
Entitas SEO: Panduan definitif
Diterbitkan: 2023-04-06Artikel ini ditulis bersama oleh Andrew Ansley .
Benda, bukan string. Jika Anda belum pernah mendengarnya, ini berasal dari postingan blog Google terkenal yang mengumumkan Grafik Pengetahuan.
Peringatan 11 tahun pengumumannya hanya sebulan lagi, namun banyak yang masih berjuang untuk memahami apa sebenarnya arti "benda, bukan string" untuk SEO.
Kutipan tersebut merupakan upaya untuk menyampaikan bahwa Google memahami banyak hal dan bukan lagi algoritma pendeteksian kata kunci yang sederhana.
Pada Mei 2012, orang dapat berargumen bahwa entitas SEO lahir. Pembelajaran mesin Google, dibantu oleh basis pengetahuan semi-terstruktur dan terstruktur, dapat memahami makna di balik kata kunci.
Sifat bahasa yang ambigu akhirnya memiliki solusi jangka panjang.
Jadi jika entitas penting bagi Google selama lebih dari satu dekade, mengapa SEO masih bingung tentang entitas?
Pertanyaan bagus. Saya melihat empat alasan:
- Entitas SEO sebagai istilah belum digunakan secara luas untuk SEO agar merasa nyaman dengan definisinya dan karenanya memasukkannya ke dalam kosa kata mereka.
- Mengoptimalkan entitas sangat tumpang tindih dengan metode lama yang berfokus pada kata kunci. Akibatnya, entitas digabungkan dengan kata kunci. Selain itu, tidak jelas bagaimana entitas berperan dalam SEO, dan kata "entitas" terkadang dapat dipertukarkan dengan "topik" saat Google berbicara tentang subjek tersebut.
- Memahami entitas adalah tugas yang membosankan. Jika Anda ingin pengetahuan mendalam tentang entitas, Anda perlu membaca beberapa paten Google dan mengetahui dasar-dasar pembelajaran mesin. Entity SEO adalah pendekatan yang jauh lebih ilmiah untuk SEO – dan sains bukan untuk semua orang.
