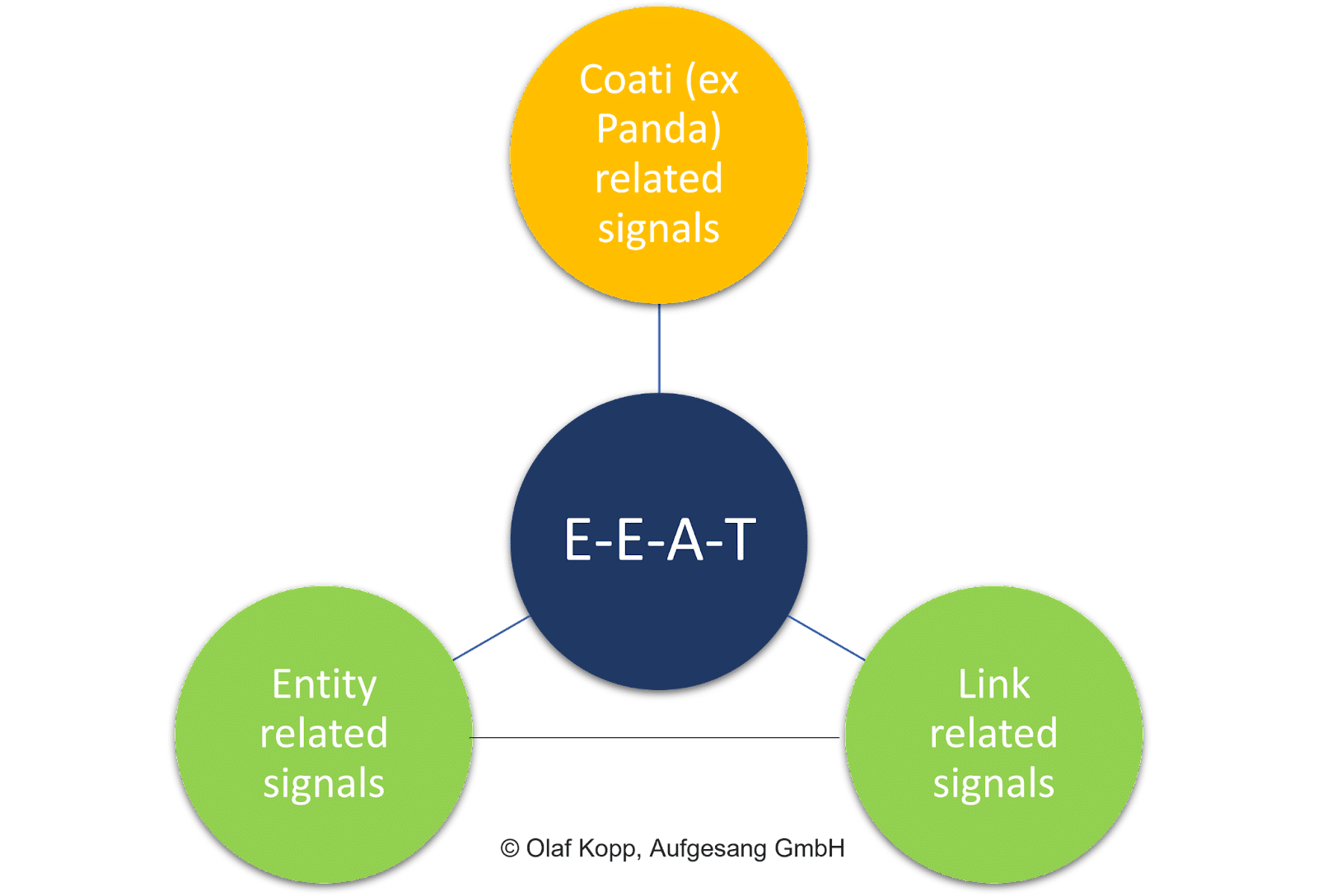
Contrairement à la notation des documents, l'évaluation du contenu individuel n'est pas l'objectif de l'EEAT.
Le concept a une référence thématique liée au domaine et à l'entité d'origine. Il est indépendant de l'intention de recherche et du contenu individuel lui-même.
En fin de compte, EEAT est un facteur d'influence indépendant des requêtes de recherche.
EEAT fait principalement référence à des domaines thématiques et est compris comme une couche d'évaluation qui évalue des collections de contenus et des signaux hors page par rapport à des entités telles que des entreprises, des organisations, des personnes et leurs domaines.
L'importance de l'auteur comme source de contenu
Bien avant (E-)EAT, Google a essayé d'inclure la notation des sources de contenu dans les classements de recherche. Par exemple, la mise à jour Vince de 2009 a donné au contenu créé par la marque un avantage de classement.
À travers des projets comme Knol ou Google+, qui sont depuis longtemps terminés, Google a tenté de collecter des signaux pour les évaluations des auteurs (c'est-à-dire via un graphe social et les évaluations des utilisateurs).
