
L'écosystème Hadoop et ses composants
Publié: 2015-04-23Big Data est le mot à la mode qui circule dans l'industrie informatique depuis 2008. La quantité de données générées par les réseaux sociaux, la fabrication, la vente au détail, les actions, les télécommunications, l'assurance, la banque et les soins de santé dépasse largement notre imagination.
Avant l'avènement d'Hadoop, le stockage et le traitement des mégadonnées étaient un défi de taille. Mais maintenant que Hadoop est disponible, les entreprises ont réalisé l'impact commercial du Big Data et comment la compréhension de ces données stimulera la croissance. Par exemple:
• Les secteurs bancaires ont une meilleure chance de comprendre les clients fidèles, les débiteurs défaillants et les transactions frauduleuses.
• Les secteurs du commerce de détail disposent maintenant de suffisamment de données pour prévoir la demande.
• Les secteurs manufacturiers n'ont pas besoin de dépendre des mécanismes coûteux des tests de qualité. La capture des données des capteurs et leur analyse révéleraient de nombreux modèles.
• E-Commerce, les réseaux sociaux permettent de personnaliser les pages en fonction des intérêts des clients.
• Les marchés boursiers génèrent une énorme quantité de données, corréler de temps en temps révélera de belles idées.
Le Big Data a de nombreuses applications utiles et perspicaces.
Hadoop est la réponse directe pour le traitement du Big Data. L'écosystème Hadoop est une combinaison de technologies qui ont un avantage efficace dans la résolution de problèmes commerciaux.
Comprenons les composants de l'écosystème Hadoop pour créer des solutions adaptées à un problème métier donné.
Écosystème Hadoop :
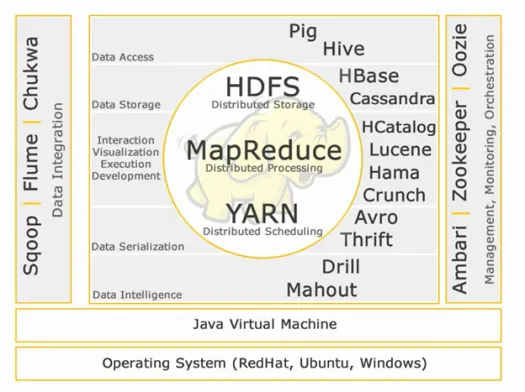

Cœur Hadoop :
HDFS :
HDFS signifie Hadoop Distributed File System pour la gestion de grands ensembles de données avec un volume, une vitesse et une variété élevés. HDFS implémente une architecture maître-esclave. Le maître est le nœud de nom et l'esclave est le nœud de données.
Caractéristiques:
• Évolutif
• Fiable
• Matériel de base
HDFS est bien connu pour le stockage Big Data.
Carte Réduire :
Map Reduce est un modèle de programmation conçu pour traiter de gros volumes de données distribuées. La plate-forme est construite à l'aide de Java pour une meilleure gestion des exceptions. Map Reduce comprend deux démons, Job tracker et Task Tracker.
Caractéristiques:
• Programmation fonctionnelle.
• Fonctionne très bien sur Big Data.
• Peut traiter de grands ensembles de données.
Map Reduce est le principal composant connu pour le traitement du Big Data.
FIL:
YARN signifie encore un autre négociateur de ressources. Il est également appelé MapReduce 2 (MRv2). Les deux principales fonctionnalités de Job Tracker dans MRv1, la gestion des ressources et la planification/surveillance des travaux, sont divisées en démons distincts qui sont ResourceManager, NodeManager et ApplicationMaster.
Caractéristiques:
• Meilleure gestion des ressources.
• Évolutivité
• Allocation dynamique des ressources du cluster.
Accès aux données :
Porc:
Apache Pig est un langage de haut niveau construit sur MapReduce pour analyser de grands ensembles de données avec de simples programmes d'analyse de données ad hoc. Pig est également connu sous le nom de langage de flux de données. Il est très bien intégré avec python. Il est initialement développé par Yahoo.
Caractéristiques principales du porc :
• Facilité de programmation
• Opportunités d'optimisation
• Extensibilité.
Les scripts Pig seront convertis en interne en programmes de réduction de carte.

Ruche:
Apache Hive est un autre langage de requête de haut niveau et une infrastructure d'entrepôt de données construite sur Hadoop pour fournir la synthèse, la requête et l'analyse des données. Il est initialement développé par Yahoo et rendu open source.
Caractéristiques saillantes de la ruche :
• SQL comme langage de requête appelé HQL.
• Partitionnement et compartimentage pour un traitement plus rapide des données.
• Intégration avec des outils de visualisation comme Tableau.
Les requêtes Hive seront converties en interne en programmes de réduction de carte.
Si vous souhaitez devenir analyste de données volumineuses, ces deux langages de haut niveau sont incontournables !!

Stockage de données:
Hbase :
Apache HBase est une base de données NoSQL conçue pour héberger de grandes tables avec des milliards de lignes et des millions de colonnes au-dessus des machines matérielles Hadoop. Utilisez Apache Hbase lorsque vous avez besoin d'un accès en lecture/écriture aléatoire et en temps réel à votre Big Data.
Caractéristiques:
• Lectures et écritures strictement cohérentes. Dans les opérations de mémoire.
• API Java facile à utiliser pour l'accès client.
• Bien intégré avec cochon, ruche et sqoop.
• Est un système cohérent et tolérant aux partitions dans le théorème CAP.

