
Bagaimana ChatGPT dapat membantu Anda mengoptimalkan konten untuk entitas
Diterbitkan: 2023-08-07Saat digunakan secara strategis, ChatGPT dapat melampaui upaya manual manusia dalam kualitas keluaran.
Tidak, alat tidak akan menulis konten yang lebih baik.
Sebaliknya, saya yakin seorang penulis yang dipersenjatai dengan teknologi ini dapat membuat konten yang dioptimalkan yang lebih selaras dengan kriteria peringkat Google.
Dengan menjelajahi berbagai metode penilaian konten dan ekstraksi entitas, saya bertujuan untuk memandu Anda memaksimalkan manfaat alat.
“Di luar kata kunci: Bagaimana entitas memengaruhi strategi SEO modern” membahas bagaimana dan mengapa menyertakan entitas yang relevan di seluruh situs web Anda (yaitu, peta topikal).
Artikel ini akan fokus pada mengapa dan bagaimana menggunakan entitas untuk membuat konten SEO dengan peringkat lebih baik.
Bagaimana entitas SEO dan OpenAI terkait?
Sebelum membahas bagaimana perangkat lunak mengoptimalkan penggunaan entitas untuk hasil pencarian, mari kita pahami kesamaan antara SEO entitas dan ChatGPT OpenAI.
Blok bangunan bahasa
Pada tingkat yang paling dasar, bahasa dibangun di sekitar:
- Subyek: Tentang apa (atau siapa) kalimat itu.
- Predikat: Mengatakan sesuatu tentang subjek.
Misalnya, dalam kalimat “The cat sat on the mat”, “The cat” adalah subjek dan “sat on the mat” adalah predikatnya.
Mesin pencari Google dan ChatGPT OpenAI dirancang untuk memahami struktur dasar bahasa.
Mesin pencari semantik fokus pada pemahaman konten dengan cara komputasi yang efisien.
ChatGPT melangkah lebih jauh, menggunakan komputasi yang jauh lebih banyak untuk menghasilkan konten.
Mesin pencari semantik
Mesin telusur Google mengidentifikasi entitas, yang pada dasarnya adalah subjek kalimat di laman web.
Kemudian menggunakan konteks di sekitar entitas tersebut untuk memahami predikat – atau apa yang dikatakan tentang entitas tersebut.
Ini memungkinkan Google untuk memahami konten halaman dan bagaimana relevansinya dengan kueri penelusuran pengguna.
Hubungan yang dipertimbangkan digambarkan dalam Grafik Pengetahuan Google.
Saat Google menganalisis sebuah artikel, Google menggunakan Grafik Pengetahuannya untuk mendapatkan wawasan yang lebih dalam.
Ini mengidentifikasi entitas yang relevan dan predikat dalam konten, yang memungkinkannya untuk membedakan pencarian kata kunci apa yang paling relevan dengan bagian tersebut.
ChatGPT OpenAI
Di sisi lain, ChatGPT menggunakan model transformator dan penyematannya untuk memahami subjek dan predikat.
Secara khusus, mekanisme perhatian model memungkinkannya untuk memahami hubungan antara kata-kata yang berbeda dalam sebuah kalimat, secara efektif memahami predikatnya.
Sementara itu, penyematan membantu model memahami hubungan dan makna kata itu sendiri, termasuk memahami subjek.

Terlepas dari perbedaan besar mereka, ChatGPT dan entitas SEO memiliki kemampuan yang sama:
Mengenali entitas dan predikat yang relevan dengan suatu topik. Kesamaan ini menggarisbawahi betapa pentingnya entitas untuk pemahaman kita tentang bahasa.
Terlepas dari kerumitannya, profesional SEO harus memfokuskan upaya mereka pada entitas, subjek, dan predikatnya.
Jadi bagaimana kita menggunakan pemahaman baru ini untuk mengoptimalkan konten kita?
Mengoptimalkan konten baru untuk entitas
Google mengidentifikasi entitas dan predikatnya di halaman web. Itu juga membandingkannya di seluruh halaman yang berpotensi relevan.
Intinya, ini seperti pencari jodoh, mencoba menemukan kecocokan terbaik antara kueri penelusuran pengguna dan konten yang tersedia di web.
Mengingat algoritme Google dioptimalkan untuk hasil berkualitas tinggi, mulailah proses pengoptimalan Anda dengan memeriksa 10 hasil Google teratas.
Ini akan memberi Anda wawasan tentang atribut yang disukai Google untuk istilah pencarian tertentu.