- Meskipun YouTube telah memengaruhi distribusi pengetahuan secara besar-besaran, YouTube telah meratakan pengalaman belajar untuk banyak mata pelajaran. Pembuat konten yang paling sukses di platform ini secara historis mengambil jalan yang mudah saat mengedukasi pemirsa mereka. Akibatnya, pembuat konten tidak menghabiskan banyak waktu untuk entitas hingga saat ini. Karena itu, Anda perlu mempelajari entitas dari peneliti NLP, dan kemudian Anda perlu menerapkan pengetahuan tersebut ke SEO. Paten dan makalah penelitian adalah kuncinya. Sekali lagi, ini memperkuat poin pertama di atas.
Artikel ini adalah solusi untuk keempat masalah yang mencegah SEO untuk sepenuhnya menguasai pendekatan berbasis entitas untuk SEO.
Dengan membaca ini, Anda akan belajar:
- Apa entitas itu dan mengapa itu penting.
- Sejarah pencarian semantik.
- Cara mengidentifikasi dan menggunakan entitas di SERP.
- Cara menggunakan entitas untuk menentukan peringkat konten web.
Mengapa entitas penting?
SEO Entitas adalah masa depan di mana mesin pencari mengarah sehubungan dengan memilih konten apa yang akan diberi peringkat dan menentukan maknanya.
Gabungkan ini dengan kepercayaan berbasis pengetahuan, dan saya yakin SEO entitas akan menjadi masa depan bagaimana SEO dilakukan dalam dua tahun ke depan.
Contoh entitas
Jadi bagaimana Anda mengenali entitas?
SERP memiliki beberapa contoh entitas yang mungkin pernah Anda lihat.
Jenis entitas yang paling umum terkait dengan lokasi, orang, atau bisnis.
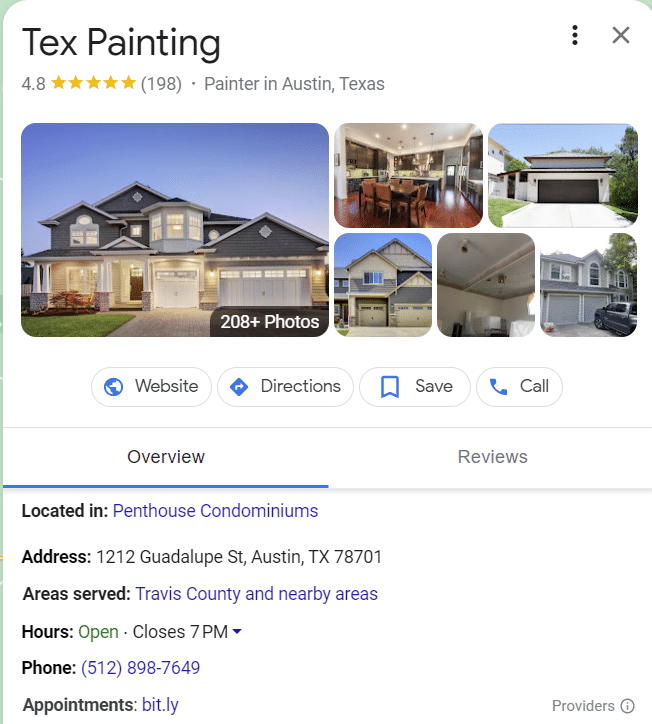
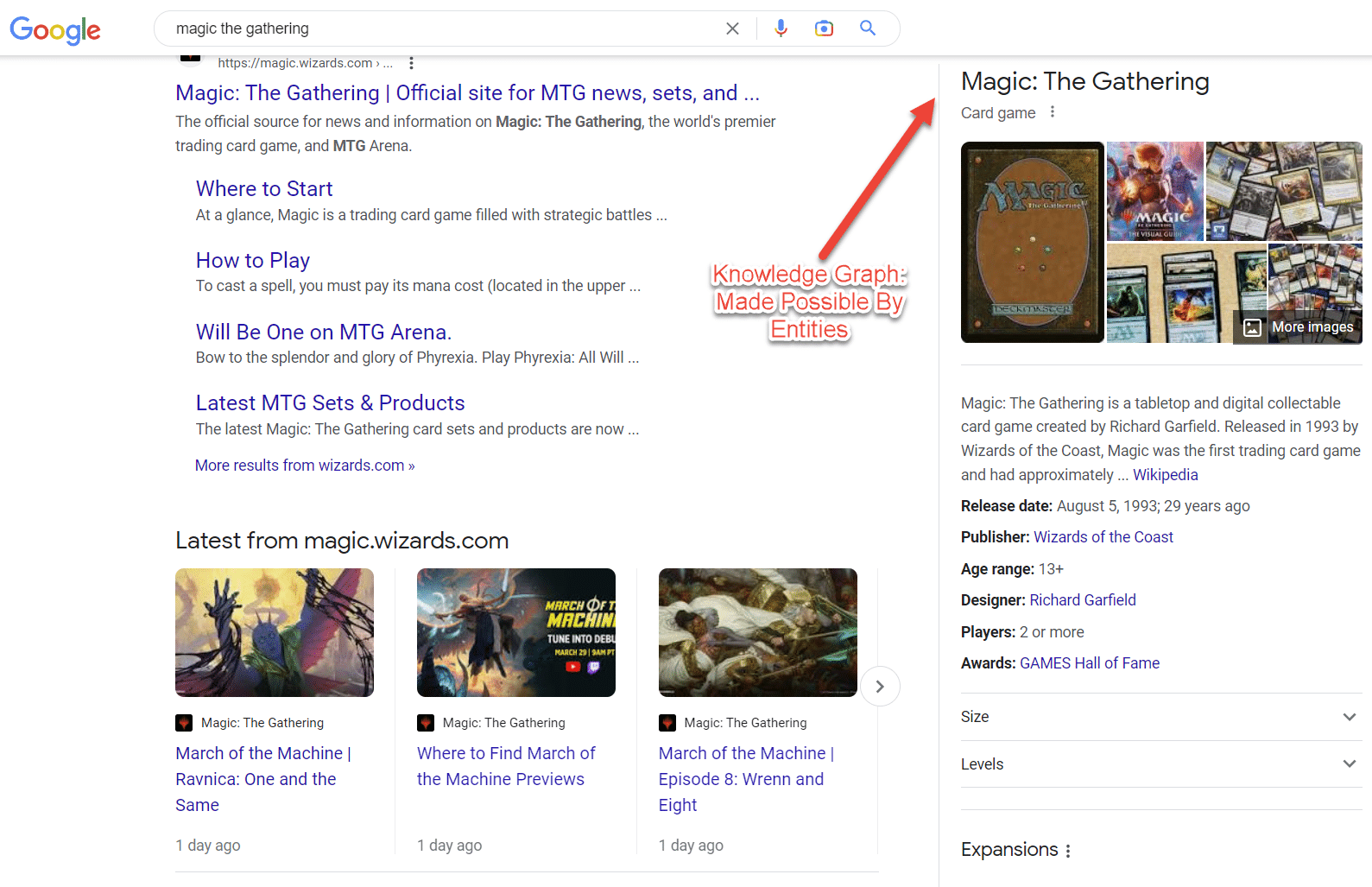
Mungkin contoh entitas terbaik di SERP adalah cluster niat. Semakin banyak topik dipahami, semakin banyak fitur pencarian ini muncul.
Yang cukup menarik, satu kampanye SEO dapat mengubah wajah SERP saat Anda tahu cara menjalankan kampanye SEO yang berfokus pada entitas.
Entri Wikipedia adalah contoh lain dari entitas. Wikipedia memberikan contoh yang bagus tentang informasi yang terkait dengan entitas.
Seperti yang bisa Anda lihat dari kiri atas, entitas memiliki segala macam atribut yang diasosiasikan dengan “ikan”, mulai dari anatominya hingga kepentingannya bagi manusia.
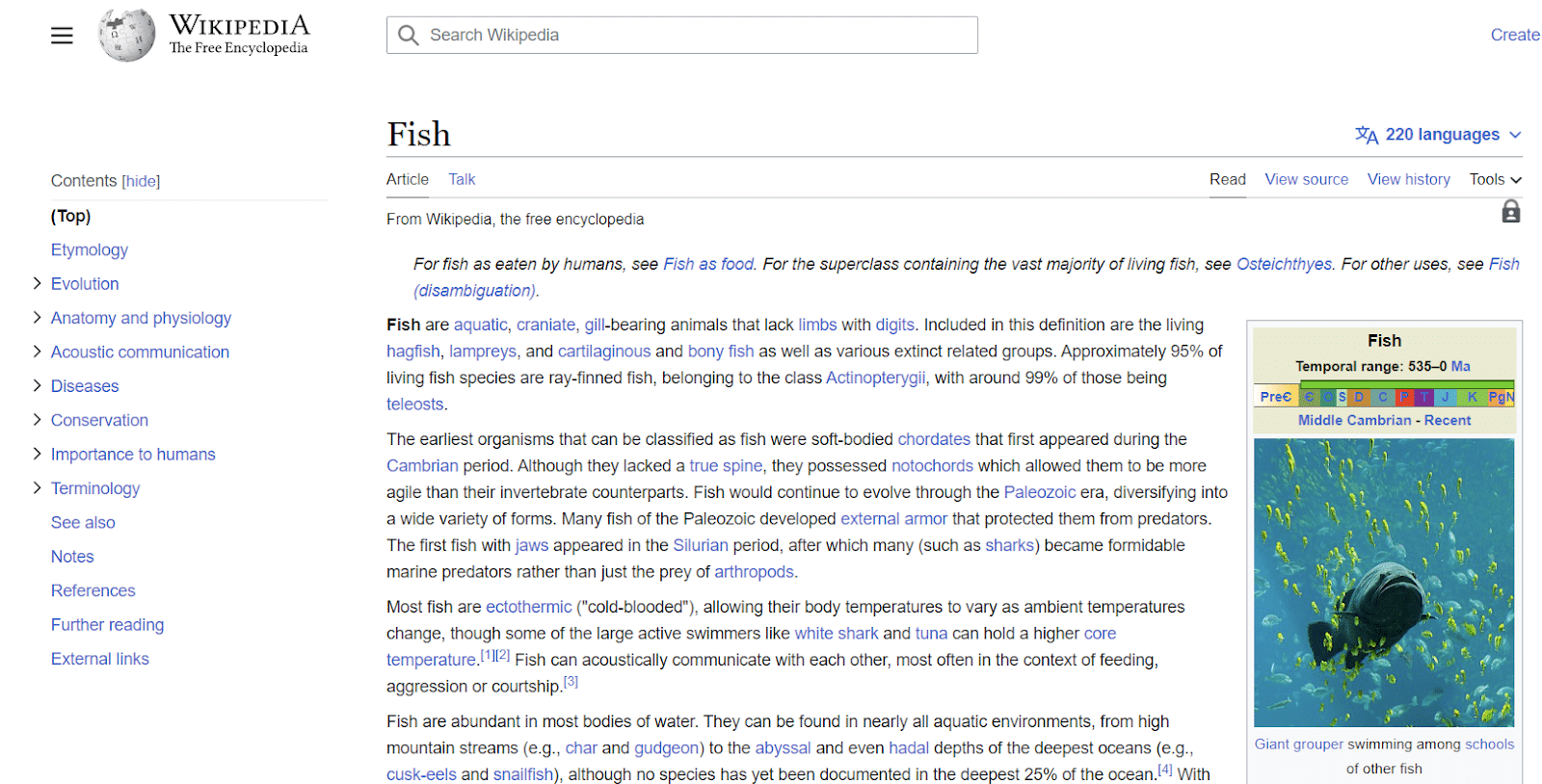
Meskipun Wikipedia berisi banyak poin data tentang suatu topik, itu tidak berarti lengkap.
