
Suivi de 20 ans de recherche
Publié: 2023-08-11Êtes-vous un nouveau spécialiste du marketing de recherche qui souhaite en savoir plus sur l'histoire de la recherche ?
Voulez-vous rester à jour sur les dernières nouvelles du marketing de recherche ?
Si c'est le cas, il n'y a qu'une seule personne que vous devez « suivre » pour connaître 90 % des changements intéressants dans l'industrie.
Cette personne a un site Web ; son premier billet de blog a été publié le 2 décembre 2003. Le code Google Analytics (GA) du site est étonnamment court : UA-67314-1.
Il y a plusieurs mois, après une brève interaction sur Mastodon, j'ai eu accès à son compte GA pour voir si je pouvais raconter une histoire sur l'histoire de la recherche à travers son travail en tant que responsable des archives du marketing de recherche.
En regardant ses habitudes de publication ( Figure 1 ), il est clair que le volume n'est pas un défi. (J'ai même revérifié ce graphique plusieurs fois pour m'assurer qu'il était correct. Wow !)
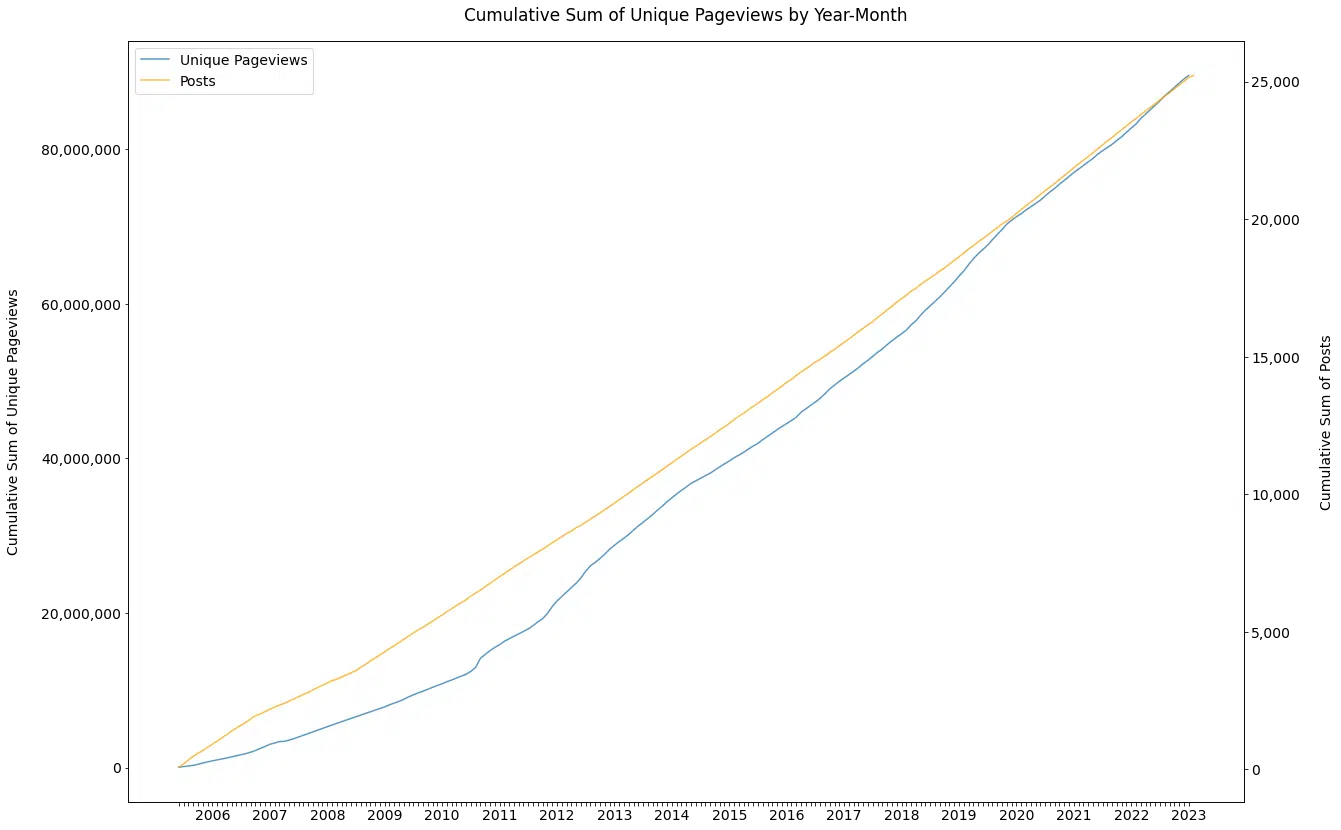
Au cours des 20 dernières années, cette personne a posté, en moyenne :
- 3,81 fois par jour.
- 26,67 fois par semaine.
- 116,20 fois par mois.
- 1 437 fois par an.
Je suis sûr que vous l'avez déjà deviné, mais je parle de Barry Schwartz et de son site Web, Search Engine Roundtable.
Cet article couvre les principaux points à retenir et les conclusions de mon analyse des données historiques de Google Analytics de seroundtable.com.
(Si vous êtes intéressé par la façon dont j'ai analysé les données et les outils que j'ai utilisés, vous pouvez consulter la méthodologie ci-dessous.)
Couverture des moteurs de recherche au fil des ans
Comme nous disposions de données de 2003 et d'une affiche prolifique, nous avons pensé qu'il serait intéressant de regarder la couverture thématique qui mentionnait différents moteurs dans les titres des messages ( Figure 2 ).
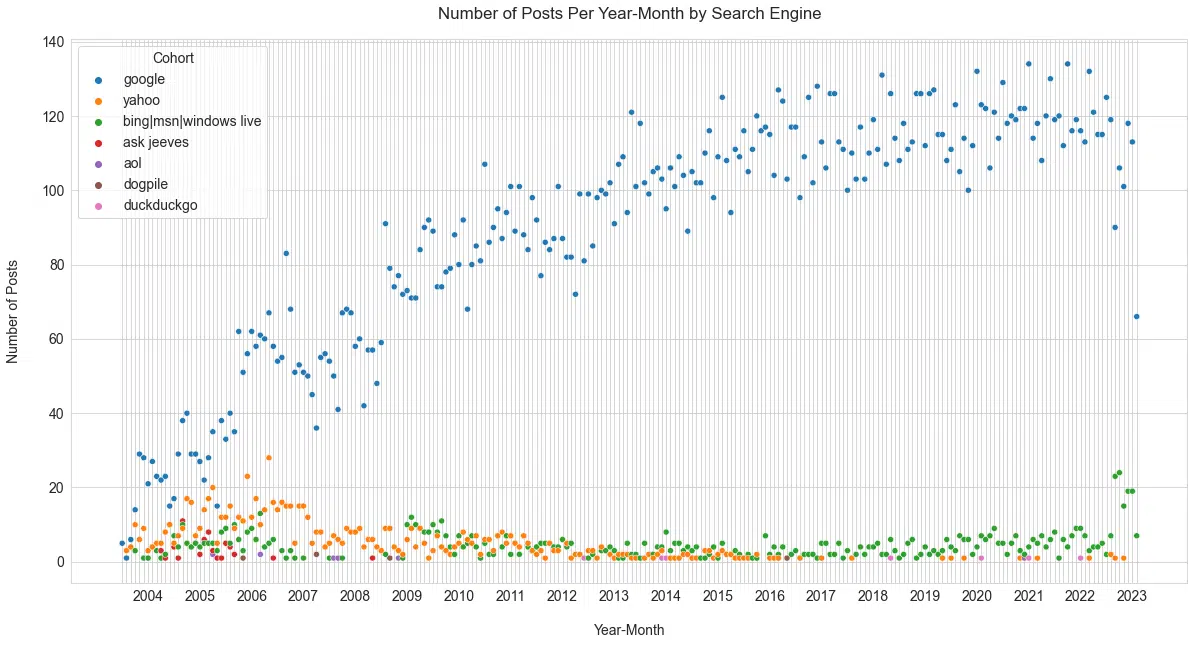
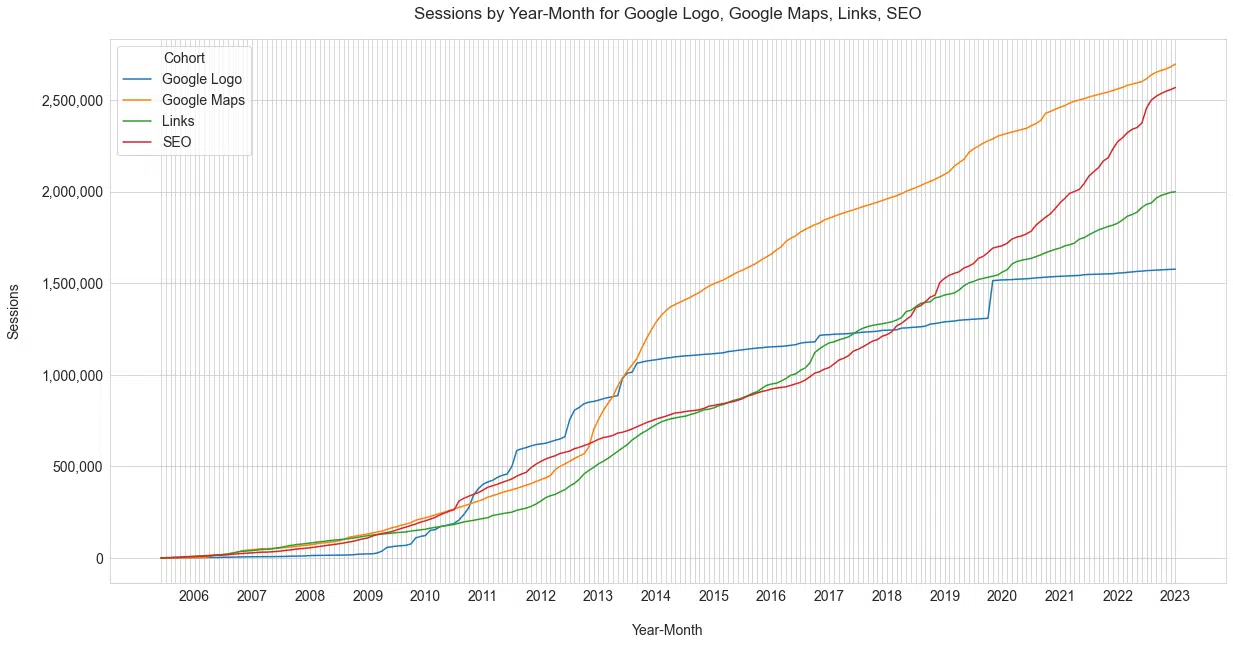
Ce chiffre raconte la même histoire que nous connaissons tous, Google est le moteur de recherche le plus couvert au cours des deux dernières décennies.
