
Étude de cas SEO d'un an : ce que vous devez savoir sur Googlebot
Publié: 2019-08-30Note de l'éditeur : le PDG du robot d'exploration JetOctopus, Serge Bezborodov, donne des conseils d'expert sur la façon de rendre votre site Web attrayant pour Googlebot. Les données de cet article sont basées sur des recherches d'un an et sur 300 millions de pages explorées.
Il y a quelques années, j'essayais d'augmenter le trafic sur notre site Web d'agrégateur d'emplois avec 5 millions de pages. J'ai décidé d'utiliser les services d'une agence de référencement, m'attendant à ce que le trafic passe par le toit. Mais je me trompais. Au lieu d'un audit complet, j'ai fait lire des cartes de tarot. C'est pourquoi je suis revenu à la case départ et j'ai créé un robot d'exploration Web pour une analyse SEO complète sur la page.
J'espionne Googlebot depuis plus d'un an et je suis maintenant prêt à partager des informations sur son comportement. J'espère que mes observations clarifieront au moins le fonctionnement des robots d'indexation Web et vous aideront tout au plus à effectuer efficacement l'optimisation sur la page. J'ai rassemblé les données les plus significatives qui sont utiles pour un nouveau site Web ou un site Web contenant des milliers de pages.
Vos pages apparaissent-elles dans les SERP ?
Pour savoir avec certitude quelles pages figurent dans les résultats de recherche, vous devez vérifier la capacité d'indexation de l'ensemble du site Web. Cependant, les analyses de chaque URL sur un site Web de plus de 10 millions de pages coûtent une fortune, à peu près autant qu'une nouvelle voiture.
Utilisons plutôt l'analyse des fichiers journaux. Nous travaillons avec les sites Web de la manière suivante : nous explorons les pages Web comme le fait le robot de recherche, puis nous analysons les fichiers journaux qui ont été collectés pendant la moitié de l'année. Les journaux indiquent si les bots visitent le site Web, quelles pages ont été explorées et quand et à quelle fréquence les bots ont visité les pages.
L'exploration est le processus par lequel les robots de recherche visitent votre site Web, traitent tous les liens sur les pages Web et placent ces liens en ligne pour l'indexation. Pendant l'exploration, les bots comparent les URL qui viennent d'être traitées avec celles déjà présentes dans l'index. Ainsi, les robots actualisent les données et ajoutent/suppriment certaines URL de la base de données du moteur de recherche pour fournir les résultats les plus pertinents et les plus récents aux utilisateurs.
Maintenant, nous pouvons facilement tirer ces conclusions :
- À moins que le robot de recherche ne soit sur l'URL, cette URL ne sera probablement pas dans l'index.
- Si Googlebot visite l'URL plusieurs fois par jour, cette URL est prioritaire et nécessite donc votre attention particulière.
Au total, ces informations révèlent ce qui empêche la croissance organique et le développement de votre site Web. Désormais, au lieu d'opérer à l'aveuglette, votre équipe peut optimiser judicieusement un site Web.
Nous travaillons principalement avec de grands sites Web, car si votre site Web est petit, Googlebot explorera toutes vos pages Web tôt ou tard.
À l'inverse, les sites Web de plus de 100 000 pages sont confrontés à un problème lorsque le robot d'exploration visite des pages invisibles pour les webmasters. Un précieux budget de crawl peut être gaspillé sur ces pages inutiles voire nuisibles. Dans le même temps, le bot peut ne jamais trouver vos pages rentables car il y a un désordre dans la structure d'un site Web.
Le budget de crawl correspond aux ressources limitées que Googlebot est prêt à consacrer à votre site Web. Il a été créé pour hiérarchiser ce qu'il faut analyser et quand. La taille du budget de crawl dépend de nombreux facteurs, comme la taille de votre site web, sa structure, le volume et la fréquence des requêtes des utilisateurs, etc.
