
Comment tirer le meilleur parti de l'API Google Search Console à l'aide de regex
Publié: 2022-11-02Google Search Console est un outil incroyable qui fournit des données de recherche inestimables par de vrais utilisateurs directement à partir de Google. Bien que les graphiques et les tableaux soient conviviaux, une grande partie des données n'est pas accessible à partir de l'interface utilisateur.
La seule façon d'accéder à ces données cachées est d'utiliser l'API et d'extraire toutes les précieuses données de recherche qui sont à votre disposition - si vous savez comment. C'est possible avec les expressions régulières.
Voici comment optimiser l'API Google Search Console à l'aide d'expressions régulières, selon Eric Wu, vice-président de la croissance des produits chez Honey, une société PayPal, qui a pris la parole à SMX Advanced.
Diagnostiquer les problèmes de référencement avec GSC
Vous travaillez sur un site Web qui connaît une croissance stagnante ou en baisse ou une baisse de mise à jour principale ?
La plupart des professionnels du référencement se tournent vers Google Search Console (GSC) pour diagnostiquer ces problèmes.
(Ou si les ressources le permettent, vous pouvez même utiliser un outil payant comme Ryte ou créer votre propre plateforme.)
Heureusement pour la communauté SEO, les tableaux de bord Looker Studio (anciennement Google Data Studio) utiles pour l'analyse GSC ne manquent pas, notamment :
- Le tableau de bord gratuit d'Aleyda Solis, qui utilise les données du GSC pour identifier facilement les changements de classement potentiels ces derniers jours à partir de la mise à jour Google Core.
- Le tableau de bord de surveillance du trafic de recherche de Google, qui extrait désormais les données de trafic Discover et Google News.
- Search Console Explorer Studio d'Hannah Butler. (Et si vous souhaitez manipuler les données GSC de manière pratique et trouver des informations rapides, vous pouvez utiliser la feuille d'exploration de la console de recherche de Butler.)
Les tableaux de bord permettent aux référenceurs d'avoir un aperçu des différentes tendances au lieu d'utiliser GSC et de faire plusieurs clics pour accéder aux données dont vous avez besoin.
Mais si vous analysez des sites d'entreprise, vous pouvez rencontrer des obstacles.
- Looker Studio et Google Sheets se chargent lentement, en particulier lorsque vous traitez de grands sites.
- L'interface de GSC a une limite d'exportation de 1 000 lignes.
- GSC a un énorme problème d'échantillonnage. Selon Similar.ai, les équipes de référencement d'entreprise ratent 90 % de leurs mots clés GSC. Et si vous savez comment extraire les données, vous pouvez en fait obtenir 14 fois plus de mots-clés.
Surmonter le problème d'échantillonnage de GSC
Explorer for Search est un autre outil que vous pouvez utiliser pour l'analyse GSC. De Noah Learner et de l'équipe de Two Octobers, il est construit avec des pipelines de données utilisant l'API de GSC qui envoie ensuite des données à BigQuery (en contournant Google Sheets et en téléchargeant des fichiers CSV), puis visualise les informations avec Data Studio.
Avec cela, vous pouvez être sûr que vous accédez à presque toutes les données.
Il y a toujours une mise en garde en raison du problème d'échantillonnage de GSC, en particulier pour les grands sites de commerce électronique avec de nombreuses catégories différentes. GSC n'affichera pas nécessairement toutes les données provenant de ces répertoires.
Après avoir effectué divers tests pour extraire le maximum de données de l'API GSC, l'équipe Similar.ai a découvert un moyen de combler l'écart d'échantillonnage GSC.
Ils ont constaté qu'en ajoutant plus de sous-répertoires en tant que profils différents dans votre tableau de bord GSC, vous pouvez extraire encore plus de données car Google vous donne plus d'informations à ce niveau inférieur.
