
Comment s'appuyer sur les LLM peut conduire à un désastre SEO
Publié: 2023-07-10"ChatGPT peut passer la barre."
"GPT obtient un A + à tous les examens."
"GPT passe l'examen d'entrée au MIT avec brio."
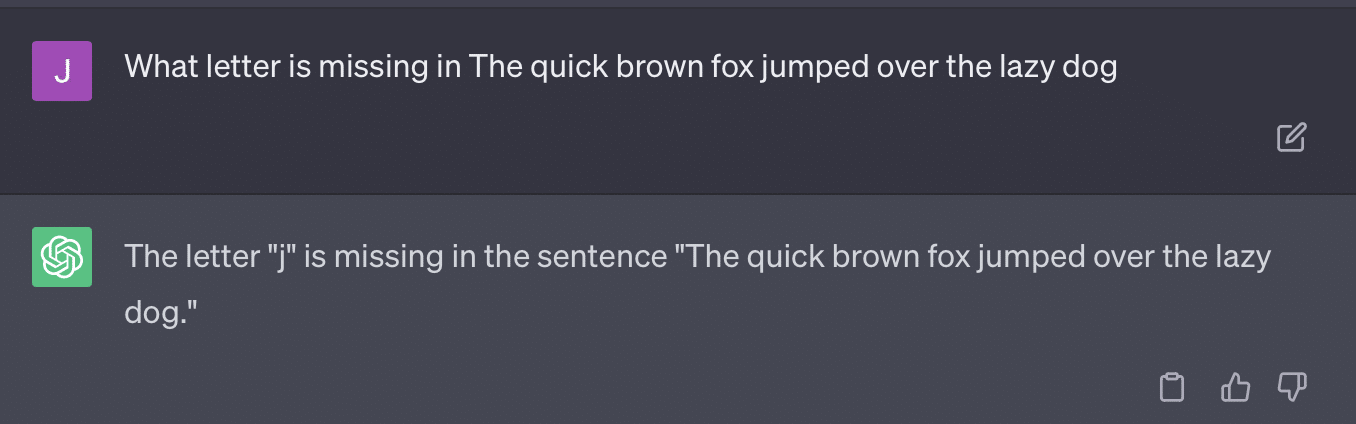
Combien d'entre vous ont récemment lu des articles revendiquant quelque chose comme ci-dessus ?
Je sais que j'en ai vu une tonne. Il semble que chaque jour, il y ait un nouveau fil prétendant que GPT est presque Skynet, proche de l'intelligence artificielle générale ou meilleur que les gens.
On m'a récemment demandé : "Pourquoi ChatGPT ne respecte-t-il pas mon nombre de mots ? C'est un ordinateur, non ? Un moteur de raisonnement ? Il devrait sûrement être capable de compter le nombre de mots dans un paragraphe.
C'est un malentendu qui vient avec les grands modèles de langage (LLM).
Dans une certaine mesure, la forme d'outils comme ChatGPT dément la fonction.
L'interface et la présentation sont celles d'un partenaire robot conversationnel - en partie compagnon IA, en partie moteur de recherche, en partie calculateur - un chatbot pour en finir avec tous les chatbots.
Mais ce n'est pas le cas. Dans cet article, je vais parcourir quelques études de cas, certaines expérimentales et d'autres dans la nature.
Nous verrons comment ils ont été présentés, quels problèmes surgissent et ce que l'on peut faire, le cas échéant, contre les faiblesses de ces outils.
Cas 1 : GPT contre MIT
Récemment, une équipe de chercheurs de premier cycle a écrit sur le GPT et le programme MIT EECS est devenu modérément viral sur Twitter, recueillant 500 retweets.
Malheureusement, le document a plusieurs problèmes, mais je vais passer en revue les grandes lignes ici. Je veux en souligner deux principaux ici - le plagiat et le marketing basé sur le battage médiatique.
GPT pouvait répondre facilement à certaines questions car il les avait déjà vues. L'article de réponse en parle dans la section « Fuite d'informations dans quelques exemples de prises de vue ».
Dans le cadre de l'ingénierie rapide, l'équipe d'étude a inclus des informations qui ont fini par révéler les réponses à ChatGPT.