Mais il est également intéressant de noter la mort de Yahoo et la résurgence de Microsoft Bing. (Bien que Microsoft Bing ait connu une augmentation de la couverture, il n'est pas clair que cela aide du point de vue de l'utilisation, comme indiqué en mai.)
En regardant le point de vue d'une personne sur la couverture de "l'intérêt" de ces produits est une manière unique d'appréhender leur histoire.
Notamment, la plupart des principaux moteurs de recherche américains ont reçu peu de mentions au cours des 13 dernières années, à l'exception de Microsoft Bing, qui a récemment pris une importance soudaine en raison de l'intégration de Microsoft avec OpenAI.
En examinant le nombre moyen de sessions par publication et la fréquence des publications au fil du temps par cohorte de moteurs de recherche ( Figure 2 ), il est clair que la vaste couverture médiatique contribue grandement à l'importance de Google pour l'audience de ce site.
Une partie importante des moteurs de recherche est la fréquence à laquelle ils améliorent leurs résultats. Nous pouvons revenir sur l'historique des "mises à jour d'algorithmes" couvertes ainsi que sur le volume de recherche généré chaque mois.
Vous remarquerez comment les messages augmentent après l'augmentation initiale du trafic avec une annonce de mise à jour. Le graphique ci-dessous dépeint une histoire vraiment intéressante de:
- Quelle est la fréquence des mises à jour (au moins les plus importantes).
- La connexion de Schwartz et la cohérence de sa couverture.
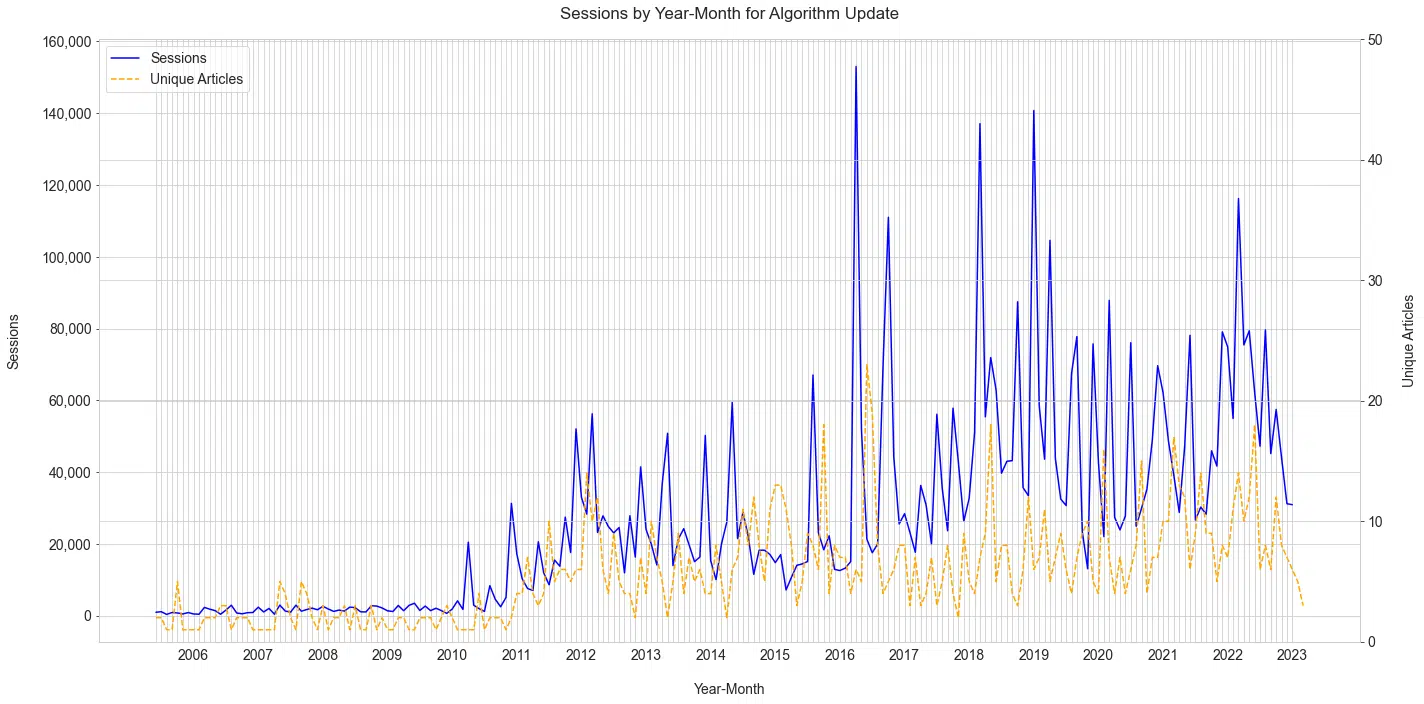
L'impact et la popularité des mises à jour de Google dans la communauté de recherche
Nous avons étiqueté environ 20 mises à jour Google nommées. Les huit présentés ci-dessous sont les huit premiers par sessions globales ( Figure 4 ). Nous avons ajouté la catégorie "Pénalité" à ce tableau, car il s'agissait d'un sujet important à l'époque de Penguin.
Alors que le sujet est encore discuté, sa popularité a diminué, comme on le voit ci-dessous. Cela montre l'énorme impact des mises à jour de Penguin sur la communauté de recherche.
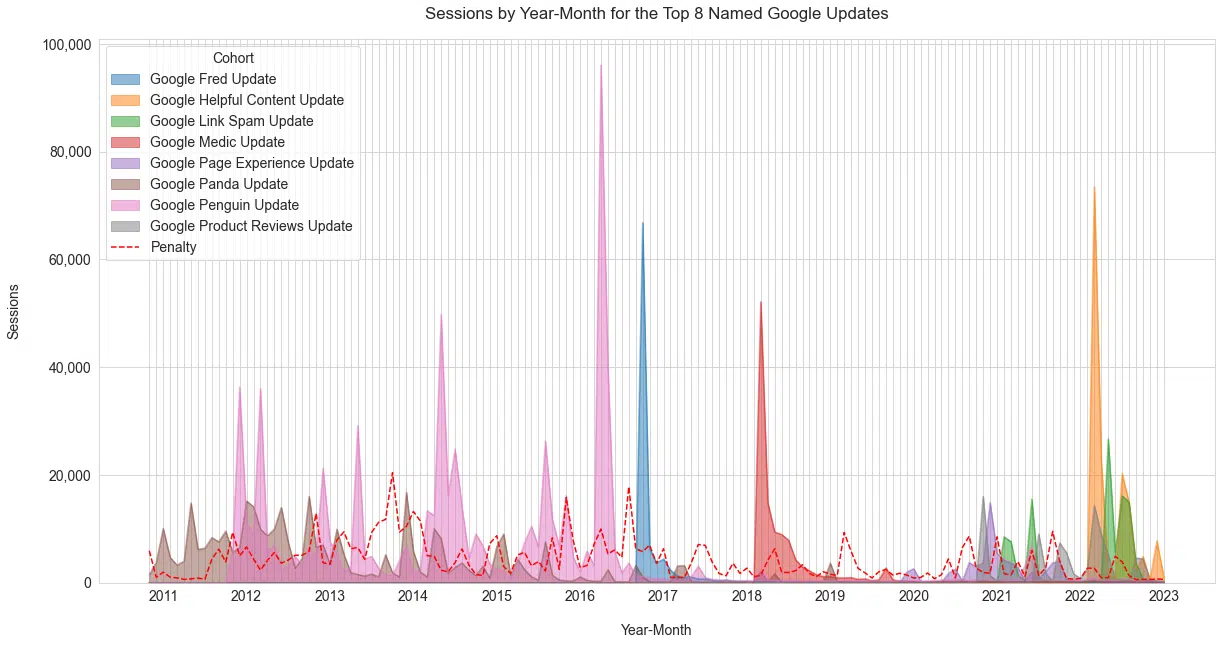
Chose intéressante, seroundtable.com a eu une action manuelle de Google d'environ 2007 à mars 2013.
Schwartz a écrit à ce sujet en 2011, et nous pouvons voir des annotations dans son compte GA qui indiquent qu'il a été levé en mars et vérifié via une demande de réexamen en avril.