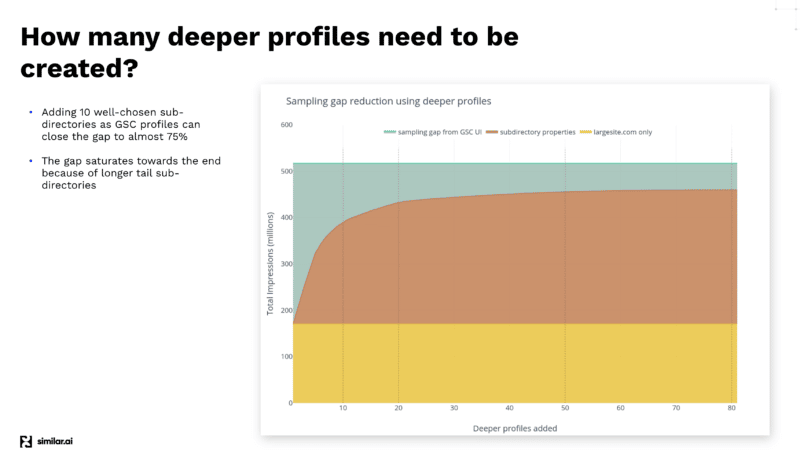
Par exemple, si vous consultez example.com/televisions et que vous ajoutez "televisions" comme sous-répertoire dans votre profil GSC, Google vous fournira uniquement les mots-clés et les informations sur les clics pour ce sous-répertoire et plus bas.
Et en ajoutant un grand nombre de ces différents sous-répertoires, vous pouvez extraire beaucoup plus d'informations.
Cela résout le problème d'échantillonnage, mais vous pouvez obtenir encore plus de données en utilisant des expressions régulières.
Obtenir plus de données GSC avec des expressions régulières
L'expression régulière, ou regex, est un outil puissant pour comprendre vos données.
En avril 2021, Google a ajouté la prise en charge des expressions régulières à GSC, offrant aux référenceurs plus de moyens de découper et de découper les données de recherche organiques.
Souvent, les données ne sont utiles que si vous pouvez les comprendre. Et regex aide à extraire des informations exploitables à partir des données riches de GSC.
Mais aussi puissantes soient-elles, les regex peuvent être difficiles à apprendre.
Le meilleur endroit pour comprendre et approfondir les expressions régulières est la documentation officielle de Google sur GitHub. (Google utilise RE2 dans ses produits, qui est une sorte d'expression régulière.)
Alors que regex est disponible dans toutes sortes de langages de programmation différents, vous le trouverez presque partout, même pour ceux qui modifient les fichiers .htaccess.
Dans les prochaines sections, vous trouverez des cas d'utilisation pour tirer parti de regex pour GSC.
Requêtes d'information Regex
Lorsque vous examinez des requêtes de recherche d'informations réelles dans GSC, vous souhaitez généralement comprendre :
- Comment les gens viennent-ils réellement sur votre site ?
- Quelles questions extraient-ils ?
Examiner ces choses d'un point de vue ponctuel, au sein de GSC, peut être difficile.
Vous êtes toujours à la recherche des mots « quoi », « comment », « pourquoi » puis « quand ».
Il existe plusieurs façons de rendre l'extraction de requêtes d'information moins fastidieuse avec regex.
Daniel K. Cheung a partagé une chaîne regex qui vous montrera toutes les requêtes contenant « quoi », « comment », « pourquoi » et « quand » qui ont obtenu un clic ou une impression :
-
"what|how|why|when"
Et cette chaîne regex partagée par Steve Toth fait monter d'un cran l'exemple précédent :
-
^(who|what|where|when|why|how)[" "]
Vous pouvez utiliser cette chaîne si vous souhaitez capturer des requêtes basées sur des questions commençant par "qui", "quoi", "où", "quand", "pourquoi" et "comment", puis suivies d'un espace.
C'est une excellente liste à utiliser lorsque vous recherchez n'importe quel type de mot qui commencerait une question :
- sont, peuvent, ne peuvent pas, pourraient, ne pouvaient pas, ont fait, n'ont pas fait, font, ne font pas, comment, si, est, n'est pas, devrait, ne devrait pas, était, n'était pas, étaient, n'étaient pas, quoi, quand, où, qui, qui, dont, pourquoi, sera, ne sera pas, serait, ne serait pas
Mettre tout cela sous forme de regex ressemblerait à ceci :
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
Dans cette chaîne de 178 caractères :
- Vous avez le caret (
^) qui vous indique que la requête doit commencer par ce mot : - Les mots sont séparés par des pipes (
|) au lieu de virgules. - Tous les mots sont mis entre parenthèses.
