
Spark vs Hadoop : quel framework Big Data va élever votre entreprise ?
Publié: 2019-09-24"Les données sont le carburant de l'économie numérique"
Alors que les entreprises modernes s'appuient sur des tas de données pour mieux comprendre leurs consommateurs et leur marché, les technologies telles que le Big Data gagnent un énorme élan.
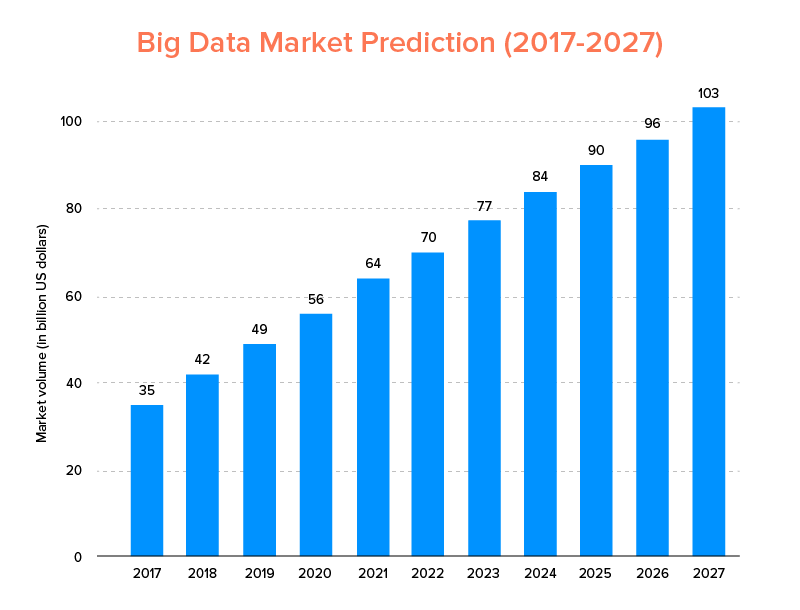
Le Big Data, tout comme l'IA, n'a pas seulement atterri dans la liste des principales tendances technologiques pour 2020 , mais devrait être adopté à la fois par les startups et les entreprises du Fortune 500 pour bénéficier d'une croissance commerciale exponentielle et assurer une plus grande fidélité des clients. Une indication claire de cela est que le marché du Big Data devrait atteindre 103 milliards de dollars d'ici 2027.
Maintenant, alors que d'un côté tout le monde est très motivé pour remplacer ses outils d'analyse de données traditionnels par le Big Data - celui qui prépare le terrain pour l'avancement de la Blockchain et de l'IA, ils sont également confus quant au choix du bon outil Big Data. Ils sont confrontés au dilemme de choisir entre Apache Hadoop et Spark - les deux titans du monde du Big Data.
Donc, compte tenu de cette pensée, nous couvrirons aujourd'hui un article sur Apache Spark vs Hadoop et vous aiderons à déterminer laquelle est la bonne option pour vos besoins.
Mais, tout d'abord, faisons une brève introduction de ce qu'est Hadoop et Spark.
Apache Hadoop est un framework open source, distribué et basé sur Java qui permet aux utilisateurs de stocker et de traiter des mégadonnées sur plusieurs clusters d'ordinateurs à l'aide de constructions de programmation simples. Il comprend divers modules qui fonctionnent ensemble pour offrir une expérience améliorée, qui sont : -
- Commun Hadoop
- Système de fichiers distribué Hadoop (HDFS)
- FIL Hadoop
- Hadoop MapReduce
Tandis qu'Apache Spark est un framework de Big Data open-source de calcul en cluster distribué qui est "facile à utiliser" et offre des services plus rapides.
Les deux grands cadres de données sont soutenus par de nombreuses grandes entreprises en raison de l'ensemble des opportunités qu'ils offrent.
