
Wikipedia Web Scraping 2023 : Extraction de données pour analyse
Publié: 2023-03-29Le grattage en ligne vous permet de collecter des données ouvertes à partir de sites Web à des fins telles que la comparaison des prix, les études de marché, la vérification des publicités, etc.
De grandes quantités de données publiques nécessaires sont généralement extraites, mais lorsque vous rencontrez des blocages, l'extraction peut devenir difficile.
La restriction peut être soit un blocage de débit, soit un blocage d'IP (l'adresse IP de la requête est restreinte car elle provient d'une zone interdite, d'un type d'IP interdit, etc.). (l'adresse IP est bloquée car elle a fait plusieurs requêtes).

Maintenant, si vous êtes prêt à récupérer des connaissances et des informations utiles, je suis sûr que vous avez dû envisager de récupérer Wikipédia, l'encyclopédie des connaissances qui contient des tonnes d'informations.
Comprenons quelques éléments sur le grattage Web de Wikipédia.
Table des matières
Wikipédia Web Scraping
Le scraping Web est une méthode automatisée de collecte de données sur Internet. Des informations détaillées sur le web scraping, une comparaison avec le web crawling et des arguments en faveur du web scraping sont fournies dans cet article.
L'objectif est de collecter des données à partir de la page d'accueil de Wikipédia à l'aide de diverses méthodes de grattage Web, puis de les analyser.
Vous vous familiariserez avec diverses méthodes de grattage Web, les bibliothèques de grattage Web Python et les procédures d'extraction et de traitement de données.
Récupération Web et Python
Le scraping Web consiste essentiellement à extraire des données structurées d'une grande quantité de données à partir d'un grand nombre de sites Web à l'aide d'un logiciel créé dans un langage de programmation et à les enregistrer localement sur nos appareils, de préférence dans des feuilles Excel, JSON ou des feuilles de calcul.
Cela aide les programmeurs à créer un code logique et compréhensible pour les petits et les grands projets.
Python est principalement considéré comme le meilleur langage pour le scraping Web. Il peut gérer efficacement la majorité des tâches liées à l'exploration Web et est plus polyvalent.
Comment récupérer les données de Wikipédia ?
Les données peuvent être extraites des pages Web de différentes manières.
Par exemple, vous pouvez l'implémenter vous-même en utilisant des langages informatiques comme Python. Mais, à moins que vous ne soyez féru de technologie, vous devrez étudier beaucoup avant de pouvoir faire grand-chose avec ce processus.
Cela prend également du temps et peut prendre autant de temps que de parcourir manuellement les pages de Wikipédia. De plus, des grattoirs Web gratuits sont accessibles en ligne. Pourtant, ils manquent souvent de fiabilité et leurs fournisseurs peuvent avoir des intentions louches.
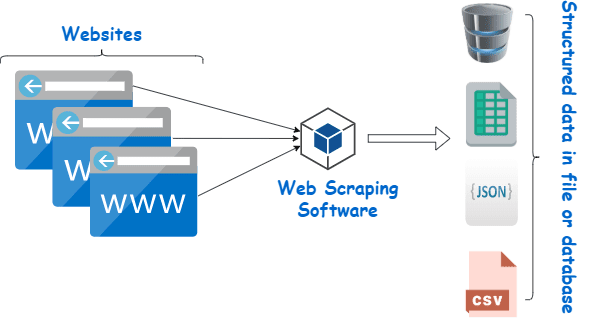
Investir dans un grattoir Web décent d'un fournisseur réputé est la meilleure méthode pour collecter des données Wiki.
La prochaine étape est généralement simple et peu compliquée car le fournisseur vous proposera des instructions sur la façon d'installer et d'utiliser le grattoir.
Un proxy est un outil que vous pouvez utiliser en conjonction avec votre scraper wiki pour mieux scraper efficacement les données. Les frameworks basés sur Python comme Scrapy, Scraping Robot et Beautiful Soup ne sont que quelques exemples de la facilité avec laquelle il est possible de gratter en utilisant ce langage.
