
Google utilise-t-il un système de type ChatGPT pour la détection et le classement des sites Web de spam et de contenu IA ?
Publié: 2023-02-01Le titre est intentionnellement trompeur - mais uniquement dans la mesure où l'utilisation du terme "ChatGPT" est concernée.
"ChatGPT-like" vous permet immédiatement, le lecteur, de connaître le type de technologie auquel je fais référence, au lieu de décrire le système comme "un modèle de génération de texte comme GPT-2 ou GPT-3". (De plus, ce dernier ne serait vraiment pas aussi cliquable…)
Ce que nous examinerons dans cet article est un article Google plus ancien mais très pertinent de 2020, "Les modèles génératifs sont des prédicteurs non supervisés de la qualité des pages : une étude à grande échelle".
De quoi parle le papier ?
Commençons par la description des auteurs. Ils introduisent ainsi le sujet :
"Beaucoup ont soulevé des inquiétudes quant aux dangers potentiels des générateurs de texte neuronaux dans la nature, en grande partie en raison de leur capacité à produire du texte d'apparence humaine à grande échelle.
Des classificateurs formés pour faire la distinction entre le texte généré par l'homme et celui généré par la machine ont récemment été employés pour surveiller la présence de texte généré par la machine sur le Web [29]. Cependant, peu de travail a été fait pour appliquer ces classificateurs à d'autres usages, malgré leur propriété attrayante de ne nécessiter aucune étiquette - seulement un corpus de texte humain et un modèle génératif. Dans ce travail, nous montrons, grâce à une évaluation humaine rigoureuse, que les discriminateurs prêts à l'emploi de l'homme par rapport à la machine servent de puissants classificateurs de la qualité de la page . Autrement dit, les textes qui semblent générés par une machine ont tendance à être incohérents ou inintelligibles. Pour comprendre la présence de pages de faible qualité dans la nature, nous appliquons les classificateurs à un échantillon d'un demi-milliard de pages Web en anglais.
Ce qu'ils disent essentiellement, c'est qu'ils ont découvert que les mêmes classificateurs développés pour détecter la copie basée sur l'IA, en utilisant les mêmes modèles pour la générer, peuvent être utilisés avec succès pour détecter un contenu de mauvaise qualité.
Bien sûr, cela nous laisse avec une question importante :
S'agit-il d'une causalité (c'est-à-dire, le système le détecte-t-il parce qu'il est vraiment bon) ou d' une corrélation (c'est-à-dire, beaucoup de spams actuels sont-ils créés d'une manière facile à contourner avec de meilleurs outils) ?
Avant d'explorer cela, examinons certains des travaux des auteurs et leurs conclusions.
La mise en place
Pour référence, ils ont utilisé les éléments suivants dans leur expérience :
- Deux modèles de génération de texte , le détecteur GPT-2 basé sur RoBERTa d'OpenAI (un détecteur qui utilise le modèle RoBERTa avec une sortie GPT-2 et prédit s'il est probablement généré par l'IA ou non) et le modèle GLTR, qui a également accès au top Sortie GPT-2 et fonctionne de manière similaire.
Nous pouvons voir un exemple de la sortie de ce modèle sur le contenu que j'ai copié de l'article ci-dessus :
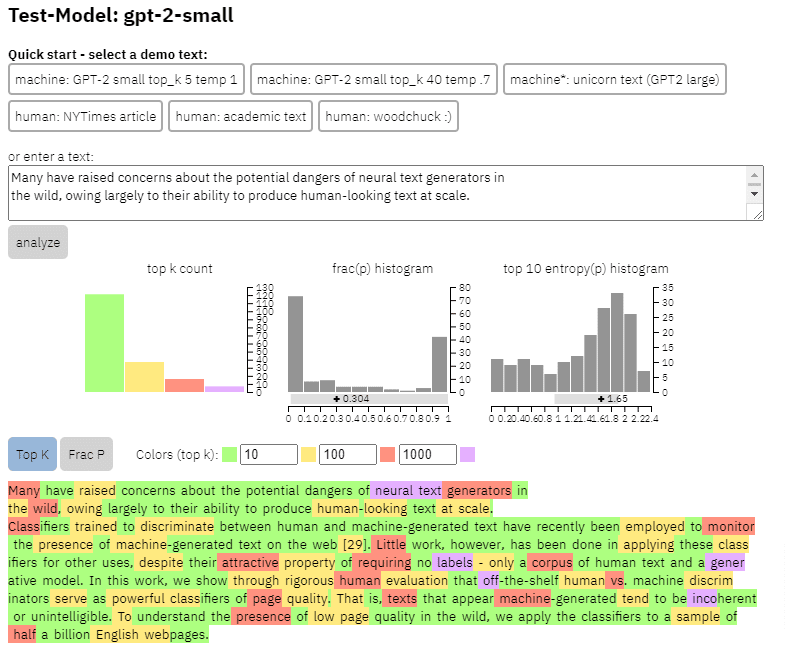
- Trois ensembles de données Web500M (un échantillonnage aléatoire de 500 millions de pages Web en anglais), GPT-2 Output (250 000 générations de texte GPT-2) et Grover-Output (ils ont généré en interne 1,2 million d'articles à l'aide du modèle Grover-Base pré-formé, qui a été conçu pour détecter les fake news).