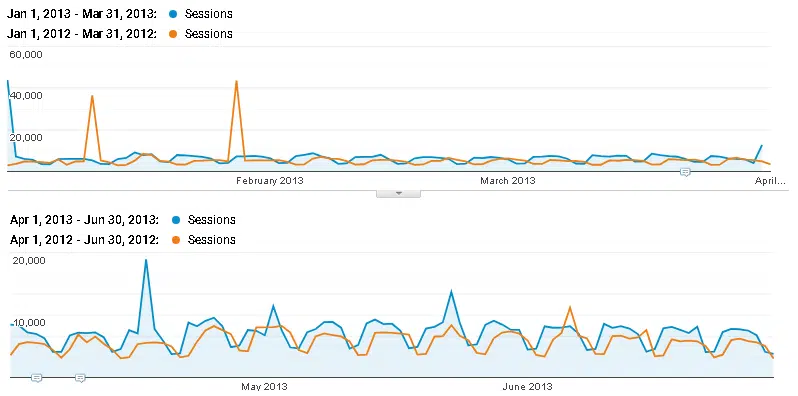
La croissance de ses sessions Google/Organic (YoY) pour le premier trimestre 2013 était de 16 %, contre 25 % au deuxième trimestre ( Figure 5 ).
La croissance des nouveaux utilisateurs a augmenté de 22 points de pourcentage. Malgré cela, l'impact est douteux en raison de pics d'intérêt aberrants favorisant le deuxième trimestre.
Schwartz, à partir de son message sur le penalty (et ses liens de parrainage), a déclaré :
- "Je suis têtu et je suis l'un des rares blogs SEO à avoir décidé de ne pas changer lorsque Google a déclenché sa pénalité."
Des années plus tard, il a reconsidéré. (De nombreux détails manquent maintenant dans GA, mais la pénalité manuelle n'a probablement pas eu d'impact drastique.)
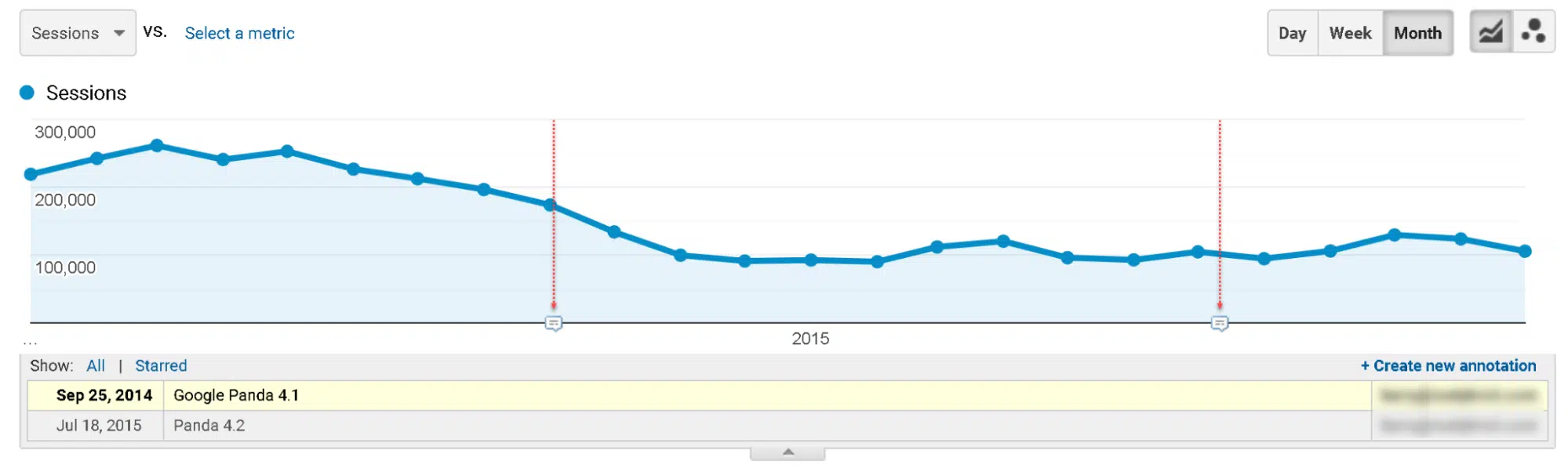
Seroundtable.com a également été victime de la mise à jour Panda 4.1 en 2014 ( Figure 6 ).
Comme Schwartz l'a indiqué en 2015, les performances ont commencé à s'améliorer modestement avec Panda 4.2 mi-2015 jusqu'en mai 2020, date à laquelle il y a eu une autre baisse soudaine.
Membres de l'équipe Google
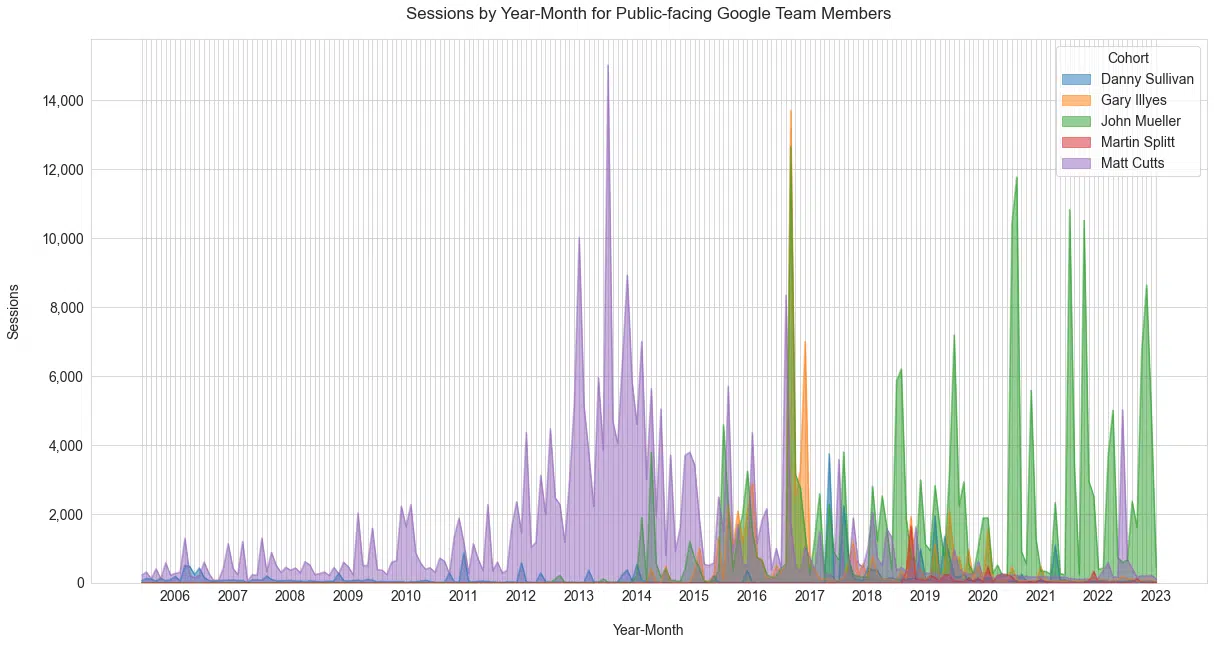
Nous avons identifié 10 employés de Google mentionnés dans les titres des publications ( Figure 7 ).
Sur les 10, nous avons restreint la liste pour n'afficher que ceux qui communiquent régulièrement des informations à la communauté SEO.
C'est ma vue préférée car elle montre clairement les époques Matt Cutts contre John Mueller.
En tant que liaison publique pour la recherche Google, Danny Sullivan n'est pas aussi prononcé dans les messages. Il est important de noter que toute mention de lui avant la fin de 2017 ferait référence à son rôle précédent avant d'occuper ce poste.
En tant que fondateur de Search Engine Watch et plus tard éditeur fondateur de Search Engine Land, Sullivan fait sans aucun doute partie intégrante de l'histoire du référencement.
Couverture de l'outil de référencement
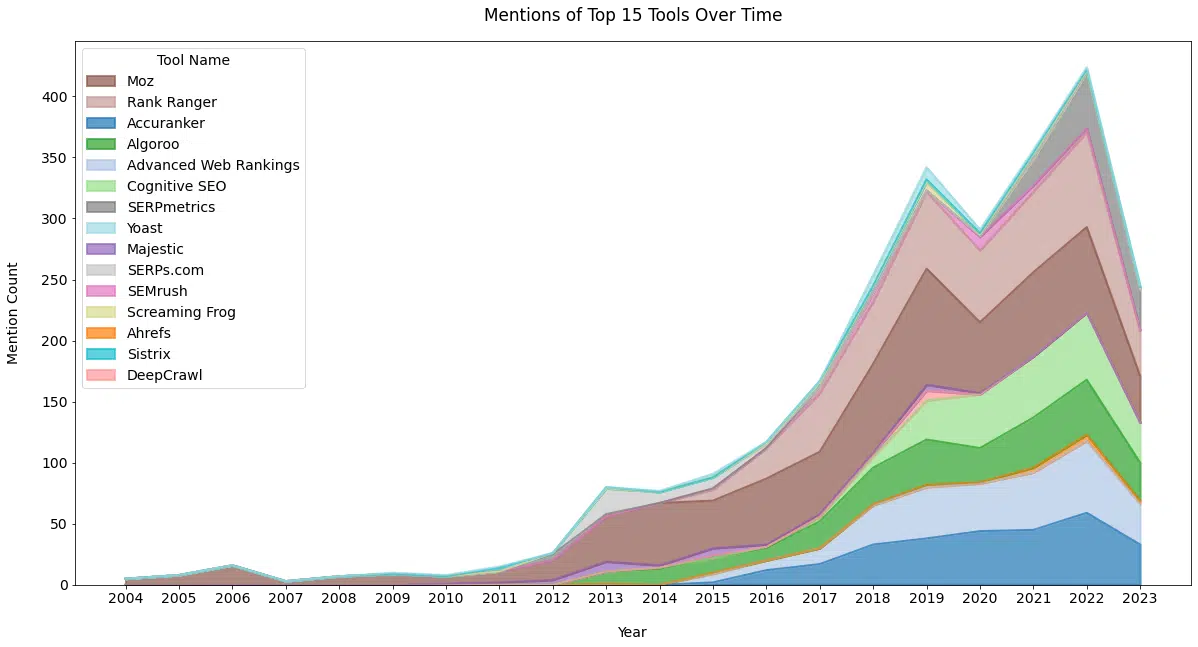
L'industrie du référencement ne manque pas d'outils. En examinant les messages de Schwartz, nous pouvons voir qu'il a mentionné un large éventail de sociétés d'outils au fil des ans.
