
TW-BERT : pondération des termes de requête de bout en bout et avenir de la recherche Google
Publié: 2023-09-14La recherche est difficile, comme l’écrivait Seth Godin en 2005.
Je veux dire, si nous pensons que le référencement est difficile (et c'est le cas), imaginez si vous essayiez de créer un moteur de recherche dans un monde où :
- Les utilisateurs varient considérablement et changent leurs préférences au fil du temps.
- La technologie à laquelle ils accèdent en matière de recherche progresse chaque jour.
- Les concurrents vous mordillent constamment les talons.
En plus de cela, vous avez également affaire à des référenceurs embêtants qui tentent de jouer avec votre algorithme pour obtenir des informations sur la meilleure façon d'optimiser pour vos visiteurs.
Cela va rendre les choses beaucoup plus difficiles.
Imaginez maintenant si les principales technologies sur lesquelles vous devez vous appuyer pour progresser avaient leurs propres limites – et, peut-être pire encore, des coûts énormes.
Eh bien, si vous êtes l'un des auteurs de l'article récemment publié, « End-to-End Query Term Weighting », vous voyez cela comme une opportunité de briller.
Qu'est-ce que la pondération des termes de requête de bout en bout ?
La pondération des termes de requête de bout en bout fait référence à une méthode dans laquelle le poids de chaque terme dans une requête est déterminé dans le cadre du modèle global, sans recourir à des schémas de pondération de termes traditionnels ou programmés manuellement, ni à d'autres modèles indépendants.
A quoi cela ressemble-t-il?
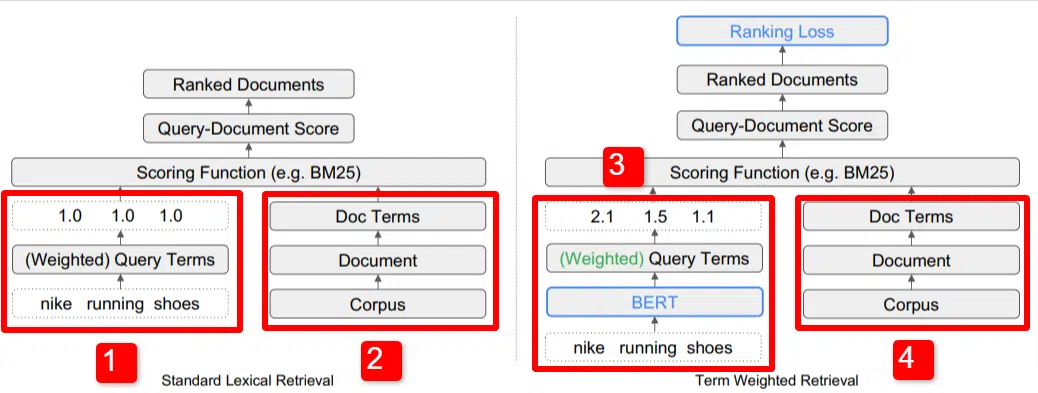
Nous voyons ici une illustration de l’un des principaux différenciateurs du modèle décrit dans l’article (figure 1, en particulier).
Sur le côté droit du modèle standard (2), nous voyons la même chose qu'avec le modèle proposé (4), qui est le corpus (ensemble complet de documents dans l'index), menant aux documents, menant aux termes.
Cela illustre la hiérarchie réelle du système, mais vous pouvez facilement y penser à l'envers, de haut en bas. Nous avons des conditions. Nous recherchons des documents contenant ces termes. Ces documents font partie du corpus de tous les documents que nous connaissons.
En bas à gauche (1) dans l'architecture standard de recherche d'informations (IR), vous remarquerez qu'il n'y a pas de couche BERT. La requête utilisée dans leur illustration (chaussures de course Nike) entre dans le système et les poids sont calculés indépendamment du modèle et lui sont transmis.