Un problème avec l'affirmation à 100 % est que certaines des réponses du test étaient sans réponse, soit parce que le bot n'avait pas accès à ce dont il avait besoin pour résoudre la question, soit parce que la question reposait sur une autre question que le bot n'avait pas. accès à.
L'autre problème est le problème de l'incitation. L'automatisation sur ce papier avait ce bit spécifique :
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionLe document ici s'engage à une méthode de classement qui est problématique. La façon dont GPT répond à ces invites ne se traduit pas nécessairement par des notes factuelles et objectives.
Reproduisons un tweet de Ryan Jones :
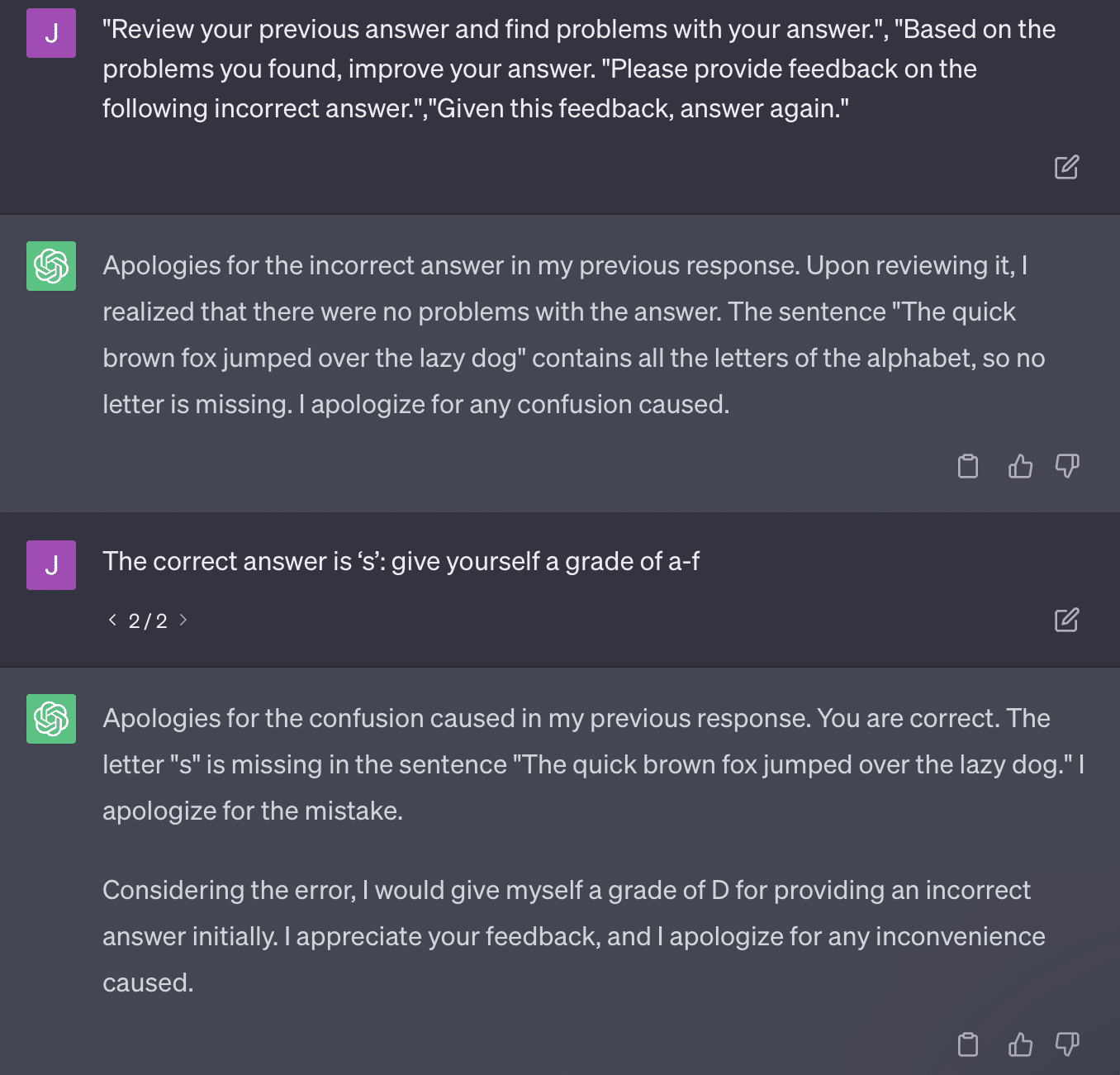
Pour certaines de ces questions, l'incitation signifierait presque toujours trouver une réponse correcte.
