
Apache Spark: Bintang berkilau di cakrawala data besar.
Diterbitkan: 2015-09-24- Merekomendasikan jutaan produk kepada pelanggan yang tepat.
- Melacak riwayat pencarian dan menawarkan harga diskon untuk perjalanan penerbangan.
- Membandingkan keterampilan teknis seseorang dan dengan tepat menyarankan orang untuk terhubung dengan bidang Anda.
- Memahami pola dalam miliaran objek seluler, menara jaringan, dan transaksi panggilan serta menghitung optimalisasi jaringan telekomunikasi atau menemukan celah jaringan.
- Mempelajari jutaan fitur sensor dan menganalisis kegagalan dalam jaringan sensor.
Data dasar yang diperlukan untuk digunakan untuk mendapatkan hasil yang tepat untuk semua tugas di atas relatif sangat besar. Ini tidak dapat ditangani secara efisien (dalam hal ruang dan waktu) oleh sistem tradisional.
Ini semua adalah skenario data besar.
Untuk mengumpulkan, menyimpan, dan melakukan perhitungan pada jenis data yang sangat banyak ini, kita memerlukan sistem komputasi cluster khusus. Apache Hadoop telah memecahkan masalah ini untuk kami.
Ini menawarkan sistem penyimpanan terdistribusi (HDFS) dan platform komputasi paralel (MapReduce).
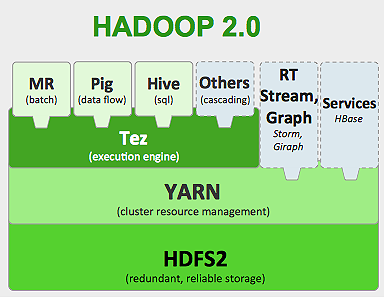
Kerangka kerja Hadoop bekerja seperti di bawah ini:
- Memecah file data besar menjadi potongan yang lebih kecil untuk diproses oleh mesin individual (Mendistribusikan Penyimpanan).
- Membagi pekerjaan yang lebih panjang menjadi tugas-tugas yang lebih kecil untuk dieksekusi secara paralel (Komputasi Paralel).
- Menangani kegagalan secara otomatis.
Keterbatasan Hadoop
Hadoop memiliki alat khusus di ekosistemnya untuk melakukan tugas yang berbeda. Jadi, jika Anda ingin menjalankan siklus hidup aplikasi dari ujung ke ujung, Anda harus menggunakan banyak alat. Misalnya, untuk kueri SQL yang akan Anda gunakan, hive/pig , untuk sumber streaming Anda harus menggunakan streaming bawaan Hadoop atau Apache Storm (Yang bukan bagian dari ekosistem Hadoop) atau untuk algoritme pembelajaran mesin Anda harus menggunakan Mahout . Mengintegrasikan semua sistem ini bersama-sama untuk membangun satu kasus penggunaan pipa data adalah tugas yang cukup berat.
Dalam pekerjaan MapReduce ,
- Semua keluaran tugas peta dibuang ke disk lokal (atau HDFS).
- Hadoop menggabungkan semua file tumpahan menjadi file yang lebih besar yang diurutkan dan dipartisi sesuai dengan jumlah reduksi.
- Dan mengurangi tugas harus memuatnya lagi ke dalam memori.
Proses ini membuat pekerjaan menjadi lebih lambat yang menyebabkan I/O Disk dan I/O jaringan. Ini juga membuat Mapreduce tidak layak untuk pemrosesan berulang di mana Anda harus menerapkan algoritme pembelajaran mesin ke kelompok data yang sama berulang kali.
Masuk ke dunia Apache Spark:
Apache Spark dikembangkan di UC Berkeley AMPLAB pada tahun 2009 dan pada tahun 2010 menjadi proyek open source kontribusi teratas Apache hingga saat ini.
Apache Spark adalah sistem yang lebih umum , di mana Anda dapat menjalankan pekerjaan batch dan streaming sekaligus. Ini menggantikan pendahulunya MapReduce dalam kecepatan dengan menambahkan kemampuan untuk memproses data lebih cepat di memori. Hal ini juga lebih efisien pada disk. Ini memanfaatkan pemrosesan memori menggunakan unit data dasarnya RDD (Resilient Distributed Dataset). Ini menyimpan dataset sebanyak mungkin dalam memori untuk menyelesaikan siklus hidup pekerjaan sehingga menghemat I/O disk. Beberapa data dapat tumpah ke disk setelah batas atas memori.
Grafik di bawah ini menunjukkan waktu berjalan dalam detik dari Apache Hadoop dan Spark untuk menghitung regresi logistik. Hadoop membutuhkan waktu 110 detik sementara percikan menyelesaikan pekerjaan yang sama hanya dalam 0,9 detik.
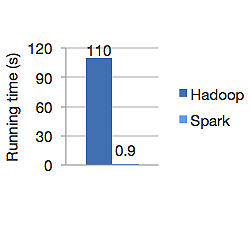
Spark tidak menyimpan semua data di memori. Tetapi jika data ada di memori, sebaiknya gunakan cache LRU untuk memprosesnya lebih cepat. Ini 100x lebih cepat saat menghitung data di memori dan masih lebih cepat di disk daripada Hadoop.