- Il y a une barre oblique inverse et le "s" (
\s) qui dénote un espace après le mot.
C'est bien, mais cela peut aussi devenir fastidieux à faire.
Ci-dessous, Wu a simplifié la liste de mots précédente pour qu'elle soit plus adaptée aux regex et plus courte, ce qui est idéal pour copier et coller. Le maintenir de cette façon contribue également à l'efficacité.
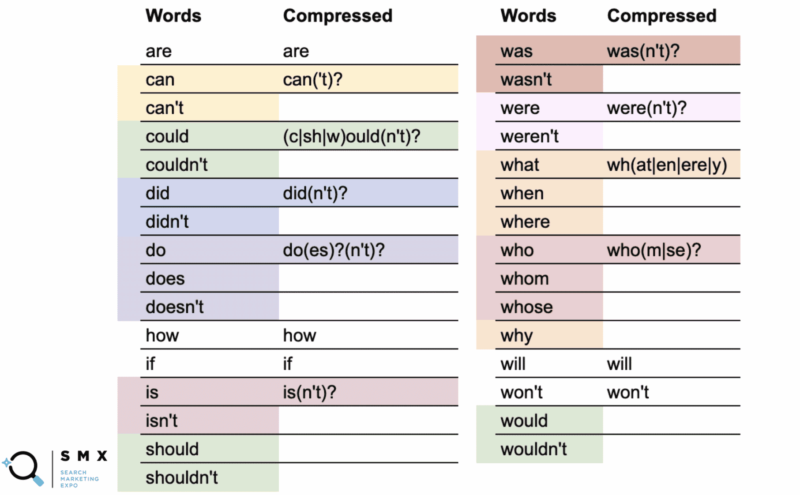
Dans la première colonne se trouvent les mots normaux et dans la deuxième colonne, la regex compressée.
Par exemple, le mot "can" utilise la version compressée can('t)? .
Ce que le point d'interrogation indique, c'est que tout ce qui se trouve entre parenthèses est facultatif. La syntaxe compressée vous permet de couvrir à la fois le mot "can" et "can't".
Plus intéressant encore, vous pouvez le faire avec could/couldn't, should/shouldn't et would/wouldn't où la partie -ould des mots est la base commune, comme (c|sh|w)ould(n't)? . Cette courte chaîne couvre ces six cas.
Bien que la simplification de cette longue liste de mots ait rendu la chaîne moins lisible, ce qui est génial, c'est qu'elle s'intègre davantage dans le champ regex et vous permet de copier-coller plus facilement.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
Si vous allez un peu plus loin, vous pouvez le compresser encore plus. Dans ce cas, Wu a réduit le nombre de caractères de 135 à 113 caractères.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Les expressions régulières peuvent devenir vraiment compliquées. Si vous obtenez une chaîne regex de quelqu'un d'autre et que vous souhaitez lever l'ambiguïté de ce qui fait quoi, vous pouvez utiliser Regexper pour vous aider à la visualiser.
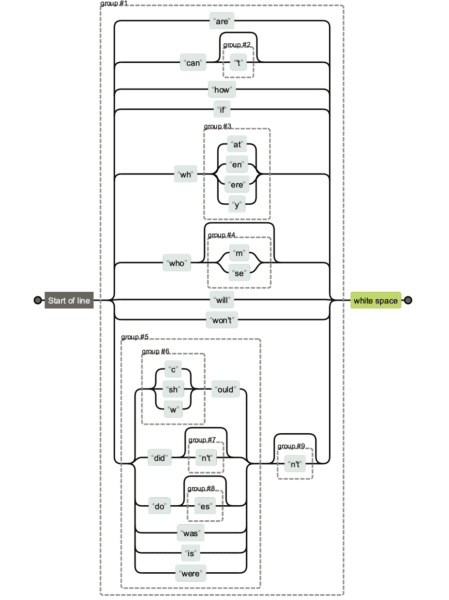
Vous trouverez ci-dessous une comparaison des différentes versions de chaînes de regex. Il est plus facile de maintenir le premier, et évidemment plus difficile de maintenir et de lire le dernier.

Mais parfois, le nombre de caractères compte vraiment, surtout lorsque vous avez des expressions régulières plus longues.
Les limites du filtre Regex pour GSC sont de 4 096 caractères, selon Google Search Advocate Daniel Waisberg.