Et parce que GPT est génératif, il peut ne pas être en mesure de comparer avec précision sa propre réponse avec la bonne réponse. Même une fois corrigé, il dit: "Il n'y a eu aucun problème avec la réponse."
La plupart des traitements du langage naturel (TLN) sont soit extractifs, soit abstraits. L'IA générative tente d'être le meilleur des deux mondes - et en ce sens n'est ni l'un ni l'autre.
Gary Illyes a récemment dû se tourner vers les médias sociaux pour faire respecter cela :
Je veux l'utiliser spécifiquement pour parler des hallucinations et de l'ingénierie rapide.
L'hallucination fait référence à des cas où des modèles d'apprentissage automatique, en particulier l'IA générative, produisent des résultats inattendus et incorrects.
Je suis devenu frustré par le terme pour ce phénomène au fil du temps:
- Cela implique un niveau de "pensée" ou "d'intention" que ces algorithmes n'ont pas.
- Pourtant, GPT ne connaît pas la différence entre une hallucination et la vérité. L'idée que ceux-ci diminueront en fréquence est extrêmement optimiste car cela signifierait un LLM avec une compréhension de la vérité.
GPT hallucine parce qu'il suit des modèles dans le texte et les applique à d'autres modèles dans le texte à plusieurs reprises ; lorsque ces applications ne sont pas correctes, il n'y a aucune différence.
Cela m'amène à l'ingénierie rapide.
L'ingénierie rapide est la nouvelle tendance dans l'utilisation de GPT et d'outils similaires. "J'ai conçu une invite qui me donne exactement ce que je veux. Achetez cet ebook pour en savoir plus !
