
Qu’est-ce que l’IA générative et comment fonctionne-t-elle ?
Publié: 2023-09-26L’IA générative, un sous-ensemble de l’intelligence artificielle, est devenue une force révolutionnaire dans le monde de la technologie. mais qu'est ce que c'est exactement? Et pourquoi retient-il autant d’attention ?
Ce guide détaillé examinera le fonctionnement des modèles d'IA génératifs, ce qu'ils peuvent et ne peuvent pas faire, ainsi que les implications de tous ces éléments.
Qu’est-ce que l’IA générative ?
L'IA générative, ou genAI, fait référence à des systèmes capables de générer de nouveaux contenus, qu'il s'agisse de texte, d'images, de musique ou même de vidéos. Traditionnellement, l’IA/ML signifiait trois choses : l’apprentissage supervisé, non supervisé et par renforcement. Chacun donne des informations basées sur la sortie du clustering.
Les modèles d'IA non génératifs effectuent des calculs basés sur des entrées (comme classer une image ou traduire une phrase). En revanche, les modèles génératifs produisent de « nouveaux » résultats tels que l'écriture d'essais, la composition de musique, la conception graphique et même la création de visages humains réalistes qui n'existent pas dans le monde réel.
Les implications de l’IA générative
L’essor de l’IA générative a des implications importantes. Avec la capacité de générer du contenu, des secteurs comme le divertissement, le design et le journalisme connaissent un changement de paradigme.
Par exemple, les agences de presse peuvent utiliser l’IA pour rédiger des rapports, tandis que les concepteurs peuvent obtenir des suggestions graphiques assistées par l’IA. L'IA peut générer des centaines de slogans publicitaires en quelques secondes, que ces options soient bonnes ou non. ou pas, c'est une autre affaire.
L'IA générative peut produire du contenu sur mesure pour les utilisateurs individuels. Pensez à quelque chose comme une application musicale qui compose une chanson unique en fonction de votre humeur ou une application d'actualités qui rédige des articles sur des sujets qui vous intéressent.
Le problème est qu’à mesure que l’IA joue un rôle plus important dans la création de contenu, les questions sur l’authenticité, le droit d’auteur et la valeur de la créativité humaine deviennent plus prédominantes.
Comment fonctionne l’IA générative ?
L’IA générative consiste essentiellement à prédire la prochaine donnée dans une séquence, qu’il s’agisse du prochain mot d’une phrase ou du prochain pixel d’une image. Voyons comment cela est réalisé.
Modèles statistiques
Les modèles statistiques constituent l’épine dorsale de la plupart des systèmes d’IA. Ils utilisent des équations mathématiques pour représenter la relation entre différentes variables.
Pour l'IA générative, les modèles sont entraînés à reconnaître des modèles dans les données, puis à utiliser ces modèles pour générer de nouvelles données similaires.
Si un modèle est entraîné sur des phrases anglaises, il apprend la probabilité statistique qu'un mot se succède, ce qui lui permet de générer des phrases cohérentes.
Collecte de données
La qualité et la quantité des données sont cruciales. Les modèles génératifs sont formés sur de vastes ensembles de données pour comprendre les modèles.
Pour un modèle linguistique, cela peut signifier ingérer des milliards de mots provenant de livres, de sites Web et d’autres textes.
Pour un modèle d’image, cela pourrait signifier analyser des millions d’images. Plus les données de formation sont diverses et complètes, plus le modèle générera des résultats diversifiés.
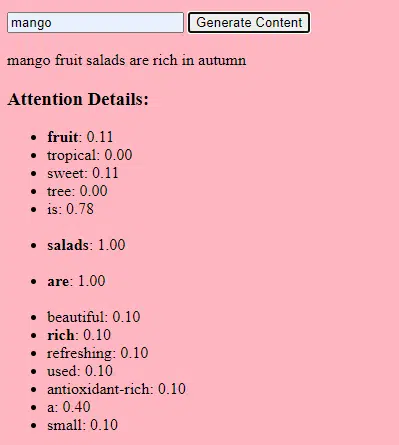
Comment fonctionnent les transformateurs et l’attention
Les transformateurs sont un type d'architecture de réseau neuronal introduit dans un article de 2017 intitulé « L'attention est tout ce dont vous avez besoin » par Vaswani et al. Depuis, ils sont devenus la base de la plupart des modèles linguistiques de pointe. ChatGPT ne fonctionnerait pas sans transformateurs.