Avantages du framework Hadoop Big Data
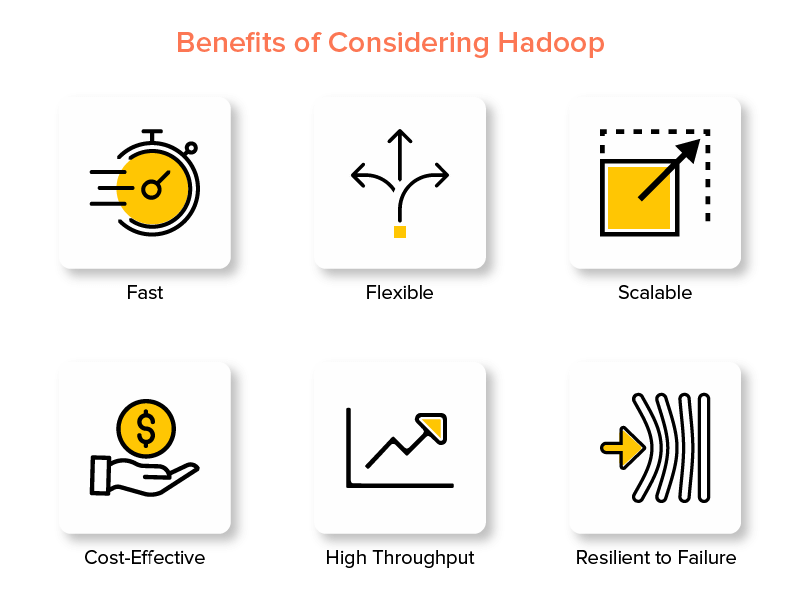
1. Rapide
L'une des caractéristiques de Hadoop qui le rend populaire dans le monde du Big Data est sa rapidité.
Sa méthode de stockage est basée sur un système de fichiers distribué qui « mappe » principalement les données où qu'elles se trouvent sur un cluster. De plus, les données et les outils utilisés pour le traitement des données sont généralement disponibles sur le même serveur, ce qui rend le traitement des données plus simple et plus rapide.
En fait, il a été constaté que Hadoop peut traiter des téraoctets de données non structurées en quelques minutes seulement, tandis que des pétaoctets en heures.
2. Flexible
Hadoop, contrairement aux outils de traitement de données traditionnels, offre une flexibilité haut de gamme.
Il permet aux entreprises de collecter des données à partir de différentes sources (comme les médias sociaux, les e-mails, etc.), de travailler avec différents types de données (structurées et non structurées) et d'obtenir des informations précieuses à utiliser ultérieurement à des fins variées (comme le traitement des journaux, l'analyse des campagnes de marché, détection de fraude, etc.).
3. Évolutif
Un autre avantage de Hadoop est qu'il est hautement évolutif. La plate-forme, contrairement aux systèmes de bases de données relationnelles traditionnels (RDBMS) , permet aux entreprises de stocker et de distribuer de grands ensembles de données à partir de centaines de serveurs qui fonctionnent en parallèle.
4. Rentable
Apache Hadoop, comparé à d'autres outils d'analyse de données volumineuses, est très peu coûteux. En effet, il ne nécessite aucune machine spécialisée ; il fonctionne sur un groupe de matériel de base. De plus, il est plus facile d'ajouter plus de nœuds à long terme.
Cela signifie qu'un cas augmente facilement les nœuds sans subir de temps d'arrêt des exigences de pré-planification.
5. Haut débit
Dans le cas du framework Hadoop, les données sont stockées de manière distribuée de sorte qu'un petit travail est divisé en plusieurs blocs de données en parallèle. Cela permet aux entreprises de réaliser plus facilement plus de travaux en moins de temps, ce qui se traduit finalement par un débit plus élevé.
6. Résilient à l'échec
Enfin et surtout, Hadoop offre des options de haute tolérance aux pannes qui aident à atténuer les conséquences d'une défaillance. Il stocke une réplique de chaque bloc qui permet de récupérer des données chaque fois qu'un nœud tombe en panne.