Cela semblerait un peu. Cependant, si vous avez un site de commerce électronique et que vous devez ajouter des noms de domaine, des sous-domaines ou des répertoires plus longs, vous atteindrez probablement cette limite.
Requêtes de marque Regex
Un autre cas où vous pouvez commencer à atteindre la limite de caractères regex dans GSC est lorsque vous l'utilisez pour des requêtes de marque.
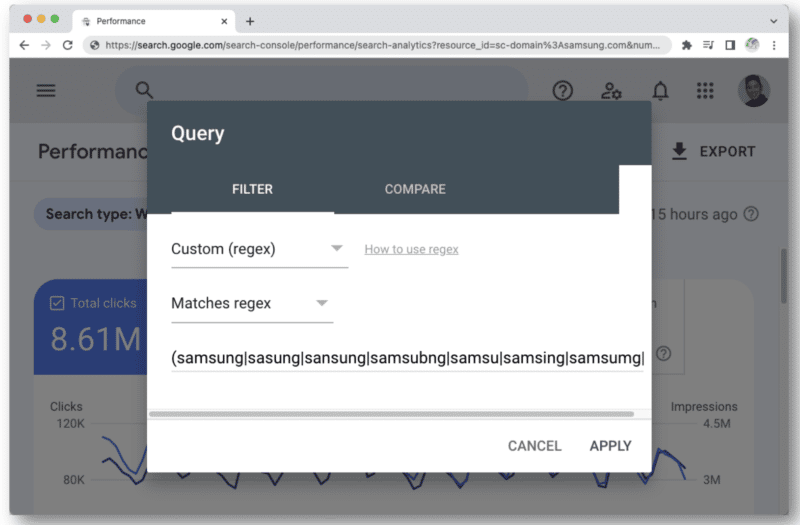
Lorsque vous pensez à tous les différents types de fautes d'orthographe d'un nom de marque qu'une personne pourrait taper, vous rencontrerez rapidement ce nombre de 4 096 caractères. Par exemple:
- aamaung, damsung, mamsang, sam chanté, samaung, samdung, samesung, sameung, samgsung, samgung, samsang, samsaung, samsgu, samshgg, samshng, samsing, samsnug, samsung, samsu, samsuag, samsubg, samsubng, samsug, samsumg, samsumng , samsun g, samsunb, samsund, samsund, samsunh, samsunt …
C'est là que comprendre regex aide. Avec cette chaîne, vous pouvez saisir le nom de la marque « samsung » ainsi que les fautes d'orthographe :
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
Souvent, les gens orthographieront mal les parties médianes du mot. Mais en général, ils obtiennent le bon format et la bonne longueur et vous pouvez aborder votre syntaxe de cette façon.

Pour les fautes d'orthographe dans les requêtes de marque, tenez compte des points suivants :
- Lettres principales qui composent la requête de marque.
- Consonnes .
- Lettres entourant les consonnes dures .

En rouge, les consonnes dures que les gens ne manquent généralement pas lorsqu'ils tapent un nom de marque. Ce sont les lettres principales qui composent cette marque particulière. Pour "samsung", le "s" au début, le "m" au milieu, puis "n" et "g" à la fin.
Les lettres bleues entourant ces consonnes principales sur le clavier sont celles que les gens tapent généralement mal. Dans l'exemple, autour de « s », vous voyez les « a », « d » et « z ». (Bien que la disposition soit différente pour les claviers internationaux, le concept est toujours le même.)
La chaîne regex ci-dessus capture toutes les variantes possibles de "samsung".
L'autre astuce majeure ici est dans [az\s]{1,4} .
Sous forme de regex, cela dit essentiellement, "Je veux faire correspondre n'importe quelle lettre" a "à" z ", ou un espace, une à quatre fois."
Cela capture toutes ces fautes d'orthographe étranges qui peuvent se produire au milieu d'une requête de marque - où une personne peut potentiellement appuyer plusieurs fois sur la même touche ou appuyer accidentellement sur espace.
De plus, le nom de la marque a une certaine longueur ("samsung" a sept caractères). Les gens ne finiront probablement pas par taper 20 à 50 caractères.