Di agensi kami, kami menerapkan kerangka kerja untuk mengidentifikasi peningkatan potensial yang dapat membuat artikel kami 10-20% lebih baik, yang akan saya bagikan di bawah.
Kerangka kerja yang memprioritaskan aspek yang tepat dapat menggambarkan perbedaan antara konten Anda dan materi dengan peringkat tertinggi.
Saat membuat konten, kami mengikuti kerangka kerja ini dan memenuhi item prioritas ini.
Kami mempersiapkan diri untuk sukses segera jika kami memenuhi semua kriteria ini.

Menyelami bagian entitas dari daftar periksa
Anggap saja seperti ini:
Bayangkan Google melacak seberapa sering entitas tertentu dan predikatnya muncul bersamaan.
Telah diketahui kombinasi mana yang paling penting bagi pengguna yang menelusuri topik tertentu.
Sebagai pakar SEO, tujuan Anda adalah memasukkan entitas kunci ini ke dalam konten Anda, yang dapat Anda identifikasi dengan merekayasa balik hasil teratas yang ditunjukkan Google kepada Anda.
Jika laman web Anda menyertakan entitas dan predikat yang diharapkan Google untuk penelusuran pengguna tertentu, konten Anda akan memperoleh skor lebih tinggi.
Kami akan membahas pengecualian relasi entitas baru dalam diskusi mendatang.
Di sinilah alat yang secara strategis memanfaatkan teknik ChatGPT dan NLP berperan untuk membantu menganalisis 10 hasil teratas.
Mencoba ini secara manual dapat memakan waktu dan sulit karena skala data yang harus Anda konsumsi.
Langkah 1: Mengekstraksi entitas
Untuk melakukan analisis ini, Anda harus meniru entitas asli Google dan proses ekstraksi predikat, lalu mengubah temuan Anda menjadi rencana tindakan/panduan penulis yang bisa diterapkan.
Dalam jargon teknis, latihan ini dikenal sebagai pengenalan entitas bernama, dan berbagai perpustakaan NLP memiliki pendekatan uniknya sendiri.
Untungnya, banyak alat penulisan konten yang tersedia di pasaran yang mengotomatiskan langkah-langkah ini.
Namun, sebelum Anda membabi buta mengikuti rekomendasi alat SEO, akan sangat membantu untuk memahami apa yang akan dan tidak akan berhasil dengan baik.
Pengakuan entitas bernama (NER)
Pikirkan NER sebagai proses dua langkah: melihat dan mengkategorikan.
Bercak
- Langkah pertama seperti permainan "I Spy". Algoritme membaca teks kata demi kata, mencari kata atau frasa yang bisa menjadi entitas. Ini seperti seseorang membaca buku dan menyoroti nama orang, tempat, atau tanggal.
Mengkategorikan
- Setelah algoritme menemukan entitas potensial, langkah selanjutnya adalah mencari tahu jenis entitas masing-masing. Ini seperti menyortir kata yang disorot ke dalam keranjang yang berbeda: satu untuk Orang , satu untuk Lokasi , satu untuk Tanggal , dan seterusnya.
Mari kita pertimbangkan sebuah contoh. Jika kita memiliki kalimat: "Elon Musk lahir di Pretoria pada tahun 1971."
Pada langkah bercak, algoritme mungkin mengidentifikasi "Elon Musk", "Pretoria", dan "1971" sebagai entitas potensial.
Pada langkah pengkategorian, kemudian akan mengklasifikasikan "Elon Musk" sebagai Orang , "Pretoria" sebagai Lokasi , dan "1971" sebagai Tanggal .
Algoritme menggunakan kombinasi aturan dan model pembelajaran mesin yang dilatih pada teks dalam jumlah besar.
Model-model ini telah belajar dari contoh seperti apa bentuk entitas yang berbeda, sehingga mereka dapat membuat tebakan cerdas saat menemukan teks baru.
Ekstraksi relasi (RE)
Setelah NER mengidentifikasi entitas dalam sebuah teks, langkah selanjutnya adalah memahami hubungan antar entitas tersebut.
Ini dilakukan melalui proses yang disebut ekstraksi relasi (RE). Hubungan ini pada dasarnya bertindak sebagai predikat yang menghubungkan entitas.
Dalam konteks NLP, koneksi ini sering direpresentasikan sebagai tripel, yang terdiri dari tiga item:
- Sebuah subjek.
- Sebuah predikat.
- Sebuah Objek.