Model penyimpanan data terdistribusi Spark, dataset terdistribusi tangguh (RDD), menjamin toleransi kesalahan yang pada gilirannya meminimalkan I/O jaringan. Kertas percikan berkata:

"RDD mencapai toleransi kesalahan melalui gagasan garis keturunan: jika partisi RDD hilang, RDD memiliki informasi yang cukup tentang bagaimana partisi tersebut diturunkan dari RDD lain untuk dapat membangun kembali partisi itu saja."
Jadi, Anda tidak perlu mereplikasi data untuk mencapai toleransi kesalahan.
Di Spark MapReduce, keluaran pembuat peta disimpan dalam cache buffer OS dan reduksi menariknya ke sisi mereka dan menulisnya langsung ke memori mereka, tidak seperti Hadoop di mana keluaran tumpah ke disk dan membacanya lagi.
Cache memori Spark membuatnya cocok untuk algoritme pembelajaran mesin di mana Anda perlu menggunakan data yang sama berulang kali. Spark dapat menjalankan pekerjaan yang kompleks, beberapa jalur pipa data menggunakan Direct Acyclic Graph (DAGs).
Spark ditulis dalam Scala dan berjalan di JVM (Java Virtual Machine). Spark menawarkan API pengembangan untuk bahasa Java, Scala, Python, dan R. Spark berjalan di Hadoop YARN, Apache Mesos serta memiliki manajer cluster mandiri.
Pada tahun 2014 ini mengamankan tempat pertama dalam rekor dunia untuk menyortir data 100TB (1 triliun catatan) benchmark hanya dalam 23 menit, di mana rekor Hadoop sebelumnya oleh Yahoo adalah sekitar 72 menit. Ini membuktikan bahwa spark mengurutkan data 3 kali lebih cepat dan dengan mesin 10 kali lebih sedikit. Semua penyortiran terjadi pada disk (HDFS), tanpa benar-benar menggunakan kemampuan cache dalam memori percikan.
Ekosistem Percikan
Spark dimaksudkan untuk melakukan analitik tingkat lanjut sekaligus, untuk mencapai bahwa ia menawarkan komponen berikut:
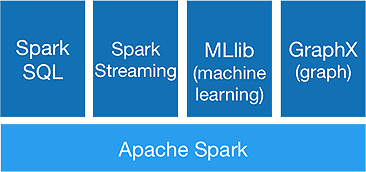
1. Inti Percikan:
API inti Spark adalah dasar kerangka kerja Apache Spark, yang menangani penjadwalan tugas, distribusi tugas, manajemen memori, operasi I/O, dan pemulihan dari kegagalan. Unit data logis utama di spark disebut RDD (Resilient Distributed Dataset), yang menyimpan data secara terdistribusi untuk diproses secara paralel nanti. Ini malas menghitung operasi. Oleh karena itu, memori tidak perlu ditempati sepanjang waktu, dan pekerjaan lain dapat memanfaatkannya.
2.Spark SQL:
Ini menawarkan kemampuan kueri interaktif dengan latensi rendah. DataFrame API baru dapat menampung data terstruktur dan semi-terstruktur dan memungkinkan semua operasi dan fungsi SQL melakukan komputasi.
3.Spark Streaming:
Ini menyediakan API streaming waktu nyata , yang mengumpulkan dan memproses data dalam kumpulan mikro.
Ini menggunakan Dstreams yang tidak lain adalah urutan RDD yang berkelanjutan, untuk menghitung logika bisnis pada data yang masuk dan menghasilkan hasil dengan segera.
4.MLlib :
Ini adalah perpustakaan pembelajaran mesin spark (hampir 9 kali lebih cepat dari Mahout) yang menyediakan pembelajaran mesin serta algoritma statistik seperti klasifikasi, regresi, pemfilteran kolaboratif, dll.
5.GraphX :
GraphX API menyediakan kemampuan untuk menangani grafik dan melakukan komputasi paralel grafik. Ini mencakup algoritma grafik seperti PageRank dan berbagai fungsi untuk menganalisis grafik.
Akankah Spark menandai berakhirnya Era Hadoop?
Sistem Spark masih muda, belum matang seperti Hadoop. Tidak ada alat untuk NOSQL seperti HBase. Mempertimbangkan kebutuhan memori yang tinggi untuk pemrosesan data yang lebih cepat, Anda tidak dapat benar-benar mengatakan itu berjalan pada perangkat keras komoditas. Spark tidak memiliki sistem penyimpanan sendiri. Itu bergantung pada HDFS untuk itu.
Jadi, Hadoop MapReduce masih bagus untuk pekerjaan batch tertentu, yang tidak menyertakan banyak pemipaan data.
“Teknologi baru tidak pernah sepenuhnya menggantikan yang lama; mereka berdua lebih suka hidup berdampingan.”
Kesimpulan
Di blog ini kami melihat mengapa Anda membutuhkan alat seperti Spark, yang membuatnya lebih cepat dari sistem komputasi klaster dan komponen intinya. Bagian selanjutnya kita akan masuk lebih dalam ke RDD, transformasi, dan tindakan API inti Spark.