Donc, dans cette expression régulière, nous supposons qu'entre "s" et "m" dans "samsung", quelqu'un va mal saisir 1 à 4 caractères. Et puis de « m » à « g » à la fin, ils saisiront de manière erronée 1 à 6 caractères, espaces compris.
L'ajout de tout cela vous permet de capturer de manière exhaustive les nombreuses variantes d'une requête de marque.
L'autre chose à noter est que le nom de la marque peut apparaître dans différentes parties de la requête.

Nous devons donc nous assurer que le nom de la marque lui-même est capturé. Il doit être soit :
- Au début de la requête.
- Au milieu de la requête (donc entourée d'espaces).
- Ou à la fin de la requête.
L'expression régulière pour cela est la suivante :
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
Cela capture toutes les requêtes où le nom de marque "samsung" est soit au début, au milieu ou à la fin.
- Début de chaîne =
^ - Entouré d'espaces =
\s - Fin de chaîne =
$
Le billet de JC Chouinard, Regular Expressions (RegEx) in Google Search Console, plonge encore plus profondément dans les exemples de regex.
Regex et l'API GSC en action
Les expressions régulières se sont révélées utiles pour Wu et son équipe lorsqu'ils ont travaillé avec un client qui a rencontré des baisses de trafic suite à une mise à jour principale.
Après avoir examiné les différents problèmes du site de commerce électronique, ils ont découvert que le problème résidait dans certaines pages de détails du produit.
Ils avaient besoin de segmenter les types de page pour les analyser dans GSC. Mais c'était une tâche complexe en raison des différentes structures d'URL pour les produits américains et internationaux.

Les URL de produits internationales du site incluaient des codes de langue et de pays, contrairement aux URL de produits américains.
Même l'utilisation de la syntaxe regex était délicate car des lettres et des tirets existent dans le slug, les catégories et les sous-catégories du produit. De plus, ils devaient filtrer les URL internationales des produits pour ne capturer que les pages américaines.
Pour obtenir toutes les pages de destination et de détail des produits américains ( pas les pages i18n), ils ont proposé les chaînes regex suivantes :
Inclure : /([^/]+/){1,2}p?
Exclure : /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Voici une ventilation :

L'équipe voulait faire correspondre la catégorie, la sous-catégorie et tous les produits, ils ont donc inclus :
- Tout caractère qui n'est pas une barre oblique =
[^/]+ - 1 ou 2 répertoires =
/){1,2} - Parfois suivi d'un slug de produit =
p?
Un caret ( ^ ) signifie généralement le début de la chaîne. Mais lorsqu'il est entre parenthèses (comme dans [^/] ), cela indique une négation (c'est-à-dire « rien dans cette boîte »).
Donc cette chaîne /([^/]+/){1,2}p? signifie "Je veux n'importe quel nombre de caractères qui ne sont pas une barre oblique, menant à une barre oblique (qui indique le répertoire) et parfois suivis de la lettre 'p' (le préfixe des slugs de produit)."
Dans le même temps, l'équipe ne voulait pas faire correspondre la combinaison de pays et de langue qui contenait également des lettres et des tirets, elle a donc exclu :
- Tout répertoire de 2 lettres =
[a-zA-Z]{2} - Combo 2 lettres + 2 lettres langue-pays =
[a-zA-Z]{2}-[a-zA-Z]{2}
Créer une expression régulière pour faire correspondre tous les codes de langue et de pays à eux seuls serait fastidieux en raison de toutes les combinaisons possibles, ils n'ont donc pas pu aborder cela comme pour les requêtes d'information (où chaque type de combinaison était exclu).
Mais même après avoir créé ces chaînes regex, ils ont eu un problème.
Dans Google Search Console, il n'y a qu'un seul champ pour coller une chaîne regex. Vous devrez choisir entre Correspond à la regex ou Ne correspond pas à la regex – vous ne pouvez pas utiliser les deux en même temps.