Alors que les articles consacrés à une entreprise en particulier sont assez rares, Schwartz a couvert des études de données et des annonces de produits.
Ci-dessous ( Figure 8a ), nous pouvons voir la fréquence de couverture des publications depuis 2003. Ces données diffèrent des autres données de cet article car elles tiennent compte des mentions dans le titre et le contenu de l'article.
| Nom de l'outil | Nombre de mentions |
| Moz | 924 |
| Ranger de rang | 561 |
| Accuranker | 297 |
| Algoroo | 292 |
| Classements Web avancés | 289 |
| Référencement cognitif | 232 |
| Métriques SERP | 116 |
| Levure | 91 |
| Majestueux | 53 |
| SERPs.com | 46 |
| SEMrush | 44 |
| Grenouille hurlante | 34 |
| Ahrefs | 29 |
| Sœur | 21 |
| DeepCrawl | 20 |
| SimilaireWeb | 13 |
| Classement SE | 12 |
| HARO | 9 |
| SERPStat | 7 |
| SERP Woo | 6 |
Historiquement, nous pouvons voir l'avantage pour les fournisseurs d'outils de créer des métriques de classement agrégées comme Mozcast.
Mentions fréquentes et croissantes à chaque fluctuation de classement. Il est également clair ici la puissance de Moz.
Meilleurs messages
Le tableau suivant ( Figure 9 ) montre le meilleur message pour chaque année par pages vues uniques.
Il existe un contenu avec un attrait plus large (en dehors de la communauté SEO) et un contenu plus étroitement ciblé sur les spécialistes du marketing des moteurs de recherche.
Je me demande comment il décide de cet équilibre? J'ai été un peu surpris par cette liste, mais elle a du sens.
| Année | Titre | Pages vues uniques |
| 2005 | Première proposition de mariage via le moteur de recherche | 3 568 |
| 2006 | Google Earth – Téléchargement gratuit | 50 669 |
| 2007 | Google Earth – Téléchargement gratuit | 44 214 |
| 2008 | Google Earth – Téléchargement gratuit | 64 097 |
| 2009 | Arnaque : Google Money System ou Google Kit | 88 657 |
| 2010 | Comment configurer des unités vidéo Google AdSense via YouTube | 78 537 |
| 2011 | Comment configurer des unités vidéo Google AdSense via YouTube | 148 083 |
| 2012 | Google célèbre le premier cinéma drive-in | 126 629 |
| 2013 | Google Maps Murder au 52.376552,5.198303 aux Pays-Bas | 265 977 |
| 2014 | Google Maps Murder au 52.376552,5.198303 aux Pays-Bas | 110 222 |
| 2015 | Google Analytics modifie la terminologie : les sessions et les utilisateurs remplacent les visites et les uniques | 68 565 |
| 2016 | Comment obtenir la longitude/latitude d'un emplacement à l'aide de Google Maps sur iPhone | 129 300 |
| 2017 | Big Google Algorithm Fred Update Semble Liens Liés | 175 488 |
| 2018 | Vous pouvez désormais choisir de supprimer les recherches de tendances dans l'application de recherche Google | 125 922 |
| 2019 | Vous pouvez désormais choisir de supprimer les recherches de tendances dans l'application de recherche Google | 181 556 |
| 2020 | Le logo Google dit merci aux assistants du coronavirus | 413 202 |
| 2021 | Vous pouvez désormais choisir de supprimer les recherches de tendances dans l'application de recherche Google | 103 498 |
| 2022 | Mise à jour du contenu utile de Google pour cibler le contenu écrit pour les classements de recherche | 226 842 |
| 2023 | Google Maps Murder au 52.376552,5.198303 aux Pays-Bas | 55 533 |
Figure 9
commentaires
Pour autant que je sache, Seroundtable.com a toujours autorisé les commentaires, et la communauté SEO aime partager des opinions sur les manigances de Google.
Cette vue ( Figure 10 ), suggérée par John Mueller, affiche les publications au fil du temps par pages vues et commentaires uniques (taille de la bulle).

Cela devient intéressant si nous examinons les données par catégorie de sujet.
Par exemple, comparons le contenu sur « Google Updates » avec le contenu sur « Paid Advertising » ( Figure 11a et 11b ).
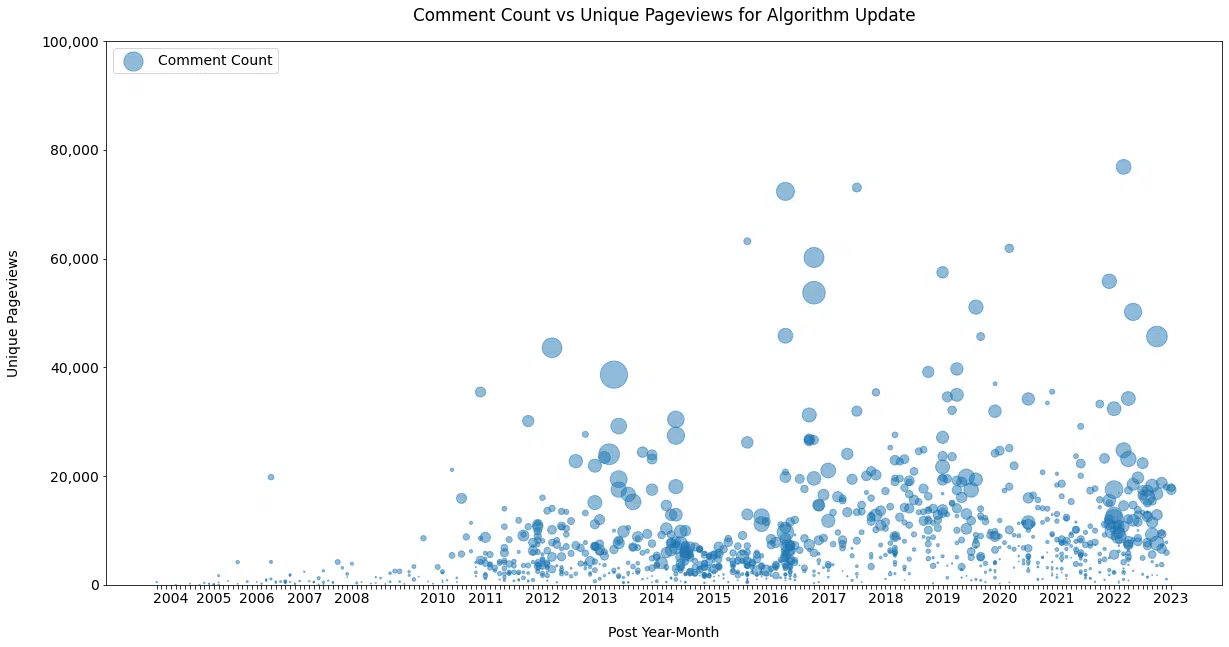
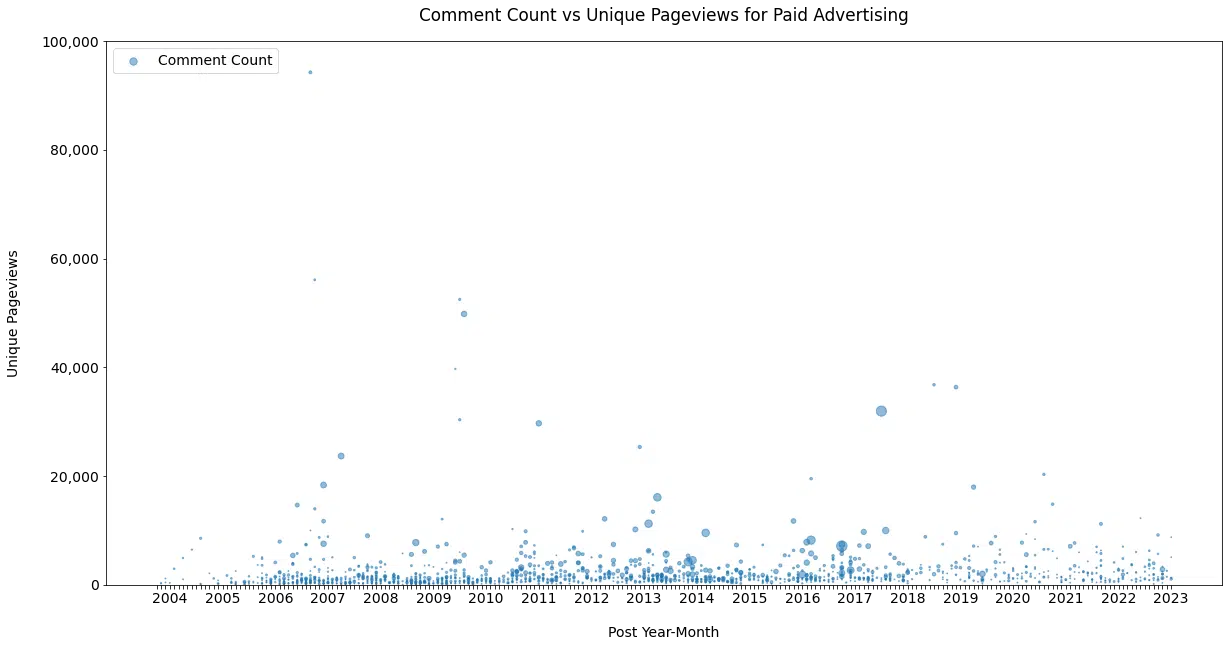
C'est beaucoup moins chaud du côté payé, mais cela montre le niveau accru d'intérêt, d'émotion et d'interaction pour les publications couvrant des changements qui peuvent potentiellement effacer des mois ou des années d'efforts.