Apa itu entitas?
Entitas adalah objek atau benda yang dapat diidentifikasi secara unik yang dicirikan oleh nama, jenis, atribut, dan hubungannya dengan entitas lain. Entitas hanya dianggap ada jika ada dalam katalog entitas.
Katalog entitas menetapkan ID unik untuk setiap entitas. Agensi saya memiliki solusi terprogram yang menggunakan ID unik yang terkait dengan setiap entitas (termasuk semua layanan, produk, dan merek).
Jika sebuah kata atau frase tidak ada di dalam katalog yang ada, itu tidak berarti bahwa kata atau frase itu bukan entitas, tetapi Anda biasanya dapat mengetahui apakah sesuatu itu entitas dengan keberadaannya di katalog.
Penting untuk dicatat bahwa Wikipedia bukanlah faktor penentu apakah sesuatu itu entitas, tetapi perusahaan ini paling terkenal dengan basis data entitasnya.
Katalog apa pun dapat digunakan saat berbicara tentang entitas. Biasanya, entitas adalah orang, tempat, atau benda, tetapi ide dan konsep juga dapat disertakan.
Beberapa contoh katalog entitas meliputi:
- Wikipedia
- Wikidata
- DBpedia
- Freebase
- Yago

Entitas membantu menjembatani kesenjangan antara dunia data terstruktur dan tidak terstruktur.
Mereka dapat digunakan untuk memperkaya teks yang tidak terstruktur secara semantik, sedangkan sumber tekstual dapat digunakan untuk mengisi basis pengetahuan terstruktur.
Mengenali penyebutan entitas dalam teks dan mengaitkan penyebutan ini dengan entri yang sesuai dalam basis pengetahuan dikenal sebagai tugas menghubungkan entitas.
Entitas memungkinkan pemahaman yang lebih baik tentang makna teks, baik untuk manusia maupun untuk mesin.
Sementara manusia dapat dengan mudah menyelesaikan ambiguitas entitas berdasarkan konteks di mana mereka disebutkan, ini menimbulkan banyak kesulitan dan tantangan bagi mesin.
Entri basis pengetahuan entitas merangkum apa yang kita ketahui tentang entitas itu.
Karena dunia terus berubah, begitu pula fakta baru yang muncul. Mengikuti perubahan ini membutuhkan upaya berkelanjutan dari editor dan pengelola konten. Ini adalah tugas yang menuntut dalam skala besar.
Dengan menganalisis isi dokumen yang menyebutkan entitas, proses penemuan fakta baru atau fakta yang perlu diperbarui dapat didukung atau bahkan diotomatisasi sepenuhnya.
Para ilmuwan menyebut ini sebagai masalah populasi basis pengetahuan, itulah sebabnya mengapa menghubungkan entitas itu penting.
Entitas memfasilitasi pemahaman semantik tentang kebutuhan informasi pengguna, seperti yang diungkapkan oleh kueri kata kunci, dan konten dokumen. Entitas dengan demikian dapat digunakan untuk meningkatkan kueri dan/atau representasi dokumen.
Dalam makalah penelitian Extended Named Entity, penulis mengidentifikasi sekitar 160 tipe entitas. Berikut adalah dua dari tujuh tangkapan layar dari daftar.


Kategori entitas tertentu lebih mudah didefinisikan, tetapi penting untuk diingat bahwa konsep dan ide adalah entitas. Kedua kategori tersebut sangat sulit bagi Google untuk mengukurnya sendiri.
Anda tidak dapat mengajarkan Google hanya dengan satu halaman saat bekerja dengan konsep yang tidak jelas. Pemahaman entitas membutuhkan banyak artikel dan banyak referensi yang berkelanjutan dari waktu ke waktu.
Sejarah Google dengan entitas
Pada 16 Juli 2010, Google membeli Freebase. Pembelian ini adalah langkah besar pertama yang mengarah ke sistem pencarian entitas saat ini.

Setelah berinvestasi di Freebase, Google menyadari bahwa Wikidata memiliki solusi yang lebih baik. Google kemudian bekerja untuk menggabungkan Freebase ke dalam Wikidata, sebuah tugas yang jauh lebih sulit dari yang diharapkan.
Lima ilmuwan Google menulis makalah berjudul "Dari Freebase ke Wikidata: Migrasi Hebat". Takeaway utama termasuk.
“Freebase dibangun di atas gagasan objek, fakta, tipe, dan properti. Setiap objek Freebase memiliki pengidentifikasi stabil yang disebut "pertengahan" (untuk ID Mesin).
“Model data Wikidata bergantung pada gagasan item dan pernyataan. Item mewakili entitas, memiliki pengidentifikasi stabil yang disebut "qid", dan mungkin memiliki label, deskripsi, dan alias dalam berbagai bahasa; pernyataan lebih lanjut dan pranala ke halaman tentang entitas di proyek Wikimedia lainnya – terutama Wikipedia. Bertentangan dengan Freebase, pernyataan Wikidata tidak bertujuan untuk menyandikan fakta yang sebenarnya, tetapi klaim dari sumber yang berbeda, yang juga dapat bertentangan satu sama lain…”
Entitas didefinisikan dalam basis pengetahuan ini, tetapi Google masih harus membangun pengetahuan entitasnya untuk data yang tidak terstruktur (yaitu, blog).
Google bermitra dengan Bing dan Yahoo dan membuat Schema.org untuk menyelesaikan tugas ini.
Google memberikan petunjuk skema sehingga pengelola situs web dapat memiliki alat yang membantu Google memahami konten. Ingat, Google ingin fokus pada hal-hal, bukan string.
Dalam kata-kata Google:
“Anda dapat membantu kami dengan memberikan petunjuk eksplisit tentang arti suatu halaman ke Google dengan menyertakan data terstruktur di halaman tersebut. Data terstruktur adalah format standar untuk memberikan informasi tentang halaman dan mengklasifikasikan konten halaman; misalnya di halaman resep, apa saja bahan-bahannya, waktu memasak dan suhunya, kalorinya, dan sebagainya.”
Google melanjutkan dengan mengatakan:
“Anda harus menyertakan semua properti yang diperlukan agar suatu objek memenuhi syarat untuk ditampilkan di Google Penelusuran dengan tampilan yang disempurnakan. Secara umum, menentukan lebih banyak fitur yang direkomendasikan dapat memperbesar kemungkinan informasi Anda muncul di hasil Penelusuran dengan tampilan yang disempurnakan. Namun, lebih penting untuk menyediakan properti yang direkomendasikan lebih sedikit tetapi lengkap dan akurat daripada mencoba menyediakan setiap kemungkinan properti yang direkomendasikan dengan data yang kurang lengkap, formatnya buruk, atau tidak akurat.”