Le mécanisme « d'attention » permet au modèle de se concentrer sur différentes parties des données d'entrée, un peu comme la façon dont les humains prêtent attention à des mots spécifiques lorsqu'ils comprennent une phrase.
Ce mécanisme permet au modèle de décider quelles parties de l'entrée sont pertinentes pour une tâche donnée, ce qui le rend très flexible et puissant.
Le code ci-dessous est une analyse fondamentale des mécanismes du transformateur, expliquant chaque pièce dans un anglais simple.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)Dans le code, vous pouvez avoir une classe Transformer et une seule classe TransformerLayer. C'est comme avoir un plan pour un étage par rapport à un bâtiment entier.
Ce morceau de code TransformerLayer vous montre comment fonctionnent des composants spécifiques, tels que l'attention multi-têtes et les arrangements spécifiques.
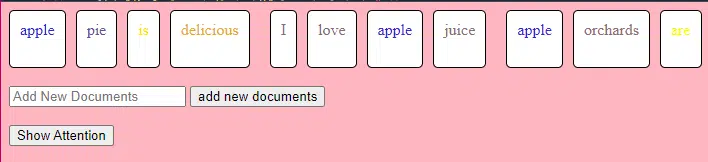
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)Un réseau de neurones à action directe est l’un des types les plus simples de réseaux de neurones artificiels. Il se compose d’une couche d’entrée, d’une ou plusieurs couches cachées et d’une couche de sortie.
Les données circulent dans une seule direction : depuis la couche d'entrée, à travers les couches cachées et vers la couche de sortie. Il n'y a pas de boucles ni de cycles dans le réseau.
Dans le contexte de l'architecture du transformateur, le réseau neuronal à action directe est utilisé après le mécanisme d'attention dans chaque couche. Il s'agit d'une simple transformation linéaire à deux couches avec une activation ReLU entre les deux.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Comment fonctionne l'IA générative – en termes simples
Considérez l’IA générative comme un lancer de dés pondéré. Les données d'entraînement déterminent les poids (ou probabilités).
Si le dé représente le mot suivant dans une phrase, un mot qui suit souvent le mot actuel dans les données d'entraînement aura un poids plus élevé. Ainsi, « ciel » pourrait suivre « bleu » plus souvent que « banane ». Lorsque l’IA « lance les dés » pour générer du contenu, elle est plus susceptible de choisir des séquences statistiquement plus probables en fonction de son entraînement.
Alors, comment les LLM peuvent-ils générer du contenu qui « semble » original ?
Prenons une fausse liste – les « meilleurs cadeaux de l'Aïd al-Fitr pour les spécialistes du marketing de contenu » – et voyons comment un LLM peut générer cette liste en combinant des indices textuels provenant de documents sur les cadeaux, l'Aïd et les spécialistes du marketing de contenu.
Avant le traitement, le texte est décomposé en morceaux plus petits appelés « jetons ». Ces jetons peuvent être aussi courts qu’un caractère ou aussi longs qu’un mot.
Exemple : « L'Aïd al-Fitr est une célébration » devient [« Eid », « al-Fitr », « est », « une », « célébration »].
Cela permet au modèle de fonctionner avec des morceaux de texte gérables et de comprendre la structure des phrases.
Chaque jeton est ensuite converti en vecteur (une liste de nombres) à l'aide d'intégrations. Ces vecteurs capturent le sens et le contexte de chaque mot.
Le codage positionnel ajoute des informations à chaque vecteur de mot sur sa position dans la phrase, garantissant ainsi que le modèle ne perd pas ces informations d'ordre.
Ensuite, nous utilisons un mécanisme d'attention : cela permet au modèle de se concentrer sur différentes parties du texte d'entrée lors de la génération d'une sortie. Si vous vous souvenez de BERT, c'est ce qui était si excitant pour les Googleurs à propos de BERT.
Si notre modèle a vu des textes sur les « cadeaux » et sait que les gens offrent des cadeaux lors des célébrations , et qu'il a également vu des textes sur « l'Aïd al-Fitr » comme une célébration importante, il prêtera « attention » à ces liens.
De même, s'il a vu des textes sur les « spécialistes du marketing de contenu » ayant besoin d'outils ou de ressources spécifiques, il peut relier l'idée de « cadeaux » aux « spécialistes du marketing de contenu ».

Nous pouvons désormais combiner des contextes : à mesure que le modèle traite le texte saisi via plusieurs couches Transformer, il combine les contextes qu'il a appris.