Proxy pour extraire les données de Wikipedia
Vous avez besoin de proxys extrêmement rapides, sûrs à utiliser et garantis de ne pas vous tomber dessus lorsque vous en avez besoin afin de récupérer efficacement les données. Ces procurations sont disponibles auprès de Rayobyte à des prix raisonnables.
Nous nous efforçons d'offrir une variété de proxys car nous sommes conscients que chaque utilisateur a des préférences et des cas d'utilisation différents.
Rotation des proxys pour le grattage Web Wikipedia
Une instance de proxy est une instance qui fait régulièrement tourner son adresse IP. De plus, afin d'éviter les interruptions, l'adresse IP est immédiatement modifiée en cas d'interdiction. Cela fait de ce proxy particulier un excellent choix pour le grattage de sites.
Les proxys statiques, en comparaison, n'ont qu'une seule adresse IP. Si votre FAI n'autorise pas les remplacements automatisés, vous vous heurterez à un mur de briques si vous n'avez accès qu'à une seule adresse IP et qu'elle est bloquée. Pour cette raison, les proxys statiques ne sont pas la meilleure option pour le scraping Web.
Proxies résidentiels pour le grattage Web des données Wiki
Les proxys résidentiels sont des adresses IP proxy que les fournisseurs de services Internet (FAI) distribuent et sont associés à des foyers spécifiques. Parce qu'ils proviennent de vraies personnes, les obtenir est assez difficile. De ce fait, ils sont rares et relativement chers.


Lorsque vous utilisez des proxys résidentiels pour récupérer des données, vous semblez être un utilisateur ordinaire car ils sont liés aux adresses de personnes réelles.
Ainsi, l'utilisation de proxys résidentiels réduit considérablement vos chances d'être découvert et bloqué. Ce sont donc d'excellents candidats pour le data scraping.
Rotation des proxys résidentiels pour la collecte de données wiki
Un proxy résidentiel rotatif, qui combine les deux types dont nous venons de parler, est le meilleur proxy pour le web scraping de Wikipédia.
Vous pouvez accéder à un grand nombre d'adresses IP domestiques à l'aide d'un proxy qui les fait tourner fréquemment.
Ceci est essentiel car, malgré la difficulté d'identifier les proxys résidentiels, le volume de requêtes qu'ils génèrent finira par attirer l'attention du site Web en cours de scraping.
La rotation garantit que le projet peut continuer même si l'adresse IP est inévitablement mise sur liste noire.
Nous avons donc ce qu'il vous faut, que vous décidiez d'opter pour plusieurs proxys de centre de données ou que vous préfériez investir dans quelques proxys résidentiels.
Vous profiterez de la meilleure expérience de grattage Web avec des proxies fonctionnant à une vitesse de 1 GBS, une bande passante illimitée et une assistance client 24 heures sur 24.
Vous pouvez également lire
- Meilleures techniques de grattage Web : un guide pratique
- Octoparse Review Est-ce vraiment un bon outil de grattage Web?
- Meilleurs outils de grattage Web
- Qu'est-ce que le Web Scraping ? - À quoi sert-il ? Comment cela peut profiter à votre entreprise
Pourquoi devriez-vous gratter Wikipedia?
Wikipédia est actuellement l'un des services les plus fiables et les plus riches en informations du monde en ligne. Il y a des réponses et des informations sur presque toutes sortes de sujets auxquels vous pouvez penser sur cette plateforme.
Donc, naturellement, Wikipedia est une excellente source pour extraire des données. Discutons des principales raisons pour lesquelles vous devriez gratter Wikipedia.
Web scraping pour la recherche universitaire
La collecte de données est l'une des activités les plus pénibles de la recherche. Comme nous l'avons déjà mentionné, les grattoirs Web rendent cette procédure plus rapide et plus facile tout en vous faisant économiser une tonne de temps et d'énergie.
Avec un web scraper, vous pouvez parcourir rapidement de nombreuses pages wiki et collecter toutes les données dont vous avez besoin de manière organisée.