Dans l'illustration ici, les pondérations sont réparties de manière égale entre les trois mots de la requête. Cependant, il n’est pas nécessaire qu’il en soit ainsi. C'est simplement un défaut et une bonne illustration.
Ce qu'il est important de comprendre, c'est que les poids sont attribués depuis l'extérieur du modèle et saisis avec la requête. Nous expliquerons pourquoi cela est important dans un instant.
Si nous regardons la version terme-poids sur le côté droit, vous verrez que la requête « chaussures de course nike » entre dans BERT (Term Weighting BERT, ou TW-BERT, pour être précis) qui est utilisé pour attribuer les poids qui serait mieux appliqué à cette requête.
À partir de là, les choses suivent un chemin similaire pour les deux, une fonction de notation est appliquée et les documents sont classés. Mais il y a une dernière étape clé avec le nouveau modèle, qui est vraiment le but de tout cela, le calcul de la perte de classement.
Ce calcul, auquel je faisais référence ci-dessus, rend les pondérations déterminées dans le modèle si importantes. Pour mieux comprendre cela, prenons un rapide aparté pour discuter des fonctions de perte, ce qui est important pour vraiment comprendre ce qui se passe ici.
Qu'est-ce qu'une fonction de perte ?
Dans l'apprentissage automatique, une fonction de perte est essentiellement un calcul de l'erreur d'un système, ledit système essayant d'apprendre à se rapprocher le plus possible d'une perte nulle.
Prenons par exemple un modèle conçu pour déterminer les prix de l'immobilier. Si vous avez entré toutes les statistiques de votre maison et que vous avez obtenu une valeur de 250 000 $, mais que votre maison s'est vendue pour 260 000 $, la différence serait considérée comme une perte (qui est une valeur absolue).
À travers un grand nombre d'exemples, le modèle apprend à minimiser la perte en attribuant différents poids aux paramètres qui lui sont attribués jusqu'à ce qu'il obtienne le meilleur résultat. Dans ce cas, un paramètre peut inclure des éléments tels que les pieds carrés, les chambres, la taille de la cour, la proximité d'une école, etc.
Revenons maintenant à la pondération des termes de requête
En repensant aux deux exemples ci-dessus, ce sur quoi nous devons nous concentrer est la présence d'un modèle BERT pour fournir la pondération des termes en aval du calcul de la perte de classement.
En d’autres termes, dans les modèles traditionnels, la pondération des termes était indépendante du modèle lui-même et ne pouvait donc pas répondre aux performances du modèle global. Il n'a pas pu apprendre à améliorer les pondérations.

Dans le système proposé, cela change. La pondération est effectuée à partir du modèle lui-même et ainsi, à mesure que le modèle cherche à améliorer ses performances et à réduire la fonction de perte, il dispose de ces cadrans supplémentaires à tourner pour intégrer la pondération des termes dans l'équation. Littéralement.
ngrammes
TW-BERT n'est pas conçu pour fonctionner en termes de mots, mais plutôt de ngrammes.
Les auteurs de l'article illustrent bien pourquoi ils utilisent des ngrammes au lieu de mots lorsqu'ils soulignent que dans la requête « chaussures de course Nike », si vous pondérez simplement les mots, une page mentionnant les mots Nike, Running et Shoes pourrait même être bien classée. s'il s'agit de « chaussettes de course Nike » et de « chaussures de skate ».
Les méthodes IR traditionnelles utilisent des statistiques de requêtes et des statistiques de documents, et peuvent faire apparaître des pages présentant ce problème ou des problèmes similaires. Les tentatives passées pour résoudre ce problème se sont concentrées sur la cooccurrence et l'ordre.