Ainsi, même si les textes originaux n'ont jamais mentionné « cadeaux de l'Aïd al-Fitr pour les spécialistes du marketing de contenu », le modèle peut rassembler les concepts d'« Aïd al-Fitr », de « cadeaux » et de « spécialistes du marketing de contenu » pour générer ce contenu.
En effet, il a appris les contextes plus larges autour de chacun de ces termes.
Après avoir traité l'entrée via le mécanisme d'attention et les réseaux de rétroaction dans chaque couche Transformer, le modèle produit une distribution de probabilité sur son vocabulaire pour le mot suivant de la séquence.
On pourrait penser qu’après des mots comme « meilleur » et « Eid al-Fitr », le mot « cadeaux » a de fortes chances de venir ensuite. De même, il pourrait associer des « cadeaux » à des destinataires potentiels tels que des « spécialistes du marketing de contenu ».
Obtenez la newsletter quotidienne sur laquelle les spécialistes du marketing de recherche comptent.
Voir les conditions.
Comment sont construits les grands modèles de langage
Le passage d'un modèle de transformateur de base à un modèle de langage étendu (LLM) sophistiqué comme GPT-3 ou BERT implique la mise à l'échelle et le raffinement de divers composants.
Voici une ventilation étape par étape :
Les LLM sont formés sur de grandes quantités de données textuelles. Il est difficile d'expliquer l'ampleur de ces données.
L'ensemble de données C4, point de départ de nombreux LLM, comprend 750 Go de données texte. Cela représente 805 306 368 000 octets – beaucoup d'informations. Ces données peuvent inclure des livres, des articles, des sites Web, des forums, des sections de commentaires et d'autres sources.
Plus les données sont variées et complètes, meilleures sont les capacités de compréhension et de généralisation du modèle.
Bien que l'architecture de base du transformateur reste la base, les LLM comportent un nombre beaucoup plus important de paramètres. GPT-3, par exemple, possède 175 milliards de paramètres. Dans ce cas, les paramètres font référence aux poids et aux biais du réseau neuronal appris au cours du processus de formation.
En apprentissage profond, un modèle est entraîné à faire des prédictions en ajustant ces paramètres afin de réduire la différence entre ses prédictions et les résultats réels.

Le processus d'ajustement de ces paramètres est appelé optimisation, qui utilise des algorithmes tels que la descente de gradient.
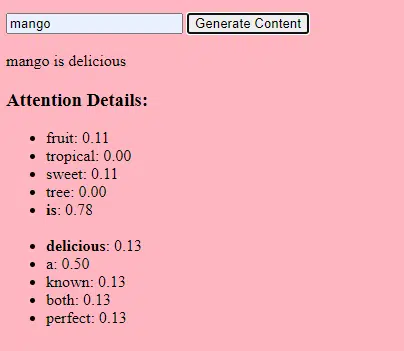
- Poids : ce sont des valeurs du réseau neuronal qui transforment les données d'entrée au sein des couches du réseau. Ils sont ajustés pendant la formation pour optimiser le rendement du modèle. Chaque connexion entre neurones de couches adjacentes a un poids associé.
- Biais : ce sont également des valeurs du réseau neuronal qui sont ajoutées à la sortie de la transformation d'une couche. Ils offrent un degré de liberté supplémentaire au modèle, lui permettant de mieux s'adapter aux données d'entraînement. Chaque neurone d'une couche a un biais associé.
Cette mise à l'échelle permet au modèle de stocker et de traiter des modèles et des relations plus complexes dans les données.
Le grand nombre de paramètres signifie également que le modèle nécessite une puissance de calcul et une mémoire importantes pour la formation et l'inférence. C'est pourquoi la formation de tels modèles nécessite beaucoup de ressources et utilise généralement du matériel spécialisé comme des GPU ou des TPU.
Le modèle est entraîné pour prédire le mot suivant dans une séquence à l’aide de puissantes ressources informatiques. Il ajuste ses paramètres internes en fonction des erreurs qu’il commet, améliorant ainsi continuellement ses prédictions.
Les mécanismes d'attention comme ceux dont nous avons discuté sont essentiels pour les LLM. Ils permettent au modèle de se concentrer sur différentes parties de l’entrée lors de la génération de la sortie.
En pesant l'importance de différents mots dans un contexte, les mécanismes d'attention permettent au modèle de générer un texte cohérent et contextuellement pertinent. Le faire à cette échelle permet aux LLM de fonctionner comme ils le font.
Comment un transformateur prédit-il le texte ?
Les transformateurs prédisent le texte en traitant les jetons d'entrée à travers plusieurs couches, chacune équipée de mécanismes d'attention et de réseaux de rétroaction.