Supposons un instant que votre objectif soit de déterminer si la dépression et l'exposition au soleil varient selon les pays.
Vous pouvez utiliser un grattoir Wiki pour localiser des informations telles que la prévalence de la dépression dans différents pays et leurs heures d'ensoleillement au lieu de parcourir de nombreuses entrées Wikipédia.
Gestion de la réputation
La création d'une page Wikipédia est devenue une stratégie marketing incontournable pour de nombreux types d'entreprises à l'ère moderne, car les publications de Wikipédia apparaissent fréquemment sur la première page de Google.
Mais avoir une page sur Wikipédia ne devrait pas être la fin de vos efforts de marketing. Wikipédia est une plate-forme participative, donc le vandalisme est quelque chose qui se produit assez fréquemment.
En conséquence, quelqu'un pourrait ajouter des informations défavorables sur la page de votre entreprise et nuire à votre réputation. Alternativement, ils peuvent diffamer votre entreprise dans un article wiki pertinent.
Pour cette raison, vous devez garder un œil sur votre page Wiki ainsi que sur les autres pages qui mentionnent votre entreprise une fois qu'elle a été créée. Vous pouvez le faire facilement à l'aide d'un grattoir wiki.
Vous pouvez rechercher périodiquement sur les pages Wikipédia des références à votre entreprise et y signaler tout cas de vandalisme.
Boostez le référencement
Vous pouvez utiliser Wikipedia pour augmenter le trafic vers votre site Web.
Créez une liste d'articles que vous souhaitez modifier en utilisant un grattoir de données Wiki pour localiser les pages pertinentes pour votre entreprise et votre public cible.
Commencez par lire les articles et faites quelques ajustements utiles pour gagner en crédibilité en tant que contributeur au site.
Une fois que vous avez établi une certaine crédibilité, vous pouvez ajouter des connexions à votre site Web aux endroits où il y a des liens brisés ou où des citations sont nécessaires.
Liens rapides
- Meilleurs proxys français
- Meilleur meilleur proxy Spotify
- Meilleures procurations Nike
Bibliothèques Python utilisées pour le scraping Web
Python est le langage de programmation et l'outil de grattage Web le plus populaire et le plus réputé au monde, comme cela a déjà été dit. Examinons maintenant les bibliothèques de grattage Web Python disponibles actuellement.
Bibliothèque de requêtes (HTTP pour les humains) pour le scraping Web
Il est utilisé pour envoyer différentes requêtes HTTP, telles que GET et POST. De toutes les bibliothèques, c'est la plus fondamentale mais aussi la plus cruciale.
Bibliothèque lxml pour le scraping Web
L'analyse très rapide et performante du texte HTML et XML des sites Web est offerte par le package lxml. C'est celui à choisir si vous avez l'intention de gratter d'énormes bases de données.
Belle bibliothèque de soupes pour le grattage Web
Son travail consiste à construire un arbre d'analyse pour l'analyse du contenu. Un excellent point de départ pour les débutants et très convivial.
Bibliothèque de sélénium pour le grattage Web
Cette bibliothèque résout le problème rencontré par toutes les bibliothèques mentionnées ci-dessus, à savoir le grattage du contenu des pages Web peuplées de manière dynamique.
Il a été conçu à l'origine pour les tests automatisés d'applications Web. De ce fait, il est plus lent et inadapté aux tâches au niveau industriel.
Scrapy pour le Web Scraping
Un cadre complet de grattage Web qui utilise une utilisation asynchrone est le BOSS de tous les packages. Cela améliore l'efficacité et le rend extrêmement rapide.
Conclusion
C'était donc à peu près l'aspect le plus important que vous deviez connaître sur Wikipedia Web Scraping. Restez à l'écoute avec nous pour plus de messages informatifs sur le Web Scraping et bien plus encore !
Liens rapides
- Meilleurs proxies pour l'agrégation des tarifs de voyage
- Meilleurs proxys français
- Les meilleurs proxys Tripadvisor
- Meilleurs mandataires Etsy
- Code promo IPRoyal
- Meilleurs proxys TikTok