Notez que le robot de recherche n'est pas intéressé par l'exploration complète de votre site Web.
L'objectif principal du bot du moteur de recherche est de donner aux utilisateurs les réponses les plus pertinentes avec un minimum de pertes de ressources.Le bot analyse autant de données qu'il en a besoin pour l'objectif principal. C'est donc VOTRE tâche d'aider le bot à sélectionner le contenu le plus utile et le plus rentable.
Espionner Googlebot
Au cours de l'année dernière, nous avons analysé plus de 300 millions d'URL et 6 milliards de lignes de journal sur de grands sites Web. Sur la base de ces données, nous avons suivi le comportement de Googlebot pour aider à répondre aux questions suivantes :
- Quels types de pages sont ignorés ?
- Quelles pages sont fréquemment visitées ?
- Qu'est-ce qui mérite l'attention du bot ?
- Qu'est-ce qui n'a pas de valeur ?
Vous trouverez ci-dessous notre analyse et nos conclusions, et non une réécriture des directives Google Webmasters. En fait, nous ne donnons aucune recommandation non prouvée et injustifiée. Chaque point est basé sur des statistiques factuelles et des graphiques pour votre commodité.
Allons droit au but et découvrons :
- Qu'est-ce qui compte vraiment pour Googlebot ?
- Qu'est-ce qui détermine si le bot visite la page ou non ?
Nous avons identifié les facteurs suivants :
Distance de l'index
DFI signifie Distance From Index et correspond à la distance entre votre URL et l'URL principale/racine/index en clics. C'est l'un des critères les plus cruciaux qui influent sur la fréquence des visites de Googlebot. Voici une vidéo éducative pour en savoir plus sur DFI .
Notez que DFI n'est pas le nombre de barres obliques dans le répertoire URL comme, par exemple :
site.com/boutique/iphone/iphoneX.html – DFI– 3__ _
Ainsi, DFI est compté exactement par CLICS à partir de la page principale
https://site.com/shop/iphone/iphoneX.html
https://site.com Catalogue iPhone → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
Ci-dessous, vous pouvez voir comment l'intérêt de Googlebot pour l'URL avec son DFI a progressivement diminué au cours du dernier mois et au cours des six derniers mois.
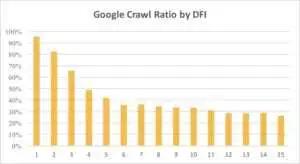
Comme vous pouvez le voir, si DFI est de 5 à 6, Googlebot n'explore que la moitié des pages Web. Et le pourcentage de pages traitées diminue si DFI est plus grand. Les indicateurs du tableau ont été unifiés pour 18 millions de pages. Notez que les données peuvent varier en fonction de la niche du site Web particulier.
Ce qu'il faut faire?
Il est évident que la meilleure stratégie dans ce cas est d'éviter les DFI plus longs que 5, de construire une structure de site Web facile à naviguer, d'accorder une attention particulière aux liens, etc.
La vérité est que ces mesures prennent beaucoup de temps pour les sites Web de plus de 100 000 pages. Habituellement, les grands sites Web ont une longue histoire de refontes et de migrations. C'est pourquoi les webmasters ne devraient pas simplement supprimer les pages avec un DFI de 10, 12 ou même 30. De plus, insérer un lien à partir de pages fréquemment visitées ne résoudra pas le problème.
La façon optimale de faire face aux longs DFI est de vérifier et d'estimer si ces URL sont pertinentes, rentables et quelles positions elles occupent dans les SERPs.
Les pages avec un long DFI mais de bonnes positions dans les SERP ont un potentiel élevé. Pour augmenter le trafic sur des pages de haute qualité, les webmasters doivent insérer des liens à partir des pages suivantes. Un à deux liens ne suffisent pas pour des progrès tangibles.
Vous pouvez voir sur le graphique ci-dessous que Googlebot visite les URL plus fréquemment s'il y a plus de 10 liens sur la page.
