
Alors que nous concluons 2016, parlons de la conclusion des tests CRO
Publié: 2021-10-23Alors que nous approchons de la clôture, encore une année, et tandis que la question « Quand ce test peut-il se terminer ? » revient toujours dans mes conversations au moins une fois par semaine, j'avais l'impression qu'il était temps de m'asseoir et d'écrire mon processus de conclusion de test et toutes les variables qui entrent en ligne de compte dans cette décision.
Aujourd'hui, je vais vous réchauffer avec deux conseils à garder à l'esprit lorsque vous approchez de la décision de conclusion, puis je vais passer aux quatre variables que j'examine lorsque vous abordez cette décision. Dépoussiérez ce manuel de statistiques que vous avez enterré il y a longtemps et commençons.
Conseil de préface n° 1 : Assurez-vous que vos données sont jolies et robustes
Avant de configurer votre test, vous devez déjà savoir quels sont vos objectifs. Remarquez comment j'ai dit "objectifs" là-bas. Oui, nous savons tous que vous devriez avoir une conversion centralisée ; la seule grande chose vers laquelle vous poussez vos utilisateurs. Mais il existe de nombreuses autres interactions avec n'importe quel site que nous pouvons suivre afin d'observer si notre altération a également affecté ces interactions. Voir l'image ci-dessous pour quelques exemples.

Avant d'analyser des données de test, vérifiez que vos données sont toutes sur un pied d'égalité. Assurez-vous d'avoir extrait des données pour chaque objectif pour la même plage de dates exacte afin de pouvoir comparer de manière appropriée les points de données sans fausser une chaîne de données. Pendant que vous êtes ici, assurez-vous également que toutes vos données d'objectif semblent «normales» et que vous ne soupçonnez aucun objectif raté ou mort qui n'a jamais vu aucune action.
Conseil de préface n°2 : ne jamais conclure sur une seule variable
Prendre une décision de conclusion ne peut pas se fonder sur une seule variable. Prenez chacune de ces quatre variables en considération et si la majorité des variables se complètent, alors vous pouvez conclure avec confiance.
Si toutes les variables se contredisent, vous pourriez envisager une multitude de scénarios divers. Mais à ce moment-là, si vous concluez, vous pourriez prendre une décision illogique aux conséquences coûteuses.
Chacune de ces variables est influencée par ou affecte au moins une des autres variables. Ainsi, les données complémentaires se soutiennent tandis que les données contradictoires vous obligent à relier des points avec des toiles de mensonges. Ne le fais pas !
Variable n° 1 : Taille de l'échantillon
La taille de l'échantillon compte. La taille de l'échantillon nous permet de généraliser en toute confiance un comportement basé sur notre population (nombre total d'utilisateurs) et notre marge d'erreur acceptable (significativité statistique de 100 objectifs).
C'est vraiment une question de proportions, mais si vous consultez constamment le même site avec très peu de fluctuations de trafic, vous pouvez définir un objectif de résultat à partir duquel travailler.
Une centaine d'utilisateurs pour chaque segment d'un test est un strict minimum. Même sur des sites à faible trafic, il est très difficile de généraliser des comportements à partir des données de quelques utilisateurs. Ainsi, plus on est de fous. Une taille d'échantillon plus élevée permet également d'annuler tous les biais que nous pourrions voir à partir des valeurs aberrantes.
Cependant, sur un site de commerce électronique assez grand qui attire au moins 1 000 utilisateurs par jour, il n'y a aucun moyen que je considère 100 et une taille d'échantillon d'utilisateurs appropriée. Tout est question de proportions et de volume d'utilisateurs typique pour votre site sur une base régulière.
Cette variable inclut les conversions ainsi que les utilisateurs pour les objectifs que vous prendrez en compte. Même si vous avez un site à faible taux de conversion, si vous comparez 0 conversions à 2 conversions, la variante avec 2 conversions gagnera très certainement simplement parce que c'était la seule variante à convertir techniquement.
Assurez-vous que vos conversions sont au moins à deux chiffres ; et si c'est votre strict minimum (chiffres à deux chiffres), assurez-vous d'avoir une forte action de compliment dans les trois autres variables.
Ou, si vous n'avez pas beaucoup d'expérience avec la taille d'échantillon dans un cadre statistique, vous pouvez utiliser ce calculateur de taille d'échantillon pratique pour déterminer une taille d'échantillon appropriée pour vous.
Variable #2 : Durée du test
Idéalement, je fais des tests de 2 à 6 semaines.
Deux semaines est un minimum solide car vous annulez la possibilité qu'une variable ait une "bonne" ou une "mauvaise" semaine et soit amener un trafic heureux, soit chasser un trafic peu motivé. Six semaines est un beau maximum car c'est un réseau temporel suffisamment large pour capturer toutes les fluctuations que vous pourriez voir.