Après traitement, le modèle produit une distribution de probabilité sur son vocabulaire pour le mot suivant de la séquence. Le mot ayant la probabilité la plus élevée est généralement sélectionné comme prédiction.
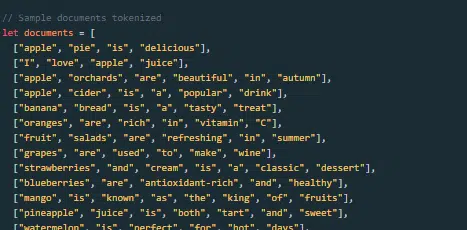
Comment un grand modèle de langage est-il construit et formé ?
Construire un LLM implique de collecter des données, de les nettoyer, de former le modèle, de l'affiner et de procéder à des tests rigoureux et continus.
Le modèle est initialement entraîné sur un vaste corpus pour prédire le mot suivant dans une séquence. Cette phase permet au modèle d'apprendre des liens entre des mots qui reprennent des modèles de grammaire, des relations qui peuvent représenter des faits sur le monde et des connexions qui ressemblent à un raisonnement logique. Ces connexions lui permettent également de détecter les biais présents dans les données d'entraînement.
Après la pré-formation, le modèle est affiné sur un ensemble de données plus restreint, souvent avec des évaluateurs humains suivant les directives.
La mise au point est une étape cruciale dans la création de LLM. Cela implique de former le modèle pré-entraîné sur un ensemble de données ou une tâche plus spécifique. Prenons ChatGPT comme exemple.
Si vous avez joué avec des modèles GPT, vous savez que l'invite consiste moins à « écrire cette chose » qu'à
- Invite : Il était une fois
- Suite : Il y avait un sorcier maléfique au sommet d'une tour.
- Suite : Il y avait un sorcier maléfique au sommet d'une tour.
- Invite : Pourquoi le poulet a-t-il rejoint un groupe ?
- Suite : Parce qu'il avait les baguettes !
Pour accéder à ChatGPT à partir de ce moment-là, cela implique beaucoup de travail peu rémunéré. Ces personnes créent d’immenses corpus pour mettre le doigt sur le poids des réponses GPT et des comportements attendus. Ces travailleurs créent des tonnes de textes d'invite/de continuation qui ressemblent à :
- Invite : Terminez cette histoire : "Il était une fois..."
- Suite : Bien sûr ! Il était une fois, dans un pays très très lointain, un petit village niché entre deux montagnes majestueuses.
- Suite : Bien sûr ! Il était une fois, dans un pays très très lointain, un petit village niché entre deux montagnes majestueuses.
- Invite : Racontez-moi une blague sur un poulet.
- Suite : Pourquoi le poulet a-t-il rejoint un groupe ? Parce qu'il y avait les baguettes !
Ce processus de mise au point est essentiel pour plusieurs raisons :
- Spécificité : alors que la pré-formation donne au modèle une large compréhension du langage, le réglage fin restreint ses connaissances et son comportement pour s'aligner davantage sur des tâches ou des domaines spécifiques. Par exemple, un modèle affiné sur les données médicales répondra mieux aux questions médicales.
- Contrôle : le réglage fin donne aux développeurs plus de contrôle sur les sorties du modèle. Les développeurs peuvent utiliser un ensemble de données organisé pour guider le modèle afin de produire les réponses souhaitées et d'éviter les comportements indésirables.
- Sécurité : cela aide à réduire les sorties nocives ou biaisées. En utilisant des lignes directrices pendant le processus de réglage fin, les réviseurs humains peuvent garantir que le modèle ne produit pas de contenu inapproprié.
- Performances : un réglage fin peut améliorer considérablement les performances du modèle sur des tâches spécifiques. Par exemple, un modèle affiné pour le support client sera bien meilleur qu’un modèle générique.
Vous pouvez dire que ChatGPT a été affiné en particulier à certains égards.
Par exemple, le « raisonnement logique » est un problème avec lequel les LLM ont tendance à avoir du mal. Le meilleur modèle de raisonnement logique de ChatGPT – GPT-4 – a été intensément entraîné pour reconnaître explicitement des modèles dans les nombres.
Au lieu de quelque chose comme ça :
- Invite : Qu’est-ce que 2+2 ?