Subjek dan objek biasanya adalah entitas yang diidentifikasi melalui NER, dan predikatnya adalah hubungan di antara mereka, yang diidentifikasi melalui RE.
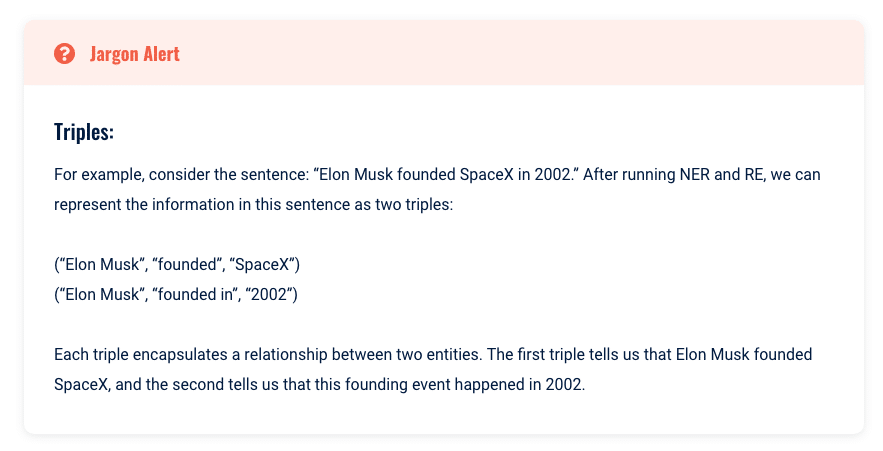
Konsep menggunakan tiga kali lipat untuk menguraikan dan memahami hubungan sangat sederhana. Kita dapat memahami gagasan inti yang disajikan dengan komputasi, waktu, atau memori minimal.
Ini adalah bukti sifat bahasa bahwa kita mendapatkan pemahaman yang baik tentang apa yang dikatakan dengan memusatkan perhatian hanya pada entitas dan predikatnya.
Hapus semua kata tambahan, dan yang tersisa adalah komponen kuncinya – sebuah snapshot, jika Anda mau, dari hubungan yang dijalin oleh penulis.
Mengekstraksi hubungan dan merepresentasikannya sebagai tiga kali lipat adalah langkah penting dalam NLP.
Ini memungkinkan komputer untuk memahami narasi teks dan konteks di sekitar entitas yang teridentifikasi, memungkinkan pemahaman yang lebih bernuansa dan pembuatan bahasa manusia.
Ingatlah bahwa Google masih berupa mesin, dan pemahaman bahasanya berbeda dengan pemahaman manusia.
Selain itu, Google tidak harus menulis konten tetapi harus menyeimbangkan kebutuhan komputasi. Alih-alih, itu dapat mengekstrak informasi dalam jumlah minimal yang mencapai tujuan menautkan konten ke kueri penelusuran.
Langkah 2: Membangun panduan penulis
Kita harus meniru proses ekstraksi entitas Google dan hubungannya untuk menghasilkan analisis dan peta jalan yang bermanfaat.
Kita harus memahami dan menerapkan dua gagasan utama ini dalam 10 hasil pencarian teratas. Untungnya, ada banyak cara untuk mendekati bangunan peta jalan.
- Kita dapat mengandalkan ekstraksi entitas
- Kami dapat mengekstrak frase kata kunci.
Rute entitas
Salah satu rute yang dapat diuji adalah metodologi yang mirip dengan alat seperti InLinks.
Platform ini menerapkan ekstraksi entitas pada 10 hasil teratas, kemungkinan menggunakan NER API Google Cloud.
Selanjutnya, mereka menentukan frekuensi minimum dan maksimum entitas yang diekstrak dalam konten.
Berdasarkan penggunaan Anda atas entitas ini, mereka menilai konten Anda.
Untuk menentukan keberhasilan penggunaan entitas dalam materi Anda, platform ini sering merancang algoritme pengenalan entitas mereka sendiri.