Cassandre :
Cassandra est une base de données NoSQL conçue pour une évolutivité linéaire et une haute disponibilité. Cassandra est basée sur le modèle clé-valeur. Développé par Facebook et connu pour sa réponse plus rapide aux requêtes.
Caractéristiques:
• Index de colonne
• Prise en charge de la dénormalisation
• Vues matérialisées
• Puissante mise en cache intégrée.


Interaction -Visualisation- exécution-développement :
Hcatalogue :
HCatalog est une couche de gestion de table qui permet l'intégration de métadonnées de ruche pour d'autres applications Hadoop. Il permet aux utilisateurs de différents outils de traitement de données comme Apache pig, Apache MapReduce et Apache Hive de lire et d'écrire plus facilement des données.
Caractéristiques:
• Vue tabulaire pour différents formats.
• Notifications de disponibilité des données.
• API REST permettant aux systèmes externes d'accéder aux métadonnées.
Lucène :
Apache LuceneTM est une bibliothèque de moteur de recherche de texte hautes performances et complète entièrement écrite en Java. Il s'agit d'une technologie adaptée à presque toutes les applications nécessitant une recherche en texte intégral, en particulier multiplateforme.
Caractéristiques:
• Indexation évolutive et haute performance.
• Algorithmes de recherche puissants, précis et efficaces.
• Solution multiplateforme.
Hama :
Apache Hama est un framework distribué basé sur l'informatique Bulk Synchronous Parallel (BSP). Capable et bien connu pour les calculs scientifiques massifs comme les algorithmes matriciels, graphiques et de réseau.
Caractéristiques:
• Modèle de programmation simple
• Bien adapté aux algorithmes itératifs
• FIL pris en charge
• Apprentissage automatique non supervisé par filtrage collaboratif.
• Regroupement K-Means.
Croquer:
Apache crunch est conçu pour mettre en pipeline des programmes MapReduce simples et efficaces. Ce framework est utilisé pour écrire, tester et exécuter des pipelines MapReduce.
Caractéristiques:
• Axé sur le développeur.
• Abstractions minimales
• Modèle de données flexible.
Sérialisation des données :
Avro :
Apache Avro est un framework de sérialisation de données indépendant du langage. Conçu pour la portabilité du langage, permettant aux données de survivre potentiellement au langage pour le lire et l'écrire.

Épargne:
Thrift est un langage développé pour créer des interfaces permettant d'interagir avec les technologies basées sur Hadoop. Il est utilisé pour définir et créer des services pour de nombreuses langues.
Intelligence des données :
Percer:
Apache Drill est un moteur de requête SQL à faible latence pour Hadoop et NoSQL.
Caractéristiques:
• Agilité
• Souplesse
• Familiarité.

Cornac:
Apache Mahout est une bibliothèque d'apprentissage automatique évolutive conçue pour créer des analyses prédictives sur le Big Data. Mahout a maintenant des implémentations apache spark pour plus de rapidité dans le calcul de la mémoire.
Caractéristiques:
• Filtrage collaboratif.
• Classification
• Regroupement
• Réduction de la dimensionnalité

Intégration de données:
Apache Sqoop :

Apache Sqoop est un outil conçu pour les transferts de données en masse entre les bases de données relationnelles et Hadoop.
Caractéristiques:
• Importation et exportation vers et depuis HDFS.
• Importer et exporter vers et depuis Hive.
• Importer et exporter vers HBase.
Canal Apache :
Flume est un service distribué, fiable et disponible pour collecter, agréger et déplacer efficacement de grandes quantités de données de journaux.
Caractéristiques:
• Robuste
• Tolérance de panne
• Architecture simple et flexible basée sur des flux de données en continu.

Apache Chukwa :
Collecteur de journaux évolutif utilisé pour surveiller les grands systèmes de fichiers distribués.
Caractéristiques:
• S'adapte à des milliers de nœuds.
• Livraison fiable.
• Doit pouvoir stocker les données indéfiniment.

Gestion, Surveillance et Orchestration :
Apache Ambari :
Ambari est conçu pour simplifier la gestion hadoop en fournissant une interface pour le provisionnement, la gestion et la surveillance des clusters Apache Hadoop.
Caractéristiques:
• Provisionner un cluster Hadoop.
• Gérer un cluster Hadoop.
• Surveiller un cluster Hadoop.

Apache Zookeeper :
Zookeeper est un service centralisé conçu pour maintenir les informations de configuration, nommer, fournir une synchronisation distribuée et fournir des services de groupe.
Caractéristiques:
• Sérialisation
• Atomicité
• Fiabilité
• API simple

Apache Oozie :
Oozie est un système de planification de flux de travail pour gérer les tâches Apache Hadoop.
Caractéristiques:
• Système évolutif, fiable et extensible.
• Prend en charge plusieurs types de travaux Hadoop tels que Map-Reduce, Hive, Pig et Sqoop.
• Simple et facile à utiliser.

Nous discuterons des composants en détail dans les prochains articles. Restez à l'écoute.