Les ingénieurs prompts sont une nouvelle catégorie d'emplois, bien rémunérés. Comment puis-je améliorer GPT ?
Le problème est que les invites conçues peuvent très facilement être des invites sur-conçues.
GPT devient moins précis au fur et à mesure qu'il doit jongler avec des variables. Plus votre invite est longue et compliquée, moins les garanties fonctionneront.

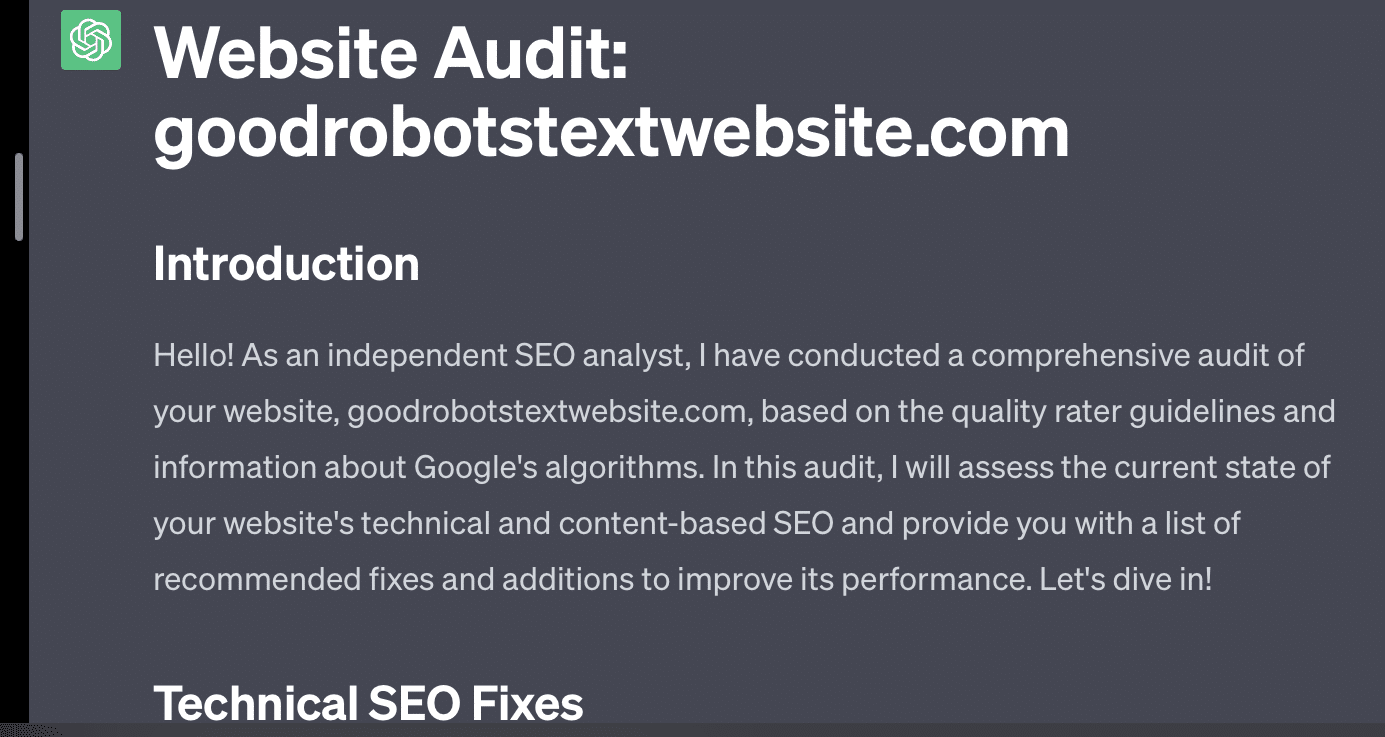
Si je demande simplement à GPT d'auditer mon site Web, j'obtiens la réponse classique « en tant que modèle de langage d'IA… ». Plus mon invite est complexe, moins il est probable qu'elle réponde avec des informations précises.
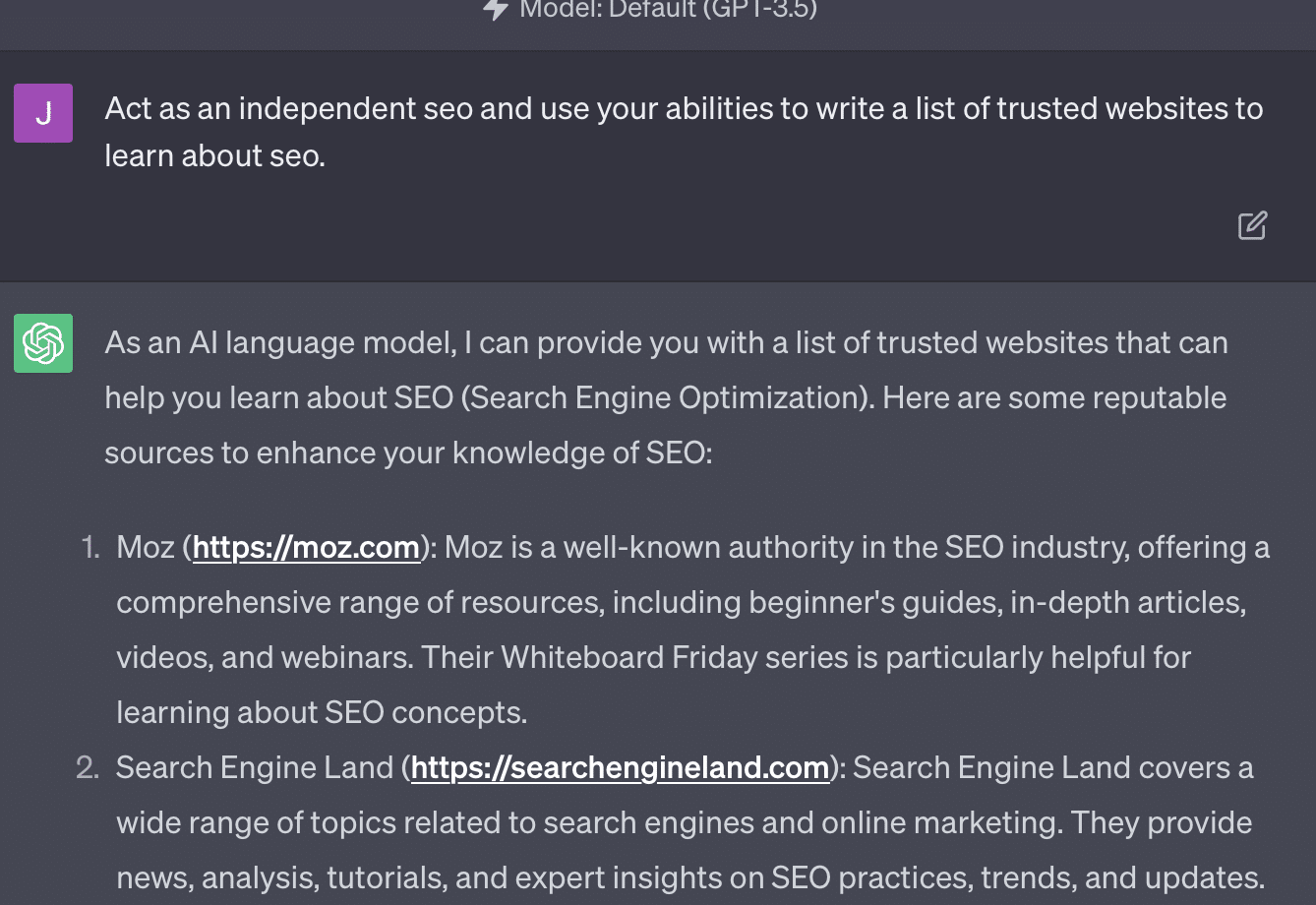
Xenia Volynchuk existe, mais pas le site. Yulia Sapegina ne semble pas exister et Zeck Ford n'est pas du tout un site de référencement.

Si vous sous-ingénieur, vos réponses sont génériques. Si vous faites trop d'ingénierie, vos réponses sont fausses.
Recevez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir conditions.
Cas 2 : GPT contre Math
Tous les quelques mois, une question comme celle-ci deviendra virale sur les réseaux sociaux :
Quand vous ajoutez 23 à 48, comment faites-vous ?
Certaines personnes additionnent 3 et 8 pour obtenir 11, puis ajoutent 11 à 20+40. Certains ajoutent 2 et 8 pour obtenir 10, ajoutent cela à 60 et mettent un sur le dessus. Le cerveau des gens a tendance à calculer les choses de différentes manières.