Liens
Schwartz n'hésite pas à créer des liens avec les autres.
Comme mentionné précédemment, Schwartz a ajouté à contrecœur un attribut nofollow aux liens de parrainage des années après avoir reçu une modeste pénalité de Google en 2007.
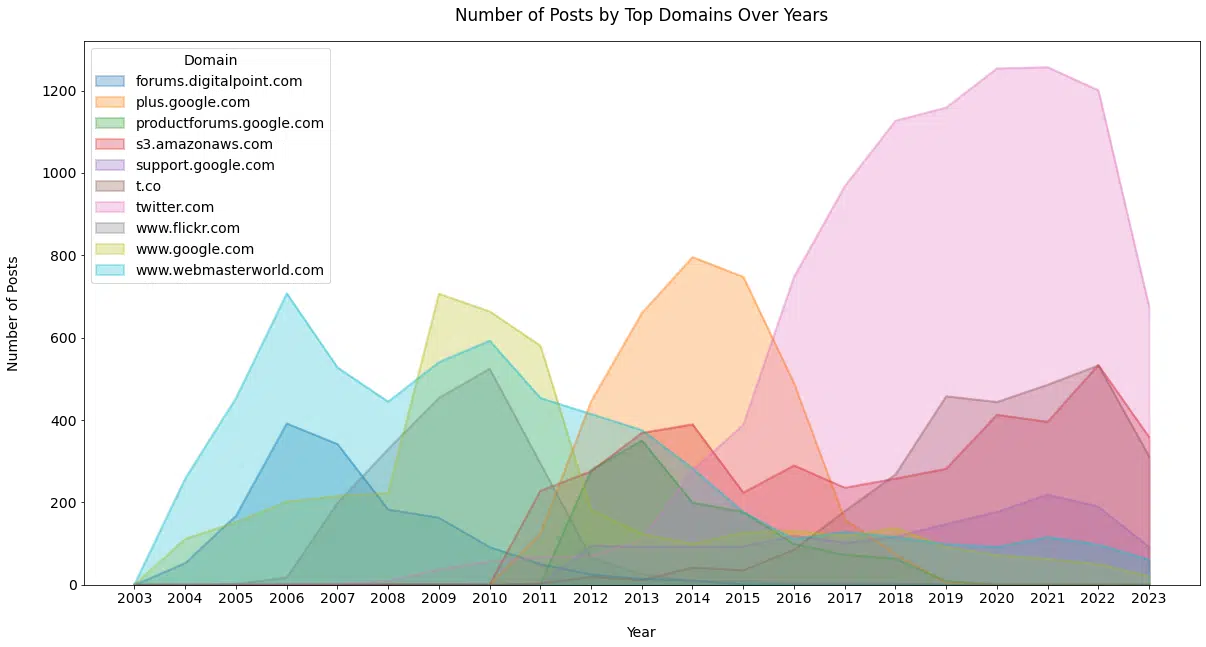
Schwartz a lié le contenu de ses publications à près de 4 000 domaines uniques au cours des 20 dernières années ( Figure 12 ).
Ce graphique montre les 10 principaux domaines liés de l'ensemble de données, illustrant clairement la valeur que Twitter a fournie à Schwartz pour faire apparaître des informations sur lesquelles écrire au cours des 10 dernières années.
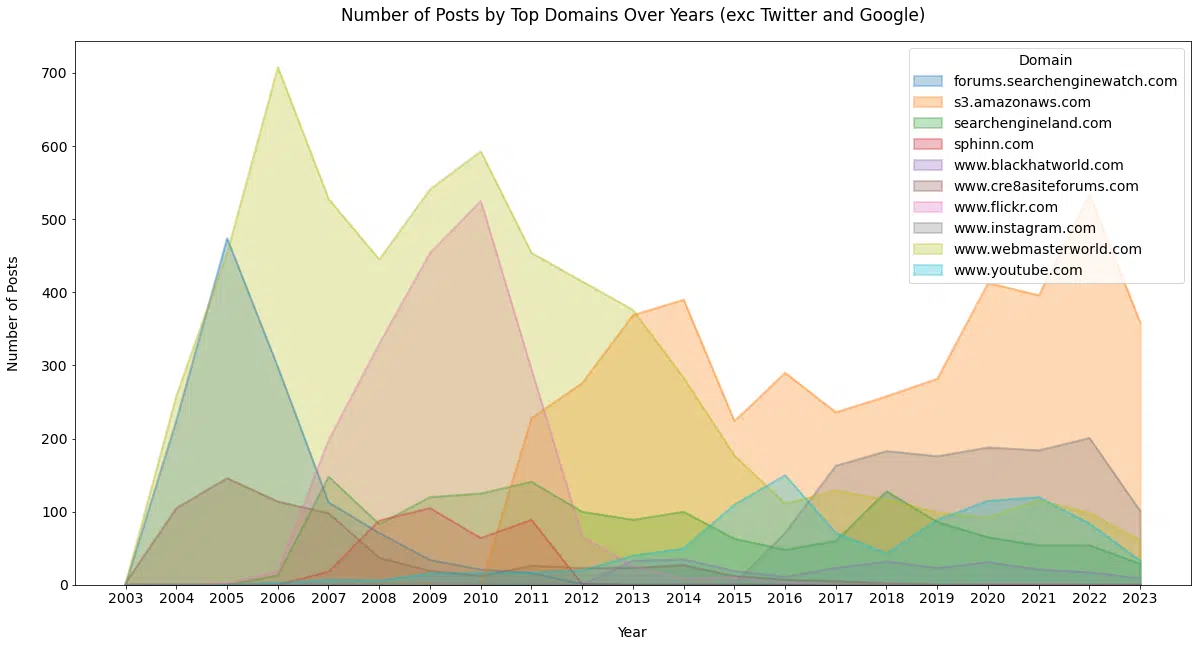
Le graphique suivant supprime Twitter et Google et fait la même chose ( Figure 13 ).
Nous commençons à voir quelques sites que les nouveaux référenceurs ignorent peut-être, mais beaucoup pourraient s'en souvenir avec plus ou moins d'affection.
Recevez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir conditions.
Visualisation des données des tendances de recherche au fil du temps
Voici un graphique à barres amusant montrant les meilleures catégories au cours des 20 dernières années ( Figure 14 ). Cela rappelle l'afflux de panique au sein de la communauté SEO lors des mises à jour de Google.
Dans une certaine mesure, cela apporte du réconfort, car même si le référencement évolue rapidement, il en a toujours été ainsi.
Figure 14 ( Voir l'animation complète ici .)
Schwartz poste comme un robot
Je pensais que quelque chose d'intéressant ici pourrait être utilisé pour indiquer où un certain jour était prioritaire pour la publication, mais non.
Publier juste comme ça arrive, et ça arrive souvent.
Je mentionne que Schwartz est un robot basé sur l'extraordinaire cohérence dont il a fait preuve dans l'affichage pendant de nombreuses années.
J'ai eu du mal à m'engager dans le même projet pendant plus de six mois, donc 20 ans, c'est plus qu'étonnant ( Figure 15 ).
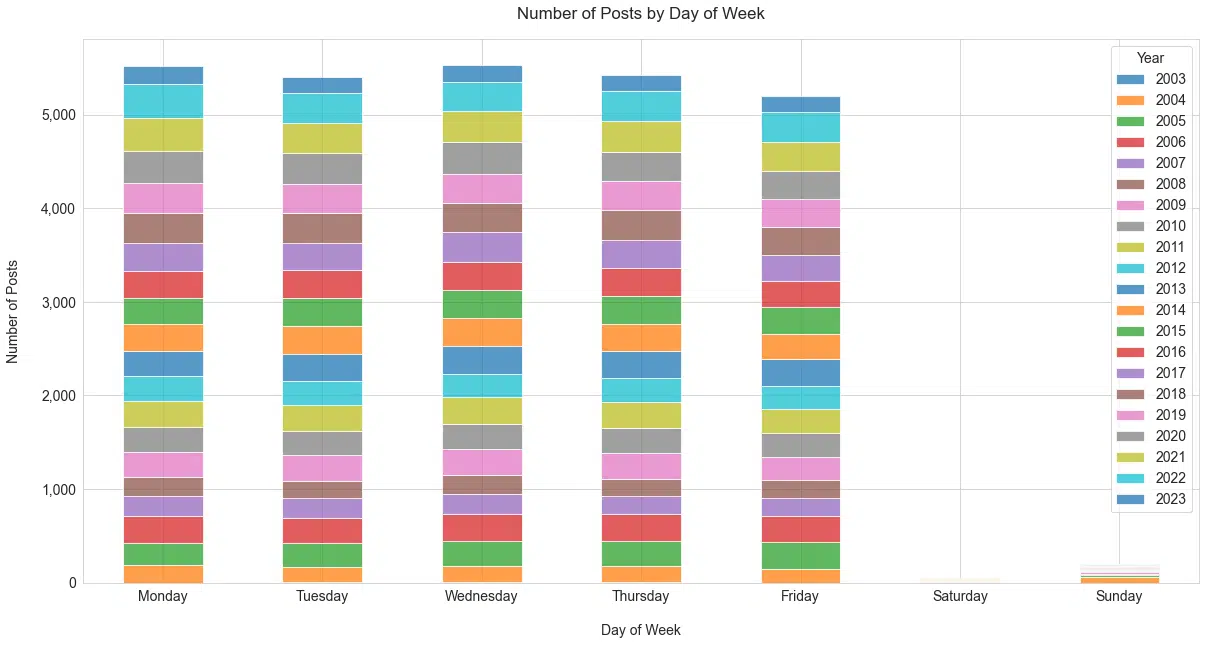
Pour équilibrer, voici le nombre de séances par jour de la semaine ( Figure 16 ). Je suppose que cela n'a vraiment pas d'importance, bien que le milieu de semaine soit clairement le gagnant.