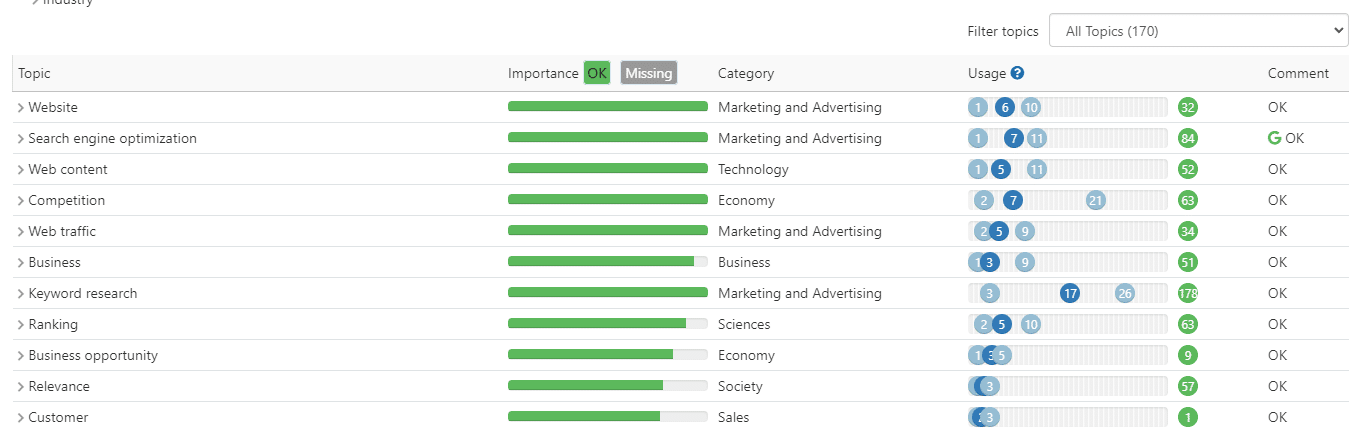
Pro dan kontra
Cara ini efektif dan dapat membantu Anda membuat konten yang lebih berwibawa. Namun, ini mengabaikan aspek utama: ekstraksi relasi.
Meskipun kami dapat mencocokkan penggunaan entitas dengan artikel peringkat teratas, sulit untuk memverifikasi apakah konten kami mencakup semua predikat atau hubungan yang relevan antara entitas ini. (Catatan: Google Cloud tidak membagikan API ekstraksi relasinya secara publik.)
Perangkap potensial lain dari strategi ini adalah mempromosikan penyertaan setiap entitas yang ditemukan dalam 10 artikel teratas.
Idealnya, Anda ingin mencakup semuanya, tetapi kenyataannya adalah bahwa beberapa entitas lebih berbobot daripada yang lain.
Hal-hal yang lebih rumit, hasil pencarian sering mengandung niat campuran, yang berarti beberapa entitas hanya relevan untuk artikel yang melayani maksud pencarian tertentu.
Misalnya, susunan entitas halaman daftar produk akan berbeda secara signifikan dari postingan blog.
Ini juga bisa menjadi tantangan bagi penulis untuk mengonversi entitas satu kata menjadi topik yang relevan untuk konten mereka. Mengaktifkan dan menonaktifkan pesaing tertentu dapat membantu memperbaiki masalah ini.
Jangan salah paham, saya penggemar alat ini dan menggunakannya sebagai bagian dari analisis saya.
Setiap pendekatan yang akan saya bagikan di sini memiliki kelebihan dan kekurangannya sendiri, yang semuanya dapat meningkatkan konten Anda sampai taraf tertentu.
Namun, tujuan saya adalah menyajikan beragam cara Anda dapat menggunakan teknologi dan ChatGPT untuk mengoptimalkan entitas.
Rute frase kata kunci
Strategi lain yang kami adopsi dalam alat kami melibatkan penggalian frase kata kunci yang paling penting dari 10 pesaing teratas.
Keindahan frase kata kunci terletak pada transparansinya, sehingga memudahkan pengguna akhir untuk memahami apa yang direpresentasikannya.
Plus, mereka biasanya menangkap subjek dan predikat topik utama, bukan hanya subjek atau entitas.
Namun, satu kelemahannya adalah pengguna sering kesulitan memasukkan kata kunci ini ke dalam konten mereka dengan mulus.
Sebaliknya, mereka cenderung menggunakan kata kunci, kehilangan esensi dari apa yang terkandung dalam frase kata kunci.
Sayangnya, dari sudut pandang pengembang, mengukur dan menilai seorang penulis berdasarkan kemampuan mereka menangkap esensi frase kata kunci itu sulit.
Oleh karena itu, pengembang harus menilai berdasarkan penggunaan yang tepat dari frase kata kunci, yang menghambat perilaku yang dimaksudkan sebenarnya.
Keuntungan signifikan lainnya dari pendekatan frase kata kunci adalah bahwa kata kunci sering berfungsi sebagai rambu untuk alat AI seperti ChatGPT, memastikan bahwa model teks generatif menangkap entitas kunci dan predikatnya (yaitu, tiga kali lipat).