Au cours des 20 dernières années, plusieurs brevets de Google ont directement ou indirectement fait référence à des plateformes de contenu telles que Knol et à des réseaux sociaux tels que Google+.
Évaluer l'origine ou l'auteur d'un contenu selon les critères EEAT est une étape cruciale pour développer davantage la qualité des résultats de recherche.
Avec l'abondance de contenu généré par l'IA et le spam classique, cela n'a aucun sens pour Google d'inclure un contenu de qualité inférieure dans l'index de recherche.
Plus il indexe et doit traiter de contenu lors de la recherche d'informations, plus la puissance de calcul requise est importante.
EEAT peut aider Google à se classer en fonction de l'entité, du domaine et du niveau d'auteur appliqué à une échelle plus large sans avoir à explorer chaque élément de contenu.
À ce niveau macro, le contenu peut être classé en fonction de l'entité d'origine et alloué avec plus ou moins de budget de crawl. Google peut également utiliser cette méthode pour exclure des groupes de contenu entiers de l'indexation.
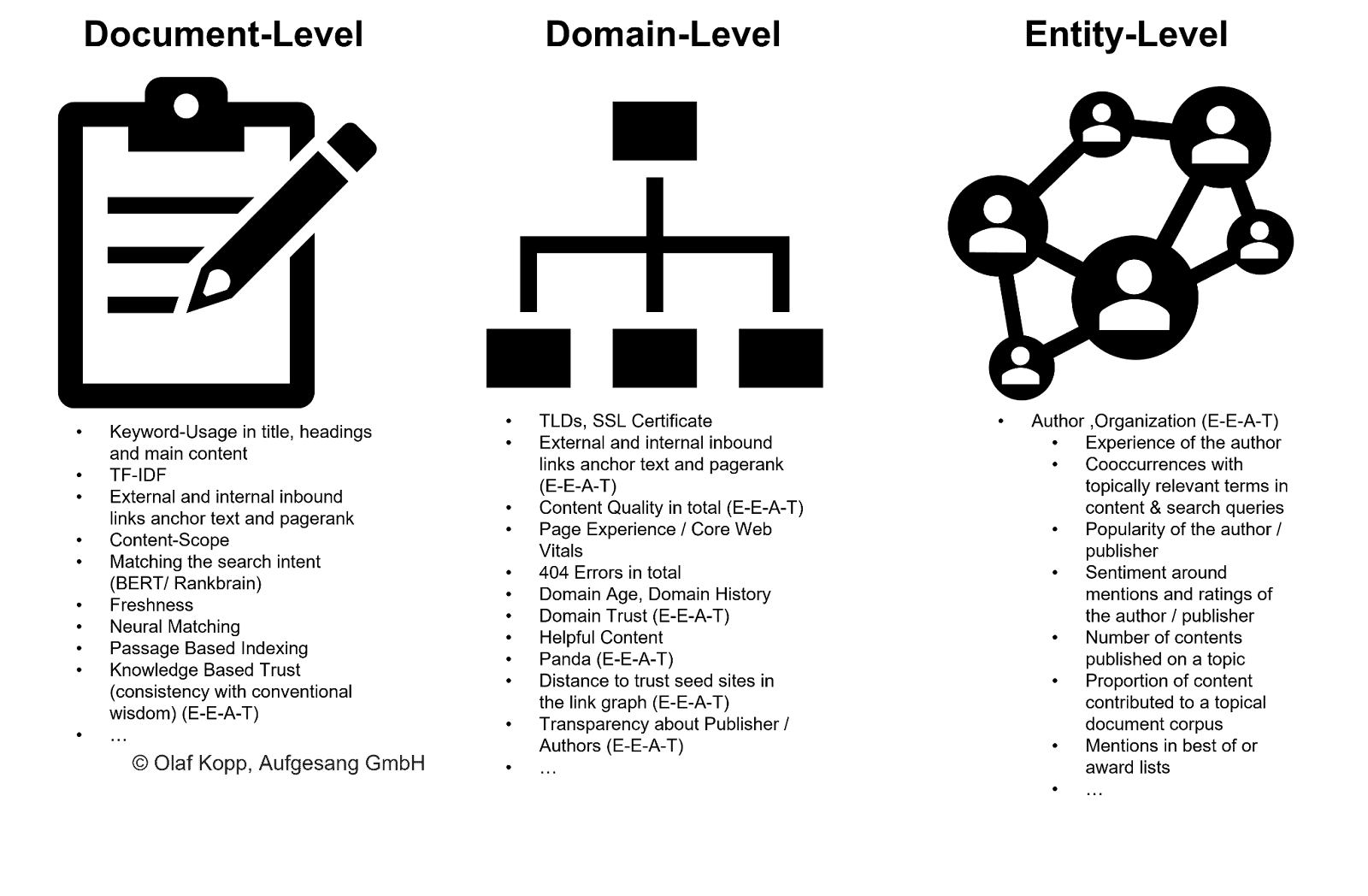
Comment Google peut-il identifier les auteurs et attribuer le contenu ?