Lebih banyak yang bisa dikatakan tentang skema, tetapi cukup untuk mengatakan skema adalah alat yang luar biasa untuk SEO yang ingin membuat konten halaman menjadi jelas bagi mesin pencari.
Bagian terakhir dari teka-teki tersebut berasal dari pengumuman blog Google berjudul "Meningkatkan Penelusuran untuk 20 Tahun Berikutnya".
Relevansi dan kualitas dokumen adalah gagasan utama di balik pengumuman ini. Metode pertama yang digunakan Google untuk menentukan konten halaman sepenuhnya berfokus pada kata kunci.
Google kemudian menambahkan lapisan topik ke pencarian. Lapisan ini dimungkinkan oleh grafik pengetahuan dan dengan menggores dan menyusun data secara sistematis di seluruh web.
Itu membawa kita ke sistem pencarian saat ini. Google berkembang dari 570 juta entitas dan 18 miliar fakta menjadi 800 miliar fakta dan 8 miliar entitas dalam waktu kurang dari 10 tahun. Seiring bertambahnya jumlah ini, pencarian entitas meningkat.
Bagaimana model entitas merupakan peningkatan dari model pencarian sebelumnya?
Model pencarian informasi berbasis kata kunci tradisional (IR) memiliki batasan inheren karena tidak dapat mengambil dokumen (relevan) yang tidak memiliki istilah eksplisit yang cocok dengan kueri.
Jika Anda menggunakan ctrl + f untuk menemukan teks pada halaman, Anda menggunakan sesuatu yang mirip dengan model pencarian informasi berbasis kata kunci tradisional.
Jumlah data yang gila-gilaan dipublikasikan di web setiap hari.
Tidak mungkin bagi Google untuk memahami arti setiap kata, setiap paragraf, setiap artikel, dan setiap situs web.
Sebagai gantinya, entitas menyediakan struktur yang darinya Google dapat meminimalkan beban komputasi sekaligus meningkatkan pemahaman.
“Metode pengambilan berbasis konsep mencoba untuk mengatasi tantangan ini dengan mengandalkan struktur tambahan untuk mendapatkan representasi semantik dari kueri dan dokumen di ruang konsep tingkat yang lebih tinggi. Struktur seperti itu termasuk kosakata terkontrol (kamus dan tesauri), ontologi, dan entitas dari gudang pengetahuan.
– Pencarian Berorientasi Entitas , Bab 8.3
Krisztian Balog, yang menulis buku definitif entitas, mengidentifikasi tiga kemungkinan solusi untuk model temu kembali informasi tradisional.
- Berbasis ekspansi : Menggunakan entitas sebagai sumber untuk memperluas kueri dengan istilah yang berbeda.
- Berbasis proyeksi : Relevansi antara kueri dan dokumen dipahami dengan memproyeksikannya ke ruang laten entitas
- Berbasis entitas : Representasi semantik eksplisit dari kueri dan dokumen diperoleh di ruang entitas untuk menambah representasi berbasis istilah.
Tujuan dari ketiga pendekatan ini adalah untuk mendapatkan representasi yang lebih kaya dari informasi pengguna yang dibutuhkan dengan mengidentifikasi entitas yang sangat terkait dengan kueri.
Balog kemudian mengidentifikasi enam algoritma yang terkait dengan metode pemetaan entitas berbasis proyeksi (metode proyeksi berhubungan dengan mengubah entitas menjadi ruang tiga dimensi dan mengukur vektor menggunakan geometri).
- Analisis semantik eksplisit (ESA) : Semantik kata tertentu dideskripsikan oleh vektor yang menyimpan kekuatan asosiasi kata tersebut ke konsep turunan Wikipedia.
- Model ruang entitas laten (LES) : Berdasarkan kerangka probabilistik generatif. Skor pengambilan dokumen dianggap sebagai kombinasi linier dari skor ruang entitas laten dan skor kemungkinan kueri asli.
- EsdRank: EsdRank adalah untuk memeringkat dokumen, menggunakan kombinasi fitur entitas kueri dan dokumen entitas. Ini sesuai dengan gagasan proyeksi kueri dan komponen proyeksi dokumen LES, masing-masing, dari sebelumnya. Dengan menggunakan kerangka pembelajaran diskriminatif, sinyal tambahan juga dapat digabungkan dengan mudah, seperti popularitas entitas atau kualitas dokumen
- Peringkat semantik eksplisit (ESR): Model peringkat semantik eksplisit menggabungkan informasi hubungan dari grafik pengetahuan untuk mengaktifkan "pencocokan lunak" di ruang entitas.
- Kerangka kerja duet entitas kata: Ini menggabungkan interaksi lintas ruang antara representasi berbasis istilah dan berbasis entitas, yang mengarah ke empat jenis kecocokan: istilah kueri ke istilah dokumen, entitas kueri ke istilah dokumen, istilah kueri ke entitas dokumen, dan entitas kueri untuk mendokumentasikan entitas.
- Model peringkat berbasis perhatian : Ini adalah yang paling rumit untuk dijelaskan.
Berikut tulisan Balog:
“Sebanyak empat fitur perhatian dirancang, yang diekstraksi untuk setiap entitas kueri. Fitur ambiguitas entitas dimaksudkan untuk mencirikan risiko yang terkait dengan anotasi entitas. Ini adalah: (1) entropi probabilitas bentuk permukaan dihubungkan ke entitas yang berbeda (misalnya, di Wikipedia), (2) apakah entitas beranotasi merupakan pengertian yang paling populer dari bentuk permukaan (yaitu, memiliki kesamaan tertinggi skor, dan (3) perbedaan skor kesamaan antara kandidat yang paling mungkin dan kandidat yang paling mungkin kedua untuk bentuk permukaan yang diberikan.Fitur keempat adalah kedekatan, yang didefinisikan sebagai kesamaan cosinus antara entitas kueri dan kueri dalam ruang embedding . Secara khusus, penyematan istilah entitas bersama dilatih menggunakan model skip-gram pada korpus, di mana penyebutan entitas diganti dengan pengidentifikasi entitas yang sesuai. Penyematan kueri dianggap sebagai titik berat penyematan istilah kueri."

Untuk saat ini, penting untuk memiliki pemahaman tingkat permukaan dengan enam algoritme yang berpusat pada entitas ini.
Pengambilan utama adalah bahwa ada dua pendekatan: memproyeksikan dokumen ke lapisan entitas laten dan anotasi dokumen entitas eksplisit.