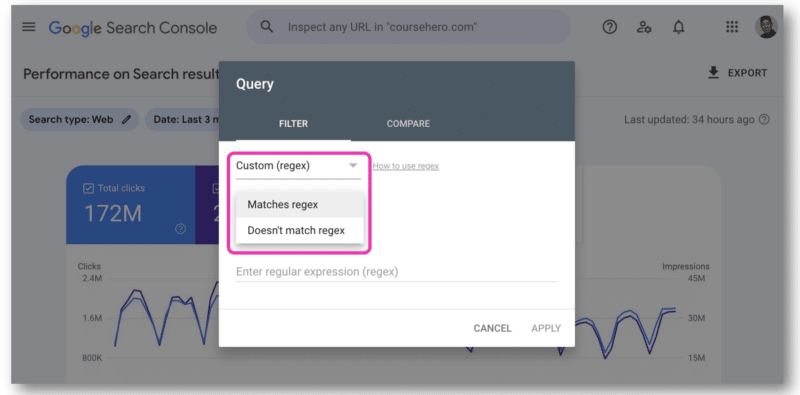
C'est là que l'API GSC est devenue utile car elle permet de joindre des chaînes regex.
Dans la documentation de l'API Google Search Console, il y a un lien Essayer maintenant .
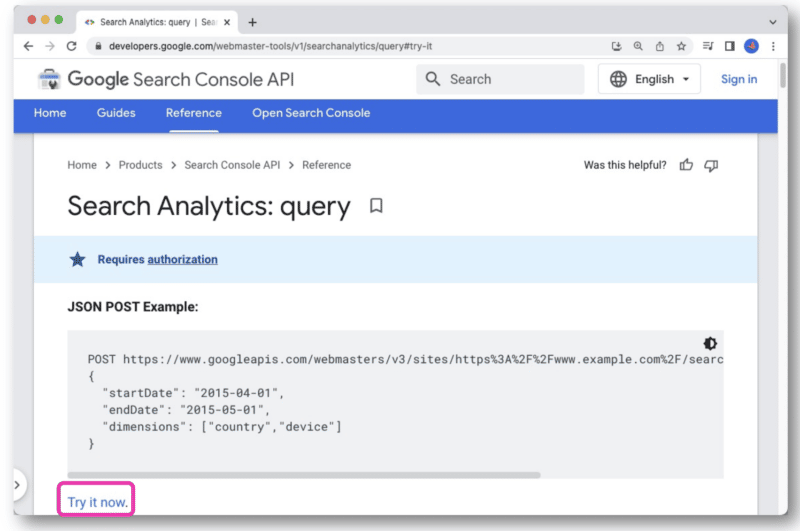
Une fois cliqué, il ouvrira une console qui vous permettra de sélectionner un site et de faire votre requête API via la vue Web.
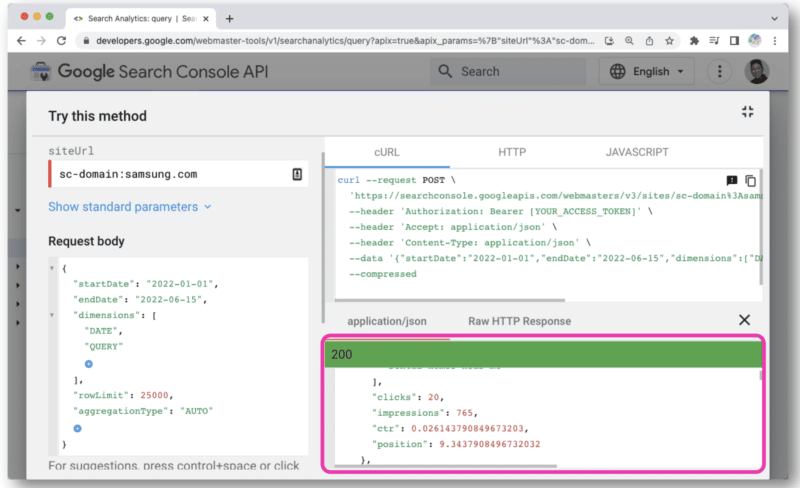
Mais pour mieux gérer les requêtes API, Wu recommande d'utiliser Postman sur le bureau ou Paw (qui est natif de Mac).
Postman vous permet de créer des requêtes et de les enregistrer pour plus tard. Et si vous avez accès à d'autres sites, vous n'avez pas à créer une nouvelle requête à chaque fois. Vous changez simplement le nom du site avec une variable, puis faites plusieurs demandes.