Les auteurs appartiennent au type d'entité personne. Une distinction doit être faite entre les entités déjà connues enregistrées dans le Knowledge Graph et les entités précédemment inconnues ou non validées enregistrées dans un référentiel de connaissances tel que le Knowledge Vault.
Même si les entités ne sont pas encore capturées dans le Knowledge Graph, Google peut reconnaître et extraire des entités à partir de contenu non structuré à l'aide d'apprentissage automatique et de modèles de langage. La solution est nommée reconnaissance d'entité (NER), une sous-tâche du traitement du langage naturel.
NER reconnaît les entités en fonction des modèles linguistiques et des types d'entités sont attribués. D'une manière générale, les noms sont des entités (nommées).
Les systèmes modernes de recherche d'informations utilisent pour cela l'incorporation de mots (Word2Vec).
Un vecteur de nombres représente chaque mot d'un texte ou d'un paragraphe de texte, et les entités peuvent être représentées sous forme de vecteurs de nœuds ou d'incorporations d'entités (Node2Vec/Entity2Vec).
Les mots sont assignés à une classe grammaticale (nom, verbe, prépositions, etc.) via le balisage de la partie du discours (POS).
Les noms sont généralement des entités. Les sujets sont les entités principales et les objets sont les entités secondaires. Les verbes et les prépositions peuvent relier les entités les unes aux autres.
Dans l'exemple ci-dessous, "olaf kopp", "responsable du référencement", "co fondateur" et "aufgesang" sont les entités nommées. (NN = nom).
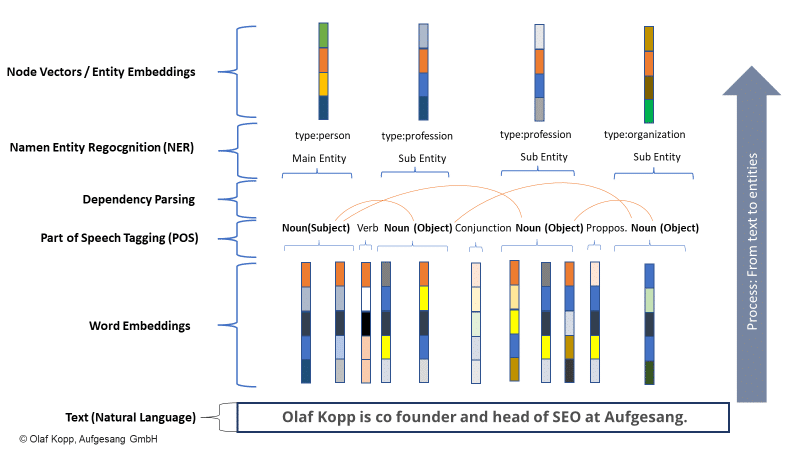
Le traitement du langage naturel peut identifier des entités et déterminer la relation entre elles.
Cela crée un espace sémantique qui capture et comprend mieux le concept d'entité.
Vous pouvez en savoir plus à ce sujet dans "Comment Google utilise le NLP pour mieux comprendre les requêtes de recherche, le contenu".
L'équivalent des incorporations d'auteur est les incorporations de document. Les incorporations de documents sont comparées aux vecteurs d'auteur via l'analyse de l'espace vectoriel. (Vous pouvez en savoir plus dans le brevet Google "Génération de représentations vectorielles de documents".)
Tous les types de contenus peuvent être représentés sous forme de vecteurs, ce qui permet :
- Vecteurs de contenu et vecteurs d'auteur à comparer dans des espaces vectoriels.
- Documents à regrouper en fonction de la similarité.
- Auteurs à attribuer.