- Spam Baseline , un classificateur formé sur l'ensemble de données Enron Spam Email. Ils ont utilisé ce classificateur pour établir le numéro de qualité linguistique qu'ils attribueraient, donc si le modèle déterminait qu'un document n'est pas un spam avec une probabilité de 0,2, le score de qualité linguistique (LQ) attribué était de 0,2.
Recevez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir conditions.
Un aparté sur la prévalence du spam
Je voulais prendre un aparté rapide pour discuter de certaines découvertes intéressantes sur lesquelles les auteurs sont tombés. L'un est illustré dans la figure suivante (Figure 3 de l'article):
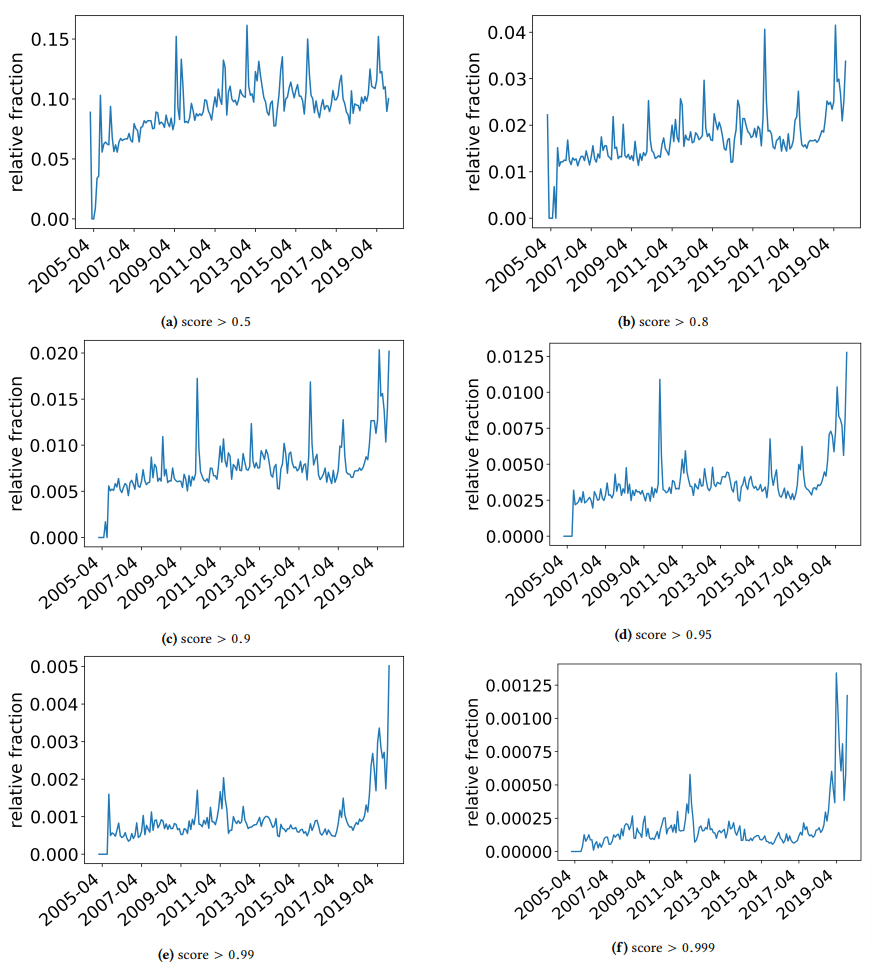
Il est important de noter le score sous chaque graphique. Un nombre vers 1.0 se déplace vers une confiance que le contenu est du spam. Ce que nous constatons alors, c'est qu'à partir de 2017 - et avec un pic en 2019 - il y avait une prévalence de documents de mauvaise qualité.
De plus, ils ont constaté que l'impact d'un contenu de mauvaise qualité était plus élevé dans certains secteurs que dans d'autres (en se rappelant qu'un score plus élevé reflète une probabilité plus élevée de spam).