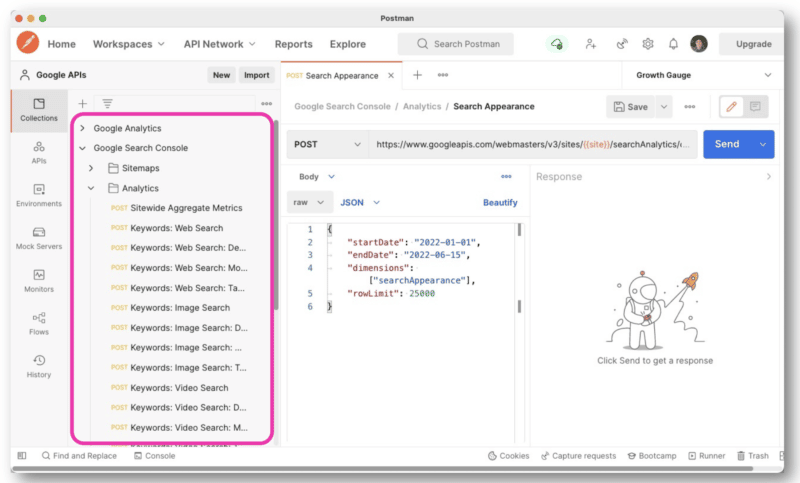
Paw, en revanche, est beaucoup plus facile à parcourir et à utiliser.
Pour accéder à l'API, vous devrez obtenir vos clés API. (Voici un tutoriel utile de Chouinard.)
Une fois que vous aurez obtenu ces informations, vous aurez votre ID client et vos secrets client, que vous ajouterez à votre authentification OAuth 2.0 dans Postman ou Paw.
À partir de là, vous pourrez vous connecter avec votre compte normal.
Wu a principalement fait des demandes d'API GSC en utilisant les chaînes regex dans Paw. La requête est saisie au milieu de l'interface.
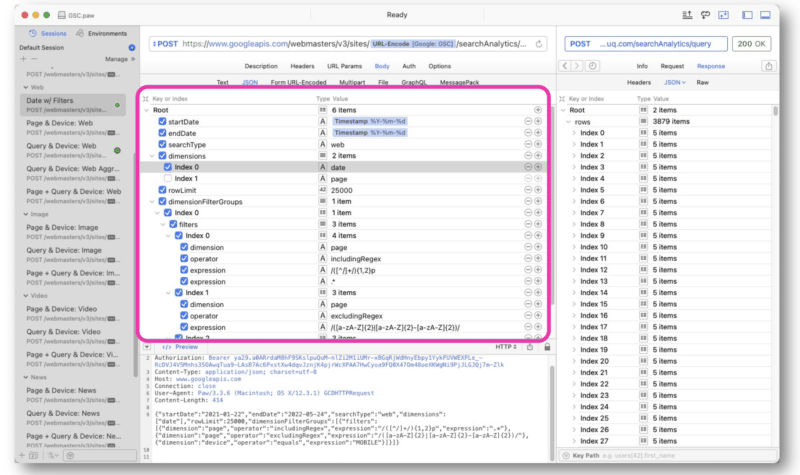
La réponse de Google est similaire à celle de la vue Web de l'API GSC. Les données peuvent ensuite être exportées pour être traitées.
Étant donné que les données sont au format JSON, les informations peuvent être désordonnées et difficiles à lire.

Pour cela, vous pouvez utiliser un processeur JSON de ligne de commande gratuit et open-source appelé JQ pour imprimer les informations.

Les données ne sont pas très utiles jusqu'à ce que vous les intégriez dans une feuille de calcul. Pipe dans le fichier que vous avez exporté de Paw vers JQ. Ouvrez-le, puis parcourez chaque ligne en enregistrant chaque élément afin de pouvoir les exporter vers un fichier CSV.