Terakhir, pertimbangkan perbedaan antara diberi daftar kata benda yang panjang versus daftar frase kata kunci.
Anda mungkin merasa bingung untuk menenun narasi yang koheren dari daftar kata benda yang terputus sebagai penulis.
Namun ketika Anda disajikan dengan frase kata kunci, jauh lebih mudah untuk membedakan bagaimana mereka dapat saling berhubungan secara alami dalam sebuah paragraf, berkontribusi pada narasi yang lebih koheren dan bermakna.

Apa saja pendekatan berbeda untuk mengekstrak frase kata kunci?
Kami telah menetapkan bahwa frase kata kunci dapat secara efektif memandu topik apa yang perlu Anda tulis.
Namun, penting untuk dicatat bahwa alat yang berbeda di pasar memiliki pendekatan yang berbeda untuk mengekstrak frasa penting ini.
Ekstraksi kata kunci adalah tugas mendasar dalam NLP yang melibatkan identifikasi kata atau frasa penting yang dapat meringkas konten teks.
Ada beberapa algoritme ekstraksi kata kunci yang populer, masing-masing dengan kekuatan dan kelemahannya sendiri saat menangkap entitas di halaman.
TF-IDF (Frekuensi istilah-frekuensi dokumen terbalik)
Meskipun TF-IDF telah menjadi titik diskusi yang populer di kalangan SEO, namun sering disalahpahami, dan wawasannya tidak selalu diterapkan dengan benar.
Mematuhi penilaiannya secara membabi buta, secara mengejutkan, dapat mengurangi kualitas konten.
TF-IDF menimbang setiap kata dalam dokumen berdasarkan frekuensinya dalam dokumen dan kelangkaannya di semua dokumen.
Meskipun merupakan metode yang sederhana dan cepat, metode ini tidak mempertimbangkan konteks kata atau makna semantik.
Nilai apa yang bisa diberikannya
Kata-kata dengan skor tinggi mewakili istilah yang sering muncul di setiap halaman dan jarang di seluruh kumpulan halaman peringkat teratas.
Di satu sisi, istilah-istilah ini dapat dilihat sebagai penanda konten yang unik dan berbeda.
Mereka mungkin mengungkapkan aspek atau subtopik tertentu dalam tema kata kunci target Anda yang tidak sepenuhnya dicakup oleh pesaing, memungkinkan Anda memberikan nilai unik.
Namun, istilah dengan skor tinggi juga bisa menyesatkan.
TF-IDF dapat mengungkapkan skor tinggi pada istilah yang secara unik penting untuk artikel peringkat tertentu, tetapi tidak mewakili istilah atau topik yang secara umum penting untuk peringkat.
Contoh dasar dari hal ini adalah nama merek perusahaan. Itu bisa digunakan berulang kali dalam satu dokumen atau artikel tetapi tidak pernah di artikel peringkat lainnya.
Memasukkannya ke dalam konten Anda tidak masuk akal.
Di sisi lain, jika Anda menemukan istilah dengan skor TF-IDF lebih rendah yang muncul secara konsisten di seluruh halaman berperingkat tinggi, ini dapat menunjukkan konten "dasar" penting yang harus ada di halaman Anda.
Mereka mungkin tidak unik, tetapi mungkin diperlukan untuk relevansi dengan kata kunci atau topik tertentu.
Catatan: TF-IDF mewakili banyak strategi, tetapi matematika tambahan dapat diterapkan dalam variasi. Ini termasuk algoritme seperti BM25 untuk memperkenalkan titik jenuh atau perhitungan pengembalian yang semakin berkurang.
Selain itu, TF-IDF dapat ditingkatkan secara signifikan, dan sering kali, dengan menunjukkan secara retroaktif untuk setiap istilah persentase dari 10 halaman teratas yang menyertakan kata tersebut. Di sini, algoritme membantu Anda mengidentifikasi istilah yang patut diperhatikan tetapi kemudian membantu Anda lebih memahami istilah "dasar" dengan menunjukkan sejauh mana 10 istilah peringkat teratas berbagi istilah tersebut.
RAKE (Ekstraksi kata kunci otomatis cepat)
RAKE menganggap semua frasa sebagai kata kunci potensial, yang dapat berguna untuk menangkap entitas multi-kata.
Namun, itu tidak mempertimbangkan urutan kata, yang dapat menyebabkan frasa yang tidak masuk akal.