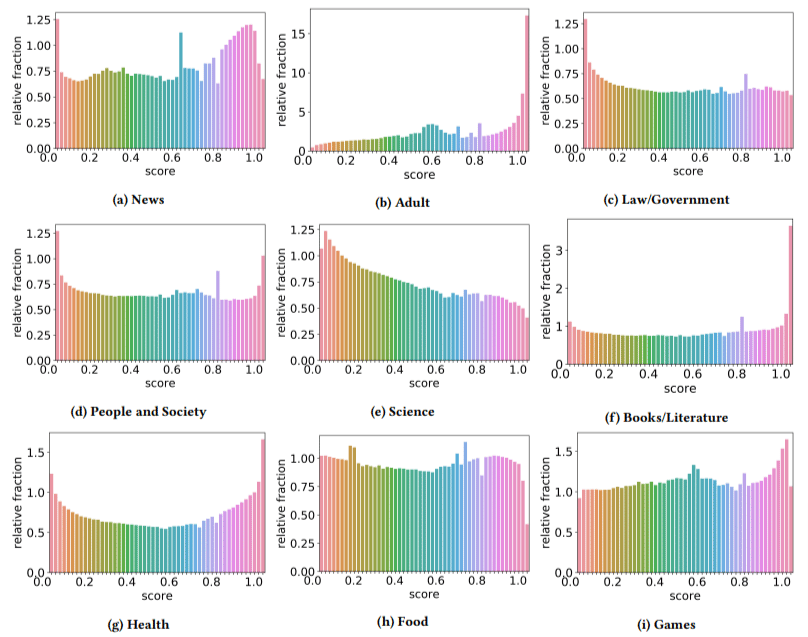
Je me suis gratté la tête sur quelques-uns d'entre eux. Adulte avait du sens, évidemment.
Mais les livres et la littérature ont été un peu une surprise. Et la santé aussi - jusqu'à ce que les auteurs présentent le Viagra et d'autres sites de "produits de santé pour adultes" comme "santé" et les fermes d'essais comme "littérature" - c'est-à-dire.
Leurs trouvailles
Outre ce dont nous avons discuté sur les secteurs et le pic en 2019, les auteurs ont également trouvé un certain nombre de choses intéressantes dont les référenceurs peuvent apprendre et doivent garder à l'esprit, d'autant plus que nous commençons à nous appuyer sur des outils comme ChatGPT.
- Le contenu de mauvaise qualité a tendance à être moins long (avec un pic à 3 000 caractères).
- Les systèmes de détection formés pour déterminer si le texte a été écrit par une machine ou non sont également bons pour classer le contenu de bas niveau par rapport au contenu de haut niveau.
- Ils appellent notre contenu conçu pour les classements comme un coupable spécifique, bien que je soupçonne qu'ils se réfèrent à la poubelle que nous savons tous ne devrait pas être là.
Les auteurs ne prétendent pas qu'il s'agit d'une solution ultime, mais plutôt d'un point de départ et je suis sûr qu'ils ont fait avancer la barre au cours des deux dernières années.
Une note sur le contenu généré par l'IA
Les modèles linguistiques se sont également développés au fil des ans. Alors que GPT-3 existait au moment de la rédaction de cet article, les détecteurs qu'ils utilisaient étaient basés sur GPT-2, qui est un modèle nettement inférieur.
GPT-4 est probablement à nos portes et Sparrow de Google devrait sortir plus tard cette année. Cela signifie que non seulement la technologie s'améliore des deux côtés du champ de bataille (générateurs de contenu contre moteurs de recherche), mais que les combinaisons seront plus faciles à mettre en jeu.
Google peut-il détecter le contenu créé par Sparrow ou GPT-4 ? Peut-être.
Mais qu'en est-il s'il a été généré avec Sparrow puis envoyé à GPT-4 avec une invite de réécriture ?
Un autre facteur à retenir est que les techniques utilisées dans cet article sont basées sur des modèles auto-régressifs. En termes simples, ils prédisent un score pour un mot en fonction de ce qu'ils prédisent que ce mot recevra ceux qui le précèdent.
Au fur et à mesure que les modèles développent un degré de sophistication plus élevé et commencent à créer des idées complètes à la fois plutôt qu'un mot suivi d'un autre, la détection de l'IA peut glisser.
D'un autre côté, la détection de contenu simplement merdique devrait s'intensifier - ce qui peut signifier que le seul contenu "de mauvaise qualité" qui gagnera est généré par l'IA.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.