En regardant les types de messages publiés au cours des dernières années, il ne semble pas y avoir une grande différence entre les types de messages en semaine ( Figure 17 ).
Là où nous voyons des différences, c'est le samedi et le dimanche, qui sont des jours qui impliquent généralement des événements temporels de grande importance.
Schwartz a historiquement publié rarement le samedi et le dimanche, avec respectivement 0,74% et 0,17% de tous les messages.
Cela a du sens intuitivement car il serait plus susceptible de rompre son week-end pour des éléments vraiment importants à couvrir.
Catégories importantes et nombre de mots
Il s'agit des principales catégories parmi celles examinées en fonction de la pente ( Figure 18 ). Pour référence, une pente est une mesure qui décrit la direction et la pente de la ligne.
L'une des raisons pour lesquelles ces catégories fonctionnent si bien du point de vue du trafic peut être que ce type de contenu sort de la bulle mondiale typique du référencement et s'étend à la population générale d'intérêt autour de Google.
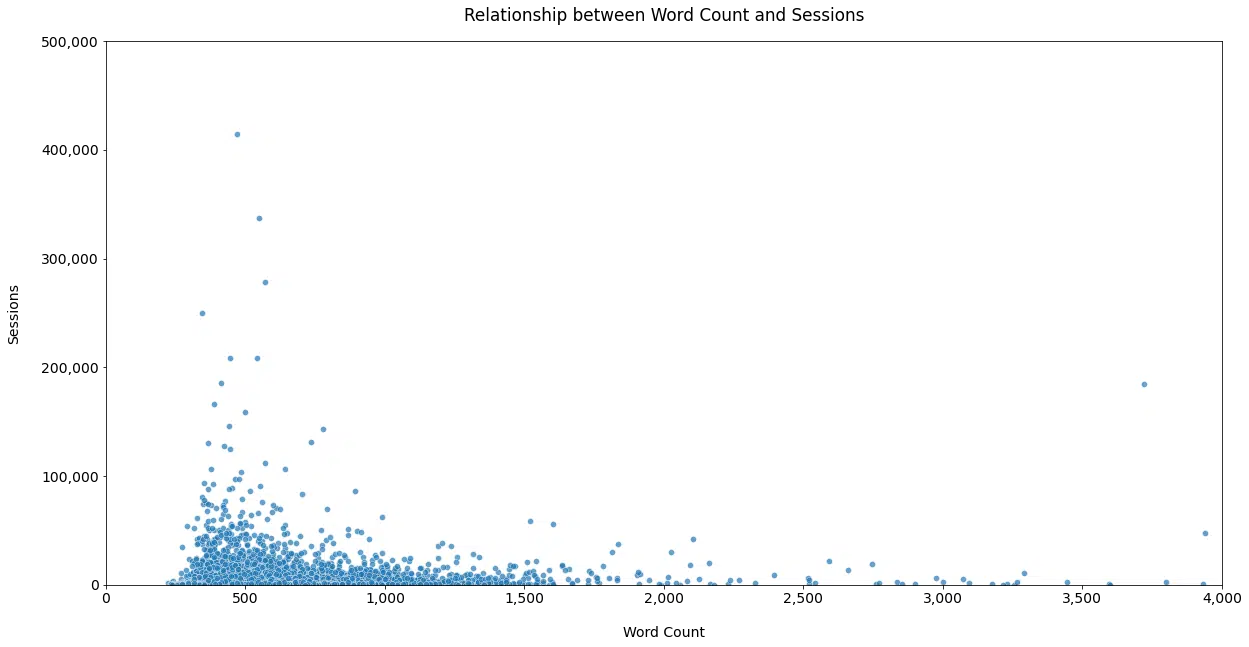
Schwartz a souvent déclaré qu'il se souciait plus de la diffusion des informations que de la profondeur avec laquelle elles sont couvertes.
Ceci est étayé par des données lorsque l'on examine la relation entre les sessions et le nombre de mots ( Figure 19 ).
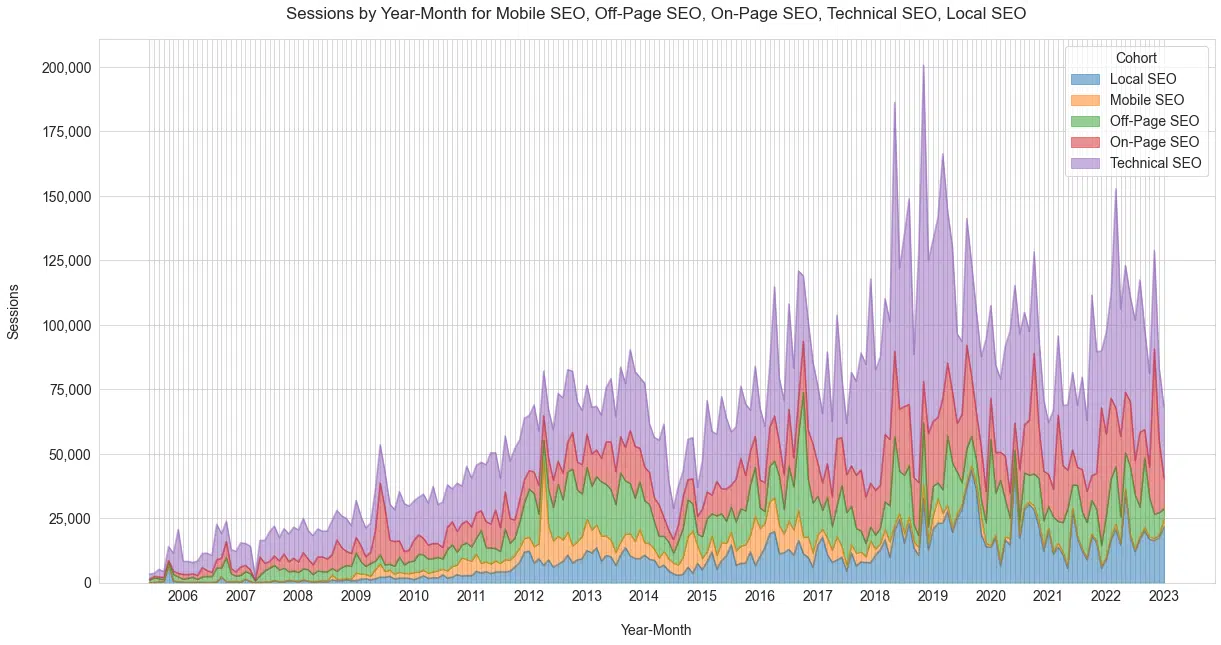
Comment le lectorat de Schwartz reflète l'industrie du référencement et l'intérêt pour différents segments
Sous-sections SEO
C'est là que les catégories peuvent me causer des ennuis.
À un niveau élevé, voici l'intérêt relatif de l'industrie du référencement par rapport aux adeptes et aux lecteurs de Schwartz pour les quatre principaux segments du référencement ( Figure 20 ).
Comme l'a souligné Mueller, vous pouvez bien voir la décennie du mobile.
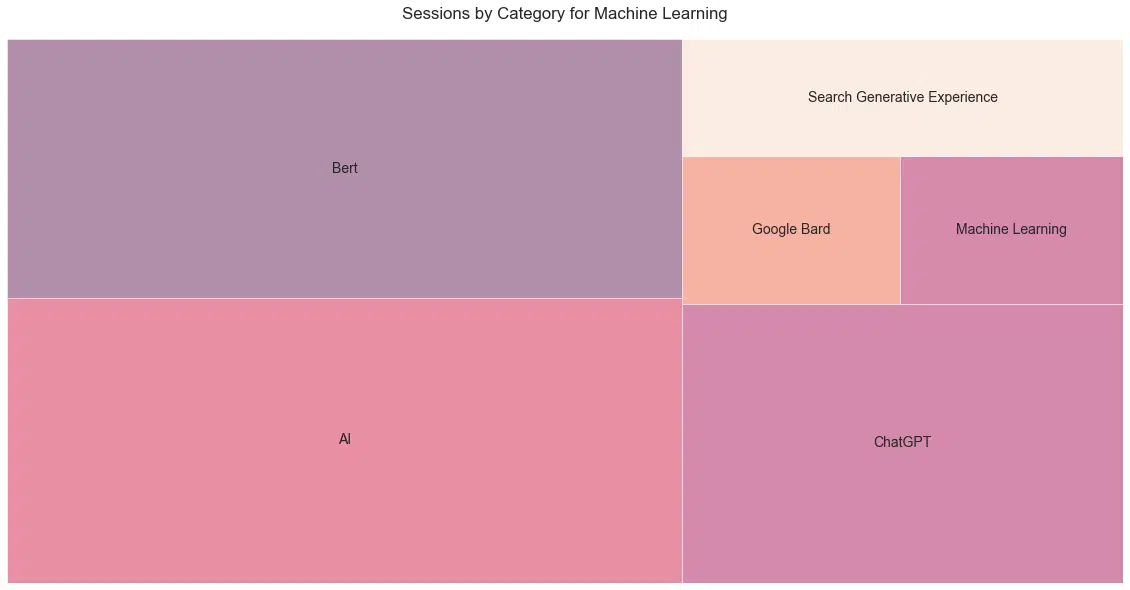
IA et SEO
OK, je voulais juste faire un treemap, mais c'est une vue sympa du nombre total de sessions par messages de la catégorie "Machine Learning" ( Figure 21 ).