Dans ce modèle, les ngrammes sont pondérés comme les mots l'étaient dans notre exemple précédent, nous obtenons donc quelque chose comme :
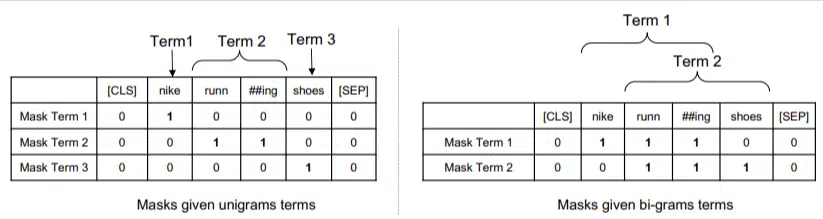
À gauche, nous voyons comment la requête serait pondérée en uni-grammes (ngrammes à 1 mot) et à droite, en bi-grammes (ngrammes à 2 mots).
Le système, parce que la pondération y est intégrée, peut s'entraîner sur toutes les permutations pour déterminer les meilleurs ngrammes ainsi que le poids approprié pour chacun, au lieu de s'appuyer uniquement sur des statistiques comme la fréquence.
Coup zéro
Une caractéristique importante de ce modèle est ses performances dans les tâches zéro-short. Les auteurs ont testé sur :
- Ensemble de données MS MARCO – Ensemble de données Microsoft pour le classement des documents et des passages
- Ensemble de données TREC-COVID – Articles et études COVID
- Robust04 – Articles de presse
- Tronc commun – Articles pédagogiques et billets de blog
Ils n'avaient qu'un petit nombre de requêtes d'évaluation et n'en utilisaient aucune pour le réglage fin, ce qui en faisait un test nul dans la mesure où le modèle n'était pas formé pour classer les documents sur ces domaines spécifiquement. Les résultats étaient les suivants :
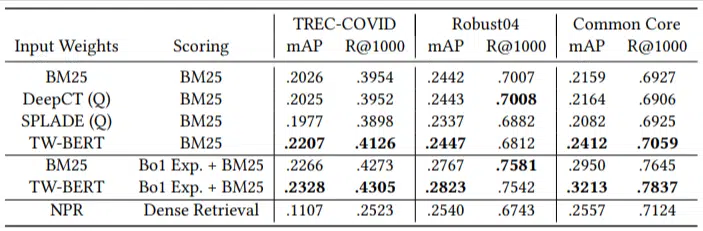
Il a surperformé dans la plupart des tâches et a mieux fonctionné sur les requêtes plus courtes (1 à 10 mots).
Et c'est plug-and-play !
OK, c'est peut-être trop simpliste, mais les auteurs écrivent :
« L'alignement de TW-BERT avec les scoreurs des moteurs de recherche minimise les changements nécessaires pour l'intégrer dans les applications de production existantes , alors que les méthodes de recherche existantes basées sur l'apprentissage en profondeur nécessiteraient une optimisation supplémentaire de l'infrastructure et des exigences matérielles. Les poids appris peuvent être facilement utilisés par les récupérateurs lexicaux standards et par d’autres techniques de récupération telles que l’expansion des requêtes.
Étant donné que TW-BERT est conçu pour s'intégrer au système actuel, l'intégration est beaucoup plus simple et moins coûteuse que les autres options.
Ce que tout cela signifie pour vous
Avec les modèles d'apprentissage automatique, il est difficile de prédire par exemple ce que vous pouvez faire en tant que référenceur (en dehors des déploiements visibles comme Bard ou ChatGPT).
Une permutation de ce modèle sera sans aucun doute déployée en raison de ses améliorations et de sa facilité de déploiement (en supposant que les déclarations soient exactes).
Cela dit, il s’agit d’une amélioration de la qualité de vie chez Google, qui améliorera les classements et les résultats zéro à faible coût.
Tout ce sur quoi nous pouvons réellement compter, c’est que si nous les mettons en œuvre, de meilleurs résultats apparaîtront de manière plus fiable. Et c'est une bonne nouvelle pour les professionnels du référencement.
Les opinions exprimées dans cet article sont celles de l’auteur invité et ne sont pas nécessairement celles de Search Engine Land. Les auteurs du personnel sont répertoriés ici.