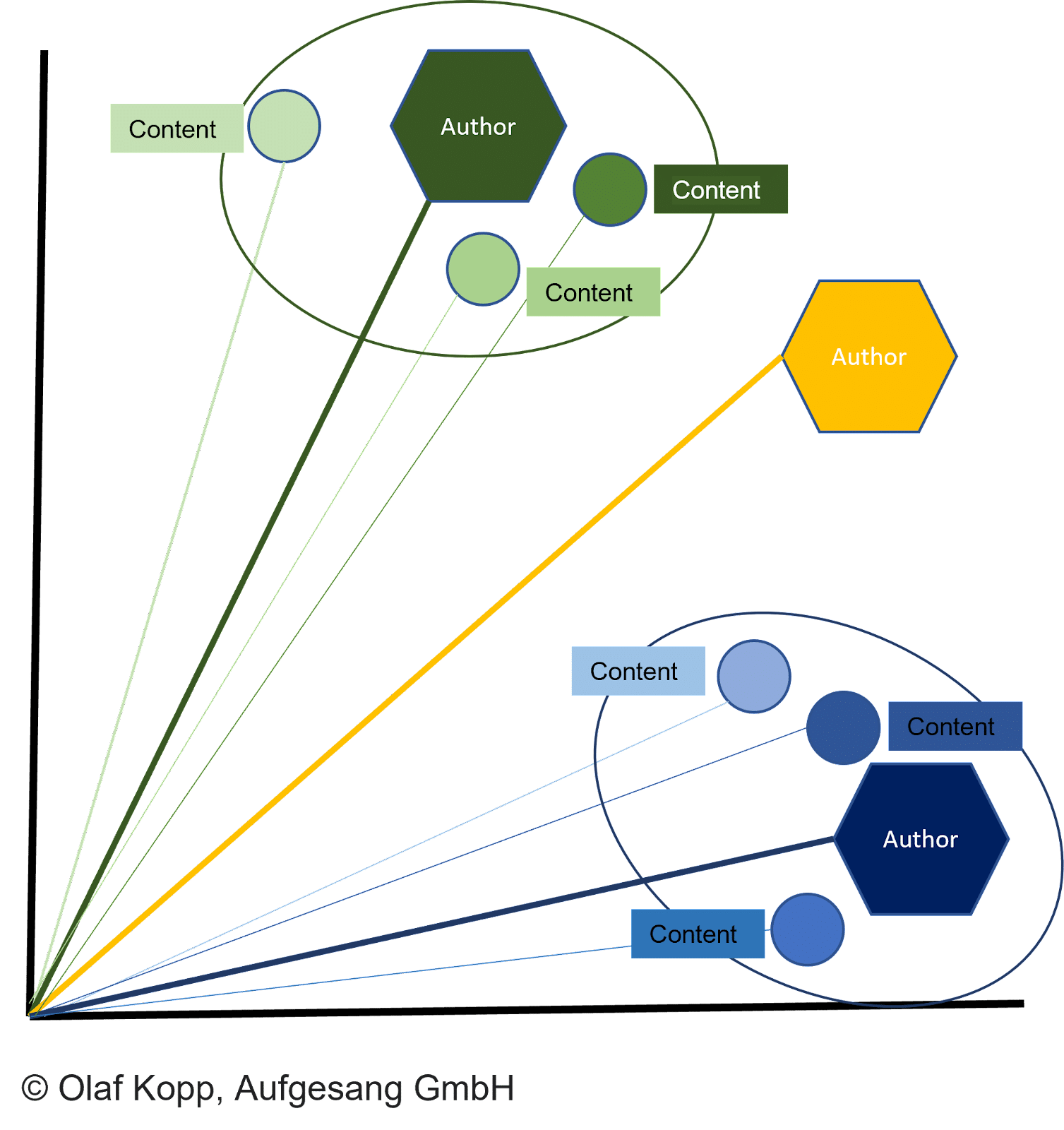
La distance entre les vecteurs de document et le vecteur d'auteur correspondant décrit la probabilité que l'auteur ait créé les documents.
Le document est attribué à l'auteur si la distance est inférieure aux autres vecteurs et qu'un certain seuil est atteint.
Cela peut également empêcher la création d'un document sous un faux drapeau. Le vecteur auteur peut alors être affecté à une entité auteur, comme déjà décrit, en utilisant le nom d'auteur spécifié dans le contenu.
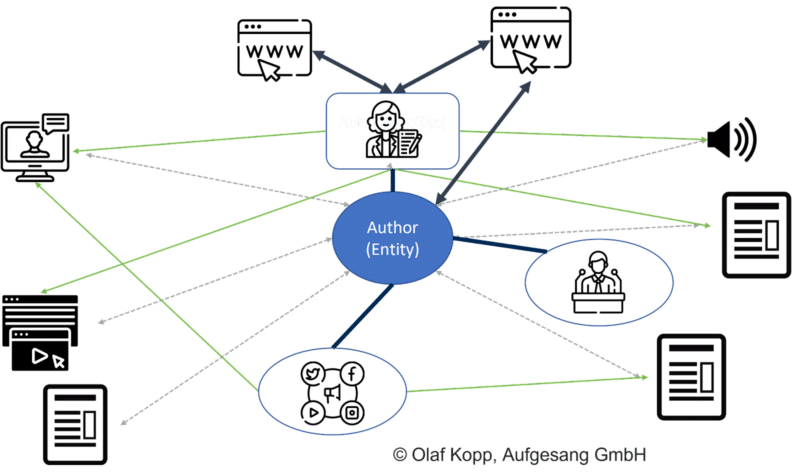
Les sources importantes d'informations sur les auteurs comprennent:
- Wikipédia Articles sur la personne.
- Profils d'auteurs.
- Profils des intervenants.
- Profils de médias sociaux.