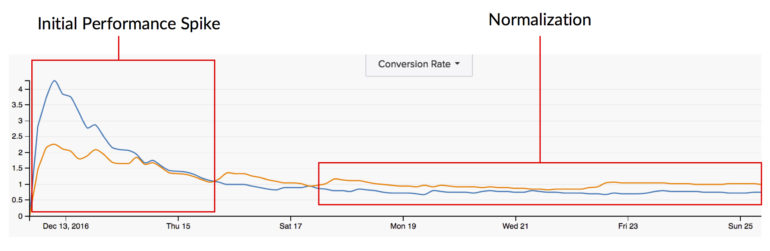
Cependant, notez que l'exécution d'un test pour toujours et à jamais peut également être préjudiciable à votre test. Un facteur important dans les résultats des tests est la réponse de l'utilisateur aux nouveaux stimuli. Ainsi, lorsque nous lançons un test pour la première fois, nous avons tendance à voir d'énormes sauts de la porte où une variation perd considérablement tandis que l'autre côte sur sa séquence de victoires. Au fil du temps, cet énorme écart entre les variations a tendance à se normaliser et à se fermer parce que le «nouveau» s'est estompé et que les utilisateurs qui reviennent ne sont plus aussi affectés par la nouvelle modification qu'ils l'étaient autrefois. Ainsi, plus le test est long, moins la modification est nouvelle et moins elle influence les comportements de ces utilisateurs récurrents.
Variable #3 : Importance statistique
Bien que la signification statistique soit essentielle pour déclarer la « confiance » dans votre conclusion, elle peut également être très trompeuse.
La signification statistique détermine si un changement dans deux taux est dû à une variance normale ou à un facteur extérieur. Ainsi, en théorie, lorsque nous atteignons une forte significativité statistique, nous savons que notre altération a eu un effet sur les utilisateurs.
Idéalement, vous voulez viser une signification statistique aussi proche que possible de 100 %. Plus vous êtes proche de 100%, plus votre marge d'erreur est faible. Cela signifie que vos résultats peuvent être reproduits de manière plus cohérente. Plus votre signification statistique est élevée, plus vous avez de chances de maintenir cette augmentation du taux de conversion si vous implémentez la variante gagnante. 95% est un bon objectif élevé à viser. 90% est un bon endroit pour s'installer. Si vous êtes inférieur à 90 %, vous devenez risqué de pouvoir conclure « en toute confiance ».
La menace ici est que la taille de l'échantillon compte vraiment. Vous pourriez atteindre une signification statistique de 98% en quelques jours et ne regarder littéralement qu'un total de 16 utilisateurs, ce qui n'est évidemment pas une taille d'échantillon digne de confiance.
La signification statistique peut également capturer cet énorme pic de performances auquel j'ai fait référence plus tôt lors du premier lancement d'un test. Les tests ont toutes les capacités de basculement et nous savons également qu'avec le temps, les données se normalisent. Ainsi, mesurer la signification statistique trop tôt pourrait nous donner une image complètement erronée de la façon dont cette modification affectera très probablement nos utilisateurs à plus long terme.
De plus, tous les tests ne gagneront pas en signification statistique. Certaines modifications que vous apportez peuvent ne pas influencer suffisamment le comportement de l'utilisateur pour être considérées comme une variance supérieure à la normale. Et c'est bien ! Cela signifie simplement que vous devez tester des modifications plus importantes pour capter un peu plus l'attention d'un utilisateur.
Variable n° 4 : Cohérence des données
Celui-ci va à tous ces tests de bascule là-bas. Certains tests refusent de se normaliser et refusent de vous présenter un gagnant clair. Ils passeront chaque jour à vous présenter une variante différente en tant que gagnant et ils vous rendront complètement dingue.
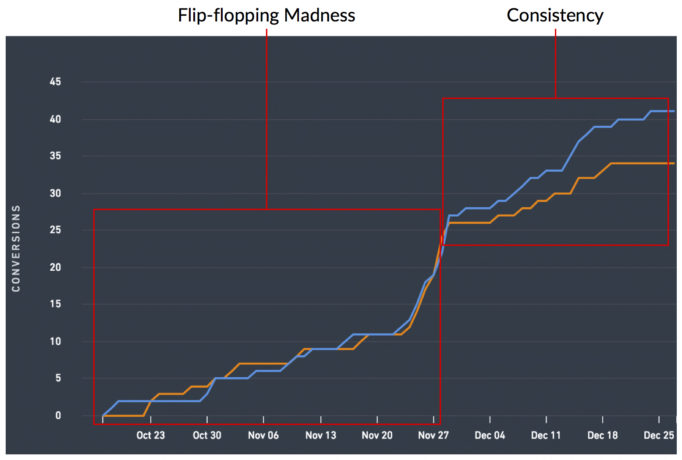
Mais ils existent et c'est exactement pourquoi la recherche d'une directionnalité cohérente des données est si cruciale. La variante que vous déclarez gagnante a-t-elle toujours été gagnante ? Si non, pourquoi n'a-t-il pas toujours été gagnant ? Si vous ne pouvez pas répondre avec assurance au « pourquoi ? » alors la mise en œuvre du gagnant pourrait nuire à vos résultats si vous mettez en œuvre la variation qui défile en tant que gagnant.
Je mesure également la différence entre le taux de conversion du contrôle et le taux de conversion de la variation (alias « lift » ou « drop »). Je recherche également que cette métrique soit cohérente afin de pouvoir m'assurer que le test est en dehors de la phase de pointe initiale.
Il est également avantageux de calculer périodiquement la signification statistique pour voir dans quelle mesure cette métrique se présente également.
Dernières pensées
La conclusion de tout type de test n'est pas une blague et est remplie de pression. Si vous faites le mauvais appel et mettez en œuvre quelque chose que vous « jugiez » gagnant alors que les données illustraient le contraire, votre résultat net et vos utilisateurs en souffriront.
Approchez une conclusion sous tous les angles viables afin de vous assurer d'avoir une conclusion vraiment confiante alimentée par des données !