Veuillez noter qu'il s'agit du nombre total de sessions du meilleur message dans chaque catégorie. Cela devrait contrôler la nouveauté relative de certaines des catégories.
Je trouve fascinant que l'entrée dans le lexique du BERT ait eu un impact plus important que les récents changements en matière d'apprentissage automatique.
Héros du référencement
Pour tous les gourous de la page, voici le niveau d'intérêt comparatif des membres de cette catégorie basé sur les sessions de la publication la plus performante ( Figure 22 ).
Une note ici que "Meta" peut être gonflé en raison de correspondances avec la société Meta (Facebook).
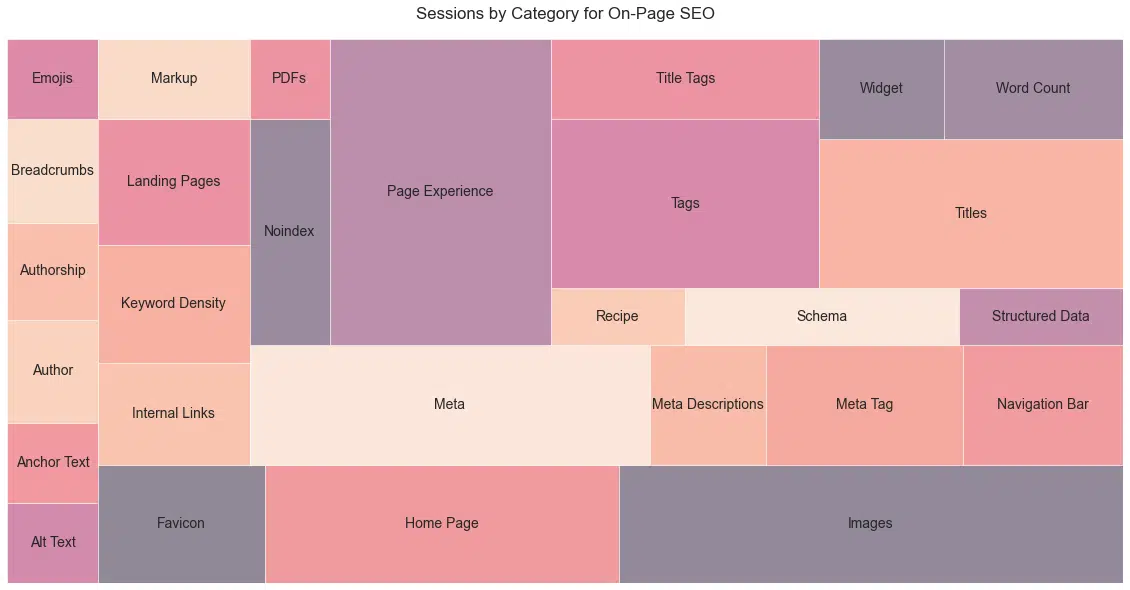
Voici les principales catégories par tactique ( Figure 23 ). Comme cela s'étend sur 20 ans, un certain nombre de ces tactiques pourraient en fait pénaliser un site Web.
Cela montre bien le passé mouvementé du référencement et la nature des pressions de Google en matière de relations publiques pour dénoncer les tactiques qui tentent de tromper leur système ou de nuire aux autres.
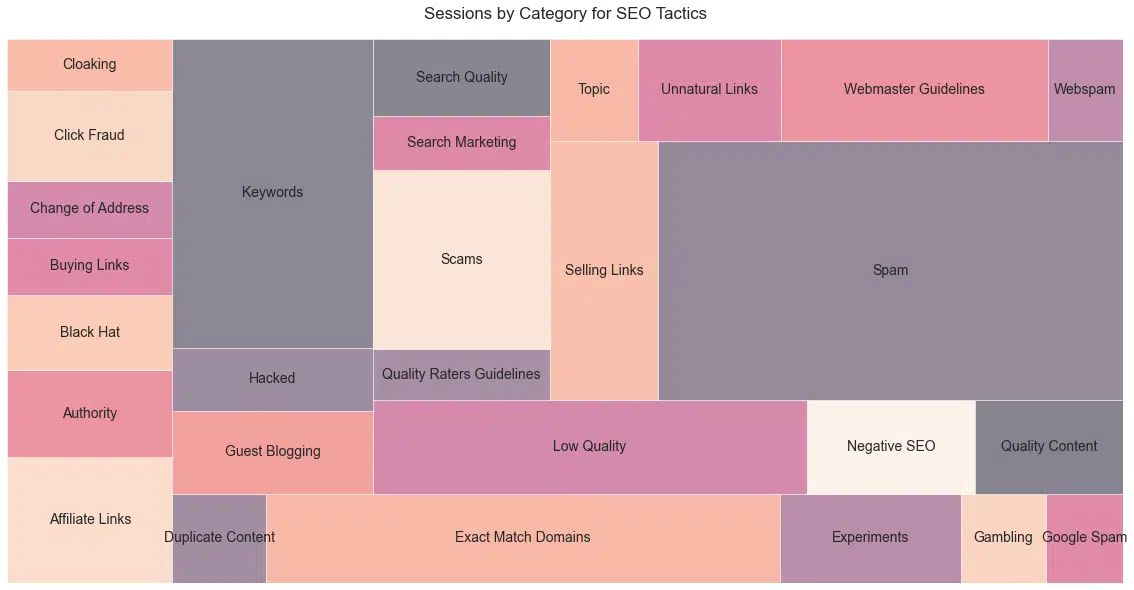
Payé
Pour mes amis du côté payant, voici les membres du groupe de publications "Publicité payante". ( Figure 24 ). Qui se souvient d'Overture ?
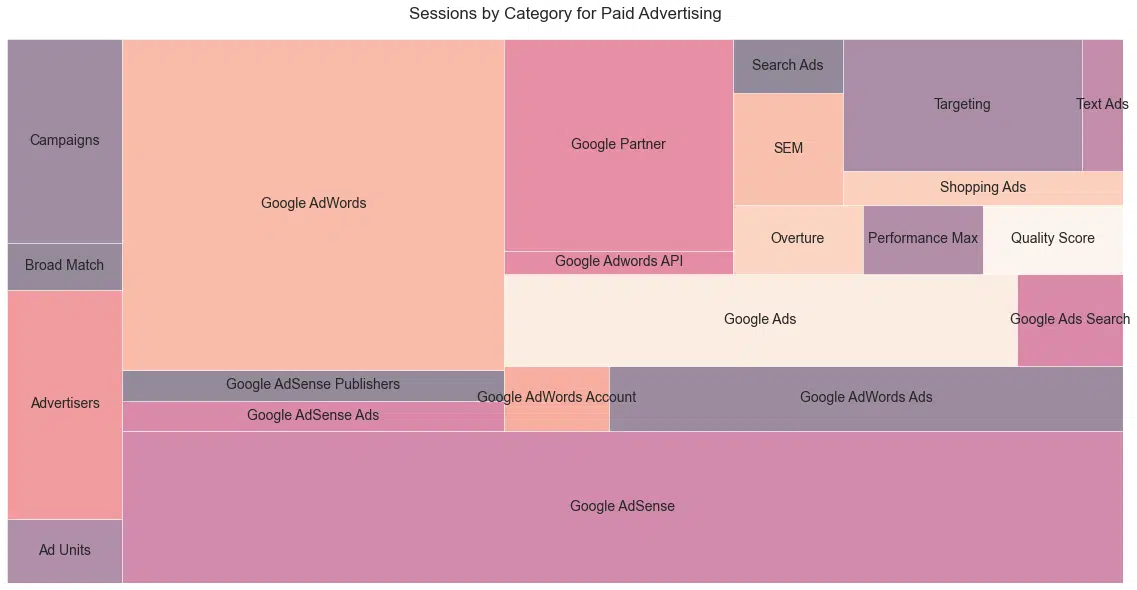
Navigateurs
Cela m'a surpris compte tenu de la couverture de Google sur ce site Web et de la part de marché déséquilibrée de Google (62,85%), mais chapeau à Schwartz pour la couverture uniforme ( Figure 25 ).
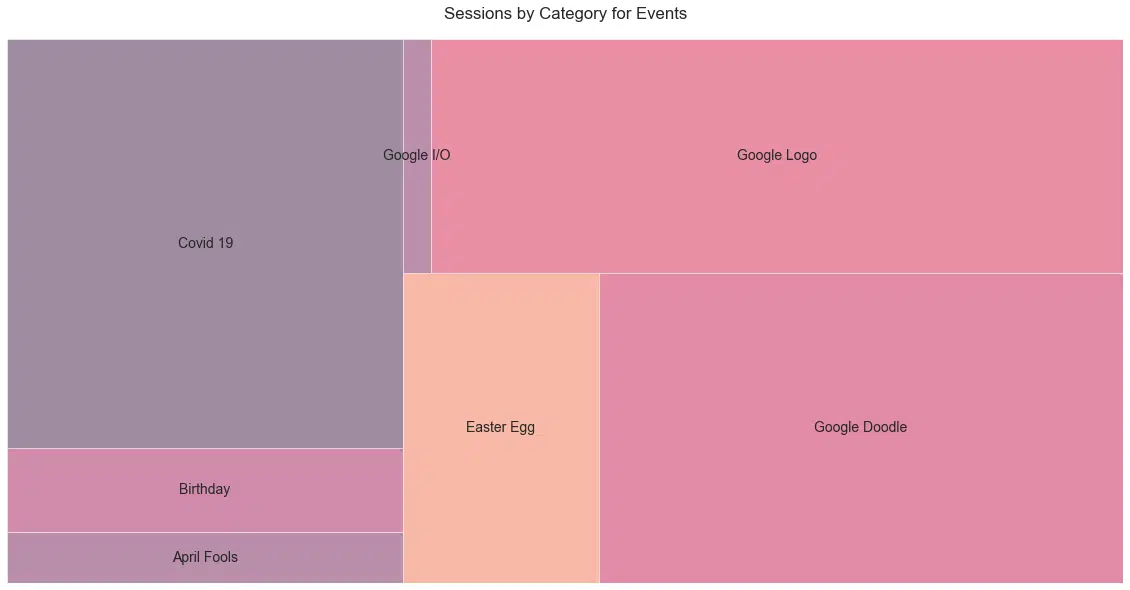
Événements
Certains messages antérieurs dans l'histoire ont promu des conférences spécifiques comme SMX, mais cela s'est déroulé sur une période relativement courte, ils ont donc été supprimés de l'ensemble de données.