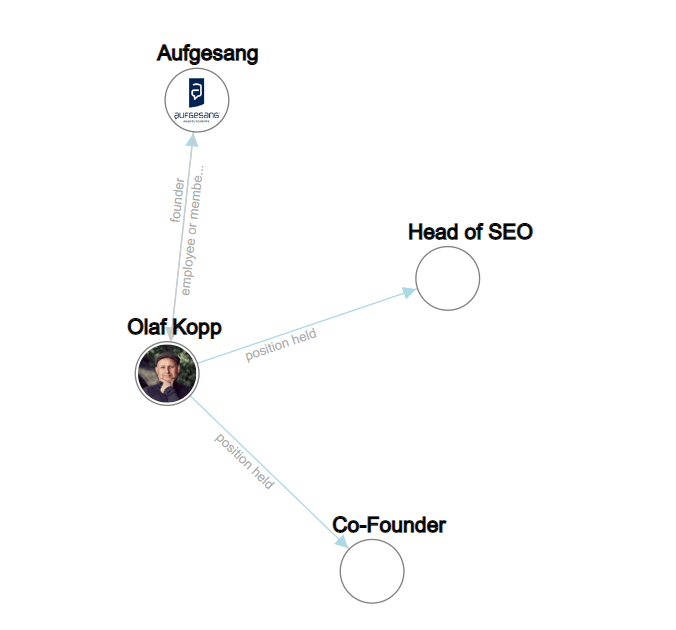
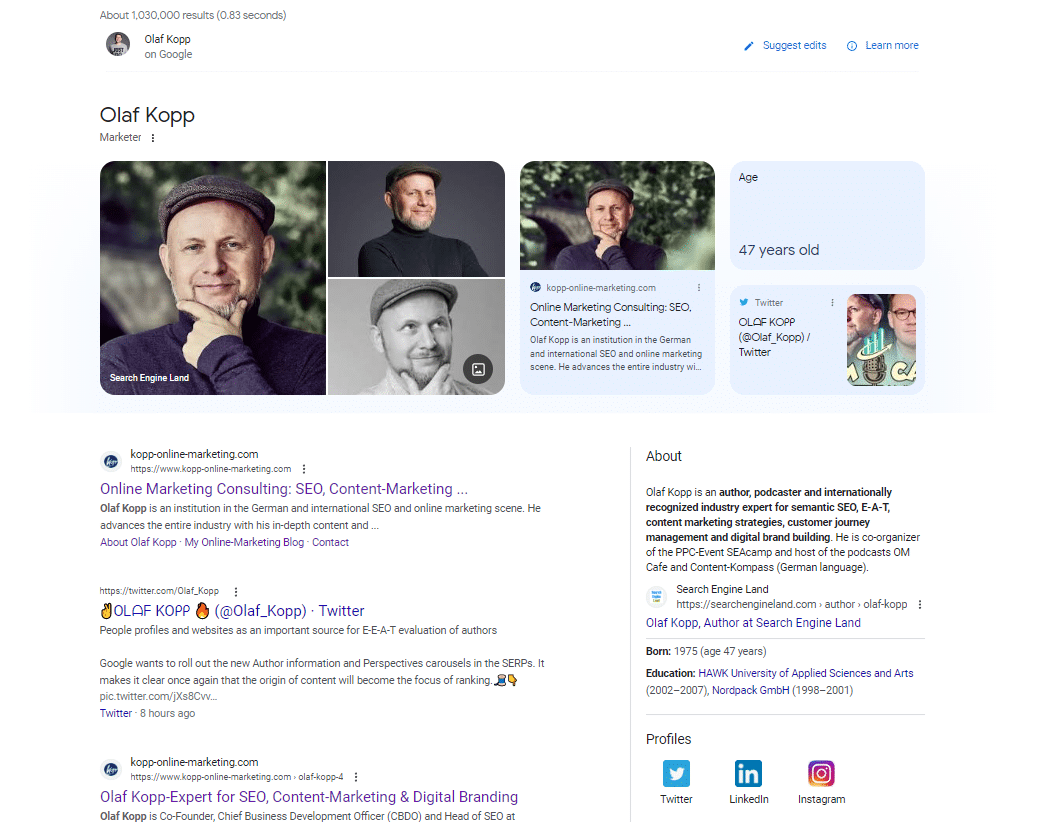
Si vous recherchez sur Google le nom d'une personne de type entité, vous trouverez des entrées Wikipedia, des profils de l'auteur et des URL de domaines qui sont directement connectés à l'auteur dans les 20 premiers résultats de recherche.
Dans les SERP mobiles, vous pouvez voir quelles sources Google établit une relation directe avec l'entité personne.
Google a reconnu tous les résultats au-dessus des icônes des profils de médias sociaux comme des sources avec une référence directe à l'entité.

Cette capture d'écran de la requête de recherche pour "olaf kopp" montre que les entités sont liées aux sources.
Il affiche également une nouvelle variante d'un panneau de connaissances. Il semble que je fasse partie d'un test bêta ici.