Tiga jenis struktur data
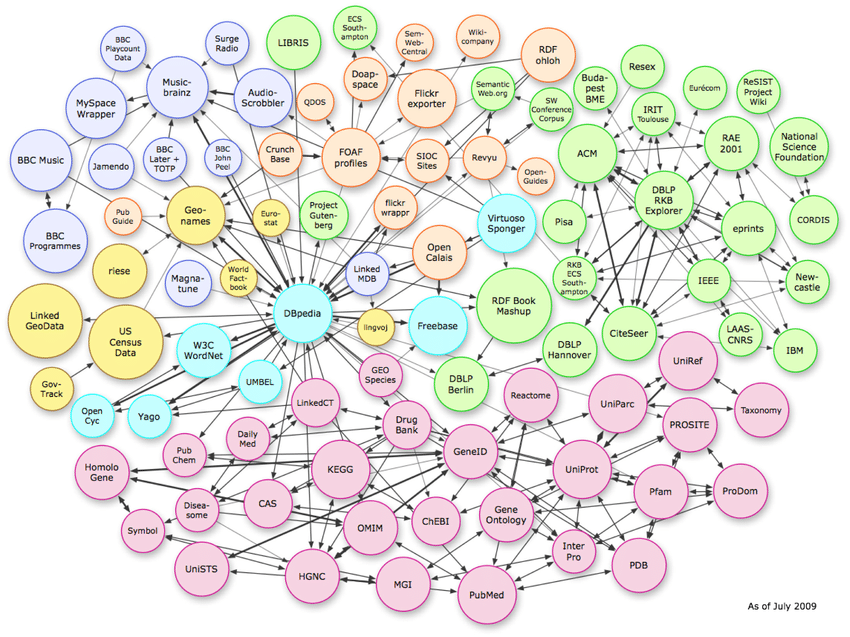
Gambar di atas menunjukkan hubungan kompleks yang ada dalam ruang vektor. Sementara contoh menunjukkan koneksi grafik pengetahuan, pola yang sama ini dapat direplikasi pada tingkat skema halaman demi halaman.
Untuk memahami entitas, penting untuk mengetahui tiga jenis struktur data yang digunakan algoritma.
- Menggunakan deskripsi entitas tidak terstruktur , referensi ke entitas lain harus dikenali dan didisambiguasi. Tepi terarah (hyperlink) ditambahkan dari setiap entitas ke semua entitas lain yang disebutkan dalam deskripsinya.
- Dalam pengaturan semi-terstruktur (yaitu, Wikipedia), tautan ke entitas lain mungkin disediakan secara eksplisit.
- Saat bekerja dengan data terstruktur , RDF tiga kali lipat menentukan grafik (yaitu, grafik pengetahuan). Secara khusus, sumber daya subjek dan objek (URI) adalah node, dan predikat adalah edge.
Masalah dengan konteks semi-terstruktur dan mengganggu untuk skor IR adalah bahwa jika dokumen tidak dikonfigurasi untuk satu topik, skor IR dapat dilemahkan oleh dua konteks berbeda yang mengakibatkan peringkat relatif hilang dari dokumen tekstual lainnya.
Pengenceran skor IR melibatkan hubungan leksikal yang tidak terstruktur dengan baik dan kedekatan kata yang buruk.
Kata-kata relevan yang melengkapi satu sama lain harus digunakan secara dekat di dalam paragraf atau bagian dokumen untuk menandai konteks dengan lebih jelas guna meningkatkan Skor IR.
Memanfaatkan atribut dan relasi entitas menghasilkan peningkatan relatif dalam kisaran 5–20%. Mengeksploitasi informasi tipe entitas bahkan lebih bermanfaat, dengan peningkatan relatif mulai dari 25% hingga lebih dari 100%.
Menganotasi dokumen dengan entitas dapat membawa struktur ke dokumen yang tidak terstruktur, yang dapat membantu mengisi basis pengetahuan dengan informasi baru tentang entitas.
Menggunakan Wikipedia sebagai kerangka SEO entitas Anda
Struktur halaman Wikipedia
- Judul (I.)
- Bagian timah (II.)
- Tautan disambiguasi (II.a)
- Kotak info (II.b)
- Teks pengantar (II.c)
- Daftar isi (III.)
- Isi tubuh (IV.)
- Lampiran dan materi bawah (V.)
- Referensi dan catatan (Va)
- Pranala luar (Vb)
- Kategori (Vc)
Sebagian besar artikel Wikipedia menyertakan teks pengantar, "petunjuk", ringkasan singkat artikel - biasanya, panjangnya tidak lebih dari empat paragraf. Ini harus ditulis dengan cara yang menciptakan minat pada artikel.
Kalimat pertama dan paragraf pembuka sangat penting. Kalimat pertama "dapat dianggap sebagai definisi entitas yang dijelaskan dalam artikel." Paragraf pertama menawarkan definisi yang lebih rumit tanpa terlalu banyak detail.
Nilai tautan melampaui tujuan navigasi; mereka menangkap hubungan semantik antar artikel. Selain itu, teks jangkar merupakan sumber yang kaya akan varian nama entitas. Tautan Wikipedia dapat digunakan, antara lain, untuk membantu mengidentifikasi dan memperjelas penyebutan entitas dalam teks.
- Ringkas fakta kunci tentang entitas (kotak info).
- Pengantar singkat.
- Tautan Internal. Aturan utama yang diberikan kepada editor adalah menautkan hanya ke kejadian pertama dari suatu entitas atau konsep.
- Sertakan semua sinonim populer untuk suatu entitas.
- Penunjukan halaman kategori.
- Templat Navigasi.
- Referensi.
- Alat Parsing khusus untuk memahami Halaman Wiki.
- Beberapa Jenis Media.
Cara mengoptimalkan untuk entitas
Berikut adalah pertimbangan utama saat mengoptimalkan entitas untuk pencarian:
- Dimasukkannya kata-kata yang terkait secara semantik pada halaman.
- Frekuensi kata dan frase pada halaman.
- Organisasi konsep pada halaman.
- Termasuk data tidak terstruktur, data semi terstruktur, dan data terstruktur pada halaman.
- Pasangan Subjek-Predikat-Objek (SPO).
- Dokumen web di situs yang berfungsi sebagai halaman buku.
- Organisasi dokumen web di situs web.
- Sertakan konsep pada dokumen web yang merupakan fitur entitas yang dikenal.
Catatan penting: Ketika penekanannya adalah pada hubungan antar entitas, basis pengetahuan sering disebut sebagai grafik pengetahuan.
Karena niat sedang dianalisis bersama dengan log pencarian pengguna dan bit konteks lainnya, frase pencarian yang sama dari orang 1 dapat menghasilkan hasil yang berbeda dari orang 2. Orang tersebut dapat memiliki maksud yang berbeda dengan kueri yang sama persis.
