
Installation de Hadoop avec Ambari
Publié: 2015-12-11Tout ce que vous voulez savoir sur l'installation de Hadoop avec Ambari
Apache Hadoop est devenu un cadre logiciel de facto pour une informatique fiable, évolutive, distribuée et à grande échelle. Contrairement à d'autres systèmes informatiques, il apporte le calcul aux données plutôt que d'envoyer des données au calcul. Hadoop a été créé en 2006 chez Yahoo par Doug Cutting sur la base d'un article publié par Google. Au fur et à mesure que Hadoop a mûri, au fil des ans, de nombreux nouveaux composants et outils ont été ajoutés à son écosystème pour améliorer sa convivialité et ses fonctionnalités. Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, Sqoop etc. pour n'en nommer que quelques-uns.
Pourquoi Ambari ?
Avec la popularité croissante de Hadoop, de nombreux développeurs se lancent dans cette technologie pour en avoir un avant-goût. Mais comme on dit, Hadoop n'est pas pour les timides, de nombreux développeurs ne pouvaient même pas franchir la barrière de l'installation de Hadoop. De nombreuses distributions proposent un bac à sable de VM préinstallé pour essayer des choses, mais cela ne vous donne pas la sensation d'une informatique distribuée. Cependant, l'installation d'un multi-nœud n'est pas une tâche facile et avec un nombre croissant de composants, il est très délicat de gérer autant de paramètres de configuration. Heureusement, Apache Ambari vient ici à notre secours !
Qu'est-ce qu'Ambari ?
Apache Ambari est un outil Web pour le provisionnement, la gestion et la surveillance des clusters Apache Hadoop. Ambari fournit un tableau de bord pour visualiser la santé du cluster, comme les cartes thermiques et la possibilité de visualiser visuellement les applications MapReduce, Pig et Hive, ainsi que des fonctionnalités permettant de diagnostiquer leurs caractéristiques de performance de manière conviviale. Il dispose d'une interface utilisateur très simple et interactive pour installer divers outils et effectuer diverses tâches de gestion, de configuration et de surveillance. Ci-dessous, nous vous expliquons les différentes étapes de l'installation de Hadoop et de ses divers composants de l'écosystème sur un cluster à plusieurs nœuds.
L'architecture Ambari est illustrée ci-dessous
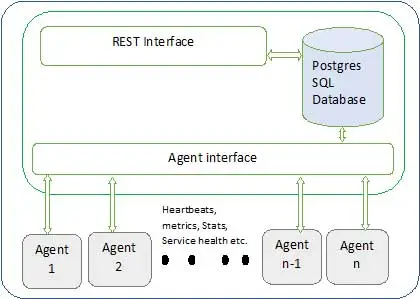
Ambari a deux composants
- Serveur Ambari - Il s'agit du processus maître qui communique avec les agents Ambari installés sur chaque nœud participant au cluster. Cela a une instance de base de données postgres qui est utilisée pour maintenir toutes les métadonnées liées au cluster.
- Agent Ambari - Ce sont des agents actifs pour Ambari sur chaque nœud. Chaque agent envoie périodiquement son propre état de santé ainsi que différentes métriques, l'état des services installés et bien d'autres choses. Selon le maître décide de l'action suivante et renvoie à l'agent pour qu'il agisse.
Comment installer Ambari ?
L'installation d'Ambari est une tâche facile avec quelques commandes.
Nous couvrirons l'installation d'Ambari et la configuration du cluster. On suppose que nous avons 4 nœuds. Nœud1, Nœud2, Nœud3 et Nœud4. Et nous choisissons Node1 comme serveur Ambari.
Ce sont des étapes d'installation sur le système basé sur RHEL, pour debian et d'autres systèmes, les étapes varieront peu.
- Installation d'Ambari : –
Depuis le nœud du serveur Ambari (nœud 1 comme nous l'avons décidé)
je. Télécharger le référentiel public Ambari

Cette commande ajoutera le référentiel Hortonworks Ambari dans yum qui est un gestionnaire de packages par défaut pour les systèmes RHEL.
ii.Installer Ambari RPMS

Cela prendra un certain temps et installera Ambari sur ce système.

iii. Configuration du serveur Ambari
La prochaine chose à faire après l'installation d'Ambari est de configurer Ambari et de le configurer pour provisionner le cluster.
L'étape suivante s'occupera de cela


iv. Démarrez le serveur et connectez-vous à l'interface utilisateur Web
Démarrez le serveur avec