Menerapkan algoritme RAKE ke masing-masing dari 10 halaman teratas secara terpisah akan menghasilkan daftar frase kunci untuk setiap halaman.
Langkah selanjutnya adalah mencari tumpang tindih – frase kunci yang muncul di beberapa halaman peringkat teratas.
Frasa umum ini mungkin menunjukkan topik yang sangat penting yang diharapkan mesin telusur terkait dengan kata kunci target Anda.
Dengan mengintegrasikan frase ini ke dalam konten Anda sendiri (dengan cara yang bermakna dan alami), Anda berpotensi meningkatkan relevansi halaman Anda dan, dengan demikian, peringkatnya untuk kata kunci yang ditargetkan.
Namun, penting untuk diperhatikan bahwa tidak semua frasa yang dibagikan bermanfaat. Beberapa mungkin umum karena bersifat umum atau terkait luas dengan topik.
Tujuannya adalah untuk menemukan frasa bersama yang memiliki makna dan konteks signifikan yang terkait dengan kata kunci spesifik Anda.
Semua teknik ekstraksi kata kunci dapat ditingkatkan dengan memungkinkan Anda menggunakan otak Anda untuk mengaktifkan atau menonaktifkan pesaing atau kata kunci.
Kemampuan untuk menghidupkan dan mematikan pesaing dan kata kunci tertentu akan membantu mengatasi masalah yang disebutkan di atas.
Pesaing
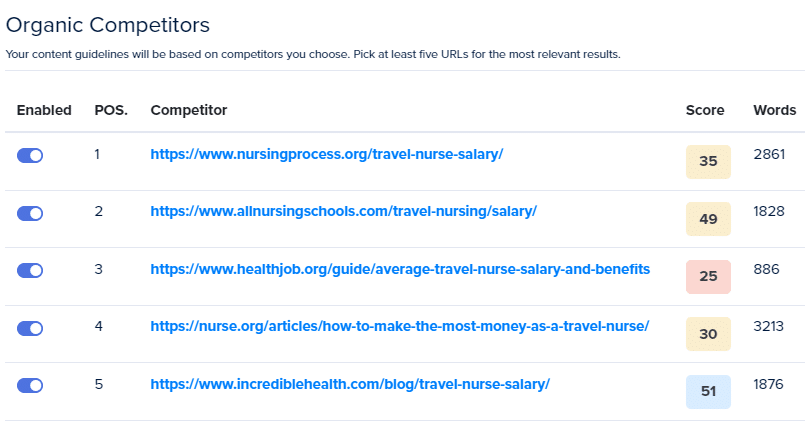
Kata kunci
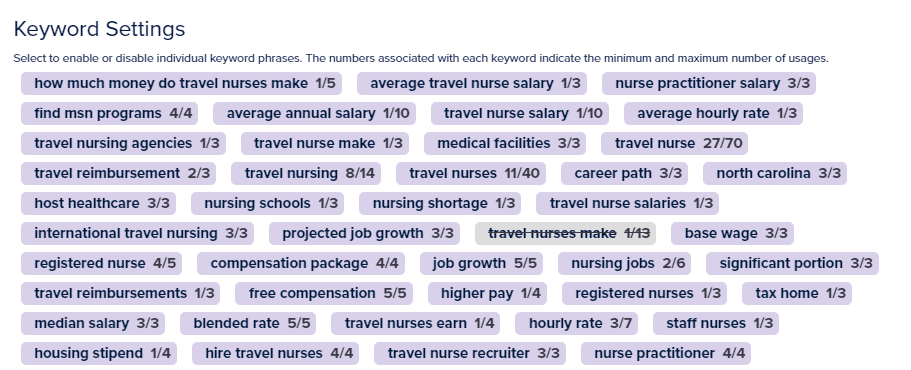
Pendekatan ini pada dasarnya menyediakan cara untuk menggabungkan kekuatan RAKE (mengidentifikasi frase kunci dalam dokumen individual) dan strategi yang lebih mirip TF-IDF (mempertimbangkan pentingnya istilah di seluruh kumpulan dokumen).
Dengan demikian, Anda dapat memanfaatkan pemahaman lanskap konten yang lebih holistik untuk kata kunci target Anda, memandu Anda untuk membuat konten yang unik dan relevan.
YAKE (Namun ekstraktor kata kunci lainnya)
Akhirnya, YAKE mempertimbangkan frekuensi kata dan posisinya dalam teks.