Jika halaman Anda mencakup kedua jenis maksud tersebut, maka halaman Anda adalah kandidat yang lebih baik untuk peringkat web. Anda bisa menggunakan struktur basis pengetahuan untuk memandu templat maksud kueri Anda (seperti yang disebutkan di bagian sebelumnya).
Orang Juga Bertanya, Orang Menelusuri, dan Pelengkapan Otomatis secara semantik terkait dengan kueri yang dikirimkan dan menyelam lebih dalam ke arah pencarian saat ini atau berpindah ke aspek lain dari tugas pencarian.
Kami mengetahui hal ini, jadi bagaimana kami dapat mengoptimalkannya?
Dokumen Anda harus berisi variasi maksud pencarian sebanyak mungkin. Situs web Anda harus berisi setiap variasi maksud pencarian untuk kluster Anda. Clustering bergantung pada tiga jenis kesamaan:
- Kesamaan leksikal.
- Kesamaan semantik.
- Klik kesamaan.
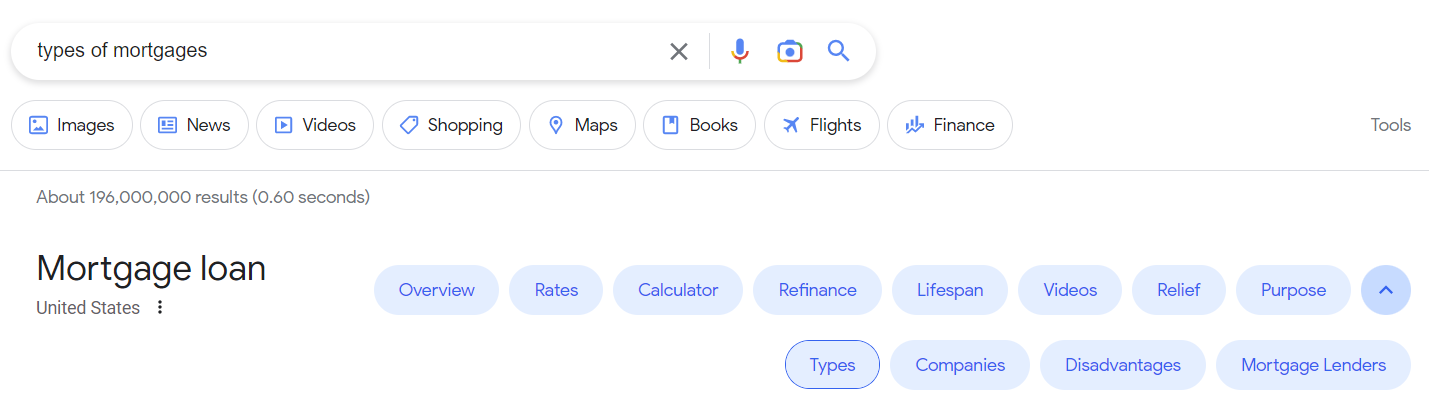
Cakupan topik
Apa itu –> Daftar atribut –> Bagian yang didedikasikan untuk setiap atribut –> Setiap bagian terhubung ke artikel yang sepenuhnya didedikasikan untuk topik itu –> Audiens harus ditentukan dan definisi untuk sub-bagian harus ditentukan –> Apa yang harus dipertimbangkan ? –> Apa manfaatnya? –> Manfaat pengubah –> Apa itu ___ –> Apa fungsinya? –> Cara mendapatkannya –> Cara melakukannya –> Siapa yang dapat melakukannya –> Tautkan kembali ke semua kategori

Google menawarkan alat yang memberikan skor arti-penting (mirip dengan cara kami menggunakan kata "kekuatan" atau "keyakinan") yang memberi tahu Anda cara Google melihat konten.

Contoh di atas berasal dari artikel Search Engine Land tentang entitas dari tahun 2018.
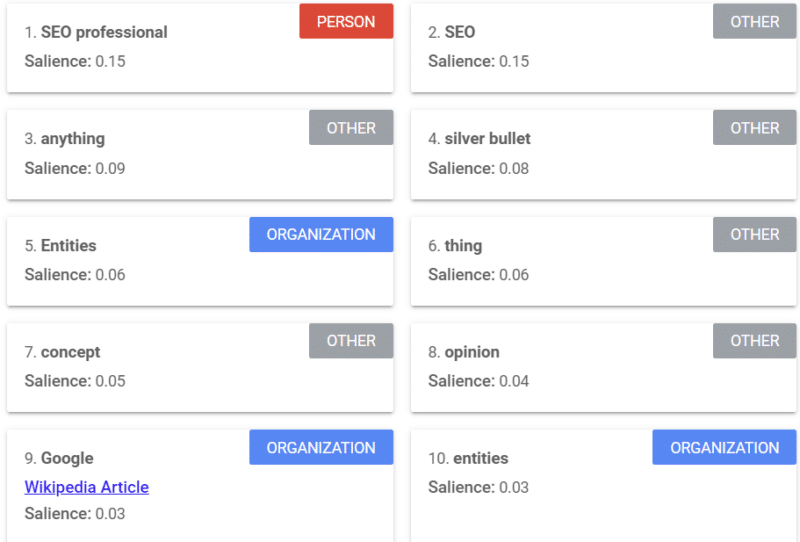
Anda dapat melihat orang, orang lain, dan organisasi dari contoh. Alat tersebut adalah API Bahasa Alami Google Cloud.
Setiap kata, kalimat, dan paragraf penting ketika berbicara tentang suatu entitas. Cara Anda mengatur pemikiran dapat mengubah pemahaman Google tentang konten Anda.
Anda dapat memasukkan kata kunci tentang SEO, tetapi apakah Google memahami kata kunci itu seperti yang Anda inginkan?
Coba tempatkan satu atau dua paragraf ke dalam alat dan atur ulang serta modifikasi contoh untuk melihat bagaimana hal itu meningkatkan atau menurunkan arti-penting.
Latihan ini, yang disebut "disambiguasi", sangat penting bagi entitas. Bahasa itu ambigu, jadi kita harus membuat kata-kata kita tidak terlalu ambigu di Google.
Pendekatan disambiguasi modern mempertimbangkan tiga jenis bukti:
Pentingnya entitas dan penyebutan sebelumnya.
Kemiripan kontekstual antara teks yang melingkupi penyebutan dan entitas kandidat serta koherensi di antara semua keputusan yang menghubungkan entitas dalam dokumen.