Inconvénients du framework Hadoop
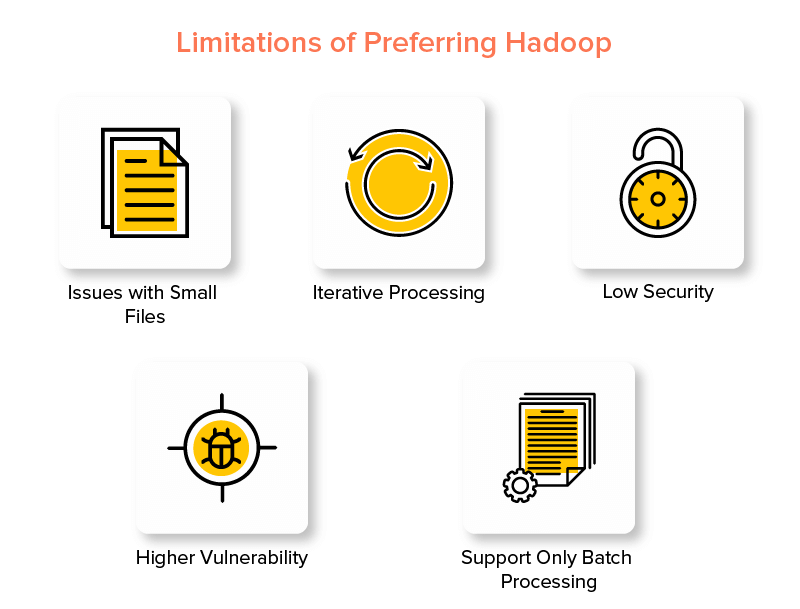
1. Problèmes avec les petits fichiers
Le plus grand inconvénient de considérer Hadoop pour l'analyse de données volumineuses est qu'il n'a pas le potentiel de prendre en charge la lecture aléatoire de petits fichiers de manière efficace et efficiente.
La raison derrière cela est qu'un petit fichier a une taille de mémoire comparativement inférieure à la taille de bloc HDFS. Dans un tel scénario, si l'on stocke un grand nombre de petits fichiers, il y a plus de chances de surcharge de NameNode qui stocke l'espace de noms de HDFS, ce qui n'est pratiquement pas une bonne idée.
2. Traitement itératif
Le flux de données dans le cadre Big Data Hadoop se présente sous la forme d'une chaîne, de sorte que la sortie de l'une devient l'entrée d'une autre étape. Alors que le flux de données dans le traitement itératif est de nature cyclique.
Pour cette raison, Hadoop est un choix inapproprié pour les solutions basées sur l'apprentissage automatique ou le traitement itératif.
3. Faible sécurité
Un autre inconvénient d'utiliser le framework Hadoop est qu'il offre des fonctionnalités de sécurité inférieures.
Le framework, par exemple, a un modèle de sécurité désactivé par défaut. Si une personne utilisant cet outil Big Data ne sait pas comment l'activer, ses données risquent davantage d'être volées ou mal utilisées. De plus, Hadoop ne fournit pas la fonctionnalité de chiffrement au niveau du stockage et du réseau, ce qui augmente à nouveau les risques de menace de violation de données.
4. Vulnérabilité accrue
Le framework Hadoop est écrit en Java, le langage de programmation le plus populaire mais le plus exploité. Cela permet aux cybercriminels d'accéder plus facilement aux solutions basées sur Hadoop et d'utiliser à mauvais escient les données sensibles.
5. Prise en charge du traitement par lots uniquement
Contrairement à divers autres frameworks de Big Data, Hadoop ne traite pas les données diffusées en continu. Il ne prend en charge que le traitement par lots , et la raison en est que MapReduce ne parvient pas à tirer le meilleur parti de la mémoire du cluster Hadoop.
Bien qu'il s'agisse de Hadoop, de ses fonctionnalités et de ses inconvénients, examinons les avantages et les inconvénients de Spark pour trouver une facilité à comprendre la différence entre les deux.