Nous pouvons maintenant accéder à l'interface utilisateur Web d'Ambari (hébergée sur le port 8080).
Connectez-vous à Ambari avec le nom d'utilisateur par défaut "admin" et le mot de passe par défaut "admin"
Configuration du cluster Hadoop
1. Page de destination
Cliquez sur "Lancer l'assistant d'installation" pour démarrer la configuration du cluster
2. Nom du cluster
Donnez à votre cluster un bon nom.
Remarque : Il s'agit simplement d'un nom simple pour le cluster, ce n'est pas si important, alors ne vous inquiétez pas et choisissez un nom pour celui-ci.
3. Sélection de la pile
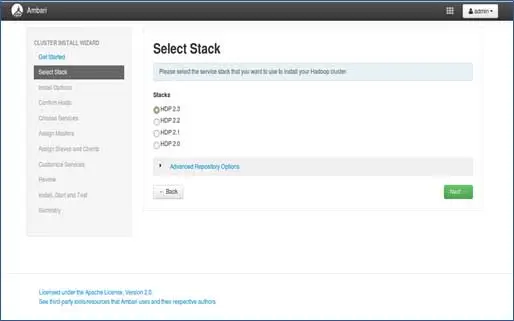
Cette page répertorie les piles disponibles pour l'installation. Chaque pile est pré-packagée avec le composant de l'écosystème Hadoop. Ces piles proviennent de Hortonworks. (Nous pouvons également installer Hadoop simple. Nous en parlerons dans des articles ultérieurs).
4. Entrée des hôtes et entrée de la clé SSH

Avant d'aller plus loin dans cette étape, nous devrions avoir une configuration SSH sans mot de passe pour tous les nœuds participants.
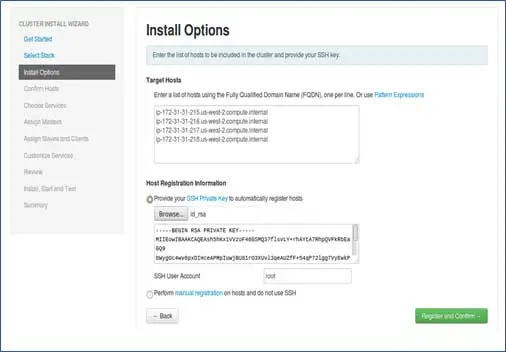
Ajoutez les noms d'hôtes des nœuds, une seule entrée sur chaque ligne. [ Ajoutez un nom de domaine complet qui peut être obtenu par la commande hostname –f]. Sélectionnez la clé privée utilisée lors de la configuration du mot de passe sans SSH et le nom d'utilisateur à l'aide duquel la clé privée a été créée.
5. Statut d'enregistrement des hôtes
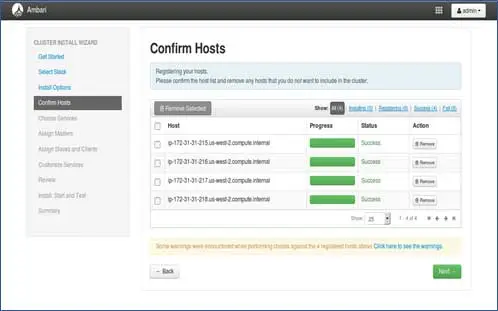
Vous pouvez voir certaines opérations en cours d'exécution, ces opérations incluent la configuration de l'agent Ambari sur chaque nœud, la création de configurations de base sur chaque nœud. Une fois que nous voyons TOUT VERT, nous sommes prêts à passer à autre chose. Parfois, cela peut prendre du temps car il installe peu de packages.

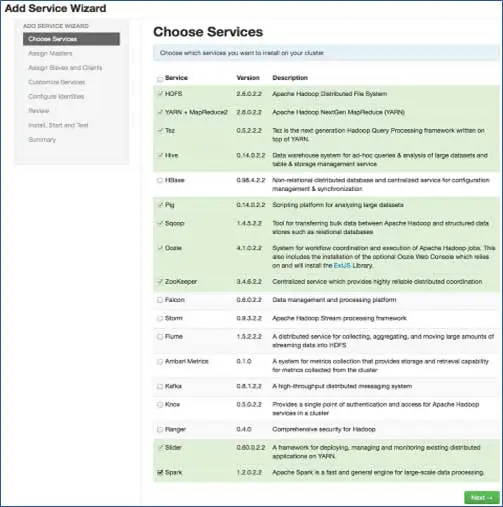
6. Choisissez les services que vous souhaitez installer
Selon les piles sélectionnées à l'étape 3, nous avons le nombre de services que nous pouvons installer dans le cluster. Vous pouvez choisir celui que vous voulez. Ambari sélectionne intelligemment les services dépendants si vous ne l'avez pas sélectionné. Par exemple, vous avez sélectionné HBase mais pas Zookeeper, il vous demandera la même chose et ajoutera également Zookeeper au cluster.
7. Cartographie des services maîtres avec les nœuds
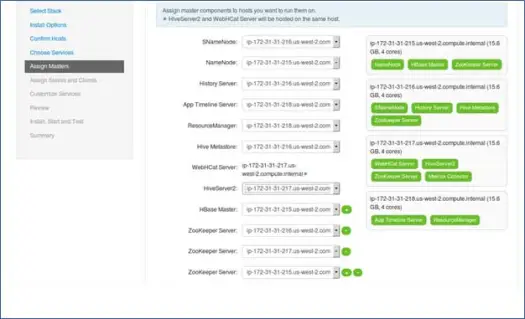
Comme vous le savez, l'écosystème Hadoop dispose d'outils basés sur une architecture maître-esclave. Dans cette étape, nous allons associer les processus maîtres au nœud. Ici, assurez-vous d'équilibrer correctement votre cluster. Gardez également à l'esprit que les services principaux et secondaires tels que Namenode et Namenode secondaire ne se trouvent pas sur la même machine.