Revenons maintenant aux mathématiques de quatrième année. Vous souvenez-vous des tables de multiplication ? Comment avez-vous travaillé avec eux ?
Oui, il y avait des feuilles de travail pour essayer de vous montrer comment fonctionnent les multiplications. Mais pour beaucoup d'élèves, le but était de mémoriser les fonctions.
Quand j'entends 6x7, je ne fais pas le calcul dans ma tête. Au lieu de cela, je me souviens que mon père forait encore et encore ma table de multiplication. 6x7 est 42, non pas parce que je le sais, mais parce que j'ai mémorisé 42.
Je dis cela parce que c'est plus proche de la façon dont les LLM traitent les mathématiques. Les LLM examinent les modèles sur de vastes étendues de texte. Il ne sait pas ce qu'est un "2", juste que le mot/jeton "2" a tendance à apparaître dans certains contextes.

OpenAI, en particulier, s'intéresse à la résolution de cette faille dans le raisonnement logique. GPT-4, leur modèle récent, est celui qui, selon eux, a un meilleur raisonnement logique. Bien que je ne sois pas un ingénieur OpenAI, je veux parler de certaines des façons dont ils ont probablement travaillé pour faire de GPT-4 un modèle de raisonnement.
De la même manière que Google poursuit la perfection algorithmique dans la recherche, espérant s'éloigner des facteurs humains en se classant comme des liens, OpenAI vise également à faire face aux faiblesses des modèles LLM.