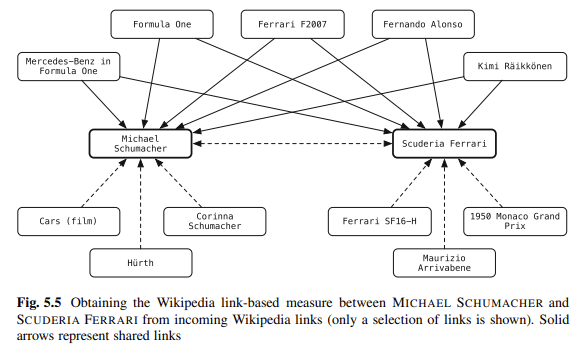
Skema adalah salah satu cara favorit saya untuk mendisambiguasi konten. Anda menautkan entitas di blog Anda ke repositori pengetahuan. Balog berkata:
“[L]memasukkan entitas dalam teks tidak terstruktur ke gudang pengetahuan terstruktur dapat sangat memberdayakan pengguna dalam aktivitas konsumsi informasi mereka.”
Misalnya, pembaca dokumen dapat memperoleh informasi kontekstual atau latar belakang dengan sekali klik, dan mereka dapat memperoleh akses mudah ke entitas terkait.
Anotasi entitas juga dapat digunakan dalam pemrosesan hilir untuk meningkatkan kinerja pengambilan atau untuk memfasilitasi interaksi pengguna yang lebih baik dengan hasil pencarian.
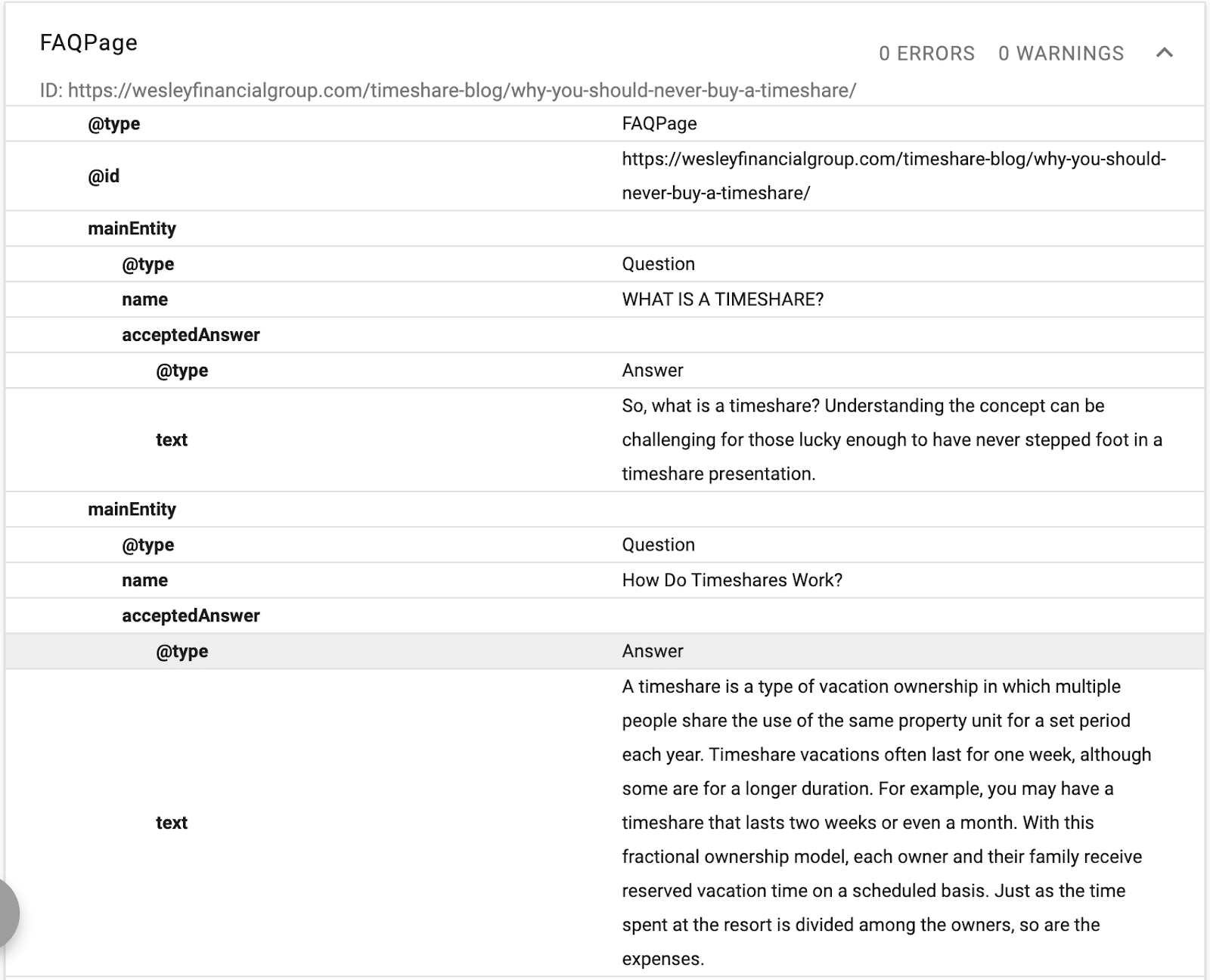
Di sini Anda dapat melihat bahwa konten FAQ disusun untuk Google menggunakan skema FAQ.
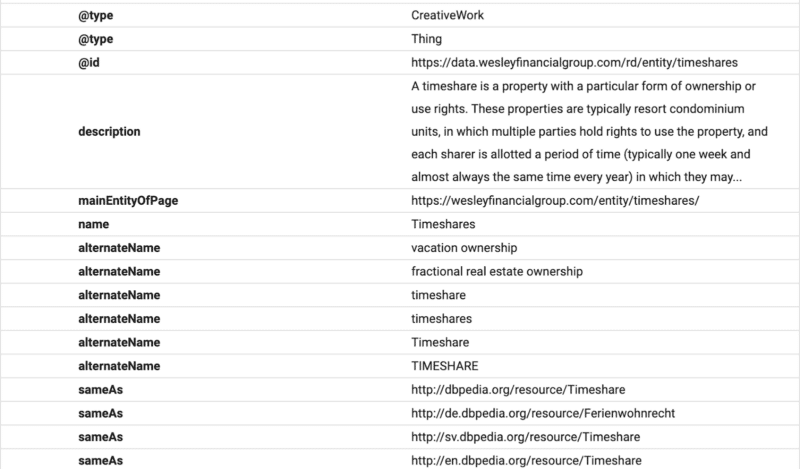
Dalam contoh ini, Anda dapat melihat skema yang memberikan deskripsi teks, ID, dan deklarasi entitas utama halaman.
(Ingat, Google ingin memahami hierarki konten, itulah mengapa H1–H6 penting.)
Anda akan melihat nama alternatif dan sama dengan deklarasi. Sekarang, ketika Google membaca konten, ia akan mengetahui basis data terstruktur mana yang dikaitkan dengan teks, dan ia akan memiliki sinonim dan versi alternatif dari kata yang ditautkan ke entitas.