- Processus : Souvent dans les manuels de mathématiques pour les enfants 2+2 =4. Parfois, il y a des références à « 2+2=5 », mais il y a généralement plus de contexte à voir avec George Orwell ou Star Trek lorsque c'est le cas. Si c’était dans ce contexte, le poids serait plutôt en faveur de 2+2=5. Mais ce contexte n'existe pas, donc dans ce cas, le prochain jeton est probablement 4.
- Réponse : 2+2=4
La formation fait quelque chose comme ceci :
- entraînement : 2+2=4
- entraînement : 4/2=2
- formation : la moitié de 4 est 2
- formation : 2 sur 2 fait quatre
…et ainsi de suite.
Cela signifie que pour ces modèles plus « logiques », le processus de formation est plus rigoureux et vise à garantir que le modèle comprend et applique correctement les principes logiques et mathématiques.
Le modèle est exposé à divers problèmes mathématiques et à leurs solutions, garantissant ainsi qu'il peut généraliser et appliquer ces principes à de nouveaux problèmes invisibles.
L’importance de ce processus de mise au point, notamment pour le raisonnement logique, ne peut être surestimée. Sans cela, le modèle pourrait fournir des réponses incorrectes ou absurdes à des questions logiques ou mathématiques simples.
Modèles d'image et modèles de langage
Bien que les modèles d'image et de langage puissent utiliser des architectures similaires comme les transformateurs, les données qu'ils traitent sont fondamentalement différentes :
Modèles d'images
Ces modèles traitent les pixels et fonctionnent souvent de manière hiérarchique, analysant d'abord les petits motifs (comme les bords), puis les combinant pour reconnaître des structures plus grandes (comme les formes), et ainsi de suite jusqu'à ce qu'ils comprennent l'image entière.
Modèles de langage
Ces modèles traitent des séquences de mots ou de caractères. Ils doivent comprendre le contexte, la grammaire et la sémantique pour générer un texte cohérent et contextuellement pertinent.
Comment fonctionnent les principales interfaces d’IA générative
Dall-E + Midjourney
Dall-E est une variante du modèle GPT-3 adaptée pour la génération d'images. Il est formé sur un vaste ensemble de données de paires texte-image. Midjourney est un autre logiciel de génération d'images basé sur un modèle propriétaire.
- Entrée : vous fournissez une description textuelle, comme « un flamant rose à deux têtes ».
- Traitement : ces modèles codent ce texte en une série de nombres, puis décodent ces vecteurs, trouvant des relations avec les pixels, pour produire une image. Le modèle a appris les relations entre les descriptions textuelles et les représentations visuelles à partir de ses données d'entraînement.
- Résultat : une image qui correspond ou se rapporte à la description donnée.
Doigts, modèles, problèmes
Pourquoi ces outils ne peuvent-ils pas générer systématiquement des mains qui semblent normales ? Ces outils fonctionnent en regardant les pixels les uns à côté des autres.
Vous pouvez voir comment cela fonctionne en comparant des images générées plus tôt ou plus primitives avec des images plus récentes : les modèles antérieurs semblent très flous. En revanche, les modèles plus récents sont beaucoup plus nets.
Ces modèles génèrent des images en prédisant le prochain pixel en fonction des pixels qu'il a déjà générés. Ce processus est répété des millions de fois pour produire une image complète.
Les mains, en particulier les doigts, sont complexes et comportent de nombreux détails qui doivent être capturés avec précision.
Le positionnement, la longueur et l'orientation de chaque doigt peuvent varier considérablement selon les images.
Lors de la génération d'une image à partir d'une description textuelle, le modèle doit faire de nombreuses hypothèses sur la pose et la structure exactes de la main, ce qui peut conduire à des anomalies.
ChatGPT
ChatGPT est basé sur l'architecture GPT-3.5, un modèle basé sur un transformateur conçu pour les tâches de traitement du langage naturel.
- Entrée : une invite ou une série de messages pour simuler une conversation.
- Traitement : ChatGPT utilise ses vastes connaissances issues de divers textes Internet pour générer des réponses. Il prend en compte le contexte fourni dans la conversation et tente de produire la réponse la plus pertinente et cohérente.
- Résultat : une réponse textuelle qui continue ou répond à la conversation.
Spécialité
La force de ChatGPT réside dans sa capacité à traiter divers sujets et à simuler des conversations de type humain, ce qui le rend idéal pour les chatbots et les assistants virtuels.
Barde + Expérience générative de recherche (SGE)
Bien que des détails spécifiques puissent être exclusifs, Bard est basé sur des techniques d'IA de transformateur, similaires à d'autres modèles de langage de pointe. SGE est basé sur des modèles similaires mais intègre d'autres algorithmes ML utilisés par Google.