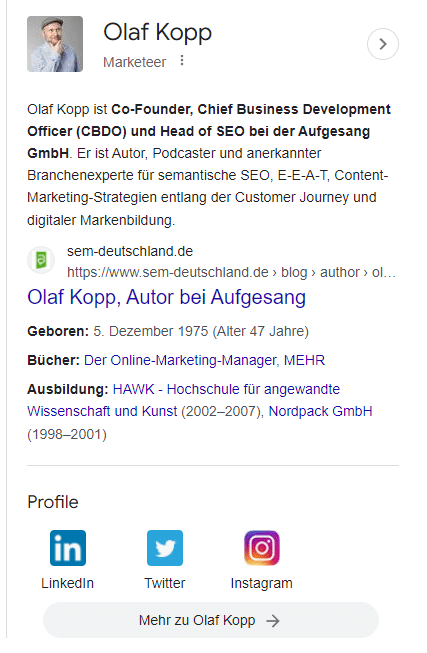
Dans cette capture d'écran, vous verrez qu'en plus des images et des attributs (âge), Google a directement lié mon domaine et mon profil de réseau social à mon entité et les fournit dans le panneau de connaissances.
Puisqu'il n'y a pas d'article Wikipédia sur moi, la description À propos est fournie à partir du profil de l'auteur sur Search Engine Land aux États-Unis et du profil de l'auteur du site Web de l'agence en Allemagne.
Les profils personnels sur le Web aident Google à contextualiser les auteurs et à identifier les profils de médias sociaux et les domaines associés à un auteur.
Les zones d'auteur ou les collections d'auteurs dans les profils d'auteur permettent à Google d'attribuer du contenu aux auteurs. Le nom de l'auteur est insuffisant comme identifiant car des ambiguïtés peuvent survenir.
Vous devez prêter attention aux descriptions des auteurs de chacun pour assurer la cohérence. Google peut les utiliser pour vérifier la validité de l'entité par rapport à l'autre.
Recevez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir conditions.
Brevets Google intéressants pour la notation EEAT des auteurs
Les brevets suivants partagent un aperçu des méthodologies possibles sur la façon dont Google identifie les auteurs, leur attribue du contenu et l'évalue en termes d'EEAT.
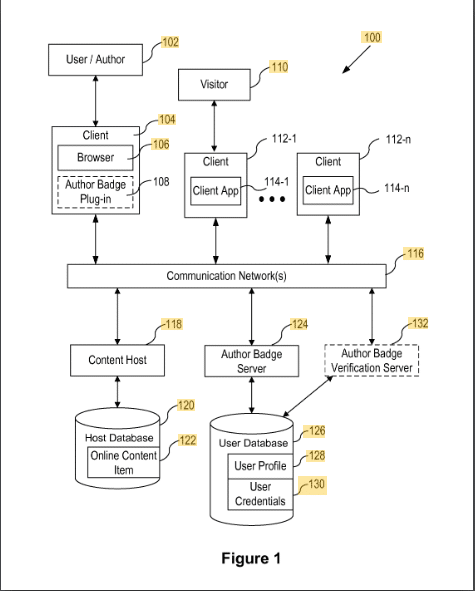
Badges d'auteur de contenu
Ce brevet décrit comment le contenu est attribué aux auteurs via un badge.
Le contenu est attribué à un badge d'auteur à l'aide d'un identifiant tel que l'adresse e-mail ou le nom de l'auteur. La vérification se fait via un addon dans le navigateur de l'auteur.

Génération de vecteurs d'auteur
Google a signé ce brevet en 2016, avec une durée allant jusqu'en 2036. Cependant, il n'y a eu que des demandes de brevet pour les États-Unis, ce qui suggère qu'il n'est pas encore utilisé dans les recherches Google dans le monde.
Le brevet décrit comment les auteurs sont représentés sous forme de vecteurs basés sur des données d'apprentissage.
Un vecteur devient un paramètre unique identifié en fonction du style d'écriture typique de l'auteur et du choix des mots.
De cette façon, le contenu qui n'était pas précédemment attribué à l'auteur peut lui être attribué, ou des auteurs similaires peuvent être regroupés en groupes.
Le classement du contenu peut ensuite être ajusté pour un ou plusieurs auteurs en fonction du comportement de l'utilisateur dans le passé dans la recherche (sur Discover, par exemple).
Ainsi, le contenu d'auteurs déjà découverts et ceux d'auteurs similaires seraient mieux classés.
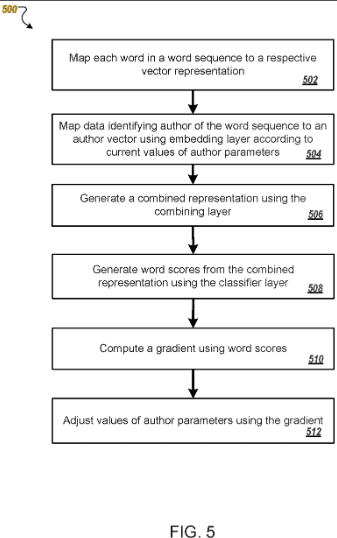
Ce brevet est basé sur ce que l'on appelle des incorporations, telles que les incorporations d'auteurs et de mots.