Liens
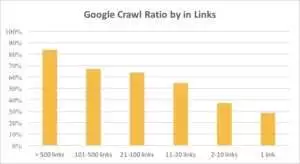
En effet, plus un site web est gros, plus le nombre de liens présents sur les pages web est important. Ces données proviennent en fait de sites Web de plus d'un million de pages.

Si vous découvrez qu'il y a moins de 10 liens sur vos pages rentables, ne paniquez pas. Tout d'abord, vérifiez si ces pages sont de haute qualité et rentables. Lorsque vous faites cela, insérez des liens sur des pages de haute qualité sans précipitation et avec de courtes itérations, en analysant les journaux après chaque étape.
Taille du contenu
Le contenu est l'un des aspects les plus populaires de l'analyse SEO. Bien sûr, plus le contenu de votre site Web est pertinent, meilleur est votre ratio de crawl. Ci-dessous, vous pouvez voir à quel point l'intérêt de Googlebot diminue considérablement pour les pages de moins de 500 mots.
Ce qu'il faut faire?
D'après mon expérience, près de la moitié de toutes les pages contenant moins de 500 mots sont des pages poubelles. Nous avons vu un cas où un site Web contenait 70 000 pages avec seulement la taille des vêtements répertoriés, donc seule une partie de ces pages figurait dans l'index.
Par conséquent, vérifiez d'abord si vous avez vraiment besoin de ces pages. Si ces URL sont importantes, vous devez leur ajouter du contenu pertinent. Si vous n'avez rien à ajouter, détendez-vous et laissez ces URL telles quelles. Parfois, il vaut mieux ne rien faire au lieu de publier du contenu inutile.
Autres facteurs
Les facteurs suivants peuvent avoir un impact significatif sur le ratio de crawl :
Temps de chargement
La vitesse des pages Web est cruciale pour l'exploration et le classement. Le bot est comme un humain : il déteste attendre trop longtemps le chargement d'une page Web. S'il y a plus d'un million de pages sur votre site Web, le robot de recherche téléchargera probablement cinq pages avec un temps de chargement d'une seconde plutôt que d'attendre une page qui se charge en 5 secondes.
Ce qu'il faut faire?
En fait, il s'agit d'une tâche technique et il n'y a pas de solution unique, telle que l'utilisation d'un serveur plus gros. L'idée principale est de trouver le goulot d'étranglement du problème. Vous devez comprendre pourquoi les pages Web se chargent lentement. Ce n'est qu'après que la raison est révélée que vous pouvez agir.
Ratio de contenu unique et de modèle
L'équilibre entre les données uniques et les modèles est important. Par exemple, vous avez un site Web avec des variantes de noms d'animaux de compagnie. Combien de contenu pertinent et unique pouvez-vous vraiment rassembler sur ce sujet ?
Luna était le nom de chien "célébrité" le plus populaire, suivi de Stella, Jack, Milo et Leo.
Les robots de recherche n'aiment pas dépenser leurs ressources sur ce type de pages.
Ce qu'il faut faire?
Maintenir l'équilibre. Les utilisateurs et les bots n'aiment pas visiter des pages avec des modèles compliqués, un tas de liens sortants et peu de contenu.
Pages orphelines
Les pages orphelines sont des URL qui ne sont pas dans la structure du site Web et vous ne connaissez pas ces pages, mais ces pages orphelines peuvent être explorées par des robots. Pour clarifier les choses, regardez le cercle d'Euler dans l'image ci-dessous :

Vous pouvez voir la situation normale du jeune site Web, dont la structure n'a pas été modifiée depuis un moment. Il y a 900 000 pages que vous et le crawler pouvez analyser. Environ 500 000 pages sont traitées par crawler mais sont inconnues de Google. Si vous rendez ces 500 000 URL indexables, votre trafic augmentera à coup sûr.