Ini dapat membantu mengidentifikasi entitas penting yang muncul di awal atau akhir dokumen.
Namun, mungkin kehilangan entitas penting yang muncul di tengah.
Setiap algoritma memindai teks dan mengidentifikasi kata kunci potensial berdasarkan berbagai kriteria (misalnya, frekuensi, posisi, kesamaan semantik).
Mereka kemudian menetapkan skor untuk setiap kata kunci potensial; kata kunci dengan skor tertinggi dipilih sebagai final.
Algoritme ini dapat menangkap entitas secara efektif, tetapi ada batasannya.
Misalnya, mereka mungkin melewatkan entitas langka atau tidak muncul sebagai kata kunci dalam teks. Mereka mungkin juga bergumul dengan entitas dengan banyak nama atau yang disebut dengan cara berbeda.
Singkatnya, kata kunci memberikan beberapa peningkatan dibandingkan NER langsung.
- Mereka lebih mudah dipahami oleh seorang penulis.
- Mereka menangkap predikat dan entitas.
- Seperti yang akan kita lihat di bagian selanjutnya, mereka berfungsi sebagai panduan yang lebih baik bagi AI untuk menulis konten yang dioptimalkan untuk entitas.
OpenAI
ChatGPT dan OpenAI benar-benar pengubah permainan dalam SEO.
Untuk membuka potensi penuhnya, diperlukan pakar SEO yang berpengetahuan luas untuk mengarahkannya ke jalur yang benar dan peta entitas yang dibuat dengan cermat untuk memandunya pada topik yang relevan untuk ditulis.
Pertimbangkan sebuah skenario:
Anda mungkin telah menyadari bahwa Anda dapat menuju ke ChatGPT dan memintanya untuk menulis artikel tentang hampir semua topik, dan itu akan segera dipatuhi.
Namun, pertanyaannya adalah, apakah artikel yang dihasilkan akan dioptimalkan untuk peringkat kata kunci?
Kami harus menarik perbedaan yang jelas antara konten umum dan konten yang dioptimalkan untuk pencarian.
Saat AI dibiarkan menggunakan perangkatnya sendiri untuk menulis konten Anda, AI cenderung menghasilkan artikel yang menarik bagi pembaca biasa.
Namun, konten yang dioptimalkan untuk SEO memiliki nada yang berbeda.
Google cenderung menyukai konten yang dapat dipindai, mencakup definisi dan pengetahuan latar belakang yang diperlukan, dan pada dasarnya menawarkan banyak kaitan bagi pembaca untuk menemukan jawaban atas permintaan pencarian mereka.
ChatGPT, yang ditenagai oleh arsitektur transformer, cenderung menghasilkan konten berdasarkan frekuensi dan pola yang diamati dalam data yang dilatihnya. Sebagian kecil dari data ini terdiri dari artikel Google peringkat teratas.
Sebaliknya, seiring berjalannya waktu, Google menyesuaikan hasil pencariannya dengan keefektifannya bagi pengguna – pada dasarnya bertahan dari potongan konten yang paling cocok.
Entitas yang ditemukan dalam artikel abadi ini sangat penting untuk ditiru sebagai konten dasar, yang cenderung menyimpang secara signifikan dari apa yang langsung diproduksi oleh ChatGPT.
Kesimpulan utamanya adalah ada perbedaan antara konten yang menjadi pemenang dari sudut pandang keterbacaan dan konten yang menjadi pemenang di lingkungan Google. Dalam dunia konten web, utilitas mengalahkan segalanya.
Seperti yang telah lama ditunjukkan oleh Nielsen, kemampuan memindai adalah yang tertinggi.

Pengguna lebih suka memindai konten web daripada membaca dari atas ke bawah. Perilaku ini biasanya mengikuti pola berbentuk F. Menulis konten yang berhasil dalam penelusuran harus fokus agar mudah dipindai vs. murni ditulis untuk dibaca dari atas ke bawah.
ChatGPT di luar kotak
Mari kita amati bagaimana kinerja ChatGPT langsung, menggunakan Noble dan Inlinks untuk penilaian.
Bahkan dengan permintaan yang dibuat dengan cermat, tanpa konteks tentang apa yang berfungsi di halaman pertama Google, ChatGPT sering meleset, menghasilkan konten yang tidak mungkin bersaing.
Saya mendorong ChatGPT untuk menulis artikel tentang "Berapa penghasilan perawat perjalanan per jam."