SGE génère probablement du contenu à l'aide d'un modèle génératif basé sur un transformateur, puis extrait les réponses des pages de classement dans la recherche. (Ce n'est peut-être pas vrai. Juste une supposition basée sur la façon dont cela semble fonctionner en jouant avec. S'il vous plaît, ne me poursuivez pas en justice !)
- Entrée : une invite/commande/recherche
- Traitement : Bard traite les entrées et fonctionne comme le font les autres LLM. SGE utilise une architecture similaire mais ajoute une couche où il recherche ses connaissances internes (acquises à partir des données de formation) pour générer une réponse adaptée. Il prend en compte la structure, le contexte et l'intention de l'invite pour produire un contenu pertinent.
- Résultat : contenu généré qui peut être une histoire, une réponse ou tout autre type de texte.
Applications de l'IA générative (et leurs controverses)
Art et désign
L'IA générative peut désormais créer des œuvres d'art, de la musique et même des conceptions de produits. Cela a ouvert de nouvelles voies pour la créativité et l’innovation.
Controverse
L’essor de l’IA dans l’art a suscité des débats sur les pertes d’emplois dans les domaines créatifs.
De plus, il existe des inquiétudes concernant :
- Violations du droit du travail, en particulier lorsque le contenu généré par l'IA est utilisé sans attribution ni compensation appropriée.
- Les dirigeants menaçant les écrivains de les remplacer par l’IA sont l’un des problèmes qui ont déclenché la grève des écrivains.
Traitement du langage naturel (NLP)
Les modèles d'IA sont désormais largement utilisés pour les chatbots, la traduction linguistique et d'autres tâches de PNL.
En dehors du rêve d’intelligence artificielle générale (AGI), c’est la meilleure utilisation des LLM puisqu’ils se rapprochent d’un modèle PNL « généraliste ».
Controverse
De nombreux utilisateurs trouvent les chatbots impersonnels et parfois ennuyeux.
De plus, même si l’IA a fait des progrès significatifs dans le domaine de la traduction linguistique, elle manque souvent des nuances et de la compréhension culturelle qu’apportent les traducteurs humains, ce qui conduit à des traductions impressionnantes et imparfaites.
Découverte de médicaments et de médicaments
L’IA peut analyser rapidement de grandes quantités de données médicales et générer des composés médicamenteux potentiels, accélérant ainsi le processus de découverte de médicaments. De nombreux médecins utilisent déjà les LLM pour rédiger des notes et des communications avec les patients.
Controverse
S'appuyer sur les LLM à des fins médicales peut être problématique. La médecine requiert de la précision, et toute erreur ou oubli de l’IA peut avoir de graves conséquences.
La médecine a également déjà des préjugés qui ne font que s’accentuer avec l’utilisation des LLM. Il existe également des problèmes similaires, comme indiqué ci-dessous, en matière de confidentialité, d'efficacité et d'éthique.
Jeux
De nombreux passionnés d’IA sont enthousiastes à l’idée d’utiliser l’IA dans les jeux : ils affirment que l’IA peut générer des environnements de jeu, des personnages et même des intrigues entières réalistes, améliorant ainsi l’expérience de jeu. Le dialogue avec les PNJ peut être amélioré grâce à l’utilisation de ces outils.
Controverse
Il y a un débat sur l'intentionnalité dans la conception de jeux.
Bien que l’IA puisse générer de grandes quantités de contenu, certains affirment qu’elle n’a pas la conception délibérée et la cohésion narrative qu’apportent les concepteurs humains.
Watchdogs 2 avait des PNJ programmatiques, ce qui n'ajoutait pas grand-chose à la cohésion narrative du jeu dans son ensemble.
Marketing et publicité
L’IA peut analyser le comportement des consommateurs et générer des publicités et du contenu promotionnel personnalisés, rendant ainsi les campagnes marketing plus efficaces.
Les LLM s'appuient sur le contexte des écrits d'autres personnes, ce qui les rend utiles pour générer des user stories ou des idées programmatiques plus nuancées. Au lieu de recommander des téléviseurs à quelqu'un qui vient d'acheter un téléviseur, les LLM peuvent recommander des accessoires dont quelqu'un pourrait avoir besoin.
Controverse
L’utilisation de l’IA dans le marketing soulève des problèmes de confidentialité. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Les opinions exprimées dans cet article sont celles de l’auteur invité et ne sont pas nécessairement celles de Search Engine Land. Les auteurs du personnel sont répertoriés ici.