Faites attention : Même un jeune site Web contient des pages (la partie bleue sur l'image) qui ne sont pas dans la structure du site Web mais qui sont régulièrement visitées par des bots.
Et ces pages pourraient contenir du contenu inutile, comme des requêtes de visiteurs inutiles générées automatiquement.
Mais les grands sites Web sont rarement aussi précis. Très souvent, les sites Web avec historique ressemblent à ceci :

Voici l'autre problème : Google en sait plus sur votre site Web que vous. Il peut y avoir des pages supprimées, des pages sur JavaScript ou Ajax, des redirections cassées, etc. Une fois, nous avons été confrontés à une situation où une liste de 500 000 liens brisés est apparue dans le plan du site à cause d'une erreur d'un programmeur. Au bout de trois jours, le bogue a été trouvé et corrigé, mais Googlebot visitait ces liens brisés depuis six mois !
Très souvent, votre budget de crawl est fréquemment gaspillé sur ces pages orphelines.
Ce qu'il faut faire?
Il y a deux façons de résoudre ce problème potentiel : La première est canonique : nettoyer le gâchis. Organisez la structure du site Web, insérez correctement les liens internes, ajoutez des pages orphelines au DFI en ajoutant des liens à partir de pages indexées, définissez la tâche des programmeurs et attendez la prochaine visite de Googlebot.
La deuxième façon est rapide : rassemblez la liste des pages orphelines et vérifiez si elles sont pertinentes. Si la réponse est "oui", créez le sitemap avec ces URL et envoyez-le à Google. Cette méthode est plus simple et plus rapide, mais seulement la moitié des pages orphelines seront dans l'index.
Le niveau suivant
Les algorithmes des moteurs de recherche se sont améliorés depuis deux décennies, et il est naïf de penser que l'exploration de la recherche pourrait être expliquée avec quelques graphiques.
Nous rassemblons plus de 200 paramètres différents pour chaque page, et nous prévoyons que ce nombre augmentera d'ici la fin de l'année. Imaginez que votre site Web est le tableau avec 1 million de lignes (pages) et multipliez ces lignes par 200 colonnes, le simple échantillon n'est pas suffisant pour un audit technique complet. Êtes-vous d'accord?
Nous avons décidé d'approfondir et d'utiliser l'apprentissage automatique pour découvrir ce qui influence l'exploration des Googlebots dans chaque cas.

Pour l'un, les liens de sites Web sont cruciaux tandis que le contenu est le facteur clé pour l'autre.
L'objectif principal de cette tâche était d'obtenir des réponses simples à partir de données complexes et massives : qu'est-ce qui, sur votre site Web, a le plus d'impact sur l'indexation ? Quels groupes d'URL sont associés aux mêmes facteurs ? Pour que vous puissiez travailler avec eux de manière exhaustive.
Avant de télécharger et d'analyser les journaux sur notre site Web d'agrégateur HotWork, l'histoire des pages orphelines qui sont visibles pour les bots mais pas pour nous me semblait irréaliste. Mais la situation réelle m'a encore plus surpris : Crawl a montré 500 pages avec une redirection 301, mais Yandex a trouvé 700 000 pages avec ce même code d'état.
Habituellement, les geeks techniques n'aiment pas stocker des fichiers journaux car ces données « surchargent » les disques. Mais objectivement, sur la plupart des sites Web avec jusqu'à 10 millions de visites par mois, le réglage de base du stockage des journaux fonctionne parfaitement.
En parlant de volume de logs, la meilleure solution est de créer une archive et de la télécharger sur Amazon S3-Glacier (vous pouvez stocker 250 Go de données pour seulement 1$). Pour les administrateurs système, cette tâche est aussi simple que de préparer une tasse de café. À l'avenir, les journaux historiques aideront à révéler les bogues techniques et à estimer l'influence des mises à jour de Google sur votre site Web.