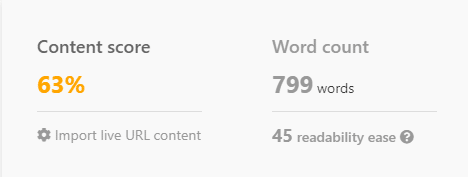

Ketika dipasangkan dengan analisis SEO
Namun, ChatGPT dapat menunjukkan kekuatannya yang sebenarnya jika digabungkan dengan analisis SERP dan kata kunci penting untuk peringkat.
Dengan meminta ChatGPT untuk memasukkan istilah-istilah ini, AI dipandu untuk menghasilkan konten yang relevan secara topikal.
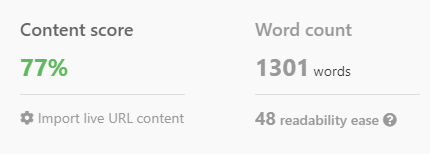

Berikut adalah beberapa poin penting untuk diingat
Sementara ChatGPT akan menggabungkan banyak entitas utama yang relevan dengan suatu topik, menggunakan alat yang menganalisis hasil SERP dapat secara signifikan meningkatkan campuran entitas dalam konten Anda.
Selain itu, perbedaan ini dapat lebih menonjol bergantung pada materi pelajaran, tetapi jika Anda menjalankan eksperimen ini lebih sering, Anda akan menemukan bahwa ini adalah tren yang konsisten.
Pendekatan berdasarkan kata kunci memenuhi dua persyaratan secara bersamaan:
- Pastikan penyertaan entitas yang paling penting.
- Berikan sistem penilaian yang lebih ketat karena mencakup predikat dan entitas.
Wawasan tambahan
ChatGPT mungkin mengalami kesulitan mencapai panjang konten yang diperlukan sendiri.
Semakin jauh maksud halaman menyimpang dari posting gaya blog, semakin terlihat kesenjangan kinerja antara alat ChatGPT dan SEO yang menggunakan ChatGPT secara terpisah.
Terlepas dari kemampuan AI, penting untuk mengingat faktor manusia. Tidak semua halaman harus dianalisis karena hasil pencarian yang beragam.
Selain itu, teknik ekstraksi kata kunci tidak mudah, dan kasus tepi dapat menghasilkan kata benda yang tidak relevan yang mungkin masih lolos dari sistem penilaian.
Oleh karena itu, keseimbangan optimal antara intervensi manusia dan AI melibatkan penonaktifan situs pesaing secara manual dengan maksud berbeda dan menyisir daftar kata kunci Anda untuk memangkas kata kunci yang salah.
Langkah terakhir: Mengambil satu langkah lebih jauh
Metode yang telah kita diskusikan adalah titik awal, memungkinkan Anda membuat konten yang mencakup lebih banyak entitas dan predikatnya daripada pesaing Anda.
Dengan mengikuti pendekatan ini, Anda menulis konten yang mencerminkan karakteristik laman yang disukai Google.
Tapi ingat, ini hanyalah titik awal. Halaman-halaman yang bersaing ini kemungkinan telah ada selama beberapa waktu dan mungkin telah memperoleh lebih banyak backlink dan metrik pengguna.
Jika tujuan Anda adalah mengungguli mereka, Anda harus membuat konten Anda lebih menonjol.
Saat web semakin jenuh dengan konten yang dihasilkan AI, masuk akal untuk berspekulasi bahwa Google mungkin mulai memilih situs web yang dipercaya untuk membangun hubungan entitas baru. Ini kemungkinan akan mengubah cara konten dievaluasi, lebih menekankan pemikiran orisinal dan inovasi.
Sebagai seorang penulis, ini berarti lebih dari sekadar menggabungkan subjek yang dicakup oleh 10 hasil teratas. Alih-alih, tanyakan pada diri Anda: perspektif unik apa yang dapat Anda tawarkan yang hilang dari 10 teratas saat ini?
Ini bukan hanya tentang alat. Ini tentang kita, ahli strategi, pemikir, pencipta.
Ini tentang bagaimana kami menggunakan alat-alat ini dan bagaimana kami menyeimbangkan kehebatan komputasi perangkat lunak dengan percikan kreatif dari pikiran manusia.
Sama seperti di dunia catur, kombinasi presisi mesin dan kecerdikan manusialah yang benar-benar membuat perbedaan.
Jadi, mari kita rangkul era baru SEO ini, di mana kita membuat konten dan menciptakan pengalaman yang selaras dengan audiens kita dan menonjol dalam lanskap digital yang luas.
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.