Aujourd'hui, les incorporations sont la norme technologique en matière d'apprentissage en profondeur et de traitement du langage naturel.
Par conséquent, il est évident que ces méthodes de Google seront également utilisées pour la reconnaissance et l'attribution des auteurs.
Notation de réputation d'un auteur
Ce brevet a été signé pour la première fois par Google en 2008 et a une durée minimale de 2029. Ce brevet fait à l'origine référence au projet Google Knol, fermé depuis longtemps.
Ainsi, c'est d'autant plus excitant que Google l'a de nouveau dessiné en 2017 sous le nouveau titre Monétisation des contenus en ligne. Knol a été fermé par Google en 2012.
Le brevet consiste à déterminer un score de réputation. Les facteurs suivants peuvent être pris en compte pour cela :
- Niveau d'encadrement de l'auteur.
- Publications dans des médias renommés.
- Nombre de parutions.
- Âge des versions récentes.
- Depuis combien de temps l'auteur travaille officiellement en tant qu'auteur.
- Nombre de liens générés par le contenu de l'auteur.
Un auteur peut avoir plusieurs scores de réputation par sujet et avoir plusieurs alias par domaine.
De nombreux points soulevés dans le brevet concernent une plate-forme fermée comme Knol. Par conséquent, ce brevet devrait suffire à ce stade.
Rang d'agent
Ce brevet Google a été signé pour la première fois en 2005 et a une durée minimale jusqu'en 2026.
En plus des États-Unis, il a également été enregistré en Espagne, au Canada et dans le monde, ce qui le rend susceptible d'être utilisé dans la recherche Google.
Le brevet décrit comment un contenu numérique est attribué à un agent (éditeur et/ou auteur). Ce contenu est classé en fonction d'un rang d'agent, entre autres.
Le rang d'agent est indépendant de l'intention de recherche de la requête de recherche et est déterminé sur la base des documents attribués à l'agent et de leurs backlinks.
Le rang d'agent se réfère exclusivement à une requête de recherche, à un groupe de requêtes de recherche ou à des domaines entiers.
"Les classements des agents peuvent également être calculés en option par rapport aux termes de recherche ou aux catégories de termes de recherche. Par exemple, les termes de recherche (ou les collections structurées de termes de recherche, c'est-à-dire les requêtes) peuvent être classés en sujets, par exemple, sports ou spécialités médicales, et un agent peut avoir un rang différent par rapport à chaque sujet.
Crédibilité d'un auteur de contenu en ligne
Ce brevet Google a été signé pour la première fois en 2008 et a une durée minimale de 2029, et n'a été enregistré qu'aux États-Unis jusqu'à présent.
Justin Lawyer l'a développé de la même manière que le score de réputation des brevets d'un auteur et est directement lié à l'utilisation dans les recherches.
Dans le brevet, on retrouve des points similaires à ceux du brevet précité.
Pour moi, c'est le brevet le plus excitant pour évaluer les auteurs en termes de confiance et d'autorité.
Ce brevet fait référence à divers facteurs qui peuvent être utilisés pour déterminer de manière algorithmique la crédibilité d'un auteur.
Il décrit comment un moteur de recherche peut classer les documents sous l'influence du facteur de crédibilité et du score de réputation d'un auteur.
Un auteur peut avoir plusieurs scores de réputation en fonction du nombre de sujets différents sur lesquels il publie du contenu.
Le score de réputation d'un auteur est indépendant de l'éditeur.
De nouveau dans ce brevet, il y a une référence aux liens comme un facteur possible dans une évaluation EEAT. Le nombre de liens vers du contenu publié peut influencer le score de réputation d'un auteur.
Les signaux possibles suivants pour un score de réputation sont mentionnés :
- Combien de temps l'auteur a produit du contenu dans un domaine.
- Conscience de l'auteur.
- Évaluations du contenu publié par les utilisateurs.
- Si un autre éditeur publie le contenu de l'auteur avec des notes supérieures à la moyenne.
- La quantité de contenu publié par l'auteur.
- Il y a combien de temps l'auteur a publié pour la dernière fois.
- Évaluations des publications précédentes sur un sujet similaire par l'auteur.
Autres informations intéressantes sur le score de réputation du brevet :
- Un auteur peut avoir plusieurs scores de réputation en fonction du nombre de sujets différents sur lesquels il publie du contenu.
- Le score de réputation d'un auteur est indépendant de l'éditeur.
- Le score de réputation peut être déclassé si du contenu ou des extraits dupliqués sont publiés plusieurs fois.
- Le nombre de liens vers le contenu publié peut influencer le score de réputation.