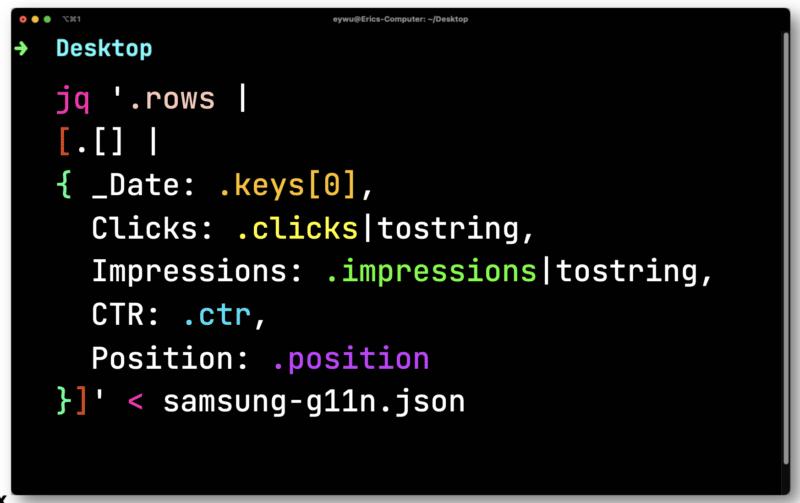
Ici, vous devrez convertir les clics et les impressions qui sont des flottants (un nombre qui a une décimale). Les deux doivent être convertis en chaînes compatibles avec un CSV.
JQ affichera alors le format beaucoup plus simple suivant.
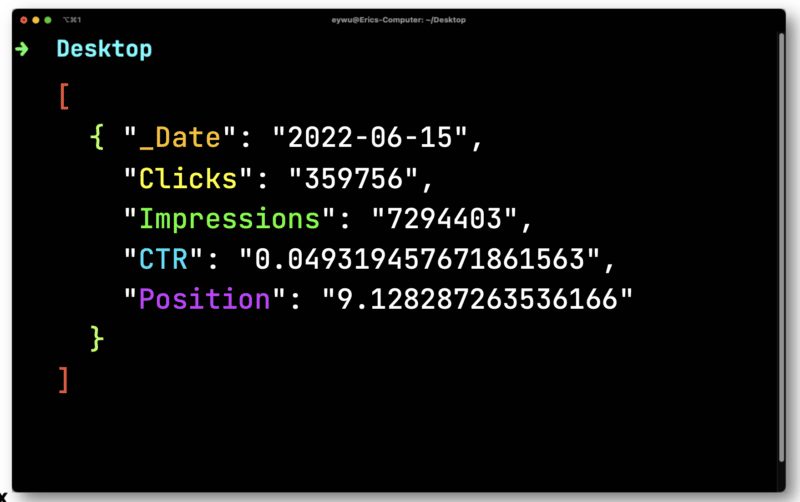
Ensuite, vous utiliserez Dasel pour prendre ce format, puis en faire un CSV.
Et voici le résultat final.
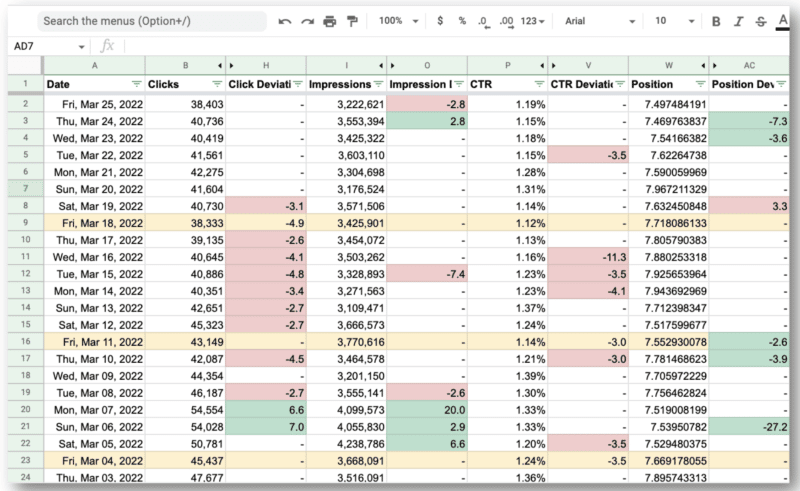
Ce qui est incroyable pour l'équipe de Wu, c'est qu'ils ont pu utiliser l'API Google Search Console et les expressions régulières pour :
- Filtrez toutes les requêtes internationales et regardez uniquement les États-Unis où ils rencontraient les principaux problèmes.
- Identifiez les jours où le site a rencontré des problèmes.
Regarder : Tirer le meilleur parti de l'API Google Search Console
Vous trouverez ci-dessous la vidéo complète de la présentation SMX Advanced de Wu.