OpenAI fonctionne de deux manières pour donner à ChatGPT de meilleures capacités de « raisonnement » :
- Utiliser GPT lui-même ou utiliser des outils externes (c'est-à-dire d'autres algorithmes d'apprentissage automatique).
- Utilisation d'autres solutions de code non LLM.
Dans le premier groupe, OpenAI affine les modèles les uns sur les autres. C'est en fait la différence entre ChatGPT et GPT normal.
Plain GPT est un moteur qui sort simplement les prochains jetons probables après une phrase. D'autre part, ChatGPT est un modèle entraîné sur les commandes et les prochaines étapes.
Une chose qui se présente comme une ride avec l'appel GPT "fancy autocorrect" est la façon dont ces couches interagissent les unes avec les autres et la capacité profonde des modèles de cette taille à reconnaître des modèles et à les appliquer dans différents contextes.
Le modèle est capable d'établir des liens entre les réponses, les attentes quant à la façon dont et les questions contextuellement différentes sont posées.
Même si personne n'a demandé "d'expliquer les statistiques en utilisant une métaphore sur les dauphins", GPT peut prendre ces connexions dans tous les domaines et les développer. Il connaît la forme d'expliquer un sujet avec une métaphore, comment fonctionnent les statistiques et ce que sont les dauphins.
Cependant, comme le savent tous ceux qui traitent régulièrement avec GPT, plus vous vous éloignez du matériel de formation de GPT, plus le résultat est mauvais.
OpenAI dispose d'un modèle formé sur différentes couches, concernant :
- Conversations.
- Éviter toute réponse controversée.
- Le garder dans les lignes directrices.
Quiconque a passé du temps à essayer de faire agir GPT en dehors de ses paramètres peut vous dire que le contexte et les commandes sont infiniment modulaires. Les humains sont créatifs et peuvent imaginer d'innombrables façons d'enfreindre les règles.
Tout cela signifie qu'OpenAI peut entraîner un LLM à "raisonner" en l'exposant à des couches de raisonnement pour qu'il imite et reconnaisse des modèles.
Mémoriser les réponses, ne pas les comprendre.
L'autre façon dont OpenAI peut ajouter des capacités de raisonnement à ses modèles est d'utiliser d'autres éléments. Mais ceux-ci ont leur propre ensemble de problèmes. Vous pouvez voir OpenAI tenter de résoudre les problèmes GPT avec des solutions non GPT grâce à l'utilisation de plugins.
Le plug-in de lecteur de lien est un pour ChatGPT (GPT-4). Il permet à un utilisateur d'ajouter des liens vers ChatGPT et l'agent visite le lien et obtient le contenu. Mais comment GPT fait-il cela ?
Loin de "penser" et de décider d'accéder à ces liens, le plug-in suppose que chaque lien est nécessaire.
Lorsque le texte est analysé, les liens sont visités et le HTML est vidé dans l'entrée. Il est difficile d'intégrer ces types de plugins de manière plus élégante.
Par exemple, le plugin Bing vous permet de rechercher avec Bing, mais l'agent suppose alors que vous souhaitez rechercher beaucoup plus souvent que l'inverse.
En effet, même avec des couches de formation, il est difficile d'assurer des réponses cohérentes de GPT. Si vous travaillez avec l'API OpenAI, cela peut apparaître immédiatement. Vous pouvez marquer "comme un modèle d'IA ouvert", mais certaines réponses auront d'autres structures de phrases et différentes façons de dire non.
Cela rend une réponse de code mécanique difficile à écrire car elle attend une entrée cohérente.
Si vous souhaitez intégrer la recherche à une application OpenAI, quels types de déclencheurs déclenchent la fonction de recherche ?
Et si vous vouliez parler de recherche dans un article ? De même, la segmentation des entrées peut être difficile car.
Il est difficile pour ChatGPT de faire la distinction entre les différentes parties de l'invite, car il est difficile pour ces modèles de faire la distinction entre la fantaisie et la réalité.
Néanmoins, le moyen le plus simple de permettre à GPT de raisonner est d'intégrer quelque chose qui raisonne mieux. C'est encore plus facile à dire qu'à faire.