8. Cartographie des esclaves avec les nœuds
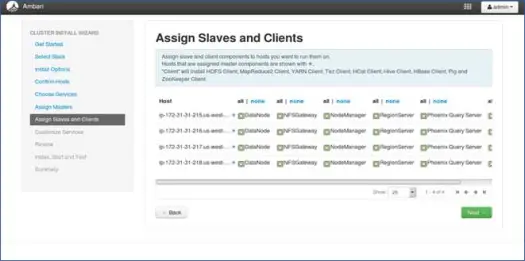
Comme pour les maîtres, mappez les services esclaves sur les nœuds. En général, tous les nœuds auront un processus esclave en cours d'exécution au moins pour les Datanodes et les Nodemanagers.
9. Personnalisez les services
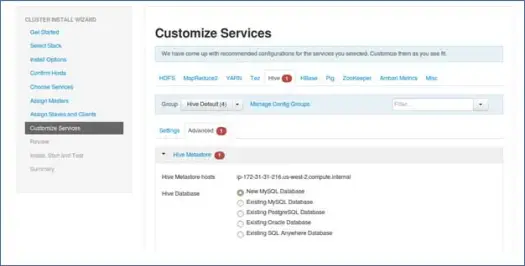
C'est une page très importante pour les administrateurs.
Ici, vous pouvez configurer les propriétés de votre cluster pour le rendre plus adapté à vos cas d'utilisation.
En outre, il aura certaines propriétés requises telles que le mot de passe du métastore Hive (si la ruche est sélectionnée), etc. Celles-ci seront pointées avec une erreur rouge comme des symboles.
10. Examinez et commencez le provisionnement
Assurez-vous de revoir la configuration du cluster avant le lancement, car cela évitera de définir des configurations incorrectes sans le savoir.
11. Lancez et restez en arrière jusqu'à ce que le statut devienne VERT.
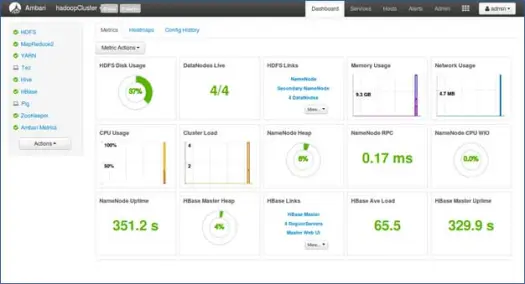
Prochaines étapes
Ouais ! Nous avons installé avec succès Hadoop et tous les composants sur tous les nœuds du cluster. Nous pouvons maintenant commencer à jouer avec Hadoop.
Ambari exécute un travail de comptage de mots MapReduce pour vérifier si tout fonctionne correctement. Vérifions le journal du travail exécuté par l'utilisateur ambari-qa.
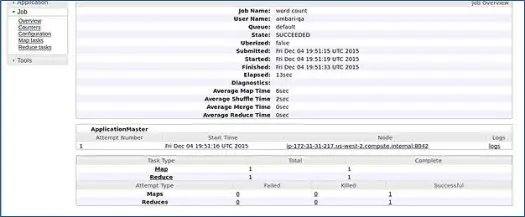
Comme vous pouvez le voir dans la capture d'écran ci-dessus, le travail WordCount s'est terminé avec succès. Cela confirme que notre cluster fonctionne bien.
Conclusion
Voilà, nous avons maintenant appris à installer Hadoop et ses composants sur le cluster multi-nœuds à l'aide d'un simple outil Web appelé Apache Ambari. Apache Ambari nous fournit une interface plus simple et nous évite beaucoup d'efforts d'installation, de surveillance et de gestion qui auraient été très fastidieux avec autant de composants et leurs différentes étapes d'installation et contrôles de surveillance.
Permettez-moi de vous laisser avec un hack

Le programme d'installation d'Ambari vérifie /etc/lsb-release pour obtenir les détails du système d'exploitation. Dans Linux Mint, le même fichier pour la version Ubuntu se trouve sous /etc/upstream-release/lsb-release. Pour tromper l'installateur, remplacez simplement le premier par le second (vous devez d'abord sauvegarder le fichier).

À un moment donné après la fin de votre installation, vous pouvez restaurer l'original avec :

PS Ceci est un hack sans aucune garantie, cela a fonctionné pour moi alors j'ai pensé le partager avec vous.
Vous êtes développeur/dev-ops et avez besoin d'installer Hadoop rapidement. Nous avons une bonne nouvelle pour vous, Ambari fournit un moyen d'ignorer le processus complet de l'assistant et le processus d'installation terminé avec un seul script, et je l'apporterai dans le prochain article, alors restez à l'écoute et jusque-là, Happy Hadooping !