Saat Anda mengoptimalkan dengan skema, Anda mengoptimalkan NER (bernama pengenalan entitas), juga dikenal sebagai identifikasi entitas, ekstraksi entitas, dan pemotongan entitas.
Idenya adalah untuk terlibat dalam Disambiguasi Entitas Bernama > Wikifikasi > Penautan Entitas.
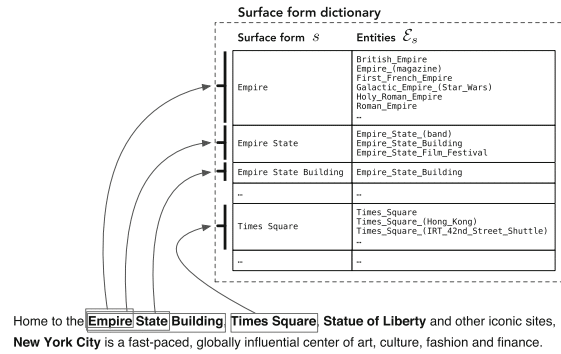
“Munculnya Wikipedia telah memfasilitasi pengenalan dan disambiguasi entitas skala besar dengan menyediakan katalog entitas yang komprehensif bersama dengan sumber daya tak ternilai lainnya (khususnya, hyperlink, kategori, dan halaman pengalihan dan disambiguasi.”
– Pencarian Berorientasi Entitas
Bagaimana caranya melampaui saran alat SEO
Sebagian besar SEO menggunakan beberapa alat di halaman untuk mengoptimalkan konten mereka. Setiap alat terbatas kemampuannya untuk mengidentifikasi peluang konten unik dan saran kedalaman konten.
Sebagian besar, alat di halaman hanya menggabungkan hasil SERP teratas dan membuat rata-rata untuk Anda tiru.
SEO harus ingat bahwa Google tidak mencari informasi pengulangan yang sama. Anda dapat menyalin apa yang dilakukan orang lain, tetapi informasi unik adalah kunci untuk menjadi situs unggulan/situs otoritas.
Berikut ini deskripsi sederhana tentang cara Google menangani konten baru:
Setelah dokumen ditemukan untuk menyebutkan entitas tertentu, dokumen tersebut dapat diperiksa untuk kemungkinan menemukan fakta baru yang dengannya entri basis pengetahuan entitas tersebut dapat diperbarui.
Balog menulis:
“Kami ingin membantu editor tetap mengikuti perubahan dengan secara otomatis mengidentifikasi konten (artikel berita, posting blog, dll.) yang mungkin menyiratkan modifikasi pada entri KB dari kumpulan entitas minat tertentu (yaitu, entitas yang diberikan editor tertentu). bertanggung jawab atas)."
Siapa pun yang meningkatkan basis pengetahuan, pengenalan entitas, dan kemampuan merayapi informasi akan mendapatkan cinta Google.
Perubahan yang dibuat dalam gudang pengetahuan dapat ditelusuri kembali ke dokumen sebagai sumber aslinya.
Jika Anda menyediakan konten yang mencakup topik dan menambahkan tingkat kedalaman yang jarang atau baru, Google dapat mengidentifikasi apakah dokumen Anda menambahkan informasi unik tersebut.
Akhirnya, informasi baru ini dipertahankan selama periode waktu tertentu dapat menyebabkan situs web Anda menjadi otoritas.
Ini bukan otoritas berdasarkan peringkat domain tetapi liputan topikal, yang menurut saya jauh lebih berharga.
Dengan pendekatan entitas untuk SEO, Anda tidak terbatas pada penargetan kata kunci dengan volume pencarian.
Yang perlu Anda lakukan hanyalah memvalidasi istilah kepala (“tongkat pancing terbang,” misalnya), dan kemudian Anda dapat berfokus pada penargetan variasi maksud pencarian berdasarkan pemikiran manusia mode yang baik.
Kita mulai dengan Wikipedia. Untuk contoh memancing, kita dapat melihat bahwa, minimal, konsep-konsep berikut harus dicakup di situs web memancing:
- Spesies ikan, sejarah, asal-usul, perkembangan, peningkatan teknologi, perluasan, metode memancing terbang, pengecoran, pengecoran mata-mata, memancing ikan trout terbang, teknik memancing terbang, memancing di air dingin, memancing ikan trout terbang kering, nimfa untuk ikan trout, air tenang memancing ikan trout, bermain ikan trout, melepaskan ikan trout, memancing air asin, tekel, lalat buatan, dan knot.
Topik di atas berasal dari halaman Wikipedia fly fishing. Meskipun halaman ini memberikan ikhtisar topik yang bagus, saya ingin menambahkan ide topik tambahan yang berasal dari topik terkait semantik.
Untuk topik “ikan”, kita dapat menambahkan beberapa topik tambahan, antara lain etimologi, evolusi, anatomi dan fisiologi, komunikasi ikan, penyakit ikan, konservasi, dan pentingnya bagi manusia.
Adakah yang mengaitkan anatomi ikan trout dengan keefektifan teknik memancing tertentu?
Apakah satu situs web memancing mencakup semua jenis ikan sambil menghubungkan jenis teknik memancing, joran, dan umpan ke setiap ikan?
Sekarang, Anda seharusnya sudah bisa melihat bagaimana perluasan topik bisa berkembang. Ingatlah hal ini saat merencanakan kampanye konten.
Jangan hanya mengulang. Tambahkan nilai. Jadilah unik. Gunakan algoritme yang disebutkan dalam artikel ini sebagai panduan Anda.
Kesimpulan
Artikel ini adalah bagian dari rangkaian artikel yang berfokus pada entitas. Di artikel berikutnya, saya akan menyelami lebih dalam upaya pengoptimalan seputar entitas dan beberapa alat yang berfokus pada entitas di pasar.
Saya ingin mengakhiri artikel ini dengan memberikan sapaan kepada dua orang yang menjelaskan banyak konsep ini kepada saya.
Bill Slawski dari SEO by the Sea dan Koray Tugbert dari Holistic SEO. Sementara Slawski tidak lagi bersama kami, kontribusinya terus memberikan efek riak dalam industri SEO.
Saya sangat mengandalkan sumber berikut untuk konten artikel, karena sumber ini adalah sumber terbaik yang ada pada topik:
- Hirarki Entitas Bernama yang Diperpanjang oleh Satoshi Ketine, Kiyoshi Sudo, dan Chikashi Nobata
- Pencarian Berorientasi Entitas oleh Krisztian Balog , Seri Pengambilan Informasi (INRE, volume 39)
- Penulisan Ulang Kueri Dengan Deteksi Entitas , Paten Google
- Menyempurnakan Kueri Penelusuran , Paten Google
- Mengaitkan Entitas Dengan Kueri Penelusuran , Paten Google
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.