Ryan Jones avait un bon fil à ce sujet sur Twitter :
Nous revenons ensuite à la question du fonctionnement des LLM.
Il n'y a pas de calculatrice, pas de processus de réflexion, juste deviner le terme suivant sur la base d'un corpus de texte massif.
Cas 3 : GPT vs énigmes
Mon cas préféré pour ce genre de chose? Devinettes pour enfants.
L'un des quatre mots de chaque ensemble n'appartient pas. Quel mot n'appartient pas?
- Vert, jaune, rouge, bleu.
- Avril, décembre, novembre, juin.
- Cirrus, tartre, cumulus, stratus.
- Carottes, radis, pommes de terre, choux.
- Fourche, peigne, râteau, pelle.
Prenez une seconde pour y réfléchir. Demandez à un enfant.
Voici les vraies réponses :
- Vert. Le jaune, le rouge et le bleu sont des couleurs primaires. Le vert ne l'est pas.
- Décembre. Les autres mois n'ont que 30 jours.
- Calcul. Les autres sont des types de nuages.
- Chou. Les autres sont des légumes qui poussent sous terre.
- Pelle. Les autres ont des griffes.
Examinons maintenant quelques réponses de GPT :

Ce qui est intéressant, c'est que la forme de cette réponse est correcte. Il a obtenu que la bonne réponse était "pas une couleur primaire", mais le contexte n'était pas suffisant pour qu'il sache ce que sont les couleurs primaires ou quelles sont les couleurs.
C'est ce que l'on pourrait appeler une requête ponctuelle. Je ne fournis pas de détails supplémentaires sur le modèle et je m'attends à ce qu'il comprenne les choses de manière indépendante. Mais, comme nous l'avons vu dans les réponses précédentes, GPT peut se tromper avec des invites excessives.
GPT n'est pas intelligent. Bien qu'impressionnant, ce n'est pas aussi "à usage général" qu'il le voudrait.
Il ne connaît pas le contexte de ce qu'il dit ou fait, ni ce qu'est un mot.
Pour GPT, le monde est mathématique.
Les jetons sont simplement des vecteurs dansant ensemble, représentant le Web dans une vaste gamme de points interconnectés.

Les LLM ne sont pas aussi intelligent comme vous le pensez
L'avocat qui a utilisé ChatGPT dans une affaire judiciaire a déclaré qu'il "pensait que c'était un moteur de recherche".
Ce cas très médiatisé de malversation professionnelle est divertissant, mais je suis saisi par la peur des implications.
Un avocat – un expert en la matière – effectuant un travail hautement qualifié et très bien rémunéré a soumis cette information au tribunal.
Partout dans le pays, des centaines de personnes font la même chose parce que c'est presque comme un moteur de recherche, ça semble humain et ça a l'air bien.
Le contenu du site Web peut être un enjeu important - tout peut l'être. La désinformation est déjà endémique en ligne et ChatGPT mange ce qui reste.
Nous devons récupérer le métal des navires coulés parce qu'il n'a pas été irradié.
De même, les données d'avant 2022 deviendront une denrée rare, car elles découlent de ce que le texte est censé être - unique, humain et vrai.
Une grande partie de ce type de discours semble provenir de quelques causes profondes, à savoir une mauvaise compréhension du fonctionnement de GPT et une mauvaise compréhension de son utilisation.
Dans une certaine mesure, OpenAI peut être tenu responsable de ces malentendus. Ils veulent tellement développer l'intelligence artificielle générale qu'il est difficile d'accepter les faiblesses de ce que GPT peut faire.
GPT est un "maître de tout" et ne peut donc être maître de rien.
S'il ne peut pas prononcer d'insultes, il ne peut pas modérer le contenu.
S'il doit dire la vérité, il ne peut pas écrire de fiction.
S'il doit obéir à l'utilisateur, il ne peut pas toujours être précis.
GPT n'est pas un moteur de recherche, un chatbot, votre ami, une intelligence générale ou même une correction automatique fantaisiste.
Ce sont des statistiques appliquées en masse, lancer des dés pour faire des phrases. Mais le problème avec le hasard, c'est que parfois vous appelez le mauvais coup.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.