Fait intéressant, le contenu COVID-19 dominant, qui a duré environ un an, a été comparé à d'autres catégories sur 20 ans ( Figure 26 ).
De plus, nous avons certainement besoin de plus d'oeufs de Pâques de Google. Schwartz m'a dit qu'il avait l'habitude de faire des événements de blog en direct, mais qu'il s'était arrêté il y a plus de dix ans.
J'ai supprimé la plupart (tous ?) des titres de l'ensemble de données qui ne mentionnaient pas au moins un sujet pertinent (par exemple, l'épisode vlog #1234 Weekly Roundup est un exemple de celui qui serait supprimé).
Schwartz a également mentionné qu'il avait cessé de couvrir les logos Google lorsque d'autres éditeurs ont commencé à les couvrir.
"Ils ont perdu leur plaisir."
À quel point est-ce cool de faire quelque chose d'aussi motivé par la passion et non par les clics ?
L'historique de la recherche dans 32 926 messages et comptage
Il est intéressant de revenir en arrière et de raconter tout ce qui a changé dans l'industrie et d'apprendre à connaître les jours de recherche du « Far West ».
Et nous devons remercier Barry Schwartz pour 20 ans de couverture de l'industrie sans faute.
S'il s'agit de marketing de recherche, nous savons que Schwartz l'a plus que probablement vu ou couvert.
Ce n'est pas nouveau.
Je tiens à remercier John Mueller et Patrick Stox pour leurs recommandations et vérifications de l'intégrité des informations et des données fournies ici. Danny Sullivan a également examiné pour un contrôle de santé mentale supplémentaire.
Les données et la méthodologie
J'ai commencé par explorer seroundtable.com dans Screaming Frog, en extrayant soigneusement le méta-contenu de la publication comme l'auteur, la date de publication et la catégorie à l'aide d'une extraction personnalisée. J'ai également extrait des données GA, bien que cela datant de 2005, je savais que cela ne suffirait pas. Les données HTML ont été sorties dans un fichier CSV pour un traitement ultérieur.
Puisqu'il y a de nombreux auteurs sur seroundtable.com, j'ai limité le reste de l'analyse aux articles écrits par Schwartz (il en a écrit plus de 32 000).
Pour mieux comprendre la contribution de Schwartz au site Web, voici un bref aperçu des 10 meilleurs auteurs et du nombre d'articles qui leur sont attribués ( Figure 27 ).
| Auteur | Des articles |
| Barry Schwartz | 32 786 |
| Tamar Weinberg | 1 875 |
| Ben Pfeiffer | 351 |
| Chris Bogg | 246 |
| cre8pc | 119 |
| point numérique | 40 |
| nachos | 34 |
| Evilgreenmonkey | 24 |
| mec de référencement | 22 |
| cshel | 21 |
J'ai ensuite configuré une extraction d'API à partir de l'API GA pour extraire les pages de destination et les sessions mensuelles pour tous les utilisateurs. De plus, nous avons extrait des données sur les pages vues et les liens externes.
Après avoir extrait toutes les données, j'ai remarqué que seroundtable.com utilisait AMP, ce qui signifie deux ensembles d'URL pour de nombreux articles. En regardant les limaces (par exemple,/category/this-is-a-slug.html), heureusement, elles étaient toutes uniques.
J'avais besoin d'éliminer les catégories, les pages d'auteur et les autres pages où le sujet n'était pas déductible du titre - en me limitant à l'endroit où Screaming Frog a trouvé les auteurs facilement nettoyés.
À partir de là, j'ai nettoyé les chemins d'URL vers des slugs uniques et les ai utilisés comme correspondance entre les données d'URL explorées et les données GA.
Il convient de noter que les données de seroundtable.com commencent dans GA au 4e trimestre 2005. Le premier message datait du 4e trimestre 2003. Comme l'a souligné Patrick Stox, le 14 novembre 2005 était le lancement officiel de GA, ce qui signifie nos données englobent toutes les données jusqu'à la naissance et la mort de GA comme nous le savions tous.
Avant cela, le site utilisait Urchin Analytics, devenu GA. Sur les 27 309 slugs uniques trouvés dans le crawl, seulement 0,2 % n'ont pas été trouvés dans les données GA. La plupart étaient après la date limite des données du 30 juin 2023.
Traitement du langage naturel (TAL)
Après m'être assuré que j'avais des données de page et des données analytiques propres, j'ai exécuté les titres de page à travers un processus qui les transforme en ngrams. Un ngramme est un groupement de n termes. Par exemple, « la grenouille verte » comprendrait : « la », « verte », « grenouille » comme 1 gramme, et « la verte », « grenouille verte » comme 2 grammes. Passer cela sur les titres et compter la fréquence de chaque niveau de gramme permet à des concepts importants de se développer.
Nous avons ensuite exécuté tous les ngrams importants dans un grand modèle de langage (LLM) pour voir dans quelle mesure il pouvait sélectionner des sujets importants et les combiner davantage dans des catégories pertinentes. C'est là que nous voyons les limites des LLM sur des sujets de niche. Bien que les modèles aient aidé dans le processus, il y a eu beaucoup de révisions manuelles de divers ngrams pour les concepts qui pourraient créer une catégorie.
De plus, il existe de nombreuses entités et concepts tels que "Google" et "recherche organique" dans l'ensemble de données qui sont présents dans de nombreux articles, tandis que des sujets temporellement importants comme "colibri" ne durent que quelques articles et confondent l'enfer des modèles de langage. .
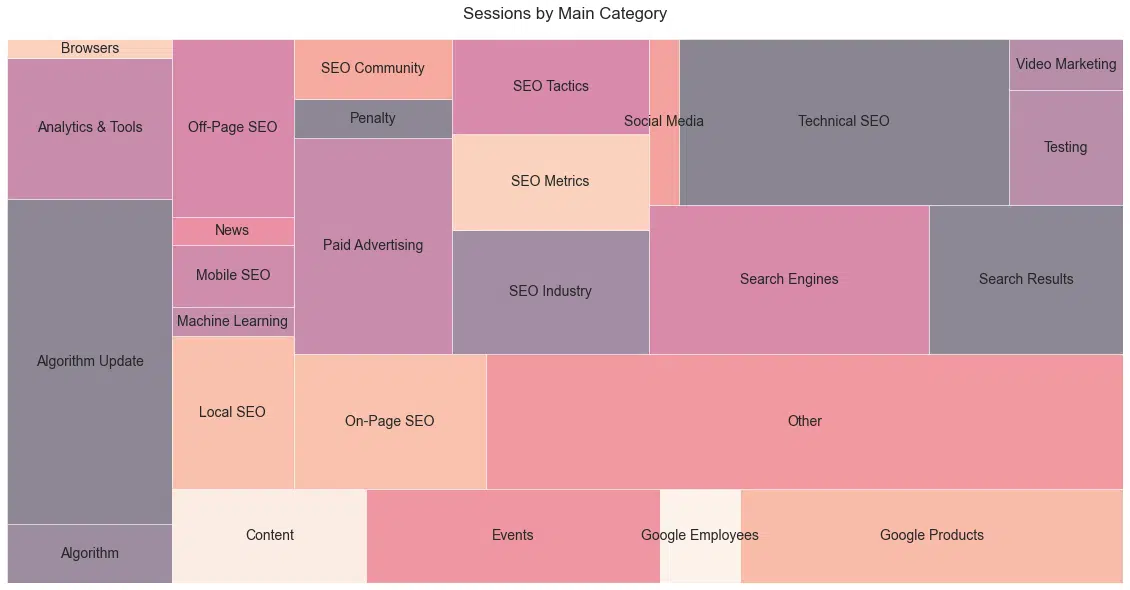
Vous pouvez consulter les données de catégorie ici et consulter les principales désignations de catégorie dans le graphique ci-dessous. Nous avons fait correspondre les catégories aux titres en utilisant une correspondance triée par longueur de mot inversée pour garantir que des phrases plus détaillées correspondent avant des phrases plus larges (plus courtes). Il convient de noter que nous avons divisé chaque sujet en une grande catégorie et une sous-catégorie plus détaillée.
Le graphique ci-dessous ( Figure 28 ) contient les grandes catégories avec des sessions au-dessus du 25e centile. Notez également que le processus de classification est très subjectif. Pour être sûr, les téléspectateurs trouveront des sujets qu'ils auraient classés différemment.
Les données de liens externes et les mentions d'outils de référencement ont été traitées via des analyses distinctes ciblant uniquement les parties de chaque page consacrées au contenu principal.
Les données de l'outil de référencement diffèrent des données catégorisées car elles prennent en compte le titre et le contenu. La catégorisation des messages a été faite sur le titre uniquement.
Le tableau, la catégorisation et les données historiques (annuelles) de pages vues et de sessions sont disponibles sur Suivi de 20 ans de données de recherche.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.