Avantages d'Apache Spark Framework
1. Dynamique dans la nature
Comme Apache Spark propose environ 80 opérateurs de haut niveau, il peut être utilisé pour le traitement dynamique des données. Il peut être considéré comme le bon outil de Big Data pour développer et gérer des applications parallèles.
2. Puissant
En raison de sa capacité de traitement des données en mémoire à faible latence et de la disponibilité de diverses bibliothèques intégrées pour les algorithmes d'apprentissage automatique et d'analyse de graphes, il peut gérer divers défis d'analyse. Cela en fait une puissante option de Big Data sur le marché.
3. Analytique avancée
Une autre caractéristique distinctive de Spark est qu'il encourage non seulement le « MAP » et la « réduction », mais prend également en charge l'apprentissage automatique (ML), les requêtes SQL, les algorithmes de graphe et les données en continu. Cela le rend idéal pour profiter d'analyses avancées.
4. Réutilisabilité
Contrairement à Hadoop, le code Spark peut être réutilisé pour le traitement par lots, exécuter des requêtes ad hoc sur l'état du flux, joindre le flux aux données historiques, etc.
5. Traitement de flux en temps réel
Un autre avantage d'utiliser Apache Spark est qu'il permet la gestion et le traitement des données en temps réel.
6. Assistance multilingue
Enfin, cet outil d'analyse de données volumineuses prend en charge plusieurs langages de codage, notamment Java, Python et Scala.
Limites de Spark Big Data Tool

1. Aucun processus de gestion de fichiers
Le principal inconvénient d'utiliser Apache Spark est qu'il ne possède pas son propre système de gestion de fichiers. Il s'appuie sur d'autres plates-formes comme Hadoop pour répondre à cette exigence.
2. Peu d'algorithmes
Apache Spark est également à la traîne par rapport aux autres frameworks de Big Data en ce qui concerne la disponibilité d'algorithmes tels que la distance de Tanimoto.
3. Problème de petits fichiers
Un autre inconvénient de l'utilisation de Spark est qu'il ne gère pas efficacement les petits fichiers.
En effet, il fonctionne avec Hadoop Distributed File System (HDFS) qui facilite la gestion d'un nombre limité de fichiers volumineux sur une multitude de petits fichiers.
4. Pas de processus d'optimisation automatique
Contrairement à diverses autres plates-formes de mégadonnées et basées sur le cloud, Spark ne dispose d'aucun processus d'optimisation automatique du code. Il faut optimiser le code manuellement uniquement.
5. Ne convient pas à un environnement multi-utilisateurs
Étant donné qu'Apache Spark ne peut pas gérer plusieurs utilisateurs en même temps, il ne fonctionne pas efficacement dans un environnement multi-utilisateurs. Quelque chose qui ajoute encore à ses limites.
Avec les bases des deux cadres de données volumineuses couvertes, il est probable que vous espérez vous familiariser avec les différences entre Spark et Hadoop.
Alors, n'attendons pas plus loin et dirigeons-nous vers leur comparaison pour voir lequel mène la bataille "Spark vs Hadoop".
Spark vs Hadoop : comment les deux outils Big Data se comparent
[ID de table = 38 /]
1.Architecture
En ce qui concerne l'architecture Spark et Hadoop, cette dernière est en tête même lorsque les deux fonctionnent dans un environnement informatique distribué.
En effet, l'architecture de Hadoop - contrairement à Spark - comporte deux éléments principaux - HDFS (Hadoop Distributed File System) et YARN (Yet Another Resource Negotiator). Ici, HDFS gère le stockage de données volumineuses sur divers nœuds, tandis que YARN s'occupe du traitement des tâches via des mécanismes d'allocation des ressources et de planification des tâches. Ces composants sont ensuite divisés en plusieurs composants pour fournir de meilleures solutions avec des services tels que la tolérance aux pannes.
2. Facilité d'utilisation
Apache Spark permet aux développeurs d'introduire diverses API conviviales comme celle pour Scala, Python, R, Java et Spark SQL dans leur environnement de développement. De plus, il est livré avec un mode interactif qui prend en charge à la fois les utilisateurs et les développeurs. Cela le rend facile à utiliser et avec une faible courbe d'apprentissage.
Alors que, quand on parle de Hadoop, il propose des add-ons pour supporter les utilisateurs, mais pas un mode interactif. Cela permet à Spark de l'emporter sur Hadoop dans cette bataille du "big data".
3. Tolérance aux pannes et sécurité
Alors qu'Apache Spark et Hadoop MapReduce offrent tous deux une fonction de tolérance aux pannes, ce dernier remporte la bataille.
En effet, il faut recommencer à zéro au cas où un processus se bloque au milieu de l'opération dans l'environnement Spark. Mais, en ce qui concerne Hadoop, ils peuvent continuer à partir du point de plantage lui-même.
4. Performances
Lorsqu'il s'agit de considérer les performances de Spark vs MapReduce, le premier l'emporte sur le second.
Le framework Spark est capable de s'exécuter 10 fois plus vite sur disque et 100 fois en mémoire. Cela permet de gérer 100 To de données 3 fois plus vite que Hadoop MapReduce.
5. Traitement des données
Un autre facteur à prendre en compte lors de la comparaison Apache Spark vs Hadoop est le traitement des données.
Alors qu'Apache Hadoop offre la possibilité de traiter uniquement par lots, l'autre cadre de données volumineuses permet de travailler avec un traitement interactif, itératif, par flux, graphique et par lots. Quelque chose qui prouve que Spark est une meilleure option pour profiter de meilleurs services de traitement de données.
6. Compatibilité
La compatibilité de Spark et Hadoop MapReduce est un peu la même.
Bien que parfois, les deux frameworks de Big Data agissent comme des applications autonomes, ils peuvent également fonctionner ensemble. Spark peut fonctionner efficacement sur Hadoop YARN, tandis que Hadoop peut facilement s'intégrer à Sqoop et Flume. Pour cette raison, les deux prennent en charge les sources de données et les formats de fichiers de l'autre.
7. Sécurité
L'environnement Spark est doté de différentes fonctionnalités de sécurité telles que la journalisation des événements et l'utilisation de filtres de servlet javax pour protéger les interfaces utilisateur Web. En outre, il encourage l'authentification via un secret partagé et peut tirer parti du potentiel des autorisations de fichiers HDFS, du chiffrement intermode et de Kerberos lorsqu'il est intégré à YARN et HDFS.
Alors que Hadoop prend en charge l'authentification Kerberos , l'authentification tierce, les autorisations de fichiers conventionnelles et les listes de contrôle d'accès, etc., ce qui offre finalement de meilleurs résultats de sécurité.
Ainsi, lorsque l'on considère la comparaison Spark vs Hadoop en termes de sécurité, ce dernier est en tête.
8. Rentabilité
Lorsque l'on compare Hadoop et Spark, le premier a besoin de plus de mémoire sur le disque tandis que le second nécessite plus de RAM. De plus, comme Spark est assez nouveau par rapport à Apache Hadoop, les développeurs travaillant avec Spark sont plus rares.
Cela rend le travail avec Spark une affaire coûteuse. Cela signifie que Hadoop offre des solutions rentables lorsque l'on se concentre sur le coût de Hadoop par rapport à Spark.
9. Portée du marché
Alors qu'Apache Spark et Hadoop sont tous deux soutenus par de grandes entreprises et ont été utilisés à des fins différentes, ce dernier est en tête en termes de portée du marché.
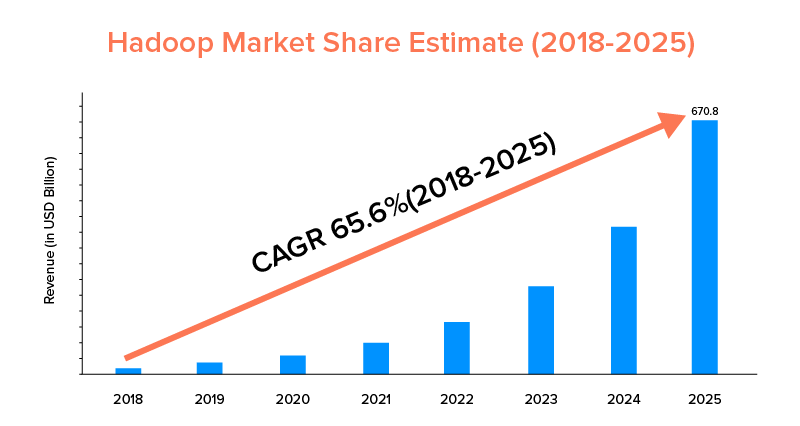
Selon les statistiques du marché, le marché Apache Hadoop devrait croître avec un TCAC de 65,6 % au cours de la période de 2018 à 2025, par rapport à Spark avec un TCAC de 33,9 % seulement.
Bien que ces facteurs vous aident à déterminer le bon outil de Big Data pour votre entreprise, il est avantageux de se familiariser avec leurs cas d'utilisation. Alors, couvrons ici.
Cas d'utilisation du framework Apache Spark
Cet outil de big data est adopté par les entreprises lorsqu'elles souhaitent :
- Diffusez et analysez les données en temps réel.
- Profitez de la puissance de l'apprentissage automatique.
- Travaillez avec des analyses interactives.
- Introduire Fog et Edge Computing dans leur business model.
Cas d'utilisation du framework Apache Hadoop
Hadoop est préféré par les startups et les entreprises lorsqu'elles souhaitent : -
- Analyser les données d'archives.
- Profitez de meilleures options de trading financier et de prévision.
- Exécuter des opérations comprenant du matériel Commodity.
- Considérez le traitement de données linéaire.
Avec cela, nous espérons que vous avez décidé lequel est le gagnant de la bataille "Spark vs Hadoop" en ce qui concerne votre entreprise. Sinon, n'hésitez pas à vous connecter avec nos experts en Big Data pour dissiper tous les doutes et obtenir des services exemplaires avec un taux de réussite plus élevé.
QUESTIONS FRÉQUEMMENT POSÉES
1. Quel framework Big Data choisir ?
Le choix dépend entièrement des besoins de votre entreprise. Si vous vous concentrez sur les performances, la compatibilité des données et la facilité d'utilisation, Spark est meilleur que Hadoop. Alors que le framework Hadoop Big Data est meilleur lorsque vous vous concentrez sur l'architecture, la sécurité et la rentabilité.
2. Quelle est la différence entre Hadoop et Spark ?
Il existe plusieurs différences entre Spark et Hadoop. Par example:-
- Spark est un facteur 100 fois supérieur à Hadoop MapReduce.
- Alors que Hadoop est utilisé pour le traitement par lots, Spark est destiné au traitement par lots, aux graphiques, à l'apprentissage automatique et au traitement itératif.
- Spark est compact et plus simple que le framework Hadoop Big Data.
- Contrairement à Spark, Hadoop ne prend pas en charge la mise en cache des données.
3. Spark est-il meilleur que Hadoop ?
Spark est meilleur que Hadoop lorsque vous vous concentrez principalement sur la vitesse et la sécurité. Cependant, dans d'autres cas, cet outil d'analyse de données volumineuses est à la traîne par rapport à Apache Hadoop.
4. Pourquoi Spark est plus rapide que Hadoop ?
Spark est plus rapide que Hadoop en raison du nombre inférieur de cycles de lecture/écriture sur le disque et du stockage des données intermédiaires en mémoire.
5. À quoi sert Apache Spark ?
Apache Spark est utilisé pour l'analyse de données lorsque l'on veut-
- Analysez les données en temps réel.
- Introduisez le ML et le Fog Computing dans votre modèle économique.
- Travaillez avec l'analyse interactive.