De plus, le brevet répond à un facteur de crédibilité pour les auteurs. Les facteurs d'influence suivants sont mentionnés :
- Des informations vérifiées sur le métier ou le rôle de l'auteur dans une entreprise. Il tient également compte de la crédibilité de l'entreprise.
- Pertinence de la profession par rapport aux sujets du contenu publié.
- Niveau d'études et de formation de l'auteur.
- L'expérience de l'auteur basée sur le temps. Plus un auteur publie depuis longtemps sur un sujet, plus il est crédible. L'expérience de l'auteur/éditeur peut être déterminée de manière algorithmique pour Google via la date de la première publication dans un domaine.
- Le nombre de contenus publiés sur un sujet. Si un auteur publie de nombreux articles sur un sujet, on peut supposer qu'il est un expert et qu'il a une certaine crédibilité.
- Temps écoulé jusqu'à la dernière version. Plus il s'est écoulé de temps depuis la dernière publication d'un auteur sur un sujet, plus un score de réputation possible pour ce sujet diminue. Plus le contenu est à jour, plus il est élevé.
- Mentions de l'auteur/éditeur dans les listes de prix et best-of.
Systèmes et procédés de reclassement de résultats de recherche classés
Ce brevet Google a été signé pour la première fois en 2013 et a une durée minimale jusqu'en 2033. Il a été enregistré aux États-Unis et dans le monde, ce qui rend probable que Google l'utilise.
Parmi les inventeurs du brevet figure Chung Tin Kwok, qui a participé à plusieurs brevets Google pertinents pour l'EEAT.
Le brevet décrit comment les moteurs de recherche, en plus des références au contenu de l'auteur, peuvent également considérer la proportion qu'il peut apporter à un corpus de documents thématiques dans une notation d'auteur.
"Dans certains modes de réalisation, la détermination du score d'auteur original pour l'entité respective comprend : l'identification d'une pluralité de parties de contenu dans l'index de contenu connu identifié comme étant associé à l'entité respective, chaque partie de la pluralité de parties représentant une quantité prédéterminée de données dans l'index de contenu connu ; et calculer un pourcentage de la pluralité des parties qui sont des premières instances des parties de contenu dans l'index de contenu connu."
Il décrit un reclassement des résultats de recherche basé sur la notation des auteurs, y compris la notation des citations. La notation des citations est basée sur le nombre de références aux documents d'un auteur.
Un autre critère de notation de l'auteur est la proportion de contenu qu'un auteur a contribué à un corpus de documents liés à un sujet.
"[W]ci-après, la détermination du score d'auteur pour une entité respective comprend : la détermination d'un score de citation pour l'entité respective, le score de citation correspondant à une fréquence à laquelle le contenu associé à l'entité respective est cité ; la détermination d'un score d'auteur original pour le entité respective, dans laquelle le score de l'auteur original correspond à un pourcentage de contenu associé à l'entité respective qui est une première instance du contenu dans un index de contenu connu ; et combiner le score de citation et le score de l'auteur original à l'aide d'une fonction prédéterminée pour produire la note de l'auteur."
Le but du brevet est d'identifier les "copieurs" et de déclasser leur contenu dans les classements, mais il peut aussi être utilisé pour l'évaluation générale des auteurs.
Facteurs clés pour évaluer un auteur
En plus des facteurs possibles pour une évaluation d'auteur énumérés dans les brevets ci-dessus, voici quelques autres à considérer (dont certains que j'ai déjà mentionnés dans mon article "14 façons dont Google peut évaluer EAT").
- Qualité globale du contenu sur un sujet : la qualité qu'un auteur livre à propos de son contenu sur un sujet dans son ensemble, indépendamment du domaine et du format, peut être un facteur pour l'EEAT. Les signaux pour cela peuvent être des signaux d'utilisateur, des liens et d'autres signaux de qualité au niveau du contenu.
- PageRank ou références au contenu de l'auteur.
- Cooccurrences de l'auteur dans le contenu (podcasts, vidéos, sites Web, PDF, livres) avec des sujets ou des termes pertinents.
- Cooccurrences de l'auteur dans les requêtes de recherche avec des sujets ou des termes pertinents.
Appliquer EEAT aux entités auteurs
Les méthodes d'apprentissage automatique permettent de reconnaître et de cartographier à grande échelle des structures sémantiques à partir de contenus non structurés.
Cela permet à Google de reconnaître et de comprendre beaucoup plus d'entités qu'auparavant dans le Knowledge Graph.
Par conséquent, la source du contenu joue un rôle de plus en plus important. EEAT peut être appliqué de manière algorithmique au-delà des documents, du contenu et du domaine.
Le concept peut également couvrir les entités auteurs du contenu (c'est-à-dire les auteurs et les organisations responsables du contenu).
Je pense que nous verrons un impact encore plus significatif de l'EEAT sur la recherche Google au cours des prochaines années. Ce facteur peut même être aussi important pour le classement que l'optimisation de